Ze Liu†Y utong Lin†Y ue CaoHan Hu‡Yixuan Wei†
Zheng Zhang Stephen Lin Baining Guo
Microsoft Research Asia (MSRA) 亚洲微软研究院
https://www.msra.cn/
1. Abstract
Swin Transformer是 Shifted Windows Transformer的简称,可以作为一种通用的backbone进行各种视觉任务。本文的工作就是将NLP的主流网络Transformer与CV任务进行一个融合,还提出了shifted windows、shifted windows based self-attention、relative position bias创新点。并且在各大榜单上屠榜,包括分类、目标检测、分割等领域,不管是在速度上还是精度上。
2. Motivation
将transformer从NLP领域转换到CV领域是极具挑战的,比如:
- 视觉实体中规模变化大(一个实体可能很大可能很小,但是NLP中不同word对应的vector大小差别不会太大;
- 相对于文本中的单词,图像中的高像素。
在NLP中最为流行的框架为transformer(attention is all you need),它在NLP的成功使得大量的研究者尝试将transformer运用到CV中,包括我们,并且最近已经在图像分类和联合vision-language modeling上得到promising的结果。
比如说VIT,也是一个transformer运用在CV中的成功例子,其在图像分类的结果令人兴奋,但是它的结构不适合作为一种通用的dense vision task的backbone,并且VIT本身存在一些缺点。比如说VIT需要大量的数据集才能有好的性能,即难以收敛。个人理解为是因为VIT运用了大尺度的全局自注意力机制,导致收敛困难。
全局的自注意力计算会带来tokens的二次级别的计算量,这个计算量是很可怕的,这也使得之前的transformer不适合于解决视觉问题,特别是需要dense prediction的任务或者是高像素的图片。
由于transformer在NLP的成功,研发者将transformer运用在CV中,运用了一种sliding windows的技术,但是这种技术会造成很高的延时,因为它们在memory access内存读取中消耗很大(暂时理解为这种数据结构不方便读取,硬件无法适配,原理可能类似空洞卷积)
3. Methods
patch partition
swin-transformer构建了一种hierarchical representation层级表示,实现方式是从构建小的patchs然后在深层layer中逐步合并patch。
patch的partition可以理解为将图像规则的分成一个个non-overlapping的小格子,比如令格子的长和宽为4pixel,那么一个 的图像就被分为
的图像就被分为
Swin Transformer Block
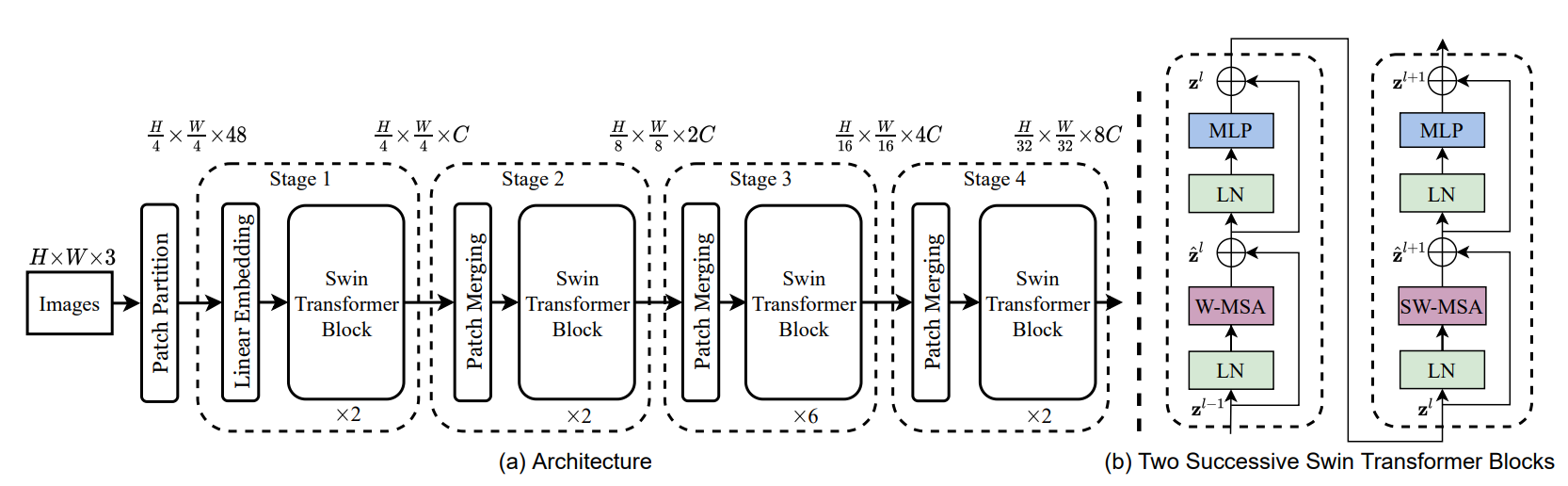
上图右侧就是两个连续的Swin Transformer Blocks,可以看到一个基础的block先是经过一个LN层(LayerNorm,区别于batchnorm)、一个W-MSA/SW-MSA模块(multi-head self attention,属于NLP中的自注意力,区别于图像中的注意力CA,CBAM等),然后是一个残差连接,再是一个LN层,最后是一个两层的MLP。
其中W-MSA即windows MSA,S-MSA即shifted windows MSA。需要注意的是堆叠的swin transformer block的数量必须是偶数。经过一次windows MSA之后要经历一次shifted windows MSA。
至于为什么是偶数,个人理解是,如果不是偶数,self-attention就变成了局部自注意力,感受野范围是patch_size的大小,而如果是偶数,就用上了作者提出的S-MSA,感受野进一步扩大。连续的W-MSA、S-MSA堆叠,可以使得一个像素点的注意力从本身扩散到全局,并且注意力程度逐步下降。
self attention in non-overlapped windows
前面提到,传统的transformer运用全局注意力机制,全局注意力机制的运算复杂度是图像像素的2次方倍。这个计算量是很恐怖的。而W-MSA解决了这个问题。
self attention
流程:
https://blog.csdn.net/weixin_40746796/article/details/88131967
中文blog
https://jalammar.github.io/illustrated-transformer/
原文blog
原理:
https://zhuanlan.zhihu.com/p/410776234
简单总结一下,在NLP的encoder模块当中(可能有很多个encoder block的叠加),包括了一个self-attention layer和一个feed forward neural network。inputs首先会经过self-attention layer,这一层的作用就是帮助encoder在encoder处理特定位置的word的时候,关注到输入序列的其他words。
自注意力的公式为:
Windows MSA
假设一张图像为H W C,每个窗口包括M * M个patches,那么MSA和W-MSA的计算量为:

还没搞懂公式怎么来的。
因为h,w,C都是固定的,那么W-MSA的计算复杂度就和M^2成线性关系。
还需继续研究
Shifted Windows
W-MSA即windows multi-head self-attention的缺点在于,其自注意力计算局限在单个window之内,windows之间没有进行自注意力的计算,这限制了它的建模能力。于是作者提出了shifted windows,可以通过图来理解: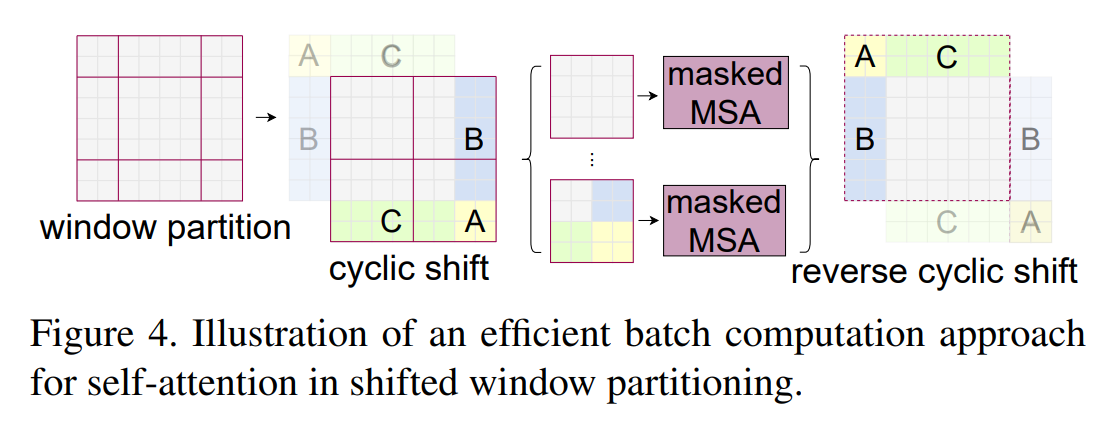
如果移动只是简单的移动windows的位置,比如说往右下角移,那么右下角的windows有patch空缺,左上侧的patch将不被windows覆盖。一个简单的方法是在这些不被覆盖的patch中再建立一些windows,然后不满足windows大小的地方用padding填充。但是这样会有一个问题,windows变多了,计算量也就变多了。
于是作者提出了一个cyclic-shifting的移动windows方案,如图所示。将左上角没有被覆盖的patch通过cyclic-shift的方式移到右下角进行填充。然后在计算完self-attention之后,再reverse cyclic shift到原本的地方。
这里我提出了一个疑问:如此的cyclic shift操作,其实打乱了图像中的相对位置关系。假设图片没有patch化,就是一张人眼RGB图,那么cyclic shift操作就像是把眼睛左上角的眉毛移动到右下角去,将眉毛和眼睛右下角放在一个windows里做自注意力。相对关系被破坏了,直觉上来讲有一点膈应。我觉得比较合理的解释是,self-attention,是patch与patch之间的关系程度计算,所以说patch放在哪其实都无所谓,把一个patch放在很远、不相关的区域进行self-attention也可以计算,只是相关程度比较低而已。
解答:
之前理解错了,在shift windows之后,的确存在位置不相关或者说相对距离较远的矩阵块放在一起计算attention,这不是我们想看到的。于是,swin-transformer中给shifted window加了一个attention mask。这个mask区别于传统的NLP中的mask。用一下步骤理解:
- 现在想象左上角的图像块编号为1挪到了右下角的编号为8进行W-MSA,8和1会按照普通W-MSA计算attention,但是其实它们并不相关。
- 我们知道自注意力是计算q @ k^T,这里的q是由8和1embedding生成的,记为
,那么
这是一个抽象矩阵等式,1不应该与8计算attention,所以我们可以对QK相乘的结果加上一个attention mask,使得1和8相乘的地方值特别小,这样子,最后计算softmax的时候这里的值就基本为0- 对于上面的例子,我们可以让掩码为:
,那么最后的attention公式就变成了:
,这里mask给不相关的西方给了一个很小的负值,这样计算算softmax之后的值就会特别小,基本为0
- https://zhuanlan.zhihu.com/p/367111046这篇图解swin transformer写的很好,关于mask的问题讲的很清楚

relative position bias
这里的相对位置关系bias意思是windows与windows之间的关系bias,作者将这个windows之间的信息加入到self-attention里进行计算,可以提升性能: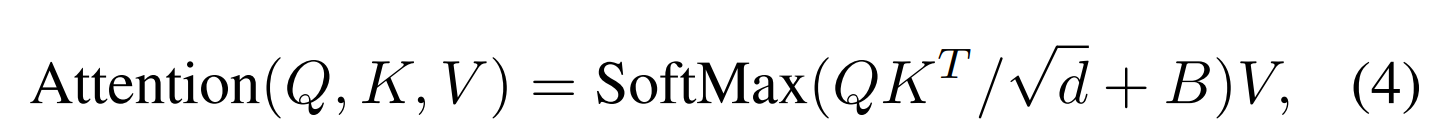
architecture variant
有观察到,一些顶级的论文,特别是提出通用型backbone的,都会给出不同大小、不同等级算力的version。
还有比如说EfficientNetV2:
4. Contribution
本文提供了一种新的vision transformer,叫做Swin Transformer,可以被当做视觉任务的有力的通用backbone。
为了解决CV和NLP在使用transformer的差异性,提出了层次化transformer的概念,这个概念通过shifted windows实现。
提出的shifted windows的方案被证明对all-MLP的架构有利。
在shifted windows的基础上,还提出了cyclic-shifting的batch computation方法,这种方法对于硬件支持来说比简单的padding效率更高,特别是在深层的stage当中。
提出的Swin Transformer获得了强大的性能,屠杀了视觉任务的各项榜单,比如图像分类、目标检测和语义分割,不管是在速度上还是精度上。
5. Conclusions
没有读过ViT,Swin-Transformer算是transformer文章的第一篇。swin-transformer一个最直观的特点也可以说是缺点的地方在于,网络模型根据输入图像的变化而变化。比如对于输入为 的图片,swin-transformer-T的大小为29*4=116MB,如果是
的图片,swin-transformer-T的大小为29*4=116MB,如果是 ,那么swin-t的大小可能要达到500M以上(没算),这样子显存有限的情况下根本没法训练。再者,如果输入图像大小和论文给出的不一致(不是224)的话,就没法使用官方给出的预训练模型,而transformer从头开始训练时很难收敛的。
,那么swin-t的大小可能要达到500M以上(没算),这样子显存有限的情况下根本没法训练。再者,如果输入图像大小和论文给出的不一致(不是224)的话,就没法使用官方给出的预训练模型,而transformer从头开始训练时很难收敛的。
第二点,transformer有如linear全连接层的缺点,对于训练好的模型,输入图像大小不能改变。这样就需要对图像进行预处理,使用场景就受限了,而且一个大图resize成224之后,就已经丢失了很多信息了。

若有收获,就点个赞吧
0 人点赞
