Leader 选举概述
Leader 选举是 ZooKeeper 中最重要的技术之一,也是保证分布式数据一致性的关键所在。下面,我们先从整体上来对 ZooKeeper 的 Leader 选举进行介绍。
1. 启动时 Leader 选举
1)每个 Server 会发出一个投票
由于是初始情况,每个 Server 都会将自己作为 Leader 服务器来进行投票,每次投票包含的最基本元素为:所推举的服务器的 myid 和 ZXID,我们用(myid,ZXID)来表示。假设集群中有两台节点,Server1 的投票为 (1,0),Server2 的投票为 (2,0),然后各自将这个投票发送给集群中其他所有机器。
2)接收来自各个服务器的投票
集群中的每台机器发出自己的投票后,也会接收到来自集群中其他机器的投票。集群中的每个服务器在接收到投票后,首先会判断该投票的有效性,包括检查是否是本轮投票、是否来自 LOOKING 状态的服务器。
3)处理投票
在接收到来自其他服务器的投票后,针对每一个投票,服务器都需要将别人的投票和自己的投票进行 PK,PK 的规则如下:
- 优先检查 ZXID,ZXID 较大的服务器优先作为 Leader。
- 如果 ZXID 相同的话,那么就比较 myid,myid 比较大的服务器作为 Leader 服务器。
现在我们来看 Server1 和 Server2 实际是如何进行投票处理的。对于 Server1 来说,它自己的投票是 (1,0),而接收到的投票为 (2,0)。首先会对比两者的 ZXID,因为都是 0,所以无法决定谁是 Leader。接下来会对比两者的 myid,显然 Server1 发现接收到的投票中的 myid 是 2,大于自己的 myid,于是就会更新自己的投票为 (2,0),
然后重新将投票发出去。而对于 Server2 来说,不需要更新自己的投票信息,只是再一次向集群中所有机器发出上一次投票信息即可。
4)统计投票
每次投票后,服务器都会统计所有投票,判断是否已经有过半的机器接收到相同的投票信息。对于 Server1 和 Server2 服务器来说,都统计出集群中已经有两台机器接受了 (2,0) 这个投票信息。这里我们对“过半”的概念做个简单的介绍。所谓“过半”就是指大于集群机器数量的一半,即大于或等于(n/2+1)。对于由 3 台机器构成的集群,大于等于 2 台即为达到“过半”要求。那么,当 Server1 和 Server2 都收到相同的投票信息 (2,0) 的时候,即认为已经选出了 Leader。
5)更新服务器状态
一旦确定了 Leader,每个服务器就会更新自己的状态:Follower 变为 FOLLOWING、Leader 变为 LEADING。
2. 运行时 Leader 选举
在 ZooKeeper 集群正常运行过程中,一旦选出一个 Leader,那么所有服务器的集群角色一般就不会再发生变化了,即使集群中有非 Leader 机器挂了或有新机器加入集群也不会影响 Leader。但是一旦 Leader 所在的机器挂了,那么整个集群将暂时无法对外服务,此时会进入新一轮的 Leader 选举。
假设当前正在运行的 ZooKeeper 集群由 3 台机器组成,分别是 Server1、Server2 和 Server3,当前的 Leader 是 Server3。假设在某一个瞬间,Leader 挂了,这个时候便开始了 Leader 选举:
1)变更状态
当 Leader 挂了之后,余下的非 Observer 服务器都会将自己的服务器状态变更为 LOOKING,然后开始进入 Leader 选举流程,并且将选票都投给自己。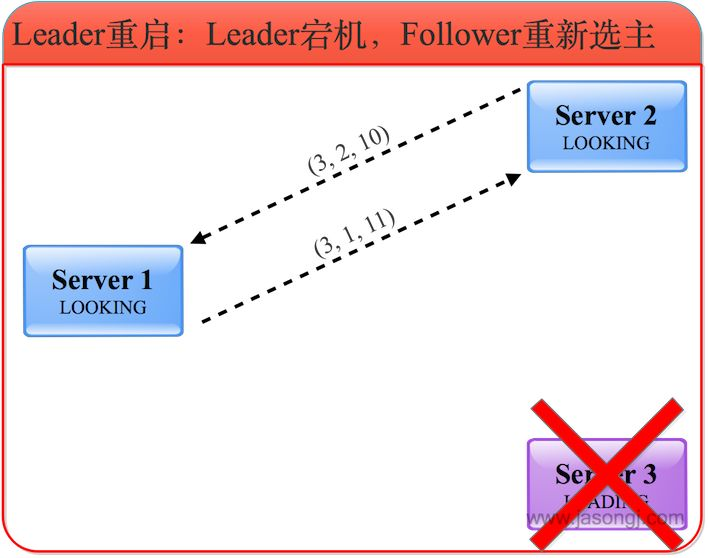
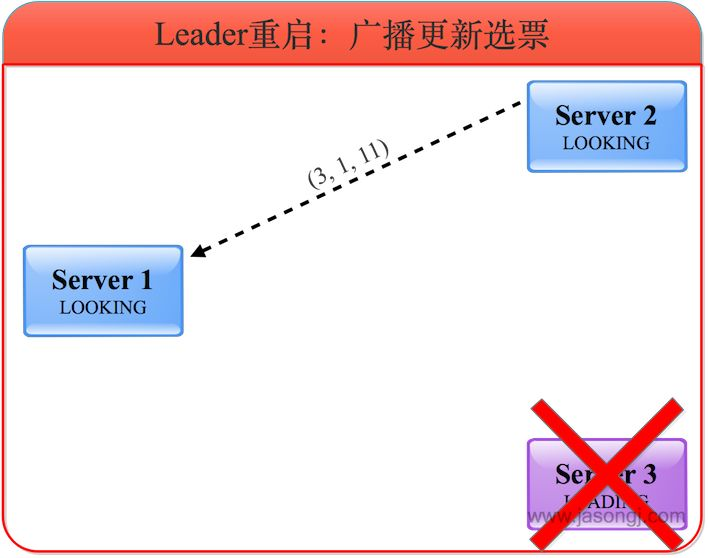
2)更新选票
Server 1 和 Server 2 会根据外部投票来确定是否要更新自身的选票,这里有两种情况:
Server 1 和 Server 2 的 ZXID 相同。例如在 Server 3 宕机前 Server 1 和 Server 2 完全与之同步,此时选票的更新主要取决于 myid 的大小。
Server 1 和 Server 2 的 ZXID 不同。例如在 Server 3 宕机之前,其所主导的写操作只需与过半服务器确认即可,而不需要与所有服务器确认。此时选票的更新主要取决于 ZXID 的大小。
3)选举新 Leader
经过选票更新后,Server 1 和 Server 2 均将选票投给 Server 1,因此 Server 1 成为新的 Leader 并维护与 Server 2 的心跳。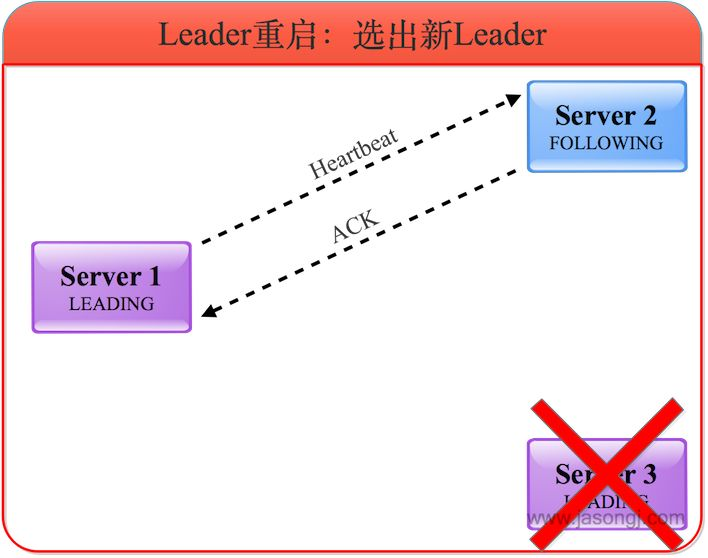
4)旧 Leader 恢复后发起选举
旧的 Leader 恢复后,进入 LOOKING 状态并发起新一轮的选举,并将选票投给自己。此时 Server 1 会将自己的 LEADING 状态及选票返回给 Server 3,Server 2 也会将自己的 FOLLOWING 状态及选票返回给
Server 3。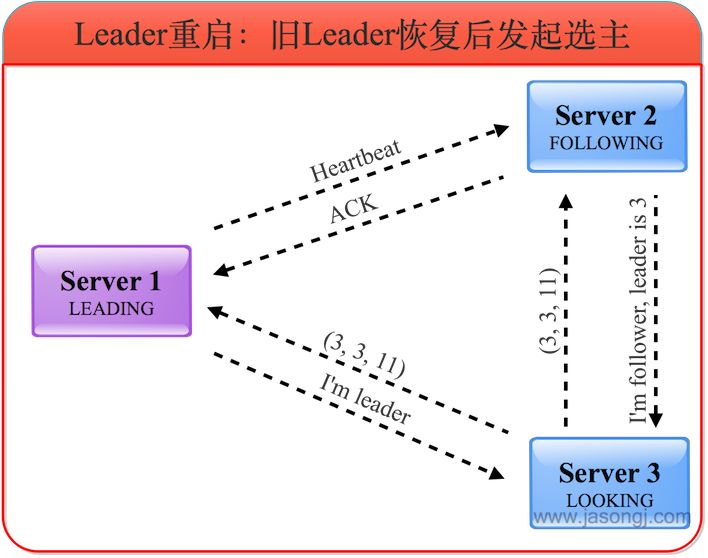
5)旧 Leader 成为 Follower
Server 3 了解到 Leader 为 Server 1,且根据选票了解到服务器确实得到过半服务器的选票,因此自己进入FOLLOWING 状态。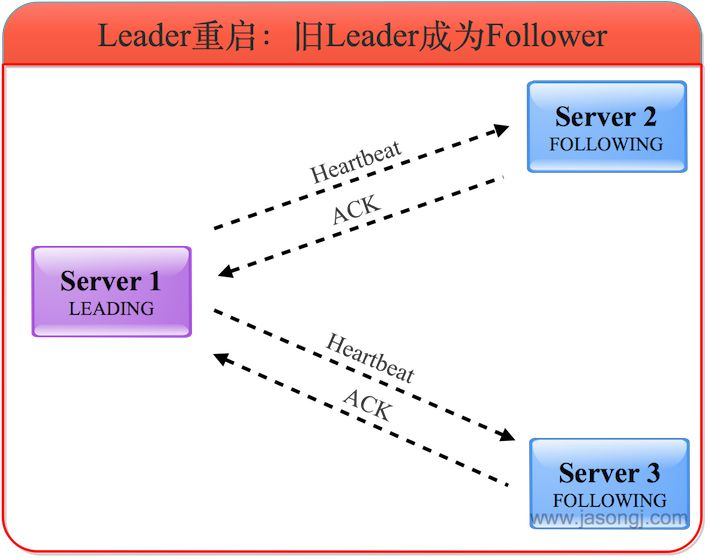
Leader 选举实现
为了能够清楚地对 ZooKeeper 集群中每台机器的状态进行标识,ZooKeeper 在 ServerState 枚举类中列举了如下四种服务器状态:
public enum ServerState {LOOKING,FOLLOWING,LEADING,OBSERVING}
LOOKING:寻找 Leader 状态。当服务器处于该状态时,它会认为当前集群中没有 Leader,因此需要进入 Leader 选举流程。
FOLLOWING:跟随者状态。表明当前服务器角色是 Follower。
LEADING:领导者状态。表明当前服务器角色是 Leader,它会维护与 Follower 间的心跳。
OBSERVING:观察者状态。表明当前服务器角色是 Observer,与 Follower 唯一不同的在于不参与选举,也不参与集群写操作时的投票。
上面说到,Leader 的选举过程是通过投票来实现的,同时每个投票中包含两个最基本的信息:所推举服务器的 SID 和 ZXID,下面我们来看在 ZooKeeper 中对 Vote 数据结构的定义:
public class Vote {final private int version;// 被推举的Leader的SID值,即myidfinal private long id;// 被推举的Leader的事务IDfinal private long zxid;// 逻辑时钟,用来判断多个投票是否在同一轮选举周期中,该值在服务端是一个自增序列,每进入新一轮投票,该值加一final private long electionEpoch;// 被推举的Leader的epochfinal private long peerEpoch;// 当前服务器的状态final private ServerState state;}
1. QuorumCnxManager
前面讲过,ClientCnxn 是 ZooKeeper 客户端中用于处理网络 I/O 的一个管理器。在 Leader 选举的过程中也有类似的角色,那就是 QuorumCnxManager。每台服务器启动的时候,都会启动一个 QuorumCnxManager,负责各台服务器之间的底层 Leader 选举过程中的网络通信。
public class QuorumCnxManager {/** 按照 SID 进行分组,使得各个机器之间通信互不干扰*/final ConcurrentHashMap<Long, SendWorker> senderWorkerMap;final ConcurrentHashMap<Long, BlockingQueue<ByteBuffer>> queueSendMap;final ConcurrentHashMap<Long, ByteBuffer> lastMessageSent;/** Reception queue*/public final BlockingQueue<Message> recvQueue;......}
在 QuorumCnxManager 这个类的内部维护了一系列的队列,用于保存接收到的、待发送的消息,以及消息的发送器。除接收队列以外,这里提到的所有队列都有一个共同点——按 SID 分组形成队列集合,我们以发送队列为例来说明这个分组的概念。假设集群中除自身外还有 4 台机器,那么当前服务器就会为这 4 台服务器分别创建一个发送队列,互不干扰。
recvQueue:消息接收队列,用于存放那些从其他服务器接收到的消息。
queueSendMap:消息发送队列,用于保存那些待发送的消息,按照 SID 进行分组,分别为集群中的每台机器分配了一个单独队列,从而保证各台机器之间的消息发送互不影响。
senderWorkerMap:发送器集合。每个 SendWorker 消息发送器,都对应一台远程 ZooKeeper 服务器,负责消息的发送。同样,该集合也按照 SID 进行了分组。
lastMessageSent:最近发送过的消息。在这个集合中,为每个 SID 保留最近发送过的一个消息。
为了能够相互投票,ZooKeeper 集群中的所有机器都需要两两建立起网络连接。QuorumCnxManager 在启动的时候会创建一个 ServerSocket 来监听 Leader 选举的通信端口(默认是 3888)。开启端口监听后,ZooKeeper 就能够不断地接收到来自其他服务器的“创建连接”请求,在接收到其他服务器的 TCP 连接请求时,会交由 receiveConnection 函数来处理。
public void receiveConnection(final Socket sock) {DataInputStream din = null;try {din = new DataInputStream(new BufferedInputStream(sock.getInputStream()));handleConnection(sock, din);} catch (IOException e) {LOG.error("Exception handling connection, addr: {}, closing server connection", sock.getRemoteSocketAddress());closeSocket(sock);}}
为了避免两台机器之间重复地创建 TCP 连接,ZooKeeper 设计了一种建立 TCP 连接的规则:只允许 SID 大的服务器主动和其他服务器建立连接,否则断开连接。在 receiveConnection 函数中,服务器通过对比自己和远程服务器的 SID 值,来判断是否接受连接请求。如果当前服务器发现自己的 SID 值更大,那么会断开当前连接,然后自己主动去和远程服务器建立连接。一旦建立起连接,就会根据远程服务器的 SID 来创建相应的消息发送器 SendWorker 和消息接收器 RecvWorker,并启动他们。
private void handleConnection(Socket sock, DataInputStream din) throws IOException {Long sid = null, protocolVersion = null;MultipleAddresses electionAddr = null;try {// 从输入流中读取SID值protocolVersion = din.readLong();if (protocolVersion >= 0) { // this is a server id and not a protocol versionsid = protocolVersion;}.....} catch (IOException e) {LOG.warn("Exception reading or writing challenge", e);closeSocket(sock);return;}// 如果当前服务器的 SID 值更大,则断开连接if (sid < self.getId()) {SendWorker sw = senderWorkerMap.get(sid);if (sw != null) {sw.finish();}closeSocket(sock);// 当前服务器主动去和远程服务器建立连接if (electionAddr != null) {connectOne(sid, electionAddr);} else {connectOne(sid);}} else {// 创建SendWorker和RecvWorker线程SendWorker sw = new SendWorker(sock, sid);RecvWorker rw = new RecvWorker(sock, din, sid, sw);sw.setRecv(rw);......// 启动线程等待接收命令sw.start();rw.start();}}
消息的接收过程是由消息接收器 RecvWorker 来负责的,ZooKeeper 会为每个远程服务器分配一个单独的 RecvWorker,因此,每个 RecvWorker 只需要不断地从这个 TCP 连接中读取消息,并将其保存到 recvQueue
队列中。
消息的发送过程也比较简单,由于 ZooKeeper 同样也已经为每个远程服务器单独分别分配了消息发送器 SendWorker,那么每个 SendWorker 只需要不断地从对应的消息发送队列中获取出一个消息来发送即可,同时将这个消息放入 lastMessageSent 中来作为最近发送过的消息。
while (running && !shutdown && sock != null) {ByteBuffer b = null;try {// 从待发送队列中获取待发送消息BlockingQueue<ByteBuffer> bq = queueSendMap.get(sid);if (bq != null) {b = pollSendQueue(bq, 1000, TimeUnit.MILLISECONDS);}......// 将这个消息放入 lastMessageSent 中来作为最近发送过的消息并发送该消息if (b != null) {lastMessageSent.put(sid, b);send(b);}}}
在 SendWorker 的具体实现中,有一个细节需要注意:一旦 ZooKeeper 发现针对当前远程服务器的消息发送队列为空,那么这时就需要从 lastMessageSent 中取出一个最近发送过的消息来进行再次发送。这个细节的处理主要是为了解决这样一类分布式问题:接收方在消息接收前,或者是在接收到消息后服务器挂掉了,导致消息尚未被正确处理。当然,对于重复发送消息的情况,ZooKeeper 能够保证接收方在处理消息的时候,会对重复消息进行正确的处理。
BlockingQueue<ByteBuffer> bq = queueSendMap.get(sid);// 如果发送队列为空,取lastMessageSent进行发送if (bq == null || isSendQueueEmpty(bq)) {ByteBuffer b = lastMessageSent.get(sid);if (b != null) {send(b);}}
2. FastLeaderElection
实现了投票信息的发送与接收后,接下来我们就来看看如何处理投票结果。在 ZooKeeper 的底层实现中,是通过 FastLeaderElection 类来实现的。
public class FastLeaderElection implements Election {// 网络连接管理器QuorumCnxManager manager;// 选票发送队列,用于保存待发送的选票LinkedBlockingQueue<ToSend> sendqueue;// 选票接收队列,用于保存接收到的外部选票LinkedBlockingQueue<Notification> recvqueue;Messenger messenger;// 用于标识当前Leader的选举轮次。在开始新一轮的投票时首先会对该值自增AtomicLong logicalclock = new AtomicLong();}
在初始化 FastLeaderElection 时,会同时创建 Messenger:
private void starter(QuorumPeer self, QuorumCnxManager manager) {......sendqueue = new LinkedBlockingQueue<ToSend>();recvqueue = new LinkedBlockingQueue<Notification>();this.messenger = new Messenger(manager);}
在 Messenger 内部维护了两个线程类,分别是 WorkerSender 和 WorkerReceiver。其中,WorkerReceiver 会不断地从 QuorumCnxManager 中获取出其他服务器发来的选举消息,并将其转换成一个选票,然后保存到
recvqueue 队列中去。而 WorkerSender 会不断地从 sendqueue 队列中获取待发送的选票,并将其传递到底层 QuorumCnxManager 中去。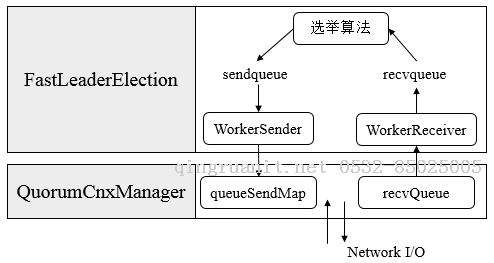
在选票的接收过程中,如果发现该外部投票的选举轮次小于当前服务器,那么就直接忽略这个外部投票,同时立即发出自己的内部投票。当然,如果当前服务器并不是 LOOKING 状态,即已经选举出了 Leader,那么也将忽略这个外部投票,同时将 Leader 信息以投票的形式发送出去。另外,对于选票接收器,还有一个细节需要注意,如果接收到的消息来自 Observer 服务器,那么就忽略该消息,并将自己当前的投票发送出去。

若有收获,就点个赞吧
0 人点赞
