Zhuang Liu1,2* Hanzi Mao1 Chao-Y uan Wu1 Christoph Feichtenhofer1 Trevor Darrell2 Saining Xie1†
1Facebook AI Research (FAIR) 2UC Berkeley 加州大学伯克利分校(参考qs32,复旦31)
代码: https://github.com/facebookresearch/ConvNeXt (1月10号发的论文,代码前两天开源的)
Abstract
这是一个没有任何创新点却让人眼前一亮的工作,FAIR和UC伯克利联手打造pure ConvNet对抗并且超越最近大火的vision Transformer(Swin Transformer),重新屠榜。这里的“没有创新点”指的是,作者将深度学习发展至今最新的技术包括vision Transformer的设计理念应用到了经典网络ResNet中,并重新命名为ConvNeXt,是一个汇总型的工作,但是逻辑清晰、实验充分,最后的效果也是SOTA。
推荐指数: / 10 颗星
推荐原因:
- 文中涉及到的知识点全面。可以帮助对整个深度学习知识点的把握。知识点包括但不限于卷积、分组卷积depthwise conv、卷积核大小的影响、Transformer、patchify、自注意力机制、多头注意力机制、ResNet、basicblock(stage)、stem cell、EfficientNet、inverted residual block、training strategy、通道数对网络的影响、激活函数的类型或数量对网络的影响、Normalization的类型或数量对网络的影响
- 论文的思路就是卷积神经网络涨点的思路。整个论文都是为了让ConvNet能够和Transformer对抗,然后运用各种最新的技术(不包括任何注意力机制),使得指标上升。这对于我们这种做人工智能小分支、需要指标涨点发论文提供了思路,甚至可以照搬论文的改进流程。
- 卷积神经网络本身更适合于特殊视觉(小)任务。卷积神经网络可以更好的应用到不同视觉任务中,因为其简单,好设计,不像Transformer,往往需要更多的数据、更多的训练内存、更好的训练策略。(这个经过我和魏佳钰的验证,至少Swin Transformer不适合于虹膜分割或重定向)。这篇论文也是帮助深入了解卷积神经网络。
- 文章语句用的很有意思。看论文有种聊天的感觉。
Methods
论文的改进可以用一个图总结: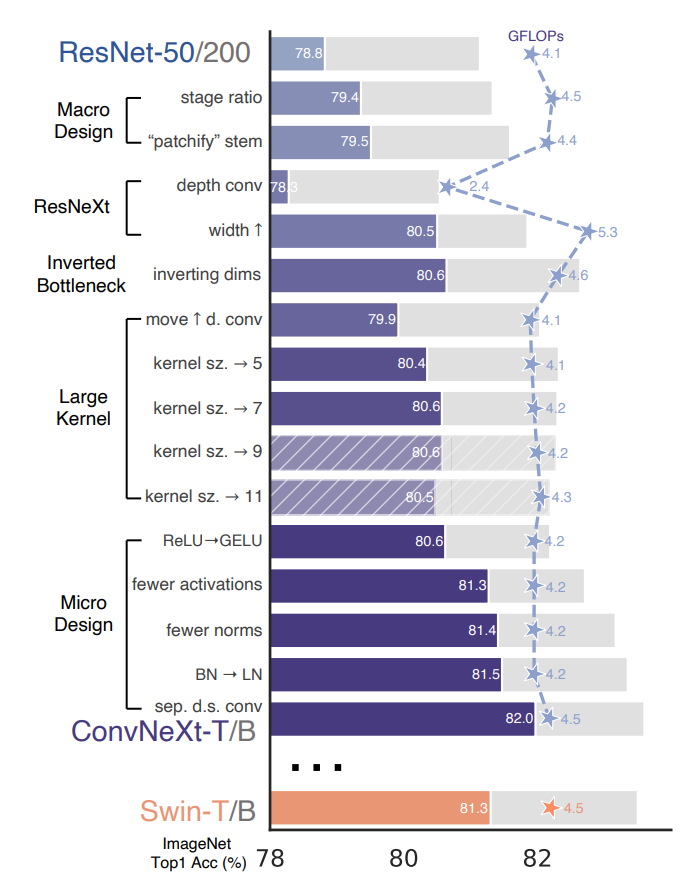

若有收获,就点个赞吧
0 人点赞
