会话管理
会话(Session)是 ZooKeeper 中最重要的概念之一,客户端与服务端间的任何交互操作都与会话息息相关,这其中就包括临时节点的生命周期、客户端请求的顺序执行以及 Watcher 通知机制等。
1. 会话状态
在 ZooKeeper 客户端与服务端成功完成连接创建后,就建立了一个会话。ZooKeeper 会话在整个运行期间的生命周期中,会在不同的会话状态之间进行切换,这些状态一般可以分为 CONNECTING、CONNECTED、RECONNECTING、RECONNECTED 和 CLOSE 等。
一旦客户端开始创建 ZooKeeper 对象,那么客户端状态就会变成 CONNECTING,同时客户端开始从上述服务器地址列表中逐个选取 IP 地址来尝试进行网络连接,直到成功连接上服务器,然后将客户端状态变更为 CONNECTED。
通常情况下,伴随着网络闪断或是其他原因,客户端与服务器之间的连接会出现断开情况。一旦碰到这种情况,ZooKeeper 客户端会自动进行重连操作,同时客户端的状态再次变为 CONNECTING,直到重新连接上 ZooKeeper 服务器后,客户端状态又会再次转变成 CONNECTED。因此,通常情况下,在 ZooKeeper 运行期间,客户端的状态总是介于 CONNECTING 和 CONNECTED 两者之一。另外,如果出现诸如会话超时、权限检查失败或是客户端主动退出程序等情况,那么客户端的状态会直接变为 CLOSE。
2. Session
Session 是 ZooKeeper 中的会话实体,代表了一个客户端会话。
public static class SessionImpl implements Session {final long sessionId;final int timeout;long tickTime;boolean isClosing;Object owner;}
- sessionId:会话 ID,用来唯一标识一个会话,每次客户端创建新会话时,ZooKeeper 都会为其分配一个全局唯一的 sessionld。
- timeout:会话超时时间。客户端在构造 ZooKeeper 实例时,会配置一个 sessionTimeout 参数用于指定会话的超时时间。ZooKeeper 客户端向服务器发送这个超时时间后,服务器会根据自己的超时时间限制最终确定会话的超时时间。如果客户端超时时间小于服务端超时时间,则采用客户端的超时时间管理会话。否则采用服务端设置的值管理会话。
- tickTime:下次会话超时时间点。为了便于 ZooKeeper 对会话实行分桶策略管理,同时也是为了高效低耗地实现会话的超时检查与清理,ZooKeeper 会为每个会话标记一个下次会话超时时间点。TickTime 是一个13 位的 long 型数据,其值接近于当前时间加上 timeout,但不完全相等。
- isClosing:该属性用于标记一个会话是否已经被关闭。通常当服务端检测到一个会话已经超时失效时,会将该会话的 isClosing 属性标记为已关闭,这样就能确保不再处理来自该会话的新请求了。
3. SessionTracker
SessionTracker 是 ZooKeeper 服务端的会话管理器,负责会话的创建、管理和清理等工作。可以说,整个会话的生命周期都离不开 SessionTracker 的管理。SessionTracker 是一个接口,其规定了 ZooKeeper 中会话管理的相关操作行为,具体实现是通过 SessionTrackerImpl 类来完成的。
public class SessionTrackerImpl extends ZooKeeperCriticalThread implements SessionTracker {// 用于根据sessionID来管理Session实体HashMap<Long, SessionImpl> sessionsById = new HashMap<Long, SessionImpl>();// 用于根据下次会话超时时间点来归档会话,便于进行会话管理和超时检查HashMap<Long, SessionSet> sessionSets = new HashMap<Long, SessionSet>();// 用于根据sessionID来管理会话的超时时间ConcurrentHashMap<Long, Integer> sessionsWithTimeout;}
SessionTracker 采用了一种特殊的会话管理方式,我们称之为分桶策略。在 ZooKeeper 中,会话将按照不同的时间间隔进行划分,超时时间相近的会话将被放在同一个间隔区间中,这种方式避免了 ZooKeeper 对每一个会话进行检查,而是采用分批次的方式管理会话。这就降低了会话管理的难度,因为每次小批量的处理会话过期也提高了会话处理的效率。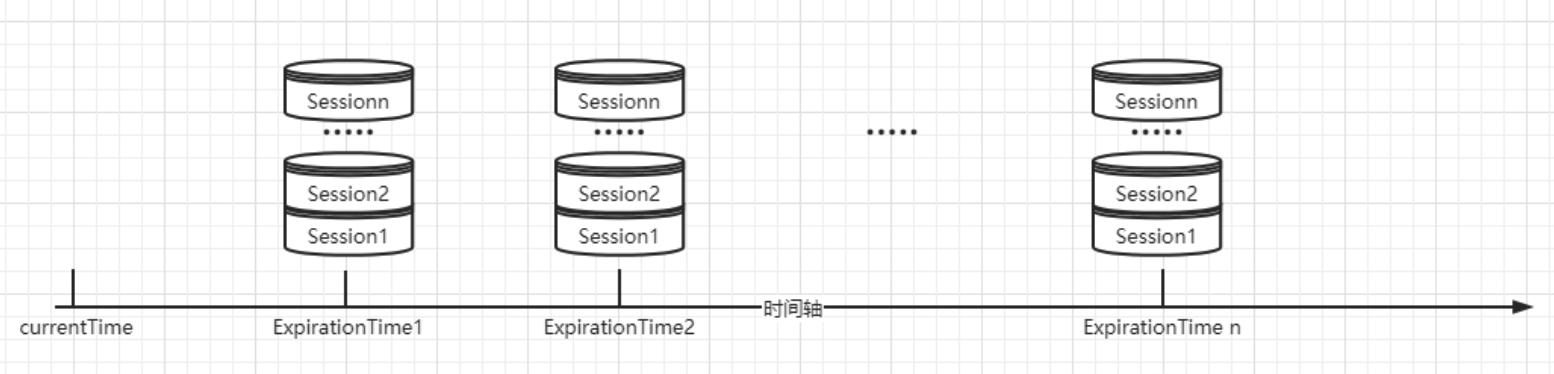
为保持客户端会话的有效性,在 ZooKeeper 的运行过程中,客户端会在会话超时时间过期范围内向服务端发送 PING 请求来保持会话的有效性,俗称心跳检测。同时,服务端需要不断地接收来自客户端的这个心跳检测,并且需要重新激活对应的客户端会话。会话激活的过程,不仅能够使服务端检测到对应客户端的存活性,同时也能让客户端自己保持连接状态。
在 ZooKeeper 中,会话超时检查同样是由 SessionTracker 负责的。SessionTracker 中有一个单独的线程专门进行会话超时检查,其工作机制非常简单:逐个依次地对会话桶中剩下的会话进行清理。在会话分桶策略中,我们依据下次超时时间点来分布会话,而且会话激活会将有效会话迁移到新的桶上去,因此超时检查线程只要在指定的时间点上进行检查即可。这样即提高了会话检查的效率,性能还非常好。
4. 会话清理
当 SessionTracker 的会话超时检查线程整理出一些已经过期的会话后,那么就要开始进行会话清理了。会话清理的步骤可大致分为以下几步:
1)标记会话状态为已关闭
由于整个会话清理过程需要一定时间,为了保证在此期间不再处理来自该客户端的新请求,SessionTracker 会首先将该会话的 isClosing 属性标记为 true。这样,即使在会话清理期间接收到该客户端的新请求,也无法继续处理了。
2)发起会话关闭请求
为了使对该会话的关闭操作在整个服务端集群中都生效,ZooKeeper 使用了提交“会话关闭”请求的方式,并立即交付给 PrepRequestProcessor 处理器进行处理。
3)收集需要清理的临时节点
在 ZooKeeper 中,一旦某个会话失效后,那么和该会话相关的临时(EPHEMERAL)节点都需要被一并清除掉。因此,在清理临时节点之前,首先需要将服务器上所有和该会话相关的临时节点都整理出来。在 ZooKeeper 的内存数据库中,为每个会话都单独保存了一份由该会话维护的所有临时节点集合,因此在会话清理阶段,只需要根据当前即将关闭的会话的 sessionId 从内存数据库中获取到这份临时节点列表即可。
4)删除临时节点
完成该会话相关的临时节点收集后,ZooKeeper 会逐个将这些临时节点转换成“节点删除”请求,并放入事务变更队列 outstandingChanges 中去。之后 FinalRequestProcessor 处理器会触发内存数据库,删除该会话对应的所有临时节点。
5)移除会话
完成节点删除后,需要将会话从 SessionTracker 中移除。主要就是从上面提到的三个数据结构中将该会话移除掉。最后,从 NIOServerCnxnFactory 找到该会话对应的 NIOServerCnxn,将其关闭。
会话创建请求过程
ZooKeeper 服务端对于会话创建的处理,大体可以分为请求接收、会话创建、预处理、事务处理、事务应用和会话响应六大环节,下面我们详细分析下具体流程。
1. 请求接收
首先,I/O 层会接收来自客户端的请求,在 ZooKeeper 中,NIOServerCnxn 实例维护每一个客户端连接,客户端与服务端的所有通信都是由 NIOServerCnxn 负责的,其负责统一接收来自客户端的所有请求,并将请求内容从底层网络 IO 中完整地读取出来。
每个会话都对应一个 NIOServerCnxn 实体。因此,对于每个请求,ZooKeeper 都会检查当前 NIOServerCnxn 实体是否已经被初始化。如果尚未被初始化,那么就可以确定该客户端请求一定是“会话创建” 请求。显然,在会话创建初期,NIOServerCnxn 尚未初始化,因此此时第一个请求必定是“会话创建”请求。
一旦确定当前客户端请求是“会话创建”请求,那么服务端就会对其进行反序列化生成一个 ConnectRequest 请求实体。然后,服务端根据客户端请求中是否包含 sessionld 来判断该客户端是否需要重新创建会话。如果客户端请求中已经包含了 sessionId,那就认为该客户端正在进行会话重连。此时,服务端只需要重新打开这个会话,否则需要重新创建会话。
2. 会话创建
在为客户端创建会话前,服务端会先通过 SessionTracker 为每个客户端都分配一个 sessionId。由于 sessionId 是 ZooKeeper 会话的一个重要标识,许多与会话相关的运行机制都是基于这个 sessionld 的,因此,无论是哪台服务器为客户端分配的 sessionId 都务必保证全局唯一。之后,就会将该客户端会话的相关信息注册到 SessionTracker 中,方便后续会话管理器进行管理。
3. 预处理
将请求交给 PrepRequestProcessor 处理器进行处理。ZooKeeper 对于每个客户端请求的处理模型采用了典型的责任链模式,即每个客户端请求都会由几个不同的请求处理器依次进行处理。
public class PrepRequestProcessor extends ZooKeeperCriticalThread implements RequestProcessor {LinkedBlockingQueue<Request> submittedRequests = new LinkedBlockingQueue<>();// 责任链private final RequestProcessor nextProcessor;}
对于事务请求,ZooKeeper 首先会为其创建请求事务头。请求事务头是每一个 ZooKeeper 事务请求中非常重要的一部分,服务端后续的请求处理器都是基于该请求头来识别当前请求是否是事务请求。请求事务头包含了一个事务请求最基本的信息,包括 sessionId、ZXID、CXID 和请求类型等。对于事务请求,ZooKeeper 还会为其创建请求的事务体。我们这里讨论的是“会话创建”请求,因此会创建事务体 CreateSessionTxn。
case OpCode.createSession:request.request.rewind();int to = request.request.getInt();request.setTxn(new CreateSessionTxn(to));request.request.rewind();// only add the global session tracker but not to ZKDbzks.sessionTracker.trackSession(request.sessionId, to);zks.setOwner(request.sessionId, request.getOwner());break;
4. 事务处理
完成对请求的预处理后,PrepRequestProcessor 处理器会将请求交给 ProposalRequestProcessor 处理器,这是一个与提案相关的处理器。所谓提案,是 ZooKeeper 中针对事务请求所展开的一个投票流程中对事务操作的包装。从该处理器开始,请求处理会进入三个子处理流程:Sync 流程、Proposal 流程和 Commit 流程。
4.1 Sync
Sync 流程的核心就是使用 SyncRequestProcessor 处理器记录事务日志的过程。ProposalRequestProcessor 处理器在接收到一个上级处理器流转过来的请求后,首先会判断该请求是否是事务请求。针对每个事务请求,都会通过事务日志的形式将其记录下来。Leader 和 Follower 服务器的请求处理链路中都有这个处理器,两者在事务日志的记录功能上是完全一致的。
完成事务日志记录后,每个 Follower 服务器都会向 Leader 服务器发送 ACK 消息,表明自身完成了事务日志的记录,以便 Leader 服务器统计每个事务请求的投票情况。
4.2 Proposal
在 ZooKeeper 的实现中,每一个事务请求都需要集群中过半机器投票认可才能被真正应用到 ZooKeeper 的内存数据库中去,这个投票与统计过程被称为 Proposal 流程。
如果当前请求是事务请求,那么 Leader 服务器就会发起一轮事务投票。在发起事务投票前,首先会检查当前服务端的 ZXID 是否可用。如果当前服务端的 ZXID 不可用,则会抛出 XidRolloverException 异常。
zks.getLeader().propose(request);
如果当前服务端的 ZXID 可用,那就可以开始事务投票了。ZooKeeper 会将之前创建的请求头和事务体,以及 ZXID 和请求本身序列化到 Proposal 对象中。这个 Proposal 对象就是一个提议,即针对 ZooKeeper 服务器状态的一次变更申请。生成提议后,Leader 服务器会以 ZXID 为标识将该提议放入 outstandingProposals 中,同时会将该提议广播给所有的 Follower 服务器。
public Proposal propose(Request request) throws XidRolloverException {......// 创建Proposal对象byte[] data = SerializeUtils.serializeRequest(request);proposalStats.setLastBufferSize(data.length);QuorumPacket pp = new QuorumPacket(Leader.PROPOSAL, request.zxid, data, null);Proposal p = new Proposal();p.packet = pp;p.request = request;synchronized (this) {......// 将该提议放入投票箱lastProposed = p.packet.getZxid();outstandingProposals.put(lastProposed, p);// 广播给所有的 FollowersendPacket(pp);}ServerMetrics.getMetrics().PROPOSAL_COUNT.add(1);return p;}
Follower 服务器在接收到 Leader 发来的这个提议后,会进入 Sync 流程来进行事务日志的记录,一旦日志记录完成后,就会发送 ACK 消息给 Leader 服务器,Leader 根据这些 ACK 消息来统计每个提议的投票情况。当一个提议获得了集群中过半机器的投票,那么就认为该提议通过。一旦 ZooKeeper 确认一个提议已经可以被提交了,那么 Leader 服务器就会向 Follower 和 Observer 服务器发送 COMMIT 消息,以便所有服务器都能够提交该提议。
public class ProposalRequestProcessor implements RequestProcessor {// 下一个处理器就是CommitProcessorRequestProcessor nextProcessor;SyncRequestProcessor syncProcessor;public void processRequest(Request request) throws RequestProcessorException {if (request instanceof LearnerSyncRequest) {zks.getLeader().processSync((LearnerSyncRequest) request);} else {// 发起commit调用nextProcessor.processRequest(request);if (request.getHdr() != null) {// 同步等待集群中各节点的投票结果try {zks.getLeader().propose(request);} catch (XidRolloverException e) {throw new RequestProcessorException(e.getMessage(), e);}syncProcessor.processRequest(request);}}}}
4.3 Commit
在 commit 阶段,ZooKeeper 会将请求交付给 CommitProcessor 处理器。CommitProcessor 处理器在收到请求后,并不会立即处理,而是会将其放入 queuedRequests 队列中。CommitProcessor 处理器会有一个单独的线程来处理这个队列中的请求。
如果从 queuedRequests 队列中取出的是一个事务请求,那就需要进行集群中各服务器间的投票处理,同时需要将 nextPending 标记为当前请求。标记 nextPending 的作用,一方面是为了确保事务请求的顺序性,另一方面也是便于 CommitProcessor 处理器检测当前集群中是否正在进行事务请求的投票。
while (!stopped && requestsToProcess > 0 && (maxReadBatchSize < 0 || readsProcessed <= maxReadBatchSize)
// 从queuedRequests队列中获取请求
&& (request = queuedRequests.poll()) != null) {
requestsToProcess--;
if (needCommit(request) || pendingRequests.containsKey(request.sessionId)) {
// 将请求标记为pending
Deque<Request> requests = pendingRequests.computeIfAbsent(request.sessionId, sid -> new ArrayDeque<>());
requests.addLast(request);
}
......
}
在 Commit 流程处理的同时,Leader 已经根据当前事务请求生成了一个提议 Proposal 并广播给了所有的 Follower 服务器。此时,Commit 流程需要等待,直到投票结束。如果一个提议已经获得了过半机器的投票,那么 ZooKeeper 会将该请求放入 committedRequests 队列中,同时唤醒 Commit 流程。
一旦发现 committedRequests 队列中已经有可以提交的请求了,那么 Commit 流程就会开始提交请求。当然在提交以前,为了保证事务请求的顺序执行,Commit 流程还会对比之前标记的 nextPending 和
committedRequests 队列中第一个请求是否一致。检查通过后 Commit 流程就会将该请求放入 toProcess 队列中,然后交给下一个请求处理器:FinalRequestProcessor。
5. 事务应用
请求流转到 FinalRequestProcessor 处理器后,会首先检查 outstandingChanges 队列中请求的有效性,如果发现这些请求已经落后于当前正在处理的请求,那么直接从 outstandingChanges 队列中移除。
outstandingChanges 队列中存放了当前 ZooKeeper 服务器正在进行处理的事务请求,以便 ZooKeeper 在处理后续请求的过程中需要针对之前的客户端请求的相关处理,例如对于“会话关闭”请求来说,其需要根据当前正在处理的事务请求来收集需要清理的临时节点。
在前面的请求处理逻辑中,我们仅仅是将该事务请求记录到了事务日志中,而内存数据库中的状态尚未变更。因此,在这个环节,我们需要将事务变更应用到内存数据库中。之后还会将该请求放入 commitProposal 队列中。该队列用来保存最近被提交的事务请求,以便集群间机器进行数据的快速同步。
6. 会话响应
客户端请求在经过 ZooKeeper 服务端处理链路的所有请求处照器的处理后,就进入最后的会话响应阶段。会话响应大致分为以下两个步骤。
- 统计处理,计算请求在服务端处理所花费的时间,同时还会统计客户端连接的一些基本信息。
- 创建 ConnectResponse 响应并发送给客户端
注意,为了保证事务请求被顺序执行,从而确保 ZooKeeper 集群的数据一致性,所有的事务请求必须由 Leader 服务器来处理,所有非 Leader 服务器如果接收到了来自客户端的请求,那么必须将其转发给 Leader 服务器来处理。
数据与存储
在 ZooKeeper 中,数据存储分为两部分:内存数据存储和磁盘数据存储。
1. 内存数据
ZooKeeper 的数据模型是一棵树,从使用角度看就像是一个内存数据库。在这个内存数据库中,存储了整棵树的内容,包括所有的节点路径、节点数据及其 ACL 信息等,ZooKeeper 会定时将这个数据存储到磁盘上。
DataTree 是 ZooKeeper 内存数据存储的核心,是一个 “树” 的数据结构,代表了内存中一份完整的数据。它不不包含任何与网络、客户端连接以及请求处理等相关的业务逻辑,是一个非常独立的组件。
public class DataTree {
// 存放了ZK上所有的数据节点,key为节点路径,value为节点内容
private final ConcurrentHashMap<String, DataNode> nodes = new ConcurrentHashMap<>();
private final WatchManager dataWatches = new WatchManager();
private final WatchManager childWatches = new WatchManager();
......
}
DataNode 是数据存储的最小单元,内部除了保存节点的数据内容、ACL 列表和节点状态之外,还记录了父节点的引用和子节点列表。同时还提供了对子节点列表操作的各个接口。
public class DataNode implements Record {
// 父节点
DataNode parent;
// 节点数据
byte data[];
Long acl;
// 节点状态
public StatPersisted stat;
// 子节点列表
private Set<String> children = null;
public synchronized boolean addChild(String child) {......}
public synchronized boolean removeChild(String child) {......}
public synchronized void setChildren(HashSet<String> children) {......}
public synchronized Set<String> getChildren() {......}
}
ZKDatabase 是 ZooKeeper 的内存数据库,负责管理 ZooKeeper 的所有会话、DataTree 存储和事务日志。它会定时向磁盘 dump 快照数据,同时在服务器启动时,会通过磁盘事务日志和快照数据文件恢复成一个完整的内存数据库。
public class ZKDatabase {
protected DataTree dataTree;
protected ConcurrentHashMap<Long, Integer> sessionsWithTimeouts;
protected FileTxnSnapLog snapLog;
protected long minCommittedLog, maxCommittedLog;
protected LinkedList<Proposal> committedLog = new LinkedList<Proposal>();
protected ReentrantReadWriteLock logLock = new ReentrantReadWriteLock();
}
2. 事务日志
在部署 ZooKeeper 集群时需要在 zoo.cfg 配置文件中配置一个目录:dataDir。这个目录是默认用于存储事务日志文件的。但其实在 ZooKeeper 中可以为事务日志单独分配一个文件存储目录:dataLogDir。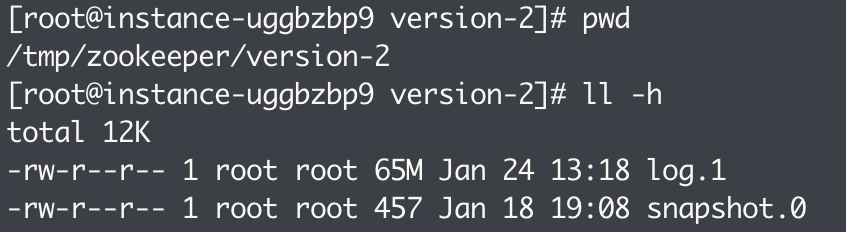
上图中的 log.1 文件即为 ZooKeeper 的事务日志。可以看到,文件大小固定为 64MB,写满后会生成一个新的日志文件。文件名后缀是一个十六进制数字,该后缀其实是一个事务 ID,即 ZXID,并且是写入该事务日志文件第一条事务记录的 ZXID。这可以帮助我们迅速定位到某一个事务操作所在的事务日志。同时,使用 ZXID 作为事务日志后缀的另一个优势是,ZXID 本身由两部分组成,高 32 位代表当前 Leader 周期,低 32 位则是真正的操作序列号。因此,将 ZXID 作为文件后缀,我们可以清楚地看出当前运行时 ZooKeeper 的 Leader 周期。
事务日志的内容是不可读的,为此 ZooKeeper 提供了一套简易的事务日志格式化工具 LogFormatter,用于将这个默认的事务日志文件转换成可视化的事务操作日志。
3. 数据快照
数据快照用来记录 ZooKeeper 服务器上某一时刻的全量内存数据内容,并将其写入到指定的磁盘文件中,它是数据存储中另一个非常核心的运行机制。和事务日志文件的命名规则一致,快照数据文件也是使用 ZXID 的十六进制表示来作为文件名后缀,该后缀标识了本次数据快照开始时刻的服务器最新 ZXID。在数据恢复阶段会根据该 ZXID 来确定数据恢复的起始点。
和事务日志文件不同的是,ZooKeeper 的快照数据文件没有采用“预分配”机制,因此不会像事务日志文件那样内容中包含大量的“0”。每个快照数据文件中的所有内容都是有效的,因此该文件的大小在一定程度上能够反映当前 ZooKeeper 内存中全量数据的大小。
快照数据文件的内容也是不可读的,为此 ZooKeeper 也提供了 SnapshotFormatter 用于将快照数据文件转换成可视化的数据内容。

若有收获,就点个赞吧
0 人点赞
