1 College of Computer Science and Engineering, Key Laboratory of Intelligent Computing in Medical Image, Northeastern University,Shenyang, China 2 Amii, University of Alberta, Edmonton, Canada haonan1wang@gmail.com, caopeng@mail.neu.edu.com, wjq010222@gmail.com, zaiane@cs.ualberta.ca
东北大学,阿尔伯特大学,世界排名120
Abstract
论文重新思考了skip connection的作用,提出了并不是所有skip connection都会对结果有帮助,并且不同数据集呈现不同的结果。提出了CCT, CCA两个channel-wise transformer模块,加入到U-Net当中,效果SOTA。其中CCT融合了encoder中multi-scale的skip connection信息。CCA是channel-wise cross-attention,对应unet中的concat+upsample。
Motivation
大多数的语义分割方法才用了具有encoder-decoder结构的unet。对于有skip connection策略的unet来说依旧很难模拟全局的multi-scale上下文。
并且我们发现并不是所有skip connection都对结果有用,有些甚至有副作用。不同数据集对skip connection呈现不同的效果。
作者发现,不考虑semantic gap,简单的用skip connection来帮助decoding process不能够很好地模拟全局的multi-scale context。
在过去的工作中,如unet++,用dense skip connection来narrows the semantic gap between encdoer and decoder。还有其他的工作尝试用non-linear transformations来加强skip connection的feature propagation from encoder to decoder。
尽管他们都达到了不错的效果,但是他们都没有有效的开发full scales的信息。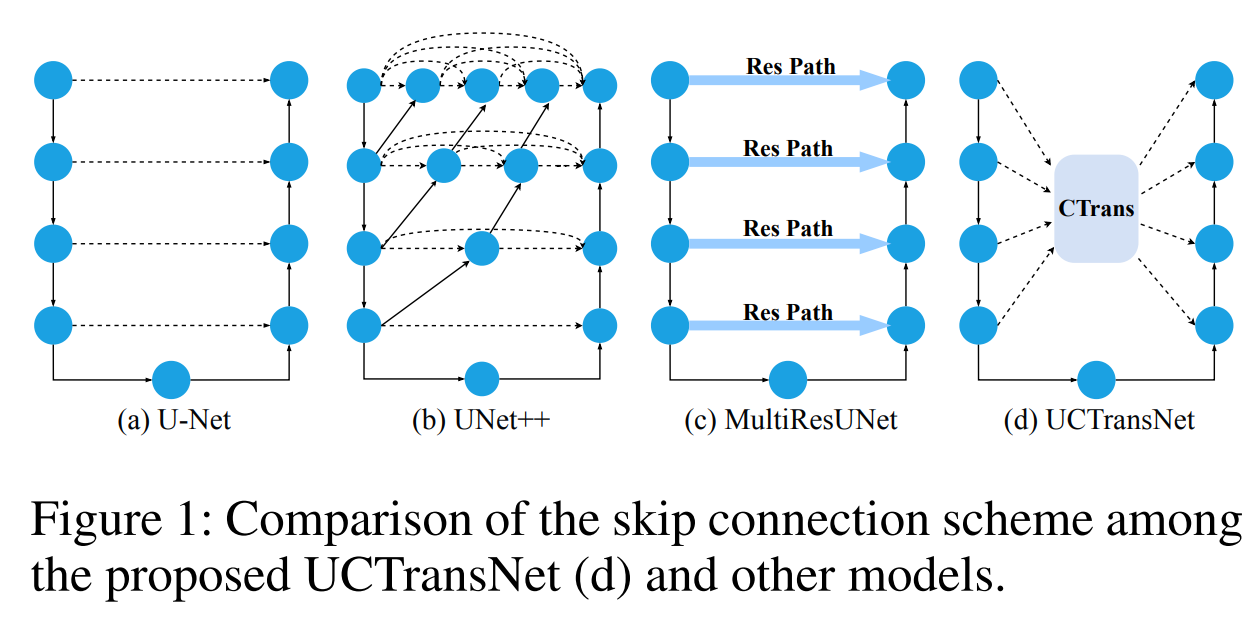
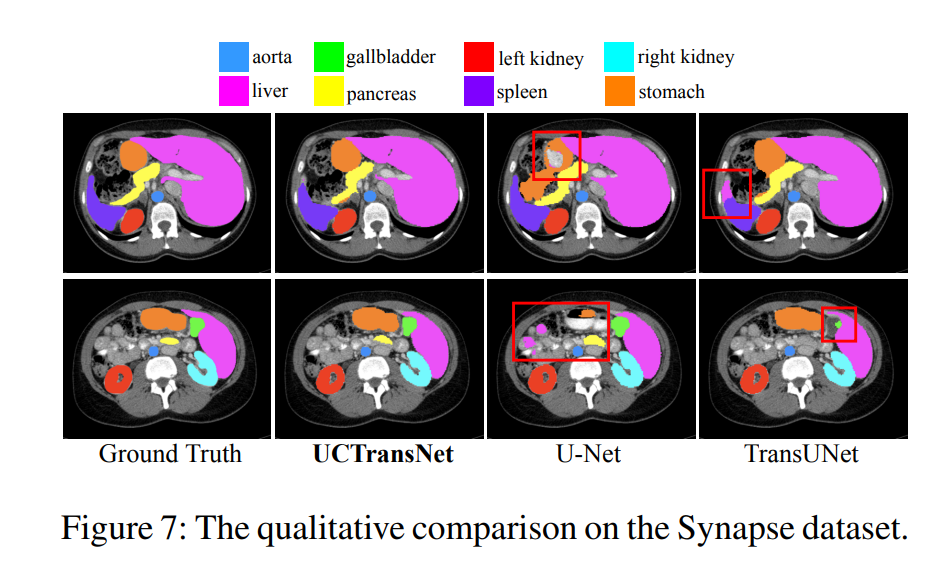
这张图很好的说明了UCTranNet解决的问题。就是融合full scale的skip connection信息。
如果有效的减小encoder和decoder之间的semantic gap变得至关重要。而本文通过有效的捕捉non-local semantic dependencies,并对其进行fusion来生成multi-scale channel-wise information。其实就是CCT模块。
Methods
UCTranNet包括了以下几个模块:
- unet,encoder-decoder结构
- CCT
- CCA
CCT - channel-wise Cross Fusion Transformer for encoder feature transformation
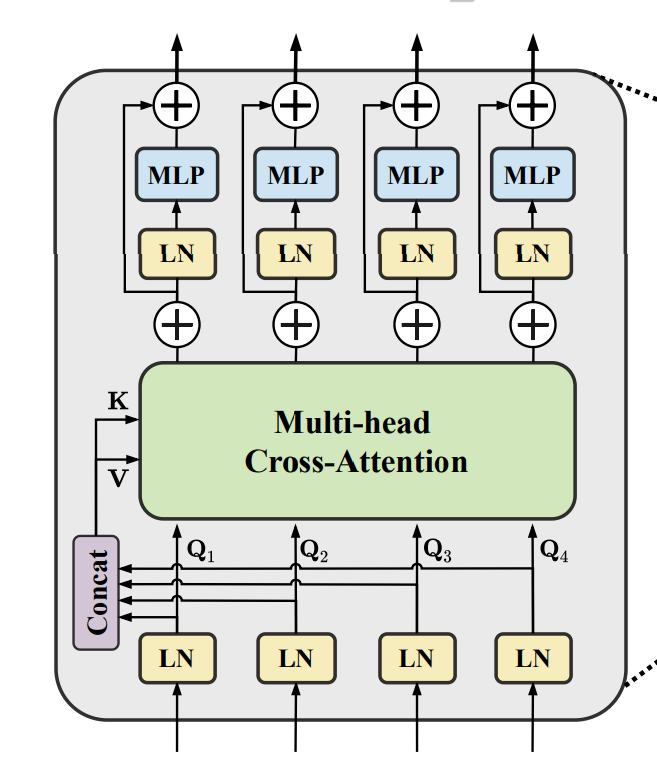
在了解self-attention之后,就很好理解CCT的结构。
下面四个LN之前是d1,d2,d3,d4的skip connection。他们分别会通过patch_embedding生成queries。q1,q2,q3,q4
而Key和Value是将它们patch_embedding后生成的ki和vi进行concat得到的一个具有四个skip connection信息的KEY和VALUE。接着用每个qi和整体的KEY和VALUE进行自注意力的计算,即可得到具有multi-scale information的skip connection。
上面是通俗表达的CCT,下面用公式讲解一下过程:
 表示4个skip connection经过patch_embedding之后生成的4个patch,
表示4个skip connection经过patch_embedding之后生成的4个patch, 表示经过patch_embedding生成的四个
表示经过patch_embedding生成的四个
太麻烦了看原文。
CCA - channel-wise Cross attention for feature fusion in decoder
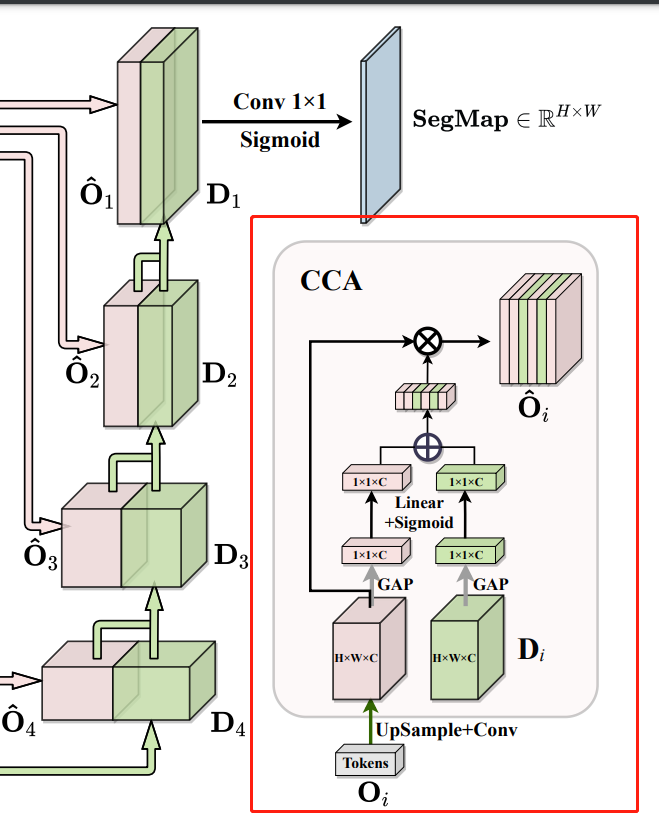
其实就是将具有full-scale的skip connection和decoder中的特征图进行channel-wise cross-attention,然后再进行decoder中的concat和upsample。
Contributions
基于作者的发现,提出了一个新的segmentation framework,命名为UCTransNet,一个带有CTrans module的UNet,用一种channel perspective的attention mechanism。
提出了CCT和CCA。
CCT可以作为一种strong skip connection scheme for medical segmentation。
我个人总结就是,作者提出了一种novel的想法,就是skip connection的rethinking,然后CCT融合full-scale information。
Experiments
rethinking of skip connection
我个人最感兴趣的就是这个,skip connection到底对分割结果会产生什么影响,作者做了丰富的对比实验: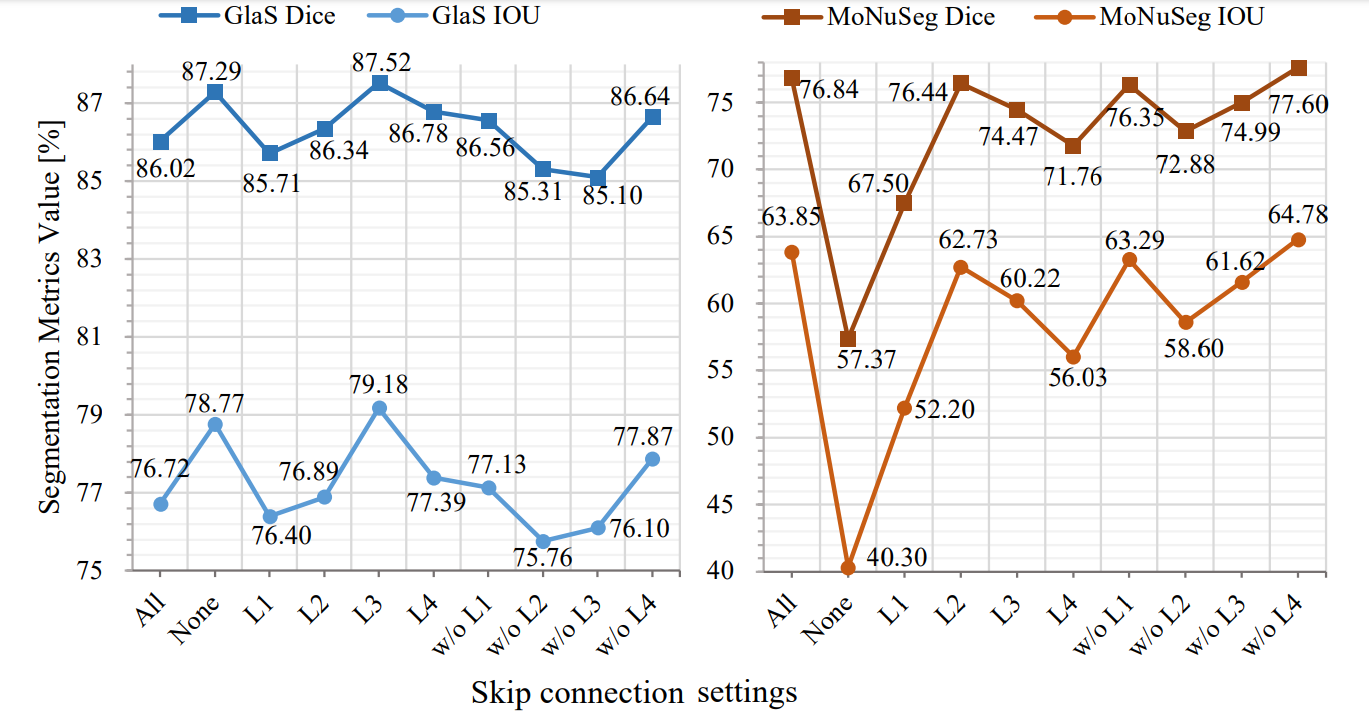
这张图很好地说明了问题。all代表左右连接都有,none表示都没有,L1表示只有这一个连接,w/oL1表示只有这个没有。
结果就是:
- 每个connection对结果的影响不同,不是所有的skip connection都有用,甚至可能是副作用
- 不同数据集对于connection的响应不同。
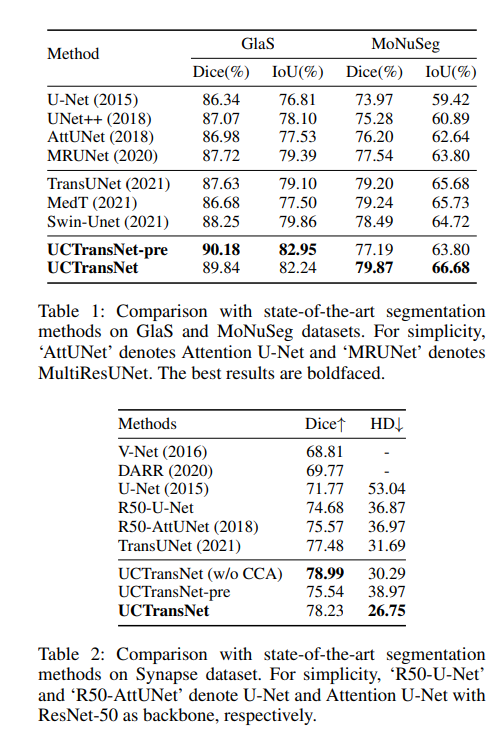
Comparison with sota methods
作者对比了UCTransNet和其他unet-based网络和sota网络,不仅在实验指标上,还在结果可视化图上。
ablation of proposed module
作者对提出的模块进行ablation,以此验证模块的作用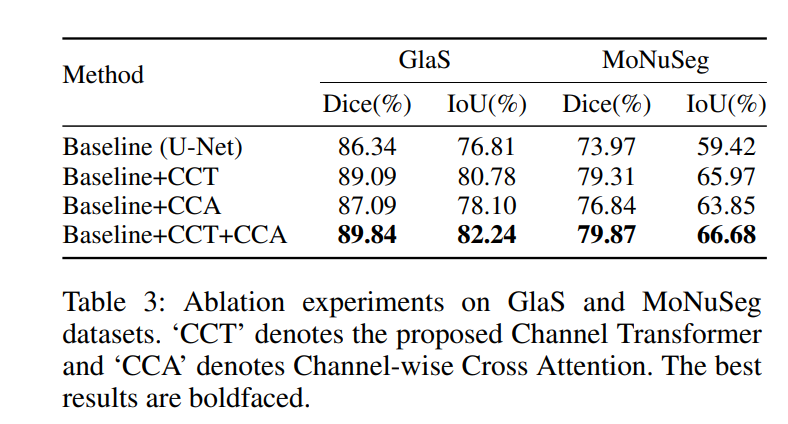
ablation of number of queries and keys
作者做了和skip connection类似的实验,将q或k的数量固定,变化另一个变量,做的对比实验,验证不同数量的queries和keys对结果的影响。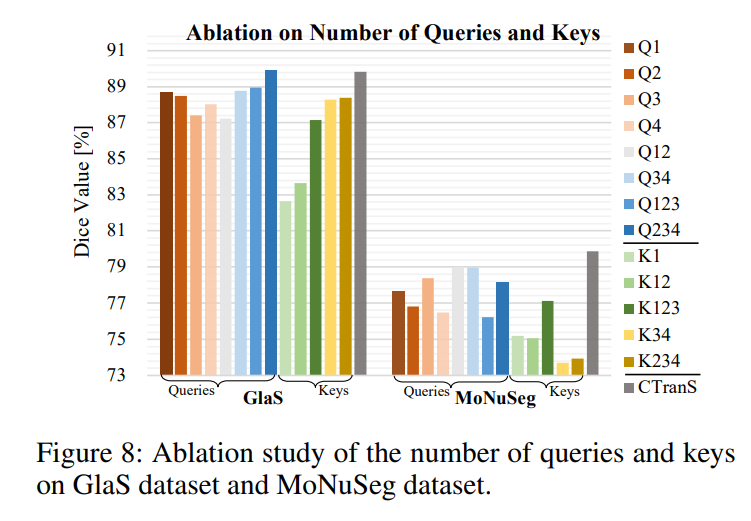
结果:数量越多越好,毕竟它融合了多个scale的信息。缺少哪一部分都是不好的。
Future work
个人理解,self-attention的过程的意义在于:
在考虑自身的同时,考虑其他tokens对于自身的影响。
那么CCT要表达的意思就是融合full-scale的information。但是本质上和作者做的skip connection的实验的目的是错开的。skip connection的目的是说明connection对结果的作用有多大。
CCT解决的是multi-scale information fusion,
对于skip connection的解决方案,正确的思路应该是这样的:
- 假如某个connection的效果不好,那就削弱它的feature propagation from encoder to decoder。但是CCT做不到这点。
- 如果某个connection对结果影响最大,那么就加强它的特征传递。CCT同样做不到,还可能会因为self-attention削弱了自身对结果的影响
那么能做到加强或削弱skip connection特征传递的方式,直观上有两种方法:
- 注意力机制,让网络学这个connection应该关注的点在哪里,相应部分的权重值就提高了,实现增强特征传递。
- 直观上来讲,concat后的特征图,如果connection占比越小,它对输出的影响就越小。那么就可以有以下做法,来增强或削弱特征传递:
- 对虹膜数据集,对不同的skip connection,改变他们的skip到decoder的通道数,看对结果的影响
- 这样就可以得到不同skip connection,不同通道数对结果的影响。

若有收获,就点个赞吧
0 人点赞
