- 泛化能力
- 感知机(perceptron)
- bias偏置
- SWOT
- TIOBE
- 显存占用(需继续研究)
- CS231N
- OCR推荐算法
- NLP
- UVC
- star原则
- 数据集
- 卷积层进行点乘求和操作
- 异质虹膜
- encoder-decoder模型(继续研究)
- 数据增强
- SOTA
- 语义分割、实例分割和全景分割
- 计算量(需继续研究)
- backbone
- FCN
- 空洞卷积(dilated convolution)
- 残差网络(residual network, ResNet)
- 深度可分离卷积(depthwise separable convolution,DW)
- 二分类交叉熵
- 下采样(subsample)和上采样(upsampling)(不懂)
- 召回率recall、正确率precision
- softmax函数
- 学习率:
- 目标检测性能评价指标(mAP, IoU, NMS,速度)
- batch批训练
- epoch
- iterations
- FLOPS FLOPs
- 边框回归(bounding-box regression)
- 梯度直方图
- 支持向量机
- 置信度
- R-CNN
- 锚点框(anchor)
- k-means —— 聚类算法
- 超参数和参数
- normalization归一化(重点,继续研究)
- DNN RNN LSTM
- 卷积,为什么是卷积?卷积核为什么是奇数?
- Top-1错误率和Top-5错误率
- 多级网络不适合NPU加速
- MLP多层感知机
- 赫布原则Hebbin Principle
- ROI
- pipeline
- checkpoint
泛化能力
generalization ability,是指机器学习算法对新鲜样本的适应能力。学习的目的是学到隐含在数据背后的规律,对具有同一规律的训练集以外的数据,经过训练的网络也能给出合适的输出,该能力称为泛化能力。
提高泛化能力:1、增加数据量。2、正则化。3、凸优化。
感知机(perceptron)
https://www.cnblogs.com/xym4869/p/11282469.html
https://blog.csdn.net/weixin_42137700/article/details/89397720
感知机由科学家frank rosenblatt发明于1950年-1960年。感知机即神经网络里的神经元
感知机有如下组成部分:
输入权值,w
激活函数
输出y = f(w*x + bias)
bias偏置
https://zhuanlan.zhihu.com/p/29633019
bias偏置或阈值的大小,度量了神经元产生正(负)激励的难易程度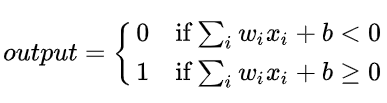
w*x + b,w是权重值,b就是偏置bias
需要注意的是,bias是不需要正则化的,并且正则化偏置的话会导致欠拟合。
SWOT
s(strengths)是优势,w是weakness劣势,o是opportunity机会,t是threats威胁
是一种分析问题的方法,常用语企业
TIOBE
编程语言排行榜
显存占用(需继续研究)
https://oldpan.me/archives/how-to-calculate-gpu-memory
https://blog.csdn.net/qian99/article/details/79008053计算参数
占用显存的地方:
- 模型自身的参数(params,卷积层(核)和其他有参数的层(全连接))
占用的:① 卷积层 ② 全连接层linear ③ batchnorm层 ④ embedding层
不占用:激活层relu等,池化层,dropout层
y = wx + b,这个 w是个矩阵,就是卷积核
- 模型计算产生的中间值(memory,也就是输入图像在计算每一层产生的输入和输出)想想左边一侧有一列图片(为什么要保存每一个输出图片的数据)
- backward的时候产生的额外中间参数
- 优化器在优化时产生的额外模型参数
CS231N
斯坦福CS231N,这是一门每学期的视频更新都会引起一波尖叫的明星课。
这门课由AI圈领军人李飞飞老师亲自设计教学,专注深度学习在计算机视觉领域的应用。
网上有视频资源以及笔记。
OCR推荐算法
OCR(optical character recognition,光学字符识别)
一般的OCR包含两步:1、detection,找到文字的区域。2、classification,识别区域中的文字
NLP
natural language processing自然语言处理。
UVC
UVC全称为USB video class,USB视频类,是一种为USB视频捕获设备定义的协议标准。
现在主流操作系统都提供UVC设备驱动,因此符合UVC规格的硬件设备在不需要安装任何的驱动程序下即可在主机中正常使用。使用UVC技术的包括摄像头,数码相机,类比影像转换器,电视棒等。
star原则
star原则,即situation(情景)、task(任务)、action(行动)、result(结果)。star是结构化面试当中非常重要的一个理论。
situation:背景,面谈中要求应聘者描述他所从事岗位期间曾经做过的某将重要的且可以当做我们考评标准的时间的所发生的的情况。
task:任务,即考察应聘者这在其背景环境中所执行的任务与角色。
action:行动,考察应聘者在其所描述的任务中担任的角色是如何操作与执行任务的。
result:结果,即该项任务在行动后所达到的效果,通常应聘者求职材料商写的都是一些结果。
数据集
https://blog.csdn.net/m0_37570854/article/details/88734695#%E4%B8%83%E3%80%81%E9%9D%A2%E9%83%A8%E5%92%8C%E7%9C%BC%E7%9D%9B%2F%E8%99%B9%E8%86%9C%E6%95%B0%E6%8D%AE%E5%BA%93
coco数据集、imagenet
ms coco全称Microsoft common objects in context,与imagenet一样,被视为计算机视觉领域最受关注和最权威的比赛之一。
coco数据集是一个大型的、丰富的物体检测、分割和字幕数据集。
UBIRIS数据集(可见光)
卷积层进行点乘求和操作
就是对应位置的权重与像素进行乘积求和
异质虹膜
可见光和红外光图像
encoder-decoder模型(继续研究)
所谓encoder-decoder,又叫做编码-解码模型。是一种应用于seq2seq问题的模型。
seq2seq又是什么呢,简单地说就是根据一个输入序列x,来生成另一个输出序列y。seq2seq有很多的应用,例如翻译,文档摘取,问答系统等。
decoder的作用是将encoder提取到的特征信息转换为语义信息。
数据增强
data augmentation。一张图像,只要有一些变化,模型都会认为他们是不同的图片。比如网球的飞行过程,即使网球永远是同一面对着你,但是发生了移位transaction
常见的方法有:翻转(flip)、旋转(rotation)、缩放比例(scale)、裁剪(crop)、移位(translation)、高斯噪声。还有其他高级增强技术
https://zhuanlan.zhihu.com/p/41679153
SOTA
state of the art,若某篇论文能够被称为sota,就表明其提出的算法(模型)的性能是当前最优的
语义分割、实例分割和全景分割
https://blog.csdn.net/qq_29893385/article/details/90213699
1、semantic segmentation语义分割,将一张图片上的所有像素点进行分类,但是同一物体的不同实例不需要单独分割出来。
2、instance segmentation,实例分割,是目标检测和语义分割的结合。相对目标检测的边界框,实例分割可以精确到物体的边缘;相对语义分割,实例分割需要标注出图中同一物体的不同个体(people1,people2…)
3、panoramic segmentation,全景分割,全景分割是语义分割和实例分割的结合。全景分割是对图中的所有物体包括背景都要进行检测和分割。
计算量(需继续研究)
计算机做乘加次数
backbone
backbone这个单词指的是脊梁骨,后来引申为支柱、核心的意思。
在神经网络中,尤其是CV,一般先对图像进行特征提取,这个部分是CV任务的根基,然后才有根据图像特征去分类、生成等等。
所以将这一部分网络结果成为backbone。
FCN
fully convolutional networks for semantic segmentation,全卷积,fcn是深度学习应用在图像分割的代表作,是一种端到端(end to end)的图像分割方法,让网络做像素级别的预测直接得出label map。因为FCN网络中所有的层都是卷积层,故称为全卷积网络。
https://blog.csdn.net/bestrivern/article/details/89523329
空洞卷积(dilated convolution)
https://www.zhihu.com/question/54149221
dilated convolution空洞卷积、膨胀卷积,或者是convolution with holes,从字面上很好理解,是在标准的convolution map里注入空洞,以此来增加reception filed。相比普通的convolution,多出了hyper-parameter(超参数)称之为dilation rate指的是kernel的间隔数量(普通的convolution是dilatation rate 1)
77的卷积层的正则等效于三个33的卷积层的叠加,这样设计可以大幅减少参数。
残差网络(residual network, ResNet)
残差网络是为了解决深度神经网络(DNN)隐藏层过多时的网络退化问题而提出。退化(degradation)问题是指:当网络隐藏层变多时,网络的准确度达到饱和然后急剧退化,而且这个退化不是由于过拟合引起的。
F(x) = H(x) - x
DRN(深度残差网络)
深度可分离卷积(depthwise separable convolution,DW)
depthwise(DW)卷积和pointwise(PW)卷积(11inputchannel的卷积核,),合起来被称作深度可分离卷积,可用来提取特征,但相较于常规卷积操作,其参数量和运算量成本较低。所以经常用于轻量级网络如mobilenet。
二分类交叉熵
是一个损失函数,定义为:
p是模型预测样本是正样本的概率,y是样本标签,如果样本属于正样本,取值为1,否则为0
下采样(subsample)和上采样(upsampling)(不懂)
缩小图像(或称为下采样subsample或降采样(downsample))的主要目的有两个:① 是的图像符合显示区域的大小;② 生成对应图像的缩略图。可以理解为就是池化层(能在一定程度上控制过拟合)。
放大图像(或称为上采样(upsampling)或图像插值(interpolating))的主要目的是放大原图像,从而可以显示在更高分辨率的显示设备上。
过采样又称上采样:重复正比例数据,实际上没有为模型引入更多数据,过分强调正比例数据,会放大正比例噪音对模型的影响。
欠采样:丢弃大量数据,和过采样一样会存在过拟合的问题。
召回率recall、正确率precision
正确率: TP / (TP + FP),表示预测为正例的样本中真正正例的比例。
召回率: TP / (TP + FN),表示预测为正例的真实比例占所有正例的比例。
混淆矩阵:
true positive (真正, TP):将正类预测为正类的数目
true negative (真负, TN):将负类预测为负类的数目
false positive (假正, FP):将负类预测为正类(Type I error)
false negative (假负, FN):将正类预测为负类数→漏报 (Type II error)
https://wangwenqiang.blog.csdn.net/article/details/82973387?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.add_param_isCf&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-3.add_param_isCf
softmax函数
https://blog.csdn.net/bitcarmanlee/article/details/82320853?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.add_param_isCf&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.add_param_isCf
softmax是一个算法,是一个函数,激活函数,又称归一化指数函数。
作用是把一个序列编程概率,他能够保证所有元素:
都在0和1之间,并且所有的值加起来等于1
学习率:
| 学习率大 | 学习率小 | |
|---|---|---|
| 学习速度 | 快 | 慢 |
| 使用时间点 | 刚开始训练时 | 一定轮数之后 |
| 副作用 | 容易梯度爆炸,容易震荡 | 易过拟合,收敛速度慢 |
目标检测性能评价指标(mAP, IoU, NMS,速度)
https://blog.csdn.net/qq_29893385/article/details/81213377
mAP平均精确度(mean average precision)
P-R曲线,以precision和recall召回率为纵横坐标。围起来的面积就是AP指。在不同的召回率下的预
IoU交并比(intersection-over-union)
预测了一个框叫候选框(candidate bound),原标记框(ground truth,gt),他们的交集比上并集的比例值就是交并比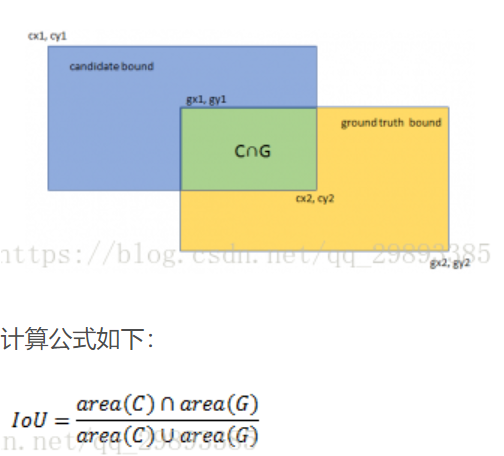
NMS(非极大值抑制)
non maximum suppression即非极大值抑制,顾名思义就是抑制不是极大值的元素,搜索局部的极大值
在物体检测中,NMS应用十分广泛,其目的是为了清除多余的框,找到最佳的物体检测的位置。
速度
每秒帧率,即每秒可以处理的图片数量(FPS,frame per second)
BPR (best possible recall)
batch批训练
单词训练用的样本数,通常为2^N,如32,64,128
如果batchsize过小,训练数据就收敛困难,过大,虽然相对处理速度加快,但所需内存容量增加。
使用中需要根据计算机性能和训练次数之间平衡
full batch learning全数据集
https://blog.csdn.net/starzhou/article/details/53692248
全数据集更代表样本总体,从而更准确的朝向极值所在的方向,其二,不同权重的梯度值差别巨大,因此选取一个全局的学习率很难,可以使用Rprop只基于梯度符号并且针对性单独更新各权值
epoch
1 epoch = 完成一次全部训练样本 = 训练集个数 / batch_size
iterations
1 epoch = 完成一次batch_size个数据样本迭代,通常一次向前传播+一次反向传播
FLOPS FLOPs
FLOPS,即每秒浮点运算次数,是每秒所执行的浮点运算次数(floating-point operations per second),被用来评估电脑性能
FLOPs,注意s小写,是floating-point operations的缩写(s表示复数),指的是浮点运算数,理解为计算量,可以用来衡量算法/模型的复杂度
边框回归(bounding-box regression)
让预测的框更接近原始框
https://blog.csdn.net/zijin0802034/article/details/77685438
梯度直方图
支持向量机
置信度
我预测的值,我有a%的概率认为它和实际值非常接近。
R-CNN
全称是region-cnn,是第一个将深度学习应用到目标检测上的算法,r-cnn基于卷积神经网络(CNN),线性回归,支持向量机(SVM)等算法,实现目标检测
https://blog.csdn.net/weixin_41923961/article/details/80113669
R-CNN是对region proposal候选区域训练, FAST-RCNN(基于VGG16)是对整张图训练,减少了重复运算,
FASTER RCNN已经将特征提取(feature extraction),proposal提取,bounding box regression(rect refine),classification, classification都整合在一个网络中,使得综合性能有较大提升,在检测速度方面尤为明显。
https://zhuanlan.zhihu.com/p/31426458
锚点框(anchor)
在目标检测中,生成的网格中心成为锚点,把每个锚点处的框称为锚点框(锚框)
https://zhuanlan.zhihu.com/p/86741707
在图片中,以一定的步长选取一定的锚点,以每个中心店为框的中心画多个固定高度和宽度的框。
k-means —— 聚类算法
分类是给数据分配标签
聚类就是将相似的事物放在一起
所谓聚类算法是指将一堆没有标签的数据自动划分为基类的方法,属于无监督学习方法。
k就是一个值,希望数据集经过聚类得到k个集合
然后对每个点,计算其与每一个质心的距离(如欧氏距离),离哪个近,就属于那个集合
重新计算每个集合的质心
如果新计算出来的质心和原来的质心之间的距离小于某一个设置的阈值(表示重新计算的质心的位置变化不大,趋于稳定,或者说收敛),我们可以认为聚类已经达到期望的结果,算法终止
超参数和参数
超参数不需要数据驱动,而是在训练前或者训练中认为的进行调整的参数,比如:
网络参数,网络层与层之间的交互方式,卷积核数量和卷积核尺寸,网络层数和激活函数等
优化参数,一般指学习率,batchsize,不同优化器的参数以及部分损失函数的可调参数
正则化参数,权重衰减系数,dropout比例
模型参数通常是由数据来驱动调整。如卷积核里的参数,即权重
normalization归一化(重点,继续研究)
https://zhuanlan.zhihu.com/p/33173246
BN
normalization是数据标准化(归一化,规范化),batch可以理解为批量
BN层的作用:
加速网络收敛速度,可以使用较大的学习率来训练网络
改善梯度弥散
提高网络的泛化能力
bn层一般用在现行层he卷积层后面,而不是放在非线性单元后面
LN(layer normalization)
WN(weight normalization)
DNN RNN LSTM
https://blog.csdn.net/Eddy_zheng/article/details/50763648?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.add_param_isCf&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.add_param_isCf
dnn,深度神经网络
rnn,循环卷及网络,可以看成一个在时间上传递的神经网络,它的深度是时间的长度。为了解决时间上的梯度消失,机器学习领域发展出了长短时记忆单元LSTM,通过门的开关实现时间上的记忆功能,并防止梯度消失。梯度消失就是梯度弥散
lstm,长短时记忆网络
卷积,为什么是卷积?卷积核为什么是奇数?
卷积,就是一个二维函数,降维打击,编程一维函数,俗称降维打击。
在统计学中,加权的滑动平均是一种卷积。
CNN里卷积就是加权平均。
卷积核是奇数的原因有几个,其中一个是padding好取值,可以根据卷积后的图像大小公式推导出来,只有当卷积核大小为奇数时,padding取整
3*3是能够包含上下左右领域信息的最小尺寸。
Top-1错误率和Top-5错误率
top-1 and top5 error 是深度学习中评价模型预测错误率的两个指标。
Top-1 error的意思是:假如模型预测某张动物的图片,比如一只猫,且模型只输出1个预测结果,那么这个结果是毛的概率就是top1正确率,不是猫的概率就是top-1错误率。
top-5 error的意思是:加入预测某张动物的图片,还是那只猫,但模型会输出5个预测结果,那么这5个结果当中有猫的话,加起来就是top-5正确率,相反,如果这五个结果里都没有猫的概率则为top-5错误率。
一般来说,top-1和top-5错误率月底,模型的性能越好。且top-5 error在数值上回避top-1 error的数值更小,毕竟从1个结果中猜对的几率总会比5个结果里猜对的几率要小。
多级网络不适合NPU加速
npu的处理速度要比cpu快,多级网络在cpu上运行完全没有问题,因为图片的处理,传输都在cpu里面
但是在npu里面不行,npu专门用于神经网络加速,不负责图像的传输,判断等操作。并且,数据传输的速率是远远小于cpu处理数据的速度又小于npu处理数据速度。
所以,让npu处理多级网络,等于是进行一个网络,然后传出来给cpu处理,然后再传进npu处理。中间的传输速率远小于两方的处理速率,所以多级网络不适合npu加速。
MLP多层感知机
赫布原则Hebbin Principle
是一个神经科学理论,解释了在学习过程中脑中的神经元所发生的变化。在人工神经网络中,突触间传递作用的变化被类比为神经元网络中相应权重的变化。如果两个神经元同步激发,则他们之间的权重增加;如果单独激发,则权重减少。赫布原则是最古老的也是最简单的神经元学习规则。
ROI
region of interest。可能感兴趣的区域(目标检测,检测通常为多目标,定位通常为但目标)
pipeline
深度学习的操作流水线,顾名思义。从数据开始,到模型,损失函数,优化算法到训练循环,推理输出一条龙服务。每个模块都有很多tricks,多做就有了pipeline
checkpoint
在TensorFlow中checkpoints文件是一个二进制文件,用于存储所有的weights,biases,gradients和其他variables值。.meta文件则用于存储graph中所有的variables,operations,collections等。简言之一个存储参数,一个存储图。

若有收获,就点个赞吧
0 人点赞
