Nianfeng Liu, Haiqing Li, Man Zhang, Jing Liu, Zhenan Sun and Tieniu Tan
Center for Research on Intelligent Perception and Computing,
Institute of Automation, Chinese Academy of Sciences, Beijing, P.R. China, 100190
{nianfeng.liu, hqli, manzhang, jingliu, znsun, tnt}@nlpr.ia.ac.cn
Abstract
传统的虹膜识别需要控制条件(例如,近距离采集和驻足凝视方案)和高用户协作来获取图像。非合作采集环境中存在许多不利因素,如模糊、离轴、遮挡和镜面反射等,对现有的虹膜分割方法的一个挑战。在本文中,我们提出了两种虹膜分割模型,即层次卷积神经网络(HCNNs)和多尺度全卷积网络(MFCNs),用于在远距离和移动中获取有噪声的虹膜图像。这两种模型都能自动定位虹膜像素,而不需要手工制作的特征或规则。并对特征和分类器进行了联合优化。它们是端到端模型,不需要进一步的预处理和后处理,性能优于其他最先进的方法。与hcnn相比,MFCNs接受任意大小的输入,产生相应大小的输出,不需要滑动窗口预测,这使得MFCNs更加高效。MFCNs结合了浅层、细层和深层、全局层,既能捕捉虹膜图案的纹理细节,又能捕捉虹膜图案的全局结构。实验结果表明,MFCNs对噪声的鲁棒性要由于HCNNs,并且比现阶段的SOTA网络分别在UBIRIS.v2和CASIA.v4-distance两个数据集上分别挺高了25.62%和13.24%。
1.Introduction
虹膜分割的目的是在噪声背景下找到有效的虹膜纹理区域。作为虹膜识别算法的起始过程,其准确性对后续特征提取和分类的准确性有很大的影响。为了减少虹膜识别中用户的合作,在过去的20年里,人们花费了大量的精力开发远距离和移动系统[8,17]。传统的虹膜分割算法在非合作环境下,由于模糊、离轴、遮挡和镜面反射等不利因素,其精度显著降低。
现有的虹膜分割方法大致可分为两大类。第一类是基于边界的方法,通过定位瞳孔、边缘和眼睑的边界来分离虹膜纹理区域。第二类是基于像素的方法,根据像素周围的外观信息直接区分虹膜像素和非虹膜像素。
两种经典的基于边界的方法是基于积分-微分算子[5]和基于Hough变换[31]。积分-微分算子在参数空间上详尽地搜索轮廓积分导数的最大值。在二值边缘映射中,霍夫变换通过一种投票程序找到最优曲线参数。在合作环境中,瞳孔和边缘边界可以拟合为圆形或椭圆形,上下眼睑边界可以拟合为样条[6]或抛物线[31]。基于边界的方法高度依赖于图像梯度。近红外(NIR)图像的边缘边界和可见光图像的瞳孔边界通常对比度较低,但由于遮挡和镜面反射,出现大量的高对比度边缘点。因此,原始的积分-微分算子和霍夫变换在非协作环境中表现不佳。为了提高基于边界的虹膜分割方法的鲁棒性和效率,人们提出了许多去噪方法[10,33]、虹膜粗定位[28]、边缘检测[13]和边界拟合方法[3,29]。active contours被用来拟合不规则的虹膜形状,但它们往往被虹膜纹理、遮挡和镜面反射所困[7,23]。
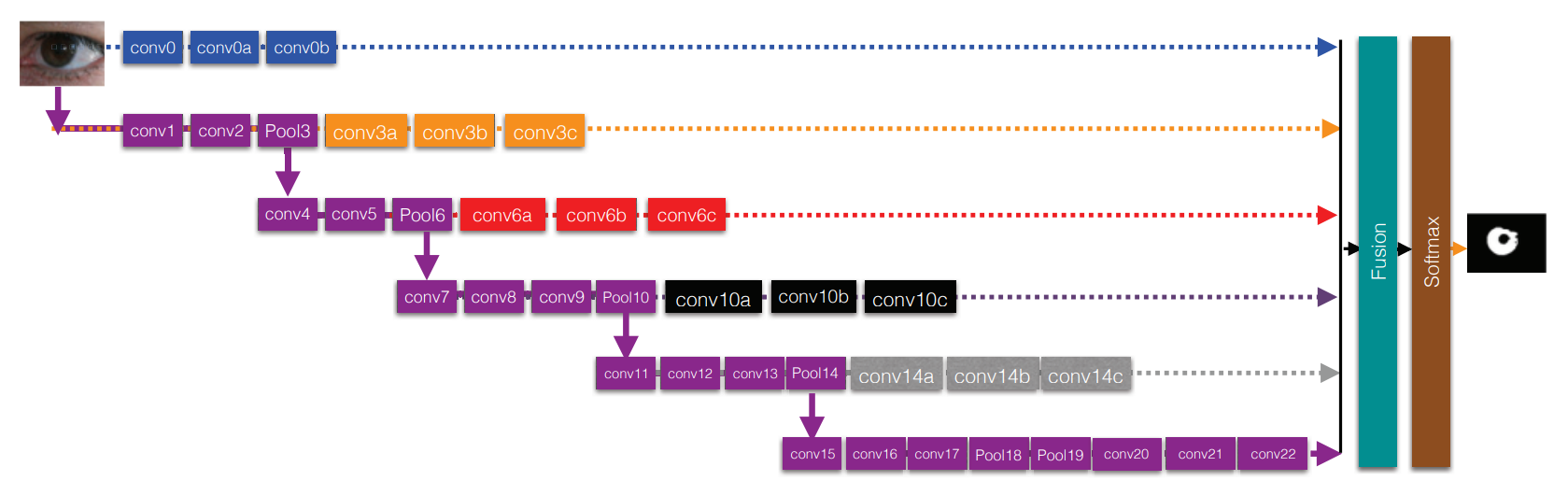
图 1 - MFCNs的结果。conv表示卷积层,Pool表示池化层,每一层具体的参数显示在表2.
虹膜图像不仅包含梯度和几何信息,还包含丰富的亮度、颜色和纹理等其他外观信息。基于像素的方法首先在像素的邻域内提取鉴别外观特征,然后构造分类器对虹膜像素进行分类。Pundlik等人[21]通过基于图割的能量最小化方法对睫毛、瞳孔、虹膜和背景进行分离。该系统采用[19]设计,并采用一层隐层的神经网络对虹膜像素进行分类。Tan和Kumar[26]提取像素周围的Zernike矩,然后使用支持向量机(svm)进行分类。Li和Savvides[14]使用Gabor滤波器和高斯混合模型(GMMs)对归一化虹膜纹理图中的虹膜像素和遮挡进行分类,而不是在原始虹膜图像中检测遮挡。
现有的基于边界和基于像素的方法主要是基于先验知识设计的,需要大量的预处理和后处理。此外,它们手工制作的特性缺乏找到最佳descriptor的灵活性。深度卷积神经网络(CNNs)提供了一个强大的端到端模型,可以自动学习最优特征和分类器。cnn最近在图像分类[12,24,25]、生物特征欺骗检测[18]、人脸识别[22]、虹膜识别[15]等方面取得了很大的成功。然而,将cnn应用于图像分割存在两个困难。第一个问题是由于cnn对局部空间变换的不变性导致的定位精度有限。第二种方法是采用滑动窗口的方式对每个像素进行分类,计算复杂度较高。为了解决这些问题,层次cnn[9,32]可以结合高、低层次的视觉线索来提高定位精度。全卷积网络(Fully convolutional networks, FCNs)[4,16]可以实现pixels-to-pixels的预测,因此可以加快学习和推理的速度。
在本文中,我们提出了两种模型,即层次卷积神经网络(hierarchical convolutional neural network,HCNNs)和多尺度全卷积网络(multi-scale fully convolutional networks,MFCNs),来解决有噪声的虹膜分割问题。通过对这两种模型的比较,证明了MFCNs在准确性和效率上的优越性。该算法对输入虹膜图像进行密集预测,生成有标记的map,避免了HCNNs中滑动窗口重叠时的重复计算。这两种模型都是端到端预测,特征和分类共同优化。注意,这两个模型都不包含进一步的预处理和后处理。为了将虹膜局部纹理的精细细节和眼睛的整体结构结合起来,MFCNs融合了从浅、细到深、粗的多层结构。我们在两个众所周知的数据集上进行实验:UBIRIS。v2[20]和CASIA。4-距离[2]数据库来评估所建议的HCNNs和MFCNs的性能。实验结果表明,该模型对可见光和近红外光照下的虹膜图像均有显著改善。MFCNs比现有的SOTA网络在平均segmentation errors上有如下提升:分别在UBIRIS.v2 and CASIA.v4-distance提升25.62% and 13.24%。
本文的其余部分组织如下。在第2节中,我们将详细描述MFCNs和HCNNs。第3节描述了我们的实验并讨论了我们的结果。最后,本文在第四部分进行总结。
2. Technical details
针对虹膜分割问题,提出了两种网络:层次卷积神经网络(HCNNs)和多级全卷积网络(MFCNs)。通过对两种模型的比较和分析,说明了MFCNs的效率和有效性的优先性。
2.1. Hierarchal convolutional neural networks (HCNNs)for iris segmentation
典型的卷积神经网络由卷积层、池化层和全连通层构成。最著名的网络有AlexNet[12]、VGGNet[24]和google[25]。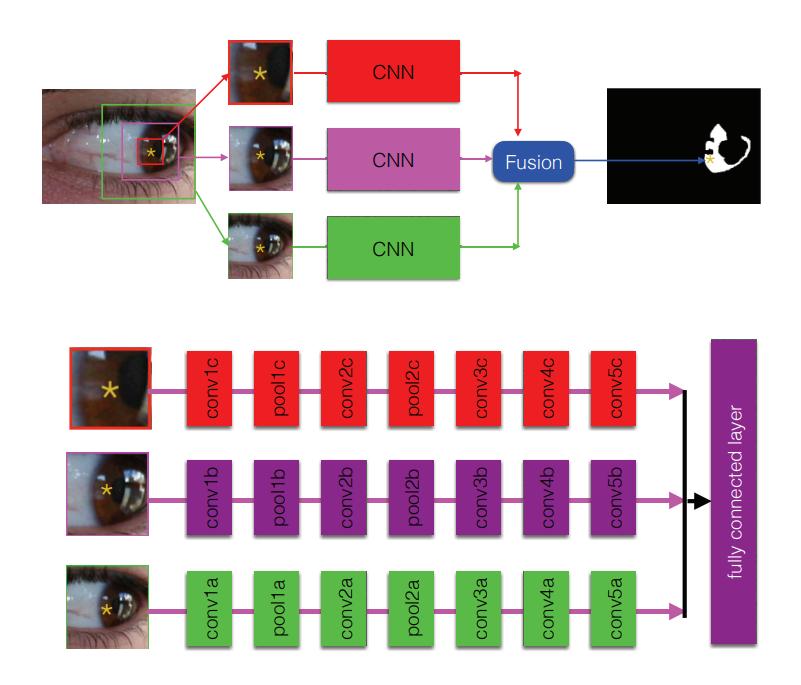
图2 - hcnn的总体架构。对于图像中的每个像素,将以三种不同尺度(56×56、112×112和224×224)从小到大裁剪三个补丁。对每个像素进行分离、训练或测试,最后将每个像素的预测标记合并为一个虹膜掩膜。
Convolutional layers利用卷积核对输入图像进行卷积操作,可以由如下公式表示: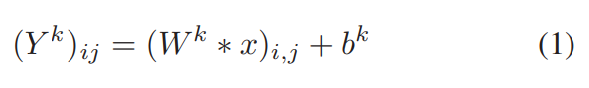
表示对图像x的卷积,k表示卷积核的序号,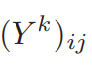 表示第k个卷积核与以(i,j)为中心的像素卷积的响应。
表示第k个卷积核与以(i,j)为中心的像素卷积的响应。
Pooling layers池化层通过不同的下采样策略进行非线性转换,包括最大池化、平均池化和随机池化。池操作为每个滑动窗口输出一个值。它减少了后续层的计算量,减少了参数数量,缓解了过拟合。最大池化常用于计算机视觉任务。
*Fully connected layers将前一层所有神经元连接到它拥有的每个神经元。它可以表示为: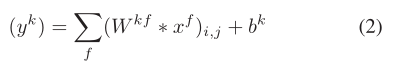
其中f表示输入中的第f个神经元的序号,yk表示k个输出神经元,Wkf和bk表示神经元xf和yk之间的权重和bias。

若有收获,就点个赞吧
0 人点赞
