参考来源:
图神经网络库PyTorch geometric(PYG)零基础上手教程
PyTorch Geometric 攻略
番外篇:PyG框架及Cora数据集简介
图神经网络(Graph Neural Networks, GNN)最近被视为在图研究等领域一种强有力的方法。跟传统的在欧式空间上的卷积操作类似,GNNs 通过对信息的传递,转换和聚合实现特征的提取。这篇博客主要想分享下,怎样在你的项目中简单快速地实现图神经网络。你将会了解到怎样用PyTorch Geometric 去构建一个图神经网络,以及怎样用GNN去解决一个实际问题(Recsys Challenge 2015)。
我们将使用 PyTorch 和 PyG(PyTorch Geometric Library)。PyG 是一个基于 PyTorch 的用于处理不规则数据(比如图)的库,或者说是一个用于在图等数据上快速实现表征学习的框架。它的运行速度很快,训练模型速度可以达到 DGL(Deep Graph Library )v0.2 的 40 倍(数据来自论文)。除了出色的运行速度外,PyG 中也集成了很多论文中提出的方法(GCN,SGC,GAT,SAGE 等等)和常用数据集。因此对于复现论文来说也是相当方便。由于速度和方便的优势,毫无疑问,PyG 是当前最流行和广泛使用的 GNN 库。让我们开始吧。
Requirments:
- Python 3
- PyTorch
- PyTorch Geometric
PyG Basics
这部分将会带你了解PyG的基础知识。重要的是会涵盖 torch_gemotric.data 和 torch_geometric.nn。 你将会了解到怎样将你的图数据导入你的神经网络模型,以及怎样设计一个 MessagePassing layer。这个也是 GNN 的核心。
Data
PyTorch Geometric 中设计了一种新的表示图数据的存储结构,也是 PyTorch Geometric 中实现的各种方法的基本数据形式。
在 torch_geometric.data 这个模块包含了一个叫 Data 的类。这个类允许你非常简单的构建你的图数据对象。你只需要确定两个东西:
- 节点的属性/特征(the attributes/features associated with each node, node features)
- 邻接/边连接信息(the connectivity/adjacency of each node, edge index)
在 PyTorch Geometric 中,一个图被定义为g=(X,(I,E)),其中X表示节点的特征矩阵,N为节点的个数,F为每个节点的特征数;用I,E这种元组形式表示图的稀疏邻接矩阵,I为边的索引,E为D维的边特征。
用于模型的图(graph)数据包括对象(nodes)及成对对象之间的关系(edges)组成。
用于 PyTorch Geometric 中的每个图(graph)都是 torch_geometric.data.Data 类型的实例。其属性有:
- data.x:节点特征矩阵,shape 为 [num_nodes, num_node_features]。
- data.edge_index:COO格式的 graph connectivity 矩阵,shape 为 [2, num_edges],类型为 torch.long。
- data.edge_attr:边的特征矩阵,shape 为 [num_edges, num_edge_features]。
- data.y:训练的 target,shape 不固定,比如,对于 node-level 任务,形状为 [num_nodes, ],对于 graph-level 任务,形状为 [1, ]。
- data.pos:节点的位置(position)矩阵,shape 为 [num_nodes, num_dimensions]。
**Data** 对象不是必须有上面所有的这些属性,也不是只能有这些属性。
PyTorch Geometric 已经实现了基于这种图数据结构的常用操作。
例1:对于一个不带权重的无向图,有三个节点和四条边,每一个节点的特征维度为1,如下图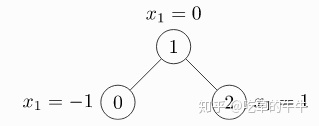
注意:这里一条无向边使用两条边(节点对)表示,比如对于节点 0 和 1,无向边表示为 (0,1) 和 (1,0)。
import torchfrom torch_geometric.data import Dataedge_index = torch.tensor([[0, 1, 1, 2],[1, 0, 2, 1]], dtype=torch.long)x = torch.tensor([[-1], [0], [1]], dtype=torch.float)data = Data(x=x, edge_index=edge_index)>>> Data(edge_index=[2, 4], x=[3, 1])
对于 edge_index 参数,shape 为 (2,4),4 表示边的条数,对于 x 参数,shape为 (3,1),3 表示节点数,1 表示节点特征维度。
Dat 类也有其对应的方法和属性,说明如下:
- data.keys:返回属性名列表。
- data[‘x’]:返回属性名为 ‘x’ 的值。
- for key, item in data: …:按照字典的方法返回 data 属性和对应值。
- ‘x’ in data:判断某一属性是否在 data 中。
- data.num_nodes:返回节点个数,相当于 x.shape[0]。
- data.num_edges:返回边的条数,相当于 edge_index.shape[1]。
- data.contains_isolated_nodes():是否存在孤立的节点。
- data.contains_self_loops():是否存在自环。
- data.is_directed():是否是有向图。
- data.to(torch.device(‘cuda’)):将数据对象转移到 GPU。
例2:让我们用一个例子来说明一个写怎样创建一个 Data 对象。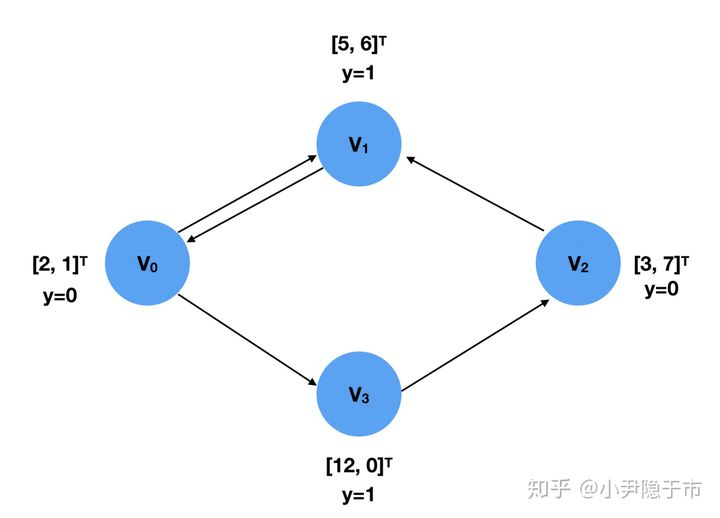
在这个图里有 4 个节点,V1,V2,V3,V4,每一个都带有一个 2 维的特征向量,和一个标签 y,代表这个节点属于哪一类。
这两个东西可以用 FloatTesonr 来表示:
x = torch.tensor([[2,1],[5,6],[3,7],[12,0]], dtype=torch.float)y = torch.tensor([0,1,0,1], dtype=torch.float)
图的节点连接信息要以 COO 格式进行存储。在 COO 格式中,COO list 是一个 2*E 维的 list。第一个维度的节点是源节点(source nodes),第二个维度中是目标节点(target nodes),连接方式是由源节点指向目标节点。对于无向图来说,存贮的 source nodes 和 target node 是成对存在的。
方式一:
edge_index = torch.tensor([[0,1,2,0,3],[1,0,1,3,2]],dtype=torch,long)
方式二:
edge_index = torch.tensor([[0, 1],[1, 0],[2, 1],[0, 3][2, 3]], dtype=torch.long)
第二种方法在使用时要调用 contiguous() 方法。
边索引的顺序跟 Data 对象无关,或者说边的存储顺序并不重要,因为这个 edge_index 只是用来计算邻接矩阵(Adjacency Matrix)。
把它们放在一起我们就可以创建一个Data了。
# 方法一import torchfrom torch_geometric.data import Datax = torch.tensor([[2,1],[5,6],[3,7],[12,0]],dtype=torch.float)y = torch.tensor([[0,2,1,0,3],[3,1,0,1,2]],dtype=torch.long)edge_index = torch.tensor([[0,1,2,0,3],[1,0,1,3,2]],dtype=torch,long)data = Data(x=x,y=y,edge_index=edge_index)# 方法二import torchfrom torch_geometric.data import Datax = torch.tensor([[2,1],[5,6],[3,7],[12,0]],dtype=torch.float)y = torch.tensor([[0,2,1,0,3],[3,1,0,1,2]],dtype=torch.long)edge_index = torch.tensor([[0, 1],[1, 0],[2, 1],[0, 3][2, 3]], dtype=torch.long)data = Data(x=x,y=y,edge_index=edge_index.contiguous())
这样我们就创建了一个新的 Data。其中 x,y,edge_index 是最基本的键值(key)。 你也可以添加自己的 key。有了这个 data,你可以在程序中非常方便的调用处理你的数据。
DataLoader
DataLoader 这个类允许你通过 batch 的方式 feed 数据。创建一个 DotaLoader 实例,可以简单的指定数据集和你期望的 batch size。
loader = DataLoader(dataset, batch_size=512, shuffle=True)
DataLoader 的每一次迭代都会产生一个 Batch 对象。它非常像 Data 对象。但是带有一个 ‘batch‘ 属性。它指明了了对应图上的节点连接关系。因为 DataLoader 聚合来自不同图的的 batch 的 x,y 和 edge_index,所以 GNN 模型需要 batch 信息去知道那个节点属于哪一图。
for batch in loader:batch>>> Batch(x=[1024, 21], edge_index=[2, 1568], y=[512], batch=[1024])
Dataset
数据集 Dataset 的创建不像 Data 一样简单直接了。Dataset 有点像 torchvision,它有着自己的规则。
PyG 提供两种不同的数据集类:
- InMemoryDataset
- Dataset
要创建一个 InMemoryDataset,你必须实现一个函数:
**Raw_file_names()**
它返回一个包含没有处理的数据的名字的 list 。如果你只有一个文件,那么它返回的 list 将只包含一个元素。事实上,你可以返回一个空 list ,然后确定你的文件在后面的函数 process() 中。
**Processed_file_names()**
很像上一个函数,它返回一个包含所有处理过的数据的 list 。在调用 process() 这个函数后,通常返回的 list 只有一个元素,它只保存已经处理过的数据的名字。
**Download()**
这个函数下载数据到你正在工作的目录中,你可以在 self.raw_dir 中指定。如果你不需要下载数据,你可以在这函数中简单的写一个 pass 就好。
**Process()**
这是 Dataset 中最重要的函数。你需要整合你的数据成一个包含 data 的 list 。然后调用 self.collate() 去计算将用 DataLodadr 的片段。下面这个例子来自 PyG 官方文档。
import torchfrom torch_geometric.data import InMemoryDatasetclass MyOwnDataset(InMemoryDataset):def __init__(self, root, transform=None, pre_transform=None):super(MyOwnDataset, self).__init__(root, transform, pre_transform)self.data, self.slices = torch.load(self.processed_paths[0])@propertydef raw_file_names(self):return ['some_file_1', 'some_file_2', ...]@propertydef processed_file_names(self):return ['data.pt']def download(self):# Download to `self.raw_dir`.def process(self):# Read data into huge `Data` list.data_list = [...]if self.pre_filter is not None:data_list [data for data in data_list if self.pre_filter(data)]if self.pre_transform is not None:data_list = [self.pre_transform(data) for data in data_list]data, slices = self.collate(data_list)torch.save((data, slices), self.processed_paths[0])
我将会在后面介绍怎样从RecSys 2015 提供的数据构建一个用于 PyG 的一般数据集。

若有收获,就点个赞吧
0 人点赞
