Bitmap
Bitmap 是 Redis 提供的扩展数据类型。Bitmap 本身是用 String 类型作为底层数据结构实现的一种统计二值状态的数据类型。String 类型是会保存为二进制的字节数组,所以,Redis 就把字节数组的每个 bit 位利用起来表示一个元素的二值状态。你可以把 Bitmap 看作是一个 bit 数组。
Bitmap 提供了 GETBIT、SETBIT 操作,使用一个偏移值 offset 对 bit 数组的某一个 bit 位进行读和写。需要注意,Bitmap 的偏移量从 0 开始计数。此外,Bitmap 还提供了 BITCOUNT 操作,用来统计这个 bit 数组中所有值为 1 的个数。最后,Redis 还提供了 BITOP 命令可以对多个位数组进行按位操作:
SETBIT <key> <offset> <value>GETBIT <key> <offset>BITCOUNT <key> [start] [end]BITOP <operation> <destkey> <key> [key ...]
BITOP 命令操作的结果会保存到一个新的 Bitmap 中,其中 operation 的可选值为:
- AND:程序用 & 操作计算出所有输入二进制位的逻辑与结果,然后保存到 destkey 键。
- OR:程序用 | 操作计算出所有输入二进制位的逻辑或结果,然后保存到 destkey 键。
- XOR:程序用 ^ 操作计算出所有输入二进制位的逻辑异或结果,然后保存到 destkey 键。
- NOT:程序用 ~ 操作计算出所有输入二进制位的逻辑非结果,然后保存到 destkey 键。
因为 BITOP AND、BITOP OR、BITOP XOR 三个命令可以接受多个位数组作为输入。程序需要遍历输入的每个位数组的每个字节来进行计算,所以这些命令的复杂度为 O(n^2)。与此相反,因为 BITOP NOT 命令只接受一个位数组输入,所以它的复杂度为 O(n)。
使用场景示例:
如果我们记录了 1 亿个用户 10 天的签到情况,现在想统计出这 10 天连续签到的用户总数。我们可以利用位数组进行位运算来计算出用户总数。具体做法是:把每天的日期作为 key,每个 key 对应一个 1 亿位的 Bitmap,每一个 bit 对应一个用户当天的签到情况。
接下来,我们对 10 个 Bitmap 做 “与” 操作,得到的结果也是一个 Bitmap。在这个 Bitmap 中,只有 10 天都签到的用户对应的 bit 位上的值才会是 1。最后,我们可以用 BITCOUNT 统计下 Bitmap 中的 1 的个数,这就是连续签到 10 天的用户总数了。
在上面的方案中,我们每天使用 1 个 1 亿位的 Bitmap,大约占 12MB 的内存(10^8/8/1024/1024),10 天的 Bitmap 的内存开销约为 120MB,内存压力不算太大。不过,在实际应用时,最好对 Bitmap 设置过期时间,让 Redis 自动删除不再需要的签到记录,以节省内存开销。
所以,如果只需要统计数据的二值状态,例如商品有没有、用户在不在等,就可以使用 Bitmap,因为它只用一个 bit 位就能表示 0 或 1。在记录海量数据时,Bitmap 能够有效地节省内存空间。
HyperLogLog
Redis 提供的 HyperLogLog 是一种用于统计基数的数据集合类型,它最大的优势就在于,当集合元素数量非常多时,它计算基数所需的空间总是固定的,而且还很小。通常用于不需要非常精确的去重计数方案,比如统计网页的 UV,但 HyperLogLog 的基数统计是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率约为 0.81%。
在 Redis 中,每个 HyperLogLog 只需要花费 12 KB 内存,就可以计算接近 2^64 个元素的基数。和元素越多就越耗费内存的 Set 和 Hash 类型相比,HyperLogLog 就非常节省空间。并且 Redis 对 HyperLogLog 的存储进行了优化,在计数比较小时,它的存储空间采用稀疏矩阵存储,空间占用很小,仅仅在计数慢慢变大,稀疏矩阵占用空间渐渐超过了阈值时才会一次性转变成稠密矩阵,才会占用 12KB 的空间。
HyperLogLog 提供了 PFADD 和 PFCOUNT 命令用于向 HyperLogLog 中添加新元素以及获取计数。此外,还提供了 PFMERGE 命令用于将多个 HyperLogLog 的计数值累加在一起形成一个新的值。
PFADD key [element [element ...]]PFCOUNT key [key ...]PFMERGE destkey sourcekey [sourcekey ...]
对于基数统计来说,如果集合元素量达到亿级别而且不需要精确统计时,建议使用 HyperLogLog。
布隆过滤器
HyperLogLog 可以解决很多精确度不高的统计需求。但如果我们想知道某个值是不是已经在 HyperLogLog 结构里面了,那它就无能为力了,因为 HyperLogLog 只提供了统计功能。而布隆过滤器(Bloom Filter)就是专门用来解决去重问题的。它在起到去重的同时,在空间上还能节省 90% 以上,只是稍微有那么点不精确,也就是有一定的误判概率。
布隆过滤器可以理解为一个不怎么精确的 set 结构,当你使用它的 contains 方法判断某个对象是否存在时,它可能会误判。当布隆过滤器说某个值存在时,这个值可能不存在;但当它说不存在时,那就肯定不存在。Redis 官方提供的布隆过滤器到 Redis 4.0 提供了插件功能之后才正式登场。布隆过滤器作为一个插件加载到了 Redis Server 中,给 Redis 提供了强大的布隆去重功能。
布隆过滤器有两个基本指令:BF.ADD 添加元素,BF.EXISTS 查询元素是否存在。注意 BF.ADD 只能一次添加一个元素,如果想要一次添加多个,就需要用到 BF.MADD 指令。同样如果需要一次查询多个元素是否存在,就需 要用到 BF.MEXISTS 指令。如果想要自定义布隆过滤器的大小,可以在添加元素前调用 BF.RESERVE 命令显式创建,错误率越低,所需的空间就越大。
BF.RESERVE {key} {error_rate} {capacity} [EXPANSION {expansion}] [NONSCALING]
- error_rate:上限错误率
- capacity:初始容量,当错误率达到上限时会自动扩展容量
- expansion:扩容因子
布隆过滤器实现原理:
每个布隆过滤器对应到 Redis 的数据结构里就是一个大型的位数组和几个不一样的无偏 hash 函数。所谓无偏就是能够把元素的 hash 值算得比较均匀。向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash 算得一个整数索引值,然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。然后再把位数组的这几个位置都置为 1,就完成了 add 操作。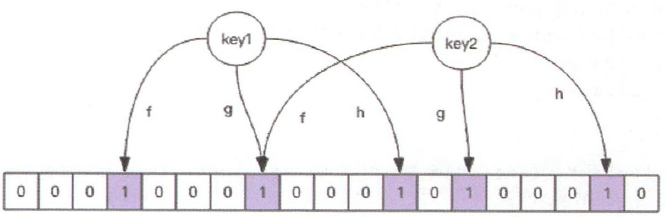
向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看位数组中这几个位置是否都为 1,只要有一个位为 0,那么说明布隆过滤器中这个 key 不存在。如果都为 1,并不能说明这个 key 一定存在,只是极有可能存在,因为这些位位置为 1 可能是因为其他的 key 存在所致。
使用布隆过滤器时不要让实际元素远大于初始化大小,当实际元素开始超出初始化大小时,应该对布隆过滤器进行重建,重新分配一个 size 更大的过滤器,再将所有的历史元素批量 add 进去(这就要求我们在其它的存储中记录了所有的历史元素)。因为 error_rate 不会因为元素数量超出就急剧增加,这就给我们重建过滤器提供了较为宽松的时间。
GEO
Redis 在 3.2 版本以后增加了地理信息 GEO 模块,支持存储地理位置信息用来实现诸如附近位置、摇一摇这类依赖于地理位置信息的功能。GEO 本身并没有设计新的底层数据结构,而是直接使用了 Sorted Set 类型。
我们以叫车为例,用 Sorted Set 来保存车辆的经纬度信息时,Sorted Set 的元素是车辆 ID,元素的权重分数是经纬度信息,如下图所示: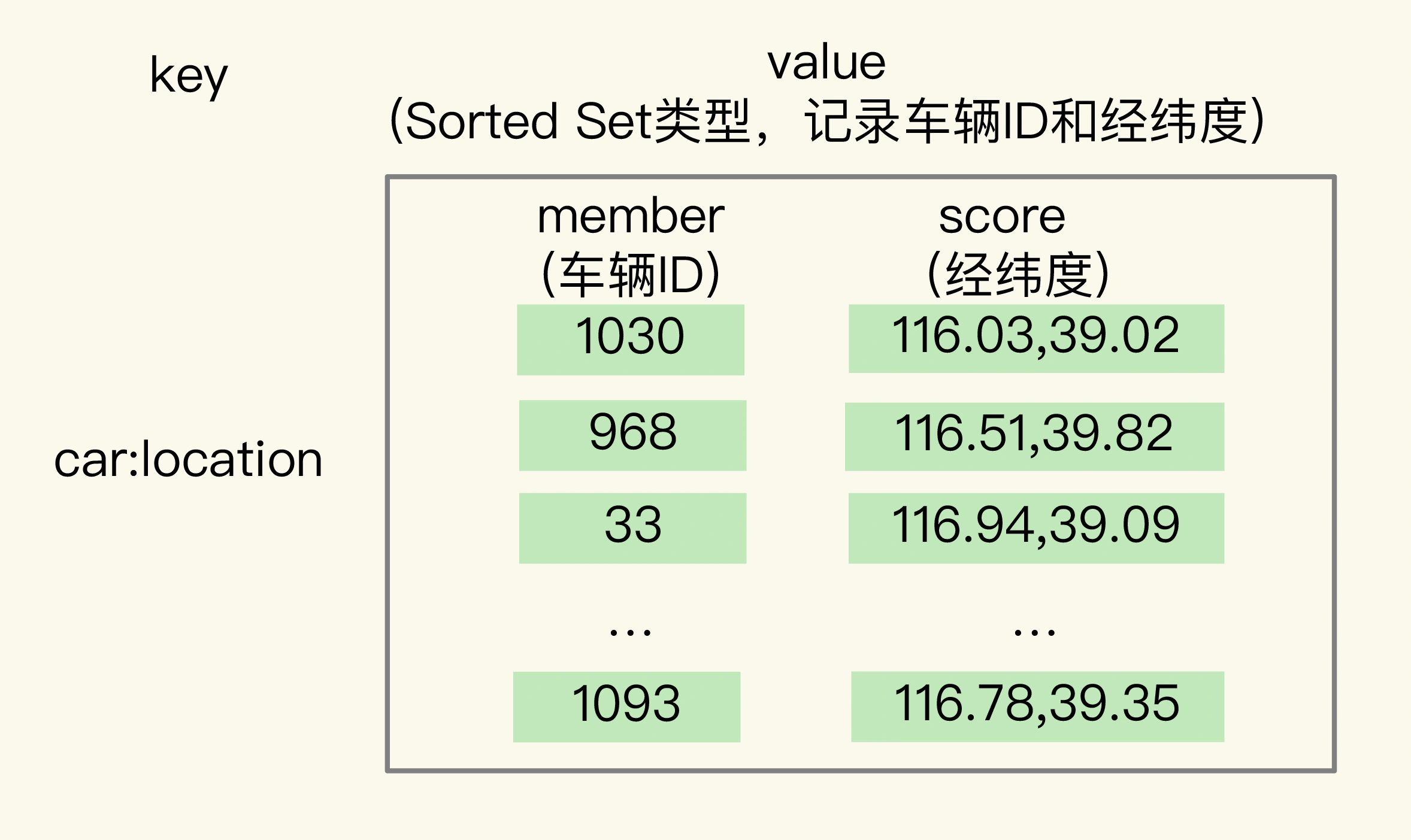
这时问题来了,Sorted Set 元素的权重分数是一个浮点数(float 类型),而一组经纬度中包含的是经度和纬度两个值,是没法直接保存为一个浮点数的,那具体该怎么进行保存呢?
1. GeoHash 编码
为了能高效地对经纬度进行比较,Redis 采用了业界广泛使用的 GeoHash 编码方法,这个方法的基本原理就是“二分区间,区间编码”。当我们要对一组经纬度进行 GeoHash 编码时,我们要先对经度和纬度分别编码,然后再把经纬度各自的编码组合成一个最终编码。
首先,我们来看下经度和纬度的单独编码过程。
对于一个地理位置信息来说,它的经度范围是 [-180,180]。GeoHash 编码会把一个经度值编码成一个 N 位的二进制值,我们来对经度范围 [-180,180] 做 N 次的二分区操作,其中 N 可以自定义。
在进行第一次二分区时,经度范围 [-180,180] 会被分成两个子区间:[-180,0) 和 [0,180](我称之为左、右分区)。此时,我们可以查看一下要编码的经度值落在了左分区还是右分区。如果是落在左分区,我们就用 0 表示;如果落在右分区,就用 1 表示。这样一来,每做完一次二分区,我们就可以得到 1 位编码值。
然后,我们再对经度值所属的分区再做一次二分区,同时再次查看经度值落在了二分区后的左分区还是右分区,按照刚才的规则再做 1 位编码。当做完 N 次的二分区后,经度值就可以用一个 N bit 的数来表示了。
举个例子,假设我们要编码的经度值是 116.37,我们用 5 位编码值(也就是 N=5,做 5 次分区)。
我们先做第一次二分区操作,把经度区间 [-180,180] 分成了左分区 [-180,0) 和右分区 [0,180],此时,经度值 116.37 是属于右分区 [0,180],所以,我们用 1 表示第一次二分区后的编码值。
接下来,我们做第二次二分区:把经度值 116.37 所属的 [0,180] 区间,分成 [0,90) 和 [90, 180]。此时,经度值 116.37 还是属于右分区 [90,180],所以,第二次分区后的编码值仍然为 1。等到第三次对 [90,180] 进行二分区,经度值 116.37 落在了分区后的左分区 [90, 135) 中,所以,第三次分区后的编码值就是 0。
按照这种方法,做完 5 次分区后,我们把经度值 116.37 定位在 [112.5, 123.75] 这个区间,并且得到了经度值的 5 位编码值,即 11010。这个编码过程如下表所示: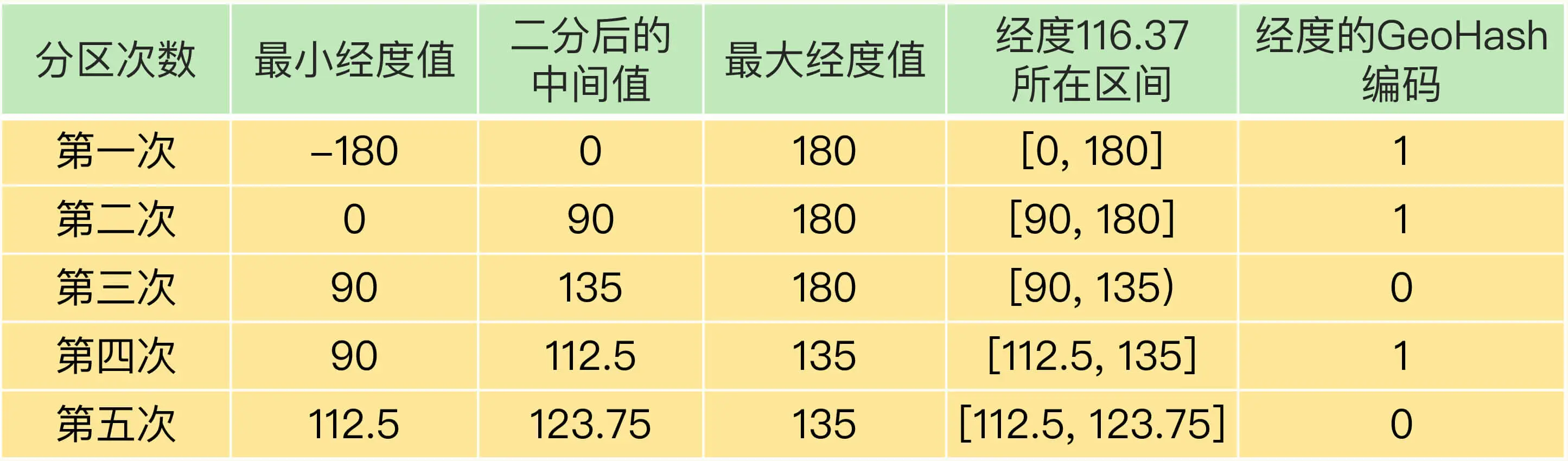
对纬度的编码方式,和对经度的一样,只是纬度的范围是 [-90,90],下面这张表显示了对纬度值 39.86 的编码过程。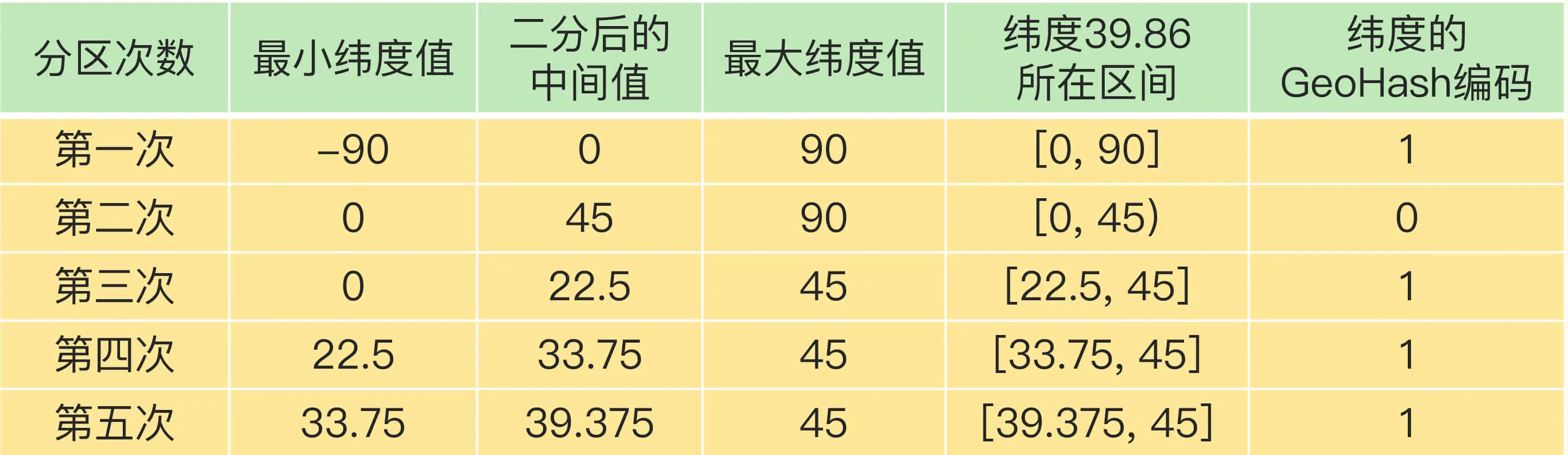
当一组经纬度值都编完码后,我们再把它们的各自编码值组合在一起,组合的规则是:最终编码值的偶数位上依次是经度的编码值,奇数位上依次是纬度的编码值,其中,偶数位从 0 开始,奇数位从 1 开始。
我们刚刚计算的经纬度(116.37,39.86)的各自编码值是 11010 和 10111,组合之后,第 0 位是经度的第 0 位 1,第 1 位是纬度的第 0 位 1,第 2 位是经度的第 1 位 1,第 3 位是纬度的第 1 位 0,以此类推,就能得到最终编码值 1110011101,如下图所示: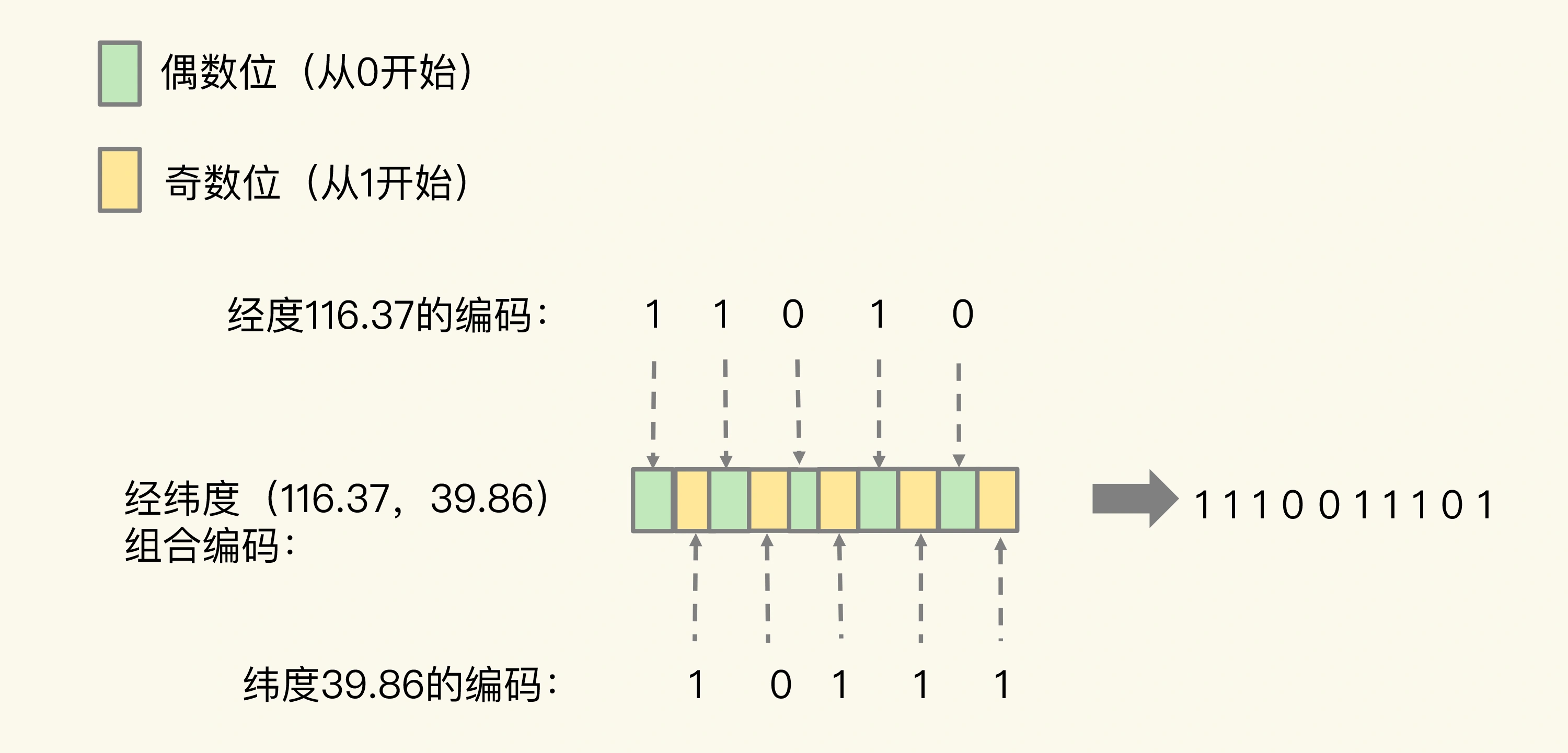
用了 GeoHash 编码后,原来无法用一个权重分数表示的一组经纬度(116.37,39.86)就可以用 1110011101 这一个值来表示,就可以保存为 Sorted Set 的权重分数了。
当然,使用 GeoHash 编码后,我们相当于把整个地理空间划分成了一个个方格,每个方格对应了 GeoHash 中的一个分区。比如,我们把经度区间 [-180,180] 做一次二分区,把纬度区间 [-90,90] 做一次二分区,就会得到 4 个分区。我们来看下它们的经度和纬度范围以及对应的 GeoHash 组合编码。
- 分区一:[-180,0) 和 [-90,0),编码 00;
- 分区二:[-180,0) 和 [0,90],编码 01;
- 分区三:[0,180]和 [-90,0),编码 10;
- 分区四:[0,180]和 [0,90],编码 11。
这 4 个分区对应了 4 个方格,每个方格覆盖了一定范围内的经纬度值,分区越多,每个方格能覆盖到的地理空间就越小,也就越精准。我们把所有方格的编码值映射到一维空间时,相邻方格的 GeoHash 编码值基本也是接近的,如下图所示: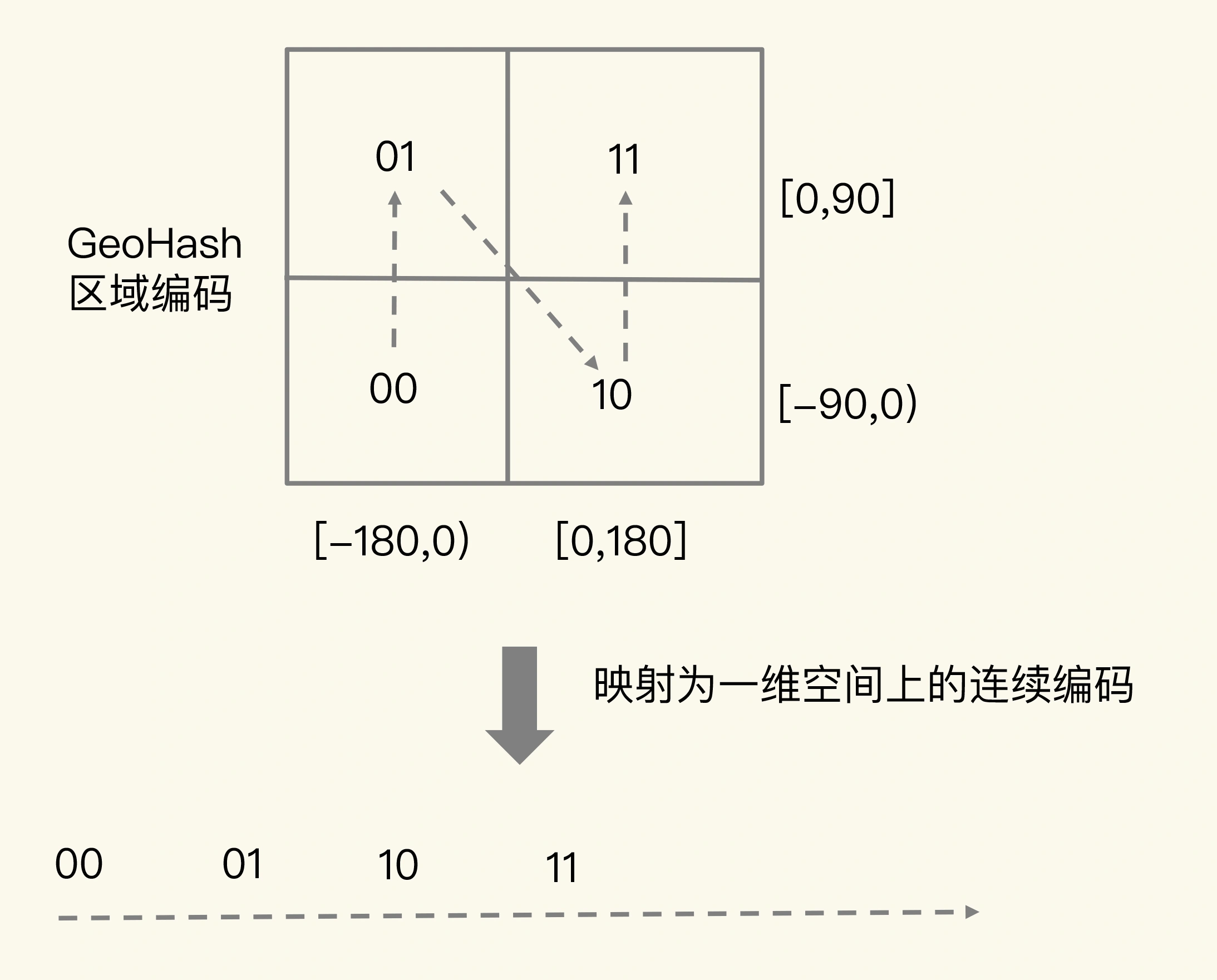
所以,我们使用 Sorted Set 范围查询得到的相近编码值,在实际的地理空间上,也是相邻的方格,这就可以实现“搜索附近的人或物”的功能了。不过,有的编码值虽然在大小上接近,但实际对应的方格却距离比较远。例如,我们用 4 位来做 GeoHash 编码,把经度区间 [-180,180] 和纬度区间 [-90,90] 各分成了 4 个分区,一共 16 个分区,对应了 16 个方格。编码值为 0111 和 1000 的两个方格就离得比较远,如下图所示: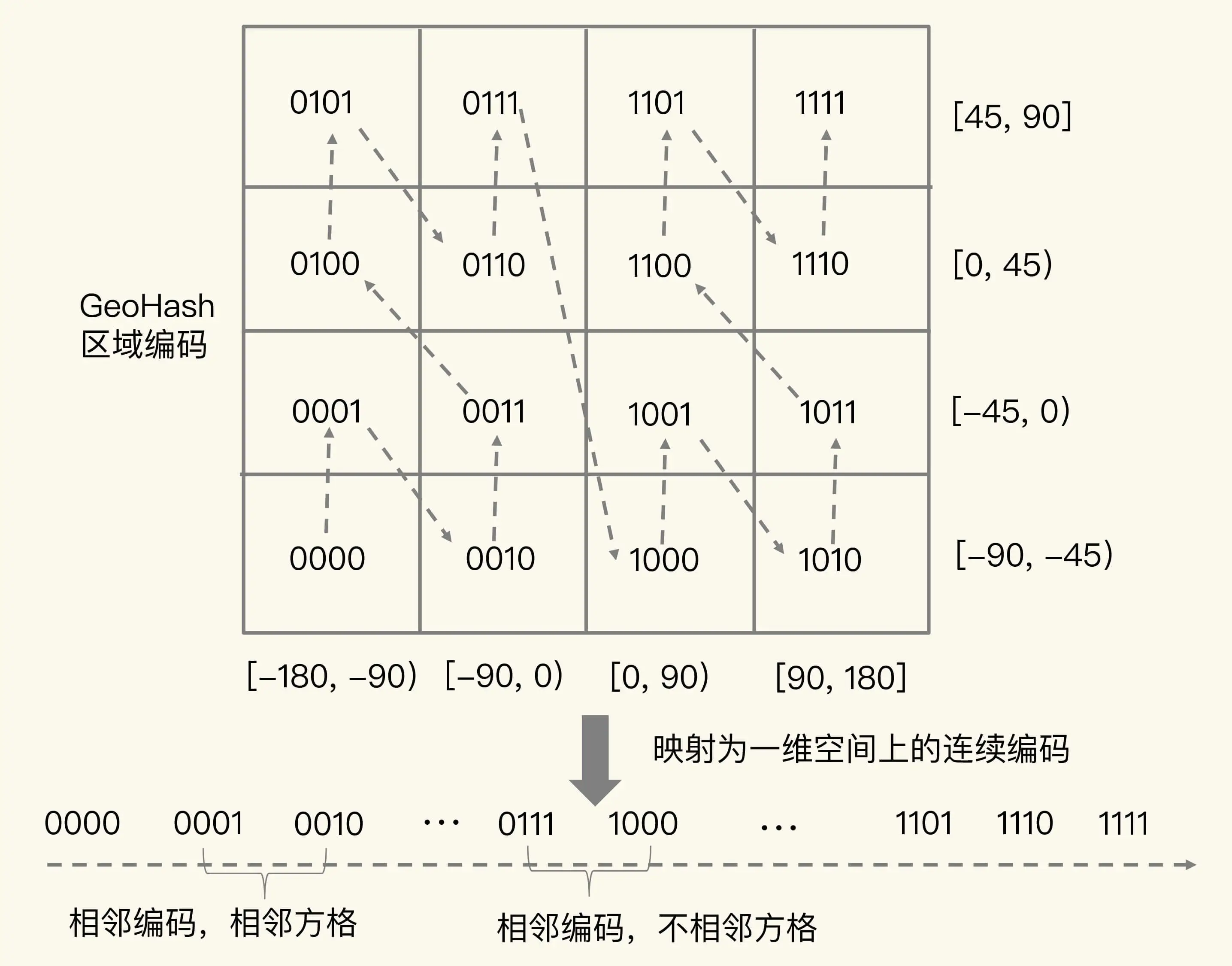
所以,为了避免查询不准确问题,我们可以同时查询给定经纬度所在的方格周围的 4 个或 8 个方格。
2. GEO 命令
GEOADD 命令用于把一组经纬度信息和相对应的一个 ID 记录到 GEO 类型集合中:
GEOADD key longitude latitude member [longitude latitude member ...]
GEOPOS 命令用于获取 GEO 类型集合中的元素:
GEOPOS key member [member ...]
GEODIST 命令用于获取两个地理位置的距离:
GEODIST key member1 member2 [m|km|ft|mi]
GEOHASH 命令会使用 GeoHash 编码将二维经纬度转换为一维字符串:
GEOHASH key member [member ...]
GEORADIUS、GEORADIUSBYMEMBER 命令会根据输入的经纬度位置,查找以这个经纬度为中心的一定范围内的其他元素。当然,我们可以自己定义这个范围:
GEORADIUS key longitude latitude radius[m|km|ft|mi]GEORADIUSBYMEMBER key member radius[m|km|ft|mi]

若有收获,就点个赞吧
0 人点赞
