Abstract
实时执行像素级语音分割的能力在移动应用程序中是至关重要的。最近针对这一任务的深度神经网络的缺点是需要大量的浮点预算,并且运行时间长,这阻碍了它们的可用性。在本文中,我们提出了一种新的深度神经网络结构,称为ENet(高效神经网络),专门为需要低延迟操作的任务创建。ENet的速度高达18倍,需要的数据处理次数减少75倍,参数减少79倍,精度与现有模型相似,甚至更高。我们已经在CamVid,Cityscapes和SUN数据集上测试了它,并报告了与现有最先进方法的比较,以及网络精度和处理时间之间的权衡。我们提供了在嵌入式系统上所提议的架构的性能度量,并且除了可能使ENet更快的软件改进建议。
1. Introduction
最近人们对增强现实可穿戴设备、家庭自动化设备和自动驾驶汽车产生了浓厚的兴趣,对能够在低功耗移动设备上实时操作的语义分割(或视觉场景理解)算法产生了强烈的需求。这些算法用一个对象类来标记图像中的每个像素。近年来,大数据集的可用性和计算能力强大的及其已经帮助深度卷积神经网络(CNNs)超越了许多传统的计算机视觉算法。尽管cnn在分类和分类任务上越来越成功,但当应用于图像像素标记时,他们提供粗糙的空间结果。因此,我们通常与其他算法级联来细化结果,例如基于颜色的分割或条件随机场,举几个例子。
为了同时对图像进行空间分类的精细分割,人们提出了几种神经网络架构,比如SegNet或fully convolutional networks。所有这些作品都是基于VGG16架构,这是一个多类分类设计的大模型。这些参考文献提出了具有大量参数和长推理时间的网络。在这种情况下,它们无法用于许多移动或电池驱动的应用程序,这些应用程序需要以高于10fps的速度处理图像。
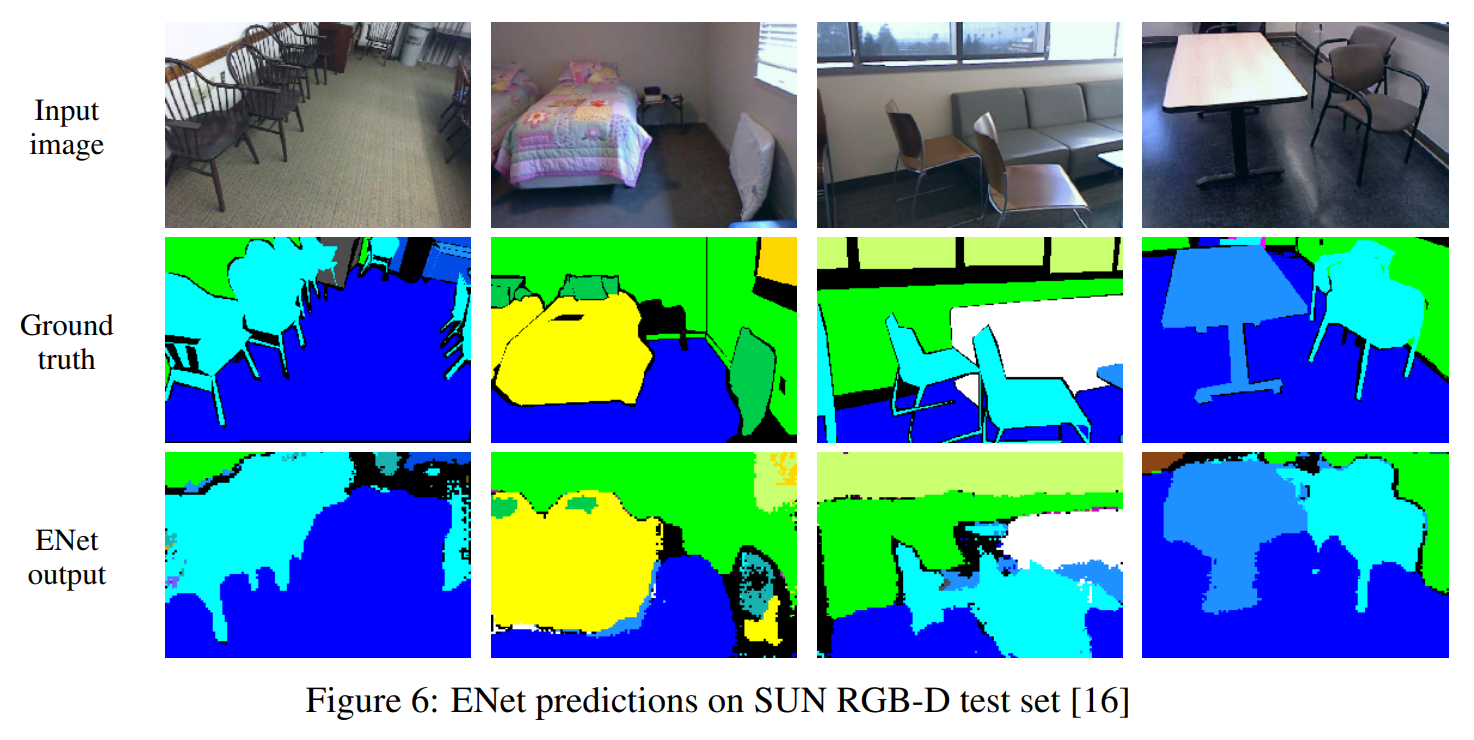
图1 : ENet在不同数据集上的预测(从左到右分别是Cityscapes,CamVid和SUN)
在本文中,我们提出了一种新的神经网络结构,优化了快速推理和高精度。使用ENet分割的图像如图1所示。在我们的工作中,我们选择不适用任何后处理步骤,这当然可以与我们的方法相结合,但是会使端到端CNN方法的性能变差。
在第三节中,我们提出了一种名为ENet的快速和紧凑的encoder-decoder架构。它是根据最近出现在文献中的规则和想法设计的,所有这些我们将在第4节讨论。我们所提出的网络已经在Cityscapes、CamVid的驾驶场景中测试过了,然而SUN数据集被用来测试我们的网络在室内的表现。我们在NVIDIA Jetson TX1陷入是系统模块和NVIDIA Titan X GPU上进行了测试。结果见第5节。
2. Related work
语义分割是理解图像内容和寻找目标对象的重要手段。这种技术是至关重要的应用,如辅助驾驶和增强现实。此外 实时操作是必须的,因此,精心设计CNNs是至关重要的。当代计算机视觉应用程序广泛使用神经网络,这是现在使用最广泛的技术之一,对许多不同的任务,包括语义分割。这项工作提出了一种新的神经网络结构,因此我们的目标是将性能与其他文献比较,以相同的方式进行比较。
最先进的场景解析scene-parsing CNNs使用两种独立的神经网络架构组合在一起:一个编码器和一个解码器。受到probabilistic auto-encoders概率自动编码器的启发,在SegNet-basic中一如了encoder-decoder网络架构,在SegNet中进一步改进。encoder是一个vanilla CNN(如VGG16),它被训练来分类输入,而decoder被用来对encoder的输出进行上采样。然而,这些网络由于其庞大的架构和众多的参数,在推理过程中速度较慢。与全卷积网络不通,最新的SegNet版本抛弃了VGG16的全连接层,以减少浮点操作的数量和内存占用,使其成为这些网络中最小的网络。不过,它们都不能实时操作。
其他现有的架构使用更简单的分类器,然后将它们与条件随机场Conditional Random Field(CRF)级联作为后处理步骤。如[11]所示,这些技术使用了繁重的后处理步骤,并且常常不能标记在一帧中占用较少像素的类。CNNs也可以结合循环神经网络RNN(recurrent neural networks)以提高准确性,但随后它们会出现速度下降的问题。此外,我们必须记住,RNN作为后处理步骤,可以与任何其他技术结合使用,包括本文中介绍的技术。
3. Network architecture
我们的网络架构如表1所示。它被分为几个阶段,以表中的水平线和每个块名称后的第一个数字突出显示。输出大小报告了一个输入图像分辨率为512512的例子。我们才用了一个ResNets的视图,该视图将它们描述为有一个单独的主分支和与之分离的卷积过滤器扩展,然后用一个元素添加合并回来,如图2b所示。每个块由三个卷积层组成:一个用于降低维数的11映射,一个主要的卷积层(图2b中的conv)和一个11展开。我们在所有的卷积之间防止批处理规范化Batch Normalization和PReLU。正如在原始论文中一样,我们讲这些称为瓶颈模块bottleneck modules。如果瓶颈是下采样,则在主分支中添加一个最大池化层。同样,第一个11映射在两个维度上都被一个22、步长为2的卷积层所替代。我们使用对activations进行zero pad零填充,以匹配特征图的数字(大小)。conv是一种规则的、扩张的或者全卷积的(也被称为反卷积deconvolution或部分跨越卷积fractionally strided convolution),带有33的滤波器。有时,我们用不对称卷积替代它也就是一个连续的51和15卷积。对于正则化,我们使用Spatial Dropout,在bottleneck2.0之前p=0.01,之后是p=0.1。
表1 : ENet架构。给出了一个以512*512的输入示例的输出大小。
初始阶段包括一个单独的块,如图2a所示。阶段1由五个bottleneck块组成,而阶段2和阶段3有相同的结构,除了阶段3没有在开始时对输入进行下采用(我们省略了第0个bottleneck)。这前三个阶段是编码器encoder,第四和第五阶段是属于解码器。
为了减少内核调用的数量和总体内存操作,我们在任何映射中都没有使用bias,因为cuDNN使用单独的内核进行卷积和bias加法。这个选择对准确性没有任何影响。在每个卷积层和紧接着的非线性之间,我们使用batch normalization。在decoder中,最大池化被替换为max unpooling,padding被替换为没有bias的spatial convolution。在最后一个upsampling模块中,我们没有使用pooling indices,因为在初始块操作在输入框架的三个通道上,而最终的输出有C个特征图(目标类的数量)。同样,出于性能方面的原因,我们决定只将全卷积作为网络的最后一个模块,进这一个模块就占据了相当大一部分decoder处理时间。
4. Design choices
在这个章节中,我们将讨论我们最重要的实验结果和直觉,它们塑造了ENet的最终框架。
Feature map resolution特征图分辨率:在语义分割的过程中,对图像进行下采用存在两个主要缺陷。首先,降低特征图的分辨率意味着丢失了像精确边缘形状这样的空间信息。其次,全像素分割要求输出和输入有相同的分辨率。这意味着下采样的强度要和上采样一样,这增加了模型的规模和成本。第一个问题已经在FCN中解决了,方法是添加由encoder生成的特征图,在SegNet中通过保存在最大池化层中选择的元素索引,并在decoder中使用它们生成稀疏的上采用图。我们采用了SegNet的方法,因为它允许减少内存的需求。尽管如此,我们发现强烈的下采样会损害准确性,并试图尽可能的限制它。
但是,上采样有一个很大的优点。下采样图像的过滤器会有一个更大的接受域,这允许它们手机更多的上下文context。这在视图区分不同类别时尤其重要,例如,在道路场景中,骑手和行人。仅仅通过网络了解人们的长相是不够的,它们所处的环境也同样重要。最后,我们发现对于这个目的,使用扩展卷积dilated convolutions是更好的[30]。
Early downsampling:实现良好的性能和实时操作的一个关键直觉是认识到处理大量输入帧是非常昂贵的。这听起来可能是显而易见的,然而许多流行的架构并没有对网络的早期阶段进行过多的优化,这往往是迄今为止最昂贵的。
ENet的前两个模块大大减少了输入的大小,并且只使用了以小组特征图。他背后的idea,是视觉信息是高度的控件冗余,因此,可以压缩成一个更有效的表示。此外,我们的直觉是,初始网络层不应该直接有助于分类。相反,它们应该作为良好的特征提取器,只对输入进行预处理,供网络的后续部分使用。这种见解在我们的实验中很有效;将特征图的数量从16增加到32并没有改善在Cityscapes数据集上的准确率。
Decoder size:在这项工作中,我们希望提供一个与[11]所提出的不同观点的encoder-decoder架构、SegNet是一个非常对称的架构,因为编码器是编码器的一个精确的镜像。相反,我们的架构由一个大的编码器和一个小的解码器组成。这是由于编码器应该能够以一种类似于原始分类架构的方式工作,即对较小分辨率数据进行操作,并提供信息处理和过滤。相反,解码器的角色是对编码器的输出进行上采样,只对细节进行微调。
Nonlinear operations:最近的一篇论文报告说,在卷积之前使用ReLU和batch normalization是有益的。我们尝试着将这些理念应用到ENet中,但这却会对准确性产生不利影响。相反,我们发现去掉网络初始层的大部分ReLUs可以改善结果。这是一个非常惊人的发现,所以我们决定调查它的原因。
我们使用PReLUs替换了网络中的所有ReLUs,PReLUs在每个特征图上使用一个额外的参数,目的是学习非线性的负斜率。我们预期,在identity is a transfer function的layer中,PReLU的权重的值接近于1,反之如果ReLU is preferable,权重值在0附近。这些实验的结果可以在图3中看到。
初始化的layers的权重表现出较大的方差,并且稍微偏向于正的值,而在decoder的后面部分,它们设置为一个循环的模式。主分支中的所有layers的行为几乎完全像规则的ReLUs,而bottleneck模块中的权重是负的,即函数倒转并缩小negative values。我们假设identity在我们的架构中不能好好的工作是因为它的深度有限。之所以会学习到这些loss function是因为最初的ResNet网络可以有数百层深度,而我们的网络只使用了几层,它需要快速过滤信息。值得注意的是,decoder的权值变得更加积极,learn functions更接近于identity。这证实了我们的直觉,decoder仅用于微调上采样输出。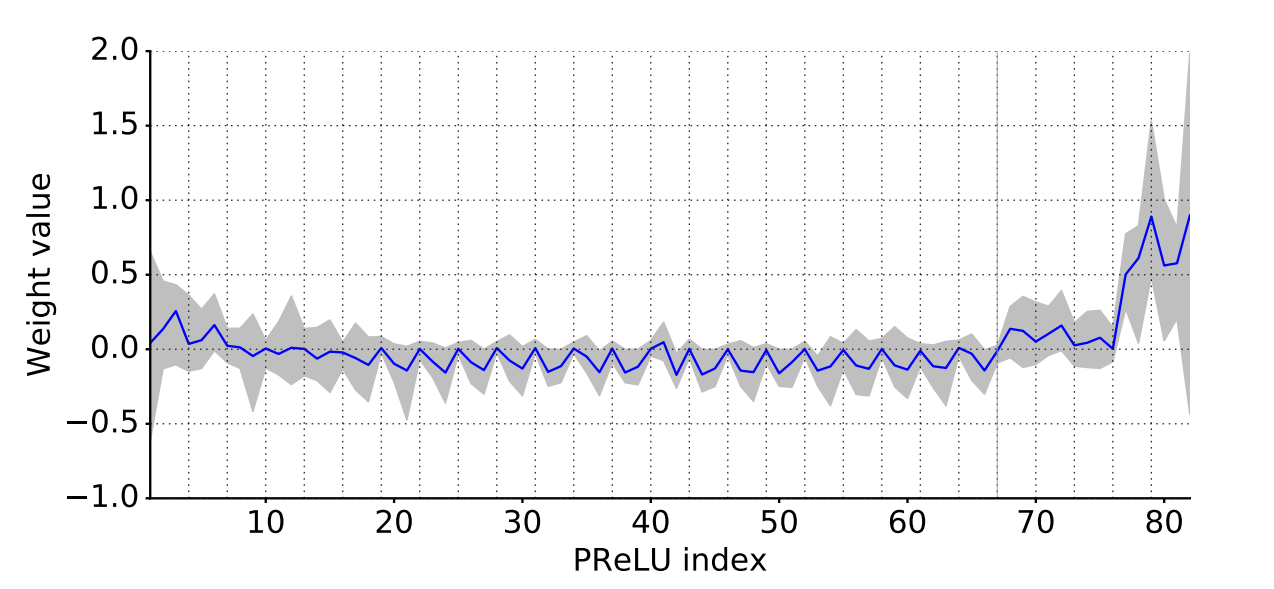
图3:PReLU权重分布vs网络深度。蓝线是权值的平均值,而最大和最小权值之间的区域是灰色的。每一条垂直的虚线都对应于主分支中的一个PReLU,并标志着每个bottleneck之间的边界。第67个模块出的灰色垂直线放置在encoder-decoder边界处。
Information-preserving dimensionality changes信息-保护的维度变化:如前面所述,有必要尽早对输入进行下采样,但积极的维数减少也会阻碍信息流。解决这个问题的一个很好的方法已经在[28]中提出。有人认为,VGG架构使用的一种方法,即执行池化,然后进行卷积扩展维数,尽管这样的操作相对代价较小,却引入了一个表达瓶颈representational bottleneck(或迫使人们使用更多的滤波器,这降低了计算效率)。另一方面,卷积后的池化,增加了特征图的深度,在计算上是昂贵的。因此,正如[28]中提出的那样,我们chose to perform pooling operation in parallel with a convolution of stride 2,并连接产生的特征图。这种技术允许我们将初始块的推断时间加快10倍。
此外,我们在原来的ResNet体系结构中发年了一个问题。在下采样时,卷积分支的第一个11映射在两个维度上都以2的步长执行,这有效地丢弃了75%的输入。将过滤器大小增加到22,可以充分考虑输入,从而提高信息流和准确性。当然,这使得这些层的计算成本增加了4倍,然后在ENet中这样的层太少了,所以开销是不明显的。
Factorizing filters分解过滤器:已经证明,卷积权值有相当多的冗余,每个nn卷积可以被分解为两个互相跟随的较小的卷积:一个1n和滤波器,一个n1的滤波器。这种思想在[28]中也有提出,从现在起我们将采用它们的命名惯例,称之为不对成卷积。我们在网络中使用了n = 5的非对称卷积,所以这两种操作的代价与单个33的卷积类似,这就增加了functions learned by blocks的多样性并增加了接受野。
此外,bottleneck中使用的一系列操作(映射、卷积、映射)可以看做是将一个大的卷积层分解成一系列更小、更简单的操作,即其low-rank近似。这种分解允许大的加速,并极大地减少了参数的数量,使他们不那么冗余。此外由于在层之间插入了非线性操作,它允许使他们计算的functions更加丰富。
Dilated convolutions扩张卷积:如上所述,网络拥有一个广泛的接受域是非常重要的,因此它可以通过考虑更广泛的背景来进行分类。我们想避免过度的下采样特征图,并决定使用扩张卷积来改进我们的模型。它们在最小分辨率的阶段中替换了几个bottleneck模块中的主要卷积层。这些方法在没有额外成本的情况下,将Cityscapes的IoU提高了约4个百分点,从而大大提高了准确性。我们将它们与其他bottleneck模块(规则的和非对称的)交叉放置,而不是像[30]那样将它们按顺序排列,从而获得了最佳的精度。
Regularization正则化:大多数像素级分割数据集都相对较小(约为10^3幅图像),因此想神经网络这样具有表现力的模型很快就开始对它们产生过拟合。在最初的实验中,我们使用L2权重衰减,但收效甚微。然后受[33]的启发,我们尝试了随机深度,这增加了准确性。然而,很明显,删除整个分支(即将其输出设置为0)实际上是spatial dropout的一种特殊情况,即所有通道都被或都不被忽略,而不是选择一个随机子集。我们键spatial dropout放置在卷积分支的末端,就在添加之前,结果证明它比随机深度更好。
5. Results
我们在三个不同的数据集上测试了ENet的性能,以证明其在实际应用中的实时性和准确性。在CamVid和Cityscapes数据集中的road scenes以及SUN数据集的indoor scenes中进行了测试。我们将SegNet作为一个基线,因为它是最快的分割模型之一,它也有比FCN更少的参数和更少的内存来操作。我们所有的模型、training、testing和性能评估都是用了Torch7 machine-learning library,并带有cuDNN后端。为了比较结果,我们使用了类平均精度和intersection-over-union(IoU)度量。
没翻译完
6. Conclusion
我们提出了一种全新的神经网络结构,专门为语义分割而设计。与成熟的深度学习工作站相比,我们的主要目标是有效利用嵌入式平台上的稀缺资源。我们的工作在这一任务中提供了很大的改进,同时匹配甚至有时超过现有的baseline models,这些模型的计算和内存需求要大一个数量级。ENet在NVIDIA TX1硬件上的应用是一个实时便携嵌入式解决方案的范例。
尽管主要目标是移动设备上运行网络,但我们发现它在高端gpu(如NVIDIA Titan x)上也非常高效。这在需要处理大量高分辨率图像的数据中心应用程序中可能会被证明是有用的。ENet允许以一种更快、更有效的方式执行大规模计算,这可能导致显著的节省。
Acknowledge答谢
这项工作得到了海军研究办公室(ONR) N00014-12-1-0167、N00014-15-1-2791和MURI N00014-10-1-0278的部分支持。我们非常感谢NVIDIA公司对TX1, Titan X, K40图形处理器的支持。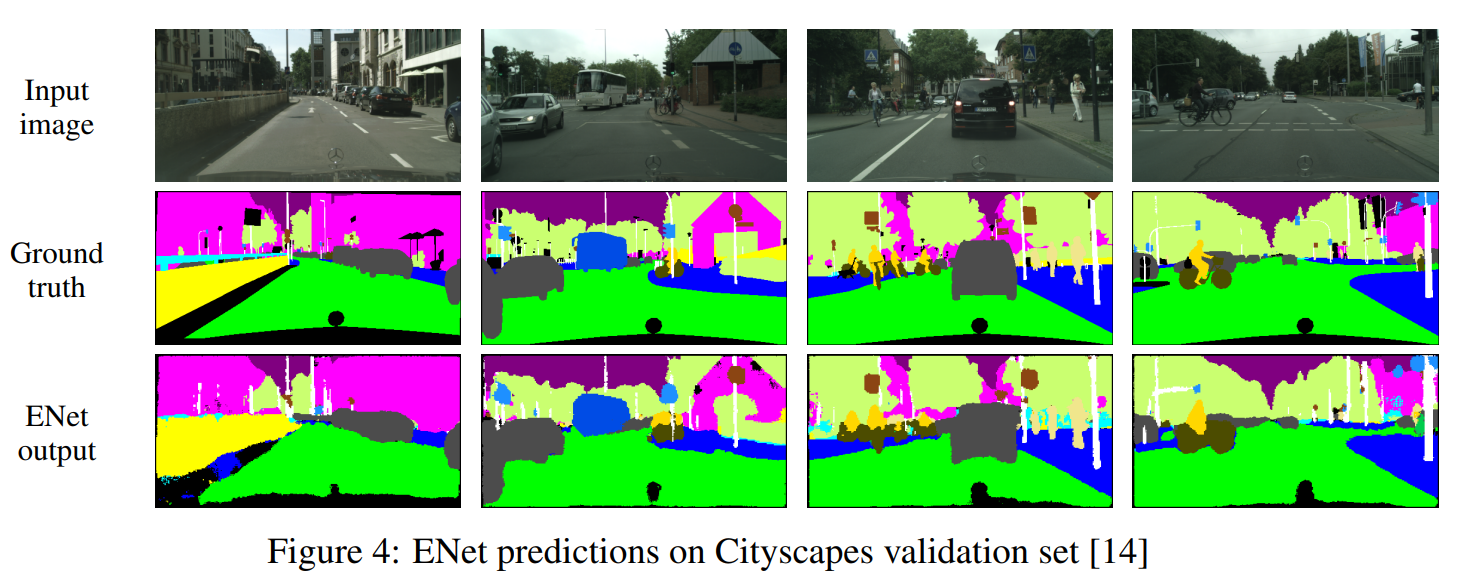

Reference
[1] Y. LeCun and Y. Bengio, “Convolutional networks for images, speech, and time series,” The handbook of brain theory and neural networks, pp. 255–258, 1998.
[2] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in Neural Information Processing Systems 25, 2012, pp. 1097–1105.
[3] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
[4] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 1–9.
[5] J. Shotton, J. Winn, C. Rother, and A. Criminisi, “Textonboost for image understanding: Multi-class object recognition and segmentation by jointly modeling texture, layout, and context,” Int. Journal of Computer Vision (IJCV), January 2009.
[6] F. Perronnin, Y. Liu, J. Sánchez, and H. Poirier, “Large-scale image retrieval with compressed fisher vectors,” in Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on, 2010, pp. 3384–3391.
[7] K. E. A. van de Sande, J. R. R. Uijlings, T. Gevers, and A. W. M. Smeulders, “Segmentation as selective search for object recognition,” in IEEE International Conference on Computer Vision, 2011.
[8] C. Farabet, C. Couprie, L. Najman, and Y. LeCun, “Learning hierarchical features for scene labeling,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 8, pp. 1915–1929, Aug 2013.
[9] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “Semantic image segmentation with deep convolutional nets and fully connected crfs,” arXiv preprint arXiv:1412.7062, 2014.
[10] V. Badrinarayanan, A. Handa, and R. Cipolla, “Segnet: A deep convolutional encoder-decoder architecture for robust semantic pixel-wise labelling,” arXiv preprint arXiv:1505.07293, 2015.
[11] V. Badrinarayanan, A. Kendall, and R. Cipolla, “Segnet: A deep convolutional encoder-decoder architecture for image segmentation,” arXiv preprint arXiv:1511.00561, 2015.
[12] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 3431–3440.
[13] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
[14] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele, “The cityscapes dataset for semantic urban scene understanding,” in Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[15] G. J. Brostow, J. Shotton, J. Fauqueur, and R. Cipolla, “Segmentation and recognition using structure from motion point clouds,” in ECCV (1), 2008, pp. 44–57.
[16] S. Song, S. P. Lichtenberg, and J. Xiao, “Sun rgb-d: A rgb-d scene understanding benchmark suite,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 567–576.
[17] M. A. Ranzato, F. J. Huang, Y.-L. Boureau, and Y. LeCun, “Unsupervised learning of invariant feature hierarchies with applications to object recognition,” in Computer Vision and Pattern Recognition, 2007. CVPR’07. IEEE Conference on, 2007, pp. 1–8.
[18] J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee, and A. Y. Ng, “Multimodal deep learning,” in Proceedings of the 28th international conference on machine learning (ICML-11), 2011, pp. 689–696.
[19] H. Noh, S. Hong, and B. Han, “Learning deconvolution network for semantic segmentation,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 1520–1528.
[20] S. Zheng, S. Jayasumana, B. Romera-Paredes, V. Vineet, Z. Su, D. Du, C. Huang, and P. H. Torr, “Conditional random fields as recurrent neural networks,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 1529–1537.
[21] D. Eigen and R. Fergus, “Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 2650–2658.
[22] S. Hong, H. Noh, and B. Han, “Decoupled deep neural network for semi-supervised semantic segmentation,” in Advances in Neural Information Processing Systems, 2015, pp. 1495–1503.
[23] P. Sturgess, K. Alahari, L. Ladicky, and P. H. Torr, “Combining appearance and structure from motion features for road scene understanding,” in BMVC 2012-23rd British Machine Vision Conference, 2009.
[24] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” arXiv preprint arXiv:1512.03385, 2015.
[25] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” arXiv preprint arXiv:1502.03167, 2015.
[26] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification,” pp. 1026–1034, 2015.
[27] J. Tompson, R. Goroshin, A. Jain, Y. LeCun, and C. Bregler, “Efficient object localization using convolutional networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 648–656.
[28] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” arXiv preprint arXiv:1512.00567, 2015.
[29] S. Chetlur, C. Woolley, P. Vandermersch, J. Cohen, J. Tran, B. Catanzaro, and E. Shelhamer, “cudnn: Efficient primitives for deep learning,” arXiv preprint arXiv:1410.0759, 2014.
[30] F. Yu and V. Koltun, “Multi-scale context aggregation by dilated convolutions,” arXiv preprint arXiv:1511.07122, 2015.
[31] K. He, X. Zhang, S. Ren, and J. Sun, “Identity mappings in deep residual networks,” arXiv preprint arXiv:1603.05027, 2016.
[32] J. Jin, A. Dundar, and E. Culurciello, “Flattened convolutional neural networks for feedforward acceleration,” arXiv preprint arXiv:1412.5474, 2014.
[33] G. Huang, Y. Sun, Z. Liu, D. Sedra, and K. Weinberger, “Deep networks with stochastic depth,” arXiv preprint arXiv:1603.09382, 2016.
[34] S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding,” arXiv preprint arXiv:1510.00149, 2015.
[35] D. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.

若有收获,就点个赞吧
0 人点赞
