这篇博文中展示了一些最先进的SOTA CNN结构,算是在开Transformer的坑前对CNN做个总结吧= =
MobileNeXt(ECCV2020)
论文:https://arxiv.org/pdf/2007.02269.pdf
算是对MobileNet的结构改进
模型结构
Sandglass Block
作者认为在较宽的地方加shortcut能够更好地传递信息,同时使得梯度传递更加顺畅。因此作者基于MBv2的Inverted Bottleneck改进得到了Bottleneck结构的Sandglass Block。在中间较窄宽度时做DW卷积会掉很多点,因此作者把DW卷积提到了Block开头宽的地方。作者还发现在末尾补一个DW卷积能扩大模型感受野并提高模型性能,同时在最后这个DW卷积后加activation会掉点(即使是在宽的地方)。
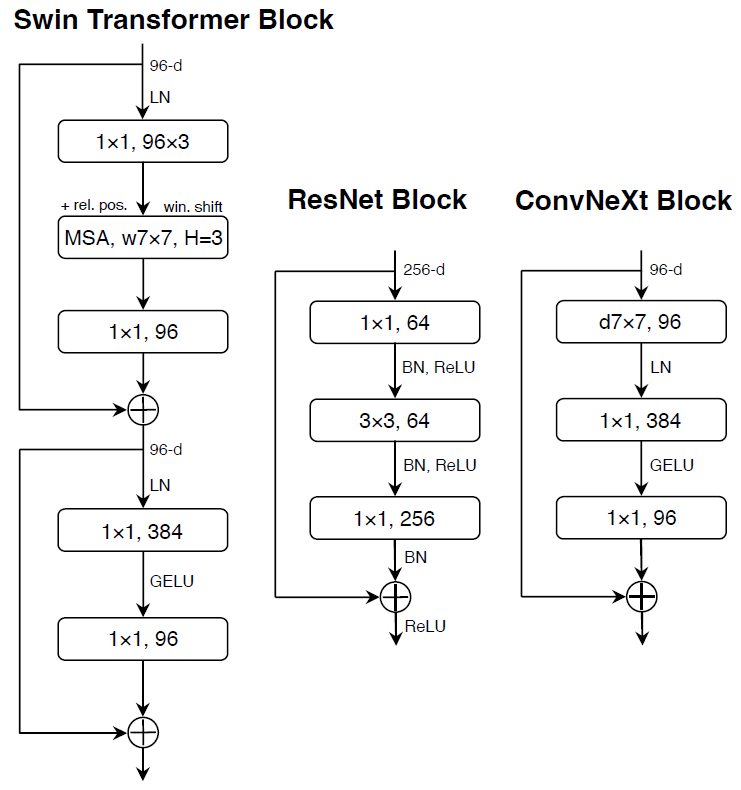
下图左:MBv2 Inverted Bottleneck;右:MobileNeXt Sandglass Block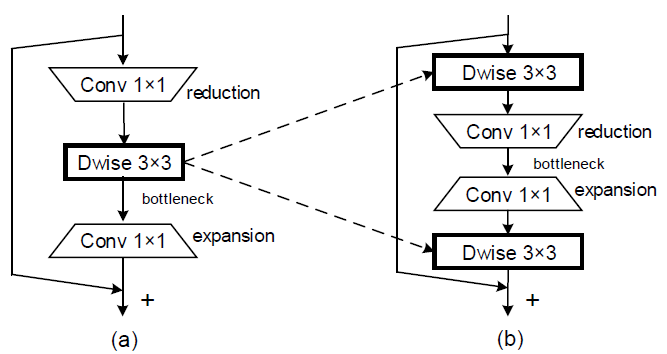
整体模型结构与MBv2略有区别大致类似: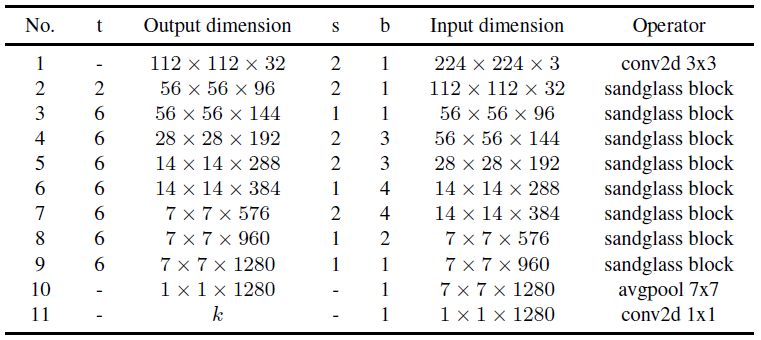
实验结果
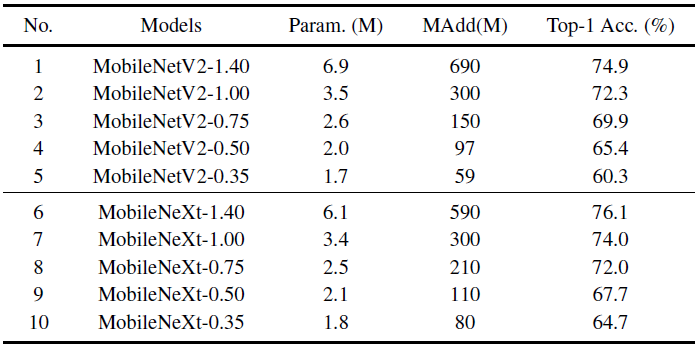
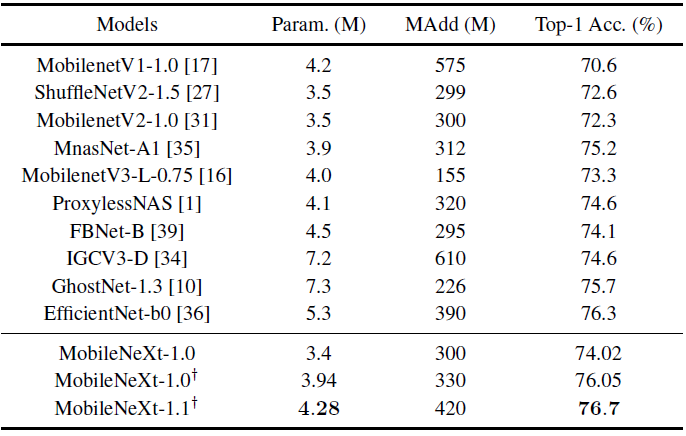
另一个比较有意思的发现:作者在shortcut中去除一部分通道以减小ele-wise add的开销与访存开销( 控制了有多少输入通过shortcut被加到了残差输出):
控制了有多少输入通过shortcut被加到了残差输出):
可以发现,当 时完全不掉点而且快了不少,继续减小
时完全不掉点而且快了不少,继续减小 会造成性能劣化。
会造成性能劣化。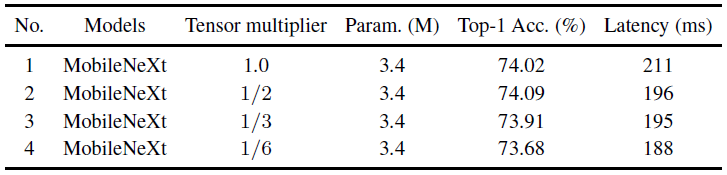
EfficientNet v2(ICML2021)
论文:http://proceedings.mlr.press/v139/tan21a/tan21a.pdf
算是EfficientNet的修修补补吧,感觉Novelty不算高
Fused-MBConv
这个不是这篇文章提的,就是把DW卷积和后面的1x1卷积合成一个常规的3x3卷积。作者发现在浅层stage使用Fused-MBConv可以提高效率,但是在深层用效果较差。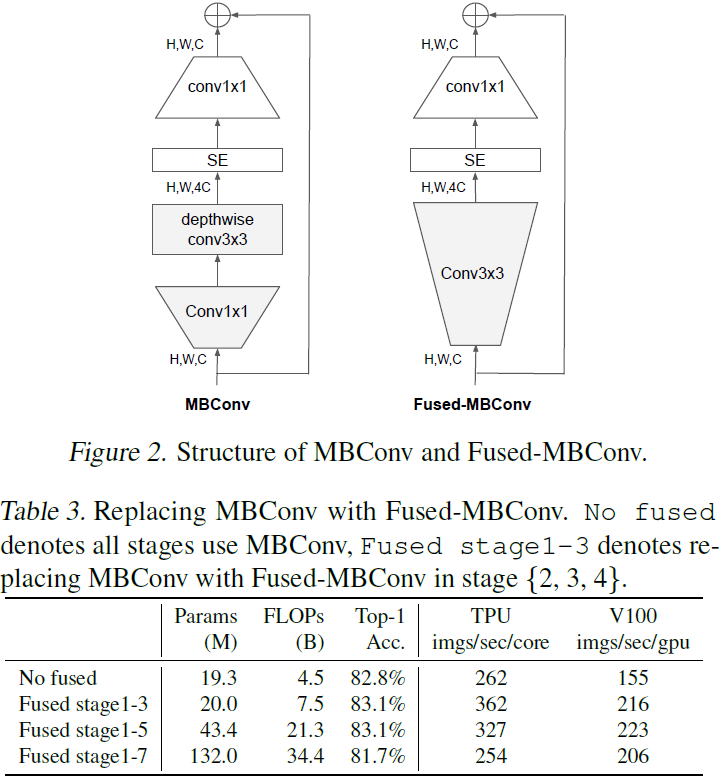
网络结构
熟悉的NAS搜出来的结构,不过作者说在搜的时候结合了模型准确度 、训练速度
、训练速度 、参数量
、参数量 ,通过
,通过 构建reward用强化学习搜。
构建reward用强化学习搜。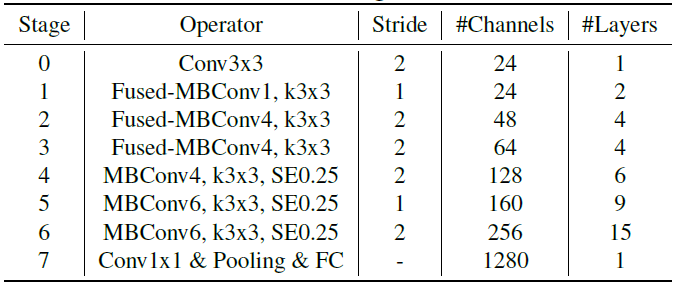
由于EfficientNet v1中大网络的图片大小大到爆炸,导致显存占用爆炸,训练的batchsize小从而超级无敌巨慢,EfficientNet v2中网络的缩放限制了最大的输入分辨率为480。
Progressive Learning
作者在训练初期用了小分辨率的输入,然后在训练过程中逐步将输入分辨率加大。其它若干工作也采用了类似的schedule但是会掉点,作者认为即使在网络相同时,输入分辨率不同时,也应该使用不同强度的正则化: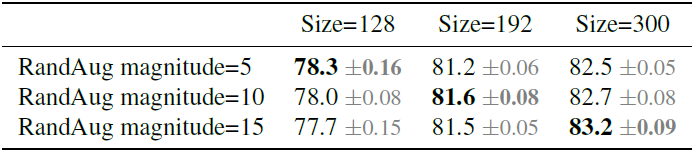
作者将整个训练过程分为了4个阶段,每个阶段使用不同的输入分辨率和正则化(第2、3阶段的输入分辨率与正则化超参数直接通过线性差值得到):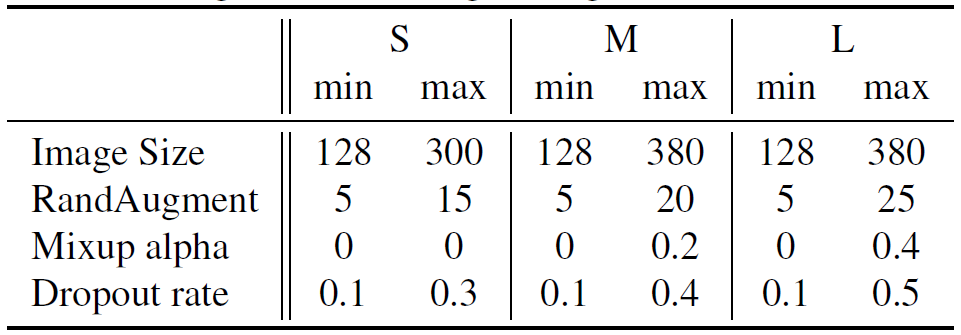
下图展示了训练阶段逐渐加大分辨率、随机选择分辨率,以及是否使用自适应正则化的实验结果: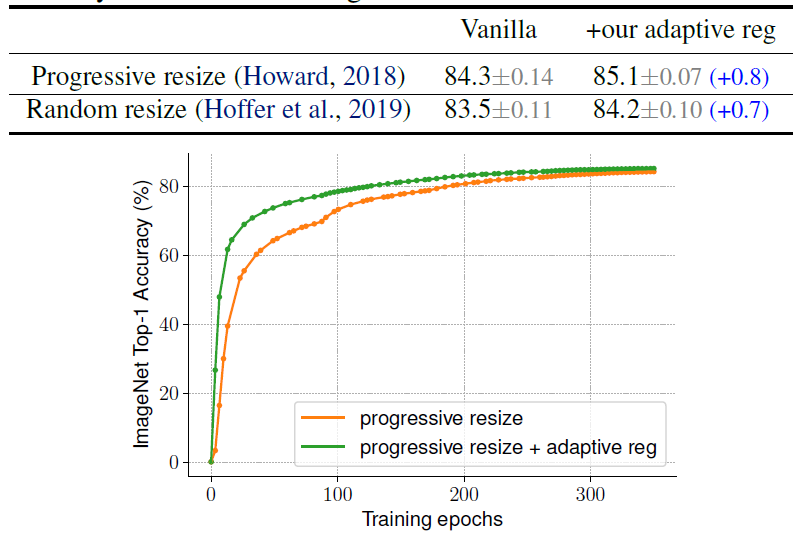
实验结果
ImageNet上总共训练350epoch,bs=4096,RMSProp lr=0.256,每2.4epoch lr*=0.97。使用了RandAugment、Mixup、Dropout、Stochastic Depth(p=0.8)、Model EMA(momentum=0.9999)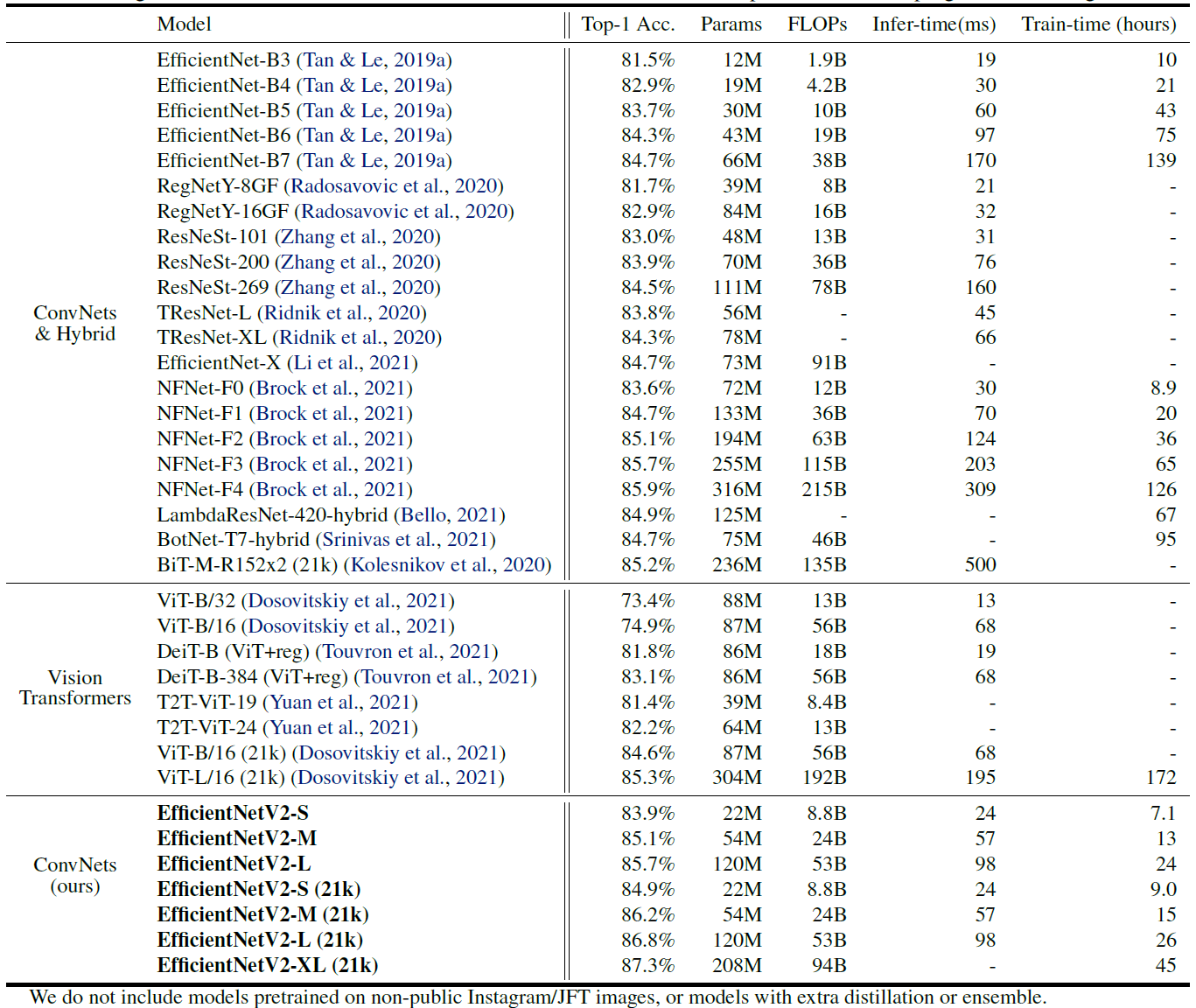
RepVGG(CVPR2021)
论文:https://openaccess.thecvf.com/content/CVPR2021/papers/Ding_RepVGG_Making_VGG-Style_ConvNets_Great_Again_CVPR_2021_paper.pdf
Let’s make VGG greater again!
这篇论文其实非常简单,和郑老师之前的一个idea很像,训练的时候带shortcut然后尝试把shortcut去掉进行推理,能大幅提高推理速度。
不过郑老师是在shortcut后加了个乘数因子,从1.0逐渐衰减到0.0,不怎么work。
Main idea
1x1卷积可以看作是kernel中周围一圈8个点全为0的3x3卷积;而shortcut又能看作是一种特殊的1x1卷积(第n个kernel中只有对应第n个输入通道处为1)。
因此对于单个3x3卷积而言(ResNet这种shortcut覆盖了2个3x3卷积的就不行了),对应的1x1卷积与shortcut是可以在推理阶段合进去的。
如下图所示,RepVGG的推理阶段完全由高效优化的3x3卷积构成,并且没有分支结构。其推理阶段每个3x3卷积结构包含3个分支:3x3卷积、1x1卷积、shortcut(当stride=1时),相加后ReLU。三个分支全部包含独立的BN,shortcut也包含(去掉shortcut上的BN掉一个点)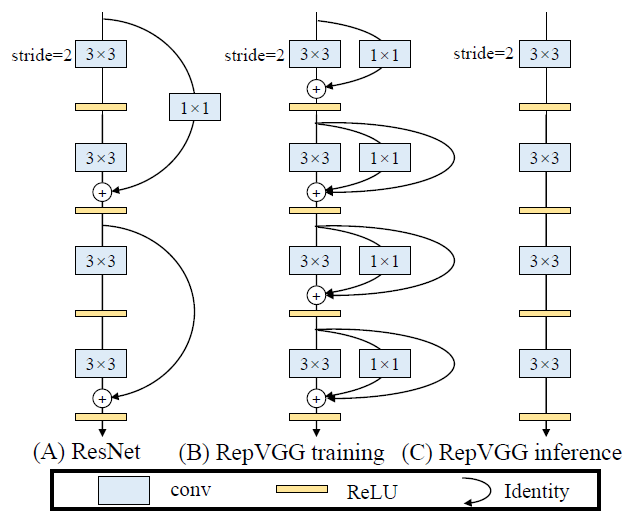
网络结构
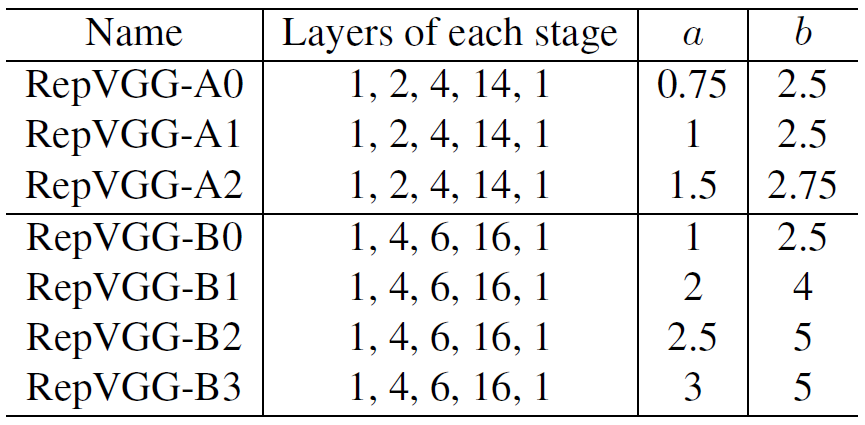
作者提出了RepVGG-A与RepVGG-B两个不同深度的网络,并利用了 与
与 两个超参用于对网络进行缩放。作者提出我们往往取
两个超参用于对网络进行缩放。作者提出我们往往取 以使得分类器的输入拥有更加丰富的特征(与我们提出的head类似)。
以使得分类器的输入拥有更加丰富的特征(与我们提出的head类似)。
为了减小大featuremap的浅层stage开销,112x112分辨率下的通道宽度被限制为最大64。
实验结果
120epoch,标准数据增强,bs256,lr0.1余弦退火,wd1e-4
*RepVGG-B1g4/g2这里的g4/g2表示的是group数。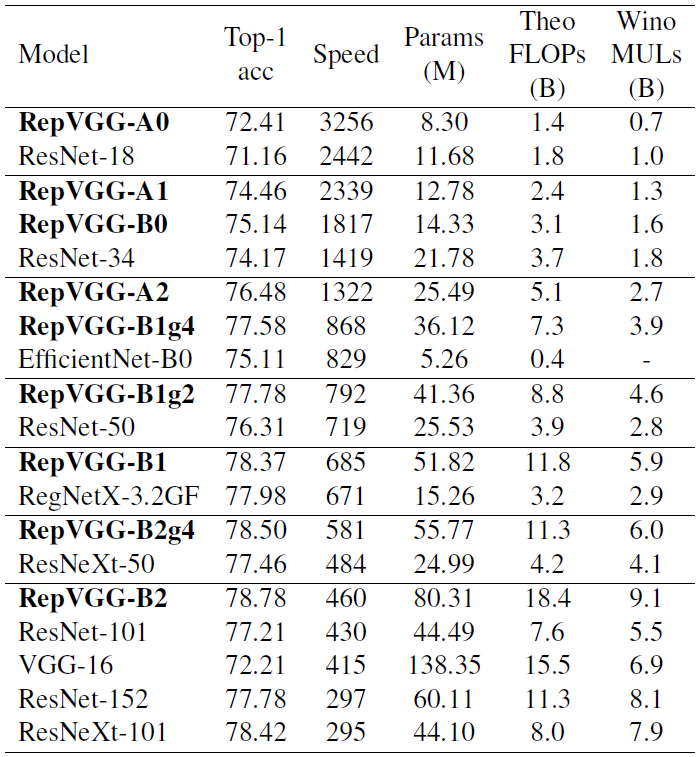
200epoch,Autoaugment,smooth label,mixup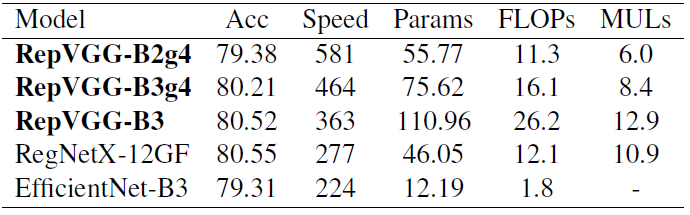
3个分支的有效性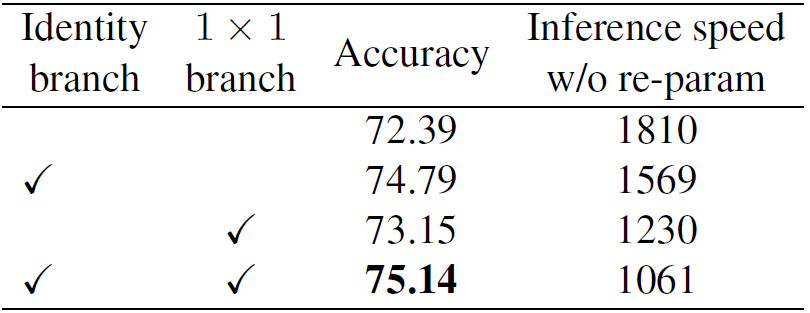
RepLKNet(CVPR2022)
论文:https://arxiv.org/pdf/2203.06717.pdf
其实和RepVGG很像,RepLKNet(Re-parameterization Large Kernel Net)反思了CNN和Transformer的差距,认为建立长距离的空间联系非常有必要,说白了就是浅层也应有更大感受野获得全局信息。RepLKNet在同个特征提取kernels上堆叠了多个不同大小的kernels,其中最大的kernels大到离谱(31x31),然后用类似RepVGG的重参数化技术堆到一个kernel上。
Main idea
大核的高效性
超大的卷积核能够大幅提高网络的有效感受野,并且在DW卷积中依然是高效的:因为DW卷积的效率受限于访存开销,增大卷积核尺寸引入的计算开销对实际推理效率的影响甚微。(虽然现有框架的支持差,作者自己优化了算子)
更依赖依赖短连接
基于MBv2的实验结果: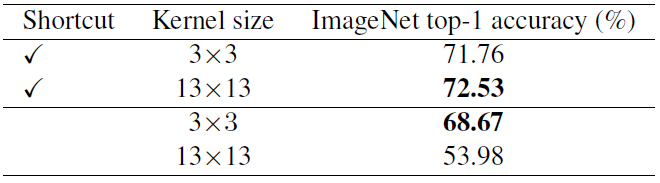
用3x3卷积重参数化
ViT对于小数据集的表现较差,其中的解决办法是在self-attention前加个DW3x3卷积。在这里,作者对大核是否使用3x3核并联(重参数化)在MBv2上做了实验: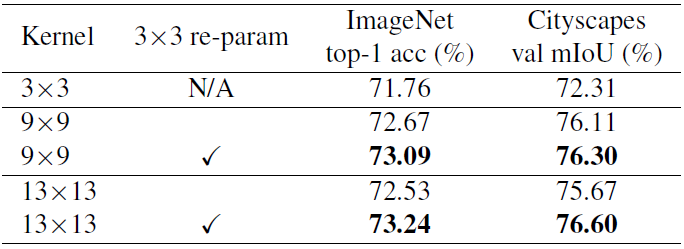
但是作者表示,当预训练的数据集大小达到73M张图片时,是否使用3x3卷积进行重参数化就几乎不再影响网络性能了。
下游任务从大卷积核中受益更多
作者推测这是因为ImageNet分类可以从局部纹理或者物体形状推理,但下游任务譬如目标检测、实例分割更关注于物体形状,这对网络的感受野有更高的要求。一个拥有更强宏观形状提取能力的网络往往能更好地向下游任务迁移。
深层的小特征图依然能从大核中获益
作者以MBv2的stage4(7x7分辨率)举例,展示了将stage4中的DW3x3卷积换成大核的效果。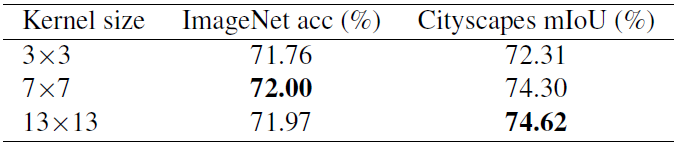
需要注意的是,13x13的卷积核大小已经远大于特征图的大小,此时CNN不再具有严格的平移不变性。但是大核除了能学习特征的相对位置信息外,还能够对绝对位置信息进行编码(由于padding effect,参考《On Translation Invariance in CNNs: Convolutional Layers can Exploit Absolute Spatial Location》)。
网络结构
*需要注意的是,RepLK Block的DW大核卷积是伴随着一个DW5x5卷积用于重参数化的,ConvFFN是一个包含两个1x1卷积与shortcut的block,作者解释为增加网络深度并增加网络的非线性性能。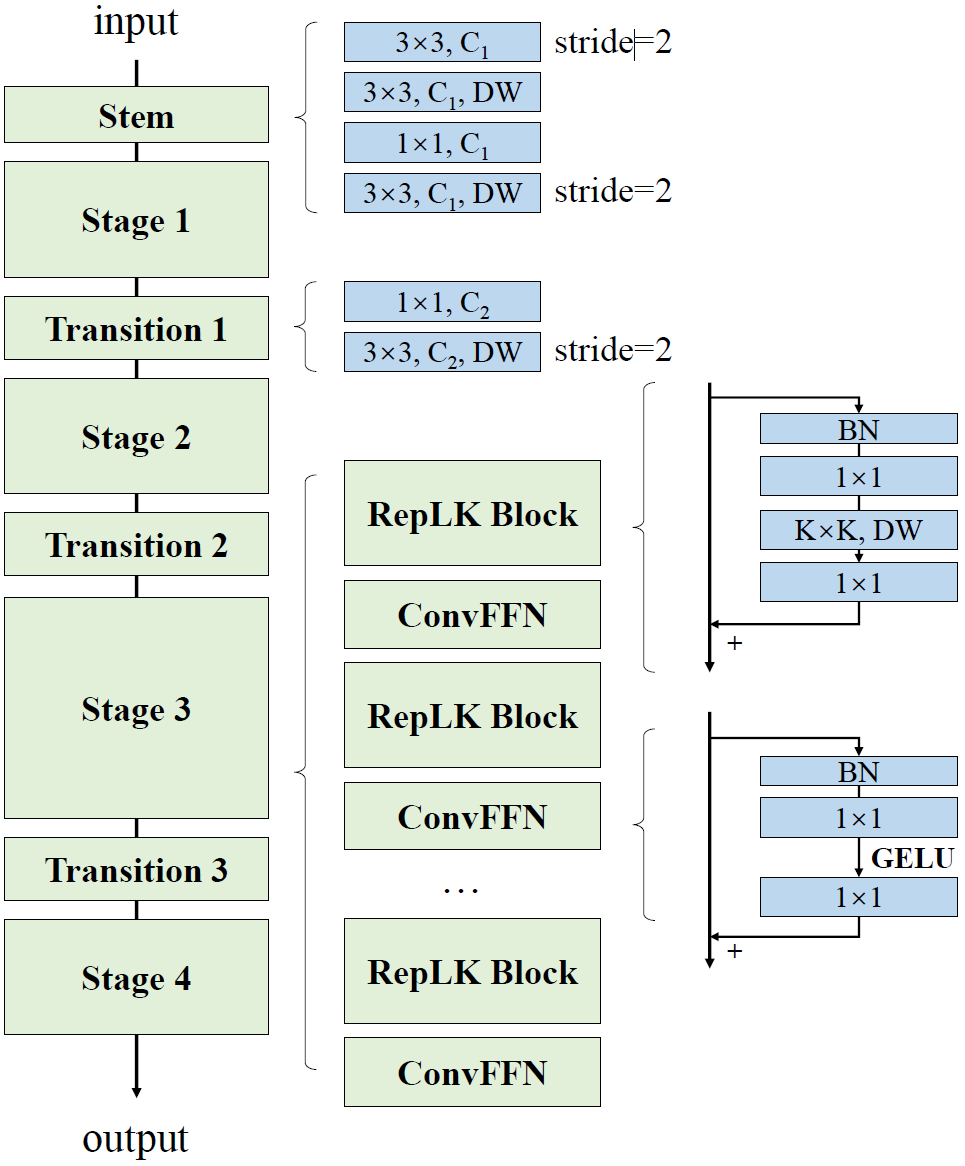
实验结果
Kernel size表示了4个stage中RepLK Block中DW大核的大小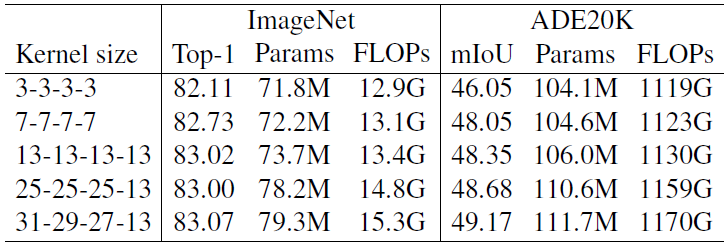
ConvNeXt(CVPR2022)
论文:https://arxiv.org/pdf/2201.03545.pdf
堆实验!各种基于ResNet的微调,有点像2022年的ResNet v1d。不过这篇有点把Swin Transformer中的设计带到CNN里来的意思。
网络调整
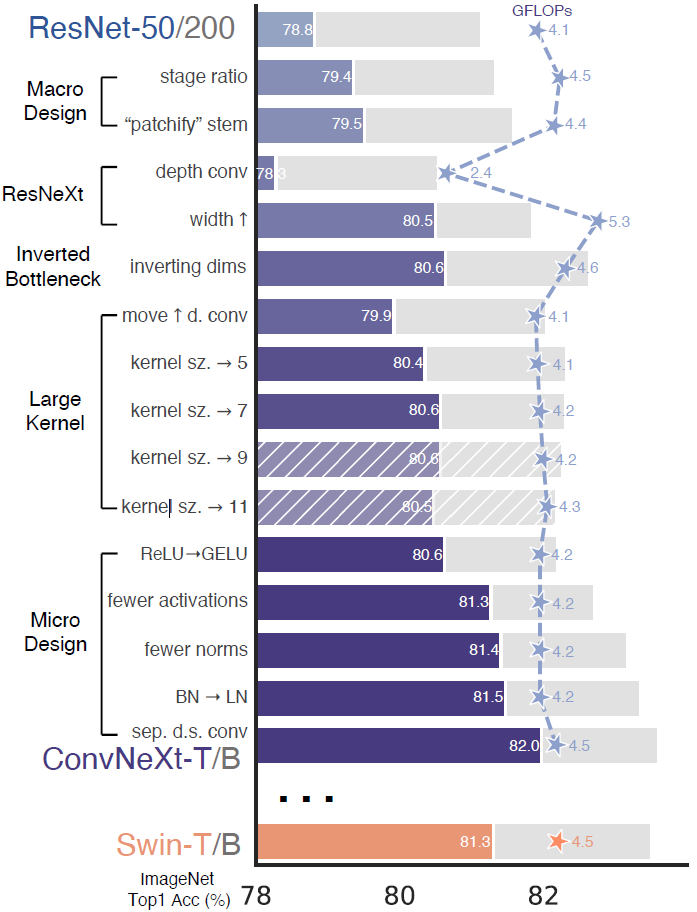
Macro Design
- 更改了各个stage中block数的比例(向ViT看齐),增加了些许深度获得了一定提升
- 把stem从7x7conv_s2+maxpool_k3s2改成了简单粗暴的4x4conv_s4
ResNeXt
3x3使用了DW卷积,并把宽度从64提到96
Inverted Bottleneck
ResNet、ResNeXt中都是两端宽中间窄,因为使用了DW卷积改用Inverted Bottleneck(e=4)。尽管DW卷积的开销变大了,但下采样block中的1x1卷积的开销大大变小的。这么做能减小FLOPs甚至还提高了一丢丢性能?Large Kernel
- 学Swin Transformer把MSA放在MLP前面,把DW卷积往前提,这么做减小了FLOPs因此也损失了一些性能
- 加大kernel size,作者发现加到7以上就无收益了
Micro Design
- 硬学Transformer,激活函数从ReLU换成GELU(在BERT GPT-2 ViT中使用)
- 硬学Transformer,只在每个block第二个卷积后加激活函数(用于升通道的这个1x1卷积),虽然MBv2也说缩通道的时候加激活函数会引发维度坍塌
- 硬学Transformer,只留了DW卷积后的这个BN,其它两个BN都删了
- 硬学Transformer,在做了这些模型改造,用各种training tricks后,把BN换成LN并不掉点反而涨了0.1
- 不再在block中做下采样,单独拉了个2x2conv_s2专门用来做下采样。这么做会导致训练炸掉,作者发现在stem后、每个下采样的2x2conv前、global average pooling后分别加上LN层能稳定训练。
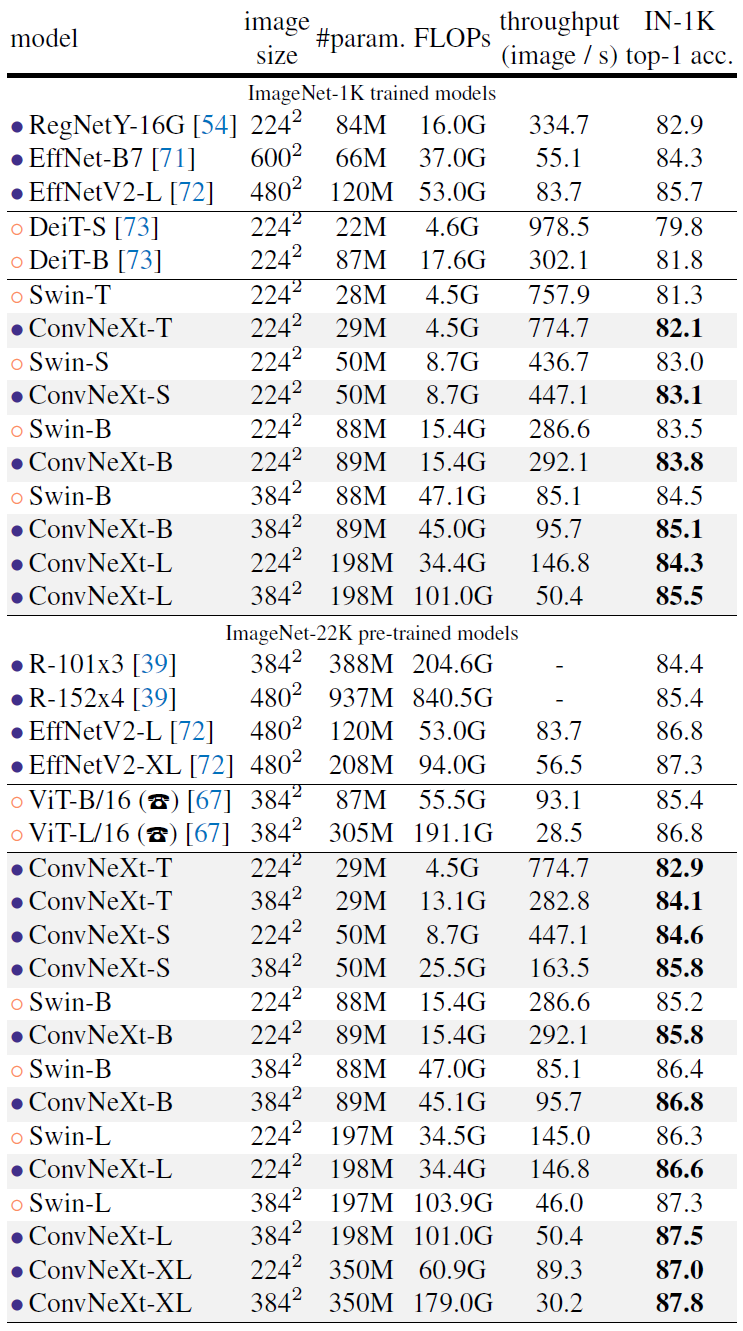
实验结果

若有收获,就点个赞吧
0 人点赞
