整体架构
前面讲到消息在真正发往 Kafka 之前,有可能需要经历拦截器、序列化器和分区器等一系列的作用,那么在此之后又会发生什么呢?我们先来看一下生产者客户端的整体架构: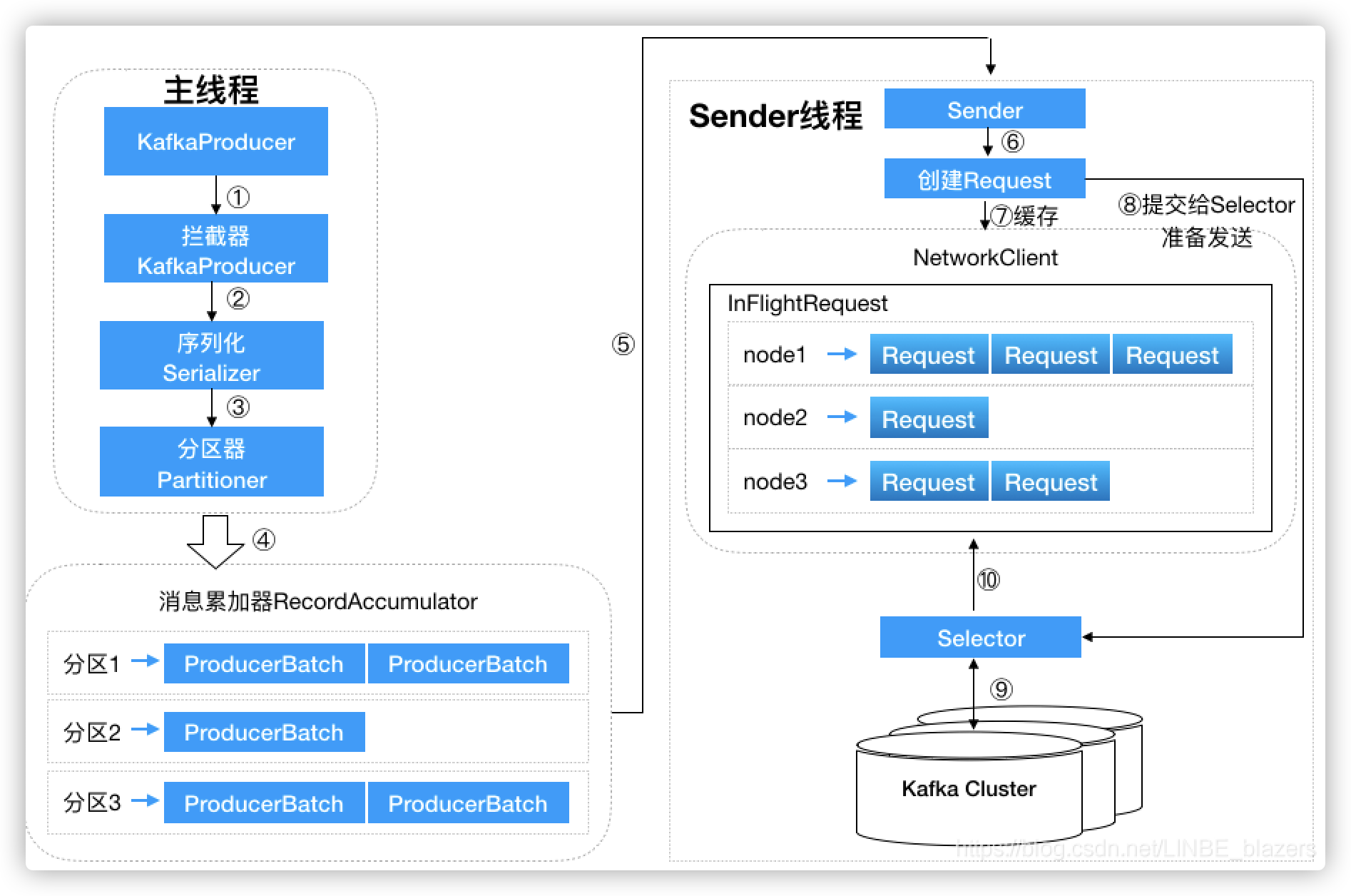
整个生产者客户端由两个线程协调运行,这两个线程分别为主线程和 Sender 线程(发送线程)。在主线程中由 KafkaProducer 创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器 RecordAccumulator 中。Sender 线程负责从 RecordAccumulator 中获取消息并将其发送到 Kafka 中。
1. RecordAccumulator
RecordAccumulator 主要用来缓存消息以便 Sender 线程可以进行批量发送,从而减少网络传输的资源消耗进而提升性能。RecordAccumulator 缓存的大小通过生产者客户端参数 buffer.memory 控制,默认值为 32 MB。如果生产者发送消息的速度超过发送到服务器的速度,则会导致生产者空间不足,此时 KafkaProducer 的 send 方法会被被阻塞,阻塞时间取决于参数 max.block.ms 的配置,默认为 60 秒。超时后则抛出异常。
public final class RecordAccumulator {private final BufferPool free;private final ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches;......}
主线程发送过来的消息都会被追加到 RecordAccumulator 的某个双端队列中,RecordAccumulator 内部为每个分区都维护了一个双端队列,队列中的内容就是 ProducerBatch,即 Deque
注意:ProducerBatch 是指一个消息批次,ProducerRecord 会被包含在 ProducerBatch 中,这样可以使字节的使用更加紧凑,同时将较小的 ProducerRecord 拼凑成一个较大的 ProducerBatch 也可以减少网络请求的次数以提升整体的吞量。如果生产者客户端需要向很多分区发送消息,则可以将 buffer.memory 参数适当地调大以增加整体的吞吐量。
消息追加到双端队列尾部:
private RecordAppendResult tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers,Callback callback, Deque<ProducerBatch> deque, long nowMs) {// 获取双端队列尾部元素ProducerBatch last = deque.peekLast();if (last != null) {// 向ProducerBatch追加消息并获取写入的FutureFutureRecordMetadata future = last.tryAppend(timestamp, key, value, headers, callback, nowMs);if (future == null)last.closeForRecordAppends();elsereturn new RecordAppendResult(future, deque.size() > 1 || last.isFull(), false, false);}return null;}
消息在网络上都是以字节(Byte)形式传输的,在发送之前需要创建一块内存区域来保存对应的消息。在 Kafka 生产者客户端中,通过 java.io.ByteBuffer 实现消息内存的创建和释放。不过频繁的创建和释放是比较耗费资源的,因此 RecordAccumulator 内部自己实现了一个 BufferPool,它主要是用来实现 ByteBuffer 的复用,以实现缓存的高效利用。不过 BufferPool 只针对特定大小的 ByteBuffer 进行管理,而其它大小的 ByteBuffer 不会缓存进 BufferPool 中,这个特定的大小由 batch.size 参数控制,默认值为 16 KB。
ProducerBatch 的大小和 batch.size 参数也有着密切的关系。当一条消息流入 RecordAccumulator 时,会先寻找与消息分区所对应的双端队列,如果没有则创建。再从这个双端队列的尾部获取一个 ProducerBatch,如果没有则创建,判断 ProducerBatch 中是否还可以写入这个 ProdcucerRecord,如果可以则写入,如果不可以则需要创建一个新的 ProducerBatch。在新建 ProducerBatch 时需要评估这条消息的大小是否超过 batch.size 参数的大小,如果不超过就以 batch.size 参数指定的大小来创建 ProducerBatch,这样在使用完这段内存区域后可以通过 BufferPool 的管理来进行复用;如果超过就以这条消息的大小创建 ProducerBatch,但这段内存区域就不会被复用了。
RecordAccumulator 的 append 方法实现:
// 分配可用内存,size为消息的大小buffer = free.allocate(size, maxTimeToBlock);// 追加到缓冲区MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);// 新建ProducerBatch并添加到双端队列ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, nowMs);dq.addLast(batch);// 回收内存free.deallocate(buffer);
2. Sender
Sender 线程在创建 KafkaProducer 时启动,它会与 bootstrap.servers 参数指定的所有 Broker 建立连接,并在一个死循环中不断读取 RecordAccumulator 中缓存的批次消息发送给 broker,直到客户端被关闭。
public class Sender implements Runnable {/* the state of each nodes connection */private final KafkaClient client;/* the record accumulator that batches records */private final RecordAccumulator accumulator;/* the maximum request size to attempt to send to the server */private final int maxRequestSize;/* the number of acknowledgements to request from the server */private final short acks;/* the number of times to retry a failed request before giving up */private final int retries;/* the max time to wait for the server to respond to the request*/private final int requestTimeoutMs;/* The max time to wait before retrying a request which has failed */private final long retryBackoffMs;// A per-partition queue of batches ordered by creation time for tracking the in-flight batchesprivate final Map<TopicPartition, List<ProducerBatch>> inFlightBatches;......}
Sender 从 RecordAccumulator 中获取缓存的消息后,会进一步将原本 <分区,Deque
private long sendProducerData(long now) {Cluster cluster = metadata.fetch();// 获取待发送消息对应分区的节点RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);......// 获取要发送的消息集合,其中 key 为 NodeIdMap<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);// 添加到InFlight缓冲区addToInflightBatches(batches);......// 发送生产者消息sendProduceRequests(batches, now);......}
在转换成
/*** Create a produce request from the given record batches*/private void sendProduceRequest(long now, int destination, short acks, int timeout, List<ProducerBatch> batches) {Map<TopicPartition, MemoryRecords> produceRecordsByPartition = new HashMap<>(batches.size());final Map<TopicPartition, ProducerBatch> recordsByPartition = new HashMap<>(batches.size());......for (ProducerBatch batch : batches) {TopicPartition tp = batch.topicPartition;MemoryRecords records = batch.records();......produceRecordsByPartition.put(tp, records);recordsByPartition.put(tp, batch);}// 构建ProduceRequest请求体ProduceRequest.Builder requestBuilder = ProduceRequest.Builder.forMagic(minUsedMagic, acks, timeout,produceRecordsByPartition, transactionalId);// 构建请求回调函数,执行成功则清除缓冲区数据,执行失败则重试或抛异常RequestCompletionHandler callback = new RequestCompletionHandler() {public void onComplete(ClientResponse response) {handleProduceResponse(response, recordsByPartition, time.milliseconds());}};// 发送网络请求到brokerString nodeId = Integer.toString(destination);ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0,requestTimeoutMs, callback);client.send(clientRequest, now);}
3. InFlightRequests
请求在从 Sender 线程发往 Kafka 之前还会保存到 InFlightRequests 中,InFlightRequests 保存对象的具体形式为 Map
NetworkClient 的 doSend 方法逻辑:
private void doSend(ClientRequest clientRequest, boolean isInternalRequest, long now, AbstractRequest request) {String destination = clientRequest.destination();RequestHeader header = clientRequest.makeHeader(request.version());......Send send = request.toSend(destination, header);InFlightRequest inFlightRequest = new InFlightRequest(clientRequest,header,isInternalRequest,request,send,now);// 添加到InFlightRequests中this.inFlightRequests.add(inFlightRequest);selector.send(send);}public void add(NetworkClient.InFlightRequest request) {String destination = request.destination;Deque<NetworkClient.InFlightRequest> reqs = this.requests.get(destination);if (reqs == null) {reqs = new ArrayDeque<>();this.requests.put(destination, reqs);}// 添加到双端队列头部reqs.addFirst(request);inFlightRequestCount.incrementAndGet();}
与此同时,InFlightRequests 还提供了许多管理类的方法,并且通过配置参数还可以限制每个连接(也就是客户端与 Node 之间的连接)最多缓存的请求数。这个配置参数为 max.in.flight.requests.per.connection,默认值为 5,即每个连接最多只能缓存 5 个未响应的请求,超过该数值之后就不能向这个连接发送更多的请求了,除非有缓存的请求收到了响应。
4. Selector
Kafka 客户端与 broker 的交互采用了 NIO 的非阻塞读写。当发送生产者数据时,会根据主题分区对应的 Node 获取远程 broker 的地址,如果此时客户端没有与该 broker 创建连接,则会尝试建立连接。
private void initiateConnect(Node node, long now) {String nodeConnectionId = node.idString();try {connectionStates.connecting(nodeConnectionId, now, node.host(), clientDnsLookup);InetAddress address = connectionStates.currentAddress(nodeConnectionId);selector.connect(nodeConnectionId,new InetSocketAddress(address, node.port()),this.socketSendBuffer,this.socketReceiveBuffer);}......}public void connect(String id, InetSocketAddress address, int sendBufferSize, int receiveBufferSize) throws IOException {ensureNotRegistered(id);SocketChannel socketChannel = SocketChannel.open();SelectionKey key = null;try {configureSocketChannel(socketChannel, sendBufferSize, receiveBufferSize);// 建立socket连接boolean connected = doConnect(socketChannel, address);// 注册到底层 NIO Selector 上key = registerChannel(id, socketChannel, SelectionKey.OP_CONNECT);......}......}protected SelectionKey registerChannel(String id, SocketChannel socketChannel, int interestedOps) throws IOException {SelectionKey key = socketChannel.register(nioSelector, interestedOps);// 把底层socket封装成KafkaChannel,用来执行读写操作KafkaChannel channel = buildAndAttachKafkaChannel(socketChannel, id, key);// 维护节点与channel之间的映射关系this.channels.put(id, channel);// 更新channle的空闲时间,channle对应的连接超过指定时间则会被关闭if (idleExpiryManager != null)idleExpiryManager.update(channel.id(), time.nanoseconds());return key;}
从代码中可以看到,Selector 为每个节点维护了一个 KafkaChannel,KafkaChannel 封装了底层的 socket 用来进行读写事件,生产者请求发送到 Selector 指定的 KafkaChannel 后就会返回了,此时客户端还未真正将请求发送给 broker,请求会在 Sender 线程的 poll 轮训中发送给 broker。
/*** Queue the given request for sending in the subsequent {@link #poll(long)} calls* @param send The request to send*/public void send(Send send) {String connectionId = send.destination();// 根据节点ID获取关联的channelKafkaChannel channel = openOrClosingChannelOrFail(connectionId);......// send里维护了ByteBuffer,里面存储了要发送的数据channel.setSend(send);......}public void setSend(Send send) {this.send = send;// 注册一个可写事件this.transportLayer.addInterestOps(SelectionKey.OP_WRITE);}
在 Sender 线程中会不断轮训执行 Selector 的 poll 方法,在其 poll 方法中会调用底层 NIO 的 selector 组件获取可读或可写的 channel。
Kafka 自己实现的 Selector 的 poll 方法逻辑:
public void poll(long timeout) throws IOException {......// 检查是否有已经就绪的事件int numReadyKeys = select(timeout);if (numReadyKeys > 0 || !immediatelyConnectedKeys.isEmpty() || dataInBuffers) {// 获取可以处理的SelectionKeySet<SelectionKey> readyKeys = this.nioSelector.selectedKeys();......// 处理读写事件,写事件就是发送生产者请求pollSelectionKeys(readyKeys, false, endSelect);// 处理完成后清除所有选定的键,以便它们可以在下一次轮训中被选中readyKeys.clear();......} else {madeReadProgressLastPoll = true; //no work is also "progress"}......}
Kafka 客户端与 broker 建立的 TCP 连接的存活时间可以通过 connections.max.idle.ms 参数控制。默认情况下该参数值是 9 分钟,即如果在 9 分钟内没有任何请求流过某个 TCP 连接,那么 Kafka 会主动关闭该 TCP 连接。用户可以在 Producer 端设置该参数为 -1 以禁掉这种主动关闭的机制。
元数据的更新
元数据是指 Kafka 集群的元数据,这些元数据具体记录了集群中有哪些主题,这些主题有哪些分区,每个分区的 leader 副本分配在哪个节点上,follow 副本分配在哪些节点上,哪些副本在 AR、ISR 等集合中,集群中有哪些节点,控制器节点是哪一个等等信息。
当客户端中没有需要使用的元数据信息时,比如给一个不存在的主题发送消息时,Broker 会告诉 Producer 这个主题不存在。此时 Producer 会给 Kafka 集群发送请求尝试获取最新的元数据信息。其次 Producer 会通过 metadata.max.age.ms 参数定期更新元数据信息,默认值是 5 分钟,即不管集群那边是否有变化,Producer 每隔五分钟都会强制刷新一次元数据以保证它可以最及时的数据。
元数据的更新操作是在客户端内部进行的,对客户端的外部使用者不可见。当需要更新元数据时,会先挑选出 leastLoadedNode(负载最小的节点),然后向这个 Node 发送 MetadataRequest 请求来获取具体的元数据信息。这个更新操作是由 Sender 线程发起的,在创建完 MetadataRequest 后同样会存入 InFlightRequests,之后的步骤和发送消息时是类似的。
@Overridepublic List<ClientResponse> poll(long timeout, long now) {// 更新集群元数据long metadataTimeout = metadataUpdater.maybeUpdate(now);try {this.selector.poll(Utils.min(timeout, metadataTimeout, defaultRequestTimeoutMs));} catch (IOException e) {log.error("Unexpected error during I/O", e);}......return responses;}

若有收获,就点个赞吧
0 人点赞
