1. 论文分享
A ConvNet for 2020s,是Facebook AI Rearch (FAIR)和UC Berkeley
2. 论文进展
编辑预审,返修,大修
修改意见:
Editorial Pre-Screening: Significant amount of published material is repeated in the paper which makes 18% duplication. It must be reduced. Also, authors have used well recognized and published methodologies with some modifications and results are compared mostly with several years old methodologies. Authors need to bring novelty and originality to their work and need to establish clear superiority of their methodology through comprehensive comparison results with very recent algorithms published in higher Impact Factor journals. Authors must explicitly reference those references of the recent methodologies with which comparisons have been performed to show superiority in the text of the paper. They also must include complete list of those references in the authors’ explanations.
总结:查重率高,创新点不足
收到意见后,除了降低查重,还想在创新点上进行进一步修改。
总体的思路:
从上一版本的CCT+CBAM组成的parallel skip connection换成CCST(Channel Cross Swin Transformer)
目前的优势:指标上升,参数量减少,Swin版本的CCT,也可作为一个skip connection的替代品
讲解:
在自注意力中,感受野是否越大越好?或者说全局注意力机制是否一定比局部注意力机制效果好?
猜想:不一定,全局注意力机制不仅会浪费计算资源,还会影响关联性高的区域分数
尝试1:给自注意力机制中加入窗口限制,使得自注意力机制在窗口内进行计算。简单来说是将Swin-Transformer进行channel-cross的自注意力计算
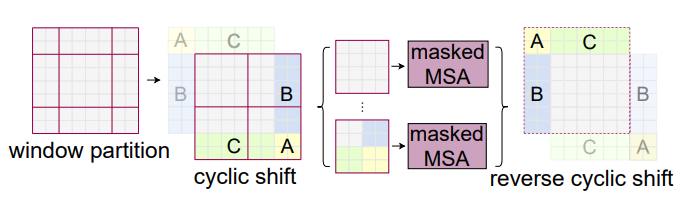
失败:代码上行不通,qkv的维度配不上,attention mask的维度配不上,看下图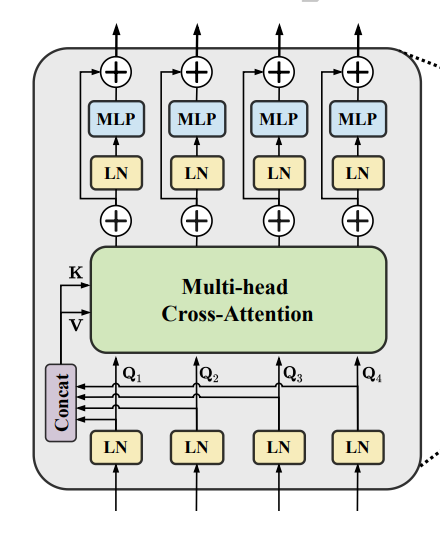
尝试2:不加入shift 操作,也不加入attention mask,进行单纯的窗口自注意力机制(非Swin)
失败:效果并没有变好,反而变差了
尝试3:重新思考CCT设计的合理性,CCT设计的根本是为了增强UNet中4条skip connection的语义特征传播效率,使得4条connection互相关联,互相进行自注意力机制计算,得出最合适的一个语义特征输出。为了实现这个想法,作者甚至修改了常见的自注意力机制的计算公式:
CCT自注意力计算公式: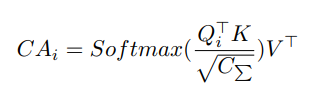
常见自注意力计算公式: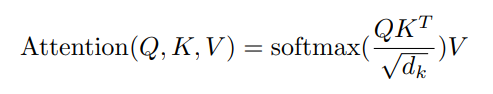 (来自attention is all you need)
(来自attention is all you need)
先不论转置Q,K,V转置对结果的影响,我决定将自注意力的计算方式变为常见的计算方式。
失败:代码不好写,弄了很长时间
尝试4:重新思考CCT中q,k,v设计的合理性。q,k,v是将patch进行一次映射得到(代码中就是简单的线性层)。为了使得4条skip connection相互关联,CCT中的K和V是用4条skip connection叠加后进行的映射。所以为了实现自注意力计算,作者只能修改自注意力计算方式。q,k,v分别为查询量query、键值key以及待更新的值value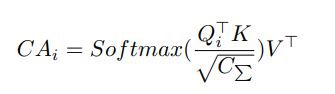
所以以上公式进行的是:用1条查询量,去查询4条键值,得到一个attention分数,再去更新4条待更新的值。虽然V是四条connection的叠加映射,但是由于公式修改了,最后得到的是一条输出,使得CCT成立。
我认为自注意力机制应该更新的是自己的映射,而非4条connection的叠加映射。所以我对代码进行的修改。① 使得key是4条connection的叠加,并且映射到一条connection的长度(通过线性层);② 使得value不再是4条connection的叠加映射,而是自己本身的映射。以上修改的总结是:一条查询量去查询4条键值来更新一条待更新的值。更通俗的来讲是:我一个人查询4个人来更新我自己。
失败:效果并没有变好,还是和之前的结果一样。
尝试5:虽然失败,但是我依然认为自注意力应该就得是自己查询,更新自己,而不是更新其他量。由于尝试3已经将patch的维度变的一样长,所以就可以完美适配Swin-Transformer中的shift操作attention mask操作。于是就是代码重写环节,将shift windows和attention mask加到其中
成功:指标上升,参数量下降
优势:
- 应该足以作为一个创新点写进论文中,使用Swin-Transformer作为skip connection的替代品,属于自创,而非之前CCT+CBAM两个旧东西的叠加。
- 指标上升,参数量减少
劣势:
- 指标上升,但是不多,比如从91.84到92.24
- 参数量减少,但是不多,参数量的减少和网络通道数成正比,一个240MB的UCTransNet可以减少到210MB,但是一个34MB的PIUCNet只减少到33MB
- 窗口自注意力理应计算量减少,但是训练时间并未减少,估计是window partition也占用了推理时间,还需优化

若有收获,就点个赞吧
0 人点赞
