前面我们讨论的架构都是单表存储的,当数据不断增大时,无论是数据库的查询还是写入性能都在下降,数据库的磁盘空间也在报警。所以现阶段我们需要考虑的问题主要有以下几点:
- 由于数据库中存储的数据越来越多,当单个表的数据量超过了千万甚至到了亿级别。这时即使使用了索引,索引占用的空间也随着数据量的增长而增大,数据库就无法缓存全量的索引信息,那么就需要从磁盘上读取索引数据,就会影响到查询的性能了。那么这时要如何提升查询性能呢?
- 数据量的增加也占据了磁盘的空间,导致数据库在备份和恢复的时间变长,那如何让数据库系统能够支持如此大的数据量呢?
- 不同模块的数据,比如用户数据和用户关系数据,全都存储在一个主库中,一旦主库发生故障,所有的模块都会受到影响,那么如何做到不同模块的故障隔离呢?
这些问题可以归纳成,数据库的写入请求量大造成的性能和可用性方面的问题,要解决这些问题,所采取的措施就是对数据进行分片。这样可以很好地分摊数据库的读写压力,也可以突破单机的存储瓶颈,而常见的一种方式是对数据库做分库分表。
分库分表是一种常见的将数据分片的方式,它的基本思想是依照某一种策略将数据尽量平均地分配到多个数据库节点或者多个表中。不同于主从复制时数据是全量地被拷贝到多个节点,分库分表后,每个节点只保存部分的数据,这样可以有效地减少单个数据库节点和单个数据表中存储的数据量,在解决了数据存储瓶颈的同时也能有效地提升数据查询的性能。同时,因为数据被分配到多个数据库节点上,那么数据的写入请求也从请求单一主库变成了请求多个数据分片节点,在一定程度上也会提升并发写入的性能。
垂直拆分
数据库分库分表的方式有两种:一种是垂直拆分,另一种是水平拆分。垂直拆分,顾名思义就是对数据库竖着拆分,也就是将数据库的表拆分到多个不同的数据库中。具体可以根据一张表中的字段,将一张表划分为两张表,其规则就是将一些不经常使用的字段拆分到另一张表中。例如,一张订单详情表有一百多个字段,显然这张表的字段太多了,一方面不方便我们开发维护,另一方面还可能引起跨页问题。这时我们就可以拆分该表字段,解决上述两个问题。
垂直拆分的原则一般是按照业务类型来拆分,核心思想是专库专用,将业务耦合度比较高的表拆分到单独的库中。把不同业务的数据分拆到不同的数据库节点上,这样一旦数据库发生故障时只会影响到某一个模块的功能,不会影响到整体功能,从而实现了数据层面的故障隔离。以微博系统为例,在微博系统中有和用户相关的表,有和内容相关的表,这些表都存储在主库中。在拆分后,我们期望用户相关的表分拆到用户库中,内容相关的表分拆到内容库中。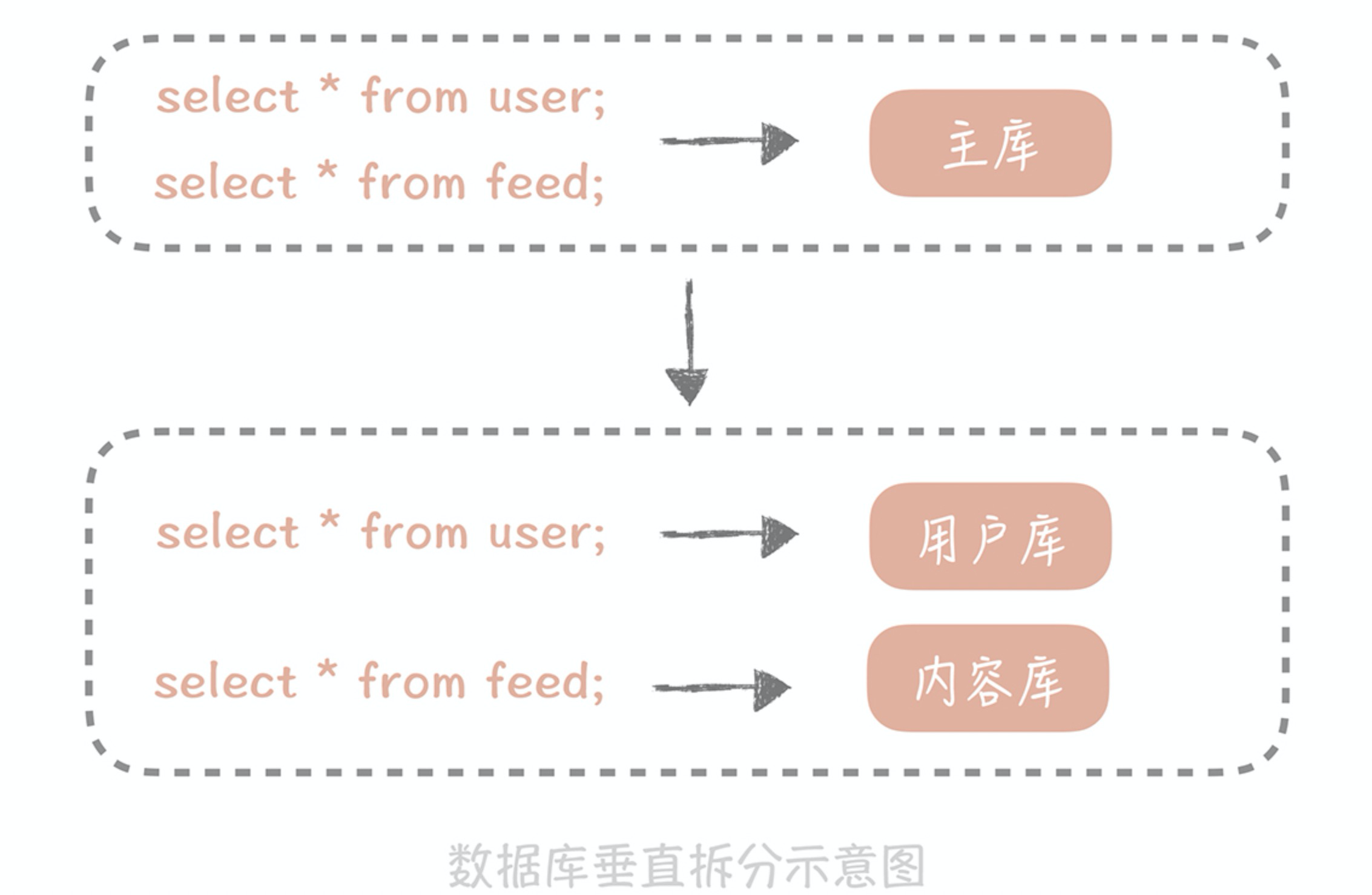
对数据库进行垂直拆分是一种偏常规的方式,不过拆分之后,虽然可以暂时缓解存储容量的瓶颈,但并不是万事大吉,因为数据库垂直拆分后依然不能解决某一个业务模块的数据大量膨胀的问题,比如微博关系量早已经过了千亿,单一的数据库或数据表已经远远不能满足存储和查询的需求了。这个时候,你需要将数据拆分到多个数据库和数据表中,也就是对数据库和数据表做水平拆分。
水平拆分
和垂直拆分的关注点不同,垂直拆分的关注点在于业务相关性,而水平拆分指的是将单一数据表按照某一种规则拆分到多个数据库和多个数据表中,关注点在数据的特点。拆分的规则有下面这两种:
1)根据哈希值拆分
按照某一个字段的哈希值做拆分,这种拆分规则比较适用于实体表,比如说用户表,内容表,我们一般按照这些实体表的 ID 字段来拆分。比如说我们想把用户表拆分成 16 个库,每个库是 64 张表,那么可以先对用户 ID 做哈希,哈希的目的是将 ID 尽量打散,然后再对 16 取余,这样就得到了分库后的索引值;对 64 取余,就得到了分表后的索引值。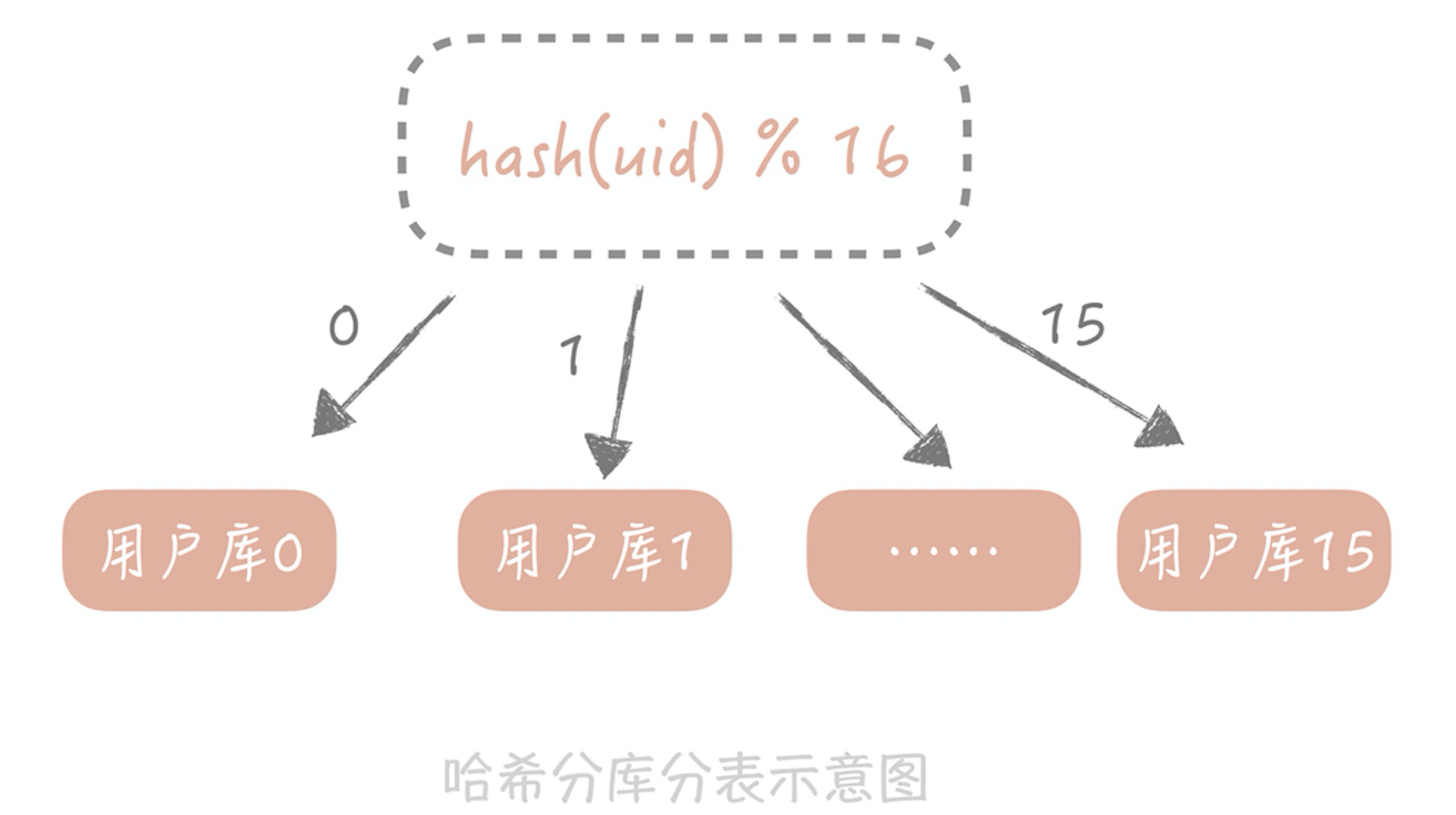
2)根据字段值拆分
另一种常用水平拆分方式是按照某一个字段的区间来拆分,比较常用的是时间字段。比如在内容表里面有创建时间的字段,而我们也是按照时间来查看一个人发布的内容。这时就可以按照创建时间的区间来分库分表,比如说可以把一个月的数据放入一张表中,这样在查询时就可以根据创建时间先定位数据存储在哪个表里面,再按照查询条件来查询。
一般来说,列表数据可以使用这种拆分方式,比如一个人一段时间的订单,一段时间发布的内容。但是这种方式可能会存在明显的热点,这很好理解嘛,你当然会更关注最近我买了什么,发了什么,所以查询的 QPS 也会更多一些,对性能有一定的影响。另外,使用这种拆分规则后,数据表要提前建立好,否则如果时间到了却忘记了建表,那么数据就没有库表可写了,就会发生故障了。
分库分表引入的问题
数据库在分库分表后,数据的访问方式也有了极大的改变,原先只需根据查询条件到从库中查询数据即可,现在则需要先确认数据在哪一个库表中,再到那个库表中查询数据。这种复杂度可以通过数据库中间件来解决。不过你要知道的是,分库分表虽然能够解决数据库扩展性的问题,但是它也给我们的使用带来了一些问题。
1)分区键问题
分库分表引入的一个最大的问题就是引入了分库分表键,也叫做分区键,也就是我们对数据库做分库分表所依据的字段。从分库分表规则中可以看到,无论是哈希拆分还是区间段拆分,我们首先都要选取一个数据库字段,这带来一个问题是:我们之后所有的查询都需要带上这个字段,才能找到数据所在的库和表,否则就只能向所有的数据库和数据表发送查询命令。
如果像上面说的要拆分成 16 个库和 64 张表,那么一次数据的查询会变成 16*64=1024 次查询,查询的性能肯定是极差的。那针对这个问题,我们也会有一些相应的解决思路。
比如在用户库中我们使用 ID 作为分区键,这时如果需要按照昵称来查询用户,可以按照昵称作为分区键再做一次拆分。但这样会极大地增加存储成本,最合适的思路是建立一个昵称和 ID 的映射表,在查询的时候要先通过昵称查询到ID,再通过 ID 查询完整的数据,这个表也可以是分库分表的,也需要占用一定的存储空间,但因为表中只有两个字段,所以相比重新做一次拆分还是会节省不少的空间的。
2)数据库特性实现困难
分库分表引入的另外一个问题是一些数据库的特性在实现时可能变得很困难。比如说多表的 JOIN 在单库时是可以通过一个 SQL 语句完成的,但是拆分到多个数据库之后就无法跨库执行 SQL 了,不过好在我们对于 JOIN 的需求不高,即使有也一般是把两个表的数据取出后在业务代码里面做筛选,虽然复杂但也是可以实现的。
再比如说在未分库分表之前查询数据总数时只需要在 SQL 中执行 count() 即可,现在数据被分散到多个库表中,我们可能要考虑其他的方案,比方说将计数的数据单独存储在一张表中或者记录在 Redis 里面。
虽然分库分表会对我们使用数据库带来一些不便,但是相比它所带来的扩展性和性能方面的提升,我们还是需要做的,因为,只有经历过分库分表后的系统,才能够突破单机的容量和请求量的瓶颈。
3)全局主键 ID 问题
在分库分表后,主键将无法使用自增长来实现了,在不同的表中我们需要统一全局主键 ID。因此,我们需要单独设计全局主键,避免不同表和库中的主键重复问题。
使用 UUID 实现全局 ID 是最方便快捷的方式,即随机生成一个 32 位 16 进制数字,这种方式可以保证一个 UUID 的唯一性,水平扩展能力以及性能都比较高。但使用 UUID 最大的缺陷就是,它是一个比较长的字符串,连续性差,如果作为主键使用,性能相对来说会比较差。
我们也可以基于 Redis 分布式锁实现一个递增的主键 ID,这种方式可以保证主键是一个整数且有一定的连续性,但分布式锁存在一定的性能消耗。此外,还可以基于 Twitter 开源的分布式 ID 生产算法——snowflake 解决全局主键 ID 问题,snowflake 是通过分别截取时间、机器标识、顺序计数的位数组成一个 long 类型的主键 ID。这种算法可以满足每秒上万个全局 ID 生成,不仅性能好,而且低延时。
4)扩容问题
随着用户的订单量增加,根据用户 ID Hash 取模的分表中,数据量也在逐渐累积。此时,我们需要考虑动态增加表,一旦动态增加表了,就会涉及到数据迁移问题。我们在最开始设计表数据量时,尽量使用 2 的倍数来设置表数量。当我们需要扩容时,也同样按照 2 的倍数来扩容,这种方式可以减少数据的迁移量。

若有收获,就点个赞吧
0 人点赞
