键过期
1. 设置键的过期时间
通过 EXPIRE 命令或者 PEXPIRE 命令,客户端可以以秒或毫秒精度为 Redis 中的某个键设置生存时间(Time To Live,TTL),在经过指定的秒数或毫秒数之后,Redis 就会自动删除生存时间为 0 的键。
# 键在seconds秒后过期EXPIRE [key] [seconds]# 键在milliseconds毫秒后过期PEXPIRE [key] [milliseconds]
与 EXPIRE 命令和 PEXPIRE 命令类似,客户端还可以通过 EXPIREAT 命令或 PEXPIREAT 命令,以秒或者毫秒精度给 Redis 中的某个键设置过期时间(Expire Time)。过期时间是一个 UNIX 时间戳,当键的过期时间来临时,Redis 会自动删除这个键。
# 键在秒级时间戳timestamp后过期EXPIREAT [key] [timestamp]# 键在毫秒级时间戳timestamp后过期PEXPIREAT [key] [timestamp]
此外,Redis 还提供了 TTL 和 PTTL 命令接收一个带有生存时间或过期时间的键,并返回这个键的剩余的生存时间。其中 TTL 以秒为单位返回键的剩余生存时间,而 PTTL 的精度更高,可以达到毫秒级别。
虽然有上面四种不同单位、不同形式的设置键过期的命令,但实际上 EXPIRE、PEXPIRE、EXPIREAT 这三个命令都是使用 PEXPIREAT 命令来实现的,即无论客户端使用的是哪一个命令,经过转换之后,最终的执行效果都和执行 PEXPIREAT 命令一样。
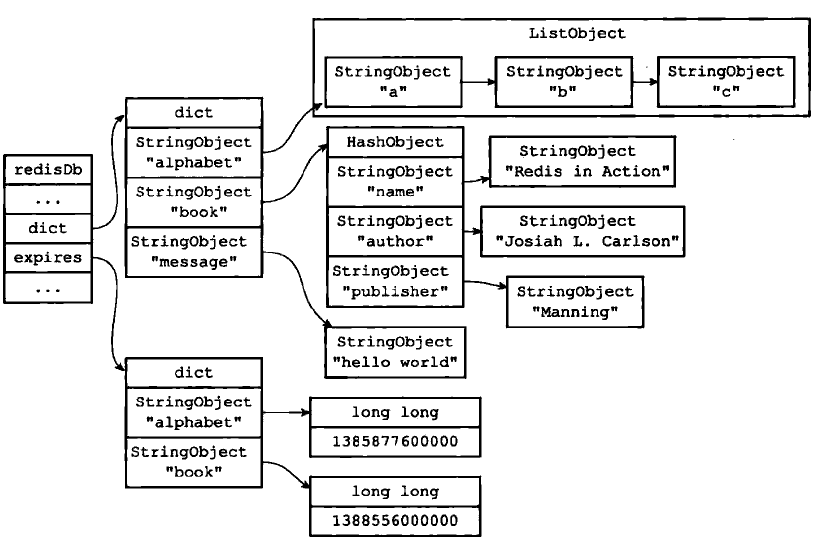
在 redisDb 结构的 expires 字典里保存了 Redis 数据库中所有键的过期时间,被称为过期字典。过期字典的键是一个指针,指向某个键对象,值是一个 long 类型整数,保存了键所指向的数据库键的过期时间——毫秒精度的 UNIX 时间戳。
typedef struct redisDb {dict *dict; /* The keyspace for this DB */dict *expires; /* Timeout of keys with a timeout set */...} redisDb;
2. 移除键的过期时间
PERSIST 命令可以移除一个键的过期时间,PERSIST 命令就是 PEXPIREAT 命令的反操作,它会在过期字典中查找给定的键,并解除键和值在过期字典中的关联。
3. 过期键删除策略
如果一个键过期了,那么它什么时候会被删除呢?这个问题有三种可能的答案,它们分别代表了三种不同的删除策略:
- 定时删除:在设置键的过期时间的同时,创建一个定时器,让定时器在键的过期时间来临时,立即执行对键的删除操作。
- 惰性删除:放任键过期不管,但每次获取键时先检查取得的键是否过期,如果过期就删除该键;如果没有过期,就返回该键。
- 定期删除:每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键。至于要删除多少过期键以及要检查多少个数据库,则由算法决定。
定时删除策略对内存是最友好的,它可以保证过期键会尽可能快地被删除,并释放过期键所占用的内存。但定时删除策略的缺点是,它对 CPU 时间是最不友好的。在过期键比较多的情况下,删除过期键这一行为可能会占用相当一部分 CPU 时间,在内存不紧张但是 CPU 时间非常紧张的情况下,将 CPU 时间用在删除和当前任务无关的过期键上,无疑会对服务器的响应时间和吞吐量造成影响。
惰性删除策略对 CPU 时间是最友好的,程序只会在取出键时才对键进行过期检查,这可以保证删除过期键的操作只会在非做不可的情况下进行,并且删除的目标仅限于当前处理的键,这个策略不会在删除其他无关的过期键上花费任何 CPU 时间。但它对内存是最不友好的,如果一个键已经过期但没有及时被删除,它所占用的内存就不会释放。
定期删除策略是前两种策略的一种整合和折中,定期删除策略每隔一段时间执行一次删除过期键操作,并通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。此外,通过定期删除过期键,定期删除策略有效地减少了因为过期键而带来的内存浪费。定期删除策略的难点是确定删除操作执行的时长和频率,太频繁的话会消耗过多 CPU 时间,太少则还是会出现浪费内存的情况。
Redis 服务器实际使用的是 惰性删除 和 定期删除 两种策略,所有读写 Redis 数据库的命令在执行之前都会对键进行检查以判断是否需要删除,定期删除则由 Redis 内部的定时任务执行,每隔 100 毫秒,Redis 就对数据库进行一次检查,它在规定时间内,分多次遍历服务器中的各个数据库,从数据库的过期字典中随机检查一部分键的过期时间,并删除里面的过期键。
这里是删除操作是阻塞的(Redis 4.0 后可以用异步线程机制来减少阻塞影响)。如果定期删除策略执行时有超过 25% 的键过期了,则会重复删除操作直到过期键的比例降至 25% 以下。因此,如果频繁使用带有相同时间参数的 EXPIREAT 命令设置过期键,就会导致在同一秒内有大量 key 同时过期,从而导致性能变慢。
4. 从库键的过期策略
从库不会进行键过期扫描的定时任务,从库对过期键的处理是被动的。主库在 key 到期时,会在 AOF 文件里增加一条 DEL 指令,同步到所有的从库,从库通过执行这条 DEL 指令来删除过期的 key。因为指令同步是异步进行的,所以主库过期的 key 的 DEL 指令没有及时同步到从库的话,会出现主从数据的不一致的情况,即主库没有的数据在从库里还存在。
键相关命令
1. KEYS
KEYS 命令用于返回和输入模式匹配的所有 key,例如,以下命令返回所有包含 “name” 字符串的 keys。
redis> KEYS *name*1) "lastname"2) "firstname"
因为 KEYS 命令需要遍历存储的键值对,所以操作延时高,容易引起 Redis 线程操作阻塞。因此 KEYS 命令一般不建议用于生产环境中。那在 Redis 中有哪些其他命令可以代替 KEYS 命令实现同样的功能呢?
2. SCAN
Redis 提供了 SCAN 命令,以及针对集合类型数据提供的 SSCAN、HSCAN 和 ZSCAN 命令,可以根据执行时设定的数量参数返回指定数量的数据,这就可以避免像 KEYS 命令一样同时返回所有匹配的数据。
如果想要获取整个实例所有匹配的 key,可以执行如下命令得到一批 key 以及下一个游标 $cursor,然后再把这个 $cursor 当作 SCAN 的参数再次执行,以此往复直到返回的 $cursor 为 0 时,就把整个实例中的所有 key 遍历出来了。注意,这里的 count 为服务器单次遍历的字典槽位数量,而不是返回结果的数量。
SCAN cursor [MATCH pattern] [COUNT count]
不过在 Redis Cluster 模式下不支持跨节点的 SCAN 操作,要想得到整个集群的 SCAN 结果,可以遍历每个节点分别进行 SCAN 操作,然后在客户端合并结果。
此外,我们还可以用 Hash Tag,也就是在键值对的 key 中使用花括号{},例如 {user:}1、{user:}2 这样。Redis Cluster 在对键做哈希的时候只会针对花括号中的部分进行哈希,这样可以把具有相同前缀的 key 分配到同一个哈希槽里面。不过,这个方法的潜在风险是:大量相同前缀的 key 被分配到同一个哈希槽里面了,会导致数据在哈希槽之间分布不均衡。如果要用这个方法,需要评估下 key 的分布情况。
排查 bigkey
在应用 Redis 时,我们要尽量避免 bigkey 的使用,因为 Redis 主线程在操作 bigkey 时会被阻塞。那么,一旦业务应用中使用了 bigkey,我们该如何进行排查呢?
Redis 可以在执行 redis-cli 命令时带上 —bigkeys 选项,用来对整个数据库中的键值对大小情况进行统计分析。比如,统计每种数据类型的键值对个数以及平均大小。此外,这个命令执行后,会输出每种数据类型中最大的 bigkey 的信息,对于 String 类型来说,会输出最大 bigkey 的字节长度,对于集合类型来说,会输出最大 bigkey 的元素个数,如下所示:
./redis-cli --bigkeys-------- summary -------Sampled 32 keys in the keyspace!Total key length in bytes is 184 (avg len 5.75)// 统计每种数据类型中元素个数最多的bigkeyBiggest list found 'product1' has 8 itemsBiggest hash found 'dtemp' has 5 fieldsBiggest string found 'page2' has 28 bytesBiggest stream found 'mqstream' has 4 entriesBiggest set found 'userid' has 5 membersBiggest zset found 'device:temperature' has 6 members// 统计每种数据类型的总键值个数,占所有键值个数的比例,以及平均大小4 lists with 15 items (12.50% of keys, avg size 3.75)5 hashs with 14 fields (15.62% of keys, avg size 2.80)10 strings with 68 bytes (31.25% of keys, avg size 6.80)1 streams with 4 entries (03.12% of keys, avg size 4.00)7 sets with 19 members (21.88% of keys, avg size 2.71)5 zsets with 17 members (15.62% of keys, avg size 3.40)
不过,在使用 —bigkeys 选项时,有一个地方需要注意一下。这个工具是通过扫描数据库来查找 bigkey 的,所以在执行过程中,会对 Redis 实例的性能产生影响。如果你在使用主从集群,建议你在从节点上执行该命令。因为主节点上执行时,会阻塞主节点。如果没有从节点,那么,建议你在 Redis 实例业务压力的低峰阶段进行扫描查询,以免影响到实例的正常运行;或者可以使用 -i 参数控制扫描间隔,避免长时间扫描降低 Redis 实例的性能。例如,我们执行如下命令时,redis-cli 会每扫描 100 次暂停 100 毫秒(0.1 秒)。
./redis-cli --bigkeys -i 0.1
当然,使用 Redis 自带的 —bigkeys 选项排查 bigkey 有两个不足的地方:
- 这个方法只能返回每种类型中最大的那个 bigkey,无法得到大小排在前 N 位的 bigkey;
- 对于集合类型来说,这个方法只统计集合元素个数的多少,而不是实际占用的内存量。但是,一个集合中的元素个数多,并不一定占用的内存就多。因为,有可能每个元素占用的内存很小,这样的话,即使元素个数有很多,总内存开销也不大。
所以,如果我们想统计每个数据类型中占用内存最多的前 N 个 bigkey,可以自己手动进行统计。具体做法是使用 SCAN 命令对数据库扫描,然后用 TYPE 命令获取返回的每一个 key 的类型。对于 String 类型,可以直接使用 STRLEN 命令获取字符串的长度,也就是占用的内存空间字节数。对于集合类型来说,有两种方法可以获得它占用的内存大小。
如果你能够预先从业务层知道集合元素的平均大小,那么,可以使用下面的命令获取集合元素的个数,然后乘以集合元素的平均大小,这样就能获得集合占用的内存大小了。
- List 类型:LLEN 命令;
- Hash 类型:HLEN 命令;
- Set 类型:SCARD 命令;
- Sorted Set 类型:ZCARD 命令;
如果你不知道写入集合的元素大小,可以使用 MEMORY USAGE 命令(需 Redis 4.0 及以上版本)查询一个键值对占用的内存空间。例如,执行以下命令,可以获得 key 为 user:info 这个集合类型占用的内存空间大小。
MEMORY USAGE user:info(integer) 315663239
这样一来,我们就可以把每一种数据类型中的占用内存空间大小排在前 N 位的 key 统计出来,这也就是每个数据类型中的前 N 个 bigkey。
此外,bigkey 的删除操作可能会产生较大性能问题。从 Redis 4.0 开始,我们可以使用 UNLINK 命令惰性删除大 Key;而对于 4.0 之前的版本,我们可以考虑使用游标删除大 Key 中的数据,而不是直接使用 DEL 命令,比如对于 Hash 使用 HSCAN + HDEL 结合管道功能来删除。
键的惰性删除
删除指令 DEL 会直接释放对象的内存,大部分情况下,这个指令非常快,没有明显延迟。但如果删除的 key 是一个非常大的对象,比如一个包含了上千万元素的 hash,那么删除操作就会导致单线程卡顿。Redis 为了解决这个问题,在 4.0 版本引入了键值对的惰性删除(lazy-free)和数据库异步清空操作,以避免主线程阻塞。
Redis 也提供了新的命令来执行这两个操作:
- 键值对删除:当你的集合类型中有大量元素需要删除时,建议你使用 UNLINK 命令。UNLINK 命令只是将键与键空间断开连接,实际的删除操作将会在稍后异步进行。
- 清空数据库:可以在 FLUSHDB 和 FLUSHALL 命令后加上 ASYNC 选项,这样就可以让后台子线程异步地清空数据库。
此外,关于惰性删除机制,还有 4 个选项可以控制在不同场景下是否要开启异步释放内存机制:
- lazyfree-lazy-expire:key 在过期删除时尝试异步释放内存
- lazyfree-lazy-eviction:内存达到 maxmemory 并设置了淘汰策略时尝试异步释放内存
- lazyfree-lazy-server-del:执行 RENAME、MOVE 等命令或需要覆盖一个 key 时,删除旧 key 时尝试异步释放内存
- replica-lazy-flush:主从全量同步,从库清空数据库时异步释放内存
不过,即便使用了惰性删除(lazy-free)相关的命令或开启了对应配置项后,也不是一定会异步释放内存。因为
Redis 在释放一个 key 的内存时,首先会评估代价,如果释放内存的代价很小,那么就直接在主线程中进行操作了,就没必要放到异步线程中执行了。评估过程会关注释放内存时的工作量有多大,如果需要释放的内存是连续的,Redis 认为释放内存的代价比较低,就会放在主线程执行。如果释放的内存不连续,这个代价就比较高,所以才会放在异步线程中去执行。

若有收获,就点个赞吧
0 人点赞
