e在神经网络中模型中加入偏置(bias),偏置可以让我们搭建的神经网络模型偏离原点,而没有偏置的函数必定会经过原点
任学长:y = ax + b,b就是那个偏置
带偏置的模型的好处是能够使模型具有更强的变化能力,在面对不同的数据时拥有更好的泛化能力。
如果不引入激活函数,则无论我们对网络模型加深多少层,结果都是一个线性模型,在应对非线性问题时会存在很大的局限性。激活函数的引入给我们搭建的模型带来了非线性因素
引入激活函数是为了增加神经网络模型的非线性,没有激活函数的每层都相当于矩阵相乘,就算你叠加了若干层,无非还是矩阵相乘罢了。
如果不用激活函数,每一层输出都是上层输入的现行函数,无论神经网络有多少层,输出都是输入的线性组合,这种情况就是最原始的感知机(perceptron)
Sigmoid

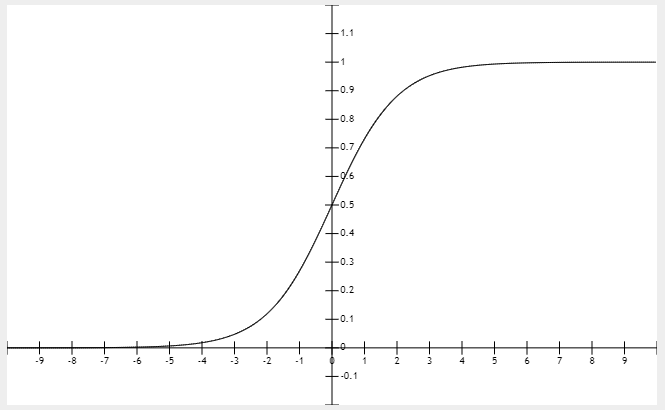
sigmoid容易使得梯度消失。sigmoid的导数值的区间为0~0.25,每经过一层,所及即便每次乘上sigmoid的导数值的最大值0.25,也相当于在后向传播的过程中每逆向经过一个节点,梯度值的大小就会变成原来的四分之一,如果模型层次达到了一定深度,那么后向传播会导致梯度越来越小,直到梯度消失
输出值恒大于0,。
尽量使用零中心数据(zero-centered),而且尽量保证输出结果是零中心数据。
导致梯度饱和,也叫做梯度弥散
tanh

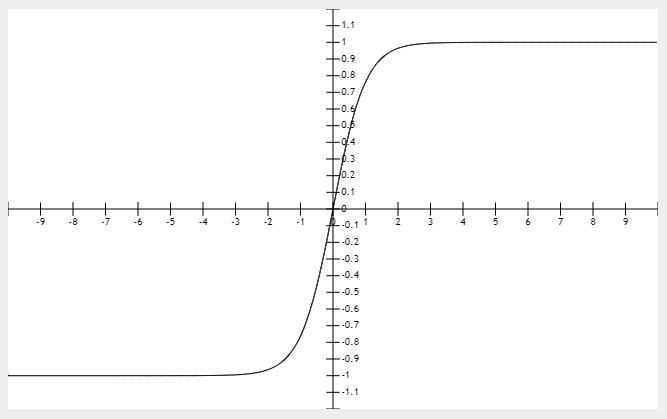
导数取值区间0~1,任然容易导致梯度消失
ReLU

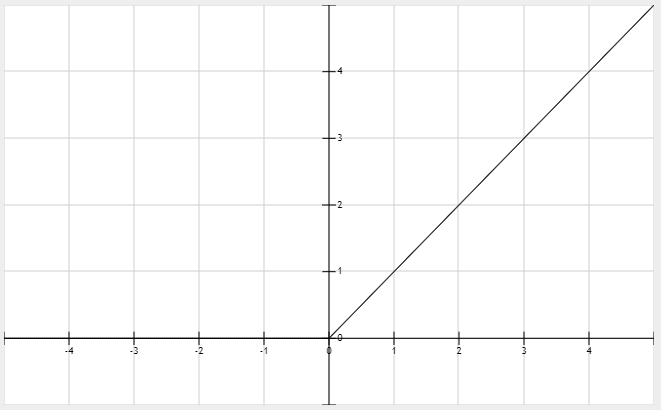
relu的输出并不是零中心数据,这可能会导致某些神经元永远不会被激活,并且这些神经元相对应的参数不能被更新。这一版是由于模型参数在初始化的时候使用了全正或全负的值,或者在后向传播过程中设置的学习速率太快导致的,其解决方法是对模型参数使用更高级的初始化方法比如Xavier,以及设置合理的后向传播学习速率,推荐使用自适应的算法如Adam
relu尽管拥有上述问题,但仍是主流的激活函数,他也在不断被改进,比如Leaky-ReLU, R-ReLU
ELU函数
PReLU

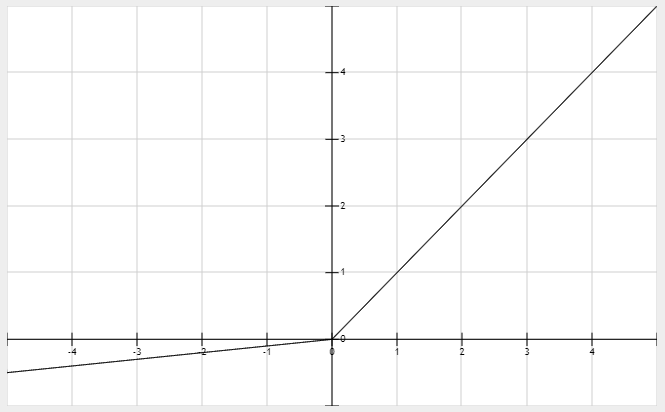
当α=0.01时,PReLU又叫LeakyReLU
总体来看,这些激活函数都有自己的有点和缺点,所有的好坏都要自己在实验中得到

若有收获,就点个赞吧
0 人点赞
