Zhe He
AIT Lab, ETH Zurich,瑞士,苏黎世联邦理工大学, 2021年qs世界大学排名69名
官网:www.ait.ethz.ch
Abstract
利用GAN网络,提出了一种用于解决photo-realistic的monocular视线重定向的框架。
在GAN网络的基础上,额外使用了几种针对于此任务的loss。
Motivation
gaze redirection有很多应用场景,比如videoconferencing,films,games,人际交流等。但是现有的方法缺少生成perceptually plausible结果的能力。
现有的Gaze Manipulation总结: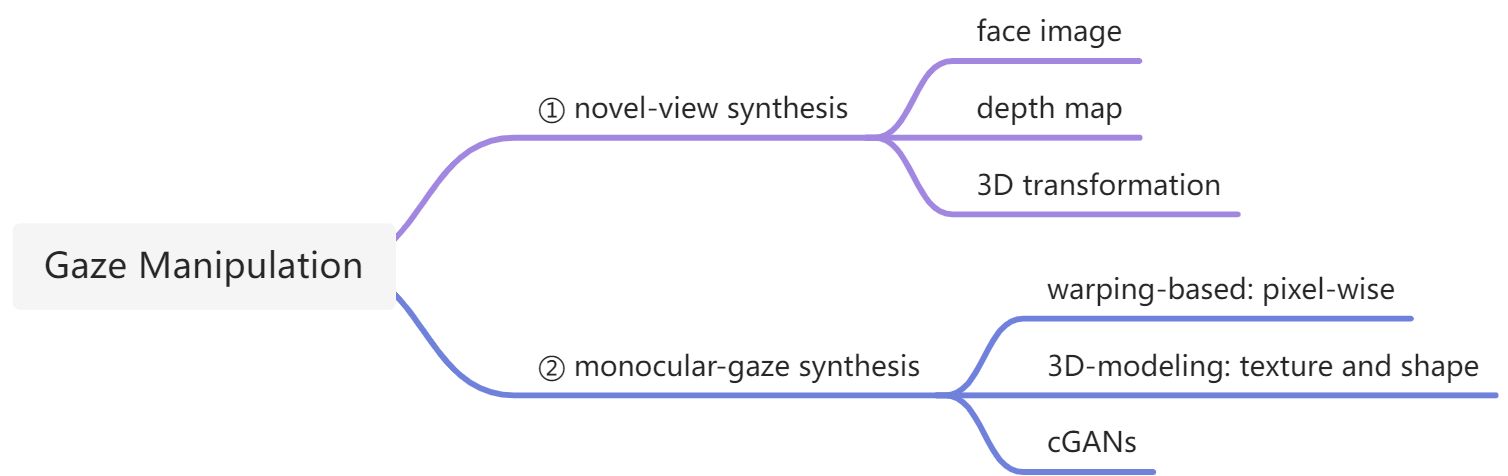
- novel-view synthesis方法需要整张脸的图像,并且需要监测深度的设备生成depth map,然后再进行3D transformation,要么设备昂贵,要么计算量大无法应用。
- monocular-gaze synthesis的方法只需要单眼图像,不需要额外设备,实现简单。这个类别下又分三种方法:
- warping-based:个人理解是2D的warp方法,比如透视变换、仿射变换这种,变换是pixel-wise的,所以结果看起来不会很逼真,因为他很难凭空产生像素,使得整体结构看起来逼真。
- 3D-modeling:估计也是需要depth map的那种三维transformation
- cGANs:作者的方法,通过网络学习出重定向的图片表示。
Methods
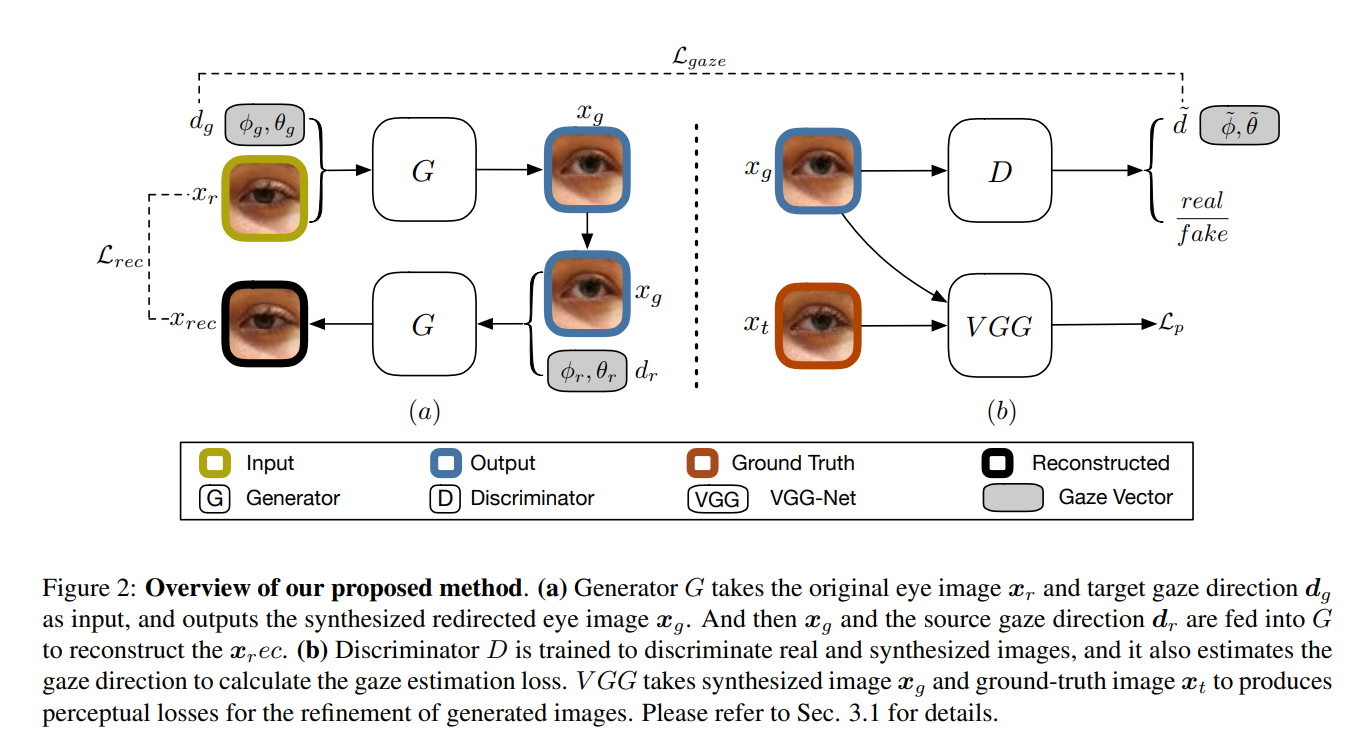
这一图其实就把作者的methods说完了,作者并未提出具体的创新网络或模块,而是为视线重定向提供了一个框架一个思路。
整体框架还是cGANs模型,即带条件的generator和discriminator。
其中一个重要的创新点是loss的设计,除了基本的adversarial loss之外,作者额外的增加了三个loss:
- gaze estimation loss:


表面意思,用于判断gaze准确性的loss - reconstruction loss:


坐着提出reconstruction loss的作用是保证personalized features不变,比如eyeglasses,skin tone等信息。那么个人根据此推断,重定向后的图片的gt,可能和train的原图不是同一个人的图像,重定向的gt只是gaze方向是预设的方向(待求证)。 - perceptual loss:
mean to match to gt images perceptually, not in the pixel-wise (MSE) way.
content loss:用于解决color、texture问题
style loss:用于解决structure、spatial relation问题
Conclusion
没有精读,大概了解了一下cGANs做重定向的方法、流程。
假如研究目标是为虹膜识别服务,那么必须满足两个条件:① 像素要高; ② 重定向后的texture不能变
如果在此论文基础上进行修改,可以把研究中心转成texture pixel-wise的而不是photo-realistic的。可以尝试的方法有:
- 保证geneartor中的输入和输出的gt是同一个人的,而且尽量除了视线改变其他地方不动。这样子可以对xg和xt进行MSE方式的loss,将loss推到pixel-wise的惩罚级别
- 或者对perceptual loss进行改进,想办法提高content loss的优先级,让网络在重定向的过程中不丢失texture
- 干脆不使用perceptual loss或MSE loss,将Xg和Xt都送入虹膜识别系统中,进行特征提取,生成特征模板,在两个模板之间比较(本质上就是进行虹膜识别),然后得出一个loss,用来训练。
- 如果是为了虹膜识别服务,那么除了正向,其他角度的重定向都没有必要了,可以简化网络。
Towards texture-wise Gaze Redirection using cGANs for Iris Recognition

若有收获,就点个赞吧
0 人点赞
