MySQL 在 5.1 版本添加了对分区表的支持。分区的过程是将一个表或索引分解为多个更小、更可管理的部分。从逻辑上讲,只有一个表或者一个索引,但是在物理上这个表或索引可能由数十个物理分区组成。每个分区都是独立的对象,可以独自处理,也可以作为一个更大的对象的一部分进行处理。
MySQL 支持的分区类型为水平分区,并不支持垂直分区。此外,MySQL 数据库的分区是局部分区索引,一个分区中既存放了数据又存放了索引。相对的,全局分区指数据存放在各个分区中,但所有数据的索引放在一个对象中。目前 MySQL 还不支持全局分区。
为了说明分区表的组织形式,这里先创建一个表 t,并初始化插入两条语句:
CREATE TABLE `t` (`ftime` datetime NOT NULL,`c` int(11) DEFAULT NULL,KEY (`ftime`)) ENGINE=InnoDB DEFAULT CHARSET=latin1PARTITION BY RANGE (YEAR(ftime))(PARTITION p_2017 VALUES LESS THAN (2017) ENGINE = InnoDB,PARTITION p_2018 VALUES LESS THAN (2018) ENGINE = InnoDB,PARTITION p_2019 VALUES LESS THAN (2019) ENGINE = InnoDB,PARTITION p_others VALUES LESS THAN MAXVALUE ENGINE = InnoDB);insert into t values('2017-4-1',1),('2018-4-1',1);
这里以范围分区(range)为例。实际上,MySQL 还支持 hash 分区、list 分区等分区方法。按照定义的分区规则,这两行记录分别落在 p_2018 和 p_2019 这两个分区上。
可以看到,这个表包含了一个.frm 文件和 4 个.ibd 文件,每个分区对应一个.ibd 文件。也就是说:
- 对于引擎层来说,这是 4 个表
- 对于 Server 层来说,这是 1 个表。
分区类型
1. RANGE 分区
RANGE 分区是最常见的一种分区类型。下面的 CREATE TABLE 语句创建了一个 id 列的区间分区表。当 id 小于 10 时,数据插入 p0 分区;当 id 大于等于 10 小于 20 时,数据插入 p1分区。
CREATE TABLE T (id INT) ENGINE=INNODBPARTITION BY RANGE (id) (PARTITION p0 VALUES LESS THAN (10),PARTITION p1 VALUES LESS THAN (20));
2. LIST 分区
LIST 分区和 RANGE 分区非常相似,只是分区列的值是离散的,而非连续的。
CREATE TABLE T (id INT) ENGINE=INNODBPARTITION BY LIST (id) (PARTITION p0 VALUES IN (1,3,5,7,9),PARTITION p1 VALUES IN (0,2,4,6,8));
3. HASH 分区
HASH 分区的目的是将数据均匀地分布到预先定义的各个分区中,保证各分区的数据数量大致都是一样的。在 RANGE 和 LIST 分区中,必须明确指定一个给定的列值或列值集合应该保存在哪个分区中,而在 HASH 分区中,MysQL 自动完成这些工作,用户所要做的只是基于将要进行哈希分区的列值指定一个列值或表达式,以及指定被分区的表将要被分割成的分区数量。
CREATE TABLE T (id INT,b DATETIME) ENGINE=INNODB// 分区按日期列b进行PARTITION BY HASH (YEAR(b))PARTITIONS 4;
4. KEY 分区
KEY 分区和 HASH 分区相似,不同之处在于 HASH 分区使用用户定义的函数进行分区,KEY 分区使用 MySQL 数据库内部提供的哈希函数进行分区。
CREATE TABLE T (id INT,b DATETIME) ENGINE=INNODBPARTITION BY KEY (b)PARTITIONS 4;
5. COLUMNS 分区
前面介绍的 RANGE、LIST、HASH 和 KEY 这四种分区中,分区的条件是数据必须是整型,如果不是整型,那应该需要通过函数将其转化为整型,如 YEAR()、TO_ DAYS()、MONTH() 等函数。MySQL 在 5.5 版本开始支持 COLUMNS 分区,可视为 RANGE 分区和 LIST 分区的一种进化。COLUMNS 分区可以直接使用非整型的数据进行分区,分区根据类型直接比较而得,不需要转化为整型。
CREATE TABLE T (id INT,b DATETIME) ENGINE=INNODBPARTITION BY RANGE COLUMNS (b) (PARTITION p0 VALUES LESS THAN ('2020-01-01'),PARTITION p1 VALUES LESS THAN ('2021-01-01'));
MySQL 在 5.5 开始支持 COLUMNS 分区,对于之前的 RANGE 和 LIST 分区,用户可以用 RANGE COLUMNS 和 LIST COLUMNS 分区进行很好的代替。
分区策略
从 MySQL 5.7.9 开始,InnoDB 引擎引入了本地分区策略(native partitioning)。这个策略是在 InnoDB 内部自己管理打开分区的行为。如果从 server 层看的话,一个分区表就只是一个表。以下面这个例子来说明下: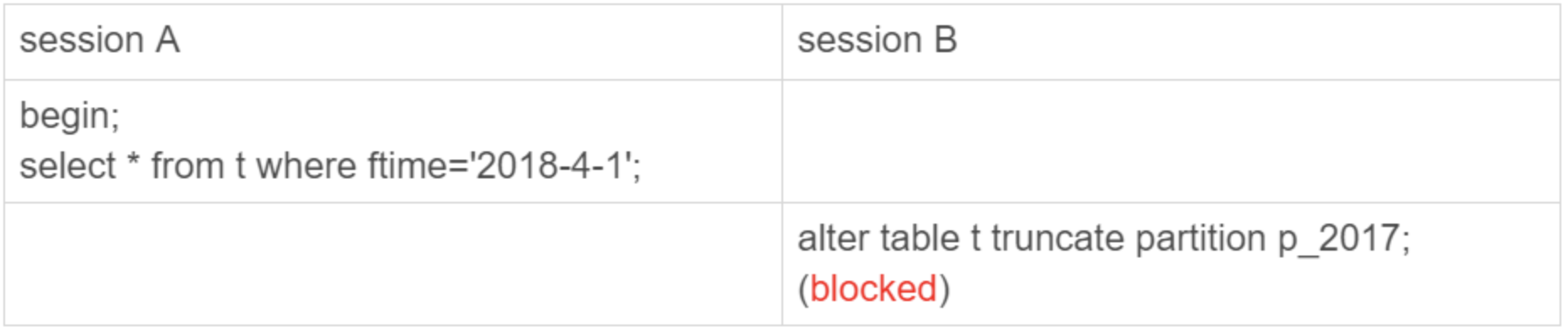
可以看到,虽然 session B 只需要操作 p_2107 这个分区,但是由于 session A 持有整个表 t 的 MDL 锁,就导致了 session B 的 alter 语句被堵住。因此,分区表在做 DDL 的时候,影响会更大。如果你使用的是普通分表,那么当你在 truncate 一个分表的时候,肯定不会跟另外一个分表上的查询语句,出现 MDL 锁冲突。
到这里我们小结一下:
- MySQL 在第一次打开分区表的时候,需要访问所有的分区
- 在 server 层,认为这是同一张表,因此所有分区共用同一个 MDL 锁,锁粒度大
- 在引擎层,认为这是不同的表,因此 MDL 锁之后的执行过程,会根据分区表规则,只访问必要的分区
必要的分区就是根据 SQL 语句中的 where 条件,结合分区规则来实现的。比如上面的例子,根据分区规则 year 函数算出来的值是 2018,那就会落在 p_2019 这个分区。如果查询语句的 where 条件中没有分区 key,那就只能访问所有分区了。因此,如果要使用分区表,就不要创建太多的分区。这里有两个问题需要注意:
- 分区并不是越细越好。实际上,单表或者单分区的数据一千万行,只要没有特别大的索引,对于现在的硬件能力来说都已经是小表了。
- 分区也不要提前预留太多,在使用之前预先创建即可。对于没有数据的历史分区,要及时的 drop 掉。
至于分区表的其他问题,比如查询需要跨多个分区取数据,查询性能就会比较慢,基本上就不是分区表本身的问题,而是数据量的问题或者说是使用方式的问题了。当然,如果你的团队已经维护了成熟的分库分表中间件,用业务分表对业务开发同学没有额外的复杂性,对 DBA 也更直观,自然是更好的。
使用场景
分区表的一个显而易见的优势是对业务透明,相对于用户分表来说,使用分区表的业务代码更简洁。还有,分区表可以很方便的清理历史数据。如果一项业务跑的时间足够长,往往就会有根据时间删除历史数据的需求。这时候,按照时间分区的分区表,就可以直接通过 alter table t drop partition … 这个语法删掉分区。
这个 alter table t drop partition … 操作是直接删除分区文件,效果跟 drop 普通表类似。与使用 delete 语句删除数据相比,优势是速度快、对系统影响小。

若有收获,就点个赞吧
0 人点赞
