Redis 服务器是典型的一对多服务器程序:一个服务器可以与多个客户端建立网络连接,每个客户端可以向服务器发送命令请求,而服务器则接收并处理客户端发送的命令清求,并向客户端返回命令回复。通过使用由 I/O 多路复用技术实现的文件事件处理器,Redis 服务器使用单线程单进程的方式来处理命令请求,并与多个客户端进行网络通信。
对于每个与服务器进行连接的客户端,服务器都为这些客户端建立了相应的 server.h/client 结构,这个结构保存了客户端当前的状态信息,以及执行相关功能时需要用到的数据结构,其中包括:
typedef struct client {// 客户端唯一IDuint64_t id;// 客户端网络连接connection *conn;// 指向客户端正在使用的数据库的指针redisDb *db;// 客户端名称,默认为空,可通过 CLIENT SETNAME 命令设置robj *name;// 输入缓冲区,用于保存客户端发送的命令请求sds querybuf;// 可变大小输出缓冲区list *reply;// 创建客户端的时间time_t ctime;// 客户端与服务器最后一次交互的时间time_t lastinteraction;// 记录了输出缓冲区第一次到达软性限制的时间time_t obuf_soft_limit_reached_time;// 客户端标志,记录了客户端的角色以及客户端目前所处的状态uint64_t flags;// buf缓冲区目前已使用的字节数int bufpos;// 输出缓冲区char buf[PROTO_REPLY_CHUNK_BYTES];} client;
客户端缓冲区
缓冲区在 Redis 中的一个主要应用场景,就是在客户端和服务器端之间进行通信时,用来暂存客户端发送的命令数据,或者是服务器端返回给客户端的数据结果。此外,缓冲区的另一个主要应用场景,是在主从节点间进行数据同步时,用来暂存主节点接收的写命令和数据。
为了避免客户端和服务器端的请求发送和处理速度不匹配,服务器端给每个连接的客户端都设置了一个输入缓冲区和输出缓冲区,我们称之为客户端输入缓冲区和输出缓冲区。输入缓冲区会先把客户端发送过来的命令暂存起来,Redis 主线程再从输入缓冲区中读取命令,进行处理。当 Redis 主线程处理完数据后,会把结果写入到输出缓冲区,再通过输出缓冲区返回给客户端,如下图所示: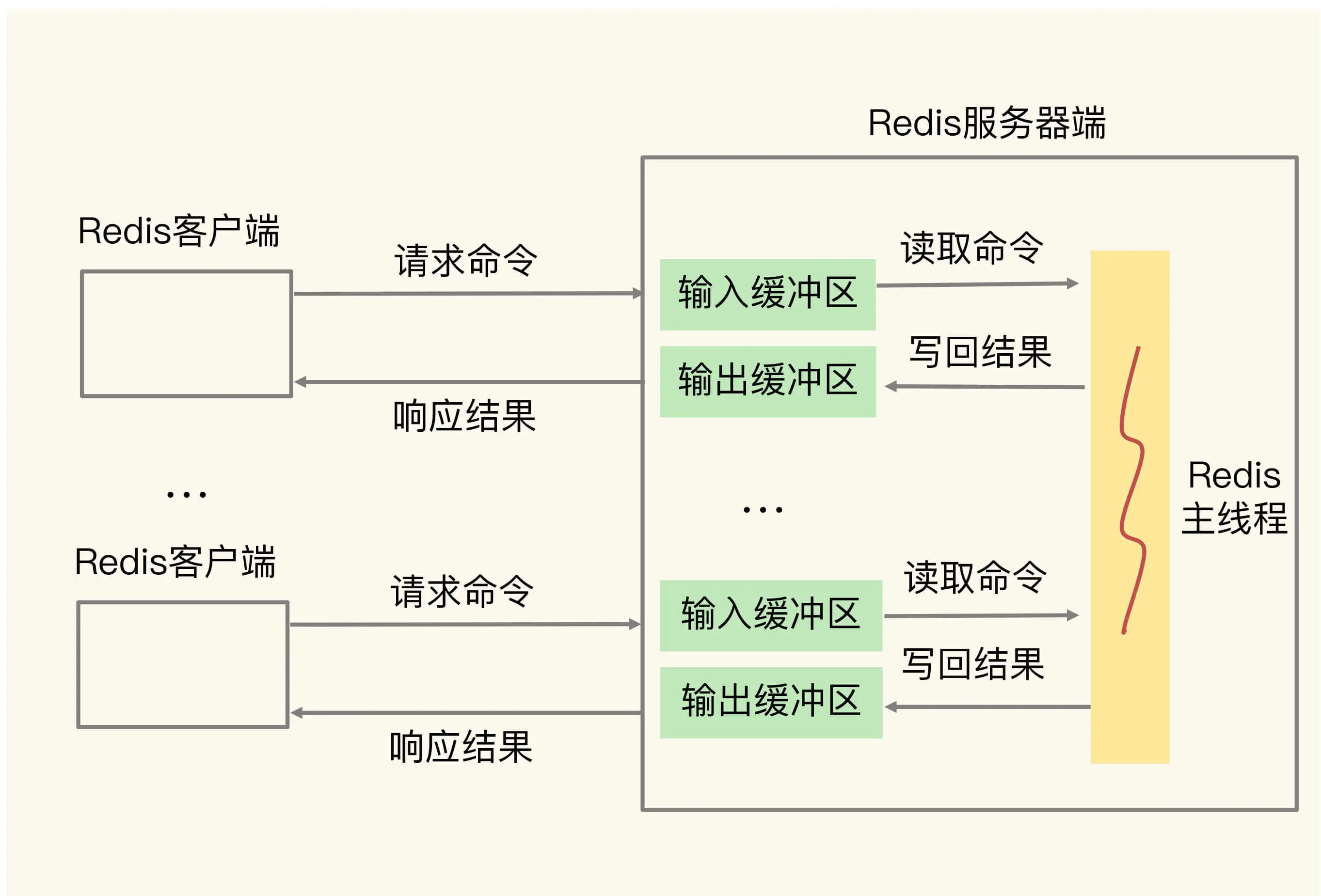
但因为缓冲区的内存空间有限,如果往里面写入数据的速度持续地大于从里面读取数据的速度,就会导致缓冲区需要越来越多的内存来暂存数据。当缓冲区占用的内存超出了设定的上限阈值时,就会出现缓冲区溢出。缓冲区溢出不仅会导致数据丢失,还可能会导致 Redis 实例崩溃。
1. 客户端输入缓冲区
typedef struct client {// 输入缓冲区,用于保存客户端发送的命令请求sds querybuf;......} client;
输入缓冲区的大小会根据输入内容动态地缩小或扩大,但它的最大大小不能超过 1 GB,否则服务器将关闭这个客户端。而可能导致客户端输入缓冲区溢出的情况主要是下面两种:
- 写入了 bigkey,比如一下子写入了多个百万级别的集合类型数据;
- 服务器端处理请求的速度过慢,例如,Redis 主线程出现了间歇性阻塞,无法及时处理正常发送的请求,导致客户端发送的请求在缓冲区越积越多。
要查看和服务器端相连的每个客户端对输入缓冲区的使用情况,我们可以使用 CLIENT LIST 命令:
CLIENT LISTid=5 addr=127.0.0.1:50487 fd=9 name= age=4 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=26 qbuf-free=32742 obl=0 oll=0 omem=0 events=r cmd=client
我们需要重点关注 CLIENT 命令返回的这两类信息:一类是与服务器端连接的客户端的信息。这个案例展示的是一个客户端的输入缓冲区情况,如果有多个客户端,输出结果中的 addr 会显示不同客户端的 IP 和端口号。另一类是与输入缓冲区相关的三个参数:
- cmd:表示客户端最新执行的命令,这个例子中执行的是 CLIENT 命令。
- qbuf:表示输入缓冲区已经使用的大小,这个例子中已使用了 26 字节大小的缓冲区。
- qbuf-free:表示输入缓冲区尚未使用的大小,这个例子中还可以使用 32742 字节的缓冲区。
通过 CLIENT LIST 命令,我们可以知道客户端输入缓冲区的内存占用情况。如果 qbuf 很大同时 qbuf-free 很小,就要引起注意了,因为这时候输入缓冲区已经占用了很多内存,而且没有什么空闲空间了。此时,客户端再写入大量命令的话,就会引起客户端输入缓冲区溢出,导致 Redis 关闭该客户端连接。
通常 Redis 服务器端不止服务一个客户端,当多个客户端连接占用的内存总量,超过了 maxmemory 配置项时就会触发 Redis 进行数据淘汰。更糟糕的是,如果使用多个客户端导致 Redis 内存占用过大,也会导致内存溢出问题,进而会引起 Redis 崩溃。所以,我们必须想办法避免输入缓冲区溢出,但单个客户端的输入缓冲区的上限阈值固定为 1GB,无法调节。要避免输入缓冲区溢出,我们只能从数据命令的发送和处理速度入手,也就是避免客户端写入 bigkey 以及避免 Redis 主线程阻塞。
2. 客户端输出缓冲区
执行命令所得的命令回复会被保存在客户端状态的输出缓冲区里,每个客户端都有两个输出缓冲区可用,一个缓冲区的大小是固定的,另一个缓冲区的大小是可变的:
- 固定大小的缓冲区用于保存那些长度比较小的回复,比如 OK、简短的字符值、整数值、错误回复等。
- 可变大小的缓冲区用于保存那些长度比较大的回复,比如一个包含了很多元素的集合等。
客户端的固定大小缓冲区由 buf 和 bufpos 两个属性组成,其中 buf 数组的默认大小为 16 KB:
typedef struct client {// 可变大小输出缓冲区list *reply;// buf缓冲区目前已使用的字节数int bufpos;// 输出缓冲区char buf[PROTO_REPLY_CHUNK_BYTES];......} client;
当 buf 数组的空间已经用完,或者回复因为太大而没办法放进 buf 数组里面时,服务器就会开始使用可变大小缓冲区。可变大小缓冲区由 reply 链表和一个或多个字符串对象组成,通过使用链表来连接多个字符串对象,服务器可以为客户端保存一个非常长的命令回复,而不必受到固定大小缓冲区 16 KB 大小的限制。
虽然,可变大小缓冲区由一个链表和任意多个字符串对象组成,理论上可以保存任意长的命令回复。但是,为了避免客户端的回复过大,占用过多的服务器资源,服务器会时刻检查客户端的输出缓冲区的大小,并在缓冲区的大小超出范围时,执行相应的限制操作。
服务器使用两种模式来限制客户端输出缓冲区的大小:
- 硬性限制(hard limit):如果输出缓冲区大小超过了硬性限制所设置的大小,服务器会立即关闭客户端。
- 软性限制(soft limit):如果输出缓冲区的大小超过了软性限制所设置的大小但还没超过硬性限制,那么服务器将使用 server.h/client 结构中的 obuf_soft_limit_reached_time 属性记录下客户端到达软性限制的起始时间;之后服务器会继续监视客户端,如果输出缓冲区的大小一直超出软性限制,并且持续时间超过服务器设定的时长,那么服务器将关闭客户端;相反地,如果输出缓冲区的大小在指定时间内,不再超出软性限制,那么客户端就不会被关闭,并且 obuf_soft_limit_reached_time 属性的值也会被清零。
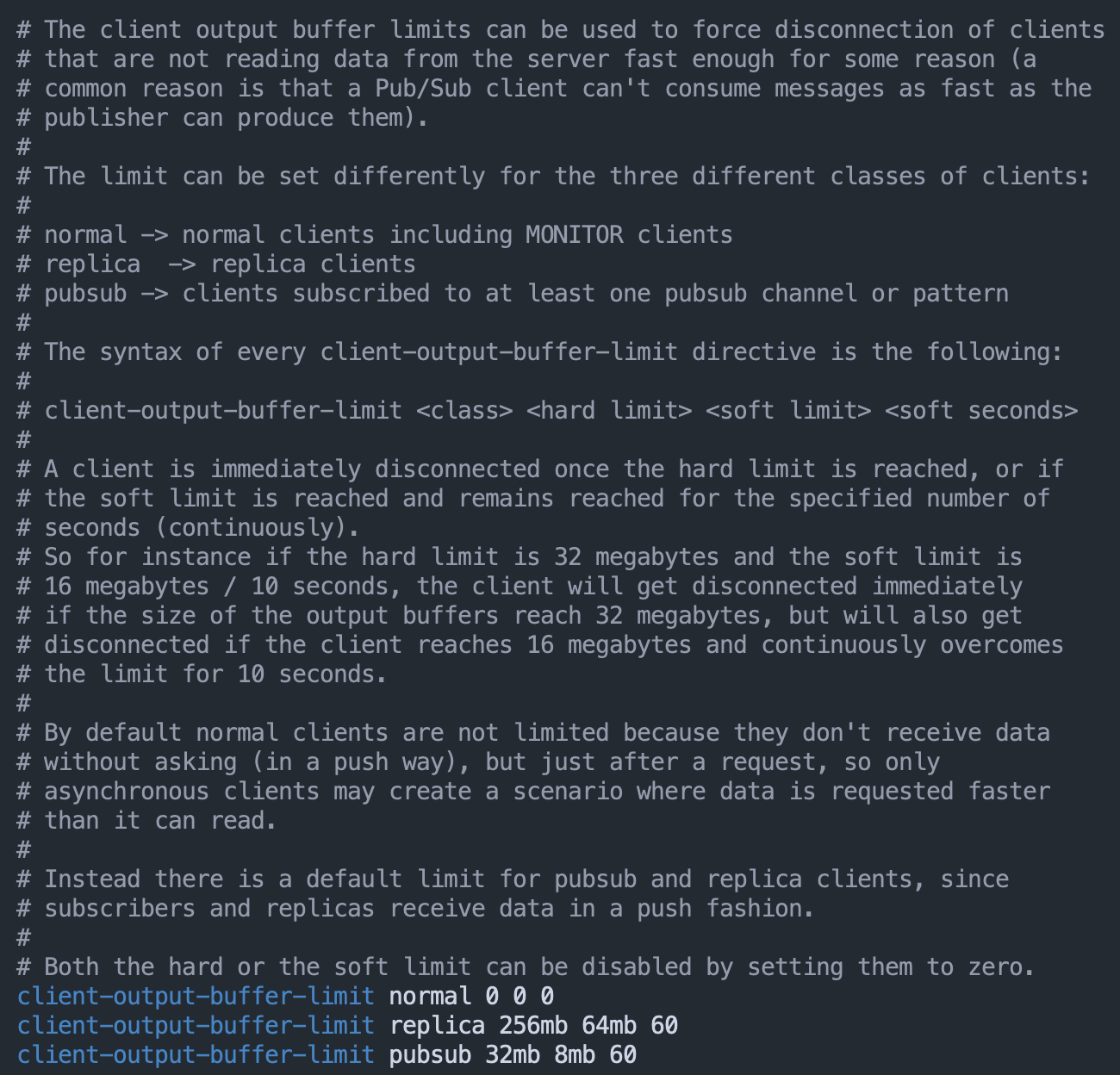
我们可以通过 client-output-buffer-limit 配置项来为客户端输出缓冲区设置硬性限制和软性限制。具体设置的内容包括两方面:
- 设置缓冲区大小的上限阈值;
- 设置输出缓冲区持续写入数据的数量上限阈值,和持续写入数据的时间的上限阈值。
在使用 client-output-buffer-limit 来设置缓冲区大小时,我们需要先区分下客户端的类型。对于和 Redis 实例进行交互的应用程序来说,主要使用两类客户端和 Redis 服务器端交互,分别是常规和 Redis 服务器端进行读写命令交互的 普通客户端,以及订阅了 Redis 频道的 订阅客户端。此外,在 Redis 主从集群中,主节点上也有一类客户端(从节点客户端)用来和从节点进行数据同步。
2.1 普通客户端
当我们给普通客户端设置缓冲区大小时,通常可以在 Redis 配置文件中进行这样的设置:
client-output-buffer-limit normal 0 0 0
其中,normal 表示当前设置的是普通客户端,第 1 个 0 设置的是缓冲区大小限制,第 2 个 0 和第 3 个 0 分别表示缓冲区持续写入量限制和持续写入时间限制。
对于普通客户端来说,它每发送完一个请求,会等到请求结果返回后,再发送下一个请求,这种发送方式称为阻塞式发送。在这种情况下,如果不是读取体量特别大的 bigkey,服务器端的输出缓冲区一般不会被阻塞。所以,我们通常把普通客户端的缓冲区大小限制,以及持续写入量、持续写入时间限制都设为 0,也就是不限制。
2.2 订阅客户端
对于订阅客户端来说,一旦订阅的 Redis 频道有消息了,服务器端都会通过输出缓冲区把消息发给客户端。所以订阅客户端和服务器间的消息发送方式,不属于阻塞式发送。不过,如果频道消息较多的话,也会占用较多的输出缓冲区空间。因此,我们会给订阅客户端进行如下设置:
client-output-buffer-limit pubsub 32mb 8mb 60
其中,pubsub 参数表示当前是对订阅客户端进行设置,32mb 表示输出缓冲区的大小上限为 32MB,一旦实际占用的缓冲区大小要超过 32MB,服务器端就会直接关闭客户端的连接;8mb 和 60 表示,如果连续 60 秒内对输出缓冲区的写入量超过 8MB 的话,服务器端也会关闭客户端连接。
2.3 从节点客户端
在全量复制过程中,主节点在向从节点传输 RDB 文件的同时,会继续接收客户端发送的写命令请求。这些写命令就会先保存在复制缓冲区中,等 RDB 文件传输完成后,再发送给从节点去执行。主节点会为每个从节点都维护一个复制缓冲区,来保证主从节点间的数据同步。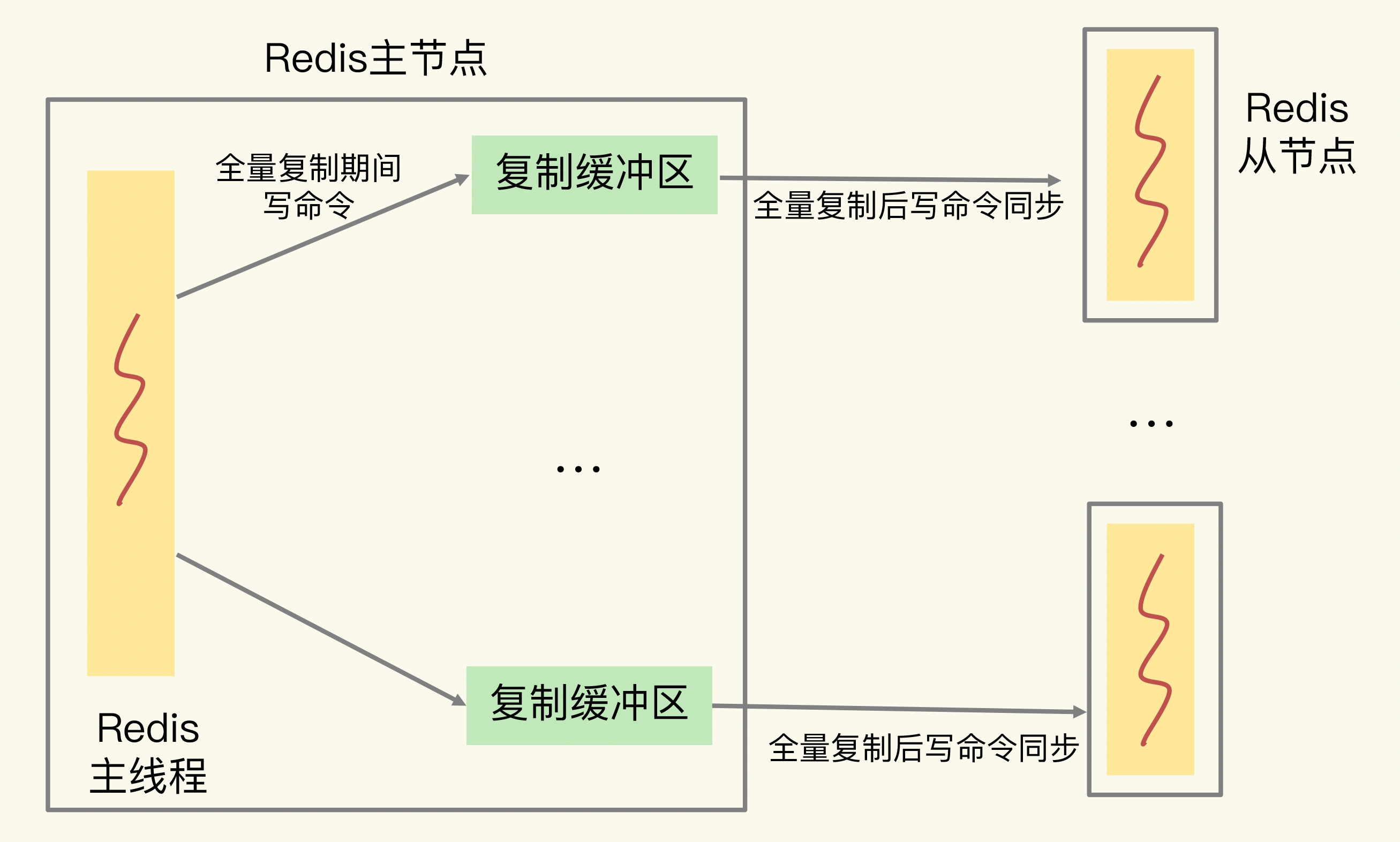
所以,如果在全量复制时,从节点接收和加载 RDB 较慢,同时主节点接收到了大量的写命令,写命令在复制缓冲区中就会越积越多,最终导致溢出。
其实,主节点上的复制缓冲区,本质上也是一个用于和从节点连接的客户端(我们称之为从节点客户端)使用的输出缓冲区。复制缓冲区一旦发生溢出,主节点也会直接关闭和从节点进行复制操作的连接,导致全量复制失败。那如何避免复制缓冲区发生溢出呢?
一方面,我们可以控制主节点保存的数据量大小。按通常的使用经验,我们会把主节点的数据量控制在 2~4GB,这样可以让全量同步执行得更快些,避免复制缓冲区累积过多命令。另一方面,我们可以使用 client-output-buffer-limit 配置项来设置合理的复制缓冲区大小。
client-output-buffer-limit slave 256mb 64mb 60
其中,slave 参数表明该配置项是针对复制缓冲区的。256mb 代表将缓冲区大小的上限设置为 256MB;64mb 和 60 代表的设置是,如果连续 60 秒内的写入量超过 64MB 的话,也会触发缓冲区溢出。

若有收获,就点个赞吧
0 人点赞
