SOLOv2: Dynamic and Fast Instance Segmentation
Xinlong Wang1 Rufeng Zhang2 Tao Kong3 Lei Li3 Chunhua Shen1
1The University of Adelaide, Australia2Tongji University, China3ByteDance AI Lab
阿德莱德大学是澳洲八大名校之一,是澳大利亚历史上的第三所大学。世界排名第120名左右。
Abstract
SOLO v2是一个实例分割的CNN网络架构。
Motivation
为了表示目标检测,bbox框简单粗暴的代表了目标的位置。使用bbox框的目标检测方法已经被充分的开发,包括其中存在的问题方案、网络结构、后处理方案还有所有对bbox框优化和处理的操作。
但是,bbox框非常的死板和不自然。试想,人在定位一个物体的时候不会在物体身上画一个框,人们可以依靠物体的边界,轻松的直接的定位出物体。实例分割,也就是使用mask定位出物体,使得目标检测推进到了像素级别,为更多实例级别的感知和应用打开了大门。
纯实例分割,包括其中的支持设备,比如说后处理,相对于使用bbox框检测和基于bbox框的实例分割方法来说,在很大程度上是未开发的。
Methods
对于实例分割,通常有一下几种方式:
- top-down的方式,detecting first then segmenting the object in the bbox
- anchor-free which have promising performance
- bottom-up, per-pixel and then clustering them into group
- solo,即在本文当中,直接进行实例分割,不依赖于box检测框或者embedding learning
在本文中,实例分割的任务被分解为像素级别分类的两个子任务,可以用标准FCNs进行解决,因此极大地简化了实例分割的方案。将图片作为输入,直接输出instance masks和对应的分类置信度。以上方法是全卷积的、box-free的和grouping-free的方案。
The object mask generation is decoupled into a mask kernel prediction and mask feature learning, which are responsible for generating convolution kernels and the feature map to be convolved with, respectively.
网络的结构分为五个部分:
- backbone
- FPN
- mask kernel G
- mask feature F
- Matrix NMS
Mask kernel G
这里的mask kernel是一种动态卷积的思想。我们知道卷积核其实和图片张量是有区别的,这两个通常不是一个东西。那么这里的动态卷积,就是将图片送进网络,生成mask kernel张量,比如是S S D维的张量,这个张量再作为卷积核对mask feature进行卷积。以这样的方法,实现动态卷积。这个卷积核会因为图片的不同而不同。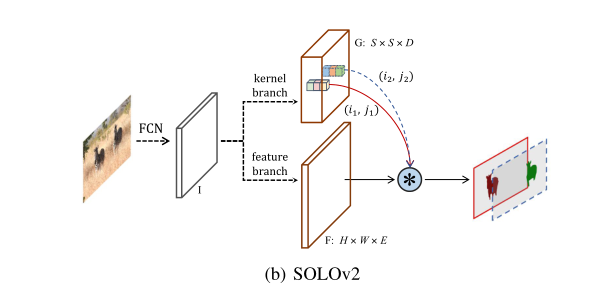
FPN的P1 - P5都会进行mask kernel的生成。动态卷积核G:S S D,这里的S代表划分的S格数量,是个手动设置的参数,即将输入图片划分为S * S的grid。
(i, j)代表grid的坐标。

这里的M是最终网络的输出掩模,这意味着最后会生成S S个mask。那么这S S个通道也就是mask的顺序是

有卷积核就有卷积核大小的概念。作者用ablation实验探索了最佳的卷积核大小。如果希望使用1 1的卷积核对mask feature进行卷积操作,那么此时的mask kernel G的D维数就等于mask feature F的E维数。假如你希望使用3 3的卷积核,那么D = 9E。直观上的理解是将D维的vector进行reshape编程一个 3 3 (D / 9)的卷积核,这个不清楚,具体可以再看看代码。后续的ablation证明1 1 256的mask kernel是最佳的。
CoordConv
文中只是提及了CoordConv的概念。将spatial functionality假如到FPN的的输出当中。可以理解为将空间信息、实例的坐标信息加入到FPN的输出中,提供给mask kernel branch 和 mask feature branch使用。添加的位置是P5 FPN中特征级别最高的位置。
后续的ablation也证明了加了CoordConv可以提高指标
Mask feature F
通常有两种办法输出mask feature:
- 对FPN每个level分别进行处理,输出mask
- 把FPN每个level进行合并,然后再处理、输出mask
本文采用的是后者。文中提出,第一种方法的缺点很明显,对于中大型物体的分割会比较差。因为,大的物体通过high level 的、low spatial resolution的FPN feature map来获得,自然会得到粗略的边界预测。
Matrix NMS
文中总结了几种NMS方法:
- tradition NMS
hard removal by threshold - soft-NMS
decrease the confidence scores of neighbors according to their overlap with higher scored predictions - adaptive NMS
对每个实例使用动态抑制阈值,非常适合人群检测 - Matrix NMS
没有细看,总体是一种parallel并行处理的思想,类似于Fast NMS,但是克服了Fast NMS的性能下降的缺点。
Contribution
- 实例分割指标state of the art。
- speed和accuracy SOTA
- 提供了一种全新的实例分割方案,一种高效率的、全面的实例掩码表示方案,动态地分割每个在图片当中的实例,不需要依赖于bbox框等东西。
- novel Matrix NMS,解决了NMS耗时的问题,还能使网络有更好地结果。
- 不用很大的修改就能通过分割掩码生成bbox框,且bbox指标的表现也是很好
- 不用很大的修改就能将网络运用到全景分割中去,且指标也是很好
Ablation Experiments
config:
- SGD
- batch_size = 16
- 36 epochs on coco and other datasets
- learning rate = 0.01, divided by 10 at 27th and 33th epoch
- use scale jitter,将图片以较短的一端为基准,进行缩放,到640 * 480像素。
ablation:
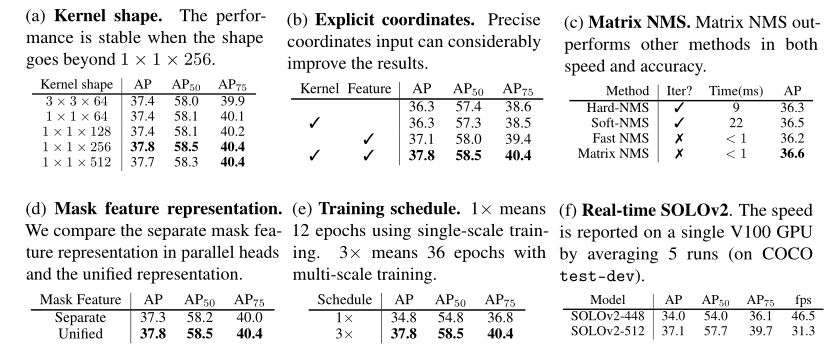
- kernel shape,对不同大小的动态卷积核进行消融实验,对比11和33在不同通道数时的效果。1 1 256最好
- effectiveness of coordinates,加与不加显式的位置信息到网络中,加了最好
- Unified Mask Feature Representation。对FPN分别进行处理或是合并后再处理。结果是合并了更好
- Matrix NMS,对比使用其他几种NMS的耗时和AP指标
- real-time setting,给出了speed priority和accuracy priority两个版本的模型。方法是修改图像短边的宽度和卷积层数、通道数。就结果来看,像素越高512的图片出的结果最好。
Future work
no idea. 不太理解其中的分类信息是如何获得的。全文看下来,感觉只有分割加区分(无类别)的内容。
Consideration
网络最终输出S*S个掩码,再进行NMS处理。假设使用场景中,实例非常的少,那S的大小是否可以缩小?
运用在虹膜分割当中,一张图像可能只有一个虹膜或两个,那么S的值就要非常的小。S值太小是否会影响效果?
对于医学图像分割,比如unet是最简便的end-to-end的网络形式,速度非常的块,甚至不需要后处理,任意的后处理如NMS等都会降低系统的推理速度。在原本的方案中这些后处理都是不需要的。
设想:
- 运用solov2这样的实例分割方案,修改mask kernel G部分。S S代表的是网格的个数,而一个网格只输出一个实例,那么是否可以将S S修改为1 * 1,只生成一个动态卷积进行虹膜的分割,由于不产生其他掩码,也不存在NMS及其cost。
直觉上来讲效果不会太好,像医学图像分割这种分割精度要求极高的,还是需要unet这种encoder-decoder结构,编解码直接存在concat联系的方案。

若有收获,就点个赞吧
0 人点赞
