- 一、第一周:Pytorch基础概念
- 3. 张量操作与线性回归
- 3.1 张量的拼接与切分
- example3
- torch.chunk
- example5
- torch.index_select
- example7
- torch.reshape
- example9
- torch.squeeze
- 3.4 张量的数学运算——加减乘除
- example10
- torch.add
- 4. 计算图与动态图机制
- 4.1 计算图
- 4.2 动态图
- 5. 自动求导系统torch.autograd及逻辑回归实现
- 5.1 autograd——自动求导系统
- 5.2 逻辑回归
- 二、第二周:Pytorch数据处理
- 7. 图像数据预处理模块——transforms
- 7.1 transforms运行机制
- 7.2 数据标准化——transforms.Normalize
- 8. transforms图像增强(一)
- 8.1 数据增强(Data Augmentation)
- 8.2 transforms——裁剪(Crop)
- 8.3 transforms——翻转与旋转(Flip and Rotation)
- 9. transforms图像增强(二)
- 9.1 transforms——图像变换(Data Augmentation)
- 9.2 transforms——transforms方法操作(Transforms Operation)
- 9.3 自定义 transforms 方法(User-Defined Transforms)
- 第三周 模型模块
- 11. 模型容器Containers与AlexNet构建
- 11.1 模型容器——Containers
- 11.2 AlexNet构建
- 12. nn中的网络层——卷积层
- 12.1 1d/2d/3d Convolution
- 12.2 卷积 - nn.Conv2d()
- 12.3 转置卷积(Transpose Convlution)
- 13. nn中的网络层——池化层、线性层、激活函数层
- 13.1 池化层(Pooling Layer)
- 13.2 线性层(Linear Layer)
- 13.3 激活函数层
- 第四周
- 15. 损失函数(一)
- 15.1 损失函数概念
- 15.2 交叉熵损失函数
- 15.3 NLL / BCE / BCEWithLogits Loss
- 16. 损失函数(二)—— pytorch 中其余 14 中损失函数
- 16.1 回归中常用的两个损失函数
- 17. 优化器 Optimizer(一)
- 17.1 什么是优化器(Optimizer)
- 17.2 优化器的基本属性
- 17.3 优化器的基本方法
- 18. 常用的优化方法(优化器)
- 18.1 learning rate 学习率
- 18.2 momentum 动量
- 18.3 torch.optim.SGD
- 18.4 Pytorch的十种优化器
- 第五周
- 20. 可视化工具——TensorBoard
- 20.1 TensorBoard简介
- 20.2 TensorBoard安装
- 20.3 TensorBoard运行可视化
- 21. TensorBoard 使用(一)
- 21.1 SummaryWriter
- 提供创建event file的高级接口
- 21.2 模型指标监控
- 22. TensorBoard 使用(二)——TensorBoaed 的图像可视化方法
- 22.1 add_image and torchvision.utils.make_grid
- 22.2 AlexNet 卷积核与特征图可视化
- 22.3 add_graph and torchsummary
- 23. Hook 函数与 CAM 可视化
- 23.1 Hook函数概念
- 23.2 Hook 函数与特征图提取
- 23.3 CAM(Class Activation Map, 类激活图) and Grad-CAM
- 第六周









一、第一周:Pytorch基础概念
2. Pytorch的Tensor(张量)
Content
- Tensor概念
- Tensor创建一:直接创建
- Tensor创建二:依据数值创建
- Tensor创建三:依据概率创建
2.1 张量是什么(What is Tensor?)
张量是一个**多维数组**,它是标量、向量、矩阵的高维拓展。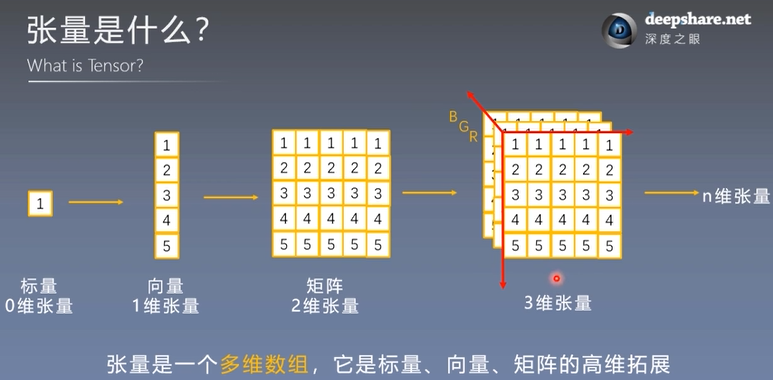
2.2 Tensor与Variable
Variable是torch.autograd中的数据类型,主要用于封装Tensor,进行自动求导。
data:被封装的Tensor
grad:data的梯度
grad_fn:创建Tensor的Function,是自动求导的关键
requires_grad:指示是否需要梯度
is_leaf:指示是否是叶子结点(张量)
Pytorch0.4.0版开始,Variable并入Tensor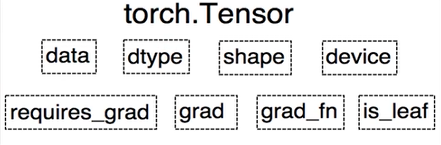
dtype:张量的数据类型,如torch.FloatTensor、torch.cuda.FloatTensor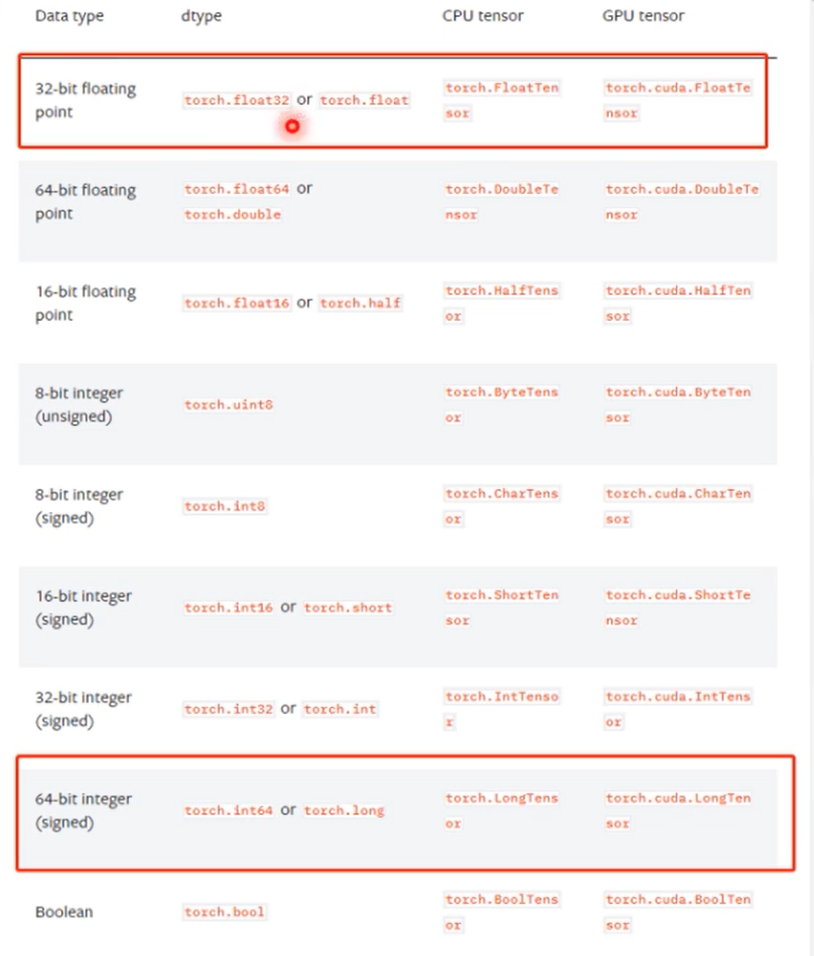
shape:张量的形状,如(64,3,224,224)
device:张量所在设备,GPU/CPU,是加速的关键
2.3 张量的创建——(1)直接创建张量
1. torch.tensor()
torch.tensor()
功能:从data创建tensor
- data:数据,可以是list,numpy
- dtype:数据类型,默认与data的一致
- device:所在设备,cuda/cpu
- requires_grad:是否需要梯度
- pin_memory:是否存于锁页内存
torch.tensor(data,dtype=None,device=None,requires_grad=False,pin_memory=False)
2. torch.from_numpy(ndarray)
torch.from_numpy(ndarray)
功能:从numpy创建tensor
注意事项:从torch.from_numpy创建的tensor与原ndarray共享内存,当修改其中一个的数据,另一个也将会被修改。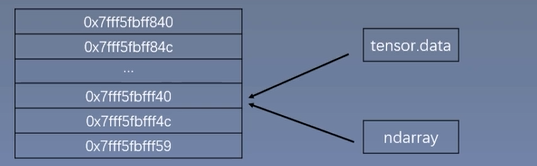
2.4 张量的创建——(2)依据数值创建张量
1. torch.zeros()
torch.zeros()
功能:依size创建全0张量
- size:张量的形状,如(3,3)、(3,244,244)
- out:输出的张量
- layout:内存中布局形式,有strided、sparse_coo等
- device:所在设备,gpu/cpu
- requires_grad:是否需要梯度
torch.zeros(*size,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False)
2. torch.zeros_like()
torch.zeros_like()
功能:依input形状创建全0张量
- input:创建于input同形状的全0张量
- dtype:数据类型
- layout:内存中布局形式
torch.zeros_like(input,dtype=None,layout=None,device=None,requires_grad=False)
3. torch.ones()
4. torch.ones_like()
torch.ones()
torch.ones_like()
功能:依input形状创建全1张量
- size:张量的形状,如(3,3)、(3,244,244)
- input:创建于input同形状的全1张量
- dtype:数据类型
- layout:内存中布局形式,有strided、sparse_coo等
- layout:内存中布局形式
- device:所在设备,gpu/cpu
- requires_grad:是否需要梯度
torch.ones(*size,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False)
torch.ones_like(input,dtype=None,layout=None,device=None,requires_grad=False)
5. torch.full()
6. torch.full_like()
torch.full()
torch.full_like()
功能:依据input形状创建全值张量
- size:张量的形状,如(3,3)
- full_value:张量的值
torch.full(size,full_value,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False)
7. torch.arange()
torch.arange()
功能:创建等差的1维张量
注意事项:数值区间为[start,end)
- start:数列起始值
- end:数列”结束值”
- step:数列公差,默认为1
torch.arange(start=0,end,step=1,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False)
8. torch.linspace()
torch.linspace()
功能:创建均分的1维张量
注意事项:数值区间为[start,end]
- start:数列起始值
- end:数列结束值
- steps:数列长度
步长为:(end-start)/(steps-1)
torch.linspace(start,end,steps=100,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False)
9. torch.logspace()
torch.logspace()
功能:创建对数均分的1维张量
注意事项:数值区间为[start,end];长度为steps,底数为base
- start:数列起始值
- end:数列结束值
- steps:数列长度
- base:对数函数的底,默认为10
torch.logspace(start,end,steps=100,base=10.0,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False)
10. torch.eye()
torch.eye()
功能:创建单位对角矩阵(2维张量)
注意事项:默认为方阵
- n:矩阵函数
- m:矩阵列数
torch.linspace(n,m=None,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False)
2.5 张量的创建——(3)依概率分布创建张量
1. torch.normal()
torch.normal()
功能:生成正态分布(高斯分布)
- mean:均值
- std:标准差
四种模式:torch.normal(mean,std,out=None)
mean为标量,std为标量
mean为标量,std为张量
mean为张量,std为标量
mean为张量,std为张量torch.normal(mean,std,size,out=None)
2. torch.randn()
3. torch.randn_like()
torch.randn()
torch.randn_like()
功能:生成标准正态分布
- size:张量的形状
torch.randn(*size,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False)
4. torch.rand()
5. torch.rand_like()
torch.rand()
torch.rand_like()
功能:在区间[0,1)上,生成均匀分布
torch.rand(*size,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False)
6. torch.randint()
7. torch.randint_like()
torch.randint()
torch.randint_like()
功能:在区间[low,high)生成整数均匀分布
- size:张量的形状
torch.randint(low,high,size,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False)
8. torch.randperm()
torch.randperm()
功能:生成从0到n-1的随机排列
- n:张量的长度
torch.randperm(n,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False)
9. torch.bernoulli()
torch.bernoulli()
功能:以input为概率,生成伯努利分布(0-1分布,两点分布)
- input:概率值
torch.bernoulli(input,*,generator=None,out=None)
3. 张量操作与线性回归
Content
- 张量的操作:拼接、切分、索引和变换
- 张量的数学运算
- 线性回归
3.1 张量的拼接与切分
1. torch.cat()
torch.cat()
功能:将张量按维度dim进行拼接
- tensors:张量序列
- dim:要拼接的维度
```python import torchtorch.cat(tensors,dim=0,out=None)
t = torch.ones((2, 3)) t0 = torch.cat([t, t], dim=0) t1 = torch.cat([t, t], dim=1)
print(‘t:\n{}\nt.shape:\n{}’.format(t,t.shape)) print(‘t0:\n{}\nt0.shape:\n{}’.format(t0,t0.shape)) print(‘t1:\n{}\nt1.shape:\n{}’.format(t1,t1.shape))
output: t: tensor([[1., 1., 1.], [1., 1., 1.]]) t.shape: torch.Size([2, 3]) t0: tensor([[1., 1., 1.], [1., 1., 1.], [1., 1., 1.], [1., 1., 1.]]) t0.shape: torch.Size([4, 3]) t1: tensor([[1., 1., 1., 1., 1., 1.], [1., 1., 1., 1., 1., 1.]]) t1.shape: torch.Size([2, 6])
<a name="WMTJT"></a>#### 2. torch.stack()torch.stack()<br />功能:在新创建的维度dim上进行拼接- tensors:张量序列- dim:要拼接的维度```pythontorch.stack(tensors,dim=0,out=None)
# example2# torch.stackimport torcht = torch.ones((2, 3))t0 = torch.stack([t, t], dim=2)t1 = torch.stack([t, t], dim=0)# 若dim指定的维度已经存在,则会创建一个新的维度,已存在的依次向后挪一个维度。print('t:\n{}\nt.shape:\n{}'.format(t, t.shape))print('t0:\n{}\nt0.shape:\n{}'.format(t0, t0.shape))print('t1:\n{}\nt1.shape:\n{}'.format(t1, t1.shape))ouput:t:tensor([[1., 1., 1.],[1., 1., 1.]])t.shape:torch.Size([2, 3])t0:tensor([[[1., 1.],[1., 1.],[1., 1.]],[[1., 1.],[1., 1.],[1., 1.]]])t0.shape:torch.Size([2, 3, 2])t1:tensor([[[1., 1., 1.],[1., 1., 1.]],[[1., 1., 1.],[1., 1., 1.]]])t1.shape:torch.Size([2, 2, 3])
3. torch.chunk()
torch.chunk()
功能:将张量按维度dim进行平均切分
返回值:张量列表
注意事项:若不能整除,最后一个张量小于其他张量
import torch
a = torch.ones((2, 5))
list_tensors = torch.chunk(a, dim=1, chunks=2) for idx, t in enumerate(list_tensors): print(‘第{}个张量:\n{}\nshape is:\n{}’.format(idx + 1, t, t.shape))
output: 第1个张量: tensor([[1., 1., 1.], [1., 1., 1.]]) shape is: torch.Size([2, 3]) 第2个张量: tensor([[1., 1.], [1., 1.]]) shape is: torch.Size([2, 2])
<a name="MXTua"></a>#### 4. torch.split()torch.split()<br />功能:将张量按维度dim进行切分<br />返回值:张量列表- tensor:要切分的张量- split_size_or_sections:为int时,表示每一份长度;为list时,按list元素切分- dim:要切分的维度注意事项:切分后,tensor指向切分完的最后一个张量```pythontorch.split(tensor,split_size_or_sections,dim=0)
# example4# torch.splitimport torcht = torch.ones((2, 5))list_tensors = torch.split(t, 2, dim=1)for idx, t in enumerate(list_tensors):print('第{}个张量:\n{}\nshape is:\n{}'.format(idx + 1, t, t.shape))print('t:\n',t)t = torch.ones((2, 5))list_tensors = torch.split(t, [2, 1, 2], dim=1)for idx, t in enumerate(list_tensors):print('第{}个张量:\n{}\nshape is:\n{}'.format(idx + 1, t, t.shape))output:第1个张量:tensor([[1., 1.],[1., 1.]])shape is:torch.Size([2, 2])第2个张量:tensor([[1., 1.],[1., 1.]])shape is:torch.Size([2, 2])第3个张量:tensor([[1.],[1.]])shape is:torch.Size([2, 1])t:tensor([[1.],[1.]])第1个张量:tensor([[1., 1.],[1., 1.]])shape is:torch.Size([2, 2])第2个张量:tensor([[1.],[1.]])shape is:torch.Size([2, 1])第3个张量:tensor([[1., 1.],[1., 1.]])shape is:torch.Size([2, 2])
3.2 张量的索引
1. torch.index_select()
torch.index_select()
功能:在维度dim上,按index索引数据
返回值:依index索引数据拼接的张量
- input:要索引的张量
- dim:要索引的维度
- index:要索引数据的序号
```pythontorch.index_select(input,dim,index,out=None)
example5
torch.index_select
import torch
t = torch.randint(0, 9, size=(3, 3)) idx = torch.tensor([0, 2], dtype=torch.long) t_select = torch.index_select(t, dim=0, index=idx) print(‘t:\n{}\nidx:\n{}\nt_select:\n{}’.format(t, idx, t_select))
output: t: tensor([[4, 4, 1], [5, 1, 8], [2, 1, 2]]) idx: tensor([0, 2]) t_select: tensor([[4, 4, 1], [2, 1, 2]])
<a name="NN86p"></a>#### 2. torch.masked_select()torch.index_select()<br />功能:按mask中的True进行索引<br />返回值:一维张量- input:要索引的张量- mask:与input同形状的布尔类型张量```pythontorch.masked_select(input,mask,out=None)
ge:>= gt:> le:<= lt:<
# example6# torch.masked_selectimport torcht = torch.randint(0, 9, size=(3, 3))mask = t.ge(5)t_select = torch.masked_select(t, mask)print('t:\n{}\nmask:\n{}\nt_select:\n{}'.format(t, mask, t_select))output:t:tensor([[5, 3, 1],[3, 8, 6],[1, 5, 4]])mask:tensor([[ True, False, False],[False, True, True],[False, True, False]])t_select:tensor([5, 8, 6, 5])
3.3 张量的变换
1. torch.reshape()
torch.reshape()
功能:变换张量的形状
注意事项:当张量在内存中是连续存在时,新张量与input共享内存
import torch
t = torch.randperm(8) t_reshape = torch.reshape(t, (-1, 4)) print(‘t:\n{}\nt_reshape:\n{}’.format(t, t_reshape))
print(‘t.data 内存地址:{}’.format(id(t.data))) print(‘t_reshape.data 内存地址:{}’.format(id(t_reshape.data))) t[0] = 1024 print(‘t:\n{}\nt_reshape:\n{}’.format(t, t_reshape))
output: t: tensor([5, 7, 0, 2, 6, 1, 4, 3]) t_reshape: tensor([[5, 7, 0, 2], [6, 1, 4, 3]]) t.data 内存地址:1749654845224 t_reshape.data 内存地址:1749654845224 t: tensor([1024, 7, 0, 2, 6, 1, 4, 3]) t_reshape: tensor([[1024, 7, 0, 2], [ 6, 1, 4, 3]])
<a name="KRXRX"></a>#### 2. torch.transpose()torch.transpose()<br />功能:交换张量的两个维度- input:要交换维度的张量- dim0:要交换的维度- dim1:要交换的维度```pythontorch.transpose(input,dim0,dim1)
# example8# torch.transposeimport torcht = torch.rand(2, 3, 4)t_transpose = torch.transpose(t, dim0=1, dim1=2)print('t:\n{}\nt_transpose:\n{}'.format(t, t_transpose))print('t.shape:\n{}\nt_transpose.shape:\n{}'.format(t.shape, t_transpose.shape))output:t:tensor([[[0.9669, 0.3727, 0.8775, 0.5900],[0.1132, 0.6863, 0.9109, 0.8974],[0.5809, 0.0539, 0.7609, 0.3699]],[[0.9527, 0.2056, 0.6411, 0.6718],[0.6573, 0.9133, 0.6319, 0.2841],[0.5032, 0.6048, 0.4830, 0.4872]]])t_transpose:tensor([[[0.9669, 0.1132, 0.5809],[0.3727, 0.6863, 0.0539],[0.8775, 0.9109, 0.7609],[0.5900, 0.8974, 0.3699]],[[0.9527, 0.6573, 0.5032],[0.2056, 0.9133, 0.6048],[0.6411, 0.6319, 0.4830],[0.6718, 0.2841, 0.4872]]])t.shape:torch.Size([2, 3, 4])t_transpose.shape:torch.Size([2, 4, 3])
3. torch.t()
torch.t()
功能:2维张量转置,对矩阵而言,等价于 torch.transpose(input,0,1)
torch.t(input)
4. torch.squeeze()
torch.squeeze()
功能:压缩长度为1的维度(轴)
- dim:若为None,移除所有长度为1的轴;若指定维度,当且仅当该轴长度为1时,可以被移除。
```pythontorch.squeeze(input,dim=None,out=None)
example9
torch.squeeze
import torch
t = torch.rand((1, 2, 3, 1)) t_sq = torch.squeeze(t) t0 = torch.squeeze(t, dim=0) t1 = torch.squeeze(t, dim=1)
print(‘t.shape:\n{}\nt_sq.shape:\n{}’.format(t.shape, t_sq.shape)) print(‘t0.shape:\n{}\nt1.shape:\n{}’.format(t0.shape, t1.shape))
output: t.shape: torch.Size([1, 2, 3, 1]) t_sq.shape: torch.Size([2, 3]) t0.shape: torch.Size([2, 3, 1]) t1.shape: torch.Size([1, 2, 3, 1])
<a name="eZVKM"></a>#### 5. torch.unsqueeze()torch.unsqueeze()<br />功能:依据dim扩展维度- dim:扩展的维度```pythontorch.usqueeze(input,dim,out=None)
6. torch.flatten()
torch.flatten(input, start_dim=0, end_dim=-1)
功能:展平/推平一个连续范围的维度,输出类型为 Tensor
- input: 一个 tensor,即要被“推平”的 Tensor。
- start_dim: “推平”的起始维度。
- end_dim: “推平”的结束维度。
首先如果按照 start_dim 和 end_dim 的默认值,那么这个函数会把 input 推平成一个 shape 为 [n] 的tensor,其中 n 即 input 中元素个数
当 start_dim = 1 而 end_dim = −1 时,它把第 1 个维度到最后一个维度全部推平合并了。而当 start_dim = 0 而 end_dim = 1 时,它把第 0 个维度到第 1 个维度全部推平合并了。
import torcht = torch.tensor([[[1, 2, 2, 1],[3, 4, 4, 3],[1, 2, 3, 4]],[[5, 6, 6, 5],[7, 8, 8, 7],[5, 6, 7, 8]]])print('t:\n{}\nt.shape:\n{}'.format(t, t.shape))x = torch.flatten(t, start_dim=1)print('x:\n{}\nx.shape:\n{}'.format(x, x.shape))y = torch.flatten(t, start_dim=0, end_dim=1)print('y:\n{}\ny.shape:\n{}'.format(y, y.shape))output:"""t:tensor([[[1, 2, 2, 1],[3, 4, 4, 3],[1, 2, 3, 4]],[[5, 6, 6, 5],[7, 8, 8, 7],[5, 6, 7, 8]]])t.shape:torch.Size([2, 3, 4])x:tensor([[1, 2, 2, 1, 3, 4, 4, 3, 1, 2, 3, 4],[5, 6, 6, 5, 7, 8, 8, 7, 5, 6, 7, 8]])x.shape:torch.Size([2, 12])y:tensor([[1, 2, 2, 1],[3, 4, 4, 3],[1, 2, 3, 4],[5, 6, 6, 5],[7, 8, 8, 7],[5, 6, 7, 8]])y.shape:torch.Size([6, 4])"""
3.4 张量的数学运算——加减乘除
1. torch.add()
torch.add()
功能:逐元素计算 input+alpha×other
- input:第一个张量
- alpha:乘项因子
- other:第二个张量
```pythontorch.add(inputalpha=1,other,out=None)
example10
torch.add
import torch
t0 = torch.randn((3, 3)) t1 = torch.ones_like(t0) t_add = torch.add(t0, 10, t1)
print(‘t0:\n{}\nt1:\n{}\nt_add:\n{}’.format(t0, t1, t_add))
output: t0: tensor([[-0.1253, -0.2573, -2.2917], [ 1.4232, 0.1650, -0.1312], [ 0.7477, 0.1264, -0.6293]]) t1: tensor([[1., 1., 1.], [1., 1., 1.], [1., 1., 1.]]) t_add: tensor([[ 9.8747, 9.7427, 7.7083], [11.4232, 10.1650, 9.8688], [10.7477, 10.1264, 9.3707]])
<a name="bhNjB"></a>#### 2. torch.addcdiv()torch.addcdiv()<br />功能:逐元素计算 input + value * tensor1 / tensor2torch.addcmul()<br />功能:input + value * tensor1 * tensor2```pythontorch.addcmul(input,value=1,tensor1,tensor2,out=None)
torch.sub()torch.div()torch.mul()
3.5 张量的数学运算——对指幂函数
torch.log(input,out=None)torch.log10(input,out=None)torch.log2(input,out=None)torch.exp(input,out=None)torch.pow()
3.6 张量的数学运算——三角函数
torch.abs(input,out=None)torch.acos(input,out=None)torch.cosh(input,out=None)torch.cos(input,out=None)torch.asin(input,out=None)torch.atan(input,out=None)torch.atan2(input,other,out=None)
3.7 线性回归
线性回归是分析一个变量与另外一(多)个变量之间关系的方法
因变量:y 自变量:x 关系:线性
y = wx + b
求解步骤:
- 确定模型 Model:y = wx + b
选择损失函数 MSE:

求解梯度并更新w,b w = LR w.grad b = b - LR b.grad (LR:学习率,步长)
线性回归模型示例:
# -*- coding:utf-8 -*-"""@file_name :lesson1.3-Linear_Regression@author :@data :2021-05-07@brief :一元线性回归"""import torchfrom matplotlib import pyplot as plttorch.manual_seed(10)lr = 0.1 # 学习率# 创建训练数据x = torch.rand(20, 1) * 10 # x data (tensor),shape=(20,1)y = 2 * x + (5 + torch.randn(20, 1)) # y data (tensor),shape=(20,1)# 构建线性回归参数w = torch.randn((1), requires_grad=True)b = torch.zeros((1), requires_grad=True)for iteration in range(1000):# 前向传播wx = torch.mul(w, x)y_pred = torch.add(wx, b)# 计算 MSE lossloss = (0.5 * (y - y_pred) ** 2).mean()# 反向传播loss.backward()# 更新参数b.data.sub_(lr * b.grad)w.data.sub_(lr * w.grad)# 绘图if iteration % 20 == 0:plt.scatter(x.data.numpy(), y.data.numpy())plt.plot(x.data.numpy(), y_pred.data.numpy(), 'r-', lw=5)plt.text(2, 20, 'Loss=%0.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})plt.xlim(1.5, 10)plt.ylim(8, 28)plt.title('Iteration:{}\nw:{} b:{}'.format(iteration, w.data.numpy(), b.data.numpy()))plt.pause(0.5)if loss.data.numpy() < 1:break
4. 计算图与动态图机制
Content
- 计算图
- Pytorch的动态图机制
4.1 计算图
- 计算图是用来描述运算的有向无环图
- 计算图两个主要元素:结点Node,边Edge
- 结点表示数据,如向量/矩阵/张量
- 边表示运算,如加/减/乘/除/卷积
用计算图表示:y = (x + w) * (w + 1)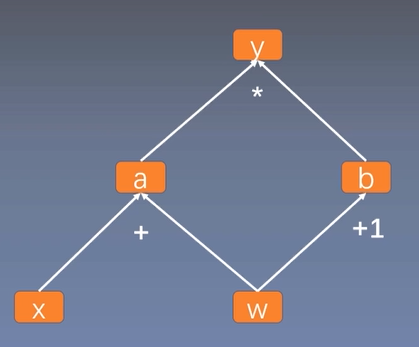
计算图与梯度求导
y = (x + w) (w + 1)
a = x + w b = w + 1
y = a b
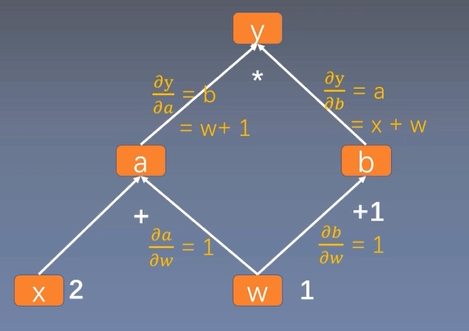

叶子结点
叶子节点:用户创建的结点,如上述的 x 和 w 。is_leaf:指示张量是否为叶子结点
非叶子节点梯度会被释放
grad_fn:记录创建该张量时所用的方法/函数
叶子结点:grad_fn = None
# y.grad_fn = <MulBackward0># a.grad_fn = <AddBackward0># b.grad_fn = <AddBackward0>
# example1# 计算图示例import torchw = torch.tensor([1., ], requires_grad=True)x = torch.tensor([2., ], requires_grad=True)a = torch.add(w, x)a.retain_grad() # 保存非叶子结点a的梯度b = torch.add(w, 1)y = torch.mul(a, b)y.backward()print(w.grad) # w=5# 查看叶子节点# print("is_leaf:\n", w.is_leaf, x.is_leaf, a.is_leaf, b.is_leaf, y.is_leaf) # TTFFFprint('w.is_leaf:', w.is_leaf)print('x.is_leaf:', x.is_leaf)print('a.is_leaf:', a.is_leaf)print('b.is_leaf:', b.is_leaf)print('y.is_leaf:', y.is_leaf)# 查看梯度# print("gradient:\n", w.grad, x.grad, a.grad, b.grad, y.grad)print('w.grad:', w.grad)print('x.grad:', x.grad)print('a.grad:', a.grad)print('b.grad:', b.grad)print('y.grad:', y.grad)# 查看 grad_fn# print("grad_fn:\n", w.grad_fn, x.grad_fn, a.grad_fn, b.grad_fn, y.grad_fn) # NNAAMprint('w.grad_fn:', w.grad_fn)print('x.grad_fn:', x.grad_fn)print('a.grad_fn:', a.grad_fn)print('b.grad_fn:', b.grad_fn)print('y.grad_fn:', y.grad_fn)output:tensor([5.])w.is_leaf: Truex.is_leaf: Truea.is_leaf: Falseb.is_leaf: Falsey.is_leaf: Falsew.grad: tensor([5.])x.grad: tensor([2.])a.grad: tensor([2.])b.grad: Noney.grad: Nonew.grad_fn: Nonex.grad_fn: Nonea.grad_fn: <AddBackward0 object at 0x000001974E7E15C8>b.grad_fn: <AddBackward0 object at 0x000001974E7E1608>y.grad_fn: <MulBackward0 object at 0x000001974E7E15C8>
4.2 动态图
动态图 VS. 静态图
根据计算图搭建方式,可将计算图分为动态图和静态图
5. 自动求导系统torch.autograd及逻辑回归实现
Content
- torch.autograd
- 逻辑回归
5.1 autograd——自动求导系统
1. torch.autograd.backward()
torch.autograd.backward()
功能:自动求取梯度
- tensors:用于求导的张量,如loss
- retain_graph:保存计算图
- create_graph:创建导数计算图,用于高阶求导
- grad_tensors:多梯度权值
torch.autograd.backward(tensors,grad_tensors=None,retain_graph=None,create_graph=Flase)
# example1# retain_graphimport torchtorch.manual_seed(10)w = torch.tensor([1.], requires_grad=True)x = torch.tensor([1.], requires_grad=True)a = torch.add(w, x)b = torch.add(w, 1)y = torch.mul(a, b)y.backward(retain_graph=True)print(w.grad)y.backward()print(w.grad)output:tensor([4.])tensor([8.])
# example2# grad_tensorsimport torchw = torch.tensor([1.], requires_grad=True)x = torch.tensor([2.], requires_grad=True)a = torch.add(w, x)b = torch.add(w, 1)y0 = torch.mul(a, b) # y0=(x + w)*(w + 1) dy0/dw=5y1 = torch.add(a, b) # y1=(x + w)+(w + 1) dy1/dw=2loss = torch.cat([y0, y1], dim=0)grad_tensors = torch.tensor([1., 2.])loss.backward(gradient=grad_tensors)# gradient 传入 torch.autograd.backward()中的grad_tensorsprint(w.grad)output:tensor([9.])
2. torch.autograd.grad()
torch.autograd.grad()
功能:求取梯度
- outputs:用于求导的张量,如loss
- inputs:需要梯度的张量
- create_graph=Flase:创建导数计算图,用于高阶求导
- retain_graph=None:保存计算图
- grad_tensors=None:多梯度权值
torch.autograd.grad(outputs,inputs,grad_tensors=None,retain_graph=None,create_graph=Flase)
# example3# torch.autograd.gradimport torchx = torch.tensor([3.], requires_grad=True)y = torch.pow(x, 2)grad_1 = torch.autograd.grad(y, x, create_graph=True)print(grad_1)grad_2 = torch.autograd.grad(grad_1[0], x)print(grad_2)output:(tensor([6.], grad_fn=<MulBackward0>),)(tensor([2.]),)
autograd小贴士:
梯度不自动清零,使用 w.grad.zero_() 操作清零
依赖于叶子结点的结点,
requires_grad默认为True叶子结点不可执行
in-place
in-place:原位操作,在原有内存地址上进行操作
# example3# tips-1import torchw = torch.tensor([1.], requires_grad=True)x = torch.tensor([2.], requires_grad=True)for i in range(3):a = torch.add(w, x)b = torch.add(w, 1)y = torch.mul(a, b)y.backward()print(w.grad)if i ==1:w.grad.zero_()output:tensor([5.])tensor([10.])tensor([5.])
# example4# tips-2import torchw = torch.tensor([1.], requires_grad=True)x = torch.tensor([2.], requires_grad=True)a = torch.add(w, x)b = torch.add(w, 1)y = torch.mul(a, b)print('a.requires_grad:',a.requires_grad)print('b.requires_grad:',b.requires_grad)print('y.requires_grad:',y.requires_grad)output:a.requires_grad: Trueb.requires_grad: Truey.requires_grad: True
5.2 逻辑回归
逻辑回归是线性的二分类模型
模型表达式:

f(x)称为Sigmoid函数,也称为Logistics函数。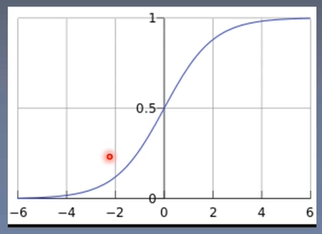

逻辑回归与线性回归
线性回归是分析自变量x与因变量y(标量)之间关系的方法
逻辑回归是分析自变量x与因变量y(概率)之间关系的方法
逻辑回归又称对数几率回归
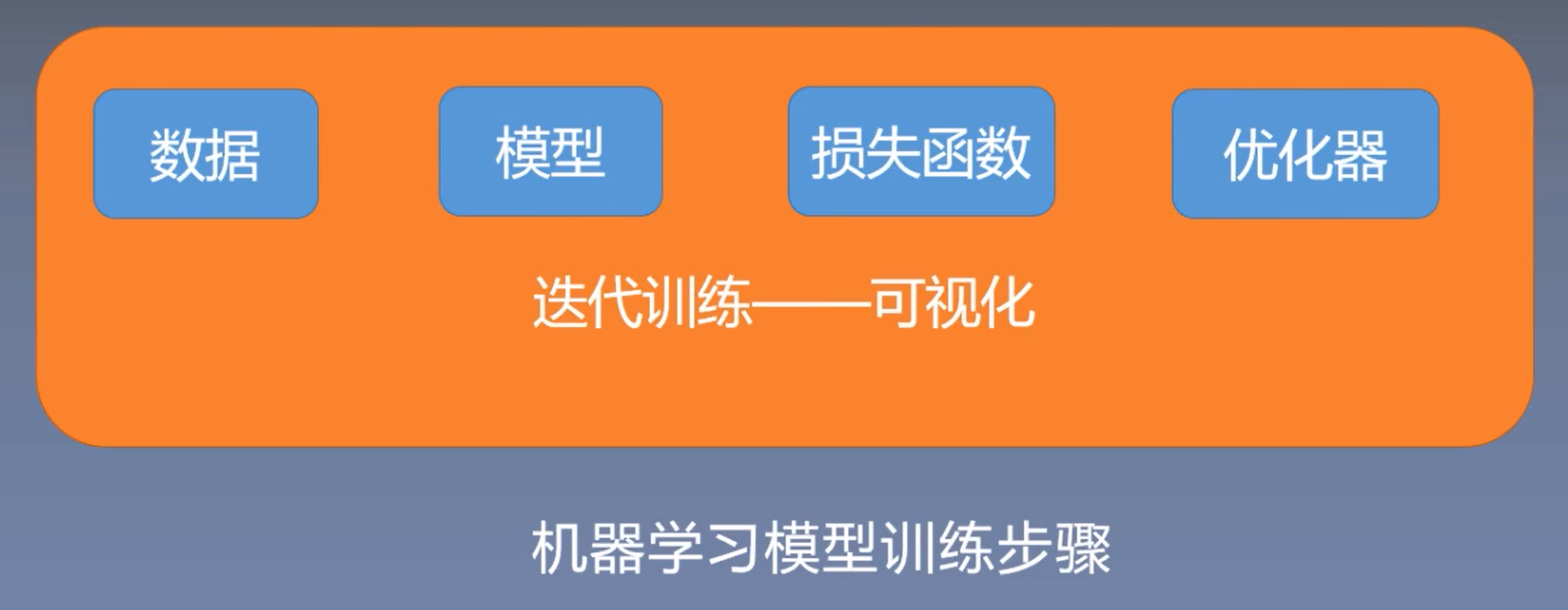
机器学习模型训练步骤:
- 数据:数据采集、数据清洗、数据划分、数据预处理
- 模型:线性模型/神经网络模型
- 损失函数:线性模型中采用的均方差损失函数、分类任务中的交叉熵
- 优化器:更新权值
- 迭代训练:反复迭代训练
逻辑回归模型示例:
# -*- coding:utf-8 -*-"""@file_name :lesson1.5-Logistic_Regression@author :@data :2021-05-09@brief :逻辑回归"""import torchimport torch.nn as nnimport matplotlib.pyplot as pltimport numpy as np# ========== step 1/5 生成数据 ==========sample_nums = 100mean_value = 1.7bias = 1n_data = torch.torch.ones(sample_nums, 2)x0 = torch.normal(mean_value * n_data, 1) + bias # 类别0 数据 shape=(100,2)y0 = torch.zeros(sample_nums) # 类别0 标签 shape=(100,1)x1 = torch.normal(-mean_value * n_data, 1) + bias # 类别1 数据 shape=(100,2)y1 = torch.ones(sample_nums) # 类别1 标签 shape=(100,1)train_x = torch.cat((x0, x1), 0)train_y = torch.cat((y0, y1), 0)# ========== step 2/5 选择数据 ==========class LR(nn.Module):def __init__(self):super(LR, self).__init__()self.features = nn.Linear(2, 1)self.sigmoid = nn.Sigmoid()def forward(self, x):x = self.features(x)x = self.sigmoid(x)return xlr_net = LR() # 实例化逻辑回归模型# ========== step 3/5 选择损失函数 ==========loss_fn = nn.BCELoss()# ========== step 4/5 选择优化器 ==========lr = 0.01 # 学习率optimizer = torch.optim.SGD(lr_net.parameters(), lr=lr, momentum=0.9)# ========== step 5/5 模型训练 ==========for iteration in range(1000):# 前向传播y_pred = lr_net(train_x)# 计算lossloss = loss_fn(y_pred.squeeze(), train_y)# 方向传播loss.backward()# 更新参数optimizer.step()# 绘图if iteration % 20 == 0:mask = y_pred.ge(0.5).float().squeeze() # 以0.5为阀值进行分类correct = (mask == train_y).sum() # 计算正确预测的样本个数acc = correct.item() / train_y.size(0) # 计算分类准确率plt.scatter(x0.data.numpy()[:, 0], x0.data.numpy()[:, 1], c='r', label='class0')plt.scatter(x1.data.numpy()[:, 0], x1.data.numpy()[:, 1], c='b', label='class1')w0, w1 = lr_net.features.weight[0]w0, w1 = float(w0.item()), float(w1.item())plot_b = float(lr_net.features.bias[0].item())plot_x = np.arange(-6, 6, 0.1)plot_y = (-w0 * plot_x - plot_b) / w1plt.xlim(-5, 7)plt.ylim(-7, 7)plt.plot(plot_x, plot_y)plt.text(-5, 5, 'Loss=%0.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})plt.title('Iteration: {}\nw0:{:.2f} w1:{:.2f} b:{:.2f} accuracy:{:.2f}'.format(iteration, w0, w1, plot_b, acc))plt.legend()plt.show()plt.pause(0.5)if acc > 0.99:break
二、第二周:Pytorch数据处理
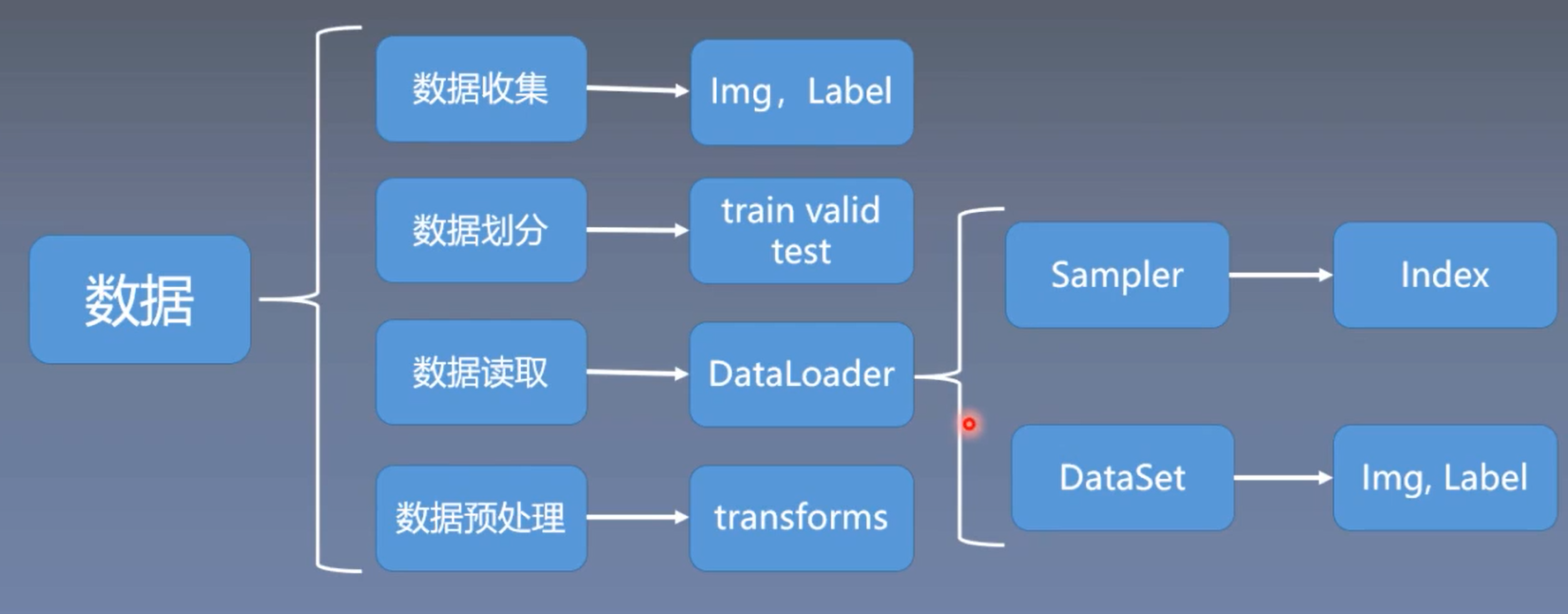
数据:
- 数据收集:数据又原始样本和标签
- 数据划分:数据会划分为训练集、验证集和测试集(train、valid、test)。
- 训练集->训练模型;- 验证集->验证模型是否过拟合,也就是挑选模型,挑选那些还没有过拟合的模型;- 测试集->测试挑选出来的模型的性能
- 数据读取:DataLoader
- Sampler->生成索引- Dataset->根据索引去读取图片和标签
- 数据预处理:transforms
6. 数据读取模块——DataSet与DataLoader
Content
- 人民币二分类
- DataLoader与Dataset
6.1 DataLoader与Dataset
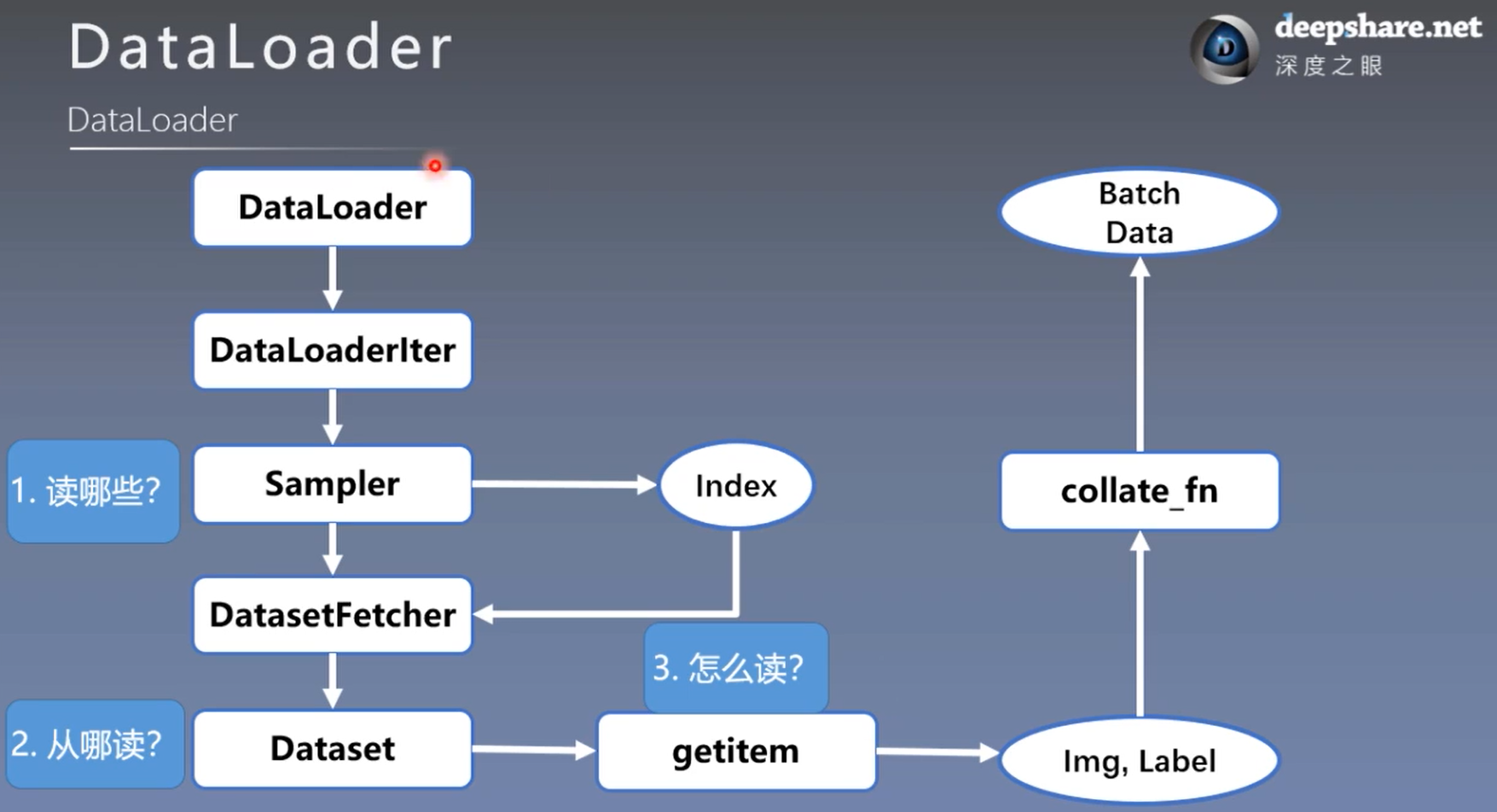
1. torch.utils.data.DataLoader
torch.utils.data.DataLoader
功能:构建可迭代的数据装载器
- dataset:Dataset类,决定数据从哪里读取
- batch_size:批大小
- num_workers:是否多进程读取数据
- shuffle=False:每个epoch是否乱序
- drop_last=False:当样本数不能被batchsize整除时,是否舍弃最后一批数据
torch.utils.data.DataLoader()DataLoader(dataset,batch_size=1,shuffle=False,sampler=None,batch_sampler=None,num_workers=0,collate_fn=None,pin_memory=False,drop_last=False,timeout=0,worker_in it_fn=None,multiprocessing_context=None)
epoch:所有训练样本都已输入到模型中,称为1个epoch
iteration:一批样本输入到模型中,称为1个iteration
batchsize:批大小,决定了一个epoch有多少个iteration
例如:
样本总数:87,batchsize:8drop_last = True:1 epoch = 10 iteration # 舍弃掉后七个样本drop_last = Flase:1 epoch = 11 iteration
2. touch.utils.data.Dataset
touch.utils.data.Dataset
功能:Dataset抽象类,所有自定义的Dataset都需要继承它,并且复写 __getitem__()(接受一个索引,返回一个样本)
torch.utils.data.Dataset()class Dataset(object):def __getitem__(self, index):# 接收一个索引,返回一个样本raise NotImplementedErrordef __add__(self, other):return ConcatDataset([self, other])
6.2 人民币二分类
数据读取:
- 读哪些数据? Sampler输出Index
- 从哪读数据? Dataset中的data_dir
- 怎么读数据? Dataset中的getitem
7. 图像数据预处理模块——transforms
Content
- transforms运行机制
- 数据标准化——transforms.normalize
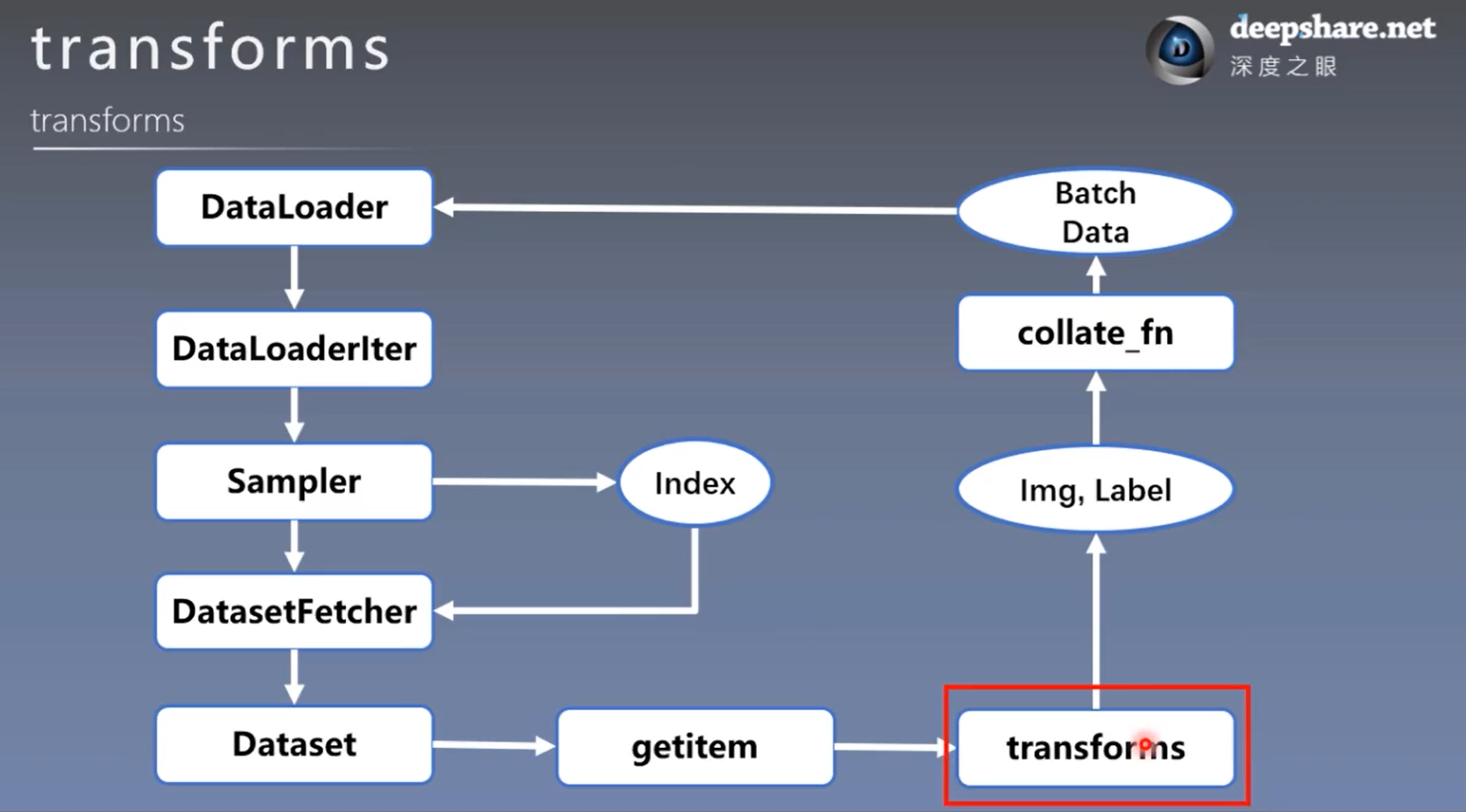
7.1 transforms运行机制
1. 计算机视觉工具包:torchvision
torchvision.transforms:常用的图像预处理方法
torchvision.datasets:常用数据集,如MNIST/CIFAR-10/ImageNet
torchvision.model:常用的模型预训练,如AlexNet/VGG/ResNet/GoogLeNet
2. 常用图像预处理方法:transforms
数据中心化/标准化
缩放/裁剪/旋转/翻转/填充/噪声添加
灰度变换/线性变换/仿射变换/亮度、饱和度及对比度变换
7.2 数据标准化——transforms.Normalize
1. transform.Normalize
transform.Normalize
功能:逐channel(通道)的对图像进行标准化,加快模型的收敛速度
output = (input - mean) / std ==> 得到0均值1标准差的数据分布
- mean:各通道的均值
- std:各通道的标准差
- inplace:是否原地操作
# 对图像的每个通道进行标准化# output = (input - mean) / stdtransforms.Normalize(mean,std,inplace=False)
8. transforms图像增强(一)
Content
- 数据增强
- transforms——裁剪
- transforms——翻转和旋转
8.1 数据增强(Data Augmentation)
数据增强又称为数据增广、数据扩增,它是对训练集进行变换,使训练集更丰富,从而让模型更具泛化能力。
原则:使得训练集与测试集更接近
- 空间位置:平移
- 色彩:灰度图,色彩抖动
- 形状:仿射变换
- 上下文场景:遮挡,填充
8.2 transforms——裁剪(Crop)
1. transforms.CenterCrop
transforms.CenterCrop
功能:从图像中心裁剪图片
- size:所需裁剪图片尺寸(也就是裁剪后图片的尺寸)
# 1. 从图像中心裁剪transforms.CenterCrop(size) # 所需裁剪图片尺寸
2. transforms.RandomCrop
transforms.RandomCrop
功能:从图片中随机裁剪出尺寸为size的图片
- size:所需裁剪图片尺寸
- padding:设置填充大小
- 当为 a 时,上下左右均填充 a 个像素
- 当为 (a,b) 时,上下填充 b 个像素,左右填充 a 个像素
- 当为 (a,b,c,d) 时,左、上、右、下分别填充 a,b,c,d 个像素
- pad_if_need:若图像小于设定的size,则填充
- padding_mode:填充模式,有 4 种模式
- constant:像素值由 fill 设定
- edge:像素值由图像边缘像素决定
- reflect:镜像填充,最后一个像素不镜像,例:[1,2,3,4] — [3,2,1,2,3,4,3,2]
- symmetric:镜像填充,最后一个像素镜像,例:[1,2,3,4] — [2,1,1,2,3,4,4,3]
- fill:constant时,设置填充的像素值
transforms.RandomCrop(size, # 所需裁剪图片的尺寸padding=None, # 设置填充大小pad_if_needed=False, # 若图像小于设定size,则填充fill=0, # 填充模式为constant时,设置填充的像素值,如(R,G,B)/(Gray)padding_mode='constant') # 填充模式,共有4种
3. transforms.RandomResizedCrop
transforms.RandomResizedCrop
功能:随机大小。长宽比裁剪图片
- size:所需裁剪图片的尺寸
- scale=(0.08, 1.0):随机裁剪面积比例
- ratio=(3/4, 4/3):随即长宽比
- interpolation:插值方法,最近邻/双线性/双三次插值
- PIL.Image.NEAREST 最近邻
- PIL.Image.BILINEAR 双线性
- PIL.Image.BICUBIC 双三次插值
# 3. 随机大小、长宽比裁剪图片transforms.RandomResizedCrop(size, # 所需裁剪图片的尺寸scale=(0.08, 1.0), # 随机裁剪面积比例ratio=(3/4, 4/3) # 随机长宽比interpolation) # 插值方法,最近邻/双线性/双三次插值
4. transforms.FiveCrop
5. transforms.TenCrop
transforms.FiveCrop
transforms.TenCrop
功能:在图像的上下左右以及中心裁剪出尺寸为size的5张图片,transforms.TenCrop对这 5 张图片进行水平或者垂直镜像获得 10 张图片。
- size:所需裁剪图片尺寸
- vertical_flip:是否垂直翻转
# 4. 从图像上下左右及中心裁剪出尺寸为size的5张图像transforms.FiveCrop(size) # 返回一个tuple
# 5. 对上述5张图像进行水平或者垂直镜像获得10张图像transforms.TenCrop(size, # 所需裁剪图片尺寸vertical_flip=False) # 是否垂直翻转
8.3 transforms——翻转与旋转(Flip and Rotation)
1. RandomHorizontalFlip
2. RandomVerticalFlip
RandomHorizontalFlip
RandomVerticalFlip
功能:依概率水平(左右)或垂直(上下)翻转图片
- p:翻转概率
# 水平翻转transforms.RandomHorizontalFlip(p=0.5)
# 垂直翻转transforms.RandomVerticalFlip(p=0.5)
3. transforms.RandomRotation
transforms.RandomRotation
功能:随机旋转图片
- degrees:旋转角度
- 当degrees=a时,在(-a, a)之间选择旋转角度
- 当degrees=(a, b)时,在(a, b)之间选择旋转角度
- resample=False:重采样方法
- expand=False:是否扩大图片,以保持原图信息
- center=None:旋转点设置,默认中心旋转
# 2. 旋转transforms.RandomRotation(degrees, # 旋转角度resample=False, # 重采样方法expand=False, # 是否扩大图片,以保持原图信息center=None) # 旋转点设置,默认中心旋转
9. transforms图像增强(二)
Content
- transforms——图像变换
- transforms——transforms方法操作
- 自定义 transforms 方法
9.1 transforms——图像变换(Data Augmentation)
1. transforms.Pad
transforms.Pad
功能:对图片的边缘进行填充
- padding:设置填充大小
- 当padding=a时,上下左右均填充a个像素
- 当padding=(a, b)时,上下填充b个像素,左右填充a个像素
- 当padding=(a, b, c, d)时,左/上/右/下分别填充a/b/c/d个像素
- padding_mode:填充模式,有 4 种模式,constant、edge、reflect、symmetric
- fill:填充模式为constant时,设置填充的像素值,如(R,G,B)/(Gray)
# 1. 填充图像边缘transforms.Pad(padding, # 设置填充大小# 当padding=a时,上下左右均填充a个像素# 当padding=(a, b)时,上下填充b个像素,左右填充a个像素# 当padding=(a, b, c, d)时,左/上/右/下分别填充a/b/c/d个像素fill=0, # 填充模式为constant时,设置填充的像素值,如(R,G,B)/(Gray)padding_mode='constant') # 填充模式,constant/edge/reflect/symmetric
2. transforms.ColorJitter
transforms.ColorJitter
功能:调整亮度、对比度、饱和度和色相
- brightness:亮度调整因子
- 当brightness=a时,在[max(0, 1-a), 1+a]之间选择
- 当brightness=(a, b)时,在[a, b]之间选择
- contrast:对比度参数,同brightness
- saturation:饱和度参数,同brightness
- hue=0:色相参数
- 当hue=a时,在[-a, a]之间选择
- 当hue=(a, b)时,在[a, b]之间选择
# 2. 调整图像亮度/对比度/饱和度/色相transforms.ColorJitter(brightness=0, # 亮度调整因子# 当brightness=a时,在[max(0, 1-a), 1+a]之间选择# 当brightness=(a, b)时,在[a, b]之间选择contrast=0, # 对比度参数,同brightnesssaturation=0, # 饱和度参数,同brightnesshue=0) # 色相参数# 当hue=a时,在[-a, a]之间选择# 当hue=(a, b)时,在[a, b]之间选择
3. transforms.Grayscale
4. transforms.RandomGrayscale
transforms.Grayscale
transforms.RandomGrayscale
功能:依概率将图片转换为灰度图
- num_ouput_channels:输出通道数
- p:概率值,图像被转换为灰度图的概率
注意事项:transforms.Grayscale 是 transforms.RandomGrayscale p = 1 时的特例
# 3. 灰度图转换transforms.Grayscale(num_output_channels) # 输出通道数,1或3transforms.RandomGrayscale(num_output_channels,p=0.1) # 概率值
5. transforms.RandomAffine
transforms.RandomAffine
功能:对图像进行仿射变换,仿射变换是二维的线性变换,由五种基本原子变换构成,分别是旋转、平移、缩放、错切和翻转。
- degrees:设置旋转角度
- translate:平移区间设置
- 如 translate = (a, b) ,a 设置宽(width),b 设置高(height);
- 图像在宽维度平移的区间为 -img_width a < dx < img_width a
- 图像在高维度平移的区间为 -img_height b < dy < img_height b
- scale:缩放比例(以面积为单位)
- fillcolor:填充颜色设置
- shear:错切角度设置,有水平错切和垂直错切
- 当 shear = a 时,仅在 x 轴错切,错切角度在 (-a, a) 之间
- 当 shear = (a, b) 时,则 x 轴在 (-a, a) 之间随机选择错切角度,y 轴在 (-b, b) 之间随机选择错切角度
- 当shear=(a, b, c, d) 时,则 x 轴在 (a, b) 之间随机选择错切角度,y 轴在 (c, d) 之间随机选择错切角度
- resample:重采样方式,NEAREST、BILINEAR、BICUBIC
# 5. 仿射变换# 仿射变换是二维的线性变换,由五种基本原子变换构成,旋转/平移/缩放/错切/翻转transforms.RandomAffine(degrees, # 设置旋转角度translate=None, # 平移区间设置# 例:translate=(a, b),a为宽,b为高# 图像在宽维度平移的区间为 -img_width * a < dx < img_width * a# 图像在高维度平移的区间为 -img_height * b < dy < img_height * bscale=None, # 缩放比例shear=None, # 错切角度设置# 当shear=a时,仅在x轴错切,错切角度在(-a, a)之间# 当shear=(a, b)时,则a设置x轴角度,b设置y轴角度# 当shear=(a, b, c, d)时,则a、b设置x轴角度,c、d设置y轴角resample=False, # 重采样方式,NEAREST/BILINEAR/BICUBICfillcolor=0) # 填充颜色设置
6. transforms.RandomErasing
transforms.RandomErasing
功能:对图像进行随机遮挡
- p:概率值,执行该操作的概率
- scale:遮挡区域面积
- ratio=:遮挡区域长宽比
- value:遮挡区域像素值,如(R,G,B)/(Gray)/‘random’(只要是字符串就会随机)
- inplace
注意事项:transforms.RandomErasing 是对张量进行操作,所以执行 transforms.RandomErasing 之前,一般需要执行 transforms.ToTensor
# 6. 随机遮挡transforms.ToTensor()transforms.RandomErasing(p=0.5, # 执行遮挡的概率scale=(0.02, 0.33), # 遮挡区域面积ratio=(0.3, 3.3) # 遮挡区域长宽比value=0, # 遮挡区域像素值,如(R,G,B)/(Gray)/'random'inplace=False)
7. transforms.ToTensor
transforms.ToTensor
功能:将 PILImage 或者 numpy 的 ndarray 转化成 Tensor ;把一个取值范围是 [0,255] 的 PIL.Image 转换成 Tensor ,shape 为 (H,W,C) 的 numpy.ndarray ,转换成形状为 [C,H,W] ,取值范围是 [0,1.0] 的 Tensor 。
对于 PILImage 转化的 Tensor ,其数据类型是 torch.FloatTensor 对于 ndarray 的数据类型没有限制,但转化成的 Tensor 的数据类型是由 ndarray 的数据类型决定的。
8. transforms.Lambda
transforms.Lambda
功能:用户自定义 lambda 方法
- lambda:lambda 匿名函数
- lambda[arg1 [,arg2,…,argn]] : expression
# 8. 自定义lambda方法transforms.Lambda(lambd) # 匿名函数 lambda[arg1 [,arg2,...,argn]] : expression
- lambda[arg1 [,arg2,…,argn]] : expression
9.2 transforms——transforms方法操作(Transforms Operation)
1. transforms.RandomChoice
transforms.RandomChoice
功能:从一系列 transforms 方法中随机挑选一个
transforms.RandomChoice([transforms1, transforms2, transforms3])
2. transforms.RandomApply
transforms.RandomApply
功能:依概率执行一组 transforms 操作
transforms.RandomApply([transforms1, transforms2, transforms3], p=0.5)
3. transforms.RandomOrder
transforms.RandomOrder
功能:对一组 transforms 操作打乱顺序
transforms.RandomOrder([transforms1, transforms2, transforms3])
9.3 自定义 transforms 方法(User-Defined Transforms)
自定义 transforms 方法要素:
- 仅接受一个参数,返回一个参数
- 注意上下游的输出与输入
class Compose(object):def __call__(self, img):for t in self.transform:img = t(img)return img
通过类实现多参数传入:
# 通过类实现多参数传入class YoutTransforms(object):def __init__(self, ...):...def __call__(self, img):...return img
椒盐噪声
椒盐噪声又称为脉冲噪声,是一种随机出现的白点或者黑点,白点成为盐噪声,黑色成为椒噪声
信噪比(Signal-Noise Rate,SNR)是衡量噪声的比例,图像中为图像像素的占比
class AddPepperNoise(object):def __init__(self, snr, p):self.snr = snrself.p = pdef __call__(self, img):"""添加椒盐噪声具体实现过程"""return imgclass Compose(object):def __call__(self,img):for t in self.transforms:img = t(img)return img
transforms 方法总结



第三周 模型模块
10. 模型创建与 nn.Module
Content
- 网络模型创建步骤
- nn.Module属性
10.1 网络模型创建步骤(Steps of Creating Module)
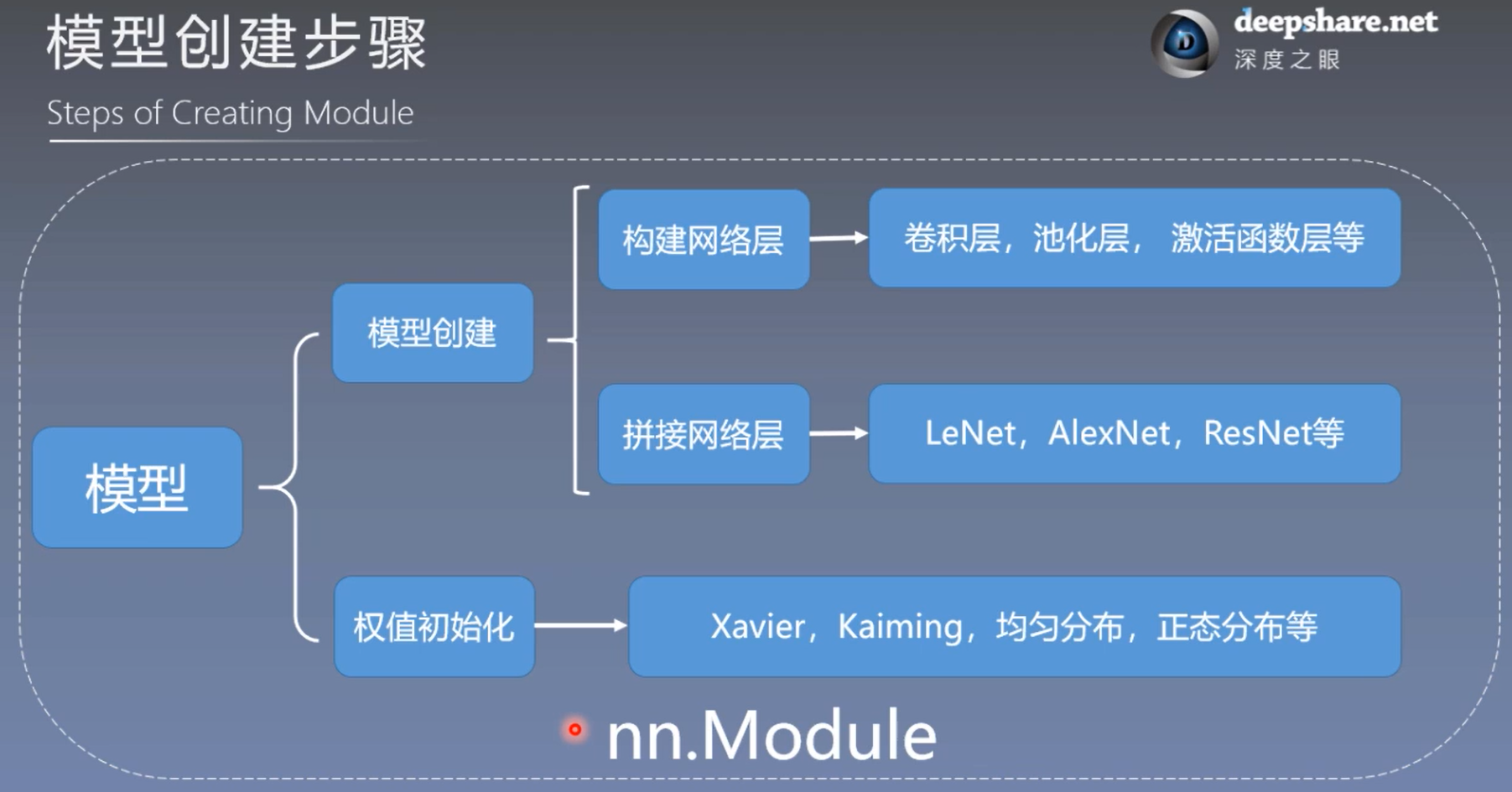
模型创建两要素:
- 构建子模块(构建网络层) ==> init()
- 拼接子模块(拼接网络层) ==> forward()
10.2 nn.Module属性

1. torch.nn
torch.nn:
nn.Parameter:张量子类,表示可学习参数,如weight/权重、bias/偏置nn.Module:所有网络层基类,管理网络属性- nn.functional:函数具体实现,如卷积、池化、激活函数等
- nn.init:参数初始化方法
2. nn.Module
nn.Module
功能:所有网络层基类,管理网络属性
nn.Module有 8 个属性,这个 8 个属性都是有序字典(OrderDict):
paramters:存储管理nn.Parameter类modules:存储管理nn.Module类- buffers:存储管理缓冲属性,如 BN 层中 running_mean
- *_hooks:存储管理钩子函数
self._parameter = OrderDict()self._buffers = OrderDict()self._backward_hooks = OrderDict()self._forward_hooks = OrderDict()self._forward_pre_hooks = OrderDict()self._state_dict_hooks = OrderDict()self._load_state_pre_dict_hooks = OrderDict()self._modules = OrderDict()
3. nn.Module总结
nn.Module总结:
- 一个module可以包含多个子module
- 一个module相当于一个运算,必须实现
forward()函数 - 每个module都有 8 个有序字典(OrderDict)管理它的属性
11. 模型容器Containers与AlexNet构建
Content
- 模型容器(Containers)
- AlexNet构建
11.1 模型容器——Containers
1. Containers
Containers:
nn.Sequetial:按顺序包装多个网络层nn.ModuleList:像Python的 list 一样包装多个网络层nn.ModuleDict:像Python的 dict 一样包装多个网络层
2. nn.Sequetial
nn.Sequetial
功能:nn.Sequetial 是 nn.module 的容器,用于按顺序包装一组网络层
特性:
顺序性:各网络层之间严格按照顺序构建自带forward():自带的 forward 里,通过 for 循环依次执行前向传播运算
注意:nn.Sequetial 中也可以传入字典类型的参数,可以实现给各个网络层命名的效果
实例:
LeNet模块 = features子模块 + classifier子模块
# Conv1-pool1-Conv2-pool2-fc1-fc2-fc3# ============================ Sequentialclass LeNetSequential(nn.Module):def __init__(self, classes):super(LeNetSequential, self).__init__()self.features = nn.Sequential(nn.Conv2d(3, 6, 5),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, 5),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2), )self.classifier = nn.Sequential(nn.Linear(16 * 5 * 5, 120),nn.ReLU(),nn.Linear(120, 84),nn.ReLU(),nn.Linear(84, classes), )def forward(self, x):x = self.features(x)x = x.view(x.size()[0], -1)x = self.classifier(x)return xfake_img = torch.randn((4, 3, 32, 32), dtype=torch.float32)net = LeNetSequential(classes=2)output = net(fake_img)print(net)print(output)output:LeNetSequential((features): Sequential((0): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))(1): ReLU()(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(3): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))(4): ReLU()(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(classifier): Sequential((0): Linear(in_features=400, out_features=120, bias=True)(1): ReLU()(2): Linear(in_features=120, out_features=84, bias=True)(3): ReLU()(4): Linear(in_features=84, out_features=2, bias=True)))tensor([[ 0.0570, -0.0268],[ 0.0579, -0.0404],[ 0.0660, -0.0268],[ 0.0500, -0.0363]], grad_fn=<AddmmBackward>)
通过给 nn.Sequetial 传入字典类型的参数,以实现给各个网络层命名的效果
# Conv1-pool1-Conv2-pool2-fc1-fc2-fc3# ============================ SequentialOrderDictclass LeNetSequentialOrderDict(nn.Module):def __init__(self, classes):super(LeNetSequentialOrderDict, self).__init__()self.features = nn.Sequential(OrderedDict({'conv1': nn.Conv2d(3, 6, 5),'relu1': nn.ReLU(inplace=True),'pool1': nn.MaxPool2d(kernel_size=2, stride=2),'conv2': nn.Conv2d(6, 16, 5),'relu2': nn.ReLU(inplace=True),'pool2': nn.MaxPool2d(kernel_size=2, stride=2),}))self.classifier = nn.Sequential(OrderedDict({'fc1': nn.Linear(16 * 5 * 5, 120),'relu3': nn.ReLU(),'fc2': nn.Linear(120, 84),'relu4': nn.ReLU(inplace=True),'fc3': nn.Linear(84, classes),}))def forward(self, x):x = self.features(x)x = x.view(x.size()[0], -1)x = self.classifier(x)return xfake_img = torch.randn((4, 3, 32, 32), dtype=torch.float32)net = LeNetSequentialOrderDict(classes=2)output = net(fake_img)print(net)print(output)output:LeNetSequentialOrderDict((features): Sequential((conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))(relu1): ReLU(inplace=True)(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))(relu2): ReLU(inplace=True)(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(classifier): Sequential((fc1): Linear(in_features=400, out_features=120, bias=True)(relu3): ReLU()(fc2): Linear(in_features=120, out_features=84, bias=True)(relu4): ReLU(inplace=True)(fc3): Linear(in_features=84, out_features=2, bias=True)))tensor([[-0.1304, -0.0338],[-0.1102, -0.0299],[-0.0928, -0.0051],[-0.0988, -0.0417]], grad_fn=<AddmmBackward>)
3. nn.ModuleList
nn.ModuleList
功能:nn.ModuleList 是 nn.module 的容器,用于包装一组网络层,以迭代方式调用网络层
主要方法:
- append():在 ModuleList 后面添加网络层
- extend():拼接两个 ModuleList
- insert():指定在 ModuleList 中位置插入网络层
#20层全连接网络# ============================ ModuleListclass ModuleList(nn.Module):def __init__(self):super(ModuleList, self).__init__()self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(20)])def forward(self, x):for i, linear in enumerate(self.linears):x = linear(x)return xnet = ModuleList()print(net)fake_data = torch.ones((10, 10))output = net(fake_data)print(output)output:"""ModuleList((linears): ModuleList((0): Linear(in_features=10, out_features=10, bias=True)(1): Linear(in_features=10, out_features=10, bias=True)(2): Linear(in_features=10, out_features=10, bias=True)(3): Linear(in_features=10, out_features=10, bias=True)(4): Linear(in_features=10, out_features=10, bias=True)(5): Linear(in_features=10, out_features=10, bias=True)(6): Linear(in_features=10, out_features=10, bias=True)(7): Linear(in_features=10, out_features=10, bias=True)(8): Linear(in_features=10, out_features=10, bias=True)(9): Linear(in_features=10, out_features=10, bias=True)(10): Linear(in_features=10, out_features=10, bias=True)(11): Linear(in_features=10, out_features=10, bias=True)(12): Linear(in_features=10, out_features=10, bias=True)(13): Linear(in_features=10, out_features=10, bias=True)(14): Linear(in_features=10, out_features=10, bias=True)(15): Linear(in_features=10, out_features=10, bias=True)(16): Linear(in_features=10, out_features=10, bias=True)(17): Linear(in_features=10, out_features=10, bias=True)(18): Linear(in_features=10, out_features=10, bias=True)(19): Linear(in_features=10, out_features=10, bias=True)))tensor([[ 0.1451, 0.1003, 0.0663, 0.1063, -0.2361, -0.1720, 0.1003, -0.1731,-0.1960, 0.2176],[ 0.1451, 0.1003, 0.0663, 0.1063, -0.2361, -0.1720, 0.1003, -0.1731,-0.1960, 0.2176],[ 0.1451, 0.1003, 0.0663, 0.1063, -0.2361, -0.1720, 0.1003, -0.1731,-0.1960, 0.2176],[ 0.1451, 0.1003, 0.0663, 0.1063, -0.2361, -0.1720, 0.1003, -0.1731,-0.1960, 0.2176],[ 0.1451, 0.1003, 0.0663, 0.1063, -0.2361, -0.1720, 0.1003, -0.1731,-0.1960, 0.2176],[ 0.1451, 0.1003, 0.0663, 0.1063, -0.2361, -0.1720, 0.1003, -0.1731,-0.1960, 0.2176],[ 0.1451, 0.1003, 0.0663, 0.1063, -0.2361, -0.1720, 0.1003, -0.1731,-0.1960, 0.2176],[ 0.1451, 0.1003, 0.0663, 0.1063, -0.2361, -0.1720, 0.1003, -0.1731,-0.1960, 0.2176],[ 0.1451, 0.1003, 0.0663, 0.1063, -0.2361, -0.1720, 0.1003, -0.1731,-0.1960, 0.2176],[ 0.1451, 0.1003, 0.0663, 0.1063, -0.2361, -0.1720, 0.1003, -0.1731,-0.1960, 0.2176]], grad_fn=<AddmmBackward>)"""
4. nn.ModuleDict
nn.ModuleDict
功能:nn.ModuleDict 是 nn.module 的容器,用于包装一组网络层,以索引方式调用网络层
主要方法:
- clear():清空ModuleDict
- items():返回可迭代的键值对
- keys():返回字典的键
- values():返回字典的值
- pop():返回一对键值,并从字典中删除
# ============================ ModuleDictclass ModuleDict(nn.Module):def __init__(self):super(ModuleDict, self).__init__()self.choices = nn.ModuleDict({'conv': nn.Conv2d(10, 10, 3),'pool': nn.MaxPool2d(3)})self.activations = nn.ModuleDict({'relu': nn.ReLU(),'prelu': nn.PReLU()})def forward(self, x, choice, act):x = self.choices[choice](x)x = self.activations[act](x)return xnet = ModuleDict()fake_img = torch.randn((4, 10, 32, 32))output = net(fake_img, 'conv', 'relu')print(output)
5. 容器总结
Containers:
nn.Sequetial:顺序性,各网络成之间严格按照顺序执行,常用语 block 构建nn.ModuleList:迭代性,常用于大量重复网络构建,通过 for 循环实现重复构建nn.ModuleDict:索引性,常用于可选择的网络层
11.2 AlexNet构建
AlexNet:2012 年以高出第二名 10 多个百分点的准确率获得 ImageNet 分类任务冠军,开创了卷积神经网络的新时代
AlexNet特点如下:
- 采用 ReLU:替换饱和激活函数(如,Sigmoid 函数),减轻梯度消失
- 采用 LRN(Local REsponse Normalization):对数据归一化,减轻梯度消失
- Dropout:提高全连接层的鲁棒性,增加网络的泛化能力
- Data Augmentation:TenCrop,色彩修改
12. nn中的网络层——卷积层
Content
- 1d/2d/3d 卷积
- 卷积 - nnConv2d()
- 转置卷积 - nn.ConvTranspose
12.1 1d/2d/3d Convolution
卷积运算:卷积核在输入信号(图像)上滑动,相应位置上进行乘加
卷积核:又称为滤波器、过滤器,可认为是某种模式、某种特征
卷积过程类似于用一个模板去图像上寻找与它相识的区域,与卷积核模式月相似,激活值越高,从而实现特征提取。
AlexNet卷积核可视化,发现卷积核学习到的是边缘、条纹、色彩这一些细节模式
卷积维度:一般情况下,卷积核在几个维度上滑动,就是几维卷积;和卷积核的维度不一定一致,请勿混淆。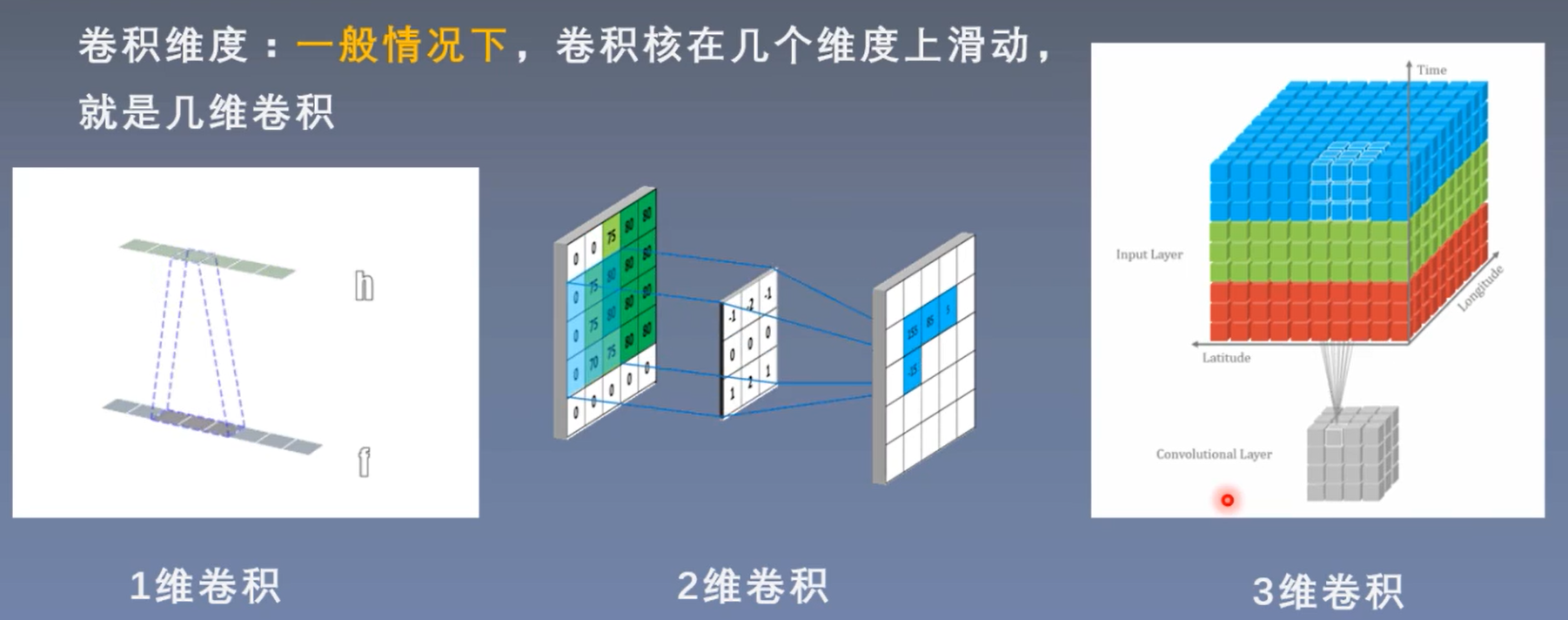
12.2 卷积 - nn.Conv2d()
nnConv2d()
功能:对多个二维信号进行二维卷积
主要参数:
- in_channels:输入通道数
- out_channels:输出通道数,等价于卷积核个数
- kernel_size:卷积核尺寸
- stride = 1:步长
- padding = 0:填充个数,保持输入输出的尺寸一致
- dilation = 1:空洞卷积大小
- groups = 1:分组卷积设置
- bias = True:偏置
尺寸计算:
简化版:不带 padding 和 dilation
完整版:
其中, 为输出尺寸;
为输出尺寸; 为输入尺寸;
为输入尺寸; 为内核尺寸;
为内核尺寸; 为步长;
为步长; 为填充个数;
为填充个数; 为空洞卷积大小
为空洞卷积大小
12.3 转置卷积(Transpose Convlution)
转置卷积又称为反卷积(Deconvolution)和部分跨越卷积(Fractionally-strided Convolution),用于对图像进行上采样(UpSample)
为什么称为转置卷积?
正常卷积:
假设图像尺寸为:44 ,卷积核为:33 ,padding = 0 ,stride = 1 。
图像:
- 16 ==> 4*4 = 16
卷积核:
- 16 ==> 3*3=9,再根据前面的
 的形状补 0 得到 16
的形状补 0 得到 16 - 4 ==> 输出特征图的尺寸得到的
输出:
转置卷积:
假设图像尺寸为:22,卷积核为:33,padding = 0,stride = 1
图像:
- 4 ==> 2*2 = 4
卷积核:
- 4 ==> 3*3 = 9,再剔除得到 4;因为能与图像相乘的最多只有 4 个
- 16 ==> 根据输出特征图的尺寸计算得到
输出:
1. nn.ConvTranspose2d
nn.ConvTranspose2d
功能:装置卷积实现上采样
主要参数:
- in_channels:输入通道数
- out_channels:输出通道数,等价于卷积核个数
- kernel_size:卷积核尺寸
- stride=1:步长
- padding=0:填充个数,保持输入输出的尺寸一致
- groups=1:分组卷积设置
- bias=True:偏置
- output_padding=0,
- dilation=1:空洞卷积大小
- padding_mode=’zeros’
# 转置卷积实现上采样nn.ConvTranspose2d(in_channels, # 输入通道数out_channels, # 输出通道数,等价于卷积核个数kernel_size, # 卷积核尺寸stride=1, # 步长padding=0, # 填充个数,保持输入输出的尺寸一致output_padding=0,groups=1, # 分组卷积设置bias=True, # 偏置dilation=1, # 空洞卷积大小padding_mode='zeros')
尺寸计算:
简化版:
复杂版:
13. nn中的网络层——池化层、线性层、激活函数层
Content
- 池化层——Pooling Layer
- 线性层——Linear Layer
- 激活函数层——Activation Layer
13.1 池化层(Pooling Layer)
池化运算:对信号进行“收集”并“总结”,类似水池收集水资源,因而得名池化层。
- 收集:信号由多变少、尺寸由大变小
- 总结:最大值/平均值
1. nn.MaxPool2d
nn.MaxPool2d
功能:对二维信号(图像)进行最大值池化
主要参数:
- kernel_size:池化核尺寸
- stride = None:步长,通常与kernel_size相同
- padding = 0 :填充个数
- dilation:池化核间隔大小
- ceil_mode = False:尺寸向上/向下取整(尺寸计算中的除法操作是向上/向下取整,默认ceil_mode = False,向下取整。)
- return_indices = False:记录池化像素索引
# 1. 最大池化nn.MaxPool2d(kernel_size, # 池化核尺寸stride=None, # 步长,通常与kernel_size相同padding=0, # 填充个数dilation=1, # 池化核间隔大小return_indices=False, # 记录池化像素索引ceil_mode=False) # 尺寸向上取整
2. nn.AvgPool2d
nn.AvgPool2d
功能:对二维信号(图像)进行平均值池化
主要参数:
- kernel_size:池化核尺寸
- stride = None:步长,通常与kernel_size相同
- padding = 0 :填充个数
- ceil_mode = False:尺寸向上取整
- count_include_pad = True:填充值用于计算
- divisor_override = None :除法因子
注意事项:最大池化后的图片亮度大于平均池化的图片亮度
# 2. 平均池化nn.AvgPool2d(kernel_size, # 池化核尺寸stride=None, # 步长,通常与kernel_size相同padding=0, # 填充个数ceil_mode=False, # 尺寸向上取整count_include_pad=True, # 填充值用于计算divisor_override=None) # 除法因子
3. nn.MaxUnpool2d
nn.MaxUnpool2d
功能:对二维信号(图像)进行最大值池化上采样
主要参数:
- kernel_size:池化核尺寸
- stride = None:步长,通常与kernel_size相同
- padding = 0:填充个数
# 3. 最大值反池化nn.MaxUnpool2d(kernel_size, # 池化核尺寸stride=None, # 步长,通常与kernel_size相同padding=0) # 填充个数# 在前向传播的过程中要添加反池化的索引值indicesforward(self, input, indices, output_size=None)
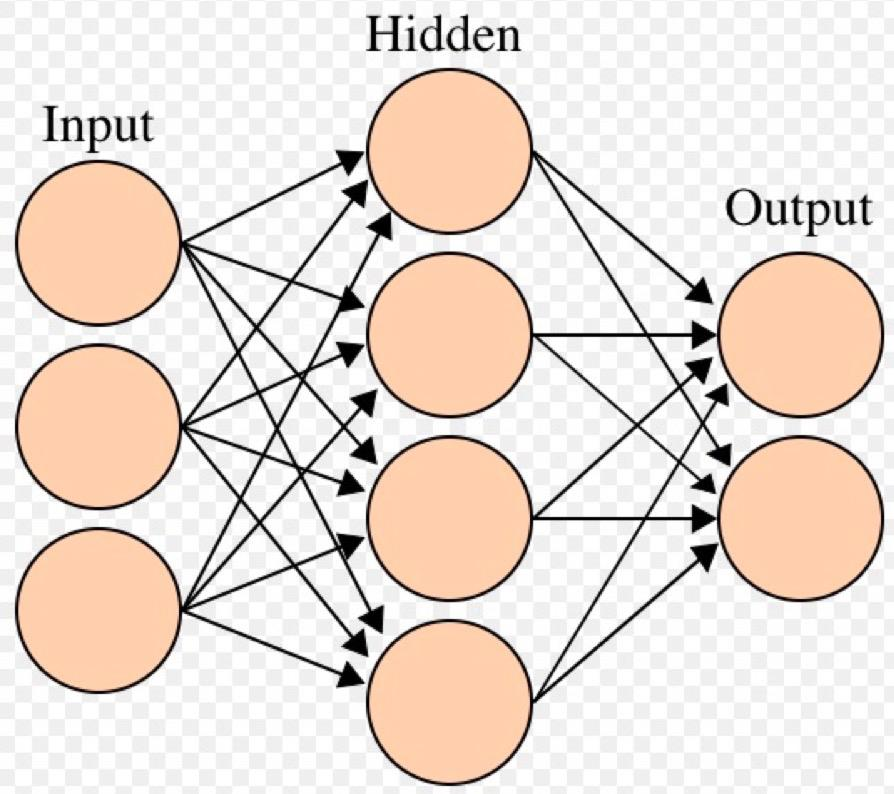
13.2 线性层(Linear Layer)
线性层又称全连接层,其,每个神经元与上一层所有神经元相连实现对前一层的线性组合、线性变换。


 =
= 



1. nn.Linear
nn.Linear
功能:对一维信号(向量)进行线性组合
主要参数:
- in_features:输入结点数
- out_features:输出结点数
- bias :是否需要偏置
计算公式:
# 对一维信号进行线性组合nn.Linear(in_features, # 输入结点数out_features, # 输出结点数bias=True) # 是否需要偏置
13.3 激活函数层
激活函数对特征进行非线性变换,赋予多层神经网络具有深度的意义
若无激活函数,多个线性层叠加等价于一个线性层
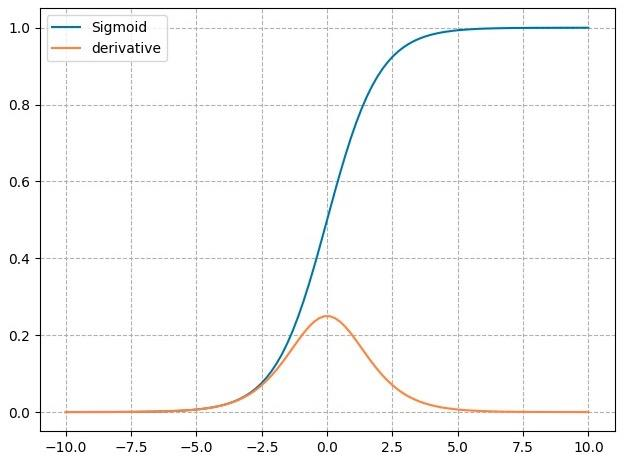
1. nn.Sigmoid
nn.Sigmoid
计算公式:
梯度公式:
特性:
- 输出值在 (0,1) ,符合概率
- 导数范围是 [0, 0.25] ,易导致梯度消失
- 输出为非 0 均值,破坏数据分布
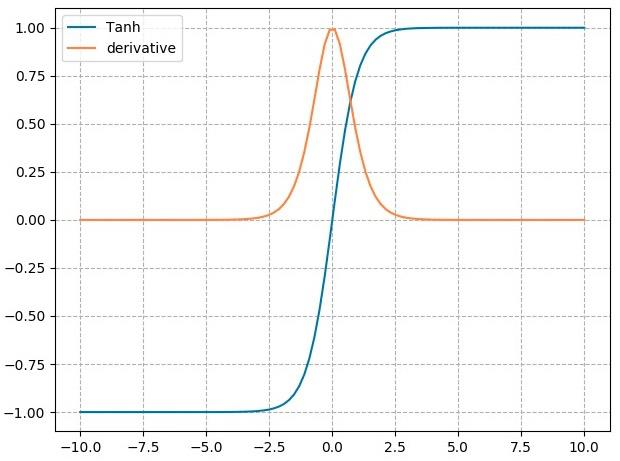
2. nn.tanh
nn.tanh
计算公式:
梯度公式:
特性:
- 输出值在 (-1,1) ,数据符合0均值
- 导数范围是 (0, 1) ,易导致梯度消失
3. nn.ReLU
nn.ReLU
计算公式:
梯度公式:
特性:
- 输出值均为正数,负半轴导致死神经元
- 导数是 1 ,缓解梯度消失,但易引发梯度爆炸
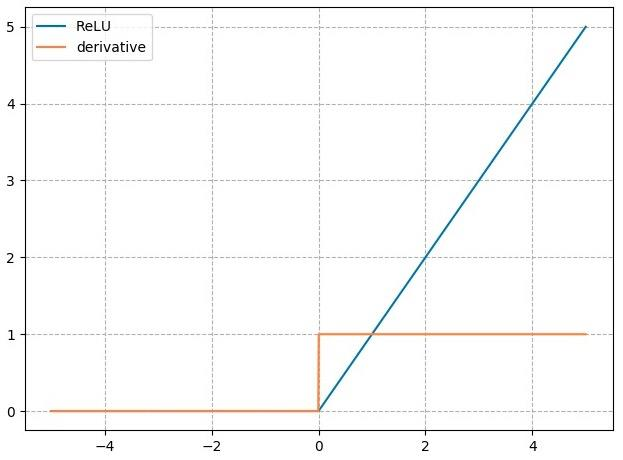
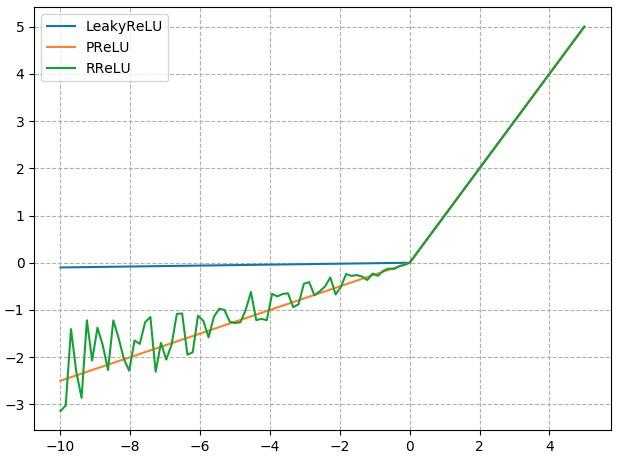
4. 改进的 nn.ReLU 激活函数
nn.LeakyReLU
- negative_slope:负半轴斜率
nn.PReLU
- init:可学习斜率
nn.RReLU
- lower:均匀分布下限
- upper:均匀分布上限
第四周
14. 权值初始化
Content
- 梯度消失与梯度爆炸
- Xavier 方法与 Kaiming 方法
- 常用初始化方法
14.1 梯度消失与梯度爆炸
1. 什么是梯度消失与梯度爆炸
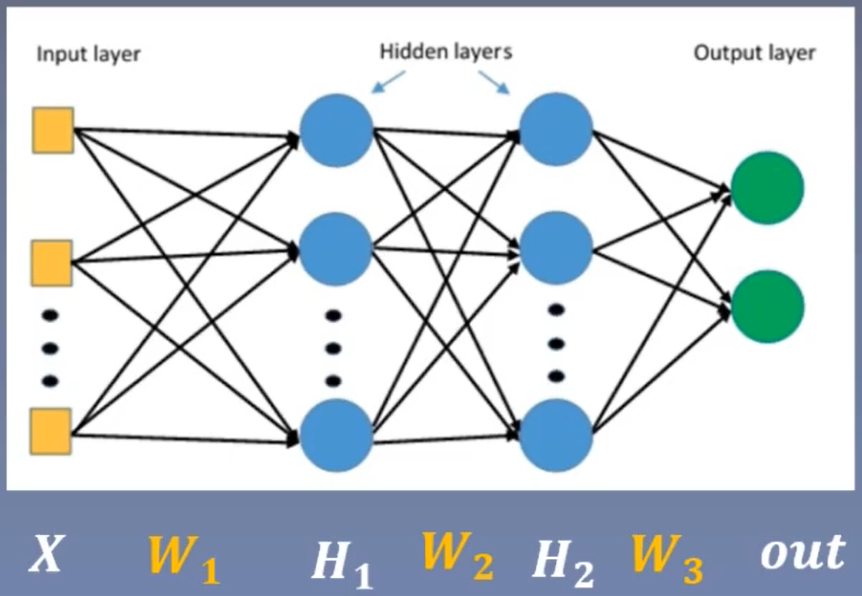


 的梯度取决于上一层的输出
的梯度取决于上一层的输出 
梯度消失: 
梯度爆炸: 
2. 为什么会梯度消失与梯度爆炸



1.2.3 ==> 


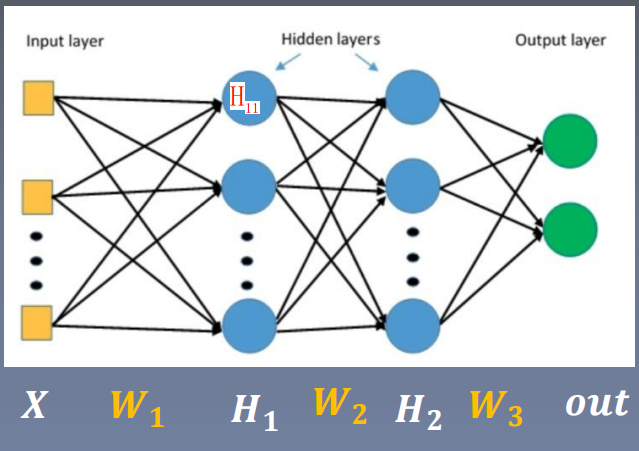
① ②
②
由 ①② 可得: 

3. 如何解决梯度消失与梯度爆炸
要解决梯度消失与梯度爆炸,就得使网络层的方差保持不变,这就得让网络层的方差为 1 。
==>
==>
当然,这只能在没有激活函数的情况解决梯度消失与梯度爆炸。
在具有激活函数的情况下,还得通过其他方法解决梯度消失有梯度爆炸
14.2 Xavier 初始化
适用激活函数:饱和函数,如 Sigmoid、Tanh
方差一致性:保持数据尺度维持在恰当范围,通常方差为 1
①
②
由①②可得:
通常 Xavier 采用的是均匀分布:
故:
==>
14.3 Kaiming 初始化
适用激活函数:ReLU及其变种
方差一致性:保持数据尺度维持在恰当范围,通常方差为 1
ReLU变种:
(其中, a:负半轴的斜率;ReLU中负半轴斜率为 0 )
14.4 常用初始化方法
1. 常用的初始化方法
常用的初始化方法可以分为四大类:
- Xavier均匀分布
Xavier标准正态分布
Kaiming均匀分布
Kaiming标准正态分布
均匀分布
- 正态分布
常数分布
正交矩阵初始化
- 单位矩阵初始化
- 稀疏矩阵初始化
2. nn.init.calculate_gain
nn.init.calculate_gain
主要功能:计算激活函数的方差变化尺度(输入数据的方差 / 经过激活函数之后输出数据的方差)
主要参数:
- nonlinearity: 激活函数名称
- param: 激活函数的参数,如 Leaky ReLU 的 negative_slop
15. 损失函数(一)
Content
- 损失函数概念
- 交叉熵损失函数
- NLL / BCE / BCEWithLogits Loss
15.1 损失函数概念
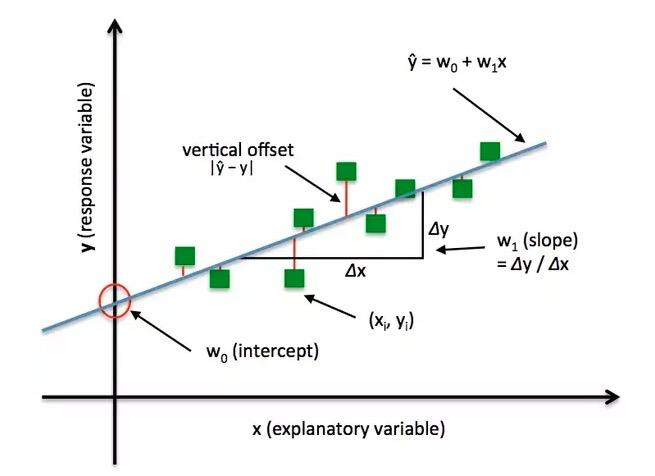
损失函数:衡量模型输出与真实标签的差异
损失函数(Loss Function):
计算一个样本:模型输出与真实标签的差异
代价函数(Cost Function):
计算整个训练集 的平均值
目标函数(Objective Function):
对模型进行的一些约束,以防止过拟合
class _Loss(Module):def __init__(self, size_average=None, reduce=None, reduction='mean'):super(_Loss, self).__init__()if size_average is not None or reduce is not None:self.reduction = _Reduction.legacy_get_string(size_average, reduce)else:self.reduction = reduction
注意:
size_average = None 与 reduce = None 这两个参数即将被舍弃,他们的功能在参数 reduction = ‘mean’ 中已经可以完全被实现了。
所以不要再使用 size_average = None 与 reduce = None 这两个参数。
15.2 交叉熵损失函数
交叉熵
交叉熵 = 信息熵 + 相对熵
熵:
用来描述不确定性;熵越大,不确定性越大。
熵是自信息的期望
自信息: ( )
相对熵: ( P:真实的分布,Q:模型输出的分布 )
又称为 KL 散度,用来衡量两个分布之间的差异,也就是两个分布之间的距离;但是它不是一个距离的函数,它没有距离函数具有的对称性。
交叉熵:
衡量两个概率分布之间的关系,两个概率分布之间的相似度
相对熵:
交叉熵: ( P:真实的分布,Q:模型输出的分布 )
1. nn.CrossEntropyLoss
nn.CrossEntropyLoss
功能: nn.LogSoftmax() 与 nn.NLLLoss() 结合,进行交叉熵计算
主要参数:
- weight=None:各类别 loss 设置的权值
- ignore_index=-100:忽略某个类别
- reduction=’mean’:计算模式,可为 none/sum/mean
- none:逐个元素计算
- sum:所有元素求和,返回标量
- mean:加权平均,返回标量
计算公式:# 计算交叉熵nn.CrossEntropyLoss(weight=None, # 各类别loss设置的权值ignore_index=-100, # 忽略某个类别reduction='mean') # 计算模式,如none/sum/mean# none:逐个元素计算# sum:所有元素求和,返回标题# mean:加权平均,返回标量
15.3 NLL / BCE / BCEWithLogits Loss
2. nn.NLLoss
nn.NLLoss
功能:实现负对数似然函数中的负号功能
主要参数:
- weigh t:各类别的 loss 设置权值
- ignore_ind e x:忽略某个类别
- reduction :计算模式,可为 none/sum /m e an
- none:逐个元素计算
- sum:所有元素求和,返回标量
- mean:加权平均,返回标量
计算公式:# 1. 实现负对数似然函数中的负号功能nn.NLLLoss(weight=None, # 各类别的loss设置权值ignore_index=-100, # 忽略某个类别reduction='mean') # 计算模式,如none/sum/
3. nn.BCELoss
nn.BCELoss
功能:二分类交叉熵
注意事项:输入值取值在 [0,1]
主要参数:
- weight:各类别的 loss 设置权值
- ignore _index:忽略某个类别
- reduction :计算模式,可为 none/sum /m e an
- none:逐个元素计算
- sum:所有元素求和,返回标量
- mean:加权平均,返回标量
计算公式:# 2. 二分类交叉熵# 注:输入值为[0,1],可配合sigmoid函数使用nn.BCELoss(weight=None, # 各类别loss设置的权值ignore_index=-100, # 忽略某个类别reduction='mean') # 计算模式,如none/sum/mean
4. nn.BCEWithLogitsLoss
nn.BCEWithLogitsLoss
功能:结合 Sigmoid 与二分类交叉熵
注意事项:网络最后不加 Sigmoid 函数
主要参数:
- pos_weight:正样本的权值
- weight:各类别的 loss 设置权值
- ignore _index:忽略某个类别
- reduction:计算模式,可为 none/sum /mean
- none:逐个元素计算
- sum:所有元素求和,返回标量
- mean:加权平均,返回标量
计算公式:# 3. 结合Sigmoid与二分类交叉熵# 注:不需要额外加入Sigmoid函数nn.BCEWithLogitsLoss(weight=None, # 各类别loss设置的权值ignore_index=-100, # 忽略某个类别reduction='mean', # 计算模式,如none/sum/meanpos_weight=None) # 正样本的权值
16. 损失函数(二)—— pytorch 中其余 14 中损失函数
Content
- nn.L1Loss
- nn.MSELoss
- nn.SmoothL1Loss
- nn.PoissonNLLLoss
- nn.KLDivLoss
- nn.MarginRankingLoss
- nn.MultiLabelMarginLoss
- nn.SoftMarginLoss
- nn.MultiLabelSoftMarginLoss
- nn.MultiMarginLoss
- nn.TripletMarginLoss
- nn.HingeEmbeddingLoss
- nn.CosineEmbeddingLoss
- nn.CTCLoss
16.1 回归中常用的两个损失函数
5. nn.L1Loss
nn.L1Loss
功能: 计算 inputs 与 target 之差的绝对值
主要参数:
- reduction :计算模式,可为 none/sum/mean
- none:逐个元素计算
- sum:所有元素求和,返回标量
- mean:加权平均,返回标量
注意:nn.L1Loss(size_average=None,reduce=None,reduction='mean’)
size_average = None 与 reduce = None 这两个参数即将被舍弃,他们的功能在参数 reduction = ‘mean’ 中已经可以完全被实现了。
所以不要再使用 size_average = None 与 reduce = None 这两个参数。
计算公式:
6. nn.MSELoss
nn.MSELoss
功能: 计算 inputs 与 target 之差的平方
主要参数:
- reduction :计算模式,可为 none/sum/mean
- none:逐个元素计算
- sum:所有元素求和,返回标量
- mean:加权平均,返回标量
注意:nn.MSELoss(size_average=None,reduce=None,reduction='mean’)
size_average = None 与 reduce = None 这两个参数即将被舍弃,他们的功能在参数 reduction = ‘mean’ 中已经可以完全被实现了。
所以不要再使用 size_average = None 与 reduce = None 这两个参数。
计算公式:
7. SmoothL1Loss
SmoothL1Loss
功能: 平滑的 L1Loss
主要参数:
- reduction :计算模式,可为 none/sum/mean
- none:逐个元素计算
- sum:所有元素求和,返回标量
- mean:加权平均,返回标量
nn.SmoothL1Loss(size_average=None,reduce=None,reduction='mean’)
注意:
size_average = None 与 reduce = None 这两个参数即将被舍弃,他们的功能在参数 reduction = ‘mean’ 中已经可以完全被实现了。
所以不要再使用 size_average = None 与 reduce = None 这两个参数。
计算公式:
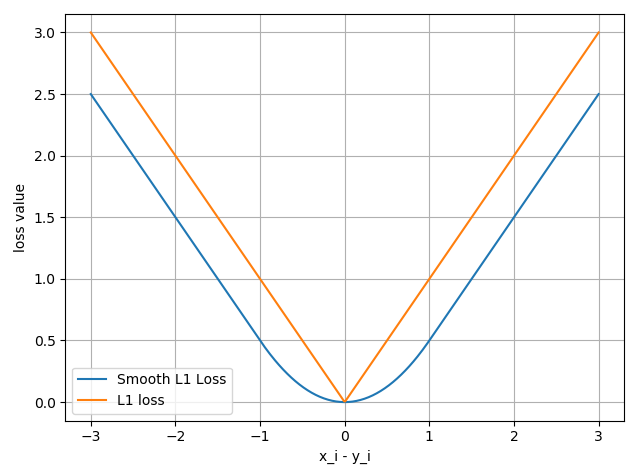
8. PoissonNLLLoss
PoissonNLLLoss
功能:泊松分布的负对数似然损失函数
主要参数:
- log_input :输入是否为对数形式,决定计算公式
- full :计算所有 loss ,默认为 False
- eps :修正项,避免 log(input) 为 nan
注意:nn.PoissonNLLLoss(log_input=True,full=False,size_average=None,eps=1e-08,reduce=None,reduction='mean')
size_average = None 与 reduce = None 这两个参数即将被舍弃,他们的功能在参数 reduction = ‘mean’ 中已经可以完全被实现了。
所以不要再使用 size_average = None 与 reduce = None 这两个参数。
计算公式:
9. nn.KLDivLoss
nn.KLDivLoss
功能:计算KLD(divergence),KL 散度,相对熵
注意事项:需提前将输入计算 log-probabilities ,如通过 nn.logsoftmax()
主要参数:
- reduction :计算模式,可为 none/sum/mean/batchmean
- batchmean:batchsize 维度求平均值
- none:逐个元素计算
- sum:所有元素求和,返回标量
- mean:加权平均,返回标量
注意:nn.KLDivLoss(size_average=None,reduce=None,reduction='mean')
size_average = None 与 reduce = None 这两个参数即将被舍弃,他们的功能在参数 reduction = ‘mean’ 中已经可以完全被实现了。
所以不要再使用 size_average = None 与 reduce = None 这两个参数。
计算公式:
公式定义的计算公式:
P:真实标签分布,Q:模型输出分布
nn.KLDivLoss 函数的计算公式如下:
10. nn.MarginRankingLoss
nn.MarginRankingLoss
功能:计算两个向量之间的相似度,用于排序任务
特别说明:该方法计算两组数据之间的差异,返回一个 n*n 的 loss 矩阵
主要参数:
- margin :边界值,x1 与 x2 之间的差异值
- reduction :计算模式,可为 none/sum/mean
nn.MarginRankingLoss(margin=0.0,size_average=None,reduce=None,reduction='mean')
注意:
size_average = None 与 reduce = None 这两个参数即将被舍弃,他们的功能在参数 reduction = ‘mean’ 中已经可以完全被实现了。
所以不要再使用 size_average = None 与 reduce = None 这两个参数。
计算公式:
y = 1时, 希望x1比x2大,当 x1 > x2 时,不产生loss
y = -1时,希望x2比x1大,当 x2 > x1 时,不产生loss
11. nn.MultiLabelMarginLoss
nn.MultiLabelMarginLoss
功能:多标签边界损失函数
举例:四分类任务,样本 x 属于 0 类和 3 类,
标签:[0, 3, -1, -1] , 不是 [1, 0, 0, 1]
主要参数:
- reduction :计算模式,可为 none/sum/mean
nn.MultiLabelMarginLoss(size_average=None,reduce=None,reduction='mean')
注意:
size_average = None 与 reduce = None 这两个参数即将被舍弃,他们的功能在参数 reduction = ‘mean’ 中已经可以完全被实现了。
所以不要再使用 size_average = None 与 reduce = None 这两个参数。
计算公式:
x:模型输出值,y:真实标签。
举例:四分类任务,样本 x 属于 0 类和 3 类,标签 y:[0, 3, -1, -1] , 不是 [1, 0, 0, 1] ;
x 属于第几类,y 中就有几,随后用 -1 将 y 的长度补足到 x 的长度。
上述计算公式中 表示每个真实类别(标签所在)的神经元输出减去其他(非标签所在的)神经元的输出。
x[y[j]] 表示 样本x所属类的输出值,x[i] 表示不等于该类的输出值。
12. nn.SoftMarginLoss
nn.SoftMarginLoss
功能:计算二分类的 logistic 损失
主要参数:
- reduction :计算模式,可为 none/sum/mean
注意:nn.SoftMarginLoss(size_average=None,reduce=None,reduction='mean')
size_average = None 与 reduce = None 这两个参数即将被舍弃,他们的功能在参数 reduction = ‘mean’ 中已经可以完全被实现了。
所以不要再使用 size_average = None 与 reduce = None 这两个参数。
计算公式:
13. nn.MultiLabelSoftMarginLoss
nn.MultiLabelSoftMarginLoss
功能:SoftMarginLoss 多标签版本
主要参数:
- weight:各类别的 loss 设置权值
- reduction :计算模式,可为 none/sum/mean
注意:nn.MultiLabelSoftMarginLoss(weight=None,size_average=None,reduce=None,reduction='mean')
size_average = None 与 reduce = None 这两个参数即将被舍弃,他们的功能在参数 reduction = ‘mean’ 中已经可以完全被实现了。
所以不要再使用 size_average = None 与 reduce = None 这两个参数。
计算公式:
14. nn.MultiMarginLoss
nn.MultiMarginLoss
功能:计算多分类的折页损失
主要参数:
- p :可选 1 或 2
- weight:各类别的 loss 设置权值
- margin :边界值
- reduction :计算模式,可为 none/sum/mean
注意:nn.MultiMarginLoss(p=1,margin=1.0,weight=None,size_average=None,reduce=None,reduction='mean')
size_average = None 与 reduce = None 这两个参数即将被舍弃,他们的功能在参数 reduction = ‘mean’ 中已经可以完全被实现了。
所以不要再使用 size_average = None 与 reduce = None 这两个参数。
计算公式:
15. nn.TripletMarginLoss
nn.TripletMarginLoss
功能:计算三元组损失,人脸验证中常用
主要参数:
- p :范数的阶,默认为 2
- margin :边界值
- reduction :计算模式,可为 none/sum/mean
三元组: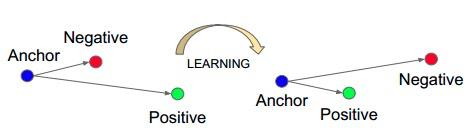
nn.TripletMarginLoss(margin=1.0,p=2.0,eps=1e-06,swap=False,size_average=None,reduce=None,reduction='mean')
注意:
size_average = None 与 reduce = None 这两个参数即将被舍弃,他们的功能在参数 reduction = ‘mean’ 中已经可以完全被实现了。
所以不要再使用 size_average = None 与 reduce = None 这两个参数。
计算公式:
16. nn.HingeEmbeddingLoss
nn.HingeEmbeddingLoss
功能:计算两个输入的相似性,常用于非线性 embedding 和半监督学习
特别注意:输入 x 应为两个输入之差的绝对值
主要参数:
- margin :边界值
- reduction :计算模式,可为 none/sum/mean
注意:nn.HingeEmbeddingLoss(margin=1.0,size_average=None,reduce=None,reduction='mean’)
size_average = None 与 reduce = None 这两个参数即将被舍弃,他们的功能在参数 reduction = ‘mean’ 中已经可以完全被实现了。
所以不要再使用 size_average = None 与 reduce = None 这两个参数。
计算公式:
17. nn.CosineEmbeddingLoss
nn.CosineEmbeddingLoss
功能:采用余弦相似度计算两个输入的相似性;关注的是方向上的差异
主要参数:
- margin :可取值 [-1, 1] , 推荐为 [0, 0.5]
- reduction :计算模式,可为 none/sum/mean
注意:nn.CosineEmbeddingLoss(margin=0.0,size_average=None,reduce=None,reduction='mean')
size_average = None 与 reduce = None 这两个参数即将被舍弃,他们的功能在参数 reduction = ‘mean’ 中已经可以完全被实现了。
所以不要再使用 size_average = None 与 reduce = None 这两个参数。
计算公式:
18. nn.CTCLoss
nn.CTCLoss
功能: 计算CTC损失,解决时序类数据的分类(Connectionist Temporal Classification)
主要参数:
- blank :blank label
- zero_infinity :无穷大的值或梯度置 0
- reduction :计算模式,可为 none/sum/mean
# 计算CTC损失,解决时序类数据的分类nn.CTCLoss(blank=0, # blank labelreduction='mean', # 无穷大的值或梯度置0zero_infinity=False)
参考文献:
A. Graves et al.: Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks
损失函数总结

17. 优化器 Optimizer(一)
Content
- 什么是优化器
- optimizer 的属性
- optimizer 的方法
17.1 什么是优化器(Optimizer)
- pytorch 的优化器:管理 并 更新 模型中可学习参数的值,使得模型输出更接近真实标签
- 导数:函数在指定坐标轴上的变化率
- 方向导数:函数在指定方向上的变化率
- 梯度:向量,方向为方向导数取得最大值的方向
17.2 优化器的基本属性
基本属性:
- defaults:优化器超参数
- state:参数的缓存,如 momentum 的缓存
- params_groups:管理的参数组
- _step_count:记录更新次数,学习率调整中使用
class Optimizer(object):def __init__(self, params, defaults):self.defaults = defaults # 优化器超参数self.state = defaultdict(dict) # 参数的缓存,如momentum的缓存self.param_grops = [] # 管理的参数组,包含字典元素的list# param_groups = [{'params': param_groups}]# _step_count:记录更新次数,学习率调整中使用...
17.3 优化器的基本方法
基本方法:
1. zero_grad()
zero_grad():清空管理参数的梯度
注:pytorch中张量梯度不自动清零
class Optimizer(object):def zero_grad(self):r"""Clears the gradients of all optimized :class:`torch.Tensor` s."""for group in self.param_groups:for p in group['params']:if p.grad is not None:p.grad.detach_()p.grad.zero_()
2. step()
step():执行一步更新
class Optimizer(object):def __init__(self, params, defaults):self.defaults = defaultsself.state = defaultdict(dict)self.param_groups = []def step(self, closure):r"""Performs a single optimization step (parameter update).Arguments:closure (callable): A closure that reevaluates the model andreturns the loss. Optional for most optimizers."""raise NotImplementedError
3. add_param_group()
add_param_group():添加参数组
class Optimizer(object):def add_param_group(self, param_group):for group in self.param_groups:param_set.update(set(group['params']))self.param_groups.append(param_group)
4. state_dict()
state_dict():获取优化器当前状态信息字典
class Optimizer(object):def state_dict(self):return {'state': packed_state,'param_groups': param_groups,}
5. load_state_dict()
load_state_dict():加载状态信息字典
class Optimizer(object):def state_dict(self):return {'state': packed_state,'param_groups': param_groups,}def load_state_dict(self, state_dict):
18. 常用的优化方法(优化器)
Content
- learning rate 学习率
- momentum 动量
- torch.optim.SGD
- Pytorch的十种优化器
18.1 learning rate 学习率
梯度下降:
例如:
梯度下降:
LR:学习率(learning rate)/步长,控制更新的步伐
18.2 momentum 动量
Momentum(动量,冲量):结合当前梯度与上一次更新信息,用于当前更新
指数加权平均:
例如:
梯度下降:
pytorch中更新公式:
例如:
18.3 torch.optim.SGD
optim.SGD
主要参数:
- params:管理的参数组
- lr:初始学习率
- momentum:动量系数,贝塔
- weight_decay:L2 正则化系数
- nesterov:是否采用 NAG
torch.optim.SGD(params, # 管理的参数组lr= < object object >, # 初始学习率momentum=0, # 动量系数betadampening=0, # L2正则化系数weight_decay=0,nesterov=False) # 是否采用NAG
NAG参考文献:
《On the importance of initialization and momentum in deep learning》
18.4 Pytorch的十种优化器
pytorch中的十种优化器:
- optim.SGD:随机梯度下降法
- optim.Adagrad:自适应学习率梯度下降法
- optim.RMSprop:Adagrad 的改进
- optim.Adadelta:Adagrad 的改进
- optim.Adam:RMSprop 结合 Momentum
- optim.Adamax:Adam 增加学习率上限
- optim.SparseAdam:稀疏版的 Adam
- optim.ASGD:随机平均梯度下降
- optim.Rprop:弹性反向传播
- optim.LBFGS:BFGS 的改进
参考文献:
- optim.SGD: 《On the importance of initialization and momentum in deep learning 》
- optim.Adagrad: 《Adaptive Subgradient Methods for Online Learning and Stochastic Optimization》
- optim.RMSprop:http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf
- optim.Adadelta: 《 AN ADAPTIVE LEARNING RATE METHOD》
- optim.Adam: 《Adam: A Method for Stochastic Optimization》
- optim.Adamax: 《Adam: A Method for Stochastic Optimization》
- optim.SparseAdam
- optim.ASGD:《Accelerating Stochastic Gradient Descent using Predictive Variance Reduction》
- optim.Rprop:《Martin Riedmiller und Heinrich Braun》
- optim.LBFGS:BDGS 的改进
第五周
19. 学习率调整策略
Content
- 为什么要调整学习率?
- pytorch 的六种学习率调整策略
- 学习率调整小结
19.1 为什么要调整学习率?
梯度下降:
LR:学习率(learning rate)/步长,控制更新的步伐
- 学习率大时,loss 下降得快,但到了一定程度不再下降
- 学习率小时,loss 下降得多,但下降的速度慢
- 在训练的过程中调整学习率,先大后小,可以使得训练的效率更高效果更好
19.2 基类——class _LRScheduler
1. class _LRScheduler 的主要属性
class _LRScheduler
主要属性:
- optimizer:关联的优化器
- last_epoch:记录 epoch 数
base_lrs:记录初始学习率
class _LRScheduler(object):def __init__(self, optimizer, last_epoch=-1):
2. class _LRScheduler 的主要方法
class _LRScheduler
主要方法:
- step():更新下一个 epoch 的学习率
get_lr():虚函数,计算下一个 epoch 的学习率
class _LRScheduler(object):def __init__(self, optimizer, last_epoch=-1):def get_lr(self):raise NotImplementedError
19.3 pytorch 的六种学习率调整策略
1. StepLR
StepLR
功能:等间隔调整学习率
主要参数:
- step_size:调整间隔数
- gamma:调整系数
调整方式:
# 1. StepLR# 等间隔调整学习率lr_scheduler.StepLR(optimizer,step_size, # 调整间隔数gamma=0.1, # 调整系数last_epoch=-1)
2. MultiStepLR
MultiStepLR
功能:按给定间隔调整学习率
主要参数:
- milestones:设定调整时刻数
- gamma:调整系数
调整方式:
# 2. MultiStepLR# 按给定间隔调整学习率lr_scheduler.MultiStepLR(optimizer,milestones, # 设定调整时刻数,如[50,70,100]gamma=0.1, # 调整系数last_epoch=-1)
3. ExponentialLR
ExponentialLR
功能:按指数衰减调整学习率
主要参数:
- gamma:指数的底
调整方式:
# 3. ExponentialLR# 按指数衰减调整学习率lr_scheduler.ExponentialLR(optimizer,gamma=0.1, # 指数的底last_epoch=-1)
4. CosineAnnealingLR
CosineAnnealingLR
功能:余弦周期调整学习率
主要参数:
- T_max:下降周期
- eta_min:学习率下限
调整方式:
# 4. CosineAnnealingLR# 余弦周期调整学习率lr_scheduler.CosineAnnealingLR(optimizer,T_max, # 下降周期eta_min=0, # 学习率下限last_epoch=-1)
5. ReduceLRonPlateau
ReduceLRonPlateau
功能:监控指标,当指标不再变化则调整学习率
主要参数:
- mode:min/max 两种模式
- mode = min:观察所要监控的指标下降,监控的指标不再下降就调整学习率;一般监控 loss
- mode = max:观察所要监控的指标上升,监控的指标不再上升就调整学习率;一般监控分类准确率
- factor:调整系数
- patience:“耐心 ”,接受连续几次不变化
- cooldown:“冷却时间”,停止监控一段时间
- verbose:是否打印日志
- min_lr:学习率下限
- eps:学习率衰减最小值
# 5. ReduceLRonPlateau# 监控指标,当指标不再变化时调整学习率# scheduler_lr.step(要监测的变量)lr_scheduler.ReduceLROnPlateau(optimizer,mode='min', # min/max两种模式factor=0.1, # 调整系数patience=10, # 接受参数不变化的迭代次数verbose=False, # 是否打印日志threshold=0.0001,threshold_mode='rel',cooldown=0, # 停止监控的迭代次数min_lr=0, # 学习率下限eps=1e-08) # 学习率衰减最小值
6. LambdaLR
LambdaLR
功能:自定义调整策略
主要参数:
- lr_lambda:function or list
# 6. LambdaLR# 自定义调整策略,可以对不同的参数组使用不同的参数调整策略lr_scheduler.LambdaLR(optimizer,lr_lambda, # 函数或元素为函数的列表last_epoch=-1)
19.4 学习率调整小结
学习率调整小结:
有序调整:Step、MultiStep、Exponential 和 CosineAnnealing
自适应调整:ReduceLROnPleateau
自定义调整:Lambda
19.5 学习率初始化
学习率初始化:
设置较小数:0.01、0.001、0.0001
搜索最大学习率: 《Cyclical Learning Rates for Training Neural Networks》
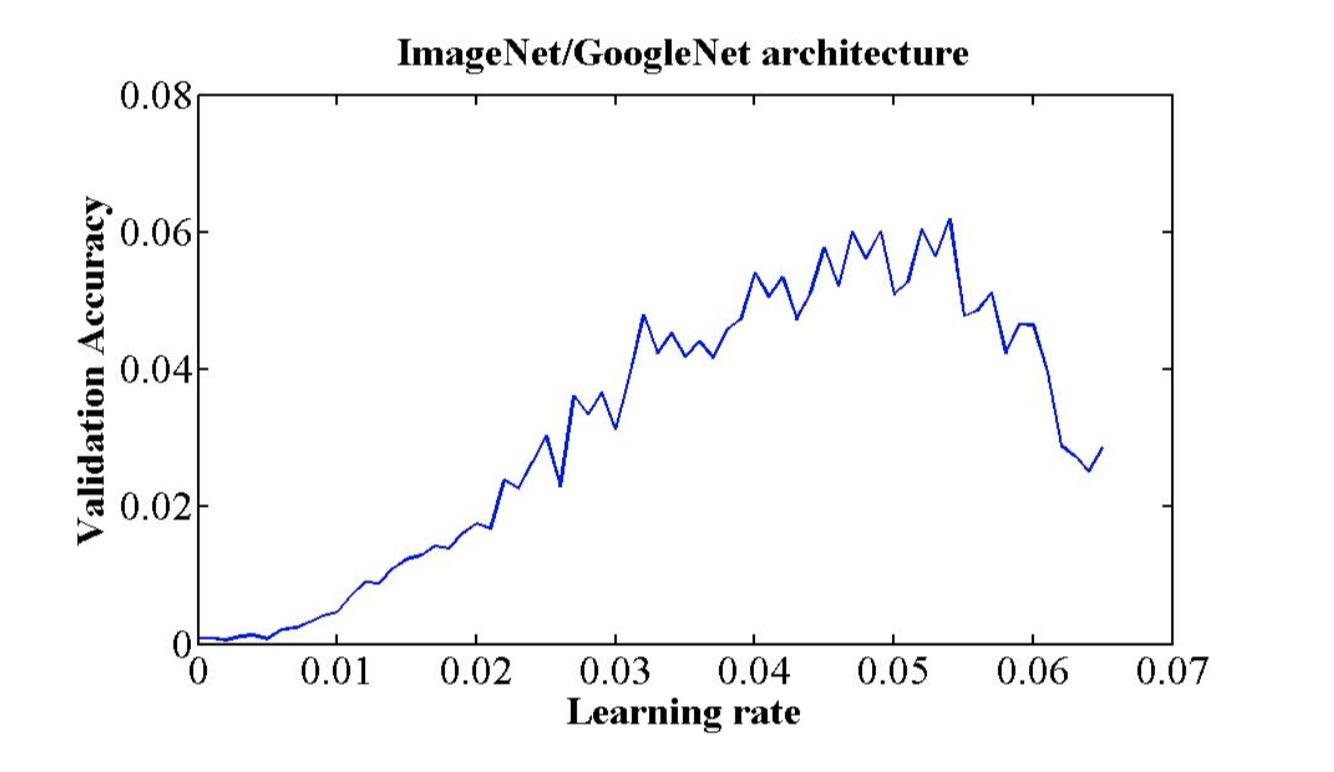
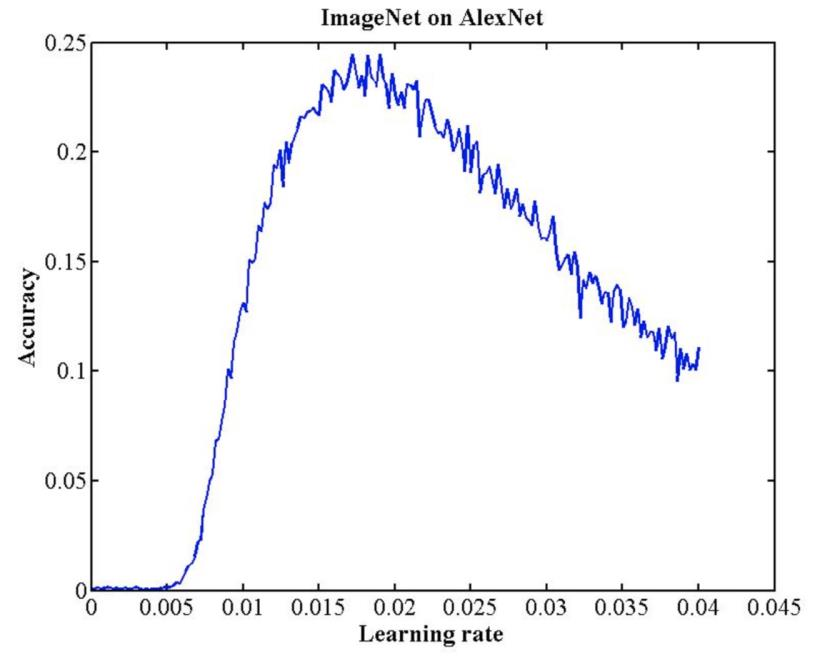
20. 可视化工具——TensorBoard
Content
- TensorBoard简介
- TensorBoard安装
- TensorBoard运行可视化
20.1 TensorBoard简介
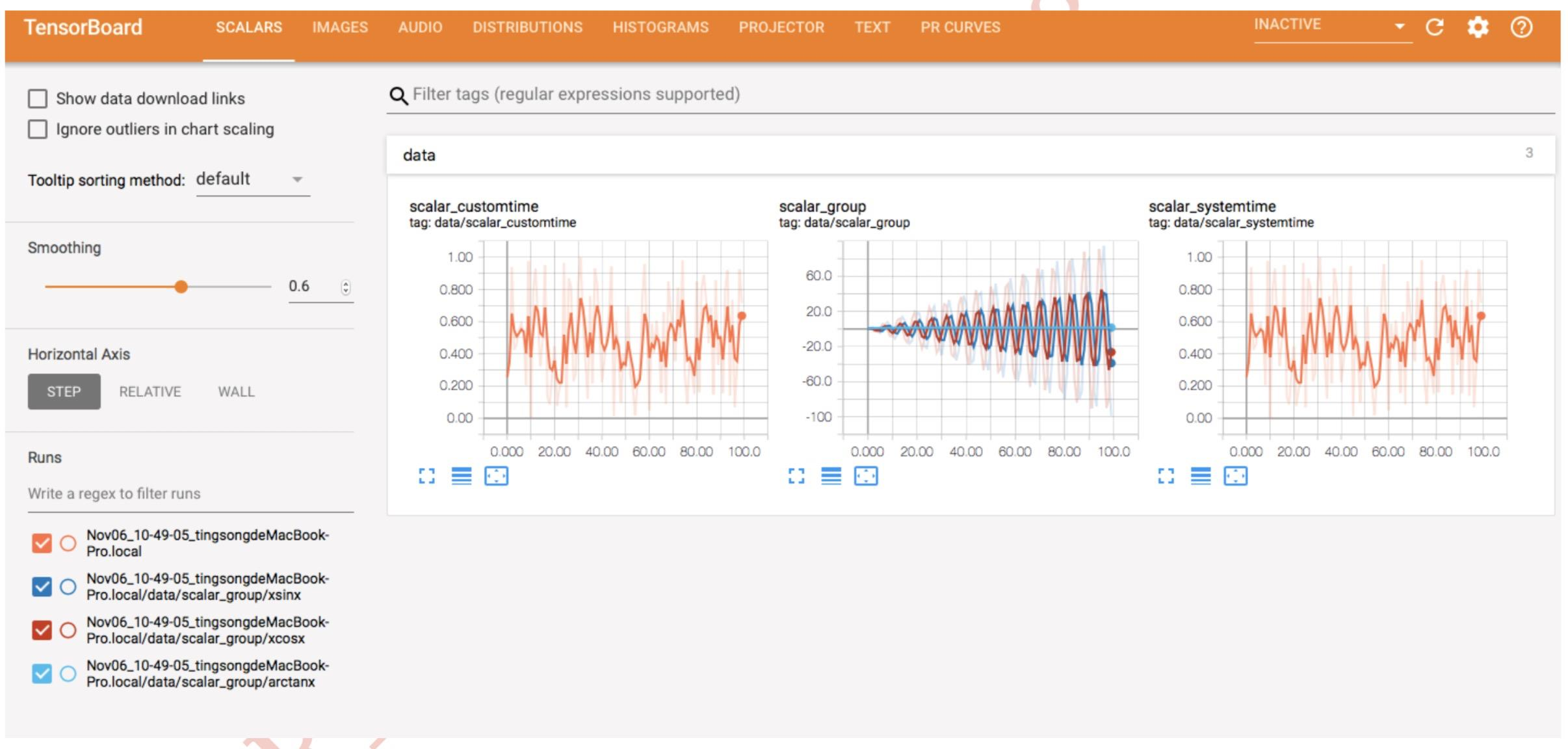
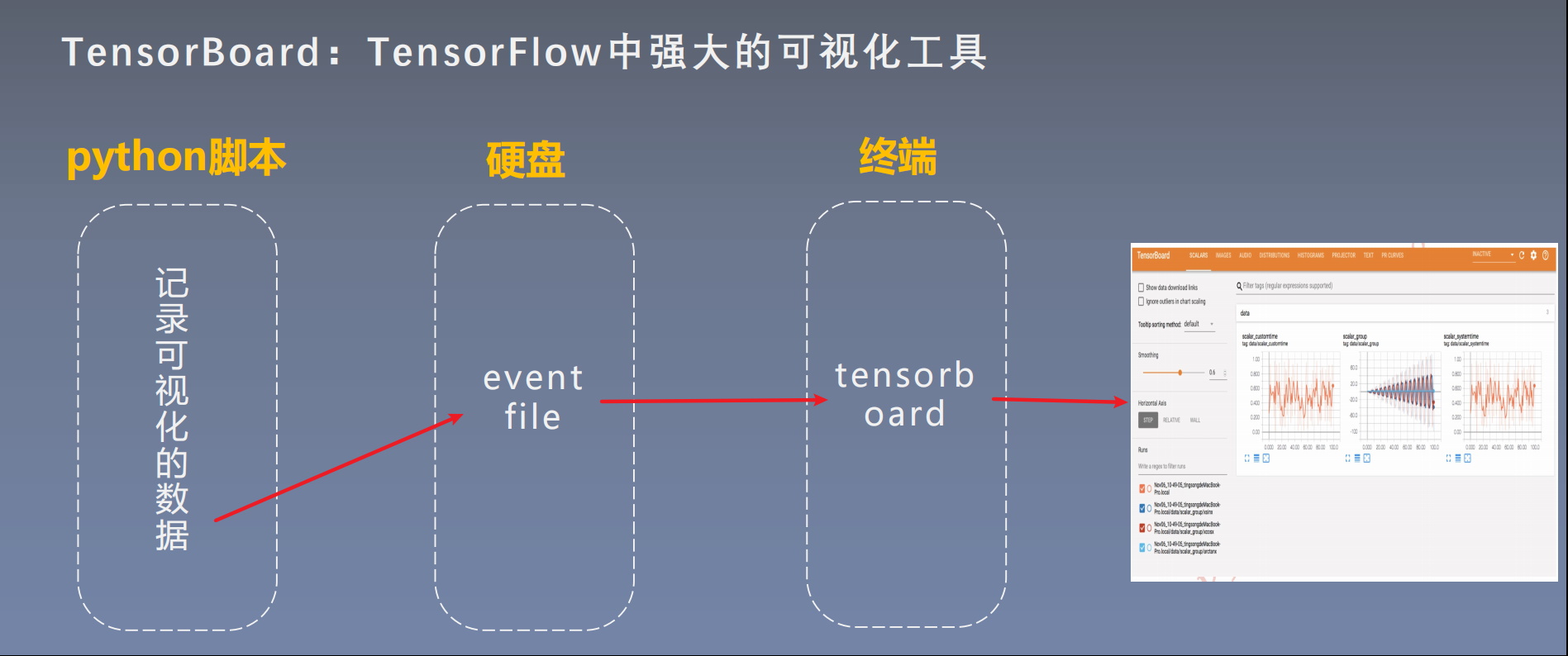
1. TensorBoard简介
TensorBoard:TensorFlow 中强大的可视化工具
支持标量、图像、文本、音频、视频和 Eembedding 等多种数据可视化
2. 运行机制
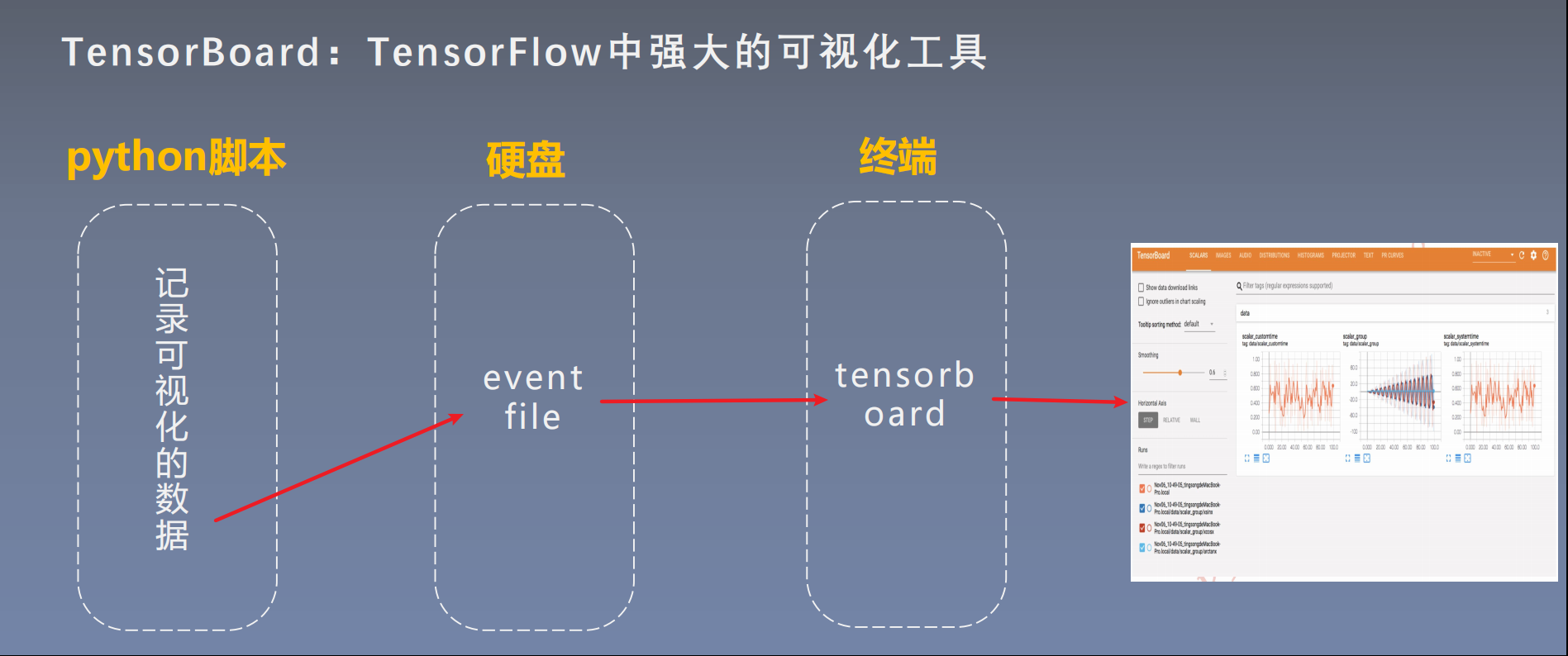
20.2 TensorBoard安装
安装注意事项:
pip install tensorboard 的时候会报错:
ModuleNotFoundError: No module named ‘past’
通过 pip install future 解决
20.3 TensorBoard运行可视化
tensorboard --logdir=./runs
TensorFlow installation not found - running with reduced feature set.Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_allTensorBoard 2.5.0 at http://localhost:6006/ (Press CTRL+C to quit)
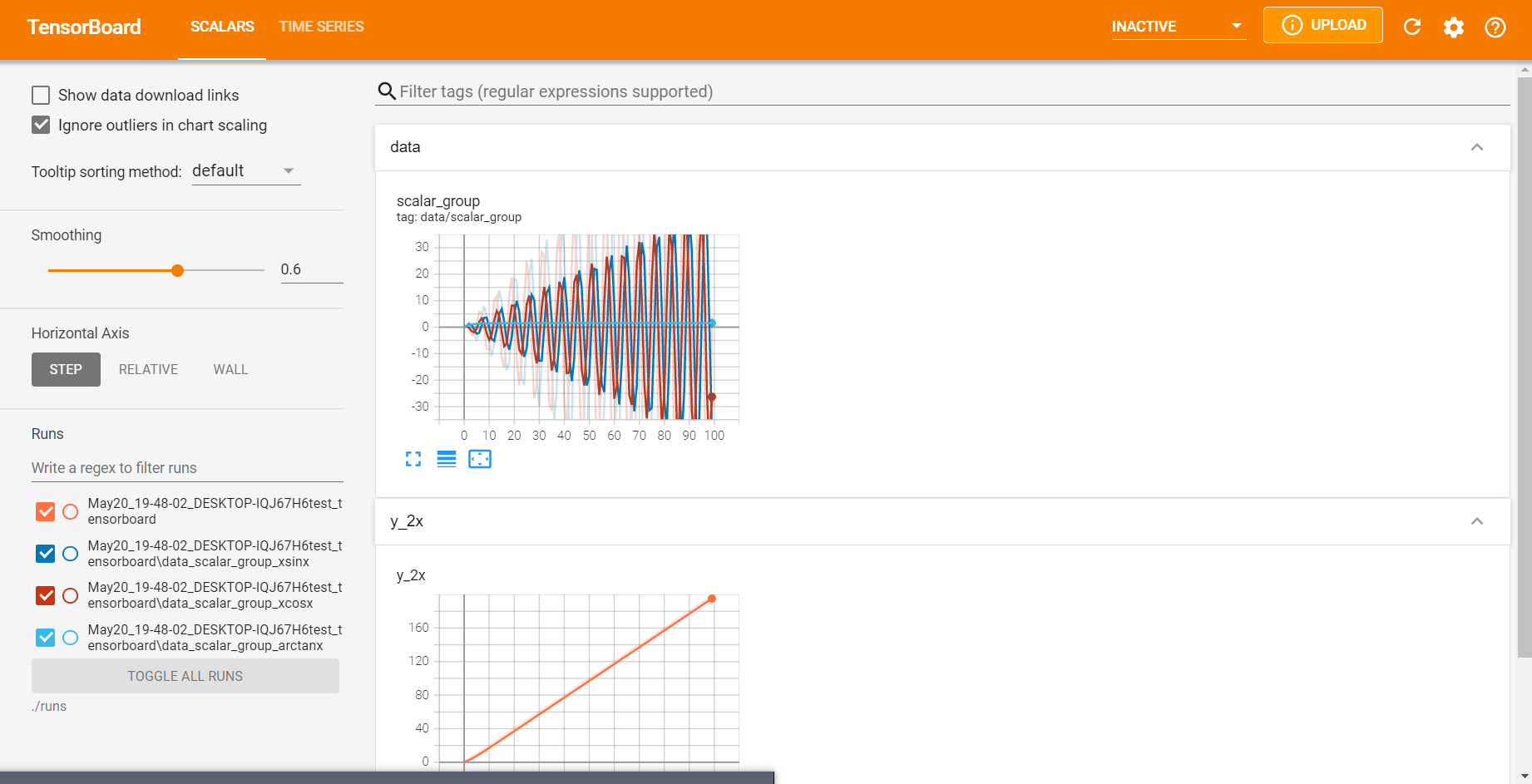
21. TensorBoard 使用(一)
Content
- SummaryWriter
- add_scalar and add_histogram
- 模型指标监控
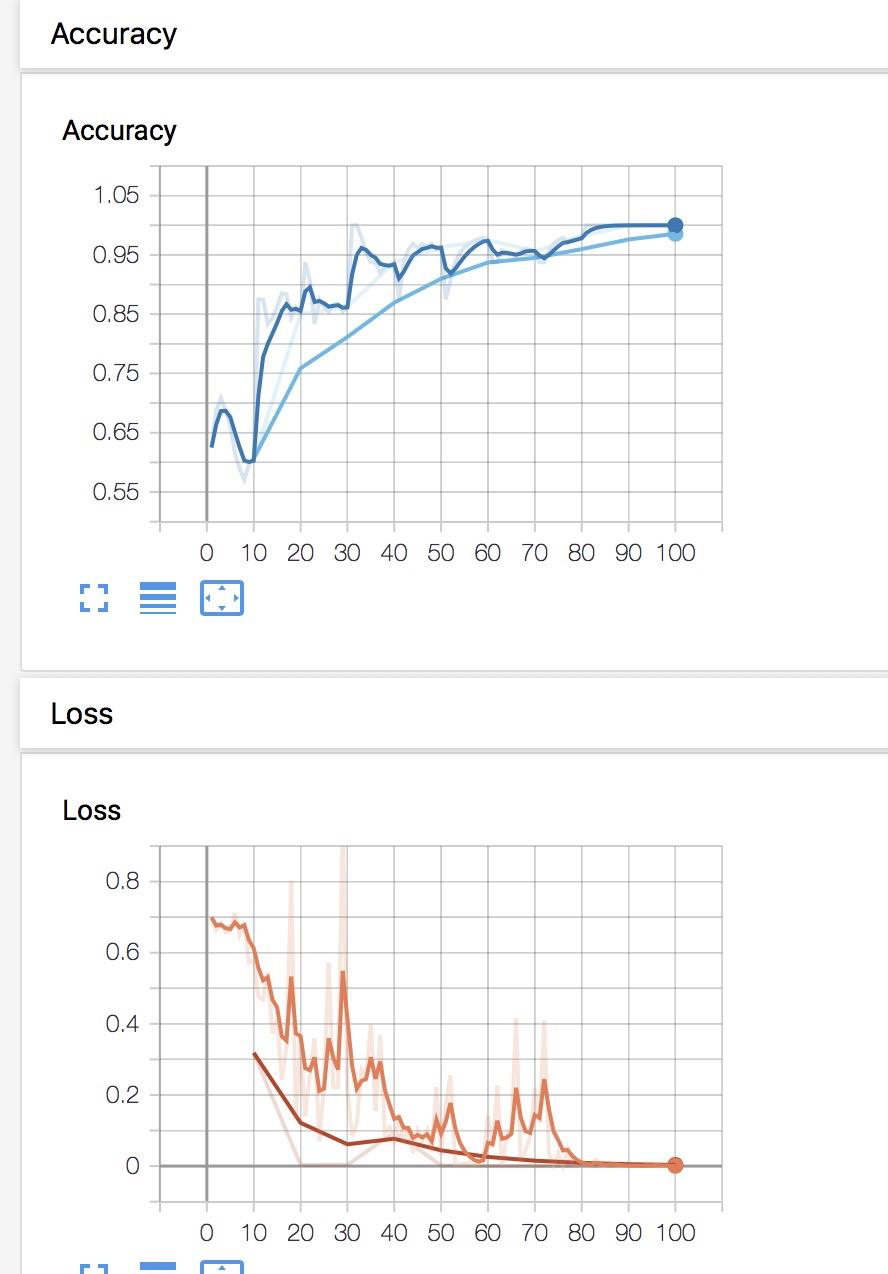
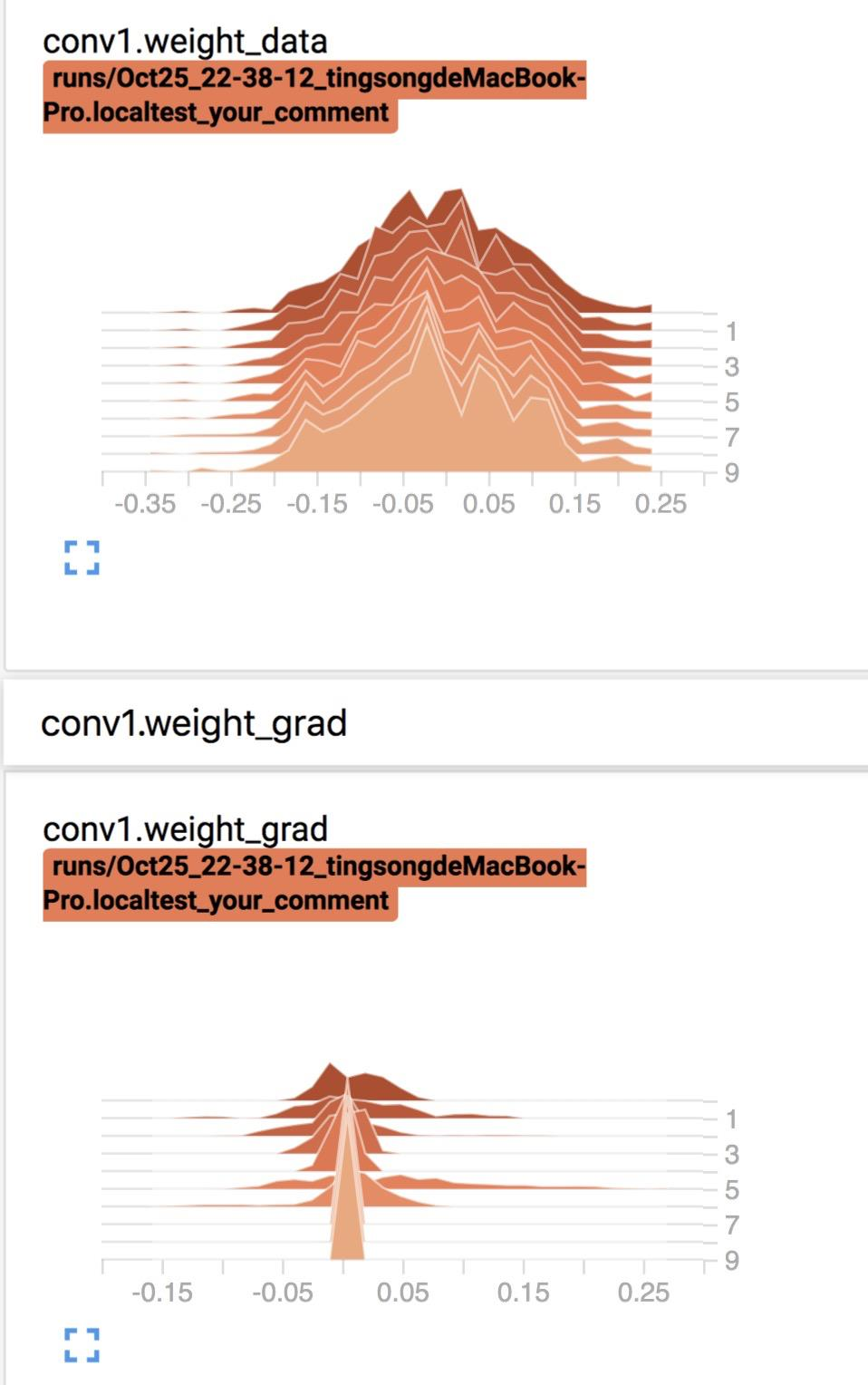
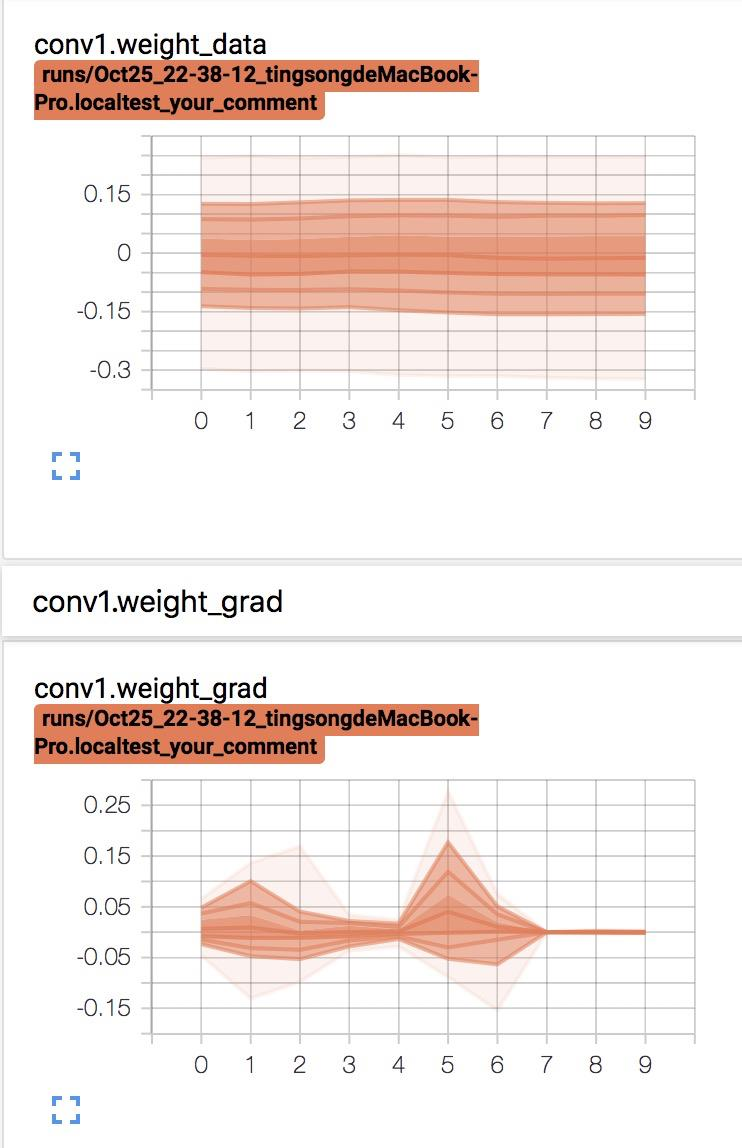
21.1 SummaryWriter
SummaryWriter
功能:提供创建event file的高级接口
主要属性:
- log_dir:event file 输出文件夹;默认 log_dir = None,表示在当前 .py 文件所在文件下创建一个 runs 文件夹
- comment:不指定 log_dir 时,文件夹后缀
- filename_suffix:event file 文件名后缀 ```python
提供创建event file的高级接口
class SummaryWriter(object): def init(self, log_dir=None, # event file 输出文件 comment=’’, # 不指定log_dir时,文件夹后缀 purge_step=None, max_queue=10, flush_secs=120, filename_suffix=’’) # event file文件名后缀
<a name="Donud"></a>### 21.2 add_scalar and add_histogram<a name="gfWcQ"></a>#### 1. add_scalar()add_scalar()<br />功能:记录标量主要方法:- tag:图像的标签名,图的唯一标识- scalar_value:要记录的标量;可以理解为 y 轴- **global_step:x 轴**注意事项:add_scalar() 只能记录一条曲线```python# 1. add_scalar# 记录标量add_scalar(tag, # 图像的标签名,图的唯一标识scalar_value, # 要记录的标量global_step=None, # x轴walltime=None)
2. add_scalars()
add_scalars()
功能:记录标量;可以记录多条曲线
主要参数:
- main_tag:该图的标签
- tag_scalar_dict:key 是变量的 tag ,value 是变量的值
# 1. add_scalars# 记录标量,可以记录多条曲线add_scalars(main_tag, # 该图的标签tag_scalar_dict, # key是变量的tag,value是变量的值global_step=None,walltime=None)
3. add_histogram()
add_histogram()
功能:统计直方图与多分位数折线图
主要参数:
- tag:图像的标签名,图的唯一标识
- values:要统计的参数
- global_step:y 轴
- bins:取直方图的 bins
# 3. add_histogram# 统计直方图与多分位数折线图add_histogram(tag, # 图像的标签名,图的唯一标识values, # 要统计的参数global_step=None, # y轴bins='tensorflow', # 取直方图的binswalltime=None)
21.2 模型指标监控
22. TensorBoard 使用(二)——TensorBoaed 的图像可视化方法
Content
- add_image and torchvision.utils.make_grid
- AlexNet 卷积核与特征图可视化
- add_graph and torchsummary


22.1 add_image and torchvision.utils.make_grid
4. add_image()
add_image()
功能:记录图像
主要参数:
- tag:图像的标签名,图的唯一标识
- img_tensor:图像数据,注意尺度
- global_step:x 轴
- dataformats:数据形式,CHW,HWC,HW
# 4. add_image# 记录图像add_image(tag, # 图像的标签名,图的唯一标识img_tensor, # 图像数据,注意尺度global_step=None, # x轴walltime=None,dataformats='CHW') # 数据形式,CHW/HWC/HW
torchvision.utils.make_grid
torchvision.utils.make_grid
功能:制作网格图像
主要参数:
- tensor:图像数据,BCH*W 形式
- nrow:行数(列数自动计算)
- padding:图像间距(像素单位)
- normalize:是否将像素值标准化
- range:标准化范围
- scale_each:是否单张图维度标准化
- pad_value:padding 的像素值
# torchvision.utils.make_grid# 制作网格图像make_grid(tensor, # 图像数据,B*C*H*W形式nrow=8, # 行数(列数自动计算)padding=2, # 图像间距(像素单位)normalize=False, # 是否将像素值标准化range=None, # 标准化范围scale_each=False, # 是否单张图维度标准化pad_value=0) # padding的像素值
22.2 AlexNet 卷积核与特征图可视化
22.3 add_graph and torchsummary
5. add_graph()
add_graph()
功能:可视化模型计算图
主要参数:
- model:模型,必须是 nn.Module
- input_to_model:输出给模型的数据
- verbose:是否打印计算图结构信息
注意事项:在 pytorch 1.2 版本中,add_graph() 有 bug
# 5. add_graph# 可视化模型计算图add_graph(model, # 模型,必须是nn.Moduleinput_to_model=None, # 输出给模型的数据verbose=False) # 是否打印计算图结构信息
torchsummary
torchsummary
功能:查看模型信息,便于调试
主要参数:
- model:pytorch 模型
- input_size:模型输入 size
- batch_size:batch size
- device:“cuda” or “cpu”
# torchsummary# 查看模型信息,便于调试summary(model, # pytorch模型input_size, # 模型输入sizebatch_size=-1, # batch sizedevice="cuda") # cuda/cpu
github: https://github.com/sksq96/pytorch-summary
23. Hook 函数与 CAM 可视化
Content
- Hook 函数概念
- Hook 函数与特征图提取
- CAM(Class Activation Map, 类激活图)
23.1 Hook函数概念
Hook函数机制:不改变主体,实现额外功能,像一个挂件
Hook函数:
torch.Tensor.register_hook(hook)
torch.nn.Module.register_forward_hook
- torch.nn.Module.register_forward_pre_hook
- torch.nn.Module.register_backward_hook
23.2 Hook 函数与特征图提取
1. torch.Tensor.register_hook(hook)
torch.Tensor.register_hook(hook)
功能:注册一个方向传播 hook 函数
hook 函数仅一个输入参数,为张量的梯度
# 1.# 注册一个反向传播的hook函数# hook(grad) -> Tensor or Nonetorch.Tensor.register_hook(hook)
记录梯度:
# ----------------------------------- 2 tensor hook 2 -----------------------------------import torchw = torch.tensor([1.], requires_grad=True)x = torch.tensor([2.], requires_grad=True)a = torch.add(w, x)b = torch.add(w, 1)y = torch.mul(a, b)a_grad = list()def grad_hook(grad):a_grad.append(grad)handle = a.register_hook(grad_hook)y.backward()# 查看梯度print("gradient:", w.grad, x.grad, a.grad, b.grad, y.grad)print("a_grad[0]: ", a_grad[0])handle.remove()output:"""gradient: tensor([5.]) tensor([2.]) None None Nonea_grad[0]: tensor([2.])"""
修改梯度:
# ----------------------------------- 2 tensor hook 2 -----------------------------------import torchw = torch.tensor([1.], requires_grad=True)x = torch.tensor([2.], requires_grad=True)a = torch.add(w, x)b = torch.add(w, 1)y = torch.mul(a, b)a_grad = list()def grad_hook(grad):grad *= 2return grad * 3handle = w.register_hook(grad_hook)y.backward()# 查看梯度print("w.grad: ", w.grad)handle.remove()output:"""w.grad: tensor([30.])"""
2. Module.register_forward_hook
Module.register_forward_hook
功能:注册 module 的前向传播 hook 函数;
参数:
- module: 当前网络层
- input:当前网络层输入数据
- output:当前网络层输出数据
# 2.# 注册module的前向传播hook函数# hook(module, input, output) -> None# module:当前网络层# input:当前网路层输入数据# output:当前网络层输出数据torch.nn.Module.register_forward_hook(hook)
通常使用 forward_hook 函数获得卷积输出的特征图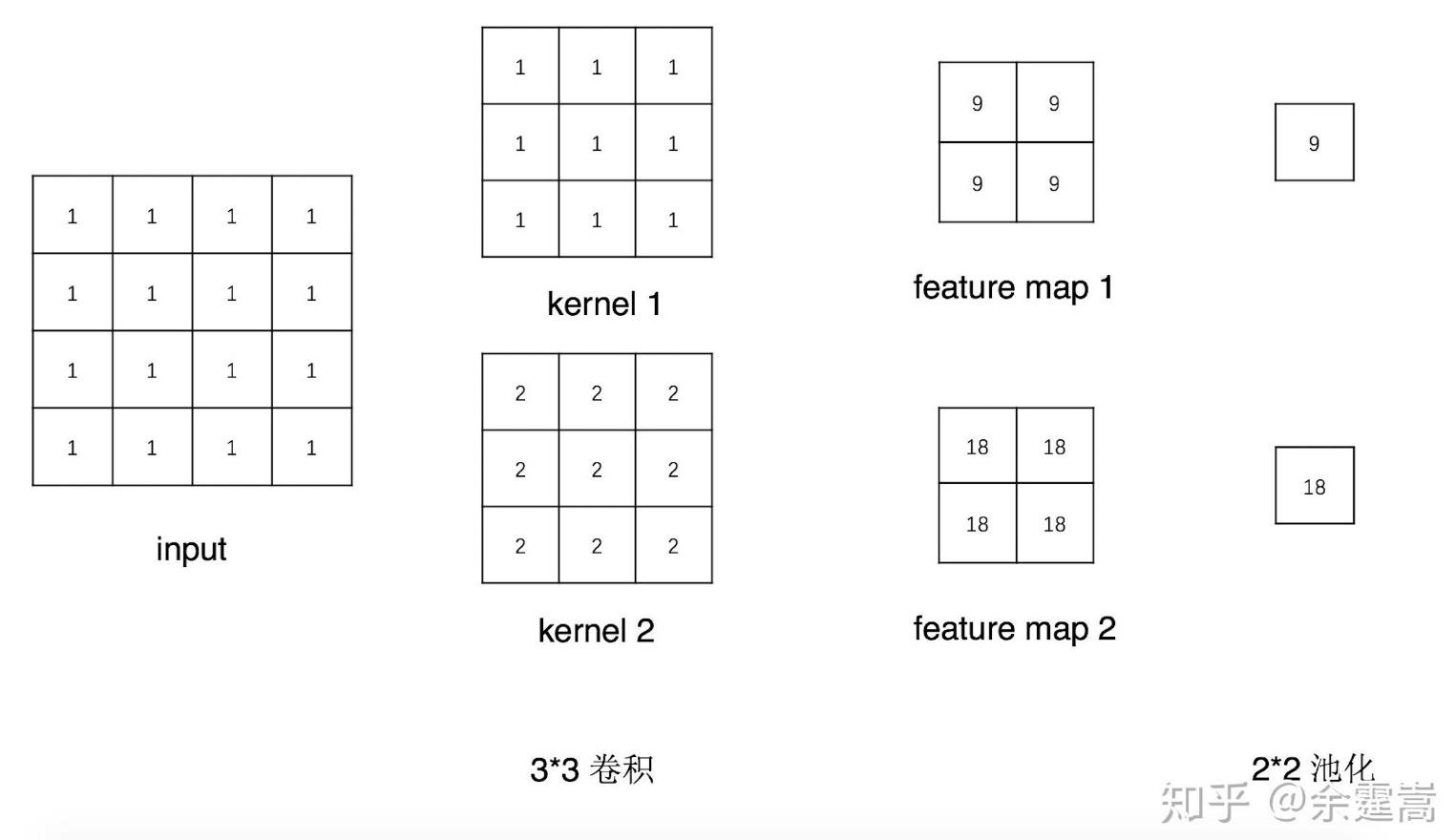
# ----------------------------- 3 Module.register_forward_hook-----------------------------class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 2, 3)self.pool1 = nn.MaxPool2d(2, 2)def forward(self, x):x = self.conv1(x)x = self.pool1(x)return xdef forward_hook(module, data_input, data_output):fmap_block.append(data_output)input_block.append(data_input)# 初始化网络net = Net()net.conv1.weight[0].detach().fill_(1)net.conv1.weight[1].detach().fill_(2)net.conv1.bias.data.detach().zero_()# 注册hookfmap_block = list()input_block = list()net.conv1.register_forward_hook(forward_hook)# inferencefake_img = torch.ones((1, 1, 4, 4)) # batch size * channel * H * Woutput = net(fake_img)# 观察print("output shape: {}\noutput value: {}\n".format(output.shape, output))print("feature maps shape: {}\noutput value: {}\n".format(fmap_block[0].shape, fmap_block[0]))print("input shape: {}\ninput value: {}".format(input_block[0][0].shape, input_block[0]))output:"""output shape: torch.Size([1, 2, 1, 1])output value: tensor([[[[ 9.]],[[18.]]]], grad_fn=<MaxPool2DWithIndicesBackward>)feature maps shape: torch.Size([1, 2, 2, 2])output value: tensor([[[[ 9., 9.],[ 9., 9.]],[[18., 18.],[18., 18.]]]], grad_fn=<ThnnConv2DBackward>)input shape: torch.Size([1, 1, 4, 4])input value: (tensor([[[[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]]]]),)"""
3. Module.register_forward_pre_hook
Module.register_forward_pre_hook
功能:注册 module 前向传播前的 hook函数
参数:
- module: 当前网络层
- input:当前网络层输入数据
# 3.# 注册module前向传播前的hook函数# hook(module, input) -> None# module:当前网络层# input:当前网路层输入数据torch.nn.Module.register_forward_pre_hook(hook)
# ------------------------------- 4 Module.register_pre_hook ------------------------------class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 2, 3)self.pool1 = nn.MaxPool2d(2, 2)def forward(self, x):x = self.conv1(x)x = self.pool1(x)return xdef forward_pre_hook(module, data_input):print("forward_pre_hook input:{}".format(data_input))# 初始化网络net = Net()net.conv1.weight[0].detach().fill_(1)net.conv1.weight[1].detach().fill_(2)net.conv1.bias.data.detach().zero_()# 注册hookfmap_block = list()input_block = list()net.conv1.register_forward_pre_hook(forward_pre_hook)# inferencefake_img = torch.ones((1, 1, 4, 4)) # batch size * channel * H * Woutput = net(fake_img)output:"""forward_pre_hook input:(tensor([[[[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]]]]),)"""
4. Module.register_backward_hook
Module.register_backward_hook
功能:注册 module 反向传播的 hook 函数
参数:
- module: 当前网络层
- grad_input:当前网络层输入梯度数据
- grad_output:当前网络层输出梯度数据
# 4.# 注册module反向传播的hook函数# hook(module, grad_input, grad_output) -> Tensor or None# module:当前网络层# grad_input:当前网络层输入梯度数据# grad_output:当前网络层输出梯度数据torch.nn.Module.register_backward_hook(hook)
# ---------------------------- 5 Module.register_backward_hook ----------------------------class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 2, 3)self.pool1 = nn.MaxPool2d(2, 2)def forward(self, x):x = self.conv1(x)x = self.pool1(x)return xdef backward_hook(module, grad_input, grad_output):print("backward hook input:{}".format(grad_input))print("backward hook output:{}".format(grad_output))# 初始化网络net = Net()net.conv1.weight[0].detach().fill_(1)net.conv1.weight[1].detach().fill_(2)net.conv1.bias.data.detach().zero_()# 注册hookfmap_block = list()input_block = list()net.conv1.register_backward_hook(backward_hook)# inferencefake_img = torch.ones((1, 1, 4, 4)) # batch size * channel * H * Woutput = net(fake_img)loss_fnc = nn.L1Loss()target = torch.randn_like(output)loss = loss_fnc(target, output)loss.backward()output:"""backward hook input:(None, tensor([[[[0.5000, 0.5000, 0.5000],[0.5000, 0.5000, 0.5000],[0.5000, 0.5000, 0.5000]]],[[[0.5000, 0.5000, 0.5000],[0.5000, 0.5000, 0.5000],[0.5000, 0.5000, 0.5000]]]]), tensor([0.5000, 0.5000]))backward hook output:(tensor([[[[0.5000, 0.0000],[0.0000, 0.0000]],[[0.5000, 0.0000],[0.0000, 0.0000]]]]),)"""
4. 特征图提取
23.3 CAM(Class Activation Map, 类激活图) and Grad-CAM
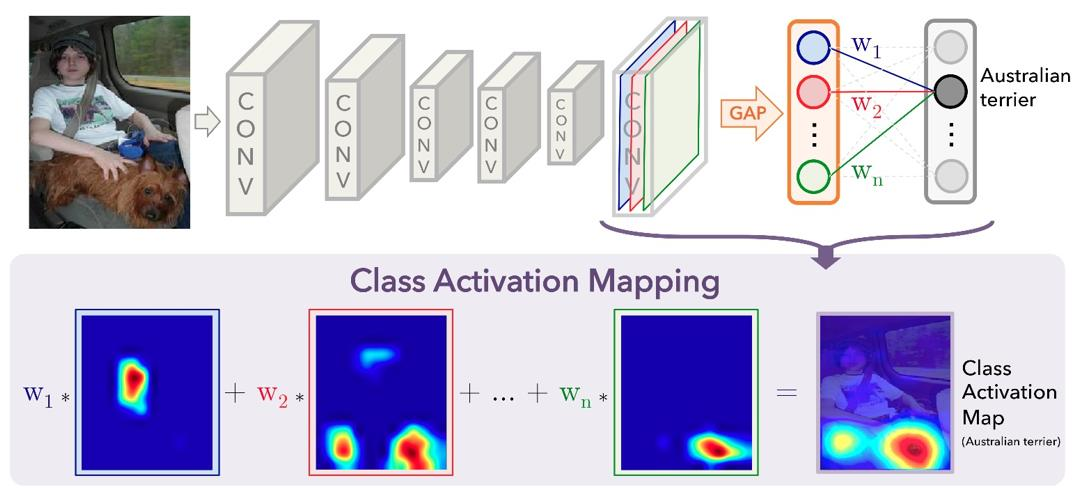
1. CAM
- CAM:类激活图,Class Activation Map
- Class Activation Map:在最后 Conv 层后、FC 层前增加 GAP 层,得到一组权重,与其对应特征图加权,得到 CAM
Grad-CAM:《Grad-CAM:Visual Explanations from Deep Networks via Gradient-based Localization》
2. Grad-CAM
- Grad-CAM:CAM 的改进,使用梯度作为特征图权重
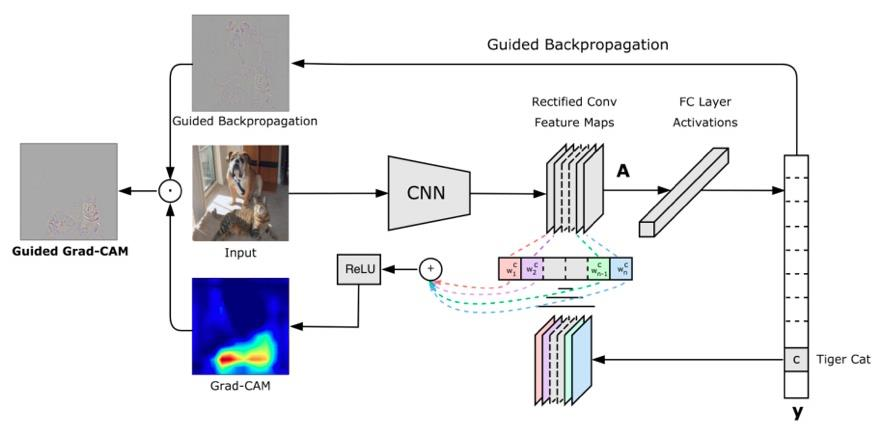
Grad-CAM:《Grad-CAM:Visual Explanations from Deep Networks via Gradient-based Localization》
3. CAM and Grad-CAM 实例


分析与代码:https://zhuanlan.zhihu.com/p/75894080
第六周
24. L1 与 L2 正则化

若有收获,就点个赞吧
0 人点赞
