参考来源:
简书:一文看懂 NLP 里的模型框架 Encoder-Decoder 和 Seq2Seq
CSDN:深度学习—-深度学习笔记(七):Encoder-Decoder 模型和 Attention 模型
1. 什么是 Encoder-Decoder ?
Encoder-Decoder 模型主要是 NLP 领域里的概念。它并不特值某种具体的算法,而是一类算法的统称。Encoder-Decoder 算是一个通用的框架,在这个框架下可以使用不同的算法来解决不同的任务。
Encoder-Decoder 这个框架很好的诠释了机器学习的核心思路:
将现实问题转化为数学问题,通过求解数学问题,从而解决现实问题。
Encoder 又称作编码器。它的作用就是「将现实问题转化为数学问题」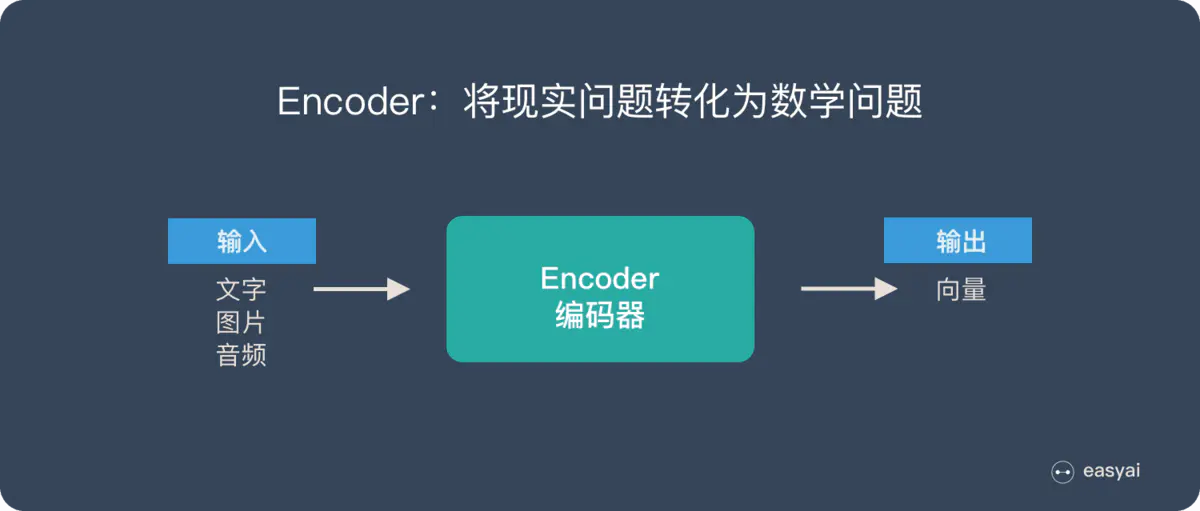
Encoder将现实问题转化为数学问题
Decoder 又称作解码器,他的作用是「求解数学问题,并转化为现实世界的解决方案」
Decoder求解数学问题,并转化为现实世界的解决方案
把 2 个环节连接起来,用通用的图来表达则是下面的样子:
图解Encoder-Decoder
关于 Encoder-Decoder,有 2 点需要说明:
- 不论输入和输出的长度是什么,中间的「向量 c」 长度都是固定的(这也是它的缺陷,下文会详细说明)
- 根据不同的任务可以选择不同的编码器和解码器(可以是一个 RNN ,但通常是其变种 LSTM 或者 GRU )
- 当然了,这个只是大概的思想,具体实现的时候,编码器和解码器都不是固定的,可选的有
CNN / RNN / BiRNN / GRU / LSTM等等,你可以自由组合。比如说,你在编码时使用 BiRNN ,解码时使用 RNN ,或者在编码时使用 RNN ,解码时使用 LSTM 等等。但通常是一个 RNN ,或者其变种 LSTM / GRU 。
只要是符合上面的框架,都可以统称为 Encoder-Decoder 模型。说到 Encoder-Decoder 模型就经常提到一个名词—— Seq2Seq。
2. 什么是 Seq2Seq?
Seq2Seq(是 Sequence-to-sequence 的缩写),就如字面意思,输入一个序列,输出另一个序列。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。例如下图:
如上图:输入了 6 个汉字,输出了 3 个英文单词。输入和输出的长度不同。
Seq2Seq 的由来
在 Seq2Seq 框架提出之前,深度神经网络在图像分类等问题上取得了非常好的效果。在其擅长解决的问题中,输入和输出通常都可以表示为固定长度的向量,如果长度稍有变化,会使用补零等操作。
然而许多重要的问题,例如机器翻译、语音识别、自动对话等,表示成序列后,其长度事先并不知道。因此如何突破先前深度神经网络的局限,使其可以适应这些场景,成为了 13 年以来的研究热点,Seq2Seq 框架应运而生。
「Seq2Seq」和「Encoder-Decoder」的关系
Seq2Seq(强调目的)不特指具体方法,满足「输入序列、输出序列」的目的,都可以统称为 Seq2Seq 模型。
而 Seq2Seq 使用的具体方法基本都属于Encoder-Decoder 模型(强调方法)的范畴。
总结一下的话:
- Seq2Seq 属于 Encoder-Decoder 的大范畴
- Seq2Seq 更强调目的,Encoder-Decoder 更强调方法
3. Encoder-Decoder 有哪些应用?

机器翻译、对话机器人、诗词生成、代码补全、文章摘要(文本 - 文本)
「文本 - 文本」 是最典型的应用,其输入序列和输出序列的长度可能会有较大的差异。
Google 发表的用Seq2Seq做机器翻译的论文《Sequence to Sequence Learning with Neural Networks》
Seq2Seq应用:机器翻译
语音识别(音频 - 文本)
语音识别也有很强的序列特征,比较适合 Encoder-Decoder 模型。
Google 发表的使用Seq2Seq做语音识别的论文《A Comparison of Sequence-to-Sequence Models for Speech Recognition》
Seq2Seq应用:语音识别
图像描述生成(图片 - 文本)
通俗的讲就是「看图说话」,机器提取图片特征,然后用文字表达出来。这个应用是计算机视觉和 NLP 的结合。
图像描述生成的论文《Sequence to Sequence – Video to Text》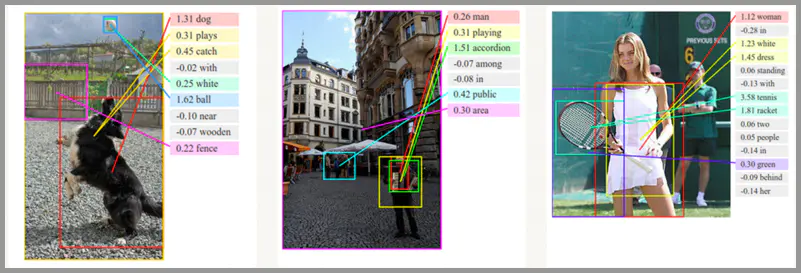
Seq2Seq应用:图像描述生成
4. Encoder-Decoder 的缺陷
上文提到:Encoder(编码器)和 Decoder(解码器)之间只有一个「向量 c」来传递信息,且 c 的长度固定。
为了便于理解,我们类比为「压缩-解压」的过程:
将一张 800X800 像素的图片压缩成 100KB,看上去还比较清晰。再将一张 3000X3000 像素的图片也压缩到 100KB,看上去就模糊了。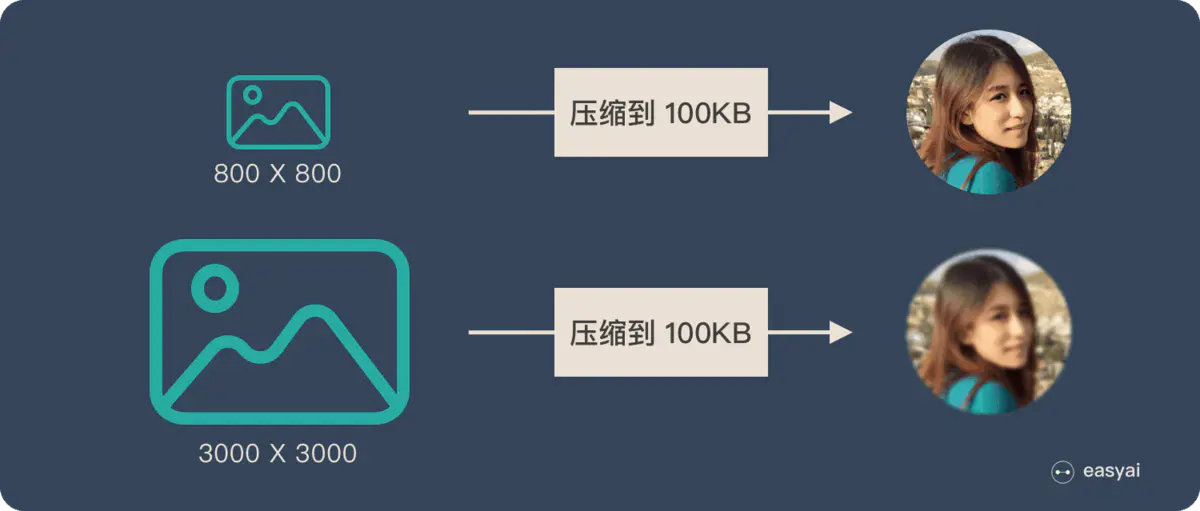
Encoder-Decoder的缺点:输入过长会损失信息
Encoder-Decoder 就是类似的问题:当输入信息太长时,会丢失掉一些信息。
5. Attention 解决信息丢失问题
Attention 机制就是为了解决「信息过长,信息丢失」的问题。
Attention 模型的特点是 Eecoder 不再将整个输入序列编码为固定长度的「中间向量 C」 ,而是编码成一个向量的序列。引入了 Attention 的 Encoder-Decoder 模型如下图:
图解 Attention
这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。而且这种方法在翻译任务中取得了非常不错的成果。

若有收获,就点个赞吧
0 人点赞
