分析(Analysis)是把全文本转换成一系列单词(term、token)的过程。它是通过分析器(Analyzer)来实现的,我们可以使用 Elasticsearch 内置的分析器或按需使用自定义的分析器。除了在数据写入时需要对全文本进行分词,匹配 Query 语句时也需要用相同的分析器对查询语句进行分词。
Analyzer 组成
分析器(analyzer)是专门处理分词的组件,无论是内置的还是自定义的分析器都由三部分组成: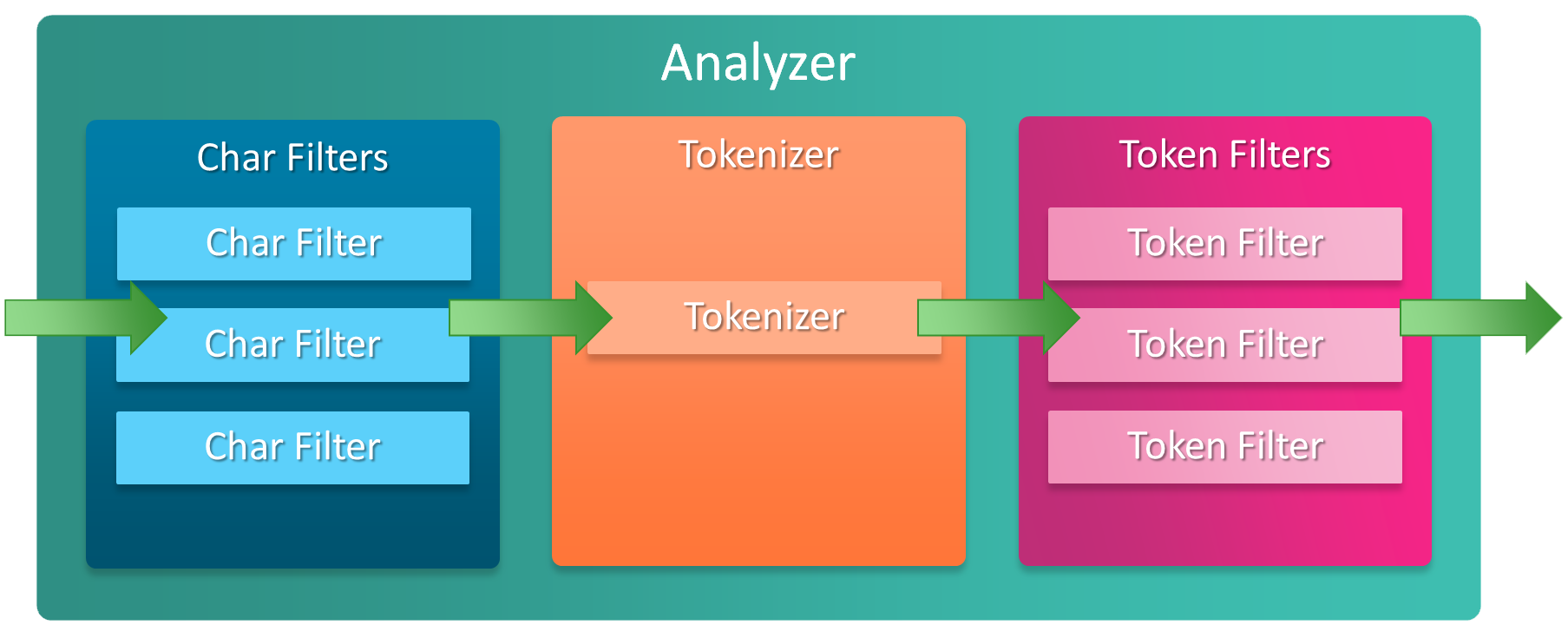
1. Character Filters
以字符流的形式接收原始文本并进行添加、删除或更改字符的预处理操作,可以配置多个。它会影响 Tokenizer 的 position 和 offset 信息。Elasticsearch 内置了丰富的 Character Filters 以帮助我们构建自定义分析器,具体如下:
1.1 mapping
可以通过 mappings 参数配置一组键和值的映射,格式为 key => value。每当遇到与键相同的字符串时,就用与该键相关联的值替换它们。使用示例如下:
curl -X PUT "localhost:9200/my_index?pretty" -H 'Content-Type: application/json' -d'{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "standard","char_filter": ["my_char_filter"]}},"char_filter": {"my_char_filter": {"type": "mapping","mappings": [":) => _happy_",":( => _sad_"]}}}}}'
进行分词测试:
curl -X POST "localhost:9200/my_index/_analyze?pretty" -H 'Content-Type: application/json' -d'{"analyzer": "my_analyzer","text": "I\u0027m delighted about it :("}'
分词结果为:
[ I'm, delighted, about, it, _sad_ ]
1.2 pattern_replace
可以通过 pattern 参数指定的正则表达式去匹配通过 replacement 参数指定的要替换的字符串。replacement 参数中可以通过 $1 ~ $9 引用正则表达式中匹配到的 group。使用示例如下:
curl -X PUT "localhost:9200/my_index?pretty" -H 'Content-Type: application/json' -d'{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "standard","char_filter": ["my_char_filter"]}},"char_filter": {"my_char_filter": {"type": "pattern_replace","pattern": "(\\d+)-(?=\\d)","replacement": "$1_"}}}}}'
进行分词测试:
curl -X POST "localhost:9200/my_index/_analyze?pretty" -H 'Content-Type: application/json' -d'{"analyzer": "my_analyzer","text": "My credit card is 123-456-789"}'
分词结果为:
[ My, credit, card, is, 123_456_789 ]
2. Tokenizer
Tokenizer 负责接收字符流并按照一定的规则将其分解为多个单词,还负责纪录每个单词的顺序和位置。 Elasticsearch 内置了丰富的 Tokenizer 以帮助我们构建自定义分析器,具体如下:
- standard:按单词进行分词
- letter:当遇到不是字母的字符时就进行分词
- lowercase:当遇到不是字母的字符时就进行分词并转小写
- whitespace:按空格分词
- uax_url_email:与 standard 类似,但它不会对 URL 和电子邮件地址进行分词
- keyword:不进行分词,直接将原文本输出
- pattern:使用正则表达式进行分词,默认为 \W+
- char_group:通过一组预定义单词进行分词,主要用于简单场景下的自定义标记
- path_hierarchy:根据路径分隔符进行分词,分词后得到的是完整的路径
-
3. Token Filters
对分解后的单词列表进行添加、删除、修改的操作,比如转小写,可配置多个。Elasticsearch 内置了丰富的 Token Filters 以帮助我们构建自定义分析器,具体如下:
length:通过 max 和 min 属性删除太长或太短的单词
- lowercase:将单词规范化为小写单词
- uppercase:将单词规范化为大写单词
- stop:过滤掉 stopwords 属性中的停用词列表中的单词
- keyword_marker:通过 keywords 属性指定一个关键字列表,在列表中的单词不受其他 token filter 的影响,注意该过滤器必须放在其他过滤器之前
- reverse:将单词进行反转
- truncate:将单词截断到指定长度,默认 length 为 10
- trim:去除单词前后的空格
- ……
内置分析器
内置的分析器可以在没有任何配置的情况下直接使用,有如下几种:1. Standard Analyzer
standard 分析器是在没有指定分析器时使用的默认分析器,它会对输入的文本按单词切分并进行小写处理。
分词后的词项如下:curl -X POST "localhost:9200/_analyze?pretty" -H 'Content-Type: application/json' -d'{"analyzer": "standard","text": "The 2 QUICK Brown-Foxes jumped over the lazy dog\u0027s bone."}'
[the, 2, quick, brown, foxes, jumped, over, the, lazy, dog's, bone]
该分析器组成如下:
- Tokenizer:Standard Tokenizer
- Token Filters:
- Lower Case Token Filter
- Stop Token Filter(默认关闭)
curl -X PUT "localhost:9200/standard_example?pretty" -H 'Content-Type: application/json' -d'{"settings": {"analysis": {"analyzer": {"rebuilt_standard": {"tokenizer": "standard","filter": ["lowercase"]}}}}}'
该分析器可接收以下参数项,使用示例如下:
- max_token_length:如果一个 token 超过这个长度,那么它将以该参数进行分隔,默认为 255。
- stopwords:一个预定义的停用词列表,默认为 none
- stopwords_path:包含停用词的文件路径,Elasticsearch 的 config 目录的相对路径
```bash
curl -X PUT “localhost:9200/my_index?pretty” -H ‘Content-Type: application/json’ -d’
{
“settings”: {
“analysis”: {
} } }’"analyzer": {"my_english_analyzer": {"type": "standard","max_token_length": 5,"stopwords": "_english_"}}
curl -X POST “localhost:9200/my_index/_analyze?pretty” -H ‘Content-Type: application/json’ -d’ { “analyzer”: “my_english_analyzer”, “text”: “The 2 QUICK Brown-Foxes jumped over the lazy dog\u0027s bone.” }’
分词后的结果为:
```json
[ 2, quick, brown, foxes, jumpe, d, over, lazy, dog's, bone ]
因为设置了 token 的最大长度为 5,所以 jumped 会被分为两部分;而且设置了 english 的停用词,所以 the 这种英文修饰词被去掉了。
2. Simple Analyzer
simple 分析器对输入的文本按照非字母切分,非字母的单词都被去除,之后再进行小写处理。
curl -X POST "localhost:9200/_analyze?pretty" -H 'Content-Type: application/json' -d'
{
"analyzer": "simple",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog\u0027s bone."
}'
分词后的词项如下:
[the, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone]
该分析器组成如下:
Tokenizer:Lower Case Tokenizer
curl -X PUT "localhost:9200/simple_example?pretty" -H 'Content-Type: application/json' -d' { "settings": { "analysis": { "analyzer": { "rebuilt_simple": { "tokenizer": "lowercase", "filter": [ ] } } } } }'3. Whitespace Analyzer
whitespace 分析器对输入的文本按照空白字符切分,不会进行小写转换。
curl -X POST "localhost:9200/_analyze?pretty" -H 'Content-Type: application/json' -d' { "analyzer": "whitespace", "text": "The 2 QUICK Brown-Foxes jumped over the lazy dog\u0027s bone." }'分词后的词项如下:
[The, 2, QUICK, Brown-Foxes, jumped, over, the, lazy, dog's, bone]该分析器组成如下:
Tokenizer:Whitespace Tokenizer
curl -X PUT "localhost:9200/whitespace_example?pretty" -H 'Content-Type: application/json' -d' { "settings": { "analysis": { "analyzer": { "rebuilt_whitespace": { "tokenizer": "whitespace", "filter": [ ] } } } } }'4. Stop Analyzer
stop 分析器与 simple 分析器类似,但是多了 stop filter,默认使用 english 停用词,因此会把 the、a、is 等英文修饰词去掉。
curl -X POST "localhost:9200/_analyze?pretty" -H 'Content-Type: application/json' -d' { "analyzer": "stop", "text": "The 2 QUICK Brown-Foxes jumped over the lazy dog\u0027s bone." }'分词后的词项如下:
[quick, brown, foxes, jumped, over, lazy, dog, s, bone]该分析器组成如下:
Tokenizer:Lower Case Tokenizer
- Token Filters:Stop Token Filter
curl -X PUT "localhost:9200/stop_example?pretty" -H 'Content-Type: application/json' -d' { "settings": { "analysis": { "filter": { "english_stop": { "type": "stop", "stopwords": "_english_" } }, "analyzer": { "rebuilt_stop": { "tokenizer": "lowercase", "filter": [ "english_stop" ] } } } } }'
该分析器可接收以下参数项:
- stopwords:一个预定义的停用词列表,默认为 english
stopwords_path:包含停用词的文件路径,Elasticsearch 的 config 目录的相对路径
5. Keyword Analyzer
keyword 分析器不会对文本内容进行分析,它会直接将文本当作一个 term 输出
curl -X POST "localhost:9200/_analyze?pretty" -H 'Content-Type: application/json' -d' { "analyzer": "keyword", "text": "The 2 QUICK Brown-Foxes jumped over the lazy dog\u0027s bone." }'分词后的词项如下:
[ The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.]该分析器组成如下:
Tokenizer:Keyword Tokenizer
curl -X PUT "localhost:9200/keyword_example?pretty" -H 'Content-Type: application/json' -d' { "settings": { "analysis": { "analyzer": { "rebuilt_keyword": { "tokenizer": "keyword", "filter": [ ] } } } } }'6. Pattern Analyzer
pattern 分析器使用正则表达式将文本拆分成单词,默认为 \W+,即非字符的符号。
curl -X POST "localhost:9200/_analyze?pretty" -H 'Content-Type: application/json' -d' { "analyzer": "pattern", "text": "The 2 QUICK Brown-Foxes jumped over the lazy dog\u0027s bone." }'分词后的词项如下:
[the, 2, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone]该分析器组成如下:
Tokenizer:Pattern Tokenizer
- Token Filters:
- Lower Case Token Filter
- Stop Token Filter(默认关闭)
curl -X PUT "localhost:9200/pattern_example?pretty" -H 'Content-Type: application/json' -d' { "settings": { "analysis": { "tokenizer": { "split_on_non_word": { "type": "pattern", "pattern": "\\W+" } }, "analyzer": { "rebuilt_pattern": { "tokenizer": "split_on_non_word", "filter": [ "lowercase" ] } } } } }'
该分析器可接收以下参数项:
- pattern:正则表达式,默认为 \W+
- lowercase:是否转小写,默认为 true
- stopwords:一个预定义的停用词列表,默认为 none
- stopwords_path:包含停用词的文件路径,Elasticsearch 的 config 目录的相对路径
7. Custom Analyzer
当 Elasticsearch 内置的分析器不能满足我们的要求时,我们可以自定义 custom 分析器,通过组合不同的组件实现。自定义分析器通常包含如下内容:
- 通过 char_filter 参数指定 0 或多个 Character Filters
- 通过 tokenizer 参数指定一个 Tokenizer
- 通过 filter 参数指定 0 或多个 Token Filters
如下示例:
curl -X PUT "localhost:9200/my_index?pretty" -H 'Content-Type: application/json' -d'
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "standard",
"char_filter": [
"html_strip"
],
"filter": [
"lowercase"
]
}
}
}
}
}'
中文分析器
ICU Analyzer
该分析器提供了 Unicode 的支持,更好的支持亚洲语言。但它不是 ES 内置的,所以需要先安装插件:
./elasticsearch-plugin install analysis-icu
IK
支持自定义词库,支持热更新分词字典。下载地址:https://github.com/medcl/elesticsearch-analysis-ik
THULAC
这个分析器是清华大学自然语言处理和社会人文计算实验室的一套中文分词器。下载地址:https://github.com/microbun/elesticsearch-thulac-plugin
HanLP
面向生产环境的自然语言处理工具包。下载地址:https://www.github.com/KennFalcon/elasticsearch-analysis-hanlp,支持如下 analyzer 类型:
- hanlp:hanlp 默认分词
- hanlp_standard:标准分词
- hanlp_index:索引分词
- hanlp_nlp:NLP 分词
- hanlp_n_short:N-最短路分词
- hanlp_dijkstra:最短路分词
- hanlp_speed:极速词典分词

若有收获,就点个赞吧
0 人点赞
