1. RCNN
1.1 RCNN的4个步骤
- 生成候选框:通过selective search生成候选框,1000-2000个
- warp并提取特征:将每个候选框缩放成224*224的大小,然后输入到CNN网络,保存第5个pool层的输出(即一个4096长度的一维向量,就是对候选框提取到的特征)
- 对特征二分类:训练一个SVM分类器(二分类),将每个候选框提取到的特征输入到SVM进行分类,每个类别对应一个SVM,判断是不是属于这个类别,是就是positive,不是就nagative
- 修正候选框:对于SVM分好类的候选框做边框坐标的regression,用bounding box回归校正原来的建议窗口。对于每一个类,分别训练一个regression模型
1.2 RCNN的3个缺点
- 训练过程是多级流水线(非端到端,要分开训练)
- 特征提取网络:RCNN首先使用目标候选框对卷积神经网络(alexnet、vggnet)使用log损失进行微调
- 分类网络:将卷积神经网络得到的特征送入SVM。这些SVM作为目标检测器,替代通过微调学习的softmax分类器。
- 回归网络:在第三个训练阶段,学习检测框回归。
- 训练在时间上和空间上的开销都很大
- 空间上:对于SVM和检测框回归训练,每张图像上的每个目标候选框提取特征,并写入磁盘。需要数百GB的存储空间
- 时间上:在单个GPU上需要花费2.5天 (VOC2007的5K的图像)
- 目标检测速度慢:每张图像的要提取2000个候选框,且各自提取特征
1.3 RCNN的2个改进方向
- 候选区域的生成:
- 用的是传统分割+区域合并的selective search方法,这个步骤一张图片就要花费2秒(首先通过分割的方法获取很多小区域,计算相邻区域之间的相似度,找出相似度最高的两个区域(颜色、纹理、合并后总面积),将其合并为新的集合,重复这个步骤)
- 特征图的提取:
- 统一特征提取:RCNN慢的原因是因为一张图片分成了2000个候选区域分别进行推理,有很多重叠的部分。所以我们可以先对整个图像进行特征提取,然后将每个候选框在整个图像上的位置映射到卷积层的特征图上,这样对于一张图像我们只需要提取一次卷积层特征,然后将每个候选框的卷积层特征输入到全连接层进行后续操作。
- 特征维度对齐:但有一个问题还没有解决,就是每个候选框的大小不一样,而全连接的输入数据长度必须固定,SPP Net可以解决这个问题。
2. SPP-Net
SPP-Net:spatial pyramid pooling in Deep Convolutional Networks for Visual Recognition, 2015
SPP-Net解决的问题就是输入尺度不统一的问题。卷积层可以适应不同的输入,但是全连接层必须固定。在RCNN中,我们将每个候选框warp或者crop成统一的224*224的大小,但是这种缩放可能导致物体被拉伸或物体不全,这限制了模型的性能
SPP-Net的改进就是在最后一个卷积层和全连接层之间加入一个SPP层(金字塔池化层),此时网络的输入可以是任意尺度的,在SPP的每一个pooling 的filter会根据输入调整大小,保证传到下一层全连接层的输入固定。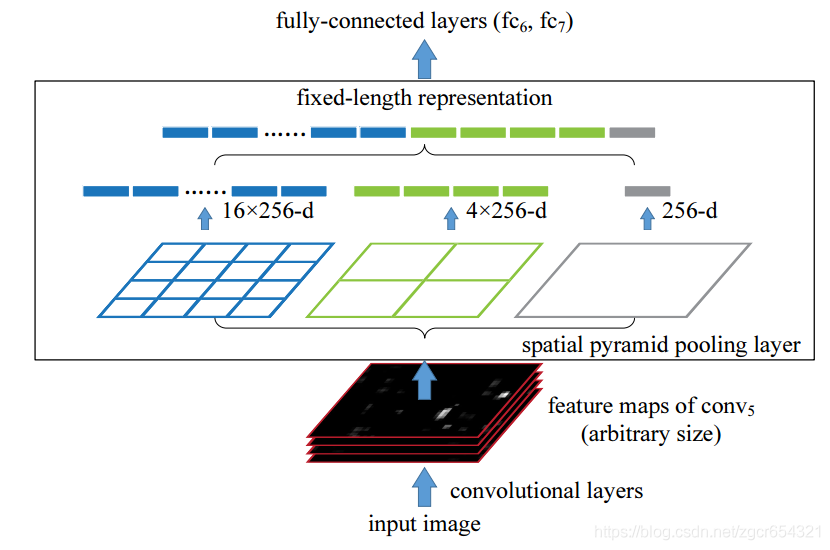
3. Fast RCNN
3.1 Fast RCNN的3个步骤
- 生成候选框:通过selective search生成候选区域
- 提取特征图:将整个图像通过CNN提取特征图,得到候选框映射到特征图上获得相应的特征图
ROI pooling后同时分类和回归:通过ROI pooling操作,将每个特征矩阵缩放到7*7大小的特征图,展平后通过并行的两个全连接层得到目标分类结果和边界框回归结果
3.2 Fast RCNN的2个缺点
训练过程是多级流水线(非端到端,要分开训练)
- 虽然Fast RCNN对RCNN进行了简化,去掉了SVM和回归网络用两个FC来代替,但是依然没有实现真正意义上的端到端训练
目标检测速度慢:依然用selective search来提取候选框,这一步就要花费2-3秒
3.3 Fast RCNN的1个改进点
区域候选框的生成:selective search速度太慢,这一步就要花费2-3秒
4. Faster RCNN
Faster RCNN就是Fast RCNN + RPN
一句话总结就是用RPN代替了Fast RCNN中的selective search。4.1 Faster RCNN的3个步骤
提取特征图:将整个图片送入神经网络得到特征图
- 提取候选框:使用RPN生成候选框,将候选框投影到特征图得到特征矩阵
- ROI pooling后同时分类和回归:通过ROI pooling操作,将每个特征矩阵缩放到7*7大小的特征图,展平后通过并行的两个全连接层得到目标分类结果和边界框回归结果
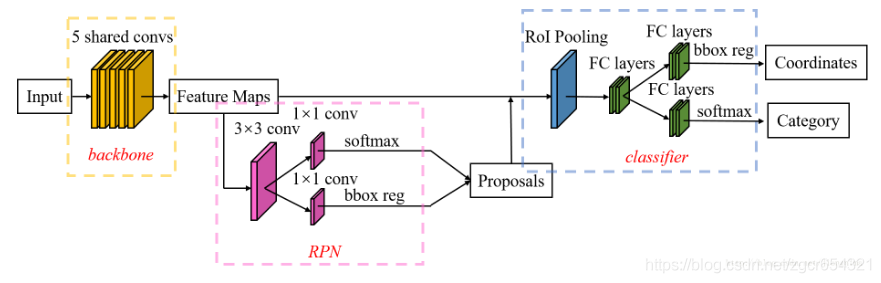
4.2 Anchor
原图经过特征提取得到的特征图大小为C H W,则对应了H W 9个anchor框,这里的H是下采样16倍后的值。9种anchor包括了三种面积(128128、256256、512*512),每种面积又包含3种长宽比(1:1,2:1,1:2)
假设特征图大小为256 w h,则RPN中
- 经过33卷积后,输出为256h*w
- 经过11卷积后,输出为4khw用于回归框(k是anchor框的数量)
- 经过11卷积后,输出为2khw用于分类(背景non-object或者前景object)
特征图上每个点都生成9个anchor,这样就会有接近2k的anchors(224/16 224/16 9 = 1764)。用RPN将anchor调整为候选框,也就是RPN用边界回归参数将anchor调整为proposal候选框,也就是anchor和候选框的概念,需要区别!用非极大值抑制减少大量重叠。RPN网络的实现(head)是使用3×3的卷积核,步距为1,padding为1,这样就可以把特征图的每个点都能遍历到,这样就可以得到一个shape和feature map一样的特征矩阵(包括channel)!

若有收获,就点个赞吧
0 人点赞
