1 Technische Universit¨at M¨unchen, M¨unchen, Germany 2 Fudan University, Shanghai, China 3 Huawei Technologies, Shanghai, China
Abstract
Swin Unet is a Unet-like Pure Transformer for Medical Image Segmentation. The whole Swin-Unet structure design is based on Swin-Transformer and Unet.
Motivation
虽然CNN到目前为止已经取得了优秀的成绩,但是它也是有缺点的,明显的,它没有办法学习到global and long-range semantic information,原因可以归结到卷积本身是一种局部的操作。
并且CNN还不能完全满足高精度的医学图像任务。
而Vit、DeiT和Swin Transformer在图像识别任务上证明了transformer在视觉任务上具有巨大的潜力。
(所以作者想把Transformer用在医学图像中来,那么很明显,医学图像中著名的网络unet就是目标,作者将Swin Transformer和Unet进行了融合)
Methods
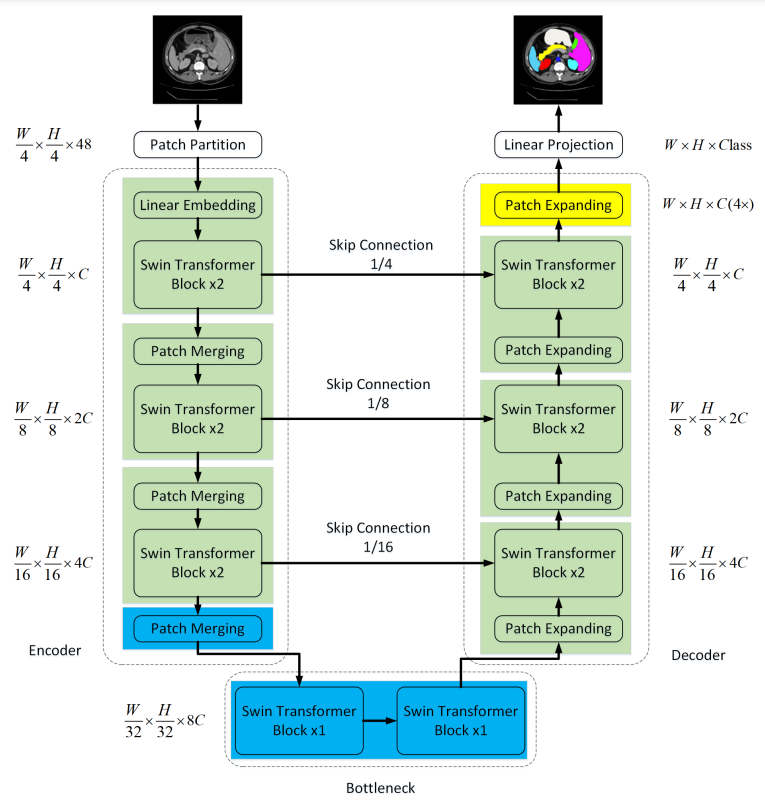
整个网络框架,可以分为以下几个部分:
- Swin-Transformer (encoder)
- patch partition
- linear embedding
- Swin-Transformer block
- patch merging
- patch expanding (decoder)
- Swin-Transformer block
- skip connection
作者提出了patch expanding和skip connection的结构。
patch expanding
为了获得一个U-shape即对称的网络结构,作者提出了一个patch expanding的模块。该模块对标Swin-Transformer中的patch merging。
patch merging的作用是融合adjacent 2 * 2个patch,通道数增加,图像中的patch数量减少,是一种下采样的思想。
那么patch expanding的作用就是对输入特征图进行上采样。首先,将输入特征图输入到一个linear layer中,使得特征的维度变为原来的两倍,比如encoder末端的输出特征图:
再通过rearrange operation来展开输入特征图,使得特征维度变为1/4倍,即原始输入特征图的1/2倍,长和宽变为原来的两倍(这里的长和宽值patch的数量):
即patch expanding 代表以下过程:
skip connection
类似于U-NET中的skip connection,在decoder即上采样的过程中融合encoder中multi-scale的特征图
按文中的意思可以表达为以下关系式:

即将从encoder skip 过来的特征图和上采样后的特征图进行concat,然后再经过一个linaer layer,将通道数下降,使得通道数保持与输入特征图一样。
Contributions
作者自己在文中做出了contributions总结:
- 基于Swin Transformer block,我们构建了一种对称的带有skip-connect的encoder-decoder架构。encoder中实现了局部到全局自注意力,decoder中将global features上采样,将特征图变为与原图相同的分辨率以实现pixel level的分割预测。
- 提出了patch expanding layer,达到上采样的效果,不使用任何的差值操作或者反卷积操作。
- 我们在实验中发现skip connection对transformer也是有效果的。
至此,一个纯净的transformer-based的、U-shaped的、带有skip connection的encoder-decoder架构就建立起来了,我们将其成为Swin-Unet。
作者提供了一种完全对应unet的transformer-based的unet网络结构。
Experiments
作者在Dice-Similarity coefficient(DSC) 和 Hausdoff Distance(HD)这两个指标与其他网络进行对比。比如V-Net、U-Net、Att-Unet、TransUnet等CNN-based网络或Transformer-CNN融合网络进行对比,达到了SOTA效果。
个人比较关注作者所做的消融实验
Effect of up-sampling
作者将patch expanding和bilinear interpolation、反卷积进行了对比,证明patch expanding效果最好。
Effect of number of skip connections
我很关注这个消融实验,最近提出的UCTransNet就提出了Unet中的skip connection并不是必须的。作者在本文中也进行了这个实验,得到的结果确实skip connection的数量越多效果越好。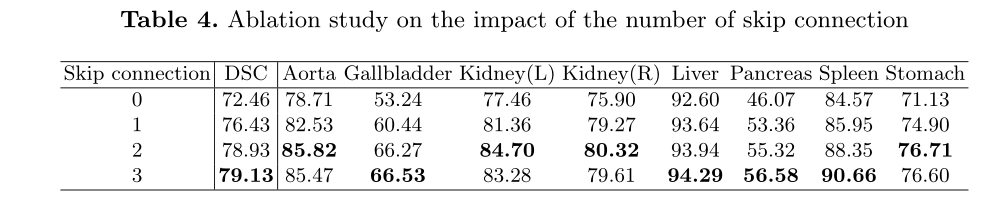
但是感觉这个实验不能说明什么,文中没有明确说明skip connection的数量对应的是哪几个skip connection,不同的skip connection对结果带来的影响是不同的,所以可以忽略这个实验。
Effect of input size
结果是图像越大越好,原因作者认为是大图像拥有更多信息。但是由于计算量、实时性的原因,选择了224*224的较小的分辨率输入。
Effect of model size
这里提到的model size是Swin-Transformer的模型大小,实验结果证明模型增大没有太大的性能提升。
个人认为是因为在医学图像中,根本不需要大模型,一个小的模型就可以表达所有的映射关系,还可能会过拟合。
Future Work
作者在实现U-shaped的Swin-Unet的过程中,都是将Swin-Transformer的模块对称过来,再通过linear layer调节,感觉过于简单粗暴,或许能有更好的办法替代文中patch expanding和skip connection中的linear layer,即使作者做了一些相关的ablation
Consideration
感觉整篇文章的撰写以及创新点都有些差强人意,甚至会让人怀疑文中提出的一些创新点、模块是否真的有用。
但是不可否认的是作者给出了一种U-Shaped的transformer。UNet可以说是最简单的网络之一,而Swin-Unet使得将transformer运用在医学图像的dense segmentation中变得非常简单。接下来我也将尝试Swin-Unet并且尝试对其进行改进。
Swin-Unet on Iris Database
结果是比较差的,比不上最原始的CNN-based Unet,甚至结果差的挺多。
分析原因可能由以下几点:
- transformer的优势在于全局注意力,CNN的缺点同时优势在于局部注意力或者说局部感受野。对于虹膜数据集,一张图像上可能只有一个区域、小区域需要网络去学习,transformer过多的关注其他的地方会导致性能的下降。
- 个人认为,transformer在embedding即将图像序列化的过程,已经破坏了图像的连续性,对于虹膜分割这种细粒度极高的分割任务,是不合适的。
- 在Swin-Transformer论文中提到ViT的一大缺点是网络难以收敛,而Swin-Transformer缓解了这个问题。但是可能难以收敛的问题可能依然存在,相比于CNN-based 网络。所以由于虹膜数据集的数量过少,导致模型不能很好收敛。
- 没有使用预训练模型。使用预训练模型感觉也不太合适,因为一个Swin-Transformer-T,也是最小的一个模型,光是backbone就有80MB,显然不适合用于虹膜分割上。除非可以自己缩小模型大小,并用这个模型去训练其他数据及得到一个预训练模型。

若有收获,就点个赞吧
0 人点赞
