Abstract
我们提出了一种简单而高效的anchor-free实例分割方法,称为CenterMask,它在anchor-free单阶段目标检测器(FCOS【33】)的基础上增加了一个新的空间注意力引导掩码(SAG-Mask)分支,与MASK R-CNN相同。将SAG-Mask分支插入FCOS目标检测器,利用空间注意图预测每个检测到的矿上的分割掩码,这有助于关注信息像素和抑制噪声。我们还提出了一种改进的backbone VoVNetV2,该backbone网络由两种有效策略:
- 残差连接(residual connection)来缓解较大VoVNetV2的优化问题。
- 有效挤压激励(effective squeeze-excitation,eSE)来解决原SE的信道信息丢失问题。
使用SAG-Mask和VoVNetV2,我们设计了CenterMask和CenterMask-lite,分别针对大模型和小模型。使用相同的backbone ResNet-101-FPN,CenterMask达到了38.3%,超越了所有以前的最先进的方法,同时速度更快。在Titan Xp上,CenterMask-lite的fps也超过了最先进的技术。我们希望CenterMask和VoVNetV2可以分别做份实时实例分割的坚实基线和各种视觉任务的backbone网络。代码可以在以下网址找到:
https://github.com/youngwanLEE/CenterMask
1、introduction
近年来,实例分割在目标检测之外取得了很大的进展。最具有代表性的方法是Mask R-CNN,扩展到对象检测(例如,Faster R-CNN),已经主导了COCO基准,因为实例分割可以很容易的检测对象,然后预测每个盒子上的像素来解决。然而,即使已经有很多关于改进Mask R-CNN的工作,但是考虑实例分割速度的工作却很少。虽然YOLACT由于其并行结构和极轻的装配过程是第一的实时的单阶段实例分割,但与Mask R-CNN的精度差距仍然很大。因此,我们的目标是通过提高准确性和速度来弥补差距。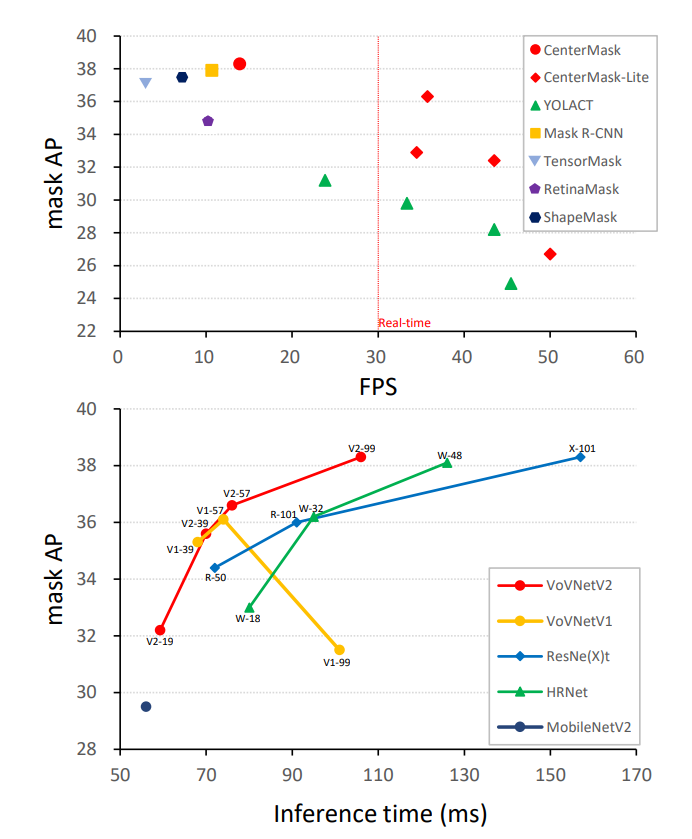
图1 - 准确性-速度的权衡。跨各种实例分割模型(顶部)和骨干网(底部)的COCO。CenterMask和CenterMask-lite的推断速度在相同的GPU(V100/Xp)上报告。请注意,底部的所有backbone在相同的我们所提出的CenterMask下进行比较。详情见3.2节、表3以及表5.
Mask R-CNN是基于一个两阶段物体检测器(例如,Faster R-CNN),它首先生成候选框,然后预测方框的位置和分类,YOLACT是建立在一个一阶段检测器(RetinaNet)上,它直接预测方框,而不需要生成候选框。然而,这些目标检测器严重依赖于预先定义的anchor,这些anchor对超参数(例如,输入大小、纵横比、比例等)和不同的数据集非常敏感。此外,由于anchor密集放置提高召回率,过多的anchor框会导致阳性/阴性样本的不平衡,计算/存储的成本更高。为了解决anchor框的这些缺点,近年来许多作品通过使用角点/中心点从anchor-based到anchor-free过度,这使得计算效率更高,性能也比anchor-based的检测器更好。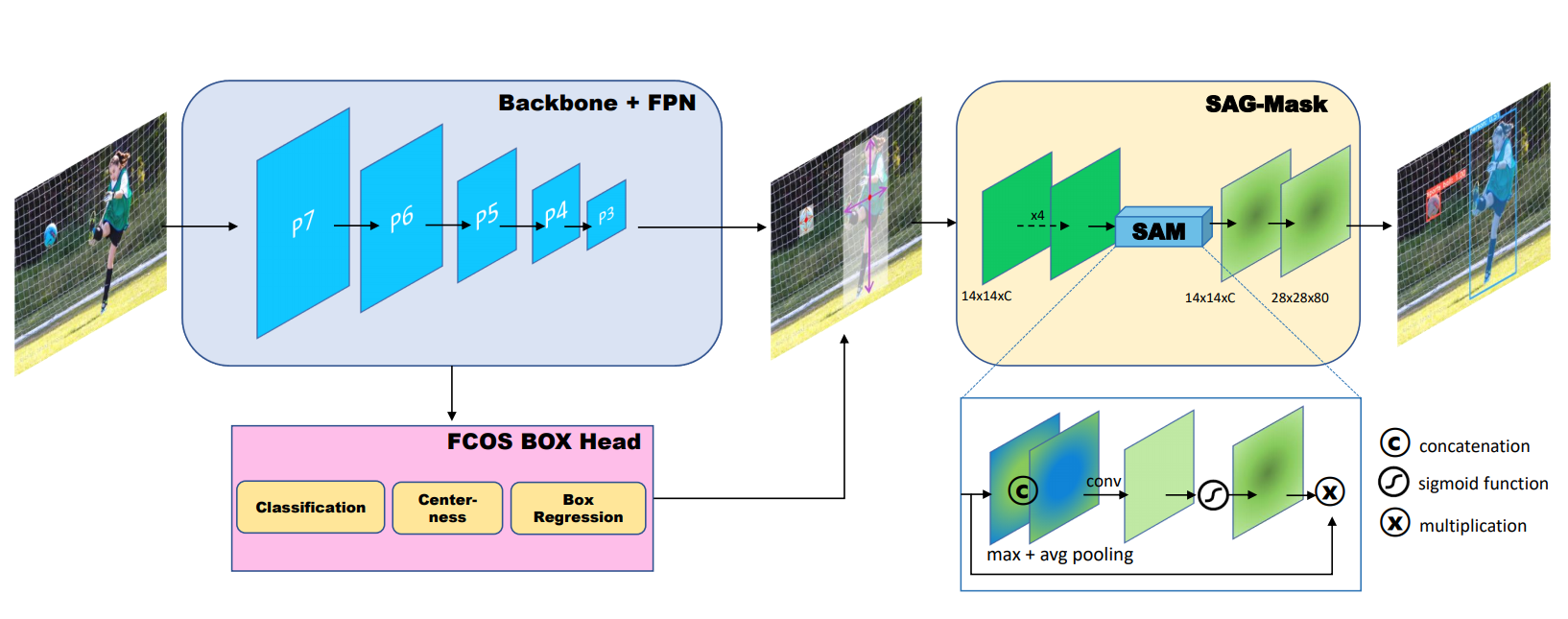
图2 :CenterMask的架构。其中P3(stride of 2^3)~P7(stride of 2^7)为backbone网络特征金字塔中的特征图。FCOS使用来自backbone的特征来预测边界框。空间注意引导掩码(SAG-Mask)利用空间注意模块(SAM)预测每个检测框内的分割掩码segmentation mask,有助于聚焦信息像素,同时抑制噪声。
因此,我们设计了一种简单而高效的anchor-free单阶段实例分割称为CenterMask,它像R-CNN一样,在效率更高的anchor-free单阶段目标检测器(FCOS)上增加了一个新的空间注意力引导的掩码分支。图2显示了我们的CenterMask的概述。插入FCOS目标检测器,我们的控件注意力引导掩码(SAG-Mask)分支从FCOS检测器中提取预测框,预测每个感兴趣区域(RoI)上的分割掩模segmentation mask。SAG-Mask中的空间注意力模块(SAM)帮助掩模分支关注有意义的像素,抑制无信息的像素。
在提取每个感兴趣区域的特征进行掩模mask预测时,需要根据感兴趣区域的大小对每个感兴趣区域池进行分配。Mask R-CNN提出了一个新的赋值函数,称为RoIAlign,它不考虑输入比例。因此,我们设计了一个尺度自适应的RoI分配函数,该函数考虑了输入尺度,是一种更适合的单阶段目标检测器。我们还提出了基于VoVNet的backbone VoVNetV2,该backbone网络具有单次聚合(one-shot aggregation,OSA)特性,性能优于ResNet和DenseNet。在图1(底部)中,我们发现在VoVNet中叠加OSA模块会导致性能下降(如VoVNetV1-99)。我们认为这种现象是ResNet的动机,因为梯度的反向传播受到了干扰。因此,我们在每个OSA模块中增加了残差连接,以方便优化,从而使VoVNet更深,从而提高了性能。
在挤压激励squeeze-excitation(SE)通道注意模块中,发现全连接层减小了通道大小,从而减少了计算量,并以外造成了通道信息丢失。因此,我们将SE模块重新设计为有效的SE(eSE),用一个保持通道为数的FC层代替两个FC层,从而防止信息的丢失,从而提高了性能。利用残差连接和eSE模块,我们提出了不同尺度的VoVNetV2:从轻量级VoVNetV2-19,base VoVNetV2-39/57和大型模型VoVNetV2-99对应的mobilenet-v2,resnet-50/101 & HRNet-W18/32,和ResNeXt-32x8d。
利用SAG-Mask和VoVNetV2,我们设计了CenterMask和CenterMask-lite,分别针对大模型和小模型。大量的实验证明了CenterMask和CenterMask-lite以及VoVNetV2的有效性。使用相同的ResNet101 backbone,CenterMask在COCO实例和检测任务上的性能优于所有以前的最先进的single 模型,同时速度更快。使用VoVNetV2-39 backbone的CenterMask-lite也实现了33.4%的mask AP / 38。0%的box AP,在Titan Xp上超过35fps,分别比最先进的实时实例分割YOLACT高出2.6/7.0的AP增益。
2、CenterMask
在本节中,我们首先回顾一下anchor-free的目标检测器FCOS,它是我们CenterMask的一个基本目标检测部分。接下来,我们将演示CenterMask的架构,并描述如何设计空间注意力引导掩码分支(SAG-Mask)来插入FCOS检测器。最后,提出了一种更有效的backbone VoVNetV2,从准确性和速度上提高了CenterMask的性能。
2.1. FCOS
FCOS是一种像FCN一样的anchor-free和proposal-free的逐像素预测方式的目标检测。几乎所有最先进的目标检测器,如Faster R-CNN、YOLO和RetinaNet,使用anchor-based的概念,需要详细的参数调整和训练中的box IoU相关的复杂计算。在没有anchor框的情况下,FCOS直接预测一个4D向量加上特征图上每个空间位置的类标签。如图2所示,4D矢量嵌入了一个边界框的四个边到该位置(如左右上下)的相对偏移量。此外,FCOS引入了center-ness来预测像素到其相应的边界框中心的偏移量,提高了检测性能。FCOS避免了anchor框的复杂计算,降低了内存/计算成本,但性能也由于anchor-based的目标检测器。基于FCOS的效率和良好的性能,我们设计了基于FCOS的目标检测器的CenterMask。
2.2. Architecture
图2显示了CenterMask的总体架构。centermask由三部分组成:
- 特征提取backbone
- FCOS检测头detection head
- 掩码头mask head
掩码对象的过程包括从FCOS box head检测对象,然后以逐像素的方式预测裁剪区域内的segmentation masks。
2.3. Adaptive RoI Assignment Function
在FCOS box head中预测候选对象之后,CenterMask使用与Mask RCNN相同纹理的预测框来预测segmentation mask。由于RoI是通过特征金字塔网络(FPN)中不同层次的特征映射来预测的,因此提取特征的RoI对齐相对于RoI尺度应该分配在不同的特征映射尺度上。具体来说,一个大范围的RoI必须被分配到一个更高的特征级别,反之亦然。基于Mask R-CNN的两阶段检测器利用FPN中的等式1来确定要分配到哪个特征图(Pk)。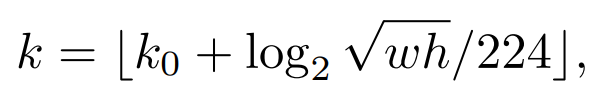
2.4. Spatial Attention-Guided Mask
近年来,注意力方法attention methods被广泛应用于目标检测,因为它有助于关注重要的特征,但也抑制不必要的特征。特别是,通道主义channel attention强调在特征图的通道中关注“什么”,而空间注意spatial attention强调“哪里”是一个信息区域。受到空间注意机制的启发,我们采用空间注意模块引导mask head聚焦于有意义的像素,抑制无信息的像素。
因此,我们设计了一个控件注意力引导mask(spatial attention-guided mask, SAG-Mask),如图2所示,在RoI对其以1414分辨率提取预测RoI中的特征后,将这些特征一次输入到四个conv层和空间注意模块(SAM)中。利用空间注意力图asag(Xi)∈R (1W*H)
这段重新翻译
2.5. VoVNetV2 backbone
在本节中,我们提出了更有效的backbone VoVNetV2,以进一步提高CenterMask的性能。VoVNetV2是对VoVNet的改进,在VoVNet中加入残差连接和提出的有效挤压激励(effective Squeeze-and-Excitation,eSE)注意模块。VoVNet是一种计算高效、性能高效的backbone,由于才用了一次性聚合(One-shot Aggrega,OSA)模块,可以有效地呈现多样化的特征表示。如图3(a)所示,OSA模块由连续的conv层组成,同时聚合后续的特征图,能够有效地捕获不同的接受域,在准确性和速度上由于DenseNet和ResNet。
Residual connection残差连接:尽管VoVNet具有高效多养的特征表示,但在优化方面存在局限性。由于OSA模块在VoVNet中被堆叠(即更深),我们观察到更深模型的精度饱和或者退化。从表4可以看出,VoVNetV1-99的准确率地域VoVNetV1-57。基于ResNet的冬季,我们推测由于conv等变换函数的增加,叠加OSA模块使得梯度的反向传播逐渐变得困难。因此,如图3(b)所示,我们还将身份映射添加到OSA模块。正确地,输入路径连接到OSA模块的末端,该模块能够像ResNet一样在每个阶段端到端的反向传播每个OSA模块的梯度。用于映射在提高VoVNet的性能的同时,也使得VoVNet有可能像VoVNet-99那样扩大其深度。
Effective Squeeze-Excitation(eSE):为了进一步提高VoVNet的性能,我们还提出了一个通道注意模块,有效挤压激励(effective Squeeze-Excitation,eSE)更有效的改进了原有的SE。
2.6. Implementation details
3、experiments
3.1.Ablation study
3.2. Comparison with state-of-the-arts methods
4. Discussion
在表5中,我们观察到使用相同的ResNet-101 backbone,Mask R-CNN在小对象上表现出比CenterMask更好的性能。我们推测,Mask R-CNN使用了比CenterMask更大的feature map,其中Mask分支可以提取比P3 feature map更精细的对象空间布局。我们注意到仍然有提高单阶段实例分割性能的空间,比如Mask R-CNN的技术。
5. Conclusion
我们提出了一种实时anchor-free的单阶段实例分割和更有效的backbone 网络。CenterMask增加了控件注意力引导的掩码mask分支到anchor-free一阶段实例检测中,在实时速度下实现了最先进的性能。新提出的VoVNetV2 backbone从轻量到较大的型号,使得CenterMask在速度和精度方面表现良好。我们希望CenterMask可以作为实时实例分割的基线。我们还认为,我们提出的VoVNetV2可以作为各种视觉人物的强大而高效的backbone网络。
References
[1] Daniel Bolya, Chong Zhou, Fanyi Xiao, and Yong Jae Lee. Yolact: Real-time instance segmentation. In ICCV, 2019. 1, 2, 7, 8
[2] Zhaowei Cai and Nuno Vasconcelos. Cascade r-cnn: Delving into high quality object detection. In CVPR, pages 6154– 6162, 2018. 1, 8
[3] Kai Chen, Jiangmiao Pang, Jiaqi Wang, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jianping Shi, Wanli Ouyang, et al. Hybrid task cascade for instance segmentation. In CVPR, pages 4974–4983, 2019. 1, 8 [4] Long Chen, Hanwang Zhang, Jun Xiao, Liqiang Nie, Jian Shao, Wei Liu, and Tat-Seng Chua. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In CVPR, pages 5659–5667, 2017. 3 [5] Xinlei Chen, Ross Girshick, Kaiming He, and Piotr Dollar. Tensormask: A foundation for dense object segmentation. In ICCV, 2019. 7, 8
[6] Kaiwen Duan, Song Bai, Lingxi Xie, Honggang Qi, Qingming Huang, and Qi Tian. Centernet: Keypoint triplets for object detection. In ICCV, 2019. 2
[7] Cheng-Yang Fu, Mykhailo Shvets, and Alexander C Berg. Retinamask: Learning to predict masks improves stateof-the-art single-shot detection for free. arXiv preprint arXiv:1901.03353, 2019. 7, 8
[8] Kaiming He, Ross Girshick, and Piotr Dollar. Rethinking imagenet pre-training. In ICCV, 2019. 7
[9] Kaiming He, Georgia Gkioxari, Piotr Dollar, and Ross Gir- ´ shick. Mask r-cnn. In ICCV, 2017. 1, 2, 3, 5, 6, 8
[10] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016. 2, 4, 7
[11] Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017. 2
[12] Jie Hu, Li Shen, Samuel Albanie, Gang Sun, and Andrea Vedaldi. Gather-excite: Exploiting feature context in convolutional neural networks. In NIPS, pages 9401–9411, 2018. 3
[13] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In CVPR, pages 7132–7141, 2018. 2, 3, 4, 7 [14] Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. In CVPR, 2017. 2
[15] Zhaojin Huang, Lichao Huang, Yongchao Gong, Chang Huang, and Xinggang Wang. Mask scoring r-cnn. In CVPR, pages 6409–6418, 2019. 1, 5, 6
[16] Youngjoo Jo and Jongyoul Park. Sc-fegan: Face editing generative adversarial network with user’s sketch and color. In ICCV, pages 1745–1753, 2019. 8
[17] Weicheng Kuo, Anelia Angelova, Jitendra Malik, and Tsung-Yi Lin. Shapemask: Learning to segment novel objects by refining shape priors. In ICCV, 2019. 8
[18] Hei Law and Jia Deng. Cornernet: Detecting objects as paired keypoints. In ECCV, pages 734–750, 2018. 2
[19] Youngwan Lee, Joong-won Hwang, Sangrok Lee, Yuseok Bae, and Jongyoul Park. An energy and gpu-computation efficient backbone network for real-time object detection. In CVPR Workshops, pages 0–0, 2019. 1, 2, 4, 7
[20] Yanghao Li, Yuntao Chen, Naiyan Wang, and Zhaoxiang Zhang. Scale-aware trident networks for object detection. arXiv preprint arXiv:1901.01892, 2019. 1
[21] Tsung-Yi Lin, Piotr Dollar, Ross B Girshick, Kaiming He, ´ Bharath Hariharan, and Serge J Belongie. Feature pyramid networks for object detection. In CVPR, 2017. 3, 5, 6
[22] Tsung-Yi Lin, Priyal Goyal, Ross Girshick, Kaiming He, and Piotr Dollar. Focal loss for dense object detection. ´ ICCV, 2017. 1, 3
[23] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollar, and C Lawrence ´ Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014. 1, 2, 5
[24] Shu Liu, Lu Qi, Haifang Qin, Jianping Shi, and Jiaya Jia. Path aggregation network for instance segmentation. In CVPR, pages 8759–8768, 2018. 1
[25] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C Berg. Ssd: Single shot multibox detector. In ECCV, 2016. 7
[26] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In CVPR, pages 3431–3440, 2015. 3
[27] Francisco Massa and Ross Girshick. maskrcnn-benchmark: Fast, modular reference implementation of Instance Segmentation and Object Detection algorithms in PyTorch. https://github.com/facebookresearch/ maskrcnn-benchmark, 2018. 8
[28] Zheng Qin, Zeming Li, Zhaoning Zhang, Yiping Bao, Gang Yu, Yuxing Peng, and Jian Sun. Thundernet: Towards realtime generic object detection on mobile devices. In ICCV, 2019. 3
[29] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In CVPR, 2016. 3 [30] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In NIPS, 2015. 1, 3
[31] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In CVPR, pages 4510–4520, 2018. 7
[32] Ke Sun, Yang Zhao, Borui Jiang, Tianheng Cheng, Bin Xiao, Dong Liu, Yadong Mu, Xinggang Wang, Wenyu Liu, and Jingdong Wang. High-resolution representations for labeling pixels and regions. arXiv preprint arXiv:1904.04514, 2019. 2, 7
[33] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. Fcos: Fully convolutional one-stage object detection. In ICCV, 2019. 1, 2, 3, 5, 6
[34] Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon. Cbam: Convolutional block attention module. In ECCV, pages 3–19, 2018. 3
[35] Yuxin Wu, Alexander Kirillov, Francisco Massa, Wan-Yen Lo, and Ross Girshick. Detectron2. https://github. com/facebookresearch/detectron2, 2019. 8
[36] Saining Xie, Ross Girshick, Piotr Dollar, Zhuowen Tu, and ´ Kaiming He. Aggregated residual transformations for deep neural networks. In CVPR, 2017. 2, 7
[37] Kimin Yun, Yongjin Kwon, Sungchan Oh, Jinyoung Moon, and Jongyoul Park. Vision-based garbage dumping action detection for real-world surveillance platform. ETRI Journal, 41(4):494–505, 2019. 8
[38] Xingyi Zhou, Dequan Wang, and Philipp Krahenb ¨ uhl. Ob- ¨ jects as points. In arXiv preprint arXiv:1904.07850, 2019. 2
[39] Xingyi Zhou, Jiacheng Zhuo, and Philipp Krahenbuhl. Bottom-up object detection by grouping extreme and center points. In CVPR, pages 850–859, 2019. 2
[40] Xizhou Zhu, Dazhi Cheng, Zheng Zhang, Stephen Lin, and Jifeng Dai. An empirical study of spatial attention mechanisms in deep networks. In ICCV, 2019. 3

若有收获,就点个赞吧
0 人点赞
