LeNet
https://blog.csdn.net/qq_42570457/article/details/81460807
https://blog.csdn.net/mmm_jsw/article/details/88185491?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.add_param_isCf&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.add_param_isCf
https://cuijiahua.com/blog/2018/01/dl_3.html
离散二维滤波器就是卷积核?
神经元是卷积核在某一层需要卷积的次数 输出层数
即(Winput - Wk + 2p)/S 的平方 输出层数
连接数等于Winput Winput 可训练参数
也就是有Winput的平方个神经元共享参数
LeNet-5
https://www.jianshu.com/p/ce609f9b5910
C5层是一个卷积层,但是与s4层全相连,有种用卷积层代替全连接层的意思。需继续了解,如全卷积网络。
https://zhuanlan.zhihu.com/p/65150848
用卷积层代替全连接层,可以对一定范围内不同大小的图片进行训练,这个范围取决于池化层的数量,加入池化层是3层,则范围是2^3 = 8。
网络的最后一层全连接层(第一个全连接)可以替换成卷积层,此时卷积核的大小和输入图的大小一致,称之为全卷积层。全连接转换成全卷积层的权重一致
卷积就是一个稀疏的全连接。
AlexNet
https://blog.csdn.net/u012679707/article/details/80793916
- 选用relu作为激活函数,relu为非饱和函数,论文中验证其效果在较深的网络超过了sigmoid,成功解决了sigmoid在网络较深时的梯度弥散问题
- dropout方式模型过拟合
- 重叠的最大池化,为了避免平均池化的模糊化效果,全部使用最大池化。overlapping pooling重叠池化,即stride < size,池化的步长小于核尺寸,这样使得池化层的输出之间会有重叠和覆盖,提升了特征的丰富性
- 提出LRN层(重点),提冲LRN层,对局部神经元的活动创建竞争机制,使得响应较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。(VGG提出,LRN对结果没什么帮助,而且浪费了内存的计算的损耗)
- GPU加速
- 数据增强,减轻过拟合
值得注意的是,55的卷积可以用两个33的卷积代替,77的卷积可以用三个33的卷积代替,效果完全一致,但可以减少计算量,且增加更多的非线性
VGGNet
https://www.cnblogs.com/ys99/p/10835805.html
以上是实现
由牛津大学视觉几何组提出(visual geometry group)。统一路卷积中使用的参数,比如卷积核大小33,stride = 1,padding = 1,增加了网络的深度。至少证明,更小的卷积核并且增加卷积神经网络的深度,可以有效的提升模型的性能。11的卷积层是一种增加决策函数的非线性的方式,而且还没有影响到卷积层的感受野。
- 小卷积层堆叠:两个3 x 3的卷积核等效于一个5 x 5的卷积核,感受野相同,且参数量更少(input *),三个3 x 3的卷积核等效于一个7 x 7的卷积核。因为每层过后有一个relu函数,所以非线性变换更多了。(还需要继续研究,因为实际操作中,小卷积核的堆叠并没有使参数量变少,反而变得更多了)
- 5段卷积,每段卷积内有2-3个卷积层,同时尾部连接一个最大池化层
- 越深的网络效果越好
- LRN层作用不大
- 1 x 1的卷积也是很有效的,但是没有3 x 3 的卷积好,大一些的卷积核可以学习更大的空间特征。
- 训练使用加动量的小批基于反向传播的梯度下降法来优化多项逻辑回归目标。批数量为256,动量为0.9,权值衰减参数为5 * 10^-4,dropout为0.5,学习率为0.1,且当验证集停止时以10的倍数衰减,同时,初始化权重取样于高斯分布,偏执初始化为0
值得注意的是,VGG复杂网络的实现很有意思,可以多看看他是怎么实现的,不要再用很low的sequential了
数据增强方法
GoogleNet
https://blog.csdn.net/qq_27464321/article/details/81254920
https://blog.csdn.net/shuzfan/article/details/50738394?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-2.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-2.control
这两个网页可以多看几遍
物体检测的最大收益并不是使用深层网络或者更大的模型,而是来自深层架构和经典计算机视觉的协同作用。
在网络中大量使用11的卷积核,使用11卷积核主要用来减少维度从而消除计算瓶颈,否则会限制网络的大小。使用1*1卷积核,不仅可以增加网络深度,而且还可以增加网络宽度(inception)且不会有太大的网络性能损失(功耗和内存不会增大过多)
一般来说,提升网络性能的最直接方法是:① 增加网络深度 ② 增加网络宽度
缺点:容易陷入过拟合中。简单的增加网络的大小,参数量变大,而得不到充分的利用
解决上面的两个缺点的思路:
将全连接的结构转换为稀疏结构(即使是内部卷积)
如果数据集的概率分布可以可以有大型的稀疏的深度神经网络表示,则优化网络的方法可以是逐层的分析层输出的相关性,对相关的输出做聚类操作(重要,周师兄的观点)
卷积在空间域的稀疏特性
patch是CNN输入图像中的一个小块,一个过滤器(CNN卷积核)一次只处理一个patch,而不是整个图像
inception v1:
- 深度,层数更深,才用了22层(9个inception模块)。为了避免梯度消失问题,不同深度增加了两个loss来保证梯度回传消失
- 宽度,增加了多种核11,33,5*5还有直接maxpooling
- 1*1卷积核降维
- 网络最后才用了average pooling替代全连接层。想法来自NIN。但是实际最后还是加了一层全连接层,主要为了方便finetune
- 虽然移除了全连接,但是网络中依然使用了dropout
- 避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。实际测试中,这两个额外的softmax会被去掉。
inception v2 & v3
寻找一种扩大网络的同时又尽可能地发挥计算性能。这里给出了一些已经被证明有效的用于放大网络的通用准则和优化方法,这些准则和方法适用但不限于inception结构。
general design principles:
- 避免表达瓶颈,尤其是在网络靠前的地方。前馈网络可以用从输入层到分类器或回归器的无环图来表示。这位信息流定义了一个明确的方向。对于分离输入到输出的任何切口,可以访问通过这个切口的信息数量。应该尽量避免由极端压缩聚类带来的瓶颈。通常来说,在到达最后的表达之前,表达的大小应该慢慢的减少。理论上讲,信息内容的评估不能仅仅通过表达的维度数量来衡量,因为它抛弃了相关结构等重要因素;维度数量仅仅提供了信息内容的粗略估计。
- 更高层的维度表达可以更轻易的被网络处理。增加卷积网络中的激活函数允许更多可区分的特征。由此产生的网络会训练的更快。
- 空间聚类可以在低维度中嵌入并且不会损失过多或根被不会损失网络的表达性能。比如说,在进行一个展开卷积(比如3*3)之前,可以降低输入表达的维度即进空间聚类,并且不会有严重的副作用。我们将设造成上述结果的原因是:如果输出被用来空间聚类上下文的话,相邻单元结果之间的强相关性,在降维过程中,减少了信息的损失。鉴于这些信号应该很容易被压缩,维度的减少可以促进(网络)更快的学习。
- 要平衡网络中的深度和宽度。最佳性能的网络应该能达到每次滤波器数量(输出通道数)和网络深度的平衡。增加网络的宽度和深度可以带来更高的网络性能。但是,如果两者(滤波器数量和网络深度)都并行的增加,则可以恒定计算量下的最优改进。计算量预算应该因此被以一种平衡的方式分配网络的宽度和深度。
尽管这些原则可能会有效果,但是它并不是直接拿来用就能提高网络的质量。我们希望只在模棱两可的情况下明智地使用它们。
文章中还提到,55的卷积核用两个33卷积核替代不会造成表达能力的降低。3*3之后加激活函数会提高性能。
并且33的卷积核可以由n1的卷积核叠加代替。但是要注意的是,作者发现,在网络上的前期使用这种分解效果并不好,还有在中度大小的feature map上使用效果才会更好,对于mxm大小的feature map,建议m在12到20之间。
v2采用了一种更高效的数据压缩方式(grid reduction technique),为了将特征图的大小压缩为1/2的大小,同时通道数变为2倍,坐着使用了一种类似inception的reduction结构,同时做pooling和conv,conv的stride为2,再将两者结果堆叠起来,实现了特征图的压缩和通道数的扩增。
https://zhuanlan.zhihu.com/p/66066537
inception v4
https://blog.csdn.net/u013841196/article/details/80673688
主要是将resnet和inception进行了结合,有inception v4和inception resnet v1和inception resnet v2
作者提出,residual connection的提出是用于训练更深的网络,但是作者发现不适用residual connection也可以训练更深的网络。residual connection并不是必要条件,只是使用了residual connection会加快训练速度
ResNet残差网络
https://blog.csdn.net/sunnyyeah/article/details/89430124
还不够深入,可以继续看文章。因为挺多网络都使用了残差结构。-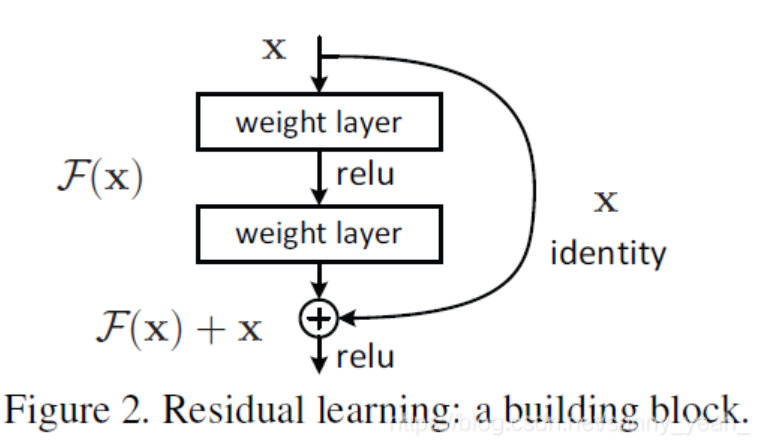
总结下来就是上面这个图。
这里的x指的是特征图上的像素,即特征矩阵。weight layer可以理解为卷积层,最后的输出为H(x).
传统神经网络是H(x)=F(x),但是现在采用残差结构。H(x)= F(x) + x,就是原本的特征矩阵加上卷积后的特征矩阵,直接值相加。
残差就体现在F(x)上。传统网络结构需要学习的是整个H(x)部分的权重,但是现在只要学习F(x)部分的权重。要学习的参数量是相等的。但是不需要更新那么的多(我的理解)。
这样可以让很深的网络不容易梯度爆炸或者梯度消失。后续有类似思想的网络结构出现,比如densenet。
加入x的维度小于F(x)的维度,则要升维,两种方法:全0或1*1卷积升维。
MobileNet V1
https://blog.csdn.net/u010712012/article/details/94888053
介绍mobilenetv1只有一句话,就是把vgg中的标准卷几层换成深度可分离卷积就可以了。
深度可分离卷积(depthwise separable convolution)
可分离卷积:
- 空间可分离。把一个大的卷积分成两个小的卷积。比如33分解为13和3*1
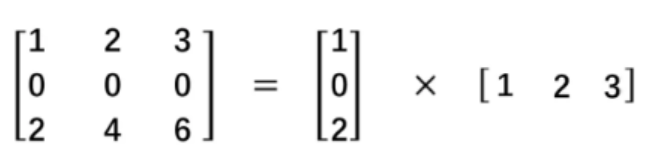
- 深度可分离卷积

普通卷积: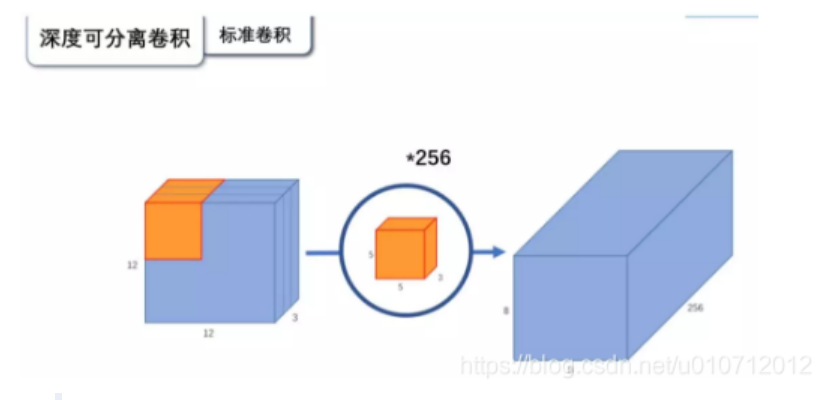
深度可分离卷积: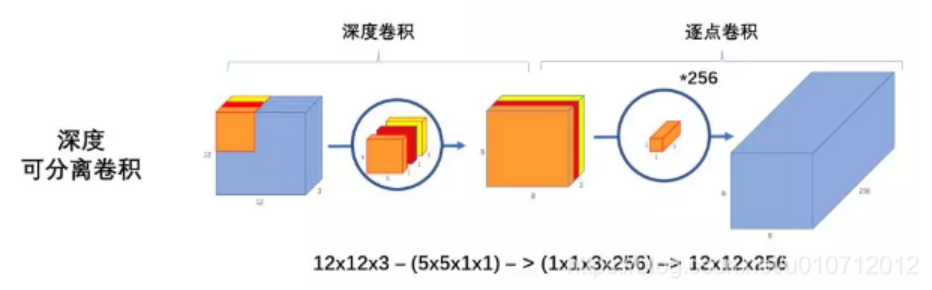
为什么要用深度可分离卷积?
因为更少的参数,效果却不会差太多。
relu6
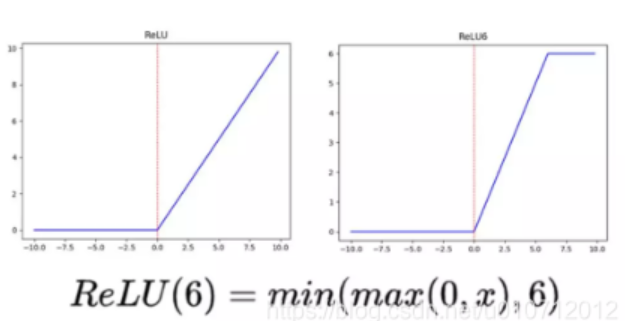
当输入的值大于6的时候,等于6,小于6的地方和relu一样。作者认为relu6作为非线性激活函数,在低精度计算下具有更强的鲁棒性。(这里所说的低精度,我看到有人说不是指的float16,而是指的顶点预算(fixed-point arithmetic))
并且作者提到,整个计算量基本集中在11卷积上,参数也集中在11卷积上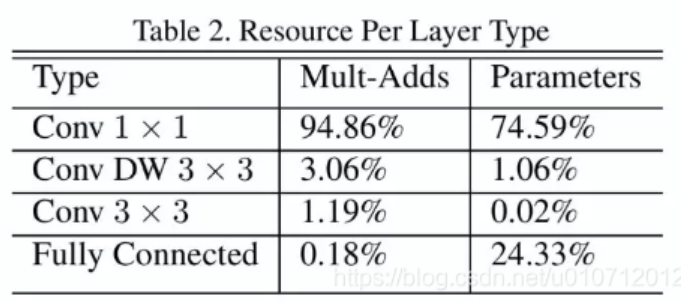
dw就是深度可分离卷积,pw就是11的卷积
平均池化层用在最后一层,比如要输出1000个类型,最后的特征图是771000,那就可以用平均池化编程11*1000,这样就不用先展开然后在全连接全连接全连接了。省去了不少参数
MobileNet V2
https://blog.csdn.net/u011995719/article/details/79135818
《Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation》
论文题目即创新点:
1、inverted residuals,通常的residuals block是先降维,然后卷积,再升维。但是inverted residuals是先升维,在深度可分离卷积,再降维。
2、linear bottleneck,为了避免relu对特征的破坏,在residual block的eltwise sum之前的那个1*1conv不再采用relu。(大概是因为深度可分离卷积,第一个卷积能提取到的特征本来就不多,通道数还减少了,就更难提取特征了,所以要升维。然后relu会使破坏特征,所以在用了dw之后,可以不适用relu)

若有收获,就点个赞吧
0 人点赞
