安装步骤
下载地址:https://www.elastic.co/cn/downloads/elasticsearch
各文件目录作用:
| 目录 | 配置文件 | 描述 |
|---|---|---|
| bin | 脚本文件,包括启动 elasticsearch,安装插件,运行统计数据等 | |
| config | elasticsearch.yml | 集群配置文件,user、role based 相关配置 |
| data | path.data | 数据文件 |
| jdk.app | Java 运行环境 | |
| lib | Java 类库 | |
| logs | path.log | 日志文件 |
| modules | 包含的所有 ES 模块 | |
| plugins | 包含所有已安装插件 |
通过以下命令启动:
./bin/elasticsearch
启动后的默认 HTTP 端口为 9200,我们可以通过访问 http://localhost:9200 查看是否启动成功
默认情况下,Elasticsearch 在前台运行,其日志会打印到标准输出,可以通过按 Ctrl-C 停止。如果想要将 Elasticsearch 作为守护进程运行,可以在启动时指定 -d 参数,此时日志信息将会保存在 logs 目录下。
./bin/elasticsearch -d
我们还可以通过 -p 参数将进程 PID 写到文件中,方便进程退出
$ ./bin/elasticsearch -p /tmp/elasticsearch-pid -d$ cat /tmp/elasticsearch-pid && echo15516$ kill -SIGTERM 15516
插件安装:
# 安装插件bin/elasticsearch-plugin install analysis-icu# 查看插件bin/elasticsearch-plugin list# 查看安装的插件GET http://localhost:9200/_cat/plugins?v
配置文件
Elasticsearch 默认会加载 config 目录下的 elasticsearch.yml 配置文件,我们可以在配置文件中指定配置项也可以在命令行中通过 -E 参数指定。通常,任何集群范围的设置(如 cluster.name)都应该添加到 elasticsearch.yml 配置文件中,而任何节点特定设置(如 node.name)则可以在命令行上指定。
./bin/elasticsearch -d -Ecluster.name=my_cluster -Enode.name=node_1
Elasticsearch 的大部分配置都有良好的默认值,因此只需要很少的配置项,此外还可以使用 Cluster Update Settings 在运行的集群上更改大多数设置。下面我们介绍 Elasticsearch 中的三个比较重要的配置文件,默认位于 $ES_HOME/config 目录下:
elasticsearch.yml:
- 文件格式遵循 YAML 规范,并且可以使用 ${…} 来引用系统的环境变量。
jvm.options:
- 以 # 开头的行被视为注释并被忽略
- 以 - 开头的行被视为独立于 JVM 版本应用的 JVM 选项,如:-Xmx2g
- 以数字开头,后面跟 : 的行被视为 JVM 选项,仅当 JVM 版本与数字匹配时才适用,如 8:-Xmx2g
- 以数字开头,后面跟 - 再跟 : 的行被视为JVM选项,仅当JVM的版本大于或等于这个数字时才适用,如 8-:-Xmx2g
- 以数字开头,后面跟 - 再跟数字,再跟 : 的行被视为 JVM 选项,仅当 JVM 的版本在这两个数字的范围内时才适用,如 8-9:-Xmx2g
log4j2.properties
- Elasticsearch 在配置文件中开放了三个动态配置项,用以确定日志文件的位置,分别为:
- ${sys:es.logs.base_path}:日志存放路径
- ${sys:es.logs.cluster_name}:集群名称,默认用作日志文件名的前缀
- ${sys:es.logs.node_name}:节点名称
设置日志级别
- 通过命令行: -E<日志层级>=<级别>(如 -Elogger.org.elasticsearch.discovery=debug)。这种方式主要用于临时调试。
- 在 elasticsearch.yml 文件上配置 <日志层级>:<级别>(如,logger.org.elasticsearch.discovery:debug)。
通过 Cluster Update Settings API 设置,适用于需动态调整活跃运行的集群上的日志级别。
curl -X PUT "localhost:9200/_cluster/settings?pretty" -H 'Content-Type: application/json' -d'{"transient": {"logger.org.elasticsearch.discovery": "DEBUG"}}'
修改 log4j2.properties 配置文件 ``` logger.
.name = logger. .level =
- Elasticsearch 在配置文件中开放了三个动态配置项,用以确定日志文件的位置,分别为:
举例:
logger.discovery.name = org.elasticsearch.discovery
logger.discovery.level = debug
<a name="rvUR8"></a># 基础配置项**cluster.name**<br />指定 Elasticsearch 的集群名称,只有当一个节点与集群中的所有其他节点共享 cluster.name 时,该节点才能加入集群。默认值为 elasticsearch。请确保不要在不同的环境中重用相同的集群名,否则可能会导致节点加入错误的集群。**node.name**<br />Elasticsearch 使用 node.name 作为 Elasticsearch 特定实例的可读标识符,默认为 Elasticsearch 启动时机器的主机名。节点名称和集群名称一样可以自定义,同一个集群的集群名称要配置统一,节点名称则取不同值以便于区分。**path.data**<br />设置索引数据的存储路径,默认是 Elasticsearch 根目录下的 data 文件夹,可以为其设置多个存储路径(单个分片内的数据会保存在相同路径下),用逗号隔开或者采用 yml 格式进行配置。```yamlpath:data:- /mnt/elasticsearch_1- /mnt/elasticsearch_2- /mnt/elasticsearch_3
path.logs
设置日志文件的存储路径,默认是 Elasticsearch 根目录下的 logs 文件夹,使用同 path.data。
node.master
指定该节点是否是 master 节点,默认值为 true,Elasticsearch 默认集群中的第一台机器为 master,如果这台机出现故障就会重新选举 master。
node.data
指定该节点是否存储索引数据,默认值为 true。
network.host
设置绑定的 IP 地址,可以是 IPv4 或 IPv6 的,默认为 127.0.0.1,如果想要通过 IP 访问则需要设置为显示 IP 并且在集群环境下也需要设置为显示 IP。
http.port
设置对外服务的 HTTP 端口,接受单个值或范围。如果指定了范围,则绑定到范围内的第一个可用端口。默认值为 9200-9300。
transport.port
设置节点间交互的 TCP 端口,也是 Java API 中使用的端口。接受单个值或范围。如果指定了范围,则绑定到范围内的第一个可用端口。默认值为 9300-9400。
discovery.seed_hosts
当需要与其他主机上的节点组成集群时,必须通过该属性配置集群内其他节点的地址,该设置通常应包含集群中所有符合主节点条件的地址。每个值都应该采用 host:port 或 host 的形式(其中端口默认为 transport.profiles.default.port 设置的值,如果没有配置该值则采用 transport.port 的值。
# 以下展示了三种可配置的格式discovery.seed_hosts:- 192.168.1.10:9300- 192.168.1.11- seeds.mydomain.com # 如果一个主机名解析为多个IP地址,该节点将尝试在所有解析的地址上发现其他节点
这个配置项以前被称为 discovery.zen.ping.unicast.hosts。它的旧名称已被弃用,但为了保持向后兼容性,它还是能够继续工作。对旧名称的支持将在将来的版本中删除。
系统配置项
理想情况下,Elasticsearch 应该单独运行在服务器上,并使用所有可用的资源。为了做到这一点,我们需要对操作系统进行配置,以允许运行 Elasticsearch 的用户能够访问超过默认允许的资源。
1. ulimit
在 Linux 系统上,可以使用 ulimit 临时更改资源限制。如果通过命令行设置 ulimit 的话,新的限制只适用于当前会话。如果想要永久修改则可以编辑 /etc/security/limits.conf 文件,在该文件中增加一行,此更改仅在 elasticsearch 用户下次打开新会话时生效。
# 将elasticsearch用户打开的最大文件数设置为65536elasticsearch - nofile 65535
可以使用 ulimit -a 来查询当前应用的所有限制,如下图所示: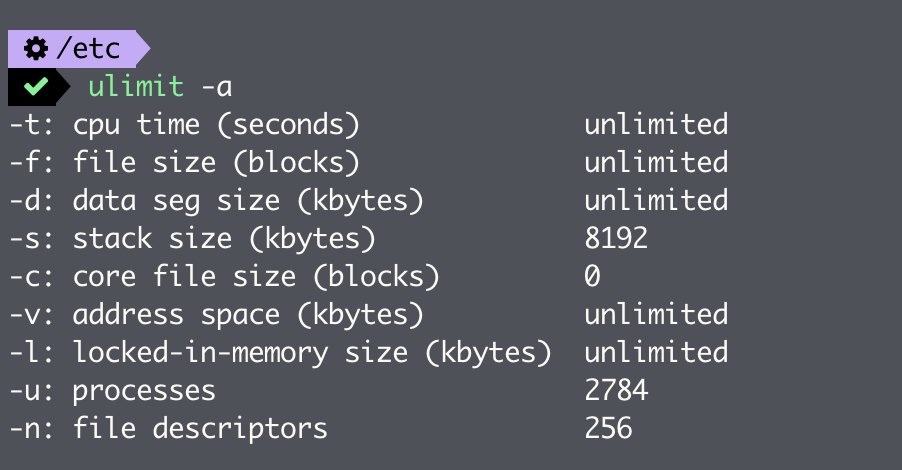
文件描述符
Elasticsearch 使用了很多文件描述符或文件句柄,而耗尽文件描述符可能是灾难性的,很可能会导致数据的丢失。因此要确保将运行 Elasticsearch 的用户的打开文件描述符数量的限制增加到 65536 或更高。
可通过设置 ulimit -n 65535 临时修改,或修改 /etc/security/limits.conf 文件将 nofile 值修改为 65535。启动 Elasticsearch 之后,还可使用 Nodes Stats API 来查看当前最大文件描述符:
curl -X GET "localhost:9200/_nodes/stats/process?filter_path=**.max_file_descriptors&pretty"# 输出{"nodes" : {"7f-bO8KZQj-bjxa6Wxlt0A" : {"process" : {"max_file_descriptors" : 10240}}}}
线程数
Elasticsearch 会将请求分为多个阶段,并将这些阶段交给不同的线程池去执行。因此 Elasticsearch 需要有创建大量线程的能力,这一点很重要。确保 Elasticsearch 用户可以创建的线程数量至少是 4096 个。可通过设置 ulimit -u 4096 临时修改,或修改 /etc/security/limits.conf 文件将 nproc 值修改为 4096。
文件大小
在 Elasticsearch 执行过程中,分片下的 Segment 文件和 translog 文件可能会变得很大(超过几 GB)。在 Elasticsearch 进程可以创建的最大文件大小受到限制的系统上,这可能会导致写操作失败。因此需要将系统配置为允许 Elasticsearch 进程写入无限大小的文件。可通过设置 ulimit -f unlimited 临时修改,或修改 /etc/security/limits.conf 文件将 fsize 值改为 unlimited。
2. swapping
大多数操作系统尝试为文件系统缓存使用尽可能多的内存,并急切地交换未使用的应用程序内存。这可能导致部分 JVM 堆甚至其可执行页被交换到磁盘。swapping 对于性能和节点稳定性非常不利,它可能导致垃圾收集持续几分钟而不是几毫秒,并可能导致节点响应缓慢,甚至断开与集群的连接。在一个有弹性的分布式系统中,让操作系统杀死节点更有效。
下面有三种方法可以禁用 swapping:
在 Linux 系统上,可以在运行时通过命令临时禁用掉 swapping,这一步骤不需要重启 Elasticsearch,如果想要永久禁用,需要修改 /etc/fstab 文件并注释掉任何包含 swap 单词的行。
sudo swapoff -a
Linux 系统上可用的另一个选项是确保 vm.swappiness 的值被设置为 1。这减少了内核交换的倾向,并且在正常情况下不应该导致交换,但在紧急情况下仍然允许整个系统进行交换。
第三个选择是通过 mlockall 将进程地址空间锁定到 RAM 中,防止任何 Elasticsearch 内存被交换出去。可通过在 config/elasticsearch.yml 文件中增加如下配置来开启锁定:
bootstrap.memory_lock: true
启动 Elasticsearch 之后,可通过检查该请求输出中的 mlockall 值来查看是否成功应用了该设置。如果输出的 mlockall 值为 false,则表示锁定失败了,最可能的原因是启动 Elasticsearch 进程的用户没有权限锁定内存。此时,我们可以执行 ulimit -l unlimited 命令临时解除限制,或者修改 /etc/security/limits.conf 文件将 memlock 的值改为 unlimited。
curl -X GET "localhost:9200/_nodes?filter_path=**.mlockall&pretty"# 输出{"nodes" : {"7f-bO8KZQj-bjxa6Wxlt0A" : {"process" : {"mlockall" : false}}}}
3. 堆内存
建议在配置堆内存时,将最小堆大小(-Xms)和最大堆大小(-Xmx)设置为彼此相等。如果 JVM 以不相等的初始堆大小和最大堆大小启动,那么当系统使用期间动态调整 JVM 堆大小时,它很容易暂停。另外,如果启用了 bootstrap.memory_lock,那么 JVM 将在启动时锁定堆的初始大小,如果初始堆大小不等于最大堆大小,那么在调整大小后,就不会出现所有 JVM 堆都锁定在内存中的情况了。
Elasticsearch 可用的堆内存越多,它可以用于缓存的内存就越多。但太大的堆也会导致长时间的垃圾收集暂停。
通常的建议是将 -Xmx 设置为不超过物理 RAM 的 50%,以确保有足够的物理 RAM 留给内核文件系统缓存来使用。注意不要将 -Xmx 设置为超出 JVM 用于压缩对象指针的界限(压缩 oops),这个值接近 32GB。更好的做法是,尽量保持在基于 0 的压缩 oops 的阈值以下,这个值接近 30 GB。
参考链接:https://www.elastic.co/cn/blog/a-heap-of-trouble
如果 GC 停顿时间过长,可考虑替换使用 G1
参考链接:https://medium.com/naukri-engineering/garbage-collection-in-elasticsearch-and-the-g1gc-16b79a447181
Bootstrap 检测
从 5.0 版本开始,Elasticsearch 支持以开发或生产两种模式来启动 Elasticsearch 集群。当一个集群以生产模式启动时,必须通过所有的 Bootstrap 检测,否则会启动失败。
Bootstrap 检测大体上分为两类:JVM、Linux Checks,其中 Linux Checks 只针对 Linux 系统,具体检测内容如下,这样检测也为我们提升集群性能提供了一个很好的方向。
JVM Checks:
- Heap Size
- Not use Serial Collector
- Disable Swapping
- Server JVM
- ……
Linux Checks:
- Maximum map count
- Maximum Size Virtual Memory
- Maximum Number of Threads
- File Descriptor
- ……

若有收获,就点个赞吧
0 人点赞
