分割篇
cross entropy loss
用于图像语义分割任务的最常用损失函数是像素级别的交叉熵损失,这种损失会逐个检查每个像素,将对每个像素类别的预测结果(概率分布向量)与我们的one-hot标签向量进行比较
假设我们需要对每个像素的预测类别有五个(五个类),则预测的概率分布向量长度为5
每个像素对应的损失函数为: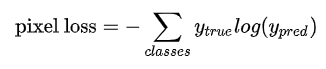
ytrue是一个one-hot向量,元素只有0-1两种取值,如果该像素的类别相同就取1,否则取0,yprec表示预测样本属于概class的概率(二值情况下则为前景,前景为1,背景为0)
整个图像的损失就是对每个像素的损失求平均值
特别注意的是,binary entropy loss是针对类别只有两个的情况,简称bce loss,损失函数公式为: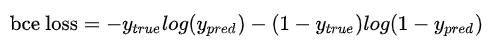
缺点:
交叉熵loss可以用在大多数语义分割场景中,但它有一个明显的缺点,那就是对于只用股分割前景和背景的时候,当前景像素的数量远远小于背景像素的数量时,即y = 0的数量远远大于y = 1的数量,损失函数y = 0的成分就会占据主导,使得模型严重偏向背景,导致效果不好。
https://zhuanlan.zhihu.com/p/35709485
看这个,说的很好
交叉熵损失函数经常用语分类问题中,特别是在神经网络做分类问题是,也经常使用交叉熵为损失函数,此外,由于交叉熵涉及到每个类别的概率,所以交叉熵几乎每次都和sigmoid(或softmax)函数一起出现。
学习过程:
1、神经网络最后一层得到每个类别的得分scores;
2、该得分经过sigmoid或者softmax函数获得概率输出;
3、模型预测的类别概率输出与真实类别的one-hot形式进行交叉熵损失函数的计算
用梯度下降法做参数更新的时候,模型学习的速度取决于两个值:1、学习率2、偏导值。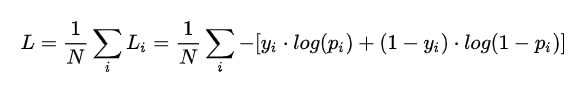
带权交叉熵loss
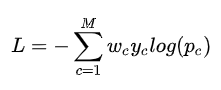
就是在交叉熵loss的基础上为每一个类别添加了一个权重参数,其中wc的计算公式为: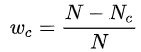 其中N表示总的像素个数,而Nc表示GT类别为c的像素个数。这样相比于原始的交叉熵loss,在样本不均衡的情况下可以获得更好的效果。
其中N表示总的像素个数,而Nc表示GT类别为c的像素个数。这样相比于原始的交叉熵loss,在样本不均衡的情况下可以获得更好的效果。
对于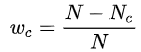 ,当Nc的像素越多,它的值就越小,所算出的Loss就越小
,当Nc的像素越多,它的值就越小,所算出的Loss就越小
dice loss
https://zhuanlan.zhihu.com/p/103426335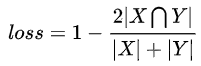
dice loss对小目标的预测是很不利的,因为一旦小目标有部分像素预测错误,就可能引起系数的大幅度波动,导致梯度变化大训练不稳定。
tversky loss
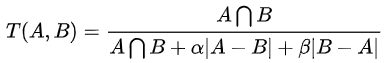
当α和β都等于0.5时,这个就是dice loss
generalized dice loss
需要多研究

若有收获,就点个赞吧
0 人点赞
