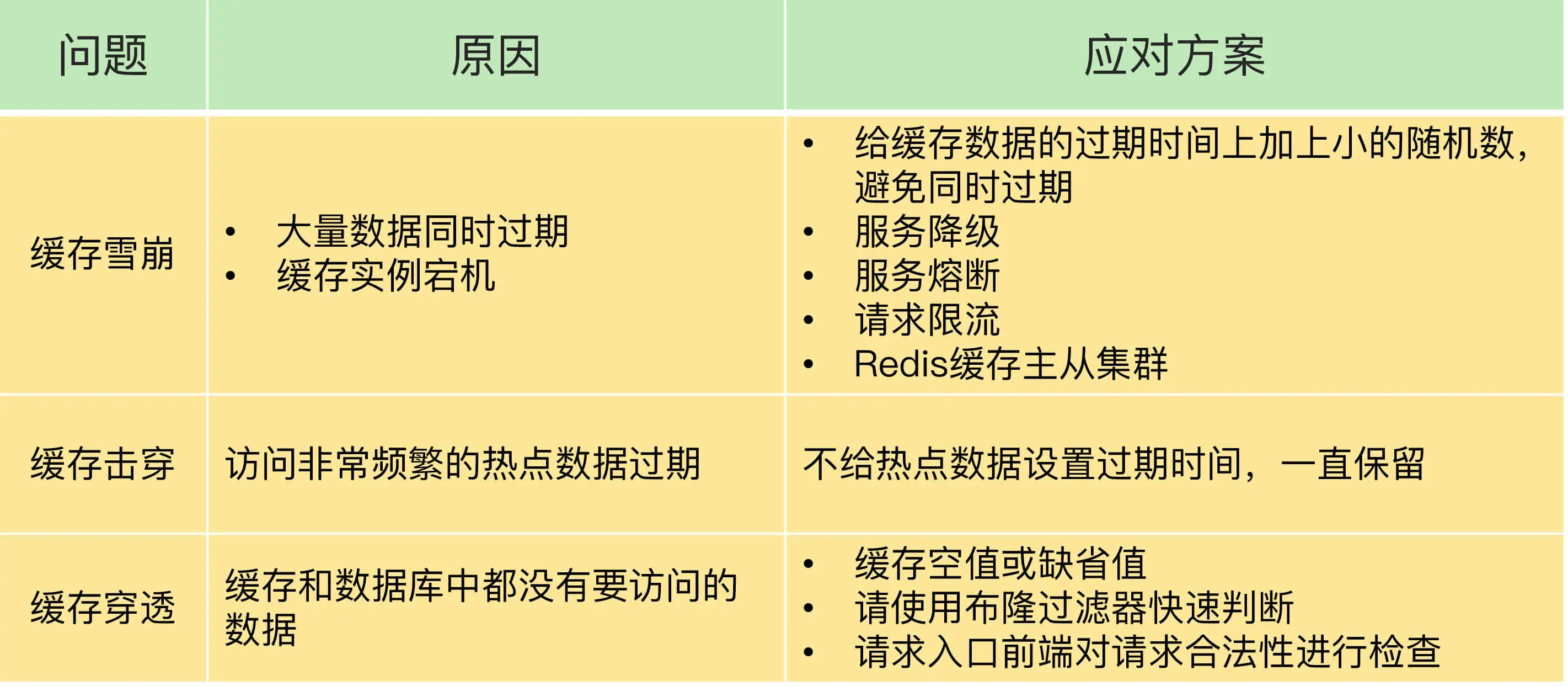
在使用缓存时,除了数据不一致问题,我们常常还会面临缓存异常的三个问题,分别是缓存雪崩、缓存击穿和缓存穿透。这三个问题一旦发生,会导致大量的请求积压到数据库层。如果请求的并发量很大,就会导致数据库宕机或是故障,产生很严重的生产事故。下面就讲解下这三个问题的表现、诱发原因以及解决方法。
缓存雪崩
缓存雪崩是指大量的应用请求无法在 Redis 缓存中进行处理,紧接着,应用将大量请求发送到数据库层,导致数据库层的压力激增。缓存雪崩一般是由两个原因导致的,应对方案也有所不同,我们一个个来看。
第一个原因是:缓存中有大量数据同时过期,导致大量请求无法得到处理。
具体来说,当数据保存在缓存中,并且设置了过期时间时,如果在某一个时刻,大量数据同时过期,此时,应用再访问这些数据的话,就会发生缓存缺失。紧接着,应用就会把请求发送给数据库,从数据库中读取数据。如果应用的并发请求量很大,那么数据库的压力也就很大,这会进一步影响数据库的其他正常业务请求处理。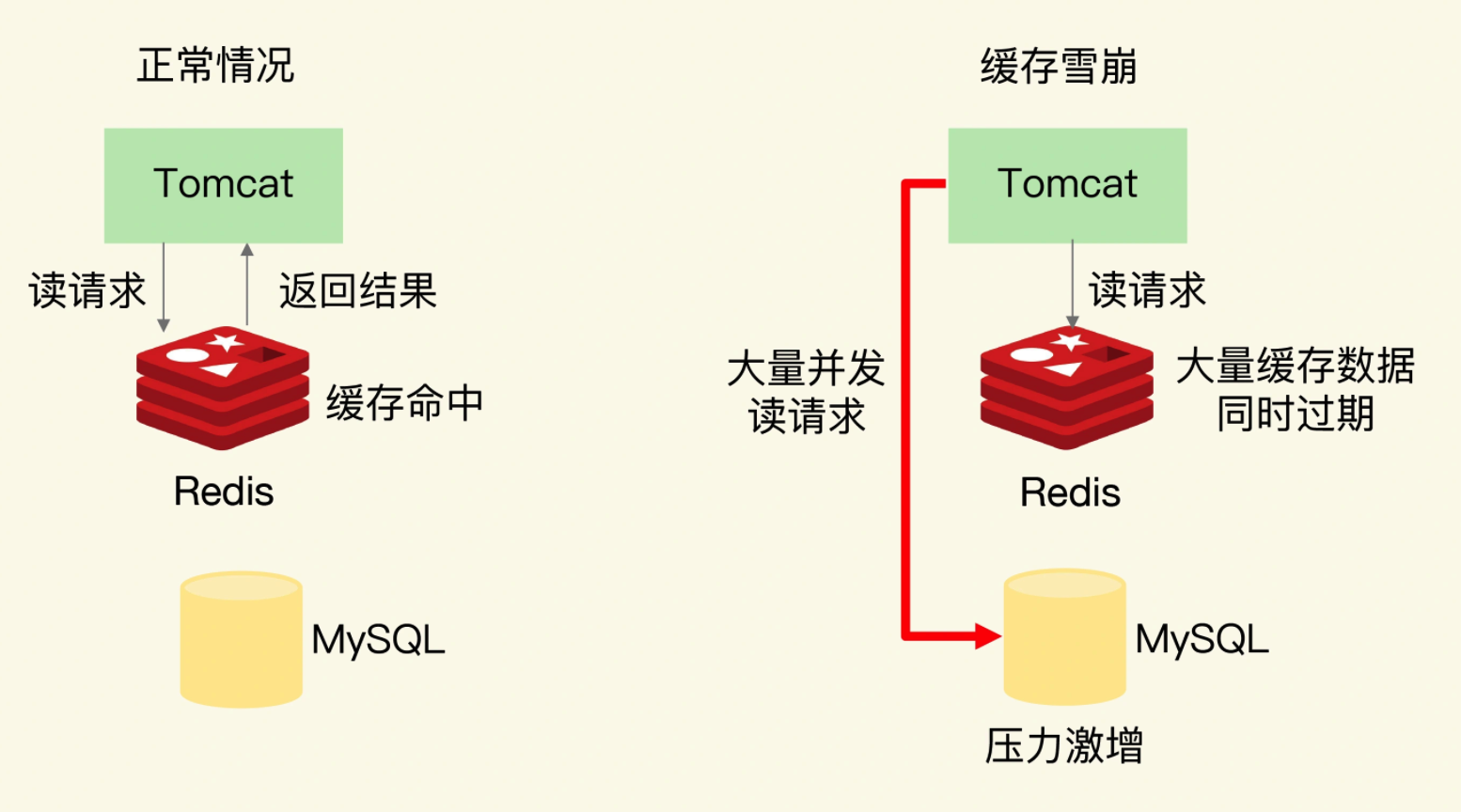
针对大量数据同时失效带来的缓存雪崩问题,我们可以避免给大量的数据设置相同的过期时间。如果业务层的确要求有些数据要同时失效,你可以在用 EXPIRE 命令给每个数据设置过期时间时,给这些数据的过期时间增加一个较小的随机数。这样,不同数据的过期时间有所差别,但差别又不会太大,既避免了大量数据同时过期,同时也保证了这些数据基本在相近的时间失效,仍然能满足业务需求。
第二个原因是:Redis 缓存实例发生故障宕机,导致大量请求无法得到处理。
当 Redis 缓存实例发生故障宕机了,无法处理请求,这就会导致大量请求一下子积压到数据库层,从而发生缓存雪崩。由于缓存雪崩,Redis 缓存失效,所以,数据库就可能要承受近十倍的请求压力,从而因为压力过大而崩溃。此时,因为 Redis 实例发生了宕机,我们需要通过其他方法来应对缓存雪崩了。我给你提供两个建议。
第一个建议,是在业务系统中实现服务熔断或请求限流机制。
所谓的服务熔断,是指在发生缓存雪崩时,为了防止引发连锁的数据库雪崩,甚至是整个系统的崩溃,我们暂停业务应用对缓存系统的接口访问。具体就是业务应用调用缓存接口时,缓存客户端并不把请求发给 Redis 缓存实例,而是直接返回,等到 Redis 缓存实例重新恢复服务后,再允许应用请求发送到缓存系统。这样一来,我们就避免了大量请求因缓存缺失,而积压到数据库系统,保证了数据库系统的正常运行。
在业务系统运行时,我们可以监测 Redis 缓存所在机器和数据库所在机器的负载指标,例如每秒请求数、CPU 利用率、内存利用率等。如果我们发现 Redis 缓存实例宕机了,而数据库所在机器的负载压力突然增加(例如每秒请求数激增),此时,就发生缓存雪崩了。大量请求被发送到数据库进行处理。我们可以启动服务熔断机制,暂停业务应用对缓存服务的访问,从而降低对数据库的访问压力。
服务熔断虽然可以保证数据库的正常运行,但是暂停了整个缓存系统的访问,对业务应用的影响范围大。为了尽可能减少这种影响,我们也可以进行请求限流。这里说的请求限流,就是指,我们在业务系统的请求入口前端控制每秒进入系统的请求数,避免过多的请求被发送到数据库。
使用服务熔断或是请求限流机制,来应对 Redis 实例宕机导致的缓存雪崩问题,是属于“事后诸葛亮”,也就是已经发生缓存雪崩了,我们使用这两个机制,来降低雪崩对数据库和整个业务系统的影响。但这些方法都是属于有损方案,在保证数据库和整体系统稳定的同时,会对业务应用带来负面影响。
我给你的第二个建议就是事前预防。
通过主从节点的方式构建 Redis 缓存高可靠集群。如果 Redis 缓存的主节点故障宕机了,从节点还可以切换成为主节点,继续提供缓存服务,避免了由于缓存实例宕机而导致的缓存雪崩问题。
缓存击穿
缓存击穿是指,针对某个访问非常频繁的热点数据的请求,无法在缓存中进行处理,紧接着,访问该数据的大量请求,一下子都发送到了后端数据库,导致了数据库压力激增,会影响数据库处理其他请求。缓存击穿的情况经常发生在热点数据过期失效时,如下图所示: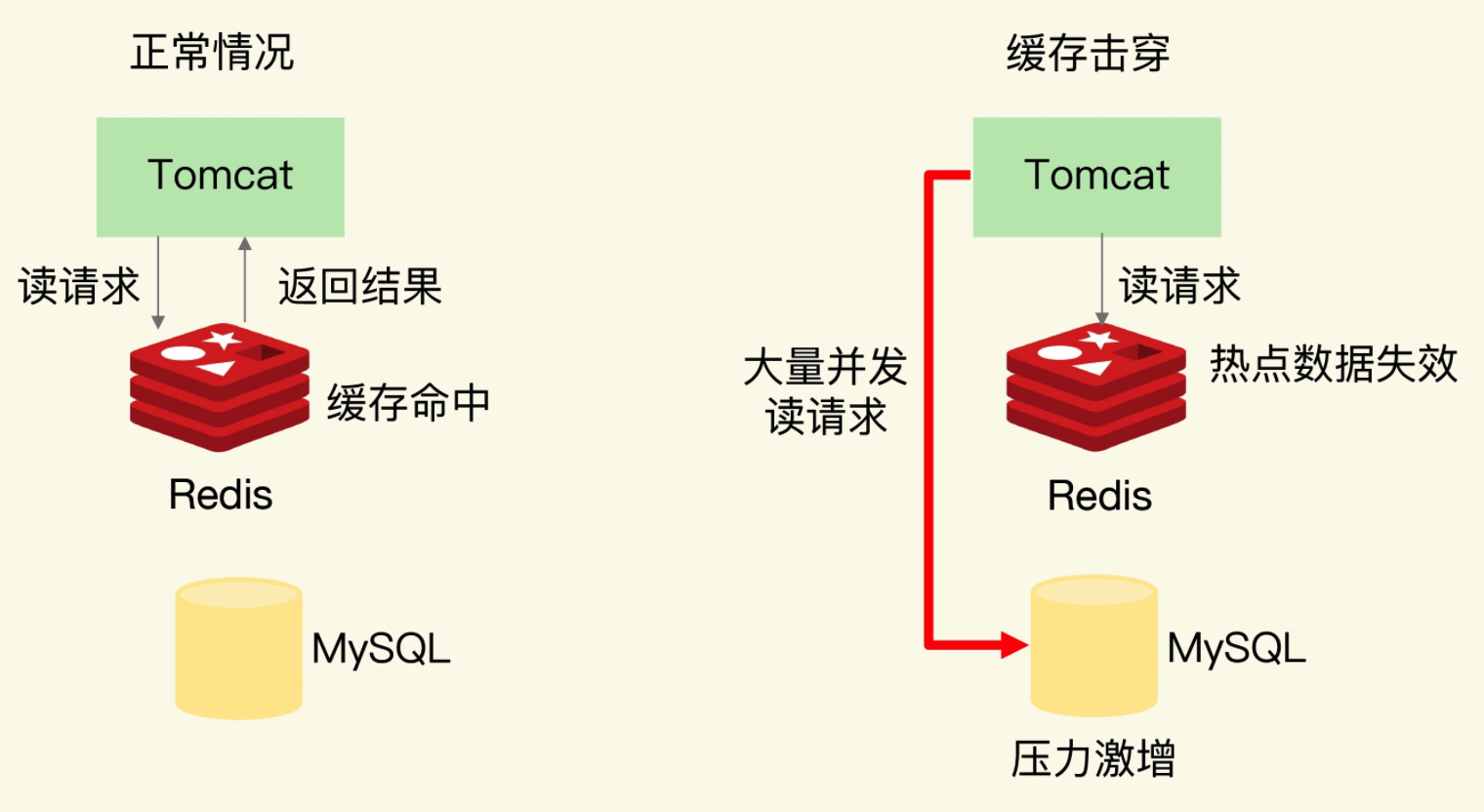
为了避免缓存击穿给数据库带来的激增压力,我们的解决方法也比较直接,对于访问特别频繁的热点数据,我们就不设置过期时间了。这样一来,对热点数据的访问请求,都可以在缓存中进行处理,而 Redis 数万级别的高吞吐量可以很好地应对大量的并发请求访问。如果这个热点 key 的内容会变,我们可以使用单独的后台线程去构建缓存。但在缓存重构期间,会出现数据不一致情况。
如果一定要设置过期时间,我们可以考虑使用锁机制来限制回源(过期后查询数据库)的并发。比如下面示例代码使用 Redisson 来获取一个基于 Redis 的分布式锁,客户端在查询数据库之前先尝试获取锁,这样,可以把回源到数据库的并发限制在 1:
@Autowiredprivate RedissonClient redissonClient;@GetMapping("right")public String right() {String data = stringRedisTemplate.opsForValue().get("hotsopt");if (StringUtils.isEmpty(data)) {RLock locker = redissonClient.getLock("locker");//获取分布式锁if (locker.tryLock()) {try {data = stringRedisTemplate.opsForValue().get("hotsopt");//双重检查,因为可能已经有一个B线程过了第一次判断,在等锁,然后A线程已经把数据写入了Redis中if (StringUtils.isEmpty(data)) {//回源到数据库查询data = getExpensiveData();stringRedisTemplate.opsForValue().set("hotsopt", data, 5, TimeUnit.SECONDS);}} finally {//别忘记释放,另外注意写法,获取锁后整段代码try+finally,确保unlock万无一失locker.unlock();}}}return data;}
在真实的业务场景下,不一定要这么严格地使用双重检查分布式锁进行全局的并发限制,因为这样虽然可以把数据库回源并发降到最低,但也限制了缓存失效时的并发。如果构建缓存的过程耗时较长,可能会存在死锁和线程阻塞的风险。可以考虑的方式是:
- 方案一,使用进程内的锁进行限制,这样每一个节点都可以以一个并发回源数据库;
- 方案二,不使用锁进行限制,而是使用类似 Semaphore 的工具限制并发数,比如限制为 10,这样既限制了回源并发数不至于太大,又能使得一定量的线程可以同时回源。
如何分散热点 Key 的缓存查询压力?
Redis 4.0 以上版本如果开启了 LFU 算法作为 maxmemory-policy,那么可以使用 —hotkeys 配合 redis-cli 命令行工具来探查热点 Key。此外,我们还可以通过 MONITOR 命令来收集 Redis 执行的所有命令,然后配合 redis-faina 工具来分析热点 Key、热点前缀等信息。
对于如何分散热点 Key 对于 Redis 单节点的压力的问题,我们可以为 Key 加上一定范围的随机数后缀,让一个 Key 变为多个相同的 Key,相当于对热点 Key 进行分区操作。然后查询的时候,也加一个同范围内的随机数,这样就分摊了读请求的压力。当然,我们也可以考虑再做一层短时间的本地缓存,结合 Redis 的 Keyspace 通知功能,来处理本地缓存的数据同步。
缓存穿透
缓存穿透是指要访问的数据既不在 Redis 缓存中,也不在数据库中,导致请求在访问缓存时,发生缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据。此时,应用也无法从数据库中读取数据再写入缓存,来服务后续请求,这样一来,如果应用持续有大量请求访问数据,就会同时给缓存和数据库带来巨大压力。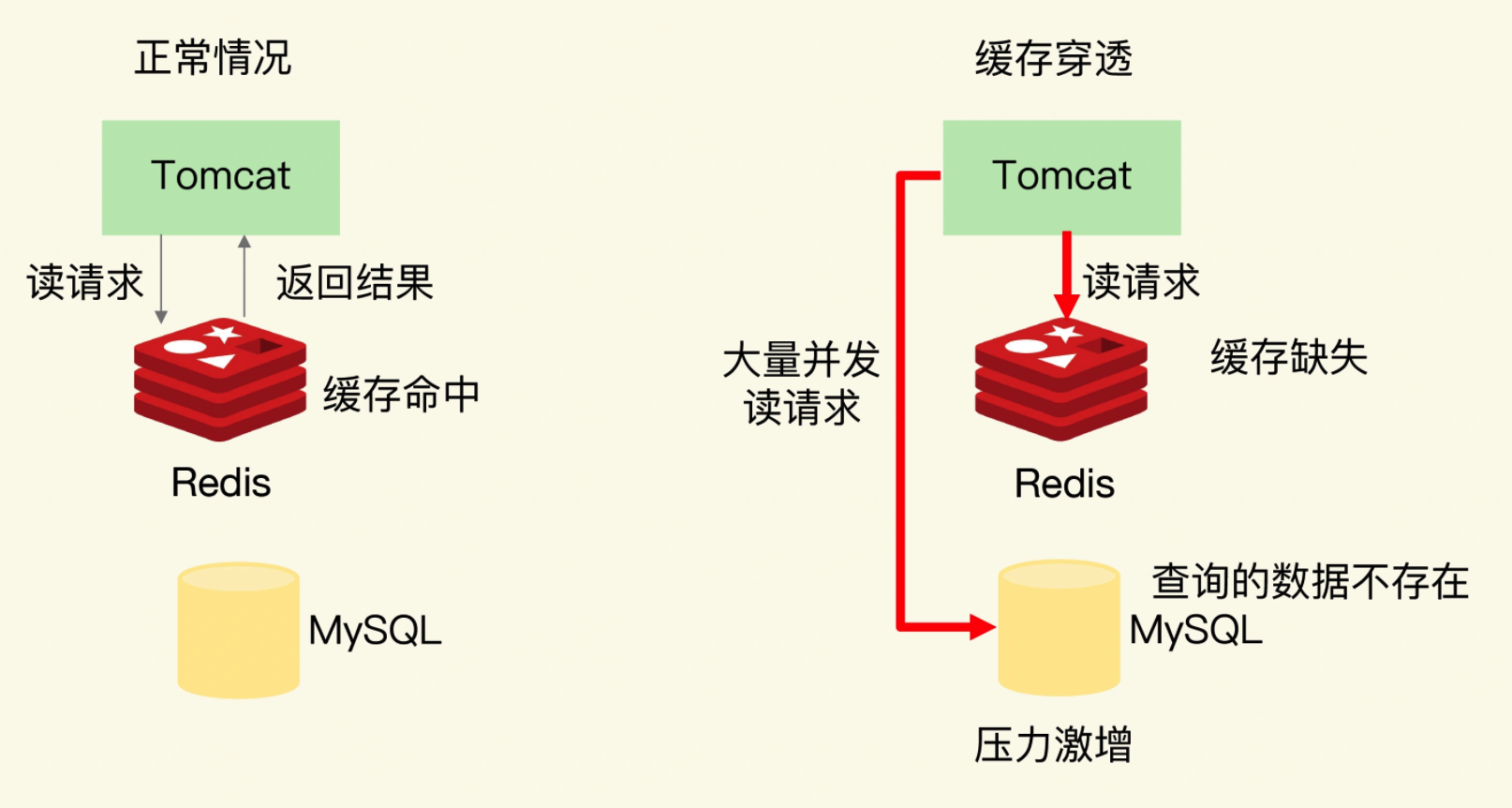
那么,缓存穿透会发生在什么时候呢?一般来说,有两种情况。
- 业务层误操作:缓存中的数据和数据库中的数据被误删除了,所以缓存和数据库中都没有数据;
- 恶意攻击:专门访问数据库中没有的数据。
为了避免缓存穿透的影响,我来给你提供三种应对方案。
第一种方案是,缓存空值或缺省值。
一旦发生缓存穿透,我们就可以针对查询的数据,在 Redis 中缓存一个空值或是和业务层协商确定的缺省值(例如,库存的缺省值可以设为 0)。紧接着,应用发送的后续请求再进行查询时,就可以直接从 Redis 中读取空值或缺省值,返回给业务应用了,避免了把大量请求发送给数据库处理,保持了数据库的正常运行。但这种方式可能会把大量无效的数据加入缓存中。
第二种方案是,使用布隆过滤器快速判断数据是否存在,数据不存在时避免从数据库中查询。
布隆过滤器是一种概率型数据库结构,由一个很长的二进制向量和一系列随机映射函数组成,可以用来快速判断某个数据是否存在。当我们想标记某个数据存在时(例如,数据已被写入数据库),布隆过滤器会通过三个操作完成标记:
- 首先,使用 N 个哈希函数,分别计算这个数据的哈希值,得到 N 个哈希值。
- 然后,我们把这 N 个哈希值对 bit 数组的长度取模,得到每个哈希值在数组中的对应位置。
- 最后,我们把对应位置的 bit 位设置为 1,这就完成了在布隆过滤器中标记数据的操作。
如果数据不存在(例如,数据库里没有写入数据),我们也就没有用布隆过滤器标记过数据,那么,bit 数组对应 bit 位的值仍然为 0。当需要查询某个数据时,我们先得到这个数据在 bit 数组中对应的 N 个位置。紧接着,我们查看 bit 数组中这 N 个位置上的 bit 值。只要这 N 个 bit 值有一个不为 1,这就表明布隆过滤器没有对该数据做过标记,所以,查询的数据一定没有在数据库中保存。但如果都为 1,也不意味着数据一定存在,因为布隆过滤器有一定的误判概率。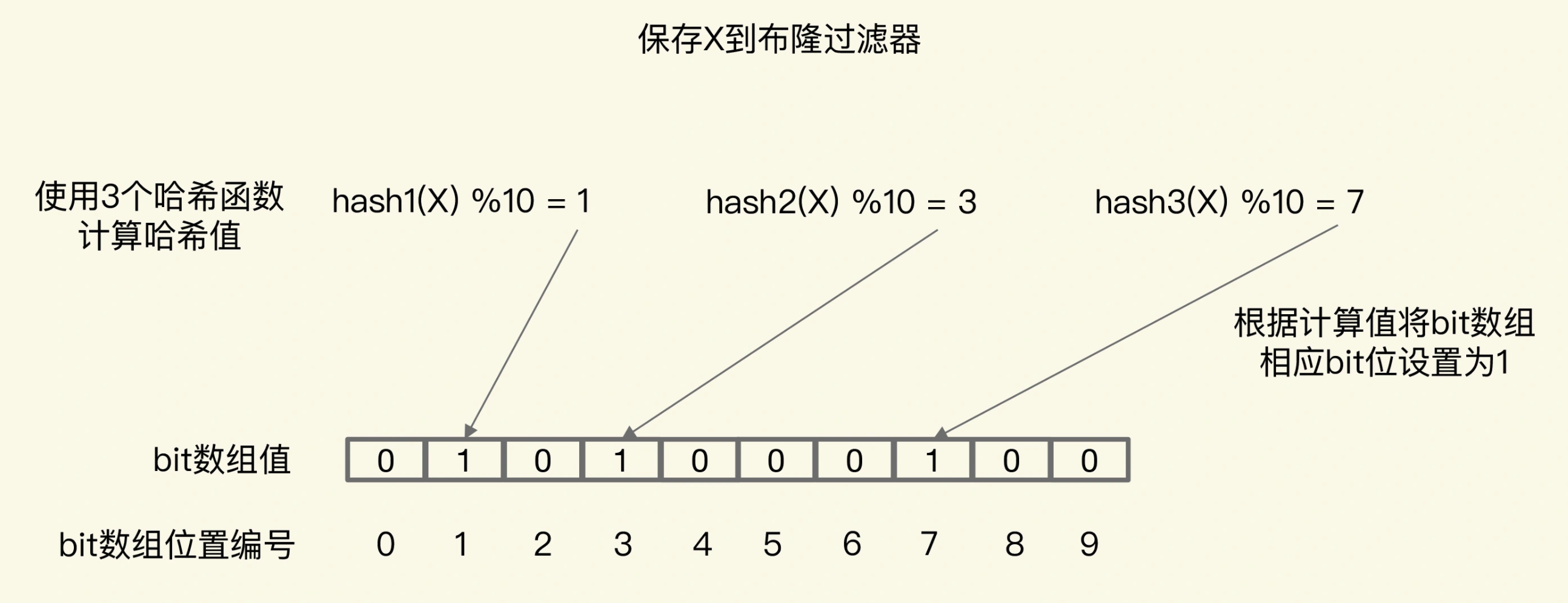
图中布隆过滤器是一个包含 10 个 bit 位的数组,使用了 3 个哈希函数,当在布隆过滤器中标记数据 X 时,X 会被计算 3 次哈希值,并对 10 取模,取模结果分别是 1、3、7。所以,bit 数组的第 1、3、7 位被设置为 1。当应用想要查询 X 时,只要查看数组的第 1、3、7 位是否为 1,只要有一个为 0,那 X 就肯定不在数据库中。
正是基于布隆过滤器的快速检测特性,我们可以在把数据写入数据库时,使用布隆过滤器做个标记。当缓存缺失后,应用查询数据库时,可以通过查询布隆过滤器快速判断数据是否存在。如果不存在,就不用再去数据库中查询了。这样一来,即使发生缓存穿透了,大量请求只会查询 Redis 和布隆过滤器,而不会积压到数据库,也就不会影响数据库的正常运行。
最后一种方案是,在请求入口的前端进行请求检测。
缓存穿透的一个原因是有大量的恶意请求访问不存在的数据,所以,一个有效的应对方案是在请求入口前端,对业务系统接收到的请求进行合法性检测,把恶意的请求(例如请求参数不合理、请求参数是非法值、请求字段不存在)直接过滤掉,不让它们访问后端缓存和数据库。这样一来,也就不会出现缓存穿透问题了。
跟缓存雪崩、缓存击穿这两类问题相比,缓存穿透的影响更大一些。从预防的角度来说,我们需要避免误删除数据库和缓存中的数据;从应对角度来说,我们可以在业务系统中使用缓存空值或缺省值、使用布隆过滤器,以及进行恶意请求检测等方法。
总结

若有收获,就点个赞吧
0 人点赞
