MobileNet-V1
其实介绍MobileNetV1只有一句话,就是把VGG中的标准卷积层换成深度可分离卷积就可以了。
深度可分离卷积
深度可分离卷积(depthwise separable convolution),根据史料记载,可追溯到2012年的论文blablabla。
https://blog.csdn.net/u010712012/article/details/94888053
以上为参考博客。
空间可分离
顾名思义,空间可分离就是将一个大的卷积核变成两个小的卷积核,比如将一个3 3的核分成一个3 1和一个1 *3的核: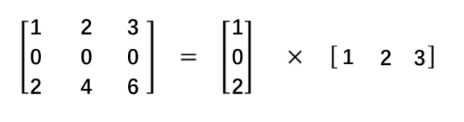
深度可分离卷积
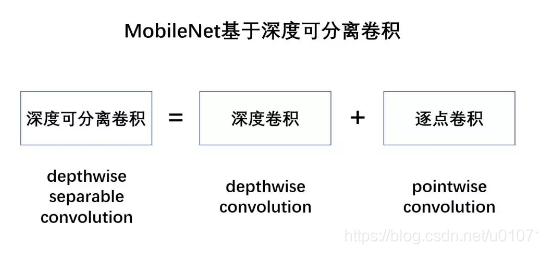
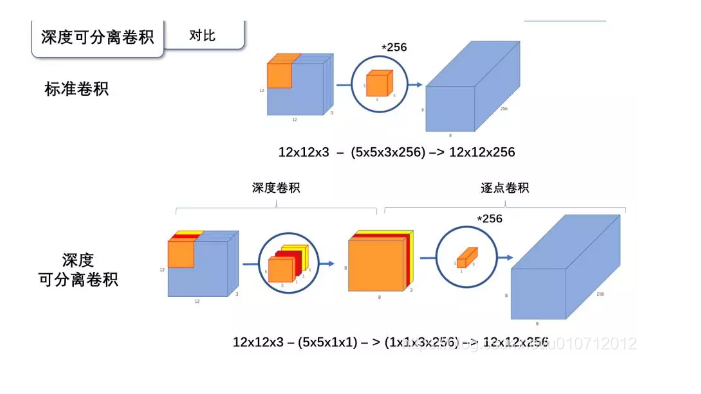
深度可分离卷积就是将普通卷积拆分成为一个深度卷积和一个逐点卷积。
先来看一下标准的卷积操作: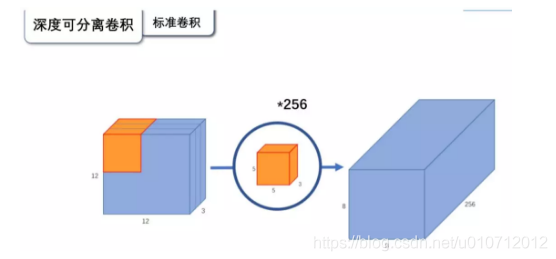
输入一个12 12 3的一个输入特征图,经过5 5 3的卷积核卷积得到一个8 8 1的输出特征图。如果此时我们有256个特征图,我们将会得到一个8 8 256的输出特征图。
深度卷积
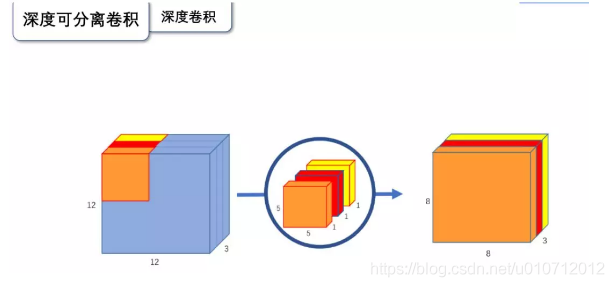
与标准卷积网络不一样的是,我们将卷积核拆分成为单通道形式,在不改变输入特征图的深度的情况下,对每一通道进行卷积操作,这样就得到了和输入特征图通道数一致的输出特征图。如上图:输入12 12 3的特征图,经过5 5 1 3的深度卷积之后,得到了8 8 * 3的输出特征图。输入和输出的维度是不变的3,。这样就会有一个问题,通道数太少,特征图的维度太少,能获取到足够的有效信息吗?
逐点卷积
逐点卷积就是1 1卷积。主要作用就是对特征图进行升维和降维。如下图: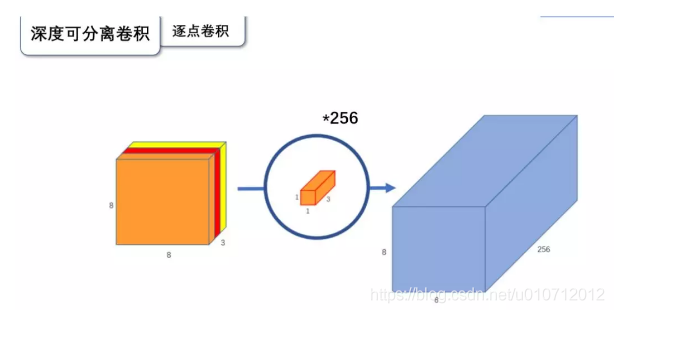
在深度卷积的过程中,我们得到了8 8 3的输出特征图,我们用256个1 1 3的卷积核对输入特征图进行卷积操作,输出的特征图和标准的卷积操作一样,都是8 8 * 256了。
为什么要用深度可分离卷积?
这个问题很好回答,如果有一个方法能让你用更少的参数,更少的运算,但是能达到差不多的结果,你会使用,啊?
深度可分离卷积就是这样一个方法。我们首先来计算一下标准卷积的参数量与计算量(只考虑madd):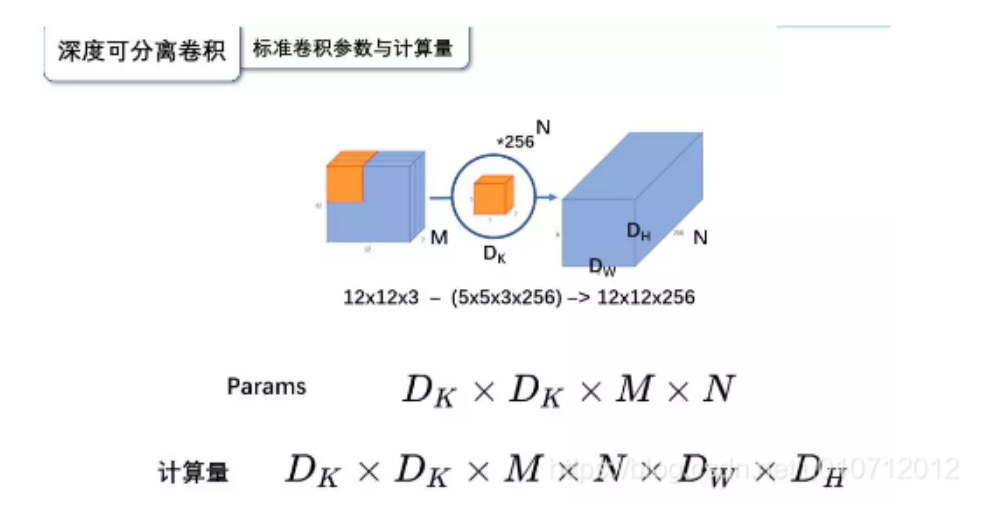
标准卷积计算完了,我们接下来计算深度可分离卷积的参数量和计算量: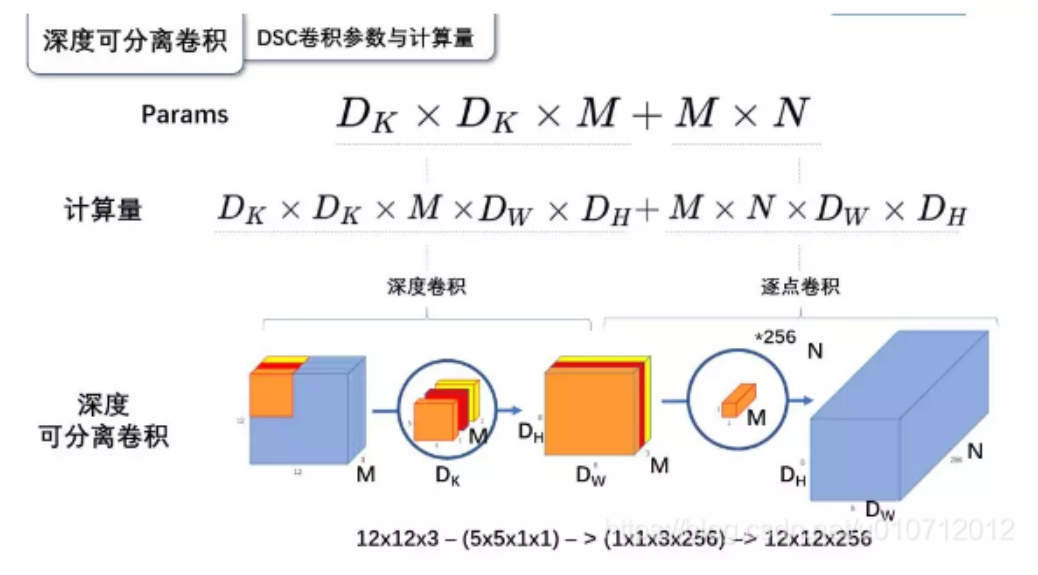
总的来说:
可见参数数量和成家操作的运算量均下降为原来的
我们通常使用的是3 * 3的卷积核,也就是会下降为原来的九分之一到八分之一
参数量和计算量的比较、指标的比较请看博客:
https://blog.csdn.net/u010712012/article/details/94888053
MobileNet-V2
MobileNetV2
《Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation》
2018年1月公开在arxiv:https://arxiv.org/abs/1801.04381
mobilenetv2是对mobilenetv1的改进,同样是一个轻量化卷积神经网络
创新点:
1、inverted residuals,通常的residuals block是先经过一个1 1 的conv layer,把feature map的通道数先“压下来”,在经过3 3conv layer,最后经过一个1 * 1 的conv layer,将feature map通道数再“扩张”回去。即先压缩,后扩张。
而inverted residuals 是先扩张,最后压缩,为什么这么做呢?请往下看。
2、linear bottlenecks,为了避免relu对特征的破坏,在residual block的 Eltwise之前的那个1 * 1conv不再采用relu,为什么?请往下看。
创新点全写在论文标题上了!
由于才疏学浅,对论文理论部分不太明白,所以选取文中重要结论来说明MobileNet-V2.
先看看mobilenetv1和v2有什么不同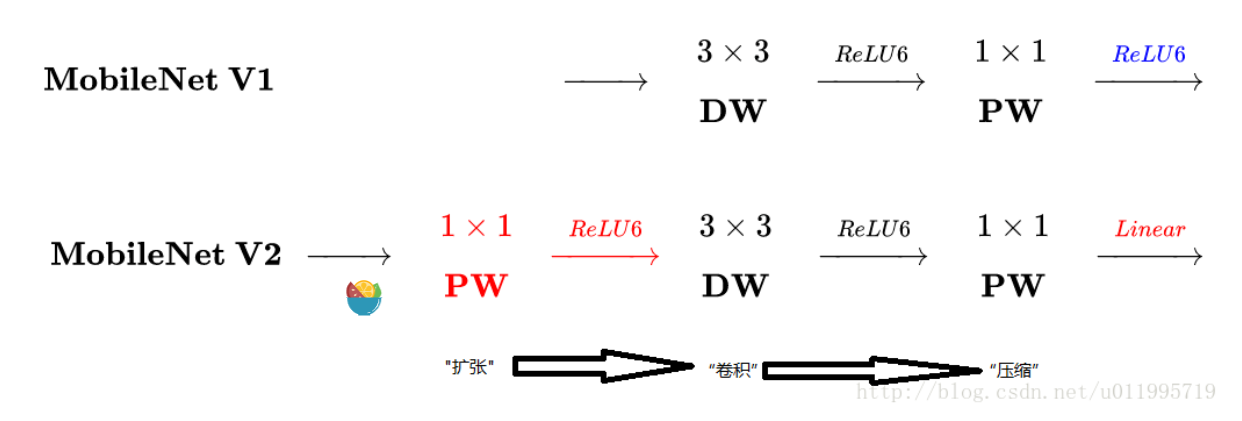
主要是两点:
1、depth-wise convolution之前多一个1 *1 的扩张层,目的是为了提升通道数,获得更多特征;
2、最后不采用relu,而是linear,目的是防止relu破坏特征。
再看看MobileNetV2的block和resnet的block: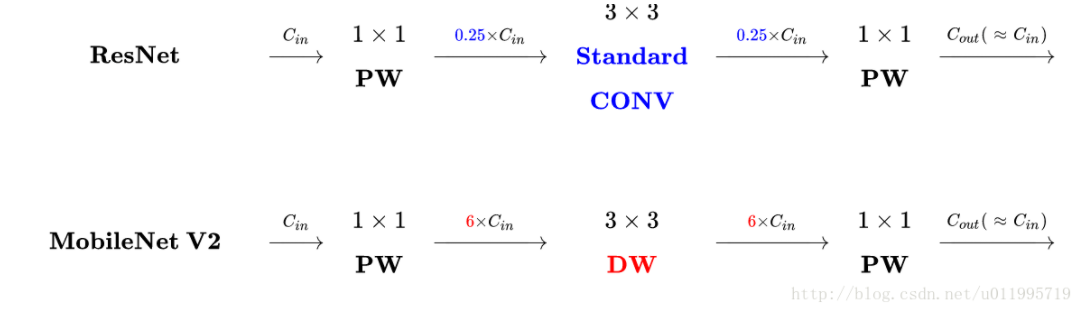
主要的不同之处在于,ResNet是:压缩->卷积提取特征->扩张,MobileNetV2则是Inverted residuals,即扩张->卷积提取特征->压缩
正文:
mobilenetv1最大的特点就是采用depth-wise separable convolution来减少运算量以及参数量,而在网络结构上,没有采用shortcut的方式
resnet以及densenet等一系列采用shortcut的网络的成功,表明了shortcut是个非常好的东西,于是mobilenet-v2将这个好东西拿来用。
拿来主义,最重要的就是结合自身的特点,MobileNet的特点就是depth-wise separable convolution,但是直接把depth-wise separable convolution应用到residual block中,会碰到如下问题:
1、DWconv layer层提取到的特征受限于输入的通道数,若是采用以往的residual block,先压缩,再卷积体特征,那么DWconv layer可提取的特征就太少了,因此一开始不压缩,MobileNetV2反其道而行,一开始先扩张,本文实验扩张倍数为6。通常residual block里面是压缩->卷积提取特征->扩张,mobilenetv2就变成了扩张->卷积提取特症->压缩,因此称为inverted residuals。
2、当采用扩张->卷积提取特症->压缩时,在压缩后会碰到一个问题,那就是relu会破坏特征。为什么这里的relu会破坏特征呢?这得从relu的性质说起,relu对于负的输入,输出全为0,;为本来的特征就已经被压缩,在经过relu的话,又要损失一部分特征,因此这里不采用relu,实验结果表明这样做事正确的,这就成为linear bottlenecks。线性瓶颈的意思,意思就是不要relu
MobileNet-V2网络结构
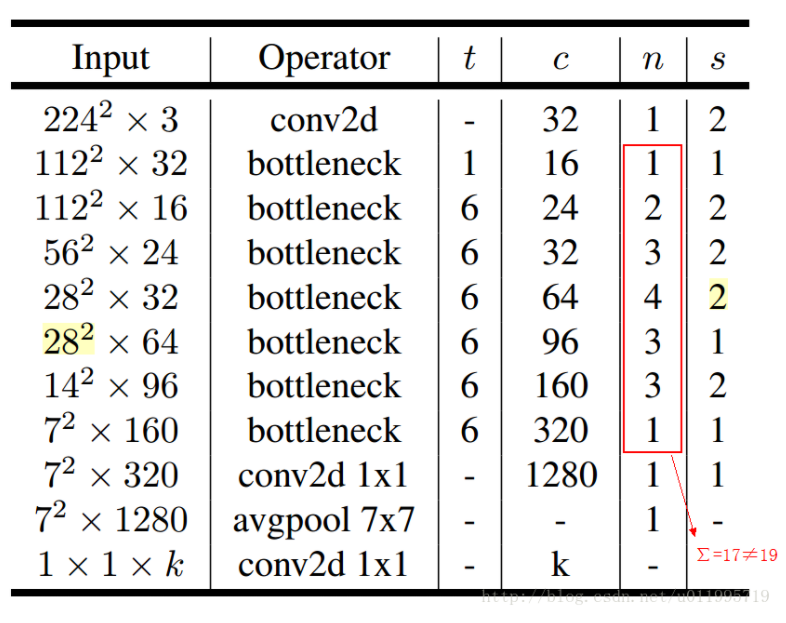
其中:t表示扩张倍数,c表示输出通道数,n表示重复次数,s表示步长stride
先说两点有误之处吧:
1、第五行,也就是7~10个bottleneck,stride=2,分辨率应该从28降低到14;如果不是分辨率出错,那就应该是stride=1;
2、文中提到共计采用19个bottleneck,但是这里只有17个
conv2d和avgpool和传统的CNN里的操作一样;最大的特点是bottleneck,一个bottleneck由如下三个部分构成:
这就是之前提到的inverted residuals结构(inverted residuals就是bottleneck?),一个inverted residuals结构的multiply add = 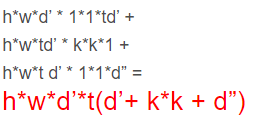
特别的,针对stride=1和stride=2,在block上有稍微不同,主要是为了与shortcut的维度匹配,因此,stride=2时,不采用short cut。具体如下图: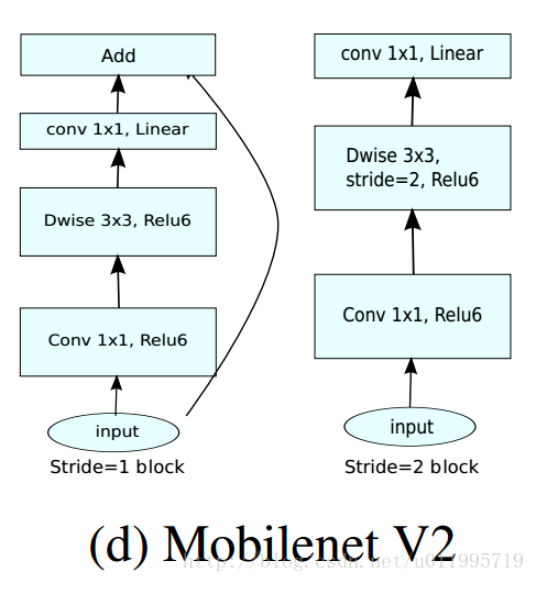
可以发现,除了最后的avgpool,整个网络并没有采用pooling进行下采样,而是利用stride=2来下采样,此法已经成为主流,不知道是否pooling层对速度又影响,因此舍弃pooling层?是否有朋友知道哪篇论文里提到了这个操作?
看看mobilenetv2分类时,inference速度: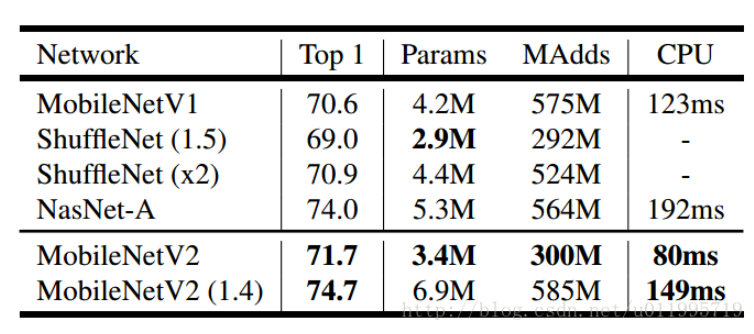
这是手机的cpu上跑出来的结果(google pixel 1 for tf-lite)
同时还进行了目标检测和图像分割实验,效果都不错,详细请看原文

若有收获,就点个赞吧
0 人点赞
