作者:Petr Hurtik
学校:University of Ostrava,英国奥斯特拉法大学,2020QS世界排名801-1000名
abstract
本文提出了一种新版本或者说扩展版的yolo,命名为Poly-YOLO,相比于YOLOV3,poly-yolo有三个改进点:
- 可训练参数更少(60%)、平均精度更高(提高40%)
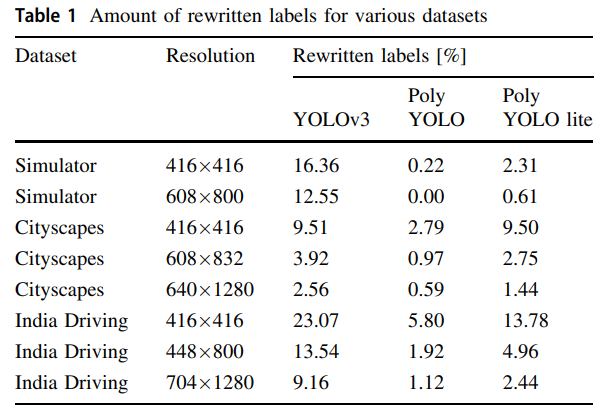
- 消除了YOLOv3大量重写标签和anchor分配不均匀问题
- poly-yolo,多顶点的目标检测,实现了实例分割。在grid cell的基础上增加 circular sector cell,每个cell负责预测一个顶点,再把每个顶点连接起来,实现多边形检测,也是一定意义上的分割了。
Motivation
作者引用了YOLOv3作者的一句话:”Boxes are stupid anyway though, I’ m probably a true believer in masks except I can’t get YOLO to learn them.”,这句话的意思是用box框来表示目标检测结果有点蠢,我觉得mask是更好地选择但是我没法让YOLO学会它。的确,用box框表示检测的方法的缺点是对于形状复杂的物体,边界框还包括背景,由于边界框没有紧紧包裹物体,背景会占据很大一部分区域。这种行为会降低应用在边界框上的分类器的性能,或者可能无法满足精确检测的要求。
恰好这句话也是作者的其中一个motivation。作者在改善YOLOv3的同时,也想办法扩展YOLOv3使得YOLO也可以进行实例分割。
作者的最终目标是创建一个具有实例分割和中等级别显卡也能实时处理的detector
Methods
标签重写问题
这个是YOLOv3遗留的一个问题,YOLO的特点是grid cell负责预测bbox,这样就很有可能预测出来的两个物体的bbox框中心点位于同一个grid cell中,并且分配给同一个anchor(这个是网上的描述,我的理解是一个anchor输出一个bbox框,没法输出两个,所以当两个相近尺寸的物体,中心点在同一个grid cell,理应让同一个anchor负责,但一个anchor框只能负责一个,这就是标签重写),导致只有一个物体被参与训练,阳性训练样本大大减少。当输入分辨率越小、物体越密集、物体的长宽越接近时,标签重写的问题就越严重。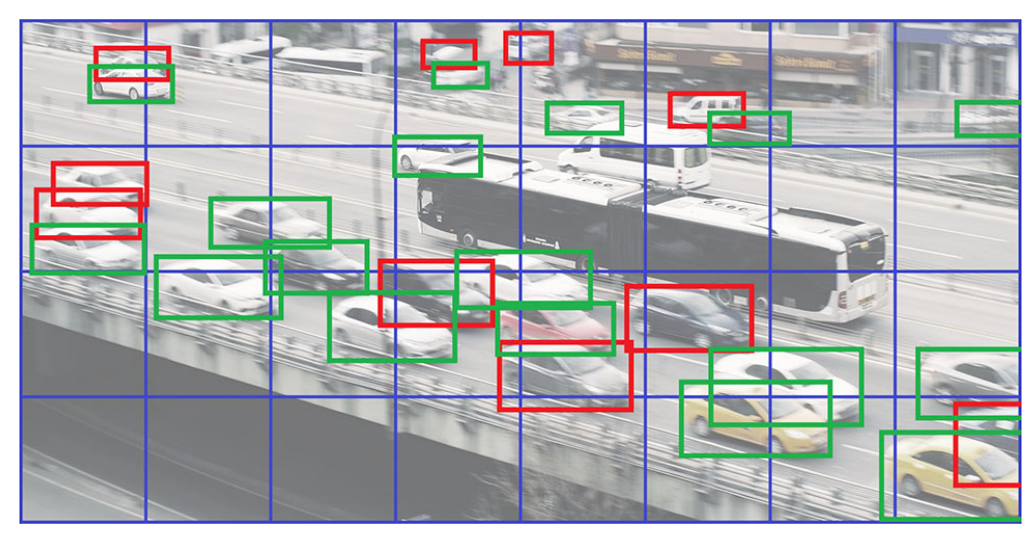
上图是作者给出的标签重写案例,27个框里就有10个被重写。
这种现象在coco数据上是不明显的,因为像coco这种大型数据集,数据类型丰富、bbox分布比较均匀,不同大小的物体(由于YOLOV3的特性)会被分配到不同尺度下的特征层,标签重写的概率是比较低的。然而在很多实际引用场景中,比如电子元器件检测,物体往往排布紧密,且大小几乎一致,这样就极可能出现两个尺度相近的物体的中心落在同一个grid cell中,导致标签重写。
但是这个问题对于虹膜检测是友好的。在虹膜检测、人眼检测中,这种问题不太可能会出现,瞳间距基本不会小到使得两只眼睛的中心点落在同一个grid cell中,而两个人一前一后使得两只眼睛在透视意义上位于同一个grid cell也不在虹膜检测的应用场景中。
anchor分配不均匀
YOLO系列中的anchor是通过kmeans算法聚类得到的,比如YOLOv3就是9个anchor,3个为一组,分别分配到不同尺度下的特征图中。小的特征图负责检测大的物体,大特征图负责小的物体。不同大小的物体会被这三组anchor分配到不同尺度的特征层中进行预测。
但是这种kmeans算法得到的结果是有问题的,比如前面说到的,并不是所有应用场景都跟coco数据集一样丰富,什么尺度的框都有,大多数是特定场景下的目标检测,比如元器件检测,框的尺度单一。假如在这种情况下使用kmeans聚类生成anchor并且参与到训练当中,就很有可能尺寸差不多的物体被强行分到不同尺度下的特征图下进行预测,这其实挺不合理的,FPN的目的就是解决多尺度目标检测问题,而现在是通尺度情况下使用FPN,有点本末倒置的意思。
作者还提出,即使在coco数据集中,使用kmeans算法也会导致一个问题,就是大多数情况下,图片中物体的尺度属于中等尺度,中等尺度就会被分配到中层特征图中进行预测,导致YOLOv3另外两个预测分支没有被很好的训练到,浪费网络(收敛缓慢)
poly-yolo的解决办法
对于标签重写问题,有两种解决方案:(The first issue can be suppressed by high values of sk,i.e., a scale multiplicator that expresses the ratio of the output resolution with respect to the input resolutionr.)
- 增加输入图片的分辨率大小(我的理解是,简单的缩放图片分辨率并不能缓解两个物体中心落在一个grid cell中的问题,应该是通过减少一个grid cell中所包含的内容而非分辨率意义上的减小,使得中心落在一起的概率降低,而一般应用场景下的改变输入大小是通过resize)
- 增加输出特征图大小(即减小grid cell的大小,grid cell所包含的内容减少,grid cell数量增多)
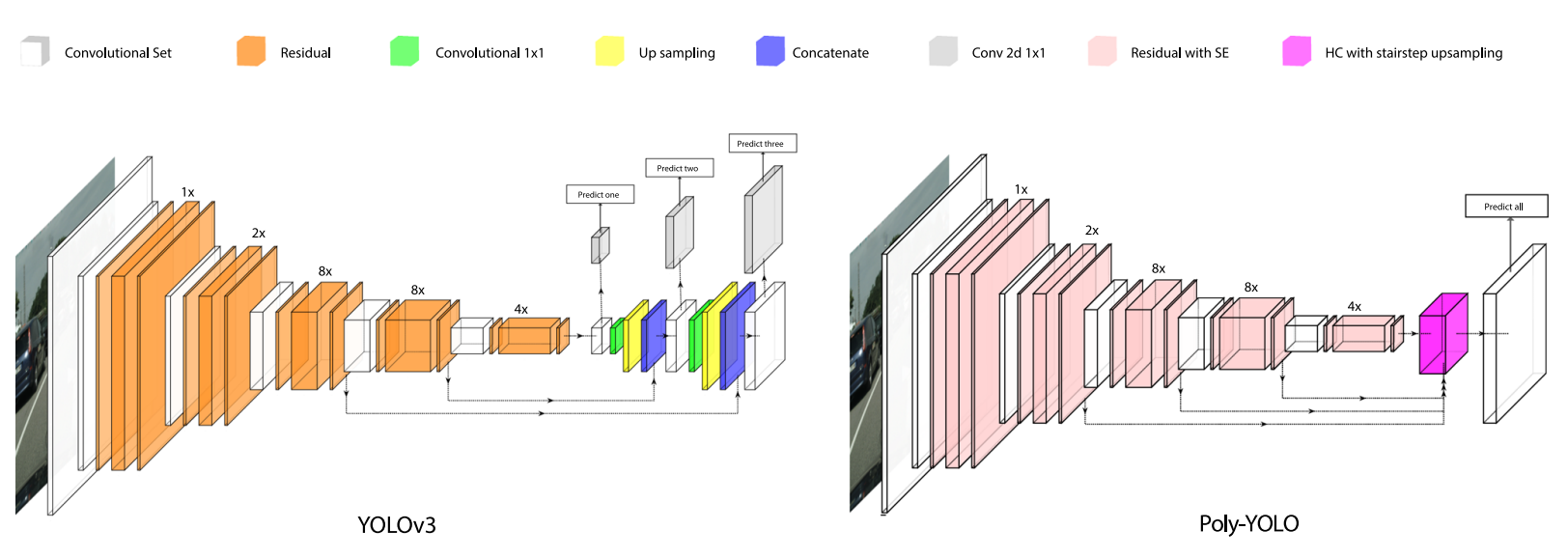
对于anchor分配不均匀问题,解决方案是对多个尺度特征图进行特征融合,只输出一个尺度的特征图进行检测。简单理解就是YOLOV3中是3个尺度,每个尺度3个anchor,那么对应到本文就是1个尺度,9个anchor。
为了同时解决两个问题,作者将模型输出3个特征图变为输出1个,并且增大特征图的分辨率。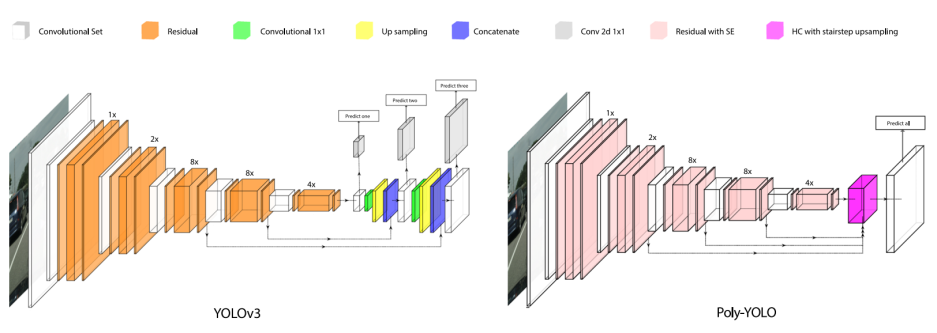
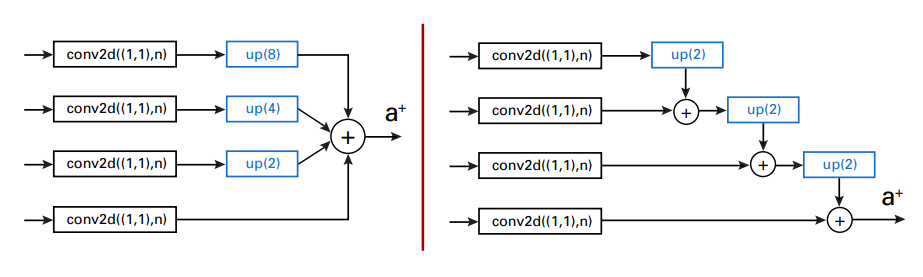
这篇论文最早是2020年发出来的,而在SOLOv2当中,也运用到了和这里一样的解决办法: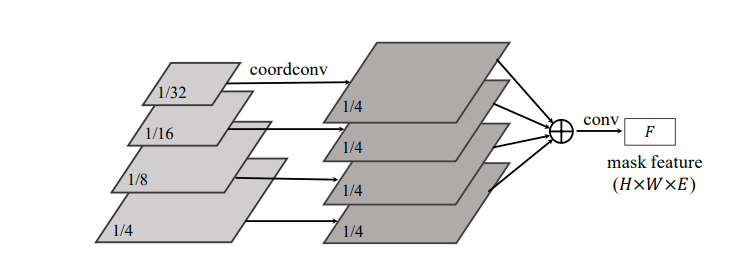
通常有两种办法输出mask feature:
- 对FPN每个level分别进⾏处理,输出mask
- 把FPN每个level进⾏合并,然后再处理、输出mask 本⽂采⽤的是后者。
⽂中提出,第⼀种⽅法的缺点很明显,对于中⼤型物体的分割会⽐较差。因为,⼤ 的物体通过high level 的、low spatial resolution的FPN feature map来获得,⾃然会得到粗略的边界 预测。 SOLOv2采用第二种办法,将FPN的不同尺度的特征图进行特征融合输出mask feature F,
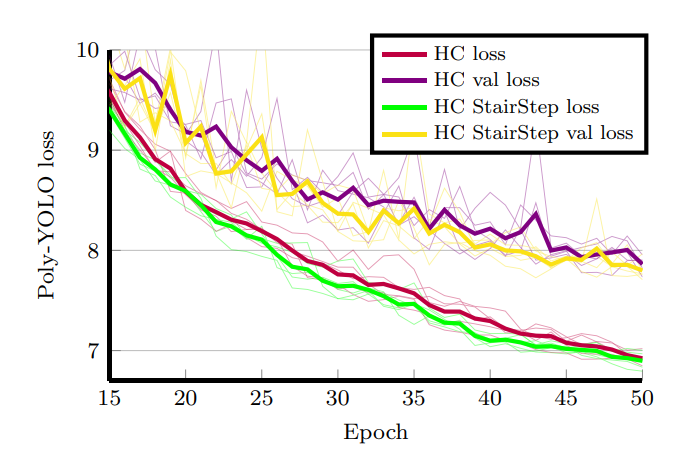
本文中作者改进了特征融合的办法,使用逐层上采样融合的方法,使得训练时的loss值更低。

若有收获,就点个赞吧
0 人点赞
