性能基线测试
从 Redis 2.8.7 版本开始,redis-cli 命令提供了 —intrinsic-latency 选项,可以用来监测和统计测试期间内的最大延迟,这个延迟可作为 Redis 的基线性能。其中,测试时长可用 —intrinsic-latency 选项的参数指定。
比如我们运行下面的命令:
./redis-cli --intrinsic-latency 120
该命令会打印 120 秒内监测到的最大延迟。可以看到最大延迟是 679 微秒,因此,基线性能为 679 微秒。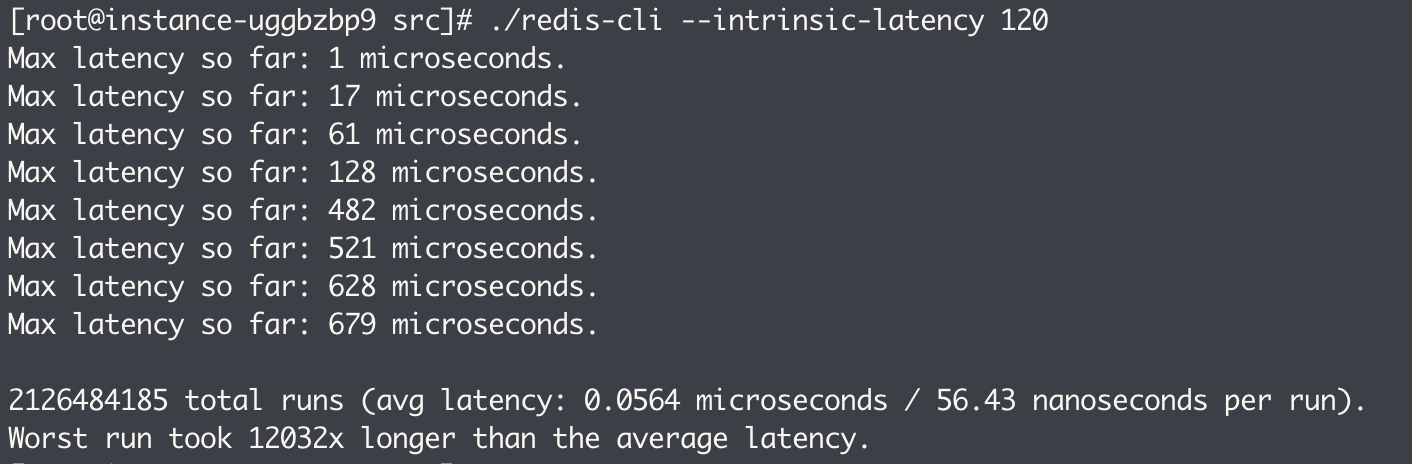
需要注意的是,基线性能和当前的操作系统、硬件配置相关。因此,我们可以把它和 Redis 运行时的延迟结合起来,再进一步判断 Redis 性能是否变慢了。一般来说,你要把运行时延迟和基线性能进行对比,如果你观察到的 Redis 运行时延迟是其基线性能的 2 倍及以上,就可以认定 Redis 变慢了。
判断基线性能这一点,对于在虚拟化环境下运行的 Redis 来说非常重要。因为在虚拟化环境中,由于增加了虚拟化软件层(虚拟机或容器),那么与物理机相比,虚拟机或容器本身就会引入一定的性能开销,所以基线性能会高一些。因此,在虚拟化环境中,Redis 的基线性能的延迟会高一点。
不过,我们通常是通过客户端和网络访问 Redis 服务,为了避免网络对基线性能的影响,这个命令需要在服务器端直接运行,这也就是说,我们只考虑服务器端软硬件环境的影响。如果想了解网络对 Redis 性能的影响,一个简单的方法是用 iPerf 这样的工具,测量从 Redis 客户端到服务器端的网络延迟。如果这个延迟有几十毫秒甚至几百毫秒,就说明 Redis 运行的网络环境中很可能有大流量的其他应用在运行,导致了网络拥塞。
慢查询日志
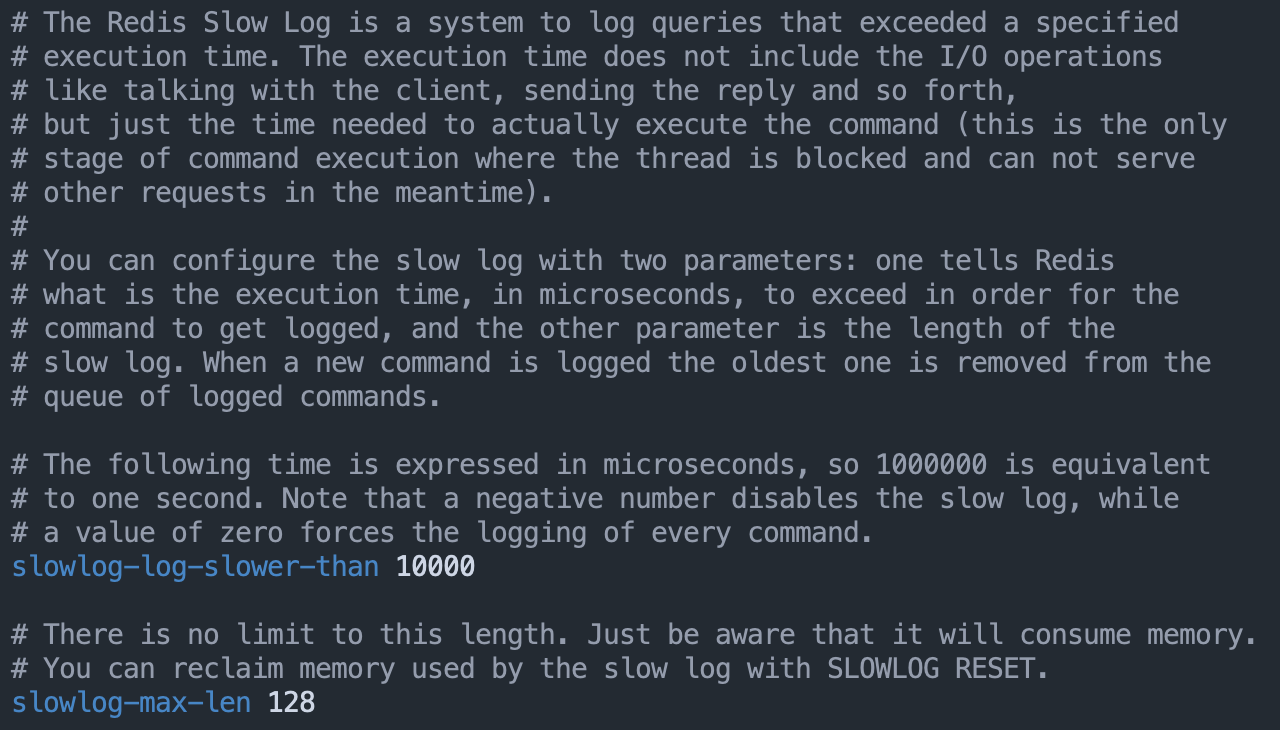
Redis 的慢查询日志功能用于记录执行时间超过给定时长的命令请求,用户可以通过这个功能产生的日志来监视和优化查询速度。redis.conf 配置文件中有两个和慢查询日志相关的配置项:
slowlog-log-slower-than 选项指定执行时间超过多少微秒的命令请求会被记录到日志上。
slowlog-max-len 选项指定服务器最多保存多少条慢查询日志。服务器使用先进先出的方式保存多条慢查询日志,当达到最大值后,服务器在添加一条新日志前,会先将最旧的一条慢查询日志删除。
此外,Redis 还提供了如下命令用来操作慢查询日志:
# 获取慢查询日志SLOWLOG GET# 获取慢查询日志列表当前的长度SLOWLOG LEN# 重置慢查询日志SLOWLOG RESET
监视器
通过执行 MONITOR 命令,客户端可以将自己变为一个监视器,实时地接收并打印出服务器当前处理的命令请求的相关信息。每当一个客户端向服务器发送一条命令请求时,服务器除了会处理这条命令请求外,还会将关于这条命令请求的信息发送给所有监视器。
执行 MONITOR 命令后会持续输出监测到的各个命令操作,因此 MONITOR 的输出结果会持续占用客户端的输出缓冲区,如果持续监控最终可能导致溢出。所以,MONITOR 命令主要用在调试环境中,不要在线上生产环境中持续使用 MONITOR。当然,偶尔使用 MONITOR 检查 Redis 的命令执行情况是没问题的。
INFO 命令
在使用 Redis 时,时常会遇到很多问题需要诊断,在诊断之前需要了解 Redis 的运行状态,通过强大的 INFO 指令,我们可以清晰地知道 Redis 内部一系列运行参数。INFO 指令显示的信息非常繁多,可通过如下选项指定输出某一部分的详细信息:
- server:服务器运行的环境参数
- clients:客户端相关信息:当前连接数、总连接数、输入缓冲大小、OPS
- memory:服务器运行内存统计数据:当前内存、峰值内存、内存碎片率
- persistence:RDB 和 AOF 的持久化信息:最后一次 RDB 时间、RDB fork 耗时、最后一次 AOF rewrite 时间、AOF rewrite 耗时
- stats:通用统计数据
- replication:主从复制相关信息:主从节点复制偏移量、主库复制缓冲区
- cpu:CPU 使用情况:主进程 CPU 使用率、子进程 CPU 使用率
- commandstats:Redis 执行命令统计数据
- cluster:集群信息
- keyspace:键值对统计数量信息:过期 key 数量、淘汰 key 数量、key 命中率
- errorstats:Redis 异常统计数据
INFO 命令在使用时,可以带一个参数 section,这个参数的取值有好几种。相应的,INFO 命令也会返回不同类型的监控信息。我把 INFO 命令的返回信息分成 5 大类,其中,有的类别当中又包含了不同的监控内容,具体如下表所示: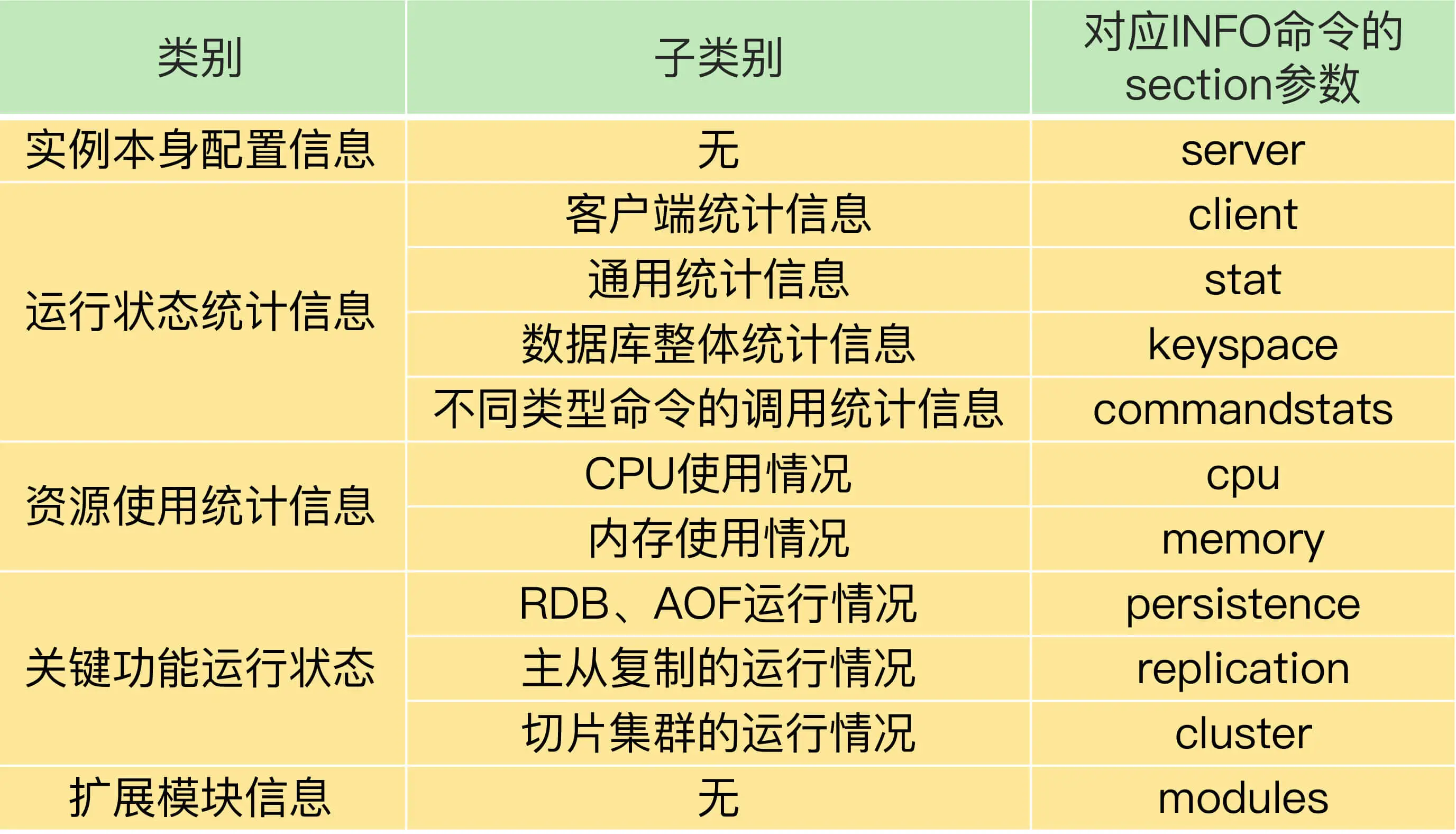
这里,我给你提几个运维时需要重点关注的参数以及它们的重要返回结果。
首先,无论你是运行单实例或是集群,我建议你重点关注一下 stat、commandstat、cpu 和 memory 这四个参数的返回结果,这里面包含了命令的执行情况(比如命令的执行次数和执行时间、命令使用的 CPU 资源),内存资源的使用情况(比如内存已使用量、内存碎片率),CPU 资源使用情况等,这可以帮助我们判断实例的运行状态和资源消耗情况。
另外,当你启用 RDB 或 AOF 功能时,你就需要重点关注下 persistence 参数的返回结果,你可以通过它查看到 RDB 或者 AOF 的执行情况。如果你在使用主从集群,就要重点关注下 replication 参数的返回结果,这里面包含了主从同步的实时状态。
数据迁移工具 Redis-shake
Redis-shake 是阿里云 Redis 和 MongoDB 团队开发的一个用于 Redis 数据同步的工具。Redis-shake 的基本运行原理,是先启动 Redis-shake 进程,这个进程模拟了一个 Redis 实例。然后,Redis-shake 进程和数据迁出的源实例进行数据的全量同步。这个过程和 Redis 主从实例的全量同步是类似的。
源实例相当于主库,Redis-shake 相当于从库,源实例先把 RDB 文件传输给 Redis-shake,Redis-shake 会把 RDB 文件发送给目的实例。接着,源实例会再把增量命令发送给 Redis-shake,Redis-shake 负责把这些增量命令再同步给目的实例。下面这张图展示了 Redis-shake 进行数据迁移的过程: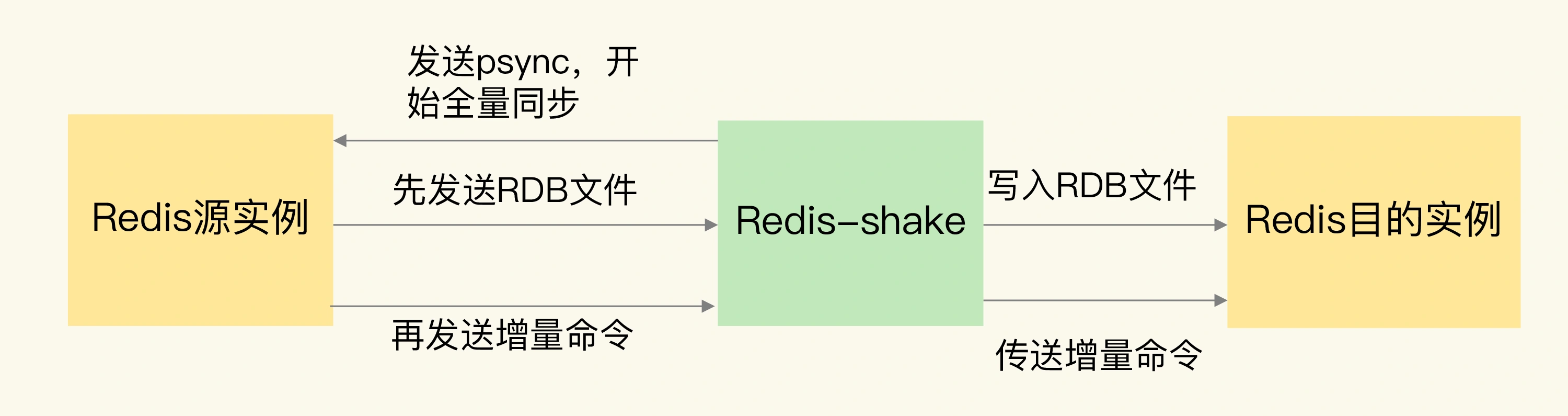
Redis-shake 既支持单个实例间的数据迁移,也支持集群到集群间的数据迁移。
在数据迁移后,通常我们需要对比源实例和目的实例中的数据是否一致。如果有不一致的数据,我们需要把它们找出来,从目的实例中剔除,或者是再次迁移这些不一致的数据。此时,我们可以采用阿里云团队开发的 Redis-full-check 工具。它会对源实例和目的实例中的数据进行全量比对,从而完成数据校验。
集群管理工具 CacheCloud
CacheCloud 是搜狐开发的一个面向 Redis 运维管理的云平台,它实现了主从集群、哨兵集群和 Redis Cluster 的自动部署和管理,用户可以直接在平台的管理界面上进行操作。针对常见的集群运维需求,CacheCloud 提供了以下 5 个运维操作。
- 下线实例:关闭实例以及实例相关的监控任务。
- 上线实例:重新启动已下线的实例,并进行监控。
- 添加从节点:在主从集群中给主节点添加一个从节点。
- 故障切换:手动完成 Redis Cluster 主从节点的故障转移。
- 配置管理:用户提交配置修改的工单后,管理员进行审核,并完成配置修改。
当然,作为运维管理平台,CacheCloud 除了提供运维操作以外,还提供了丰富的监控信息。CacheCloud 不仅会收集 INFO 命令提供的实例实时运行状态信息,进行可视化展示,而且还会把实例运行状态信息保存下来,例如内存使用情况、客户端连接数、键值对数据量。这样一来,当 Redis 运行发生问题时,运维人员可以查询保存的历史记录,并结合当时的运行状态信息进行分析。如果你希望有一个统一平台,把 Redis 实例管理相关的任务集中托管起来,CacheCloud 是一个不错的工具。
性能变慢时的 Checklist
是否用了慢查询命令?例如 SORT、SUNION、ZUNIONSTORE 或 O(N) 命令但是 N 很大的场景。如果是的话,就使用其他命令替代慢查询命令或把聚合计算命令放在客户端做。
是否对过期 key 设置了相同的过期时间?Redis 的过期机制也是在主线程中执行的,大量 key 集中过期会导致处理一个请求时,耗时都在删除过期 key 上,导致耗时变长。对于批量删除的 key,可以在每个 key 的过期时间上加一个随机数,把过期时间打散。
是否存在 bigkey?写 bigkey 在分配内存时需要消耗更多的时间,同样删除 bigkey 释放内存也会耗时。对于 bigkey 的删除操作,如果是 Redis 4.0 及以上的版本,可以直接利用异步线程机制减少主线程阻塞;如果是 Redis 4.0 以前的版本,可以使用 SCAN 命令迭代删除;对于 bigkey 的集合查询和聚合操作,可以使用 SCAN 命令在客户端完成。
Redis AOF 配置级别是什么?业务层面是否的确需要这一可靠性级别?如果我们需要高性能,同时也允许数据丢失,可以使用 everysec 机制并将配置项 no-appendfsync-on-rewrite 设置为 yes,避免 AOF 重写和 fsync 竞争磁盘 IO 资源,导致 Redis 延迟增加。当然, 如果既需要高性能又需要高可靠性,最好使用高速固态盘作为 AOF 日志的写入盘。
Redis 实例的内存使用是否过大?发生 swap 了吗?如果是的话,就增加机器内存或使用 Redis 集群,分摊单机 Redis 的键值对数量和内存压力。同时避免出现 Redis 和其他内存需求大的应用共享机器的情况。
是否运行了 Redis 主从集群?如果是的话,把主库实例的数据量大小控制在 2~4GB,以免主从复制时,从库因加载大的 RDB 文件而阻塞。
淘汰策略:淘汰策略也是在主线程执行的,当内存超过 Redis 内存上限后(maxmemory),每次写入都需要淘汰一些 key,这也会造成耗时变长。我们需要根据业务选择适合的淘汰策略(随机比 LFU 快)。
主从全量同步生成 RDB:虽然采用 fork 子进程生成数据快照,但 fork 这一瞬间也是会阻塞整个线程的,且实例内存越大,fork 拷贝内存页表耗时越久,阻塞时间越久。
并发量非常大时,单线程读写客户端 I/O 数据存在性能瓶颈,虽然采用 I/O 多路复用机制,但是读写客户端数据依旧是同步 I/O,导致只能单线程依次读取客户端的数据,无法利用到 CPU 多核。Redis 在 6.0 版本推出了多线程模式,可以在高并发场景下利用 CPU 多核多线程读写客户端数据,进一步提升 server 性能,当然,只是针对客户端的读写是并行的,每个命令的真正操作依旧是单线程的。

若有收获,就点个赞吧
0 人点赞
