Elasticsearch 的读取分为 GET 和 Search 两种操作,这两种读取操作有较大的差异,GET、MGET 必须指定三元组:_index、_type、_id。也就是说,根据文档 id 从正排索引中获取内容。而 Search 不指定 _id,根据关键词从倒排索引中获取内容。
GET 流程
GET、MGET 流程涉及两个节点:协调节点和数据节点,流程如下图所示。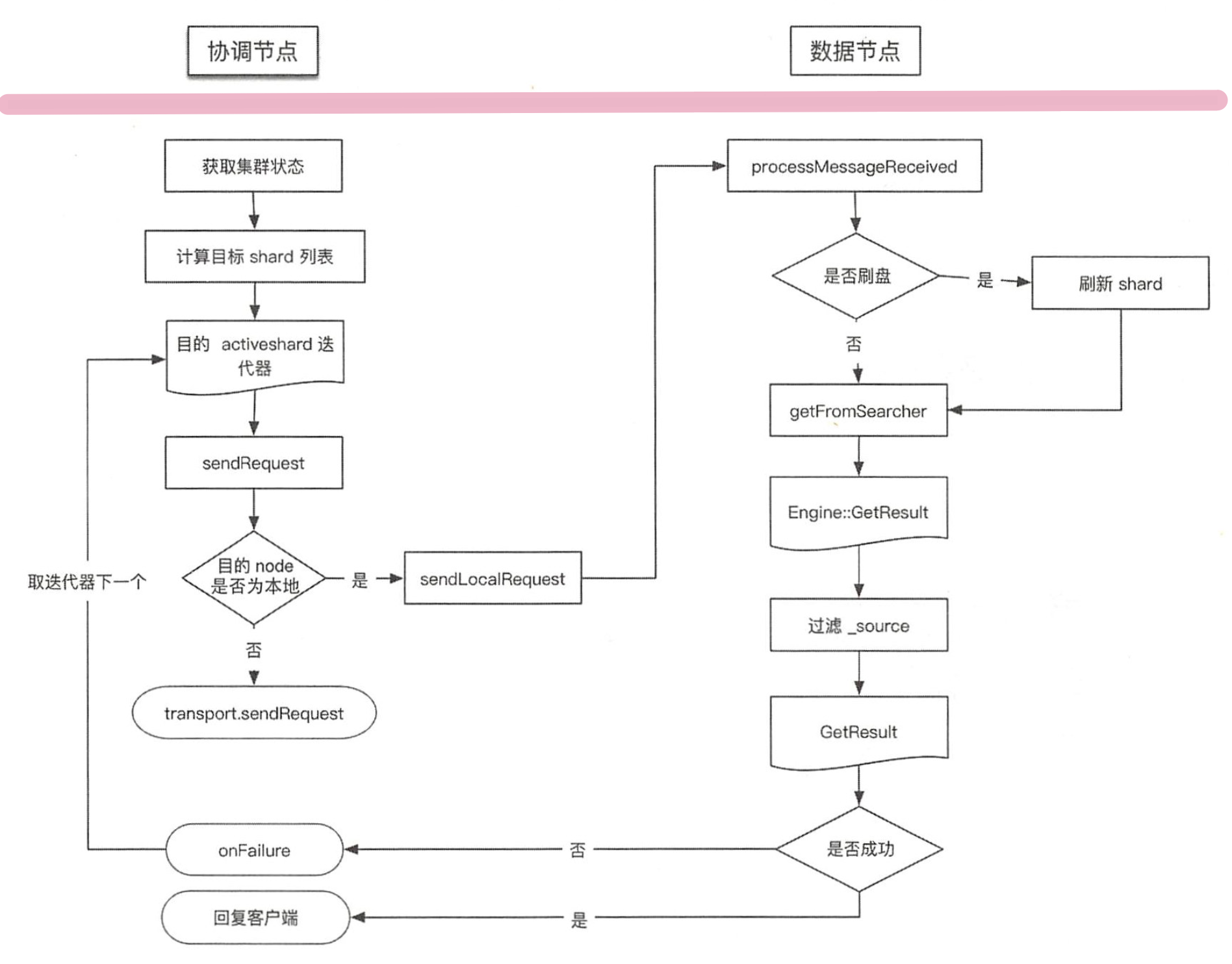
1. 协调节点
TransportSingleShardAction 类用来处理存在于一个单个分片上的读请求。协调节点负责将读请求转发到目标节点,如果请求执行失败,则尝试转发到其他节点读取。在收到读请求后,处理过程如下:
1)内容路由
准备集群状态、节点列表等信息。
根据内容路由算法计算目标 shardid,也就是文档应该落在哪个分片上。
计算出目标 shardid 后,结合请求参数中指定的优先级和集群状态确定目标节点,由于分片可能会存在多个副本,因此计算出的是一个列表。
private AsyncSingleAction(Request request, ActionListener<Response> listener) {// 1ClusterState clusterState = clusterService.state();nodes = clusterState.nodes();// 3this.shardIt = shards(clusterState, internalRequest);}
2)转发请求
作为协调节点向目标节点转发请求,如果目标是本地节点则直接读取数据。发送的具体过程如下:
- 在 TransportService 的 sendRequest 中检查目标节点是否是本地 node
- 如果是本地 node 则不发送到网络请求,直接从本地节点中获取对应文档信息;如果发送网络请求,则请求被异步发送,发送时会注册一个回调函数,等待处理 Response 直到超时
- 如果数据节点处理成功,则返回给客户端;如果数据节点处理失败,则进行重试,重试发送时会选择迭代器的下一个分片节点。
// 本地请求private void sendLocalRequest(long requestId, final String action,final TransportRequest request,TransportRequestOptions options)// 网络请求public final <T extends TransportResponse> void sendRequest(final Transport.Connection connection, final String action,final TransportRequest request,final TransportRequestOptions options,TransportResponseHandler<T> handler) {asyncSender.sendRequest(connection, action, request, options, handler);}
2. 数据节点
数据节点接收协调节点请求的入口为:TransportSingleShardAction 内部类 ShardTransportHandler 的 messageReceived 方法。
private class ShardTransportHandler implements TransportRequestHandler<Request> {@Overridepublic void messageReceived(final Request request, final TransportChannel channel) throws Exception {Response response = shardOperation(request, request.internalShardId);channel.sendResponse(response);}}
在 shardOperation() 方法中先检查是否需要 refresh,然后底层会调用 Engine 这个抽象层来读取数据。根据 _type、_id、 DocumentMapper 等信息获取数据,并对指定的 _field、_source 进行过滤,然后返回过滤后的数据。
GET API 默认是实时(realtime)的,即写入后可以立刻读取,但也仅限于 GET、MGET 操作。在 5.x 版本之前,GET、MGET 的实时读取依赖于从 translog 中读取实现,在 5.x 版本后改为只从 Lucene 中读取,实时机制依赖 refresh 实现,因此系统对实时读取的支持会对写入速度有负面影响。
当更新文档时,在 ES 内部需要先 GET 再写(写的时候先删再增),为了保证一致性会将 realtime 选项强制设置为 true 并且不可修改。因此更新操作可能会导致 refresh 过程生成新的 Lucene 分段。
Search 流程
GET 操作只能对单个文档进行处理,由 _index、_type 和 _id 三元组来确定唯一文档。但搜索需要一种更复杂的模型,因为不知道查询会命中哪些文档,找到匹配文档仅仅完成了搜索流程的一半,因为多分片中的结果必须组合成单个排序列表。
集群的任意节点都可以接收搜索请求,接收客户端请求的节点称为协调节点。在协调节点,搜索任务被执行成一 个两阶段过程,即 query then fetch。真正执行搜索任务的节点称为数据节点。需要两个阶段才能完成搜索的原因是,在查询的时候不知道文档位于哪个分片,因此索引的所有分片都要参与搜索(Query 阶段),然后协调节点将结果进行合并,再根据文档 ID 获取(Fetch 阶段)文档内容。
例如,有 5 个分片,查询返回前 10 个匹配度最高的文档,那么每个分片(可能是主分片也可能是副分片)都查询出当前分片的 TOP10,协调节点再将 5×10=50 的结果再次排序,返回最终 TOP10 的结果给客户端。但一次搜索请求只会命中所有分片副本中的一个,协调节点会在某个分片的所有副本(主、副)中做负载均衡。
1. 协调节点
在初始查询阶段,查询请求会广播到索引中每一个分片副本(主分片或副分片)上。每个分片在本地执行搜索并构建一个匹配文档的优先队列,然后将优先队列返回给协调节点。优先队列是一个存有 topN 匹配文档的有序列表,队列的大小等于分页参数 from+size 的值,列表内容只包含文档的 ID 和排序值。
协调节点的 Query 阶段如下图所示: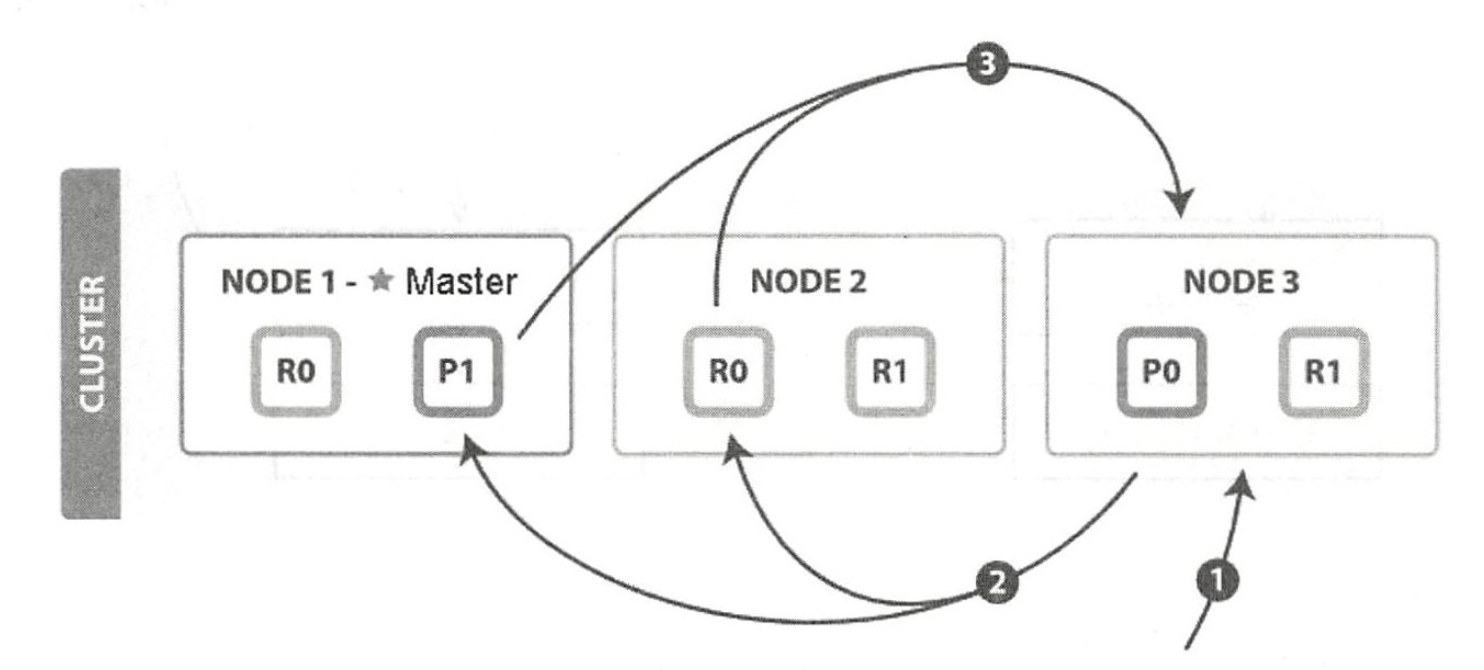
QUERY_THEN_FETCH 搜索类型的查询阶段步骤如下:
- 客户端发送 search 请求到 NODE 3。
- Node 3 将查询请求转发到索引的每个主分片或副分片中。每个分片在本地执行查询并进行打分,然后添加结果到大小为 from+ size 的本地有序优先队列中。
- 每个分片返回各自优先队列中所有文档的 ID 和排序值给协调节点,协调节点合并这些值到自己的优先队列中,最终产生一个全局排序后的列表。
协调节点广播查询请求到所有相关分片时,可以是主分片或副分片,协调节点将在之后的请求中轮询所有的分片副本来分摊负载。协调节点不会对搜索请求的内容进行解析,无论搜索什么内容,只看本次搜索需要命中哪些 shard,然后针对每个特定 shard 选择一个副本,转发搜索请求并等待响应。
Query 阶段只是知道了要取哪些数据(文档 ID),但是还没有取到具体的数据(文档内容),这就是 Fetch 阶段要做的事情。Fetch 阶段的目的是通过文档 ID 获取完整的文档内容。
协调节点的 Fetch 阶段如下图所示: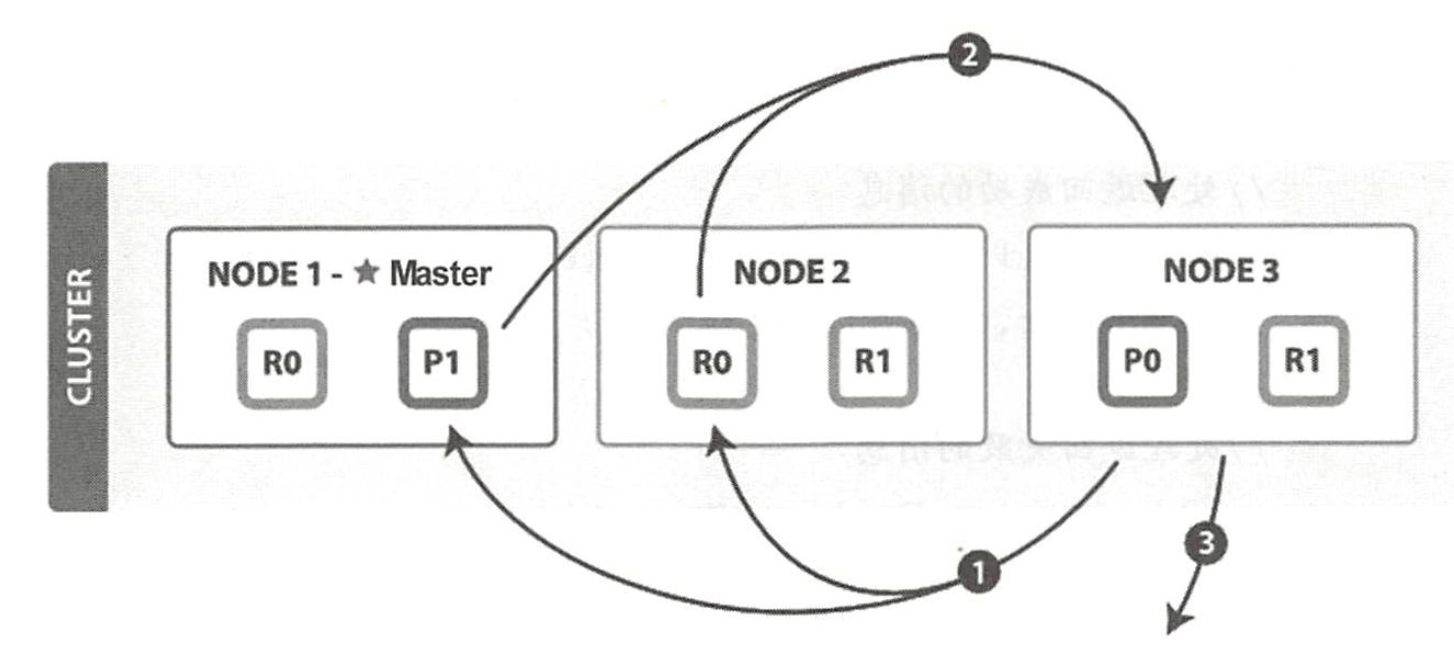
Fetch 阶段步骤如下:
- 协调节点向相关 NODE 发送 MGET 请求批量获取文档
- 分片所在节点向协调节点返回数据
- 协调节点等待所有文档被取得,然后返回给客户端
协调节点首先决定哪些文档 “确实” 需要被取回,例如,如果查询指定了 fom=90,size=10,则协调节点对 Query 阶段返回的数据排序后,只把第 91 个开始的 10 个结果取回。所以为了避免在协调节点中创建的优先队列过大,应尽量控制分页深度。
2. 数据节点
数据节点响应 Query 请求的过程就是执行查询,然后返回 Response。源码入口为 SearchTransportService 的 registerRequestHandler 方法。
在查询时,会先判断是否允许使用 cache,通过 index.requests.cache.enable 配置决定,默认为 true。但注意每次分页的请求都是一次重新搜索的过程,而不是从第一次搜索的结果中获取。因为在互联网应用中,人们基本只看前几页,很少深度分页,所以重新执行一次搜索很快;如果缓存第一次搜索结果等待翻页命中,则这种缓存的代价较大而意义却不大,因此不如重新执行一次搜索。
当调用 Lucene 完成检索后,在本阶段会一并执行聚合操作。慢查询 Query 日志的统计时间就是统计的数据节点执行 Query 阶段的处理时间。数据节点响应 Fetch 请求的过程就是基于文档 ID 执行 Fetch 查询,然后返回 Response。慢查询 Fetch 日志的统计时间就是统计的数据节点执行 Fetch 阶段的处理时间。
Query Then Fatch 的潜在问题
性能问题
- 每个分片上需要查询的文档个数:form+size
- 最终协调节点需要处理:number_of_shard * (from + size)
- 深度分页
相关性算分
每个分片都基于自己的分片上的数据进行相关度计算,这会导致打分偏离的情况,特别是数据量很少时。相关性算分在分片之间是相互独立的,当文档总数很少的情况下,如果主分片大于一,主分片越多相关性算分越不准。当数据量足够大时,只要保证文档均匀分散在各个分片上,结果一般就不会出现偏差。
如果我们想得到精确的算分,可以在搜索的 URL 中指定参数:search_type=dfs_query_then_fetch。该参数会到每个分片把各分片的词频和文档频率进行搜集,然后完整的进行一次相关性算分,不过这个操作也会耗费更多的 CPU 和内存,执行性能低下,一般不建议使用。
搜索速度优化
1. 为文件系统 cache 预留足够内存
在一般情况下,应用程序的读写都会被操作系统 “cache”(除了 direct 方式),命中 cache 可以降低对磁盘的直接访问频率。搜索很依赖对系统 cache 的命中,如果某个请求需要从磁盘读取数据,则一定会产生相对较高的延迟。应该至少为系统 cache 预留一半的可用物理内存,更大的内存有更高的 cache 命中率。
2. 使用更快的硬件
写入性能对 CPU 的性能更敏感,而搜索性能在一般情况下更多的是在于 I/O 能力,使用 SSD 会比旋转类存储介质好得多。尽量避免使用 NFS 等远程文件系统,如果 NFS 比本地存储慢 3 倍,则在搜索场景下响应速度可能会慢 10 倍左右。这可能是因为搜索请求有更多的随机访问。
如果你使用旋转介质(如机械硬盘),尝试获取尽可能快的硬盘。使用 RAID0 是提高硬盘速度的有效途径,对机械硬盘和 SSD 来说都是如此。因为没有必要使用镜像或其它 RAID 变体,Elasticsearch 在自身层面通过副本机制已经提供了备份能力,所以不需要利用磁盘的备份功能,同时如果使用磁盘备份功能的话,对写入速度有较大的影响。
3. 文档模型
为了让搜索时的成本更低,文档应该合理建模。特别是应该避免 join 操作,嵌套(nested)会使查询慢几倍,父子(parent-child)关系可能使查询慢数百倍。因此,如果可以通过非规范化(denormalizing)文档来回答相 同的问题,则可以显著地提高搜索速度。最好结合 profile、explain API 分析慢查询,持续优化数据模型。
有些字段的内容是数值,但并不意味着其总是应该被映射为数值类型,例如,对于一些可枚举的标识符,将它们映射为 keyword 可能会比 integer 或 long 更好,因为能够直接利用动态索引。并且尽量将数据先行计算后保存到 Elasticsearch 中,避免查询时使用 script 计算。尽量使用 Filter Context,利用缓存机制减少不必要的算分消耗。严禁使用 * 开头通配符 term 查询,性能会非常差。
4. 为只读索引执行 force merge
为不再更新的只读索引执行 force merge,将 Lucene 索引合并为单个分段,可以提升查询速度。当一个 Lucene 索引存在多个分段时,每个分段会单独执行搜索再将结果合并,将只读索引强制合并为一个 Lucene 分段不仅可以优化搜索过程,对索引恢复速度也有好处。
基于日期进行轮询的索引的旧数据一般都不会再更新。此前的章节中说过,应该避免持续地写一个固定的索引直到它变得巨大无比,而应该按一定的策略,例如,每天生成一个新的索引,然后用别名关联,或者使用索引通配符。这样,可以每天选一个时间点对昨天的索引执行 force merge、Shrink 等操作。
5. 预热全局序号
ES 内部对 terms 聚合的实现有两种不同的机制:
- 通过直接使用字段值来聚合每个桶的数据(map)
- 通过使用字段的全局序号并为每个全局序号分配一个 bucket(global ordinals)
ES 使用 global ordinals 作为 keyword 字段的默认聚合选项,它使用全局序号动态地分配 bucket。全局序号用一个数值来代表字段中的字符串值,然后为每一数值分配一个 bucket。这需要一个对 global ordinals 和 bucket 的构建过程。默认情况下,它们被延迟构建,因为 ES 不知道哪些字段将用于 terms 聚合,哪些字段不会。
如果我们在业务上可以提前确定,则可以通过配置索引 Mapping 时在对应 keyword 字段上开启预先加载全局序数的开关:
{"mappings": {"type": {"properties": {"foo": {"type": "keyword","eager_global_ordinals": true}}}}}
6. 调节 batched_reduce_size
该字段是搜索请求中的一个参数。默认情况下,聚合操作在协调节点需要等所有的分片都取回结果后才执行,使用 batched_reduce_size 参数可以不等待全部分片返回结果,而是在指定数量的分片返回结果之后就可以先处理一部分。这样可以避免协调节点在等待全部结果的过程中占用大量内存,避免极端情况下可能导致的 OOM。该字段的默认值为 512,从 ES 5.4 版本开始支持。
7. 限制搜索请求的分片数
一个搜索请求涉及的分片数量越多,协调节点的 CPU 和内存压力就越大。默认情况下,ES 会拒绝超过 1000 个分片的搜索请求。我们应该更好地组织数据,让搜索请求的分片数更少。如果想调节这个值,则可以通过
action.search.shard_count 配置项进行修改。
虽然限制搜索的分片数并不能直接提升单个搜索请求的速度,但协调节点的压力会间接影响搜索速度,例如,占用更多内存会产生更多的 GC 压力导致更多的 stop-the-world 时间,从而间接影响了协调节点的性能。
8. 自适应副本选择(AES)机制
为了充分利用计算资源和负载均衡,协调节点将搜索请求轮询转发到分片的每个副本,轮询策略是负载均衡过程中最简单的策略,任何一个负载均衡器都具备这种基础的策略,缺点是不会考虑后端实际系统压力和健康水平。例如,一个分片的三个副本分布在三个节点上,其中 Node2 可能因为长时间 GC、磁盘 I/O 过高、网络带宽跑满等原因处于忙碌状态,如下图所示。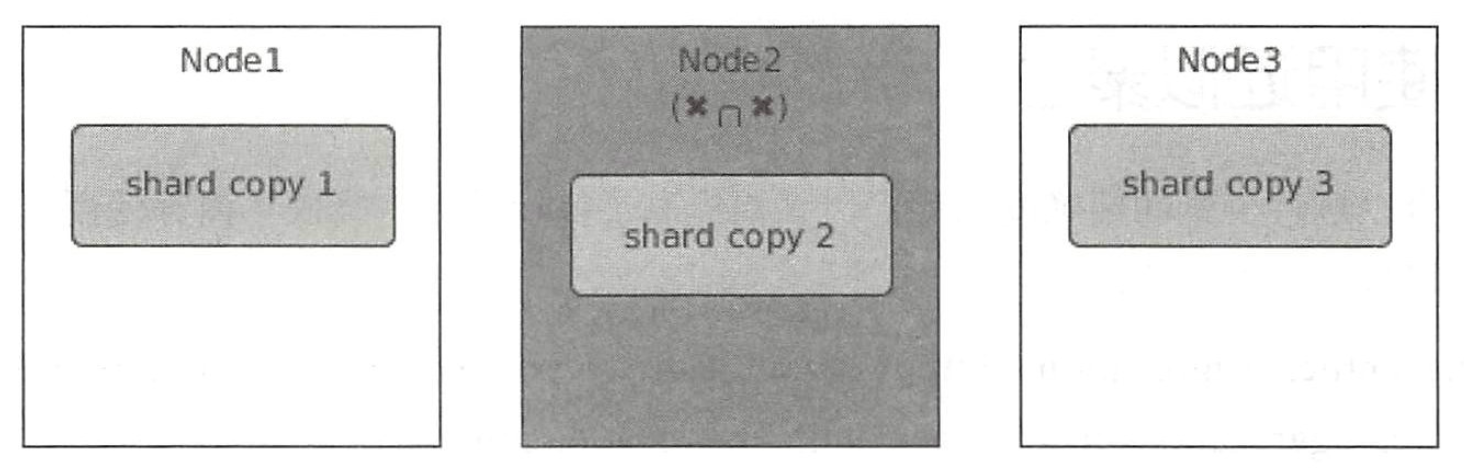
如果搜索请求被转发到副本 2,则会看到相对于其他分片来说,副本 2 有更高的延迟。由于副本 2 的高延迟会使得整个搜索请求产生长尾效应。
ES 希望这个过程足够智能,出现这种情况能够自动将请求路由到其他数据副本,直到该节点恢复到足以处理更多搜索请求的程度。在 ES 中,这个过程称为 “自适应副本选择”。
ES 的 ARS 实现基于这样一个公式:对每个搜索请求,将分片的每个副本进行排序,以确定哪个最可能是转发请求的最佳副本。与轮询方式向分片的每个副本发送请求不同,ES 会选择最佳副本并将请求路由到那里。ARS 功能从 ES 6.1 版本开始支持,但是默认关闭。从 ES 7.0 开始,ARS 将默认开启。

若有收获,就点个赞吧
0 人点赞
