聚合作用范围
Elasticsearch 聚合分析的默认作用范围是 query 的查询结果集,此外还支持以下方式改变聚合的作用范围:
- filter
- post filter
- global
1. filter
用于对具体的某个聚合做条件过滤,如下示例:
curl -X POST "localhost:9200/employees/_search?size=0&pretty" -H 'Content-Type: application/json' -d'{"aggs" : {"older_person" : {"filter" : {"range" : {"age" : {"from" : 35}}},"aggs" : {"jobs" : {"terms" : { "field" : "job.keyword" }}}},"all_jobs": {"terms" : { "field" : "job.keyword" }}}}'
通过 filter 对 older_person 这个聚合进行条件过滤,只会对符合过滤条件的文档做聚合,而和它平级的 all_jobs 则不受 filter 的条件过滤,会对所有文档做聚合。
返回结果:
{"aggregations" : {"older_person" : {"doc_count" : 2,"jobs" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "Dev Manager","doc_count" : 1},{"key" : "Java Programmer","doc_count" : 1}]}},"all_jobs" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "Java Programmer","doc_count" : 7},{"key" : "Javascript Programmer","doc_count" : 4},{"key" : "QA","doc_count" : 3},{"key" : "DBA","doc_count" : 2},{"key" : "Web Designer","doc_count" : 2},{"key" : "Dev Manager","doc_count" : 1},{"key" : "Product Manager","doc_count" : 1}]}}}
2. post_filter
在计算了聚合之后,在搜索请求的最后,将 post_filter 应用于搜索结果。也就是说,聚合还是对所有文档进行聚合分析,返回的 aggregations 中包含完整聚合结果,但在搜索时会对搜索结果使用 post_filter 过滤器,即返回的 hits 中只包含 job 字段值为 Dev Manager 的文档。
curl -X POST "localhost:9200/employees/_search?pretty" -H 'Content-Type: application/json' -d'{"aggs" : {"jobs" : {"terms" : { "field" : "job.keyword" }}},"post_filter" : {"match" : {"job.keyword" : "Dev Manager"}}}'
返回结果:
{"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "employees","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"name" : "Underwood","age" : 41,"job" : "Dev Manager","gender" : "male","salary" : 50000}}]},"aggregations" : {"jobs" : {"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,"buckets" : [{"key" : "Java Programmer","doc_count" : 7},{"key" : "Javascript Programmer","doc_count" : 4},{"key" : "QA","doc_count" : 3},{"key" : "DBA","doc_count" : 2},{"key" : "Web Designer","doc_count" : 2},{"key" : "Dev Manager","doc_count" : 1},{"key" : "Product Manager","doc_count" : 1}]}}}
3. global
curl -X POST "localhost:9200/sales/_search?size=0&pretty" -H 'Content-Type: application/json' -d'{"query" : {"match" : { "type" : "t-shirt" }},"aggs" : {"all_products" : {"global" : {},"aggs" : {"avg_price" : { "avg" : { "field" : "price" } }}},"t_shirts": { "avg" : { "field" : "price" } }}}'
在上面这个查询中,在 all_products 这个聚合中使用了 global,表示 all_products 聚合不受上面 query 条件的影响,会对所有文档聚合取平均值,而 t_shirts 聚合只会对 type 为 t-shirt 的文档进行聚合取平均值。
返回结果如下:
{"aggregations": {"all_products": {"doc_count": 7,"avg_price": {"value": 140.71428571428572}},"t_shirts": {"value": 128.33333333333334}}}
聚合排序
在聚合中可以通过 order 参数指定按照某个字段进行排序,聚合提供了 _count 和 _key 元字段,表示聚合后的文档数量和聚合后桶的 key 值,默认情况下按照 _count 降序排列。
如下示例按照 _count 升序排列,在数量相同时按 _key 降序排序
curl -XPOST "http://localhost:9200/employees/_search?size=0&pretty" -H 'Content-Type: application/json' -d'{"query": {"range" : {"age" : {"gte" : 20}}},"aggs" : {"jobs" : {"terms" : {"field" :"job.keyword","order" :[{"_count" : "asc"},{"_key" : "desc"}]}}}}'
此外,还可以按照子聚合的值进行排序,如下示例:
curl -XPOST "http://localhost:9200/employees/_search?size=0" -H 'Content-Type: application/json' -d'{"aggs": {"jobs": {"terms": {"field":"job.keyword","order":[{ "avg_salary":"desc" }]},"aggs": {"avg_salary": {"avg": {"field":"salary"}}}}}}'
如果子聚合有多值,如 stats 等指标聚合,可通过 . 进行指定具体值,示例如下:
curl -XPOST "http://localhost:9200/employees/_search?size=0" -H 'Content-Type: application/json' -d'{"aggs": {"jobs": {"terms": {"field":"job.keyword","order":[{ "stats_salary.min":"desc" }]},"aggs": {"stats_salary": {"stats": {"field":"salary"}}}}}}'
聚合原理
Elasticsearch 的聚合会先通过协调节点将聚合请求分发到多个分片上执行,每个分片返回该分片上的聚合结果给到协调节点,协调节点再对各个分片返回的结果进行统计并返回聚合结果。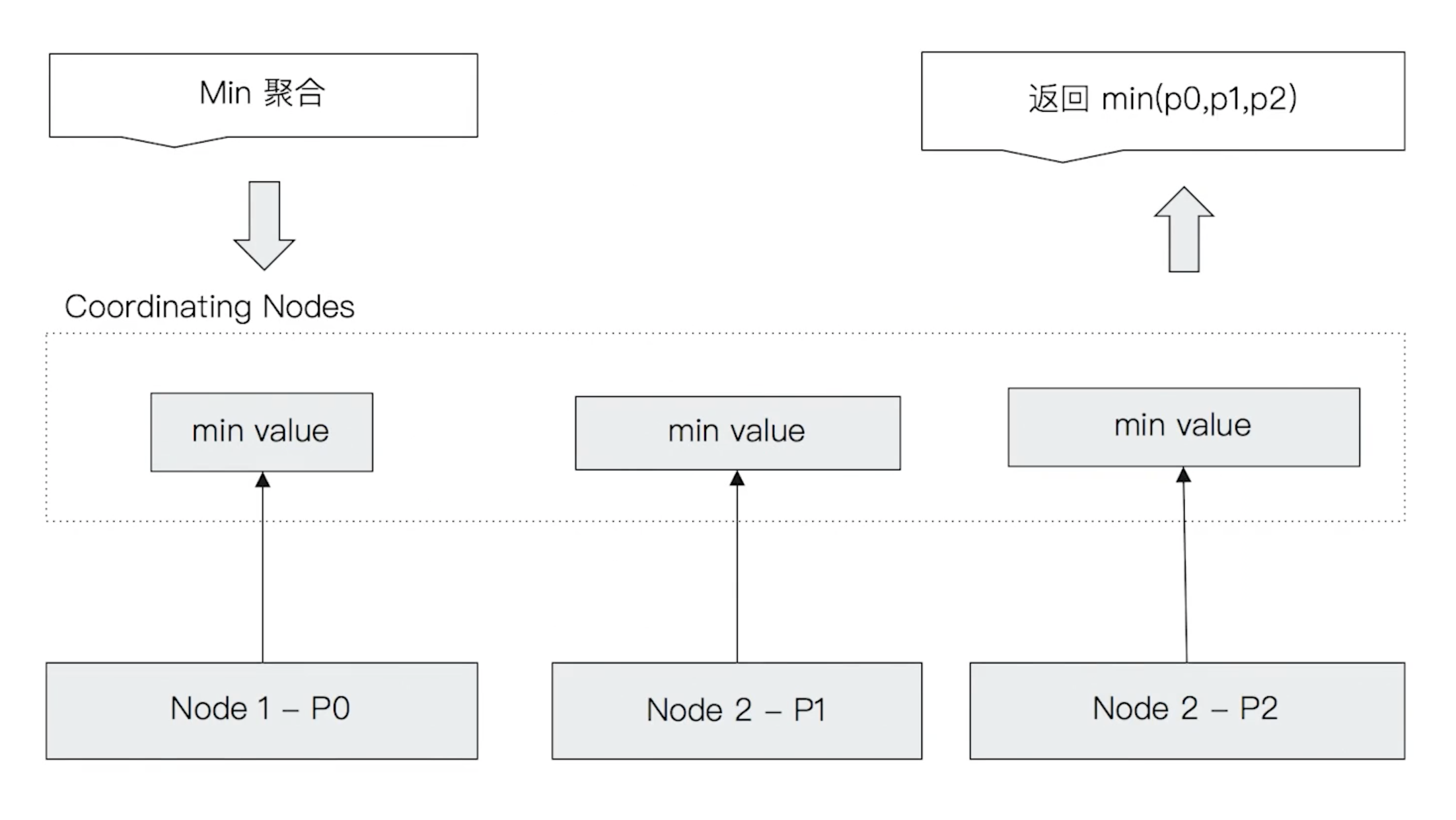
这种聚合统计的方式对于 min 这种指标聚合是不会有精确度问题的,但对于 terms 聚合就不一样了。因为数据是分散在多个分片上的,协调节点无法获取数据全貌。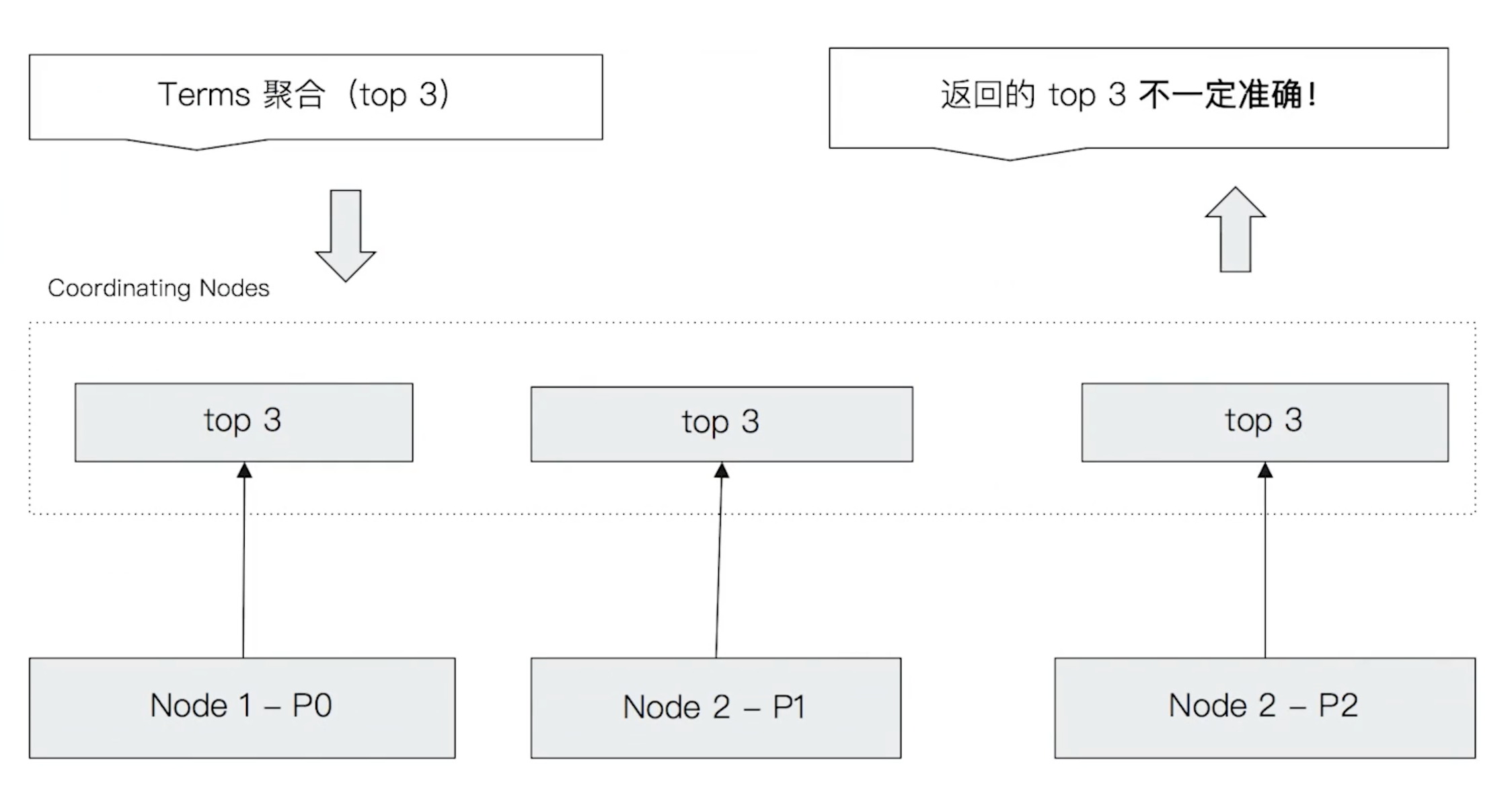
针对这个问题,如果数据量不大,可以设置 Primary Shard 为 1 提高准确性;如果在多分片上,我们可以通过提升 shard_size参数减少 terms 不准的影响。shard_size 的原理是从 Shard 上额外多获取数据来提升整体的准确率,但返回给客户端的数量还是以 size 为准。
在使用 terms 聚合时,在返回结果中还有两个特殊的字段:
"doc_count_error_upper_bound" : 0,"sum_other_doc_count" : 0,
- doc_count_error_upper_bound:被遗漏的 term 分桶包含的文档,有可能的最大值
- sum_other_doc_count:除了返回结果 bucket 的 terms 之外,其他 terms 的文档总数,其实就是文档总数-返回的文档总数。
假设有如下聚合统计: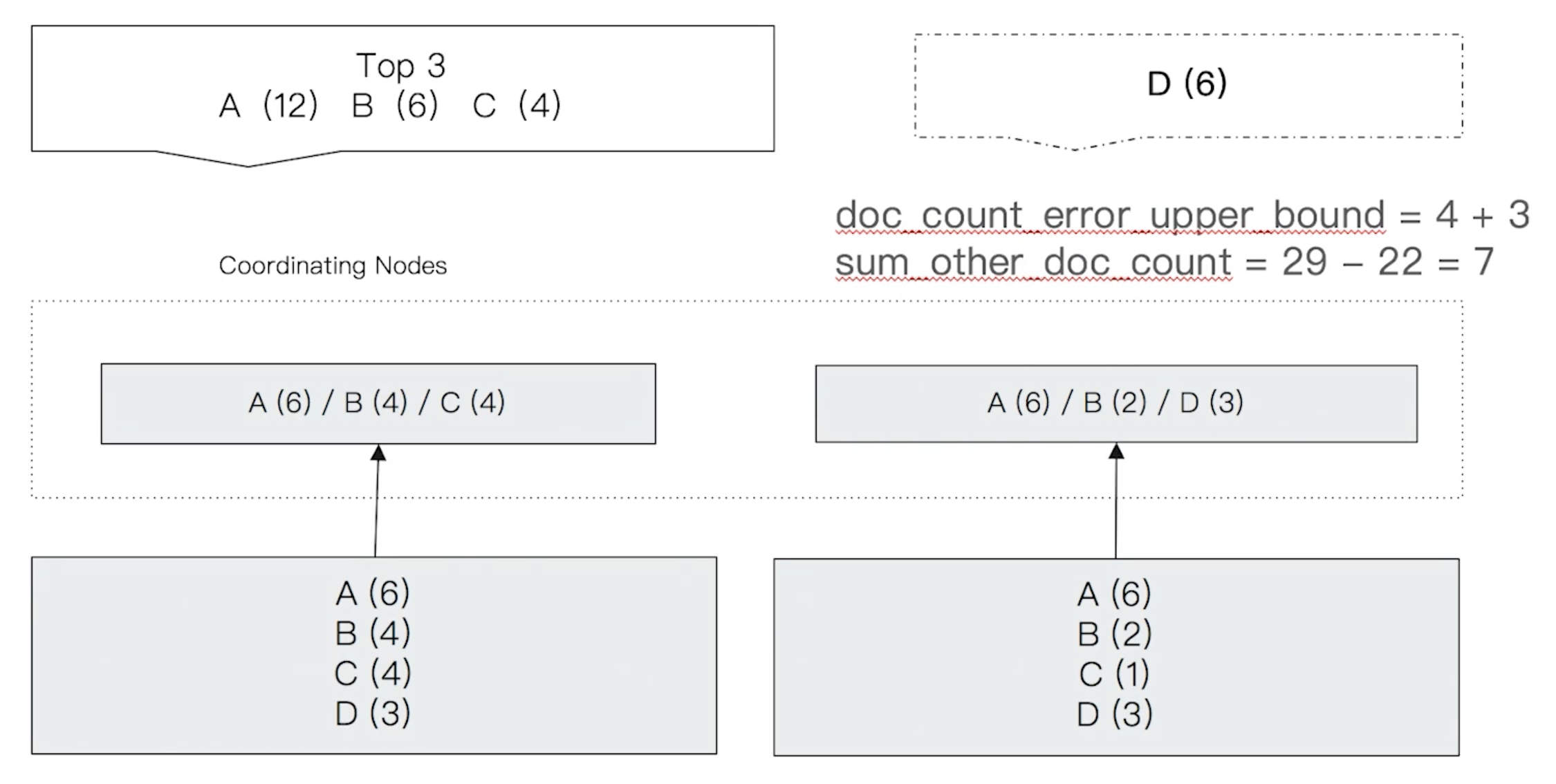
从图中可以看出,实际上 D 的总数量要大于 C,但却没有被统计出来。
本次统计返回的 doc_count_error_upper_bound 的值为 7,因为在第一个分片上取前三个桶时,第三个桶的数量为 4,所在假设它被遗漏的文档数也为 4,虽然实际上第一个分片中 D 的文档数为 3,但这个值返回的是 “可能最大” 而不是 “实际最大”。第二个分片同理,所以这个值为 7。
sum_other_doc_count 的值为所有分片上的总文档数(29)减去返回的文档数(22)即为 7。

若有收获,就点个赞吧
0 人点赞
