在 InnoDB 存储引擎中,主键是行唯一的标识符。通常应用程序中行记录的插入顺序是按照主键递增的顺序进行插入的。因此,插入聚簇索引(Primary Key)一般是顺序的,即不需要进行磁盘的随机读取。因此,对于这类情况下的插入操作,速度是非常快的。但是不可能每张表上只有一个聚簇索引,更多情况下,一张表上会有多个二级索引,这样在进行插入操作时,数据页的存放还是按主键进行顺序存放的,但是对于二级索引叶子节点的插入不再是顺序的了,这时就需要离散地访问二级索引页,由于随机读取的存在就导致了插入操作性能下降。
为此,InnoDB 存储引擎设计了 Insert Buffer,当要更新一个数据页时(插入、更新、删除),如果要更新的数据页已经在内存中就直接更新,而如果不在内存中的话,在不影响数据一致性的前提下,InnoDB会将这些更新操作缓存在 Insert Buffer 中,这样就不需要从磁盘中读入这个数据页,避免了随机读取磁盘的 IO 消耗。等到下次查询需要访问这个数据页的时候,再将数据页读入内存,然后执行 Insert Buffer 中与这个页有关的操作。通过这种方式就能保证这个数据页逻辑的正确性。
Insert Buffer 是可以持久化的数据。它在内存中有拷贝,也会被写入到磁盘上。将 Insert Buffer 中的操作应用到原数据页,得到最新结果的过程称为 merge。除了访问这个数据页会触发 merge外,系统有后台线程会定期的执行 merge 操作。在数据库正常关闭时,也会执行 merge 操作。
显然,如果能够将更新操作先记录在 Insert Buffer 中的话,可以减少随机读磁盘的 IO 消耗,语句的执行速度会得到明显的提升。而且,数据读入内存是需要占用 Buffer Pool 的,所以这种方式还能够避免占用内存,提高内存的利用率。
使用条件
如果想要使用 Insert Buffer 需要同时满足以下两个条件:
- 索引是辅助索引(Secondary Index)
- 索引不是唯一(unique)的
对于唯一索引来说,所有的更新操作都要先判断这个操作是否违反唯一性约束。而这必须要将数据页读入到内存中才能判断。如果都已经读入到内存了,那直接更新内存会更快,就没必要使用 Insert Buffer 了。因此,唯一索引的更新就不能使用 Insert Buffer,实际上也只有普通索引可以使用。
Change Buffer
InnoDB 从 1.0.x 版本开始引入了 Change Buffer,可将其视为 Insert Buffer 的升级。从该版本开始,InnoDB 存储引擎可以对 DML 操作——INSERT、DELETE、UPDATE 都进行缓冲,他们分别是:Insert Buffer、Delete Buffer、Purge Buffer。当然和之前 Insert Buffer 一样,Change Buffer 适用对象依然是非唯一的辅助索引。
InnoDB 存储引擎提供了 innodbchange buffering 参数用来开启各种 Buffer 的选项。该参数可选值为:inserts、deletes、purges、changes、all、none。其中 inserts、deletes、purges 分别对应上面这三种情况。changes 表示启用 inserts 和 deletes;all 表示启用所有;none 表示都不启用。该参数默认值为 all。
由于 Change Buffer 使用的还是 Buffer Pool 里面的内存,因此不能无限增大。从 InnoDB 1.2.x 版本开始,可以通过参数 innodb_change_buffer_max_size 来控制 Change Buffer 最大使用内存的数量,该参数值默认为 25,表示最多使用 1/4 的缓冲池内存空间。需要注意的是,该参数的最大有效值为 50。
用户可以通过命令 SHOW ENGINE INNODB STATUS 来查看 Change Buffer 的信息: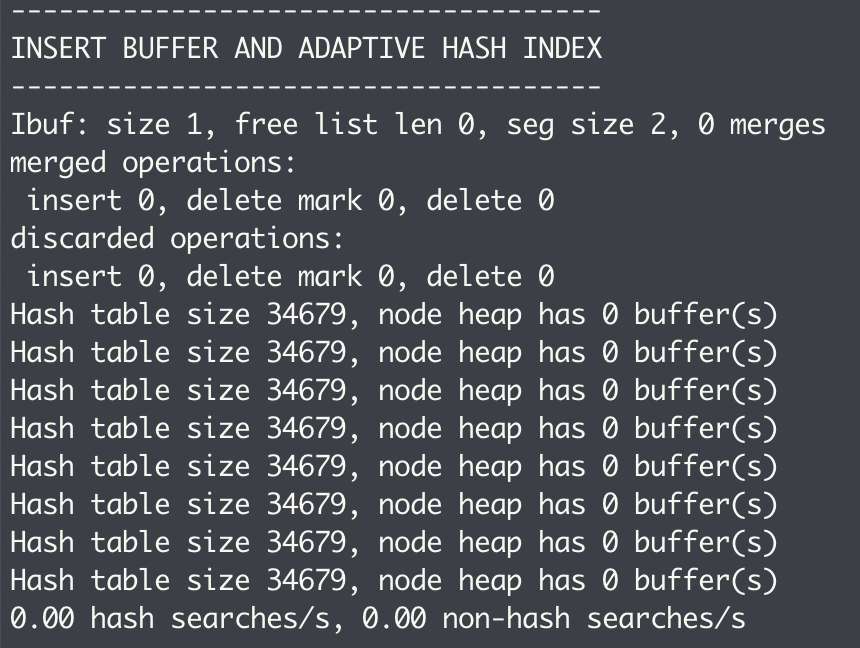
- size:代表了已经合并记录页的数量
- free list len:代表了空闲列表的长度
- seg size:显示了当前 Insert Buffer 的大小为 2×16KB
- merges:代表合并的次数,也就是实际读取页的次数
- merged operations 和 discarded operation 展示了 Change Buffer 中每个操作的次数。
- insert 表示 Insert Buffer
- delete mark 表示 Delete Buffer
- delete 表示 Purge Buffer
- discarded operations 表示当 Change Buffer 发生 merge 时,表已经被删除,此时就无需再将记录合并(merge)到辅助索引中了。
使用场景
上面讲到,Change Buffer 只限于用在普通索引的场景下,而不适用于唯一索引。那普通索引的所有场景,使用 Change Buffer 都可以起到加速作用吗?
因为执行 merge 操作的时候才是真正进行数据更新的时候,而 Change Buffer 的主要目的就是将记录的变更动作缓存下来,所以在一个数据页做 merge 之前,Change Buffer 记录的变更越多,收益就越大。因此,对于写多读少的业务来说,页面在写完以后马上被访问到的概率比较小,此时 Change Buffer 的使用效果最好。
这种业务模型常见的就是账单类、日志类的系统。反过来,假设一个业务的更新模式是写入之后马上会做查询,那么即使满足了条件,将更新先记录在 Change Buffer,但之后由于马上要访问这个数据页,会立即触发 merge 过程。这样随机访问 IO 的次数不会减少,反而增加了 Change Buffer 的维护代价。
所以,如果所有的更新后面,都马上伴随着对这个记录的查询,那么你应该关闭 Change Buffer。而在其他情况下,Change Buffer 都能提升更新性能。在实际使用中,普通索引和 Change Buffer 的配合使用,对于数据量大的表的更新优化还是很明显的。尤其在使用机械硬盘时,Change Buffer 机制的收效是非常显著的。
Change Buffer 和 redo log
假设我们要在表上执行这个插入语句:
mysql> insert into t(id,k) values(id1,k1),(id2,k2);
这里我们先假设当前 k 索引树的状态,查找到位置后,k1 所在的数据页在内存 (Buffer Pool) 中,而 k2 所在的数据页不在内存中。下图所示的是带 change buffer 的更新状态图。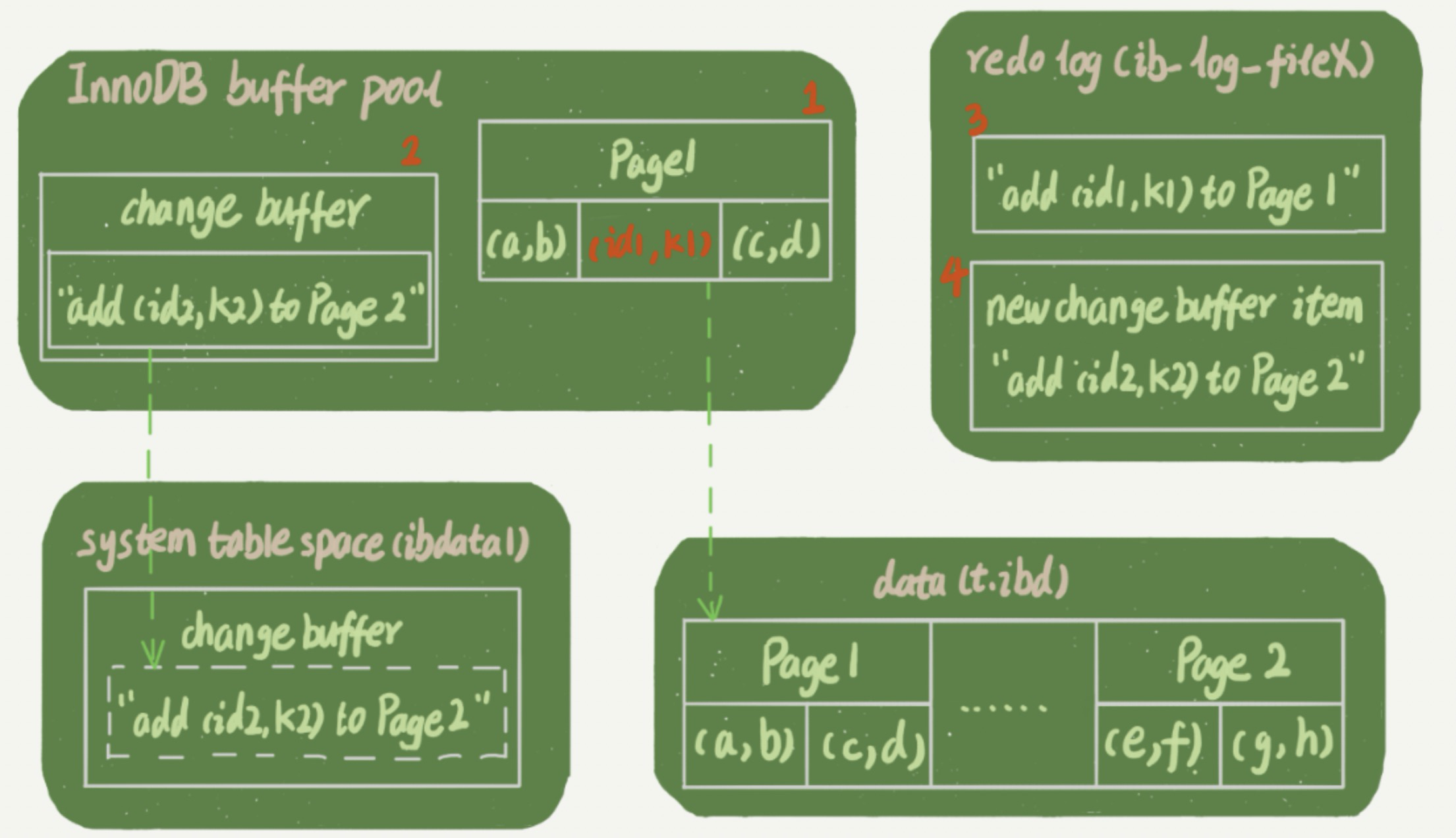
这条更新语句做了如下的操作:
- Page 1 在内存中,直接更新内存。
- Page 2 没有在内存中,就在内存的 Change Buffer 区域,记录下 “往 Page 2 插入一行” 这个信息。
- 将上述两个动作记入 redo log 中,这样异常重启后 Change Buffer 不会丢失数据。
做完上面这些,事务就可以完成了。可以看到,执行这条更新语句的成本很低,就是写了两处内存,然后写了一处磁盘(两次操作合在一起写了一次磁盘),而且还是顺序写的。同时,图中的两个虚线箭头是后台操作,不会影响更新的响应时间。
那在这之后的读请求要怎么处理呢?这里假设读语句发生在更新语句后不久,内存中的数据都还在。
select * from t where k in (k1, k2)
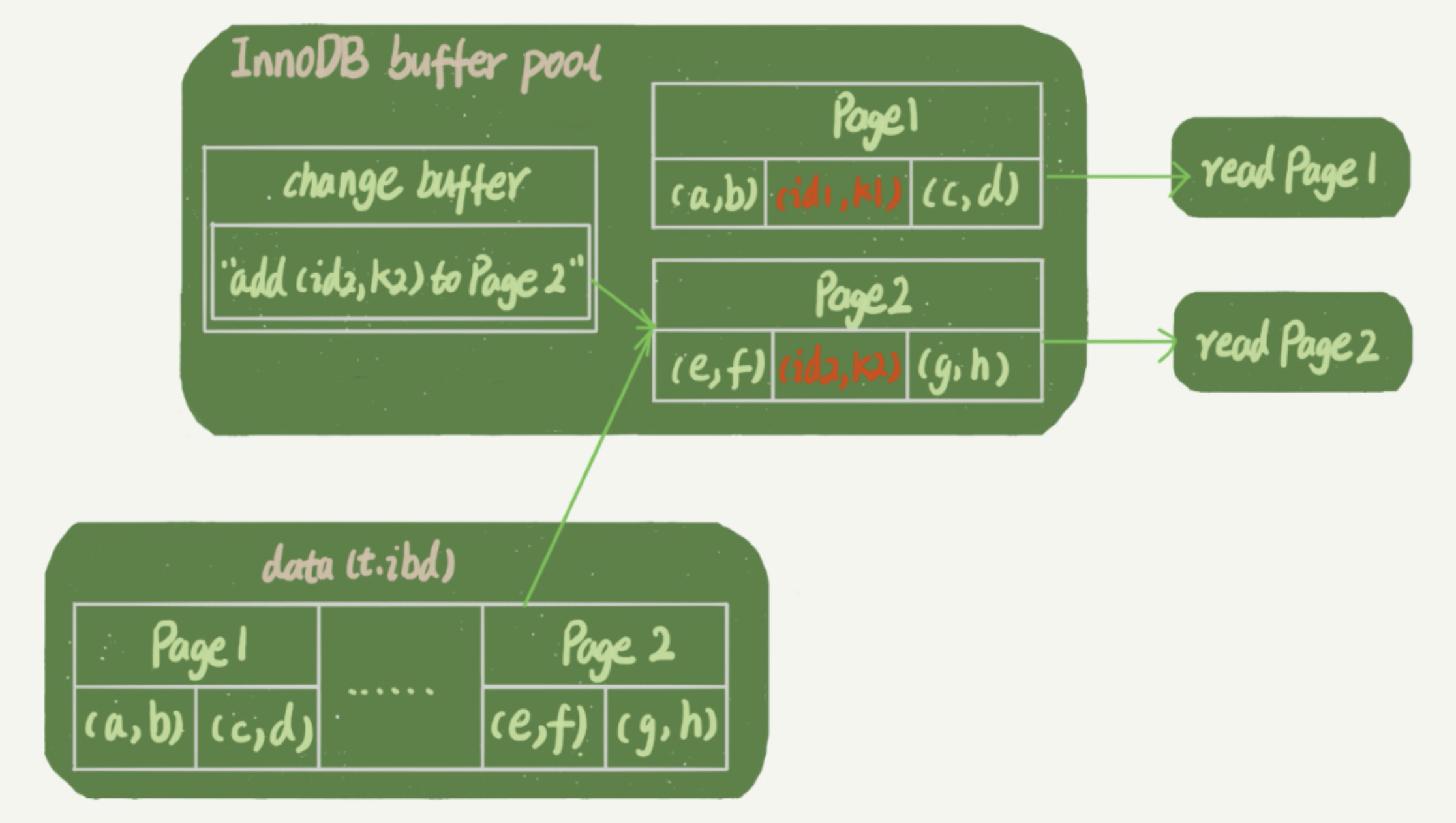
- 读 Page 1 时直接从内存返回。虽然磁盘上还是之前的数据,但这里直接从内存返回,结果是正确的。
- 读 Page 2 时需要把 Page 2 从磁盘读入内存中,然后应用 Change Buffer 里面的操作日志,生成一个正确的版本并返回结果。
我们可以看到,直到需要读 Page 2 的时候,这个数据页才会被读入内存。所以,如果要简单地对比这两个机制在提升更新性能上的收益的话,redo log 主要节省的是随机写磁盘的 IO 消耗(转成顺序写),而 Change Buffer 主要节省的则是随机读磁盘的 IO 消耗。

若有收获,就点个赞吧
0 人点赞
