ZooKeeper 是一个高可用的分布式数据管理与协调框架。基于对 ZAB 算法的实现,该框架能够很好地保证分布式环境中数据的一致性。也正是基于这样的特性,使得 ZooKeeper 成为了解决分布式一致性问题的利器。
数据发布/订阅
数据发布/订阅(Publish/Subscribe)系统,即配置中心,就是发布者将数据发布到 ZooKeeper 的一个或一系列节点上,供订阅者进行数据订阅,进而达到动态获取数据的目的,实现配置信息的集中式管理以及数据的动态更新。
发布/订阅系统一般有两种设计模式,分别是推(Push)模式和拉(Poll)模式。在推模式中,服务端主动将数据更新发送给所有订阅的客户端;而拉模式则是由客户端主动发起请求来获取最新数据。ZooKeeper 采用的是推拉相结合的方式,客户端向服务端注册自己需要关注的节点,一旦该节点的数据发生变更,那么服务端就会向相应客户端发送 Watcher 事件通知,客户端接收到消息通知后,需要主动到服务端获取最新的数据。
如果将配置信息存放到 ZooKeeper 上进行集中管理,那么通常在应用启动的时候都会主动到 ZooKeeper 服务端上进行一次配置信息的获取,同时在指定节点上注册一个 Watcher 监听,当配置信息发生变更时,服务端会实时通知到所有订阅的客户端,从而达到实时获取最新配置信息的目的。
命名服务
在分布式系统中,被命名的实体通常可以是集群中的机器、提供的服务地址或远程对象等,其中较为常见的就是一些分布式服务框架(如 RPC)中的服务地址列表。通过使用命名服务,客户端应用能够根据指定名字来获取资源的实体、服务地址和提供者的信息等。
ZooKeeper 提供的命名服务功能能够帮助应用系统通过一个资源引用的方式来实现对资源的定位与使用。在分布式环境中,上层应用仅仅需要一个全局唯一的名字,类似于数据库中的唯一主键。因此,我们必须寻求一种能够在分布式环境下生成全局唯一 ID 的方法。
我们知道,通过调用 ZooKeeper 节点创建的 API 接口可以创建一个顺序节点,ZooKeeper 会自动在顺序节点后缀加上一个数字,并且在 API 返回值中会返回这个节点的完整名字。利用这个特性,我们就可以来生成全局唯一的 ID 了。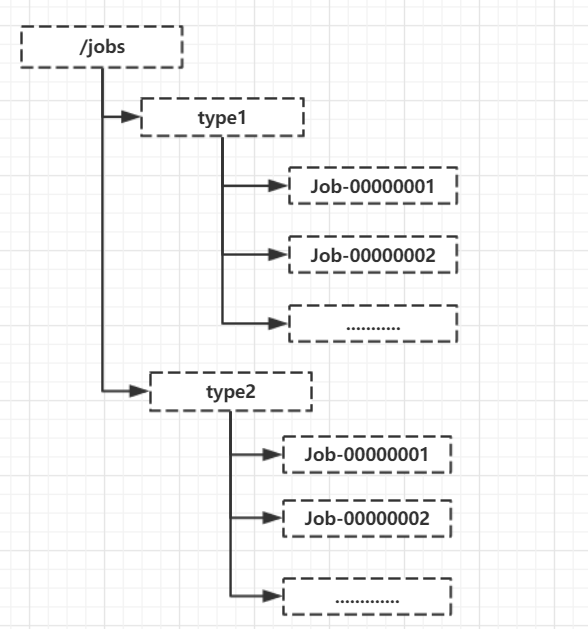
- 所有客户端都会根据自己的任务类型,在指定类型的任务下面通过调用 create() 接口来创建一个顺序节点,例如创建 “Job-“ 节点。
- 节点创建完毕后,create() 接口会返回一个完整的节点名,例如 “Job-00000001”。
- 客户端拿到这个返回值后,拼接上 type 类型,例如 “type1-Job-00000001”,这就可以作为一个全局唯一的 ID 了。
分布式协调/通知
分布式协调/通知服务可以将不同的分布式组件有机结合起来。对于一个在多台机器上部署运行的应用而言,通常需要一个协调者来控制整个系统的运行流程,例如分布式事务的处理、机器间的互相协调等。同时引入这样一个协调者,便于将分布式协调的职责从应用中分离出来,松耦合,提高系统可扩展性。
基于 ZooKeeper 实现分布式协调与通知功能,通常的做法是不同的客户端都对 ZooKeeper 上同一个数据节点进行 Watcher 注册,监听数据节点的变化,如果数据节点发生变化,那么所有订阅的客户端都能够接收到相应的 Watcher 通知,并做出相应处理。在绝大部分的分布式系统中,系统机器间的通信无外乎心跳检测、工作进度汇报和系统调度这三种类型。
1. 心跳检测
机器间的心跳检测机制是指在分布式环境中,不同机器之间需要检测到彼此是否在正常运行。在传统的开发中,我们通常是通过主机之间是否可以相互 PING 通来判断,更复杂一点的话则会通过在机器之间建立长连接,通过 TCP 连接固有的心跳检测机制来实现上层机器的心跳检测。
ZooKeeper 如何实现分布式机器间的心跳检测?
基于 ZooKeeper 的临时节点特性,可以让不同的机器都在 ZooKeeper 的一个指定节点下创建临时子节点,不同的机器之间可以根据这个临时节点来判断对应的客户端机器是否存活。因为临时节点是与客户端会话绑定的,客户端会话失效,临时节点则被移除。
2. 工作进度汇报
在一个常见的任务分发系统中,通常任务被分发到不同的机器上执行后,需要实时地将自己的任务执行进度汇报给分发系统。这个时候就可以通过 ZooKeeper 来实现。可以在 ZooKeeper 上选择一个节点,每个任务客户端都在这个节点下面创建临时子节点:
- 通过判断临时节点是否存在来确定任务机器是否存活。
- 各个任务机器会实时地将自己的任务执行进度写到这个临时节点上去,以便中心系统能够实时地获取到任务的执行进度。
3. 系统调度
任务内容被保存在 ZooKeeper 节点上,当我们执行一些指令,实际上就是修改了 ZooKeeper 上某些节点的数据,而 ZooKeeper 进一步把这些数据变更以事件通知的形式发送给了对应的订阅客户端。使用 ZooKeeper 来实现分布式系统机器间的通信,不仅能省去大量底层网络通信和协议设计上重复的工作,还大大降低了系统之间的耦合,方便实现异构系统之间的灵活通信。
集群管理
所谓集群管理,包括集群监控与集群控制两大块,前者侧重对集群运行时状态的收集,后者则是对集群进行操作与控制。ZooKeeper 的集群管理主要通过以下两大特性实现:
客户端如果对 ZooKeeper 的一个数据节点注册 Watcher 监听,那么当该数据节点的内容或是其子节点列表发生变更时,ZooKeeper 服务器就会向订阅的客户端发送变更通知。
对在 ZooKeeper 上创建的临时节点,一旦客户端与服务器间的会话失效,则该临时节点会被自动清除。
下面我们通过分布式日志收集系统这个例子来看如何使用 ZooKeeper 实现集群管理:
1)注册收集器机器
使用 ZooKeeper 来进行日志系统收集器的注册,典型做法是在 ZooKeeper 上创建一个节点作为收集器的根节点,例如 /logs/collector,每个收集器机器在启动的时候,都会在收集器节点下创建自己的节点,例如 /logs/collector/{hostname}。
2)任务分发
待所有收集器机器都创建好自己对应的节点后,系统根据收集器节点下子节点的个数,将所有日志源机器分成对应的若干组,然后将分组后的机器列表分别写到这些收集器机器创建的子节点上去。这样,每个收集器机器都能够从自己对应的收集器节点上获取日志源机器列表。
3)状态汇报
考虑到这些收集器随时都有挂掉的可能,因此我们需要有一个收集器的状态汇报机制。每个收集器在创建完自己的专属节点后,还要在对应子节点上创建一个状态子节点,例如 /logs/collector/{hostname}/status,每个收集器都需要定期向该节点写入自己的状态信息,日志系统根据该状态子节点的最后更新时间来判断对应收集器还是否存活。
4)动态分配
如果有收集器挂掉了或是进行了集群扩容,就需要动态地进行收集任务的分配。在运行过程中,日志系统始终关注着 /logs/collector 这个节点下所有子节点的变更,一旦检测到有收集器停止汇报或有新的收集器加入,就要开始进行任务的重新分配。
Master 选举
在分布式系统中,Master 往往用来协调集群中其他系统单元,具有对分布式系统状态变更的决定权。ZooKeeper 创建节点的 API 接口中有一个重要特性:ZooKeeper 会保证客户端无法重复创建一个已经存在的数据节点。这一特性很好地保证了在分布式高并发情况下节点创建的全局唯一性。
利用这个特性,当多个客户端同时向服务端创建同一数据节点时,创建成功的客户端机器即成为 Master。其他没有成功创建节点的客户端会在该节点上注册一个子节点变更的 Watcher,用于监控当前的 Master 机器是否存活,一旦发现当前的 Master 挂了,那么其余的客户端将会重新进行 Master 选举。
分布式锁
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。如果不同的系统或是同一个系统的不同主机之间共享了一组资源,那么访问这些资源的时候,往往需要通过一些互斥手段来防止彼此之间的干扰,以保证一致性,在这种情况下就需要使用分布式锁。
1. 借助 ZK 实现排他锁
在 ZooKeeper 中没有直接的 API 可以使用,而是通过 ZooKeeper 上的数据节点来表示一个锁。在需要获取排他锁时,所有客户端都会试图通过调用 create() 接口在某个指定路径,比如 /exclusive_lock 节点下创建临时子节点 /exclusive_lock/lock,ZooKeeper 会保证在所有的客户端中,最终只会有一个客户端能够创建成功,那么就可以认为该客户端获取了锁。同时,其他所有没有获取到锁的客户端注册该节点的监听器,以便实时监听到 lock 节点的变更情况。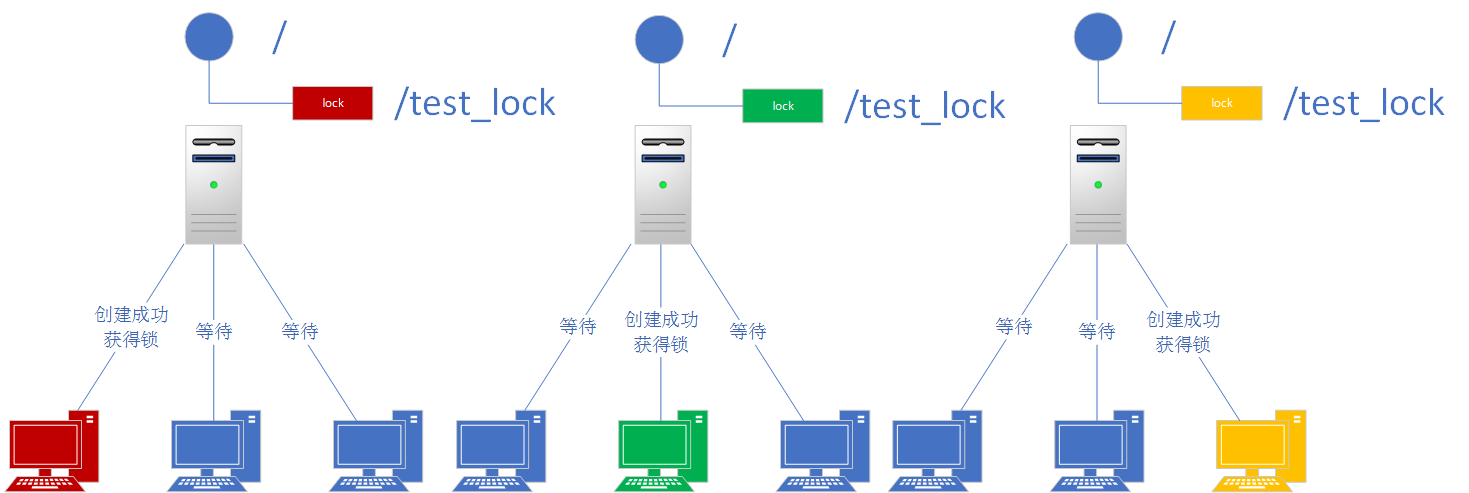
正常执行完业务逻辑后,客户端就会主动将自己创建的临时节点删除,其他客户端在接到 Watcher 通知后会再次重新发起分布式锁的获取。如果客户端在锁获取期间宕机了,由于创建的是临时节点,会话失效后临时节点也会被自动删除。
2. 借助 ZK 实现共享锁
和排他锁一样,同样是通过 ZooKeeper 上的数据节点来表示一个锁,是一个类似 /shared_lock/[Host]-请求类型-序号 的临时顺序节点,例如 /shared_lock/127.0.0.1-R-000001,该节点就代表了一个共享锁。
需要获取共享锁时,所有客户端都会在 /shared_lock 节点下创建一个临时顺序节点,如果是读请求就创建例如 /shared_lock/127.0.0.1-R-000001 的节点;如果是写请求就创建例如 /shared_lock/127.0.0.1-W-000001 的节点。
如何判断读写顺序:
- 创建完节点后,获取 /shared_lock 节点下的所有子节点,并对该节点注册子节点变更的 Watcher 监听
- 确定自己的节点序号在所有子节点中的顺序
- 对于读请求
- 如果没有比自己序号小的子节点,或所有比自己序号小的子节点都是读请求,则表明自己已经成功获取到了共享锁,同时开始执行读取逻辑。
- 如果比自己序号小的子节点中有写请求,那么就需要进入等待。
- 对于写请求
- 如果自己不是序号最小的子节点,那么就需要进入等待。
执行完相应逻辑后删除之前创建的子节点,代表释放锁。其他客户端接收到 Watcher 通知后再次获取锁。
3. 实现优化
当集群规模扩大以后,释放锁之后需要通知所有注册的 Watcher 来进行新一轮的锁获取。在整个分布式锁的竞争过程中,大量的 “Watcher 通知” 和 “子节点列表获取” 两个操作重复运行,并且绝大多数的运行结果都是判断出自己并非是序号最小的节点,从而继续等待下一次通知。因此会对 ZooKeeper 服务器造成巨大的性能影响和网络冲击。
更为严重的是,如果同一时间有多个节点对应的客户端完成事务或是事务中断引起节点消失,ZooKeeper 服务器就会在短时间内向其余客户端发送大量的事件通知——这就是所谓的羊群效应。基于此,我们对分布式锁方案进行一些优化:
- 客户端调用 create() 方法创建一个类似 “/shared_lock/[Host]-请求类型-序号” 的临时顺序节点。
- 客户端调用 getChildren() 接口获取所有已经创建的子节点列表,注意,这里不注册任何 Watcher。
- 如果无法获取共享锁,那么就调用 exist() 来对比自己小的那个节点注册 Watcher。
- 读请求:向比自己序号小的最后一个写请求节点注册 Watcher 监听。
- 写请求:向比自己序号小的最后一个节点注册 Watcher 监听。
分布式队列
1. FIFO
使用 ZooKeeper 实现 FIFO 队列和共享锁的实现非常类似:
- 所有客户端到 /queue_fifo 这个节点下创建一个临时顺序节点。
- 通过调用 getChildren() 获取 /queue_fifo 节点下的所有子节点。
- 确定自己的节点序号在所有子节点中的顺序。
- 如果自己不是序号最小的子节点就进入等待,同时向比自己序号小的最后一个节点注册 Watcher 监听。
- 接收到 Watcher 通知后,重复步骤 2。
2. Barrier
Barrier 在分布式系统中,特指系统之间的一个协调条件,规定了一个队列的元素必须都集聚后才能统一进行安排,否则一直等待。
- 开始时,/queue_barrier 节点是一个已经存在的默认节点,并且将节点的数据内容赋值为一个数字 n 来代表 Barrier 值。
- 通过调用 getChildren() 接口获取 /queue_barrier 节点下的所有子节点,同时注册对子节点列表变更的 Watcher 监听。
- 统计子节点个数。
- 如果节点个数不足 Barrier 值,那么就需要进入等待。
- 接收到 Watcher 通知,重复步骤 2。

若有收获,就点个赞吧
0 人点赞
