故障诊断
当集群出现故障时,不必担心,我们有许多方法和工具来分析问题。在大部分情况下,我们遇到的问题都是由一些简单的原因导致的。但由于分布式系统的复杂性,有时候故障现象只出现了一次,并且难以复现,这就需要采取一些措施来缩小可疑的问题范围,虽然不能立刻解决问题,但是可以向前迈进一步。
1. Profile API
有时在发起一个查询时,查询会被延迟执行或者响应时间很慢。Elasticsearch 从 2.2 版本开始就提供了 Profile API 以供用户检查查询执行的时间和其他详细信息。
可以通过在 query 部分上方提供 “profile”:true 来启用 Profile API,示例如下:
curl -XPOST "http://localhost:9200/twitter/_search" -H 'Content-Type: application/json' -d'{"profile": true,"query": {"term": {"user":"kimchy"}}}'
Profile API 的结果是基于每个分片计算的。由于在该示例索引中只有一个分片,所以在 Profile API 响应的分片数组中只有一个数组元素,如下所示。
{"profile": {"shards": [{"id": "[7f-bO8KZQj-bjxa6Wxlt0A][twitter][0]","searches": [{"query": [{"type": "TermQuery","description": "user:kimchy","time_in_nanos": 67306,"breakdown": {"set_min_competitive_score_count": 0,"match_count": 0,"shallow_advance_count": 0,"set_min_competitive_score": 0,"next_doc": 1556,"match": 0,"next_doc_count": 2,"score_count": 2,"compute_max_score_count": 0,"compute_max_score": 0,"advance": 1599,"advance_count": 1,"score": 11516,"build_scorer_count": 5,"create_weight": 32826,"shallow_advance": 0,"create_weight_count": 1,"build_scorer": 19809}}],"rewrite_time": 1002,"collector": [{"name": "SimpleTopScoreDocCollector","reason": "search_top_hits","time_in_nanos": 23000}]}],"aggregations": []}]}}
在 searches 数组项里有三个元素:query、rewrite_time、collector。下面解释每个元素的意义。
- query:查询过程
- type:它向我们显示了哪种类型的查询被触发
- time_in_nanos:Lucene 执行此查询所用的时间
- breakdown:有关查询的更详细的细节,主要与 Lucene 参数有关
- rewrite_time:由于多个关键字会分解以创建个别查询,所以在这个过程中肯定会花费一些时间。将查询重写一个或多个组合查询的时间被称为重写时间,单位为纳秒。
- collector:在 Lucene 中,收集器负责收集原始结果,并对它们进行组合、过滤、排序等处理。在示例执行的查询中,默认返回评分最高的前十个文档,所以使用的收集器是 SimpleTopScoreDocCollector。并且也同时返回了使用该收集器的原因和耗时。
Profile API 非常有用,它让我们清楚地看到查询时间。通过向我们提供有关子查询的详细信息,我们可以清楚地知道在哪个环节查询慢,这是非常有用的。另外,在 API 返回的结果中,关于 Lucene 的详细信息也让我们深入了解到 ES 是如何执行查询的。
2. Explain API
一个 ES 索引由多个分片组成,由于某些原因,某些分片可能会处于未分配状态(Unassigned)状态导致集群健康处于 Yellow 或 Red 状态,这是一种比较常见的错误信息,导致分片处于未分配的原因可能是节点离线、分片数量设置错误等原因,使用 Explain API 可以很容易分析当前的分片的分配情况。
这个 API 主要为了解决下面两个问题:
- 对于未分配的分片,给出为什么没有分配的具体原因。
- 对于已分配的分片,给出为什么将分片分配给特定节点的理由。
使用示例如下:
curl -XGET "http://localhost:9200/_cluster/allocation/explain"
curl -XGET "http://localhost:9200/_cluster/allocation/explain" -H 'Content-Type: application/json' -d'
{
"index": "twitter",
"shard": 0,
"primary": false
}'
返回结果如下:
{
"index" : "my_index",
"shard" : 0,
"primary" : false,
"current_state" : "unassigned",
"unassigned_info" : {
"reason" : "CLUSTER_RECOVERED",
"at" : "2021-07-25T09:52:53.930Z",
"last_allocation_status" : "no_attempt"
},
"can_allocate" : "no",
"allocate_explanation" : "cannot allocate because allocation is not permitted to any of the nodes",
"node_allocation_decisions" : [
{
"node_id" : "7f-bO8KZQj-bjxa6Wxlt0A",
"node_name" : "TD-lei.xul",
"transport_address" : "127.0.0.1:9300",
"node_attributes" : {
"ml.machine_memory" : "17179869184",
"xpack.installed" : "true",
"transform.node" : "true",
"ml.max_open_jobs" : "512",
"ml.max_jvm_size" : "1037959168"
},
"node_decision" : "no",
"deciders" : [
{
"decider" : "same_shard",
"decision" : "NO",
"explanation" : "a copy of this shard is already allocated to this node [[my_index][0], node[7f-bO8KZQj-bjxa6Wxlt0A], [P], s[STARTED], a[id=YNYQ7R_nTkmF6L3TH3N1aQ]]"
}
]
}
]
}
从返回结果中可以看到,my_index 索引的第 0 号分片的副分片当前处于未分配状态,因为当前集群中只有一个节点,而 ES 会避免将主副分片分配到同一个节点上去,主要是为了防止当节点失效时所有副本都不可用,以及可能的数据丢失。
3. hot threads
当发现节点进程占用 CPU 非常高时,我们想知道是哪些线程导致的,这些线程具体在执行什么任务,常规做法是通过 top 命令配合 jstack 来定位线程:top 获取线程级 cpu 占用率,再根据线程 id,配合 jstack 定位 cpu 占用率在特定比例之上的线程堆栈。
现在 ES 提供了更便捷的方式,通过 hot threads API 可以直接返回这些信息。该 API 可以返回集群中一个或全部节点的热点线程,使用示例如下:
curl -XGET "http://localhost:9200/_nodes/hot_threads"
curl -XGET "http://localhost:9200/_nodes/node1,node2/hot_threads"
该命令支持以下参数:
- threads:返回的热点线程数,默认为 3 个。
- interval:ES 通过对线程做两次检查来计算某个操作上花费时间的百分比,此参数定义这个间隔时间。默认为 500 ms。
- type:定义要检查的线程状态类型,默认为 CPU。还可以检查线程的 CPU 占用时间、阻塞(block)时间和等待(wait)时间。
- ignore_idle_threads:如果设置为 true 则空闲线程将被过滤。默认值为 true。
4. 内存使用率高
当节点内存使用率高时,我们想要知道内存是被哪些数据结构占据的,通用方式是用 jmap 导一个堆出来,加载到 MAT 中进行分析,这样可以精确定位数据结构占用内存的大小,以及被哪些对象引用。这是定位此类问题最直接的方式。但 jmap 导出的堆可能非常大,操作比较耗时,我们可以先通过一些命令简单看下 ES 中几个占用内存比较大的数据结构,进行粗略评估。
ELasticsearch 的 JVM 内存主要由以下几个部分使用: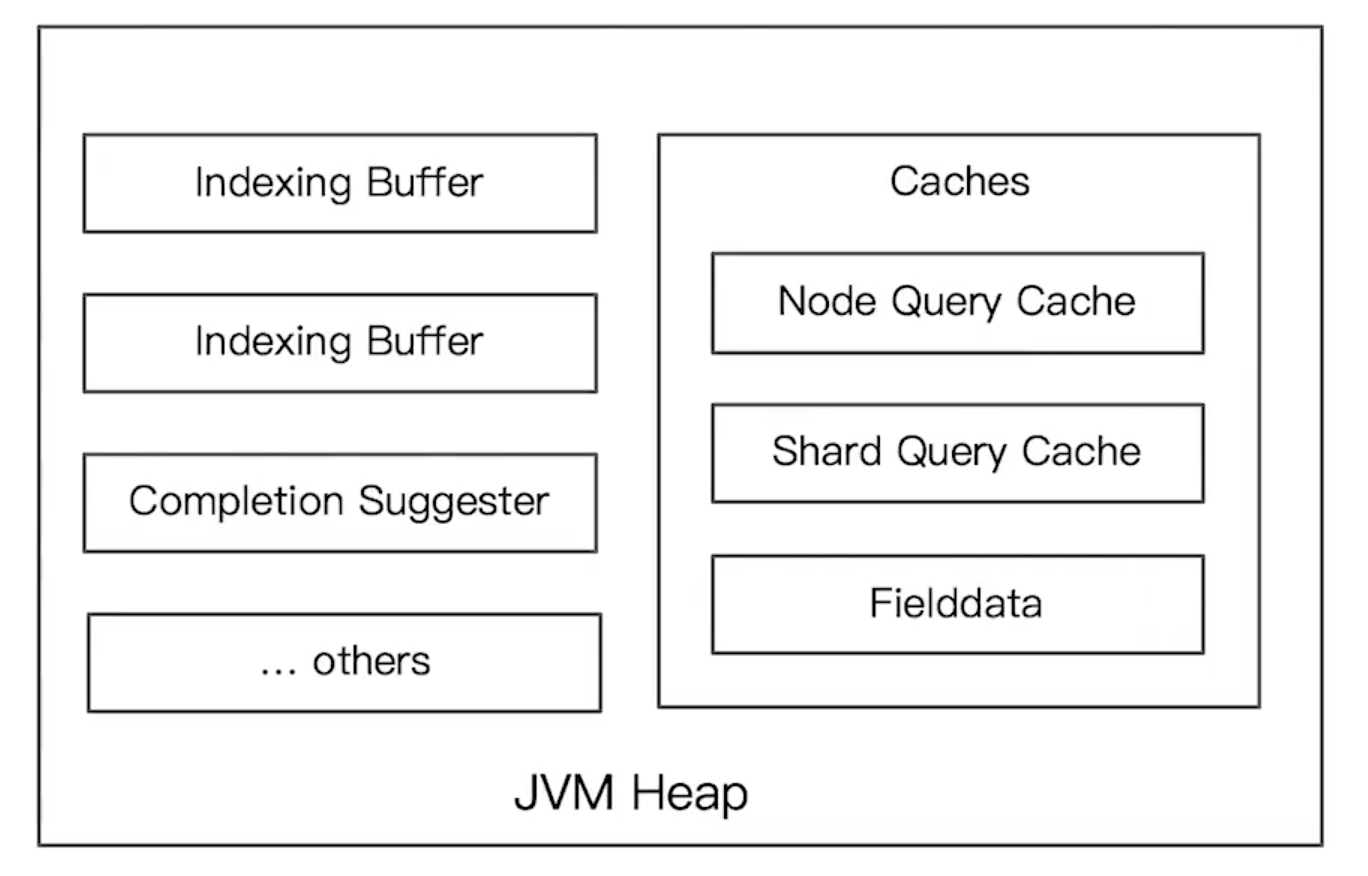
indexing buffer
索引写入缓冲用于存储索引好的文档数据,当缓冲满时生成一个新的 Lucene 分段。在一个节点上,该节点的全部分片共享 indexing buffer。该缓冲区的默认大小为堆内存的 10%,加大该缓冲需要考虑到对 GC 的压力。
Segment 占用内存
一个 Lucene 分段就是一个完整的倒排索引,倒排索引由单词词典和倒排列表组成。在 Lucene 中,单词词典中的 FST 结构会被加载到内存。因此每个分段都会占用一定的内存空间。可以通过下面的 API 来查看某个节点上的所有分段占用的内存总量:
curl -XGET "http://localhost:9200/_cat/nodes?v&h=segments.memory"
也可以单独查看每个分段的内存占用量:
curl -XGET "http://localhost:9200/_cat/segments?v&h=segments.memory&h=index,shard,segment,size.memory"
Fielddata Cache
除了 text 类型字段外,其余字段类型默认都采用 doc values 建立一个列式存储用于排序,节约了内存。如果想要对 text 类型的字段进行排序和聚合,需要开启该字段的 fielddata,默认是关闭的。如果开启了 fielddata 则其可使用的内存大小默认没有上限,通过如下配置可设置一个百分比来控制其使用的堆内存上限,内部采用 LRU 算法淘汰最久未使用的缓存信息。
# 默认值为-1,表示不限制
indices.fielddata.cache.size:
当 Segment 被合并后,该缓存会失效。可以通过下面的命令查看节点上的 fielddata 使用情况:
curl -XGET "http://localhost:9200/_cat/nodes?v&h=fielddata.memory_size"
curl -XGET "http://localhost:9200/_nodes/stats/indices/fielddata?fields=field1,field2&pretty"
curl -XGET "http://localhost:9200/_stats/fielddata?fields=field1,field2&pretty"
Shard Request Cache
分片级别的请求缓存,其使用 LRU 淘汰策略,每个分片独立地缓存查询结果,会将整个 JSON 查询字符串作为缓存键。默认开启,最大占用内存为堆大小的 1%,可通过如下配置项静态配置在每个 Data Node 上:
indices.request.cache.size: 1%
默认情况下,该缓存只会缓存设置了 size=0 的查询对应的结果,它并不会缓存命中的结果(hits),但是会缓存 hits.total、Aggregations 和 Suggestions 信息。当分片 refresh 的时候,Shard Request Cache 会失效。如果 Shard 对应的数据频繁发生变化(即需要经常进行 refresh 操作)则缓存效果会很差。
是否开启该缓冲可以动态调整:
curl -XPUT "http://localhost:9200/my_index/_settings" -H 'Content-Type: application/json' -d'
{
"index.requests.cache.enable": true
}'
也可以在某个请求中指定不使用缓存:
curl -XGET "http://localhost:9200/my_index/_search?request_cache=false"
可以使用下面的 API 来获取该缓存的使用量:
curl -XGET "http://localhost:9200/_cat/nodes?v&h=request_cache.memory_size"
curl -XGET "http://localhost:9200/_stats/request_cache?pretty"
curl -XGET "http://localhost:9200/_nodes/stats/indices/request_cache?pretty"
Node Query Cache
节点查询缓存由该节点上的所有分片共享,也是一个 LRU 缓存,用于缓存查询结果,只缓存在过滤器上下文(Filter Context)中使用的查询。该缓存默认开启,大小为堆大小的 10%。可通过如下配置项静态配置在每个 Data Node 上:
# 默认开启
index.queries.cache.enabled: true
# 默认占用总内存的 10%
indices.queries.cache.size: 10%
该缓存保存的是 Segment 级缓存命中的结果,当 Segment 被合并后缓存会失效。该缓存的使用量可通过下面的命令来获取:
curl -XGET "http://localhost:9200/_cat/nodes?v&h=query_cache.memory_size"
curl -XGET "http://localhost:9200/_nodes/stats/indices/query_cache?pretty"
curl -XGET "http://localhost:9200/_stats/query_cache?pretty"
分片调整
1. Shrink API
需要密切注意集群分片总数,分片数越多集群压力越大。在创建索引时,为索引分配了较多的分片,但可能实际数据量并没有多大。例如,按日期轮询生成的索引,可能有些日子里数据量并不大,对这种索引可以执行 Shrink 操作来降低索引分片数量。
Shrink API 是 ES 5.x 版本后推出的一个新功能,它会使用和源索引相同的配置创建一个新的索引,目的仅仅是为了减少主分片数。在使用 Shrink API 时有如下几个限制:
- 分片必须只读,且所有分片必须在同一个节点上
- 集群健康状态为 Green
- 源分片数必须是目标分片数的倍数,如果源分片数是素数,则目标分片数只能为 1
- 如果文件系统支持硬链接(hard link),则会将 Segment 直接硬链接到目标索引,性能好
使用示例如下:
# 首先将my_source_index设为只读
curl -X PUT "localhost:9200/my_source_index/_settings" -H 'Content-Type: application/json' -d'
{
"settings": {
"index.blocks.write": true
}
}'
curl -X PUT "localhost:9200/my_source_index/_shrink/my_target_index?pretty" -H 'Content-Type: application/json' -d'
{
"settings": {
"index.number_of_replicas": 0,
"index.number_of_shards": 2,
"index.codec": "best_compression"
},
"aliases": {
"my_search_indices": {}
}
}'
在 Shrink 操作执行完成后,就可以删除源索引了。注意,目标索引此时也是只读的,我们需要手动进行修改。
2. Split API
内存熔断器 Circuit Breaker
ES 内置了多种内存断路器,主要用于避免不合理操作引发的 OOM,每个断路器可以指定内存使用的限制:
- Parent circuit breaker:设置所有的熔断器可以使用的内存的总量
- Fielddata circuit breaker:加载 fielddata 所需要的内存
- Request circuit breaker:防止每个请求级数据结构超过一定的内存(过深的聚合)
- In flight circuit breaker:Request 中的断路器
- Accounting request circuit breaker:请求结束后不能释放的对象所占用的内存
我们可以通过 /_nodes/stats/breaker 查看 Circuit Breaker 的统计信息:
{
"request": {
"limit_size_in_bytes": 3823632384,
"limit_size": "3.5gb",
"estimated_size_in_bytes": 16440,
"estimated_size": "16kb",
"overhead": 1,
"tripped": 0
},
"fielddata": {
"limit_size_in_bytes": 3823632384,
"limit_size": "3.5gb",
"estimated_size_in_bytes": 475216,
"estimated_size": "464kb",
"overhead": 1.03,
"tripped": 0
},
"in_flight_requests": {
"limit_size_in_bytes": 6372720640,
"limit_size": "5.9gb",
"estimated_size_in_bytes": 0,
"estimated_size": "0b",
"overhead": 1,
"tripped": 0
},
"accounting": {
"limit_size_in_bytes": 1037959168,
"limit_size": "989.8mb",
"estimated_size_in_bytes": 0,
"estimated_size": "0b",
"overhead": 1,
"tripped": 0
},
"parent": {
"limit_size_in_bytes": 4460904448,
"limit_size": "4.1gb",
"estimated_size_in_bytes": 491656,
"estimated_size": "480.1kb",
"overhead": 1,
"tripped": 0
}
}
如果 tripped 大于 0 则说明有过熔断,当 limit_size 与 estimated_size 越接近,越可能引发熔断。但千万不要触发了熔断就盲目调大熔断阈值,有可能导致集群出问题;也不应该盲目调小,而是应该进行合理评估。
ES 在 7.0 版本之后相比之前版本提供了一套更好的 Circuit Breaker 实现机制,增加了如下配置项,可以更加精准的分析内存情况,避免 OOM。
indices.breaker.total.use_real_memory
常用运维命令
1. 分片移动
此外,我们可以通过 _cluster/reroute 从一个节点移动分片到另一个节点。比如,当一个节点上有过多的 Hot Shard 时,可以通过手动分配分片到特定节点来解决。
使用示例:
curl -X POST "localhost:9200/_cluster/reroute?pretty" -H 'Content-Type: application/json' -d'
{
"commands" : [
{
"move" : {
"index" : "test",
"shard" : 0,
"from_node" : "node1",
"to_node" : "node2"
}
}
]
}'
2. 移除节点
当我们想从集群中移除一个节点或对一个机器进行维护,又不希望因此导致集群的颜色变红或者变黄。我们需要先将该节点的数据迁移,这可以通过分配过滤器实现。通过如下配置:
curl -X PUT "localhost:9200/_cluster/settings?pretty" -H 'Content-Type: application/json' -d'
{
"transient" : {
"cluster.routing.allocation.exclude._ip" : "the_ip_of_your_node"
}
}'
或者
curl -X PUT "localhost:9200/_cluster/settings?pretty" -H 'Content-Type: application/json' -d'
{
"transient" : {
"cluster.routing.allocation.exclude._name" : "the_name_of_your_node"
}
}'
执行命令后,Elasticsearch 会自动将该节点上的数据迁移到其他节点上。我们可以通过 _cat/shard 来查看该节点的分片是否迁移完毕。等移动完成,我们就可以安全下线该节点了。
如果被下线的这个节点维护完毕,想要重新上线时,需要取消 exclude 配置,以便后续的分片还可以分配到该节点上去:
curl -X PUT "localhost:9200/_cluster/settings?pretty" -H 'Content-Type: application/json' -d'
{
"transient" : {
"cluster.routing.allocation.exclude._name" : ""
}
}'
3. 清空缓存
当节点上出现了高内存占用时,可以执行清除缓存的操作。该操作会影响集群的性能但是会避免你的集群出现 OOM 的问题。
curl -X PUT "localhost:9200/_cache/clear?pretty"

若有收获,就点个赞吧
0 人点赞
