Mobile-Former(CVPR2022)
论文:https://arxiv.org/pdf/2108.05895.pdf?ref=https://githubhelp.com
git:https://github.com/slwang9353/MobileFormer/tree/d2f1a0d37a207f102337a61b908122f6e20ddf16
Mobile-Former提出了一种结合MobileNet与极度轻量化Transformer的backbone,使得网络可以同时获得CNN局部纹理特征提取能力与Transformer的全局注意力。论文的核心思想:How to design efficient networks to effectively encode both local processing and global interaction?
网络结构
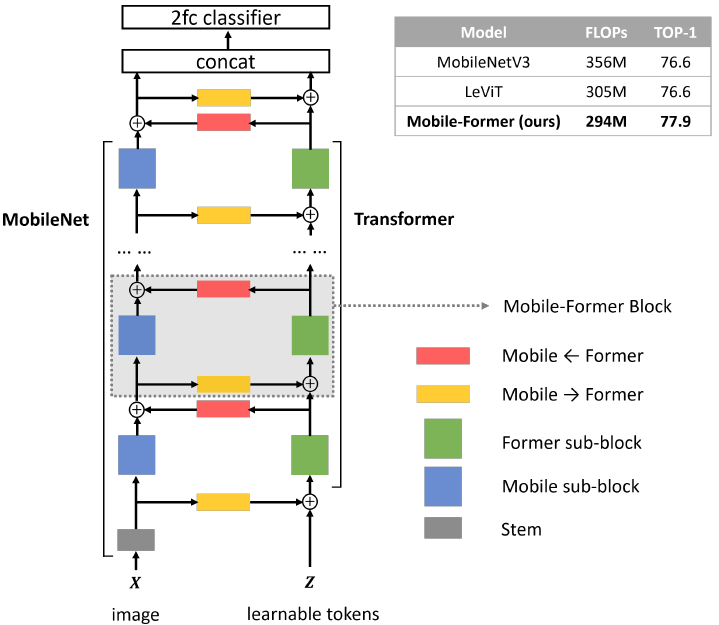
网络结构总览图中,左边分支是MobileNet的网络,右边分支是Transformer,两个分支通过Mobile←Former与Mobile→Former进行双向交互。
在ViT中,序列的长度高达196。而在Mobile-Former中,Transformer分支只是对CNN缺乏的全局信息的补充,在文中作者只取了 的token序列长度,因为非常轻量化。
的token序列长度,因为非常轻量化。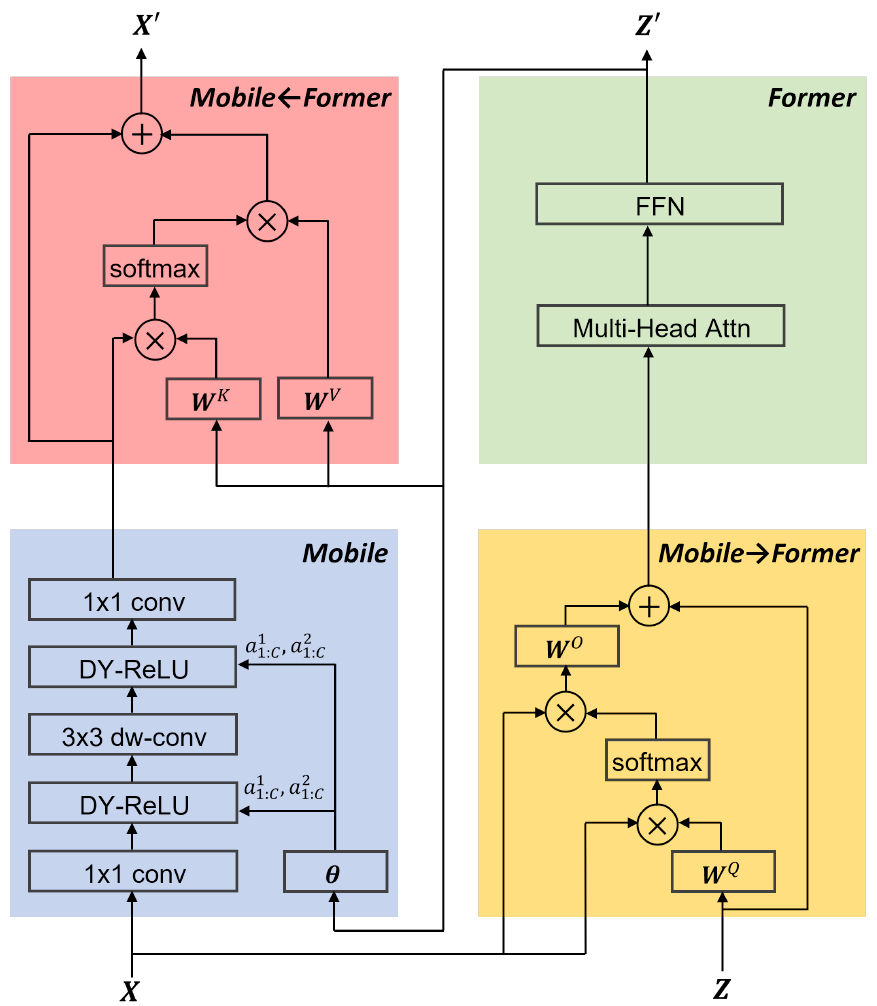
Mobile
其实就是个MobileNet(小参数稍有不同),两个主要区别:
- ReLU6换成了DY-ReLU(两段的斜率从[0,1]变成动态推理的,有点像SE),
 直接取自Former的第一个token,经过两层全连接(
直接取自Former的第一个token,经过两层全连接( )得到
)得到 个通道的两段斜率。
个通道的两段斜率。 - 没有shortcut,论文中也没提,why????
- 下采样是通过在第一个1x1前再接一个3x3s2的DW卷积,而非中间的DW卷积改成s2
Former
Mobile->Former
Mobile2Former其实也是一个Transformer的QKV Self-Attention,其中 是来自于CNN的输入
是来自于CNN的输入 的,且为了节省开销
的,且为了节省开销 被省略,
被省略, 经过重排以后(’B C H W’ -> ‘B H*W C’)被直接当做了
经过重排以后(’B C H W’ -> ‘B H*W C’)被直接当做了 。Mobile2Former的输出为(M d),分别表示序列长度和序列维度。
。Mobile2Former的输出为(M d),分别表示序列长度和序列维度。
Mobile2Former中的 对的数量非常多,但是作为Former数据通路的
对的数量非常多,但是作为Former数据通路的 的数量却很少(
的数量却很少( )因此Self Attention算起来复杂度从
)因此Self Attention算起来复杂度从 降低为了
降低为了 。
。
Former->Mobile
CNN中FeatureMap的每个pixel都作为一个 维的
维的 ,和Former的输出经过
,和Former的输出经过 得到
得到 后算self-attention。解释起来就是检测CNN分支上FeatureMap的每个pixel所响应的Former中的全局信息。
后算self-attention。解释起来就是检测CNN分支上FeatureMap的每个pixel所响应的Former中的全局信息。
实验结果
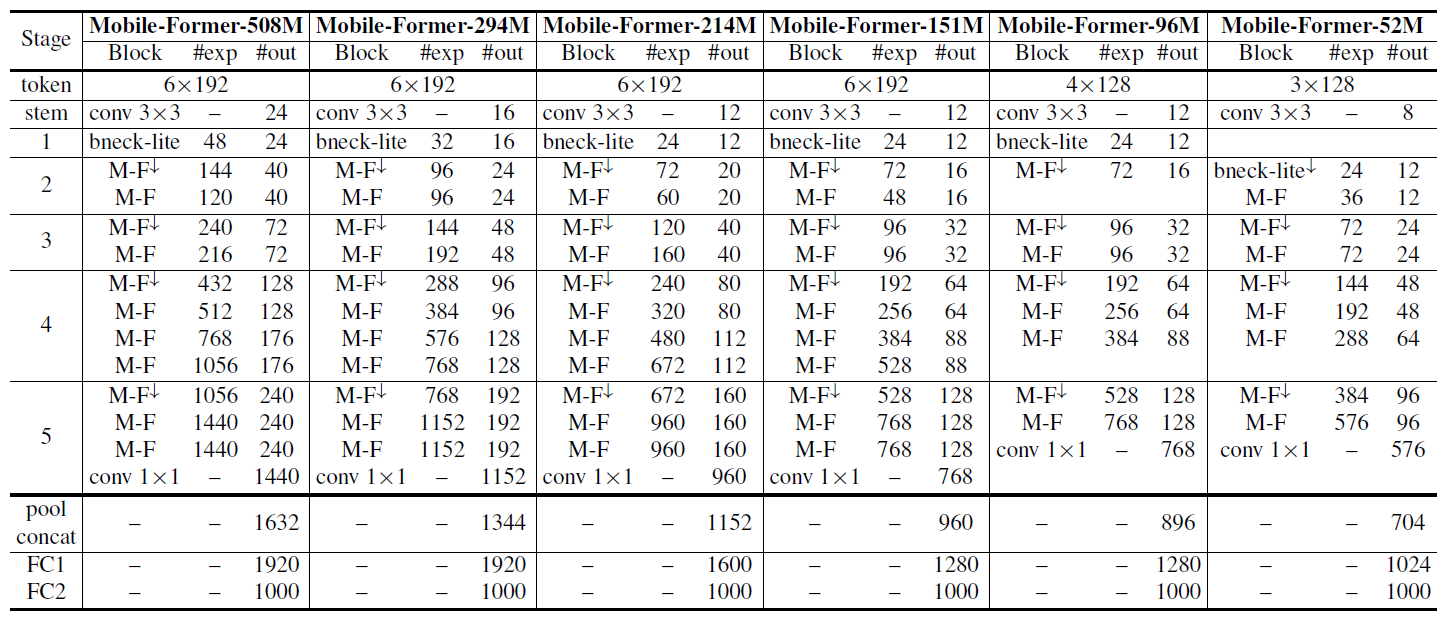
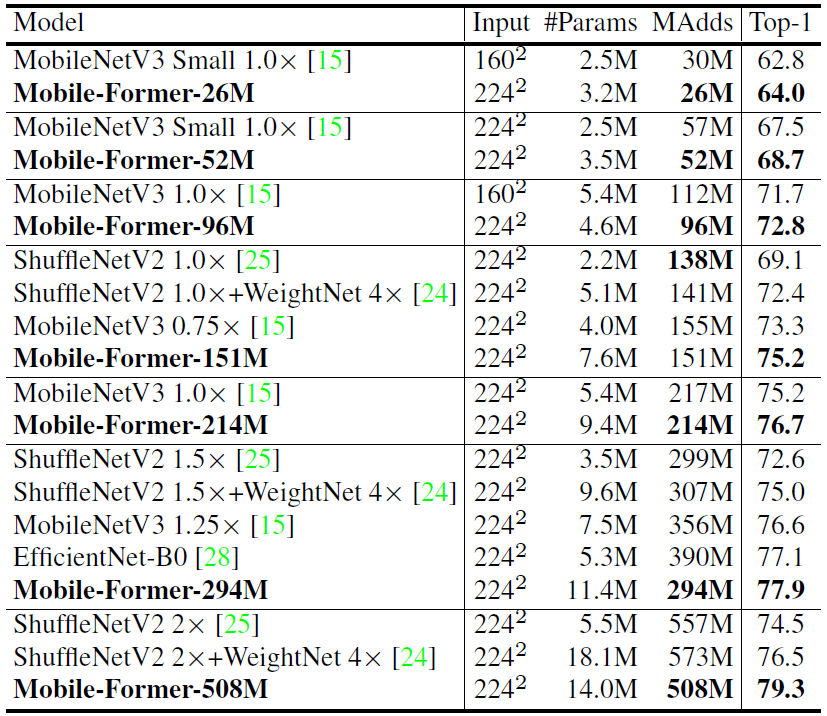
MobileViT
论文:https://arxiv.org/pdf/2110.02178.pdf?ref=https://githubhelp.com
MobileViT同样是为了结合CNN和Transformer的优点,提出了一个轻量化(参数量小),低延迟的通用骨干网络,其整体结构如下图所示。这样的结构利用了CNN的先验,同时对各种trick和数据增强没有那么敏感。作者表示这是第一个能够在naive数据增强下,只在ImageNet上训练到SOTA的ViT(虽然包含了很多CNN成分)
MobileViT相对MobileNet在结构上主要的改动就是stage2、stage3、stage4只留了一个Inverted Bottleneck其它都替换成了MobileViT block。另外激活函数全部使用了swish,expansion=4。
与Mobile-Former的区别在于,Mobile-Former是双分支结构,而MobileViT是单分支,直接将CNN的先验加入了Transformer Block的结构。
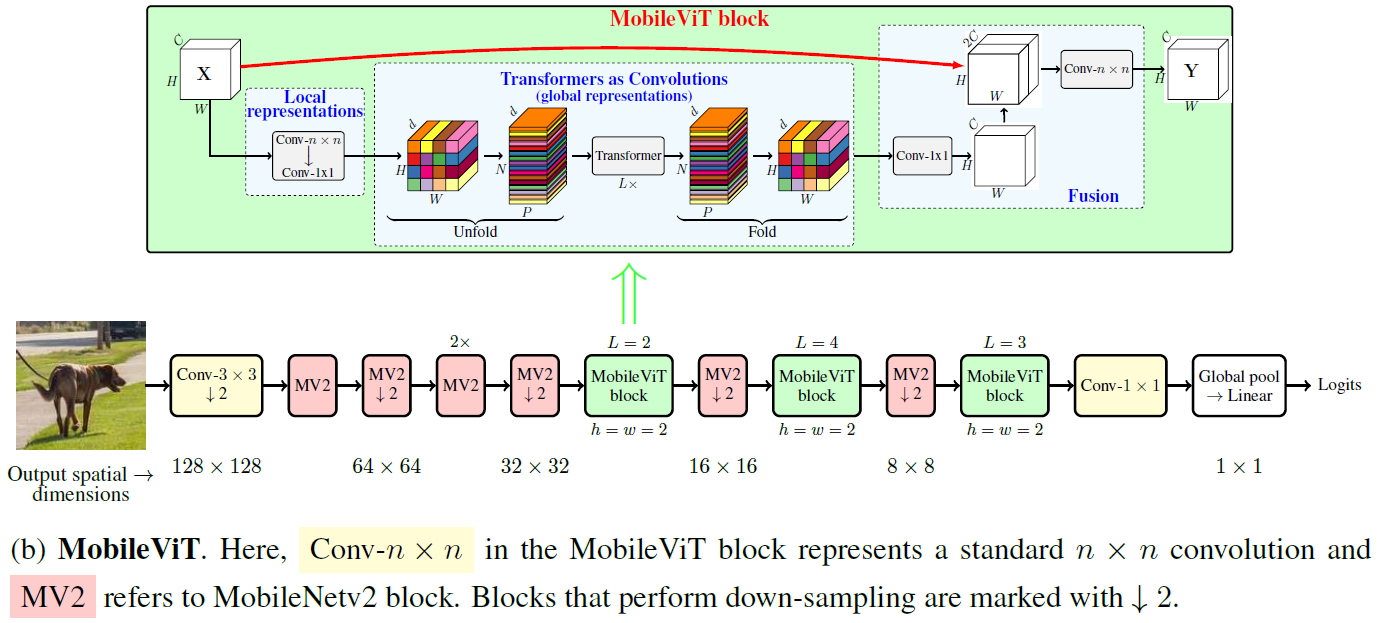
MobileViT block
首先把输入做一次 卷积,使得每个pixel都包含近邻
卷积,使得每个pixel都包含近邻 区域的信息,并通过1x1卷积变通道准备输入Transformer。
区域的信息,并通过1x1卷积变通道准备输入Transformer。
而后进行patch划分,将non-overlapped的 (文中取了
(文中取了 )的像素块划分为
)的像素块划分为 个patch,并在patch间做self-attention。与传统Transformer的self-attention不一样的地方在于MobileViT block保留了patch内的空间信息,self-attention的序列长度为
个patch,并在patch间做self-attention。与传统Transformer的self-attention不一样的地方在于MobileViT block保留了patch内的空间信息,self-attention的序列长度为 ,但一共需要做
,但一共需要做 次(针对patch内对应的相对位置的pixel),有点类似
次(针对patch内对应的相对位置的pixel),有点类似
 的空洞卷积,只不过把卷积替换为了self-attention。如下图所示。(也可以把这理解成
的空洞卷积,只不过把卷积替换为了self-attention。如下图所示。(也可以把这理解成 的self-attention)
的self-attention)

不同于Transformer丢失了空间信息,MobileViT序列化以后是可以直接反序列化成FeatureMap,序列中的每个embed都可以和FeatureMap pixel一一对应。
Multi-Scale Sampler
MobileViT相对传统ViT的一大优势就是,可以接收Multi-Scale的输入而不需要改变position encoding。MobileViT的位置信息是隐含在计算图中的,不需要进行显式的位置编码。
MobileViT在训练阶段,输入分辨率随机从(160,192,224,256,288,320)中取样,推理时用的分辨率为256(为了使得各个stage特征图分辨率都能被patch size整除)。但是训练的时候由于分辨率变了,中间特征图的分辨率不能被patch size整除,因此需要在fold和unfold时做双线性差值(真蠢!!!而且EfficientNet v2说逐渐加大分辨率比随机分辨率好)。
模型结构
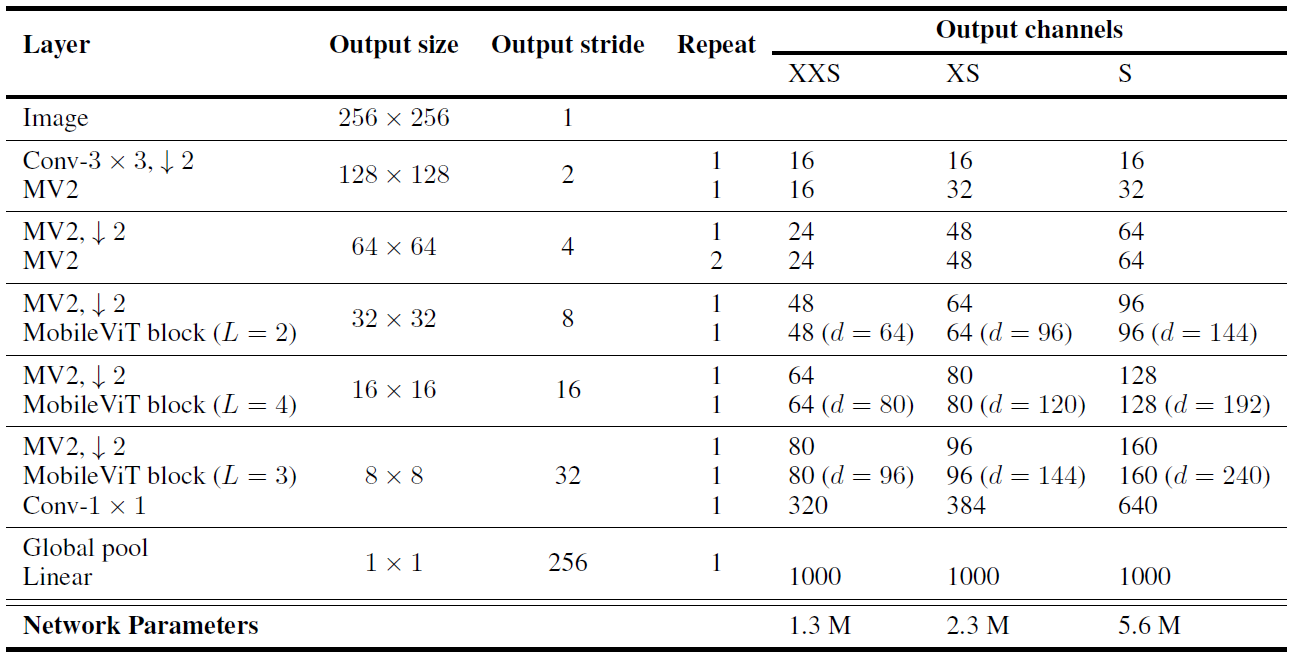
实验结果
在ImageNet上,bs=1024,训了300epoch,优化器为AdamW(warmup0.0002~0.002 3000k steps后余弦退火),smooth-label=0.1,wd=0.01,只用了rand resize crop和随机水平翻转。
实验结果作者几乎是以参数量为唯一比较项的,实际上MobileViT的FLOPS和延时都要大不少,多少有点不厚道……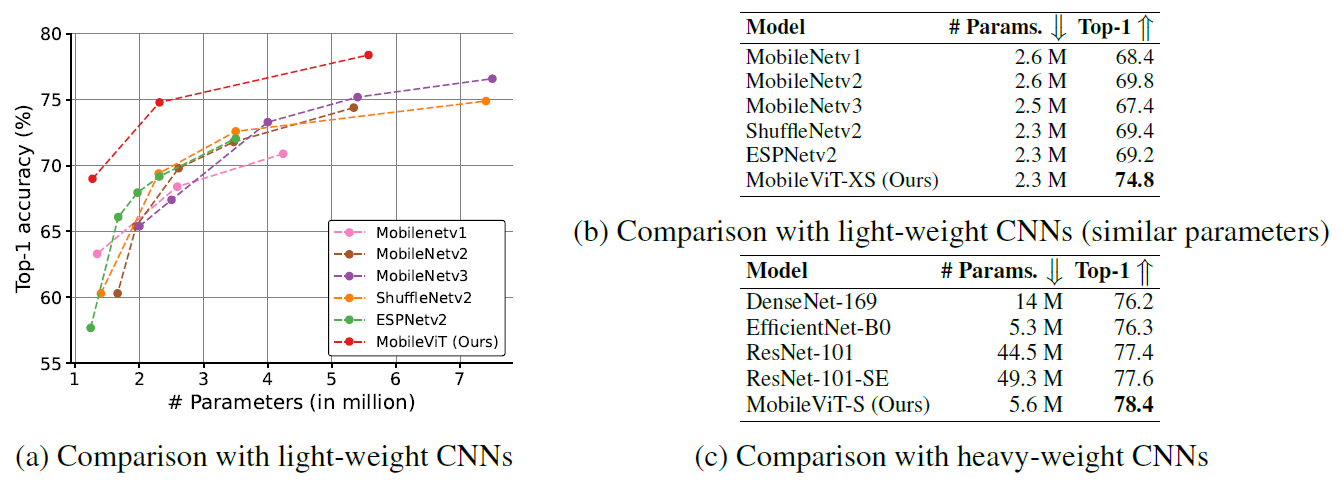
各个stage中Patch大小的影响:
patch大小为3时需要补0,因此慢得多。这也是作者为啥要用256*256作为输入大小的原因!(不过Multi-Scale Sample后不是patch_size=2的时候也成问题么???????????????????)
作者还是选择了patch_size=[2,2,2]而非[8,4,2],毕竟参数量一样准确度高,作者只用参数量比结果更好看。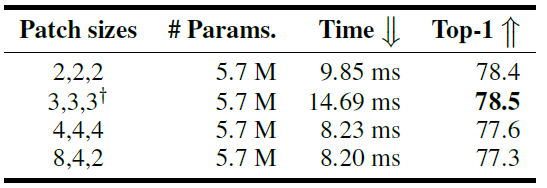
EfficientViT(Arxiv2022)
论文:https://arxiv.org/pdf/2205.14756.pdf
目标:从根源上(而非近似方法)干掉四次方复杂度的self-attention,提高效率并针对大输入分辨率的图像效率明显更优,对下游任务十分友好。
Linear self-attention
参考《Transformers are rnns: Fast autoregressive transformers with linear attention.》中提出的linear self-attention,它去除了传统self-attention的softmax操作,直接将QK线性点积结果作为attention的值。这样做的好处是可以降低self-attention的复杂度: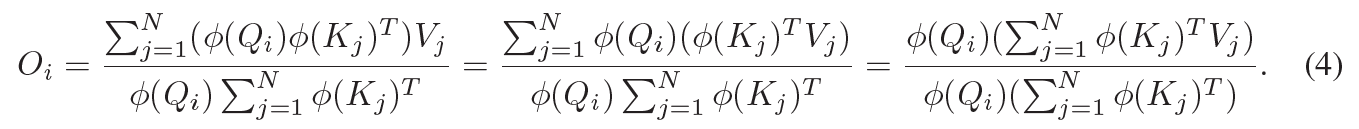
经过“简单”的线性代数变换以后,我们可以把整张图的sigma(K)和sigma(KV)事先算出来,此时复杂度就从(HW)^2降低为了HW。
↑↑↑↑但是这样掉点很严重,作者认为这是因为softmax可以起到抑制非关键点让模型关注关键点的local feature extraction作用: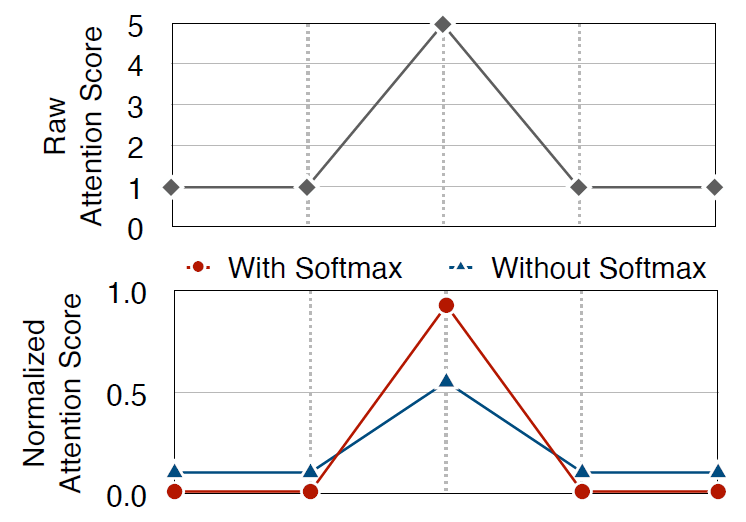
EfficientViT Block
为了缓解linear self-attention带来了local feature extraction的丢失,作者在self-attention中引入了dw卷积。作者表示引入dw卷积以后的linear self-attention的表现甚至比softmax更好。
另外这个dw卷积替代了position embedding的作用,不再需要resolution-dependent的relative PE了。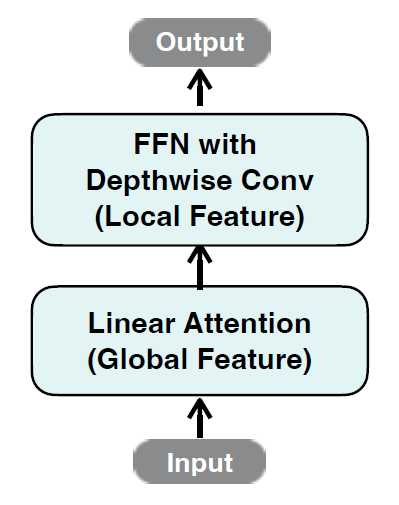
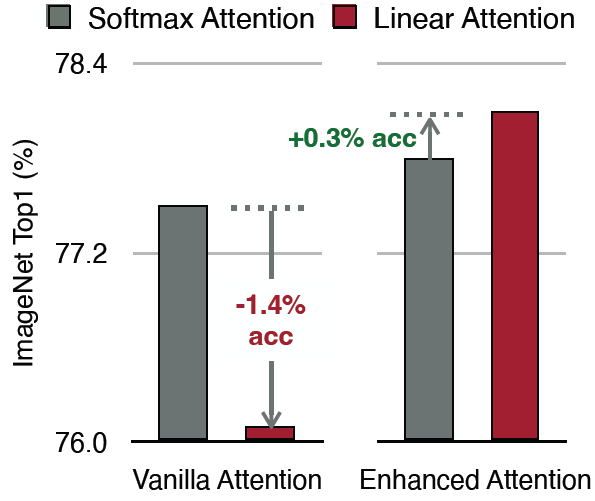
得益于linear self-attention的线性复杂度,EfficientViT在处理大分辨率输入与下游任务时就会好得多。
实验结果
ImageNet结果只是冰山一角,毕竟EfficientViT最大的优势是大分辨率输入。作者使用巴拉巴拉的tricks,AdamW优化器,训了450-epochs,bs=2048。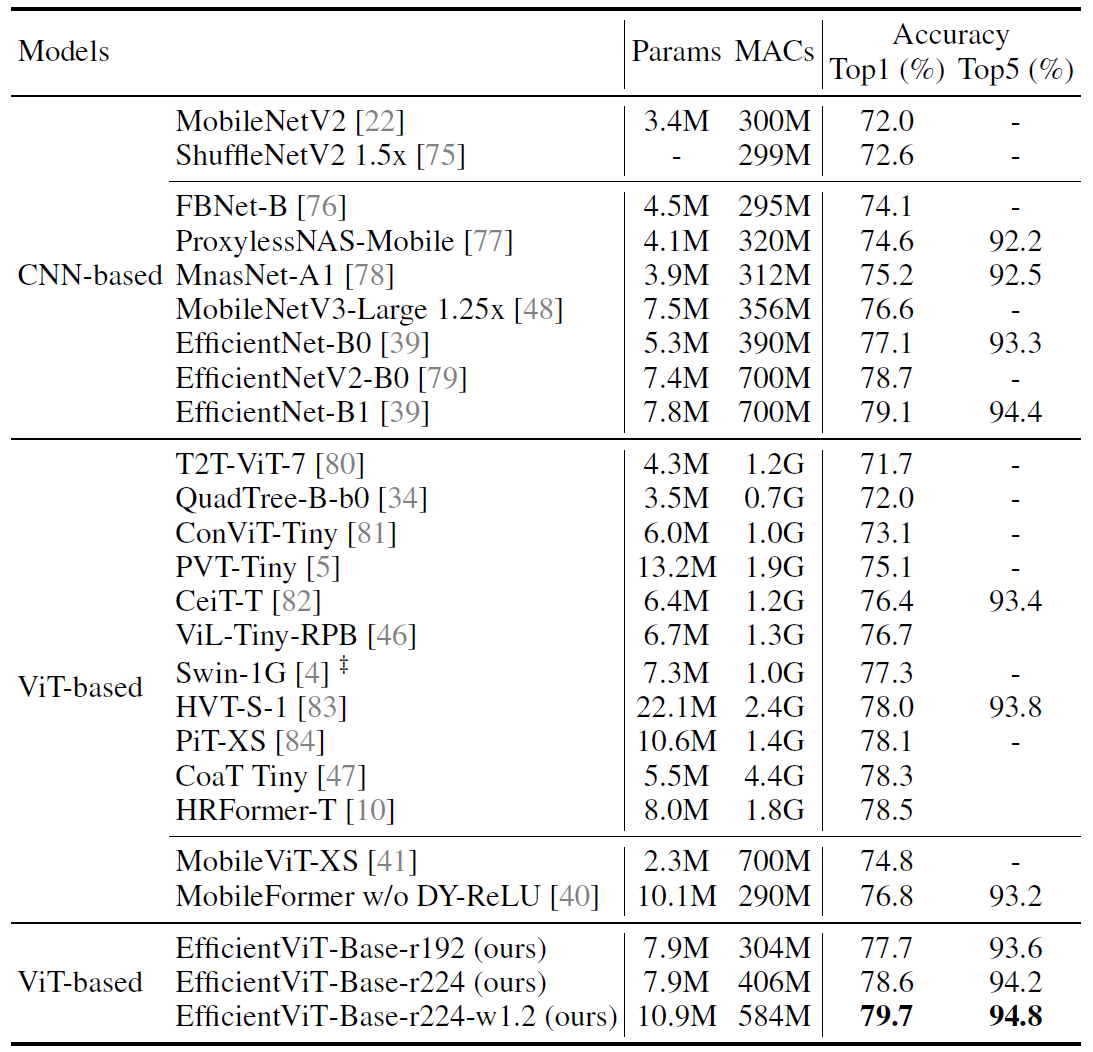
COCO!ddd ddd ddd ddd ddd ddd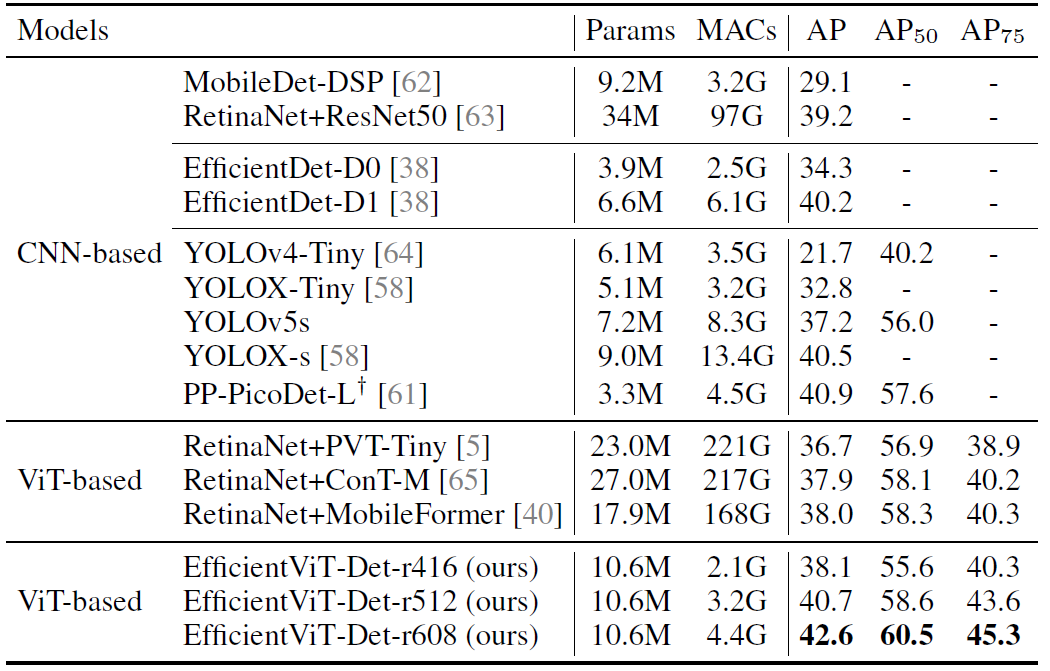
PoolFormer
论文:https://arxiv.org/pdf/2111.11418.pdf
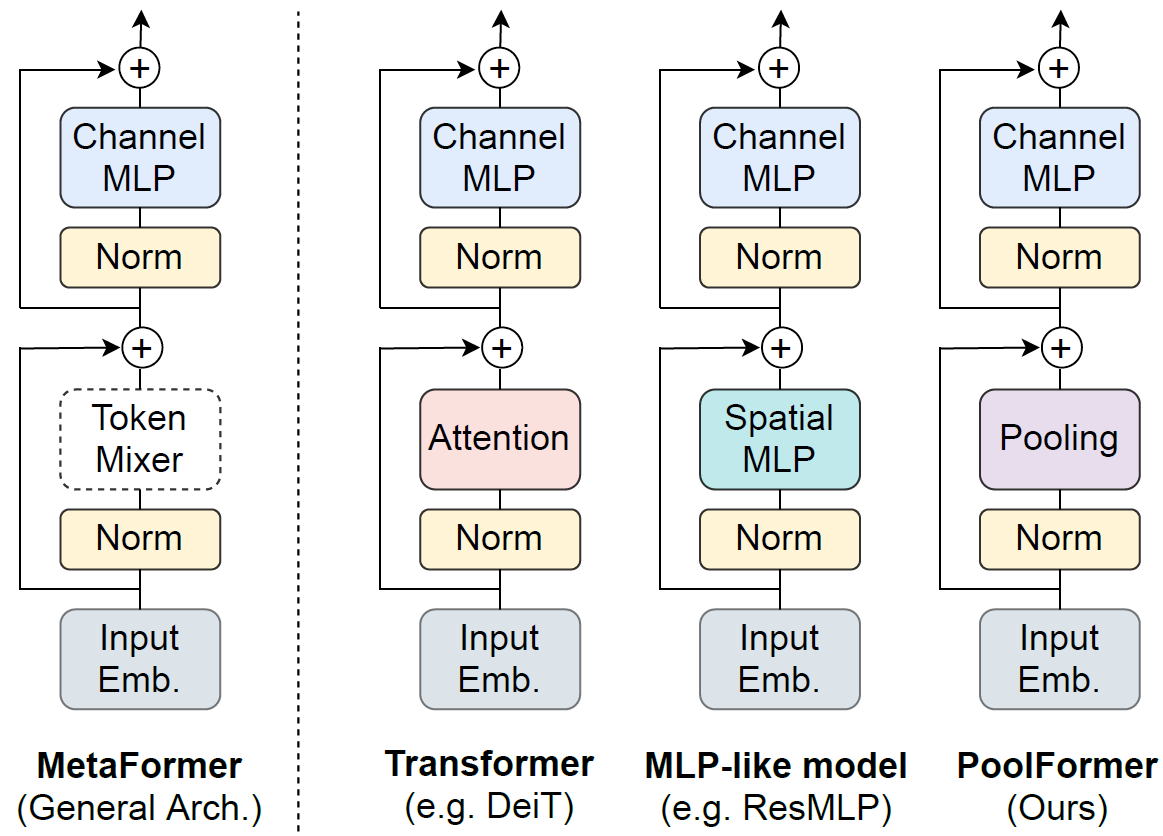
作者发现只要符合下面MetaFormer结构的网络似乎都能表现的很好,因此把Token Mixer部分简化为了一个K3S1的AvgPool发现效果依然不错?!?!
这篇论文的思想是在太简单了以至于我都不知道笔记怎么记了hhhh~
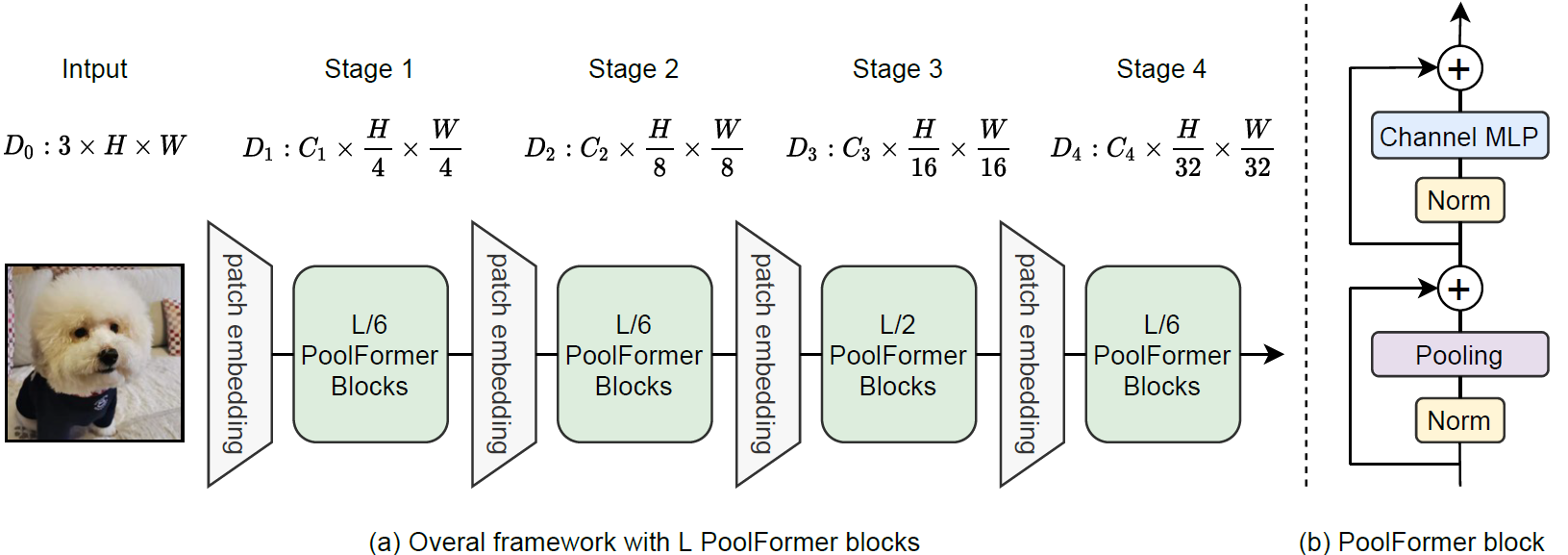
网络结构
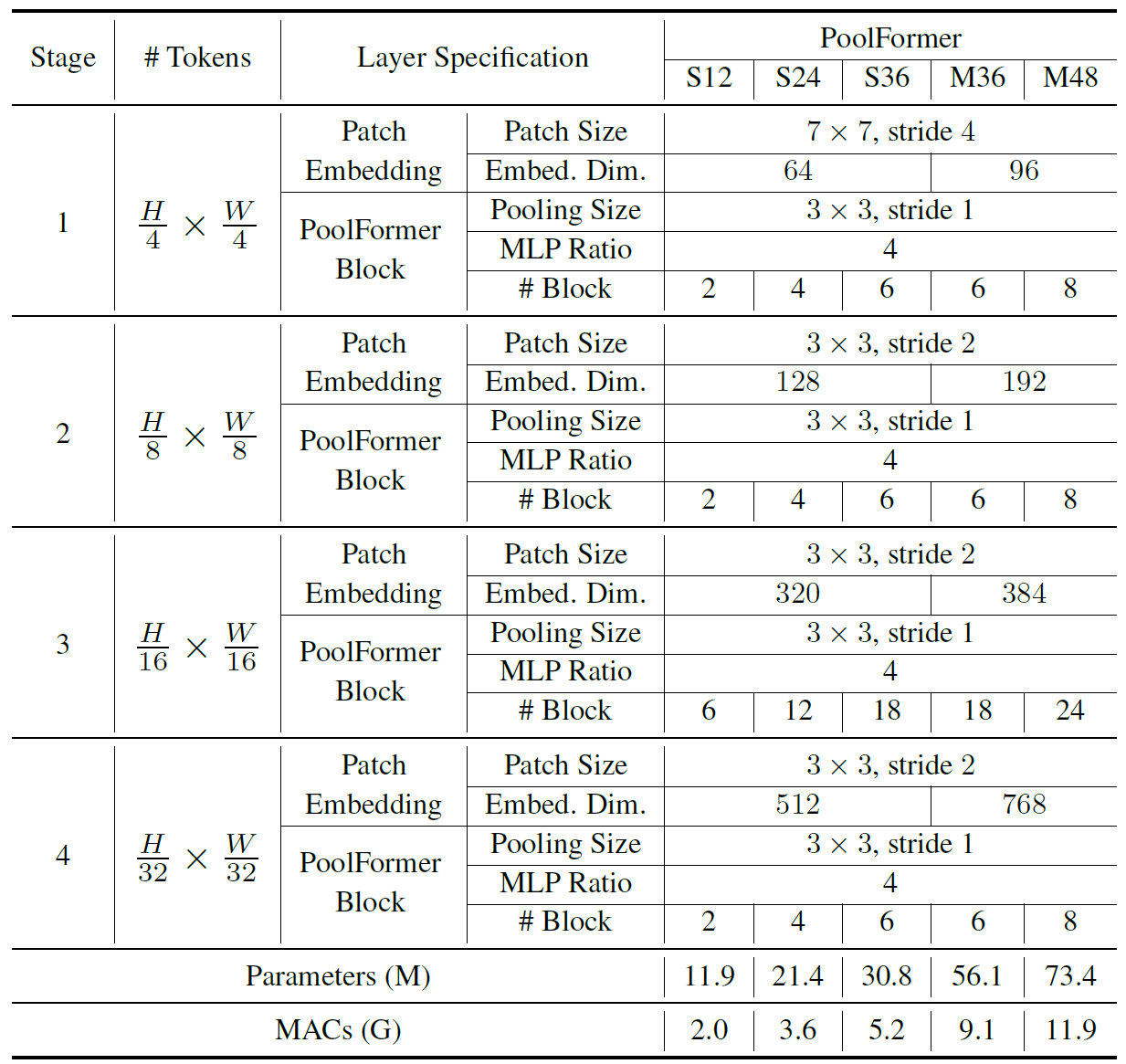
实验结果
ImageNet还是熟悉的一大堆trick+300epoch+AdamW+Cosine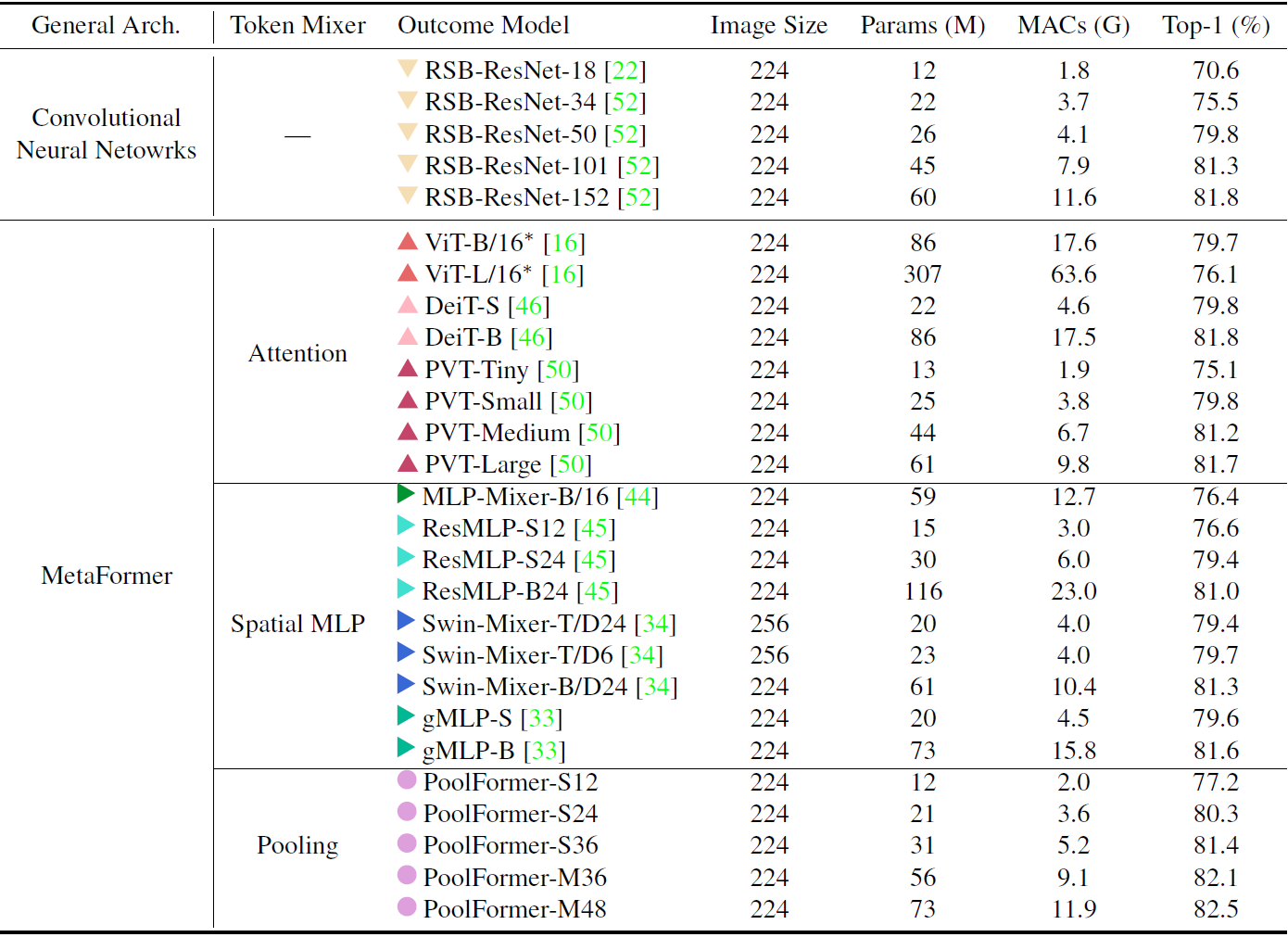
Ablation里比较神奇的是把pool也丢掉(全程1x1卷积的网络???)也能有74.3。pool是提取局部特征的,窗口大了会盖掉局部信息,会掉点也理所应当。
PoolFormer都是用GN效果更好!!!
深层换用传统的self-attention会涨点!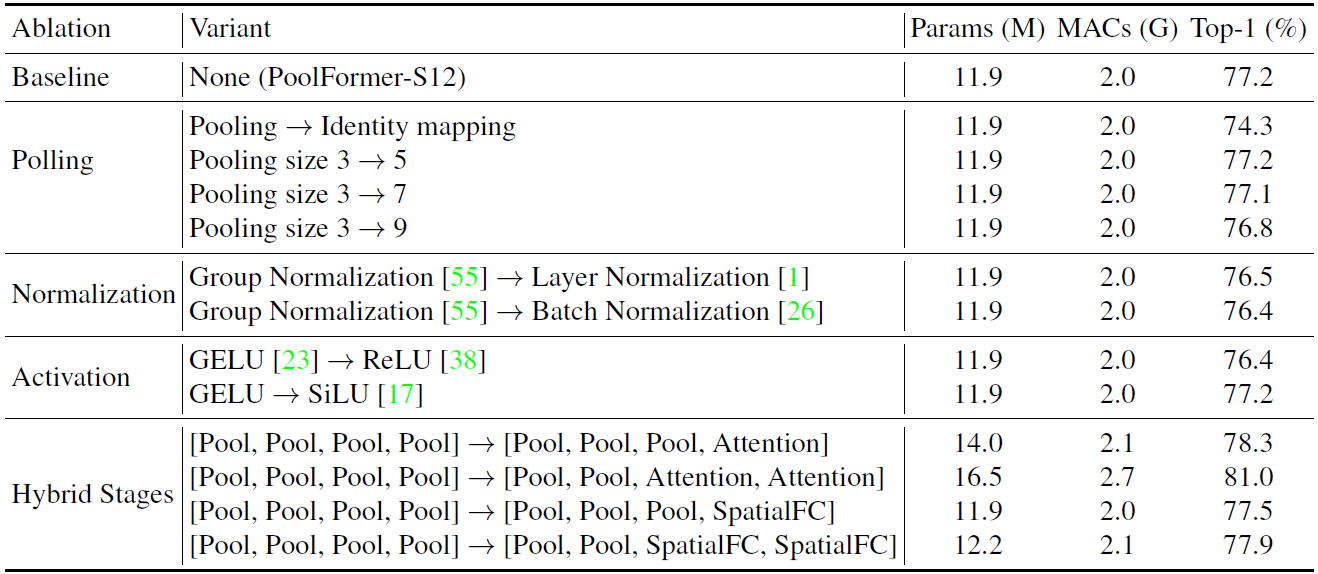
EfficientFormer(CVPR2022)
论文:https://arxiv.org/pdf/2206.01191.pdf
基于实际推理延迟,提出了一套在iPhone12上跑得比香港记者还快的纯attention结构ViT(除了stem部分没有用卷积)。
Inefficient Designs
iPhone12推理延迟: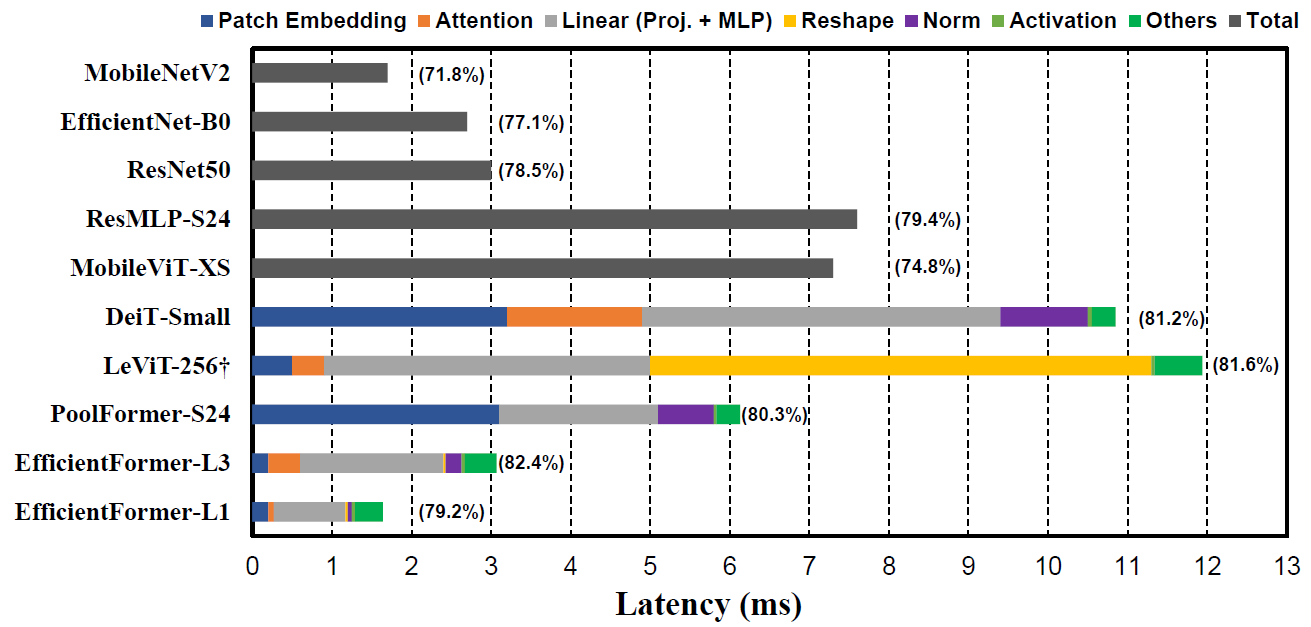
- 大核Patch Embedding (stem)
从上图可以看出,K16S16的DeiT与K7S4的PoolFormer在实际推理时都在Patch Embedding花费了相当的开销。作者认为用两个K3S2的卷积作为stem更高效。
- 频繁的4D-3D特征图reshape
从上图可以看出,频繁进行4D-3D特征图reshape的LeViT在reshape上花费了聚!!!!大的开销,另外至少对224*224的输入来说,MHSA部分的开销并非效率瓶颈。
- Conv1x1+BN比LN+Linear高效因为BN可折叠
LN引入的推理延迟占到了10%-20%,且把LN+Linear换成Conv1x1+BN的性能损失有限。
- 激活函数(这个非常强的hardware-dependent没啥用)
网络结构
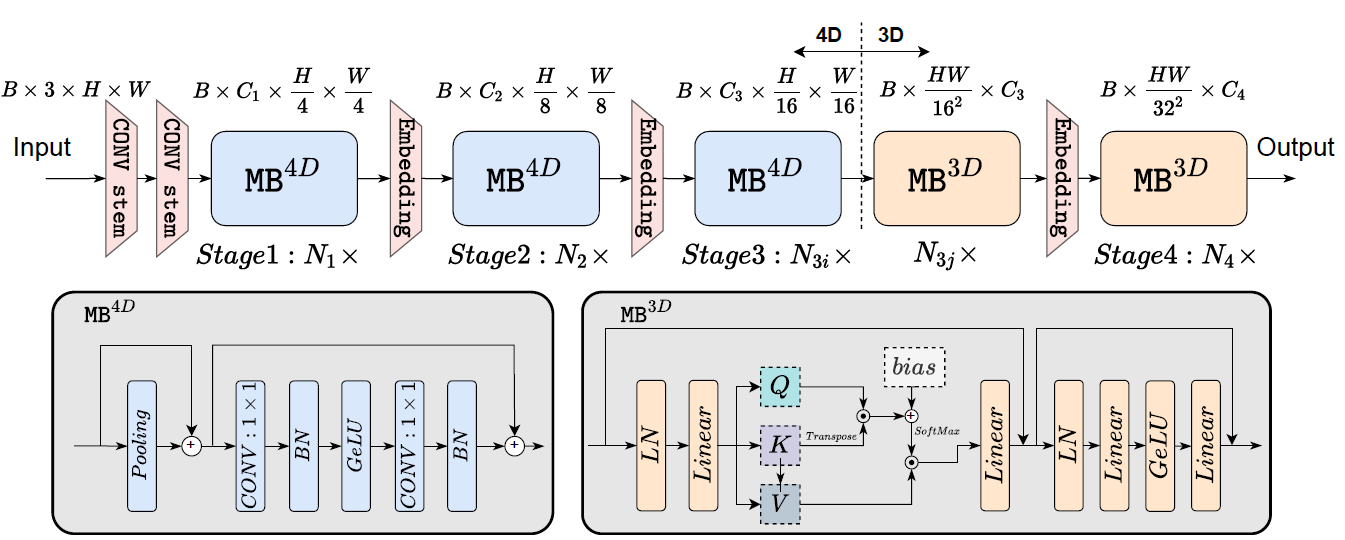
(MB:MetaBlock)
stem部分用了两个K3S2的卷积,backbone部分主要采用了两种结构,在浅层使用了PoolFormer的Block并把MLP换成了Conv1x1+BN,深层使用传统的MHSA(带类似Swin的相对位置编码)。
具体的网络宽度和哪些stage堆叠MB-4D/MB-3D是NAS搜出来的。
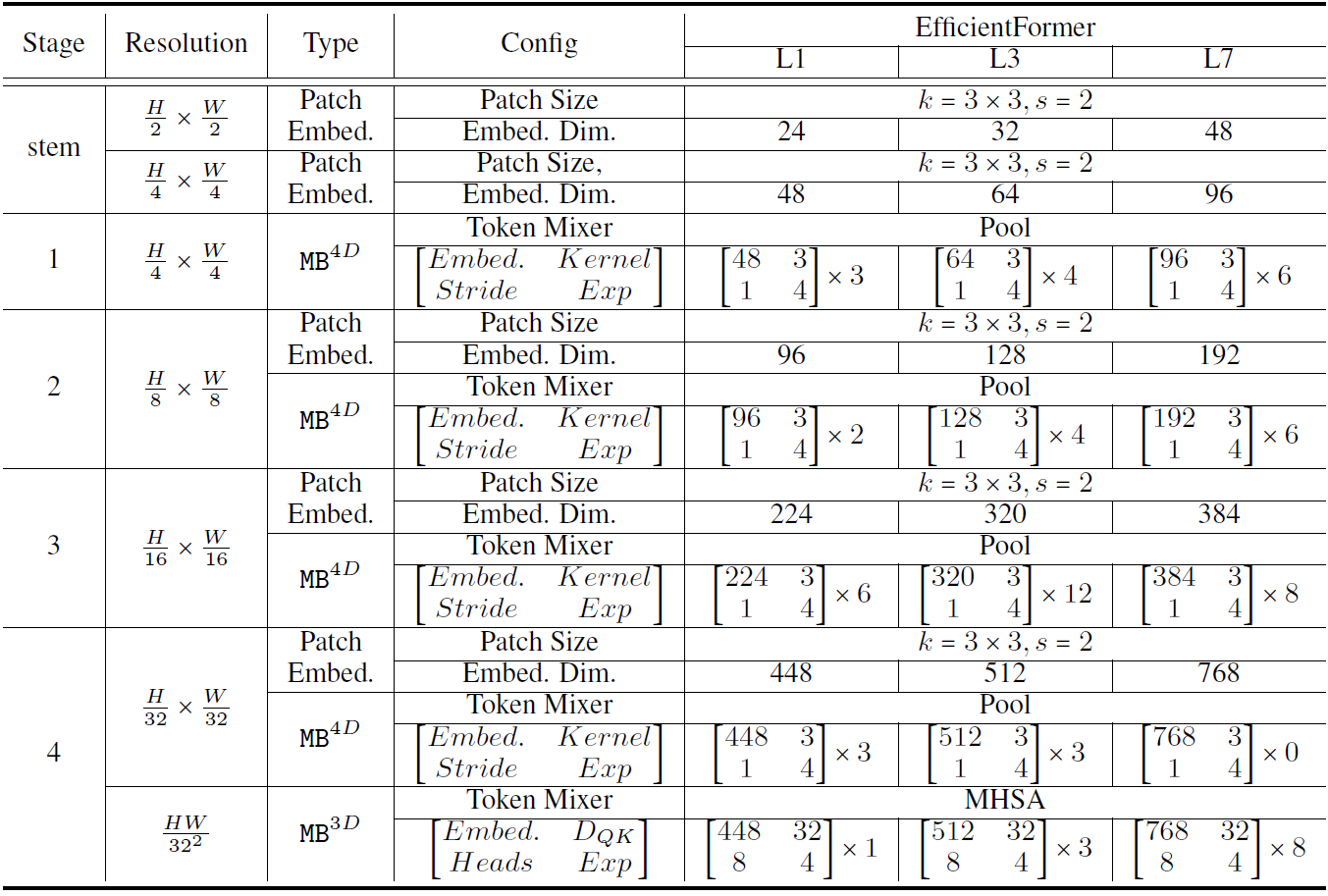
实验结果
作者加了个RegNetY-16GF用来蒸馏所以点更高吧,schedule也和DeiT一样只不过没训1000epoch只训了300epoch。常见的AdamW,lr=1e-3,bs=1024,cosine。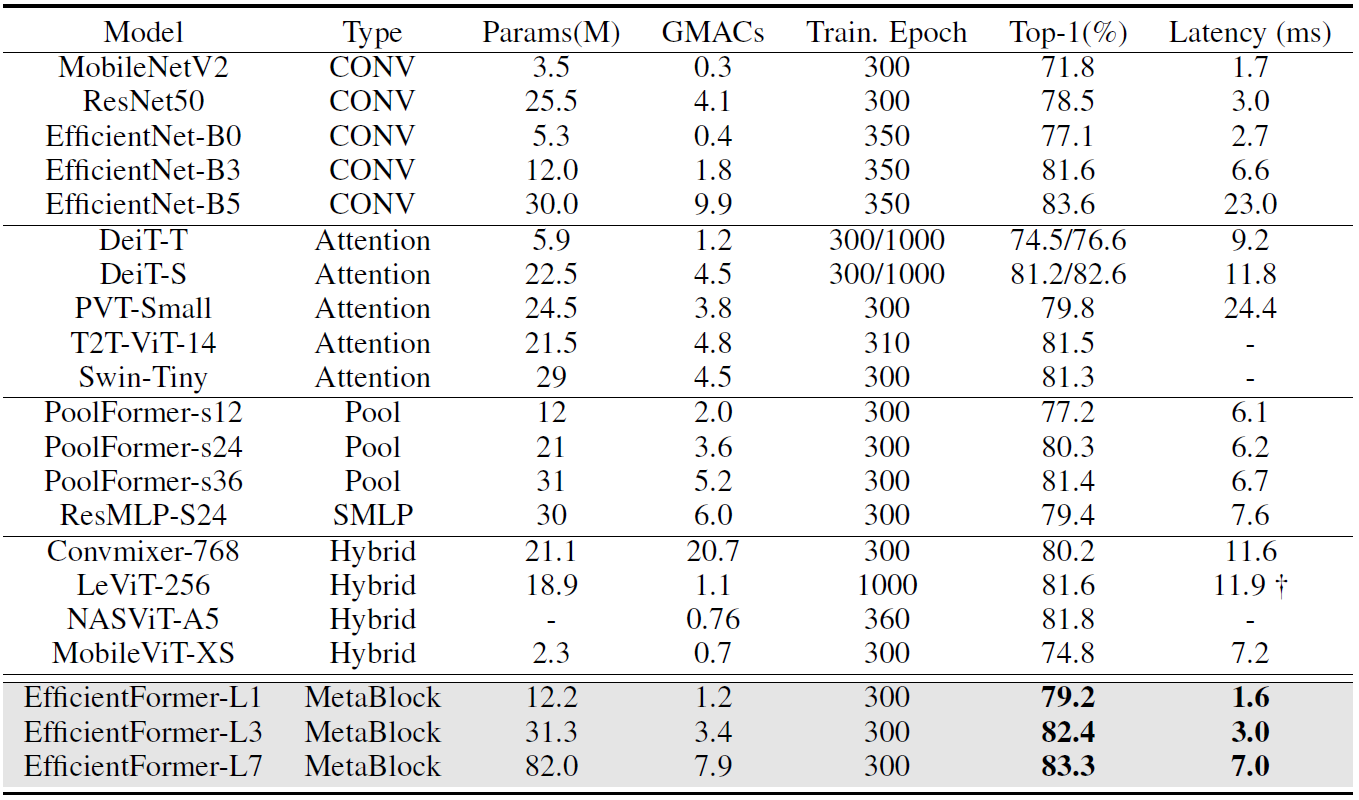
浅层的感受野明显小了,有点担心下游任务的性能,这里COCO也只和PoolFormer和ResNet比了。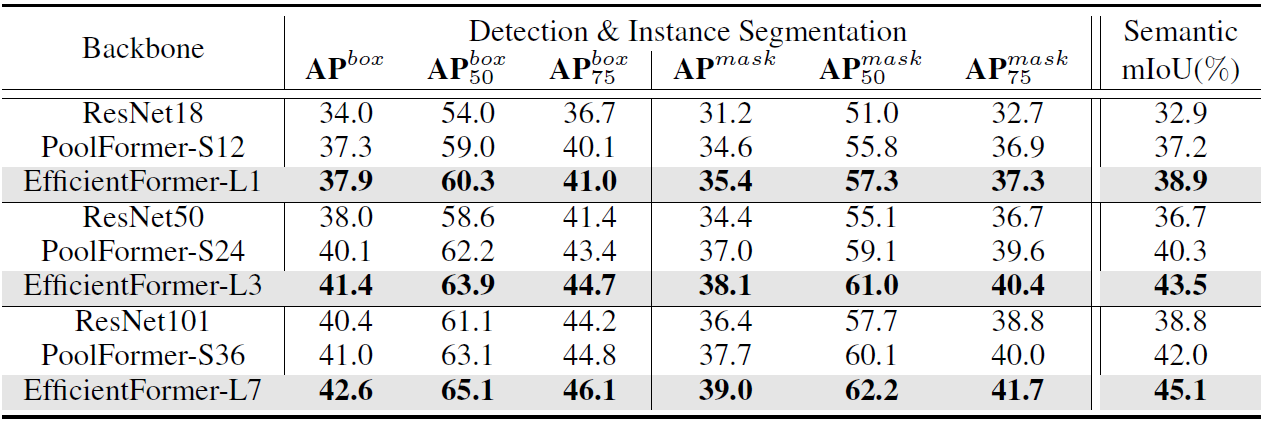
没有MHSA就是退化为PoolFormer,深层也没有MB-3D的MHSA。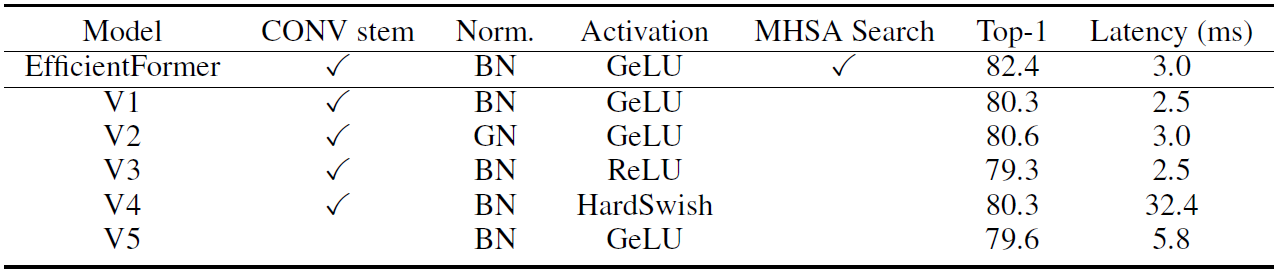
CNN Stem
论文:《Early Convolutions Help Transformers See Better》
https://arxiv.org/pdf/2106.14881.pdf
OpenReview:https://openreview.net/forum?id=Lpfh1Bpqfk
核心思想:把ViT中stem部分的K16_S16的patch化卷积替换成4个K3_S2的卷积+1个变通道的K1_S1卷积能够提点,还能增强模型对超参、优化器、数据增强的鲁棒性。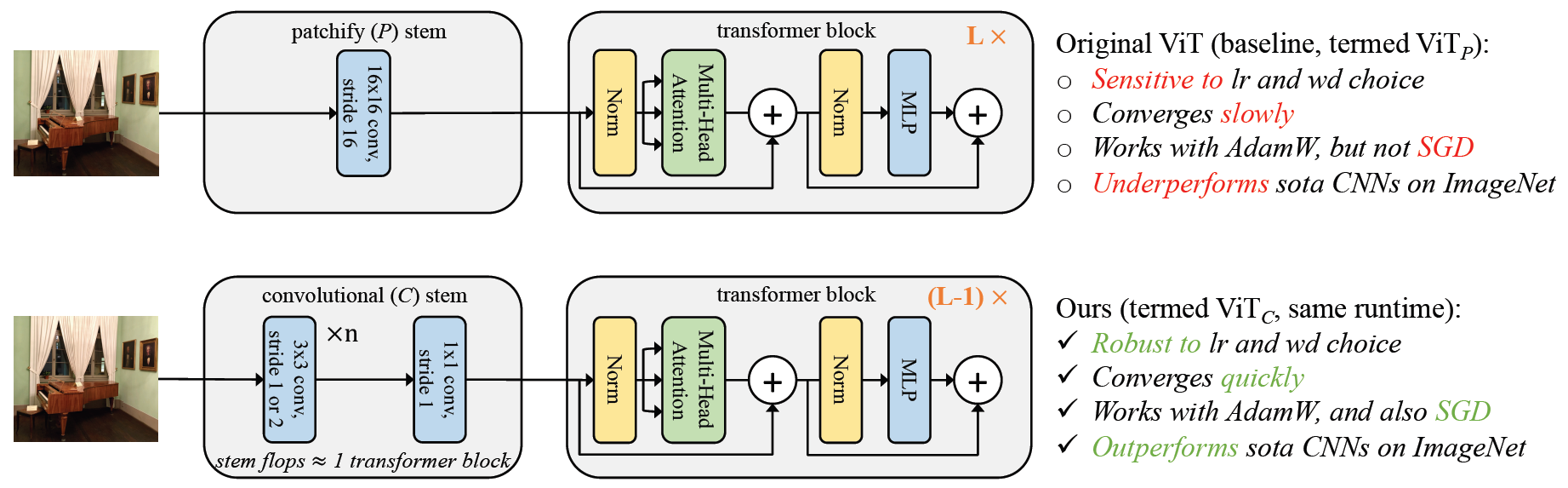
不同训练Epoch数: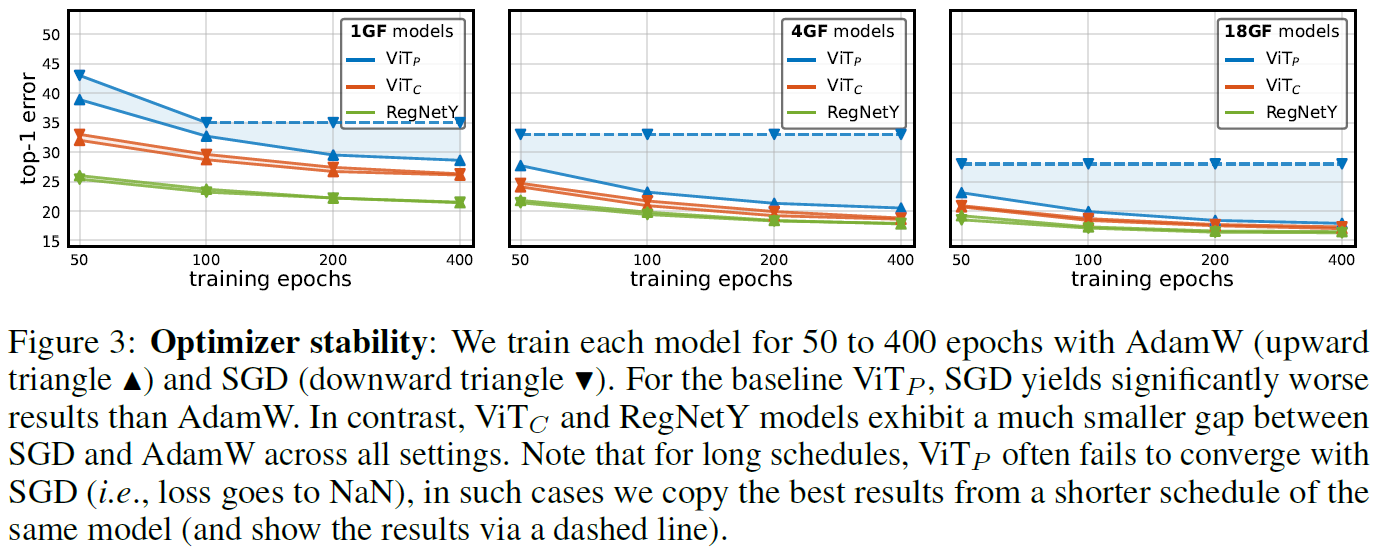
不同超参: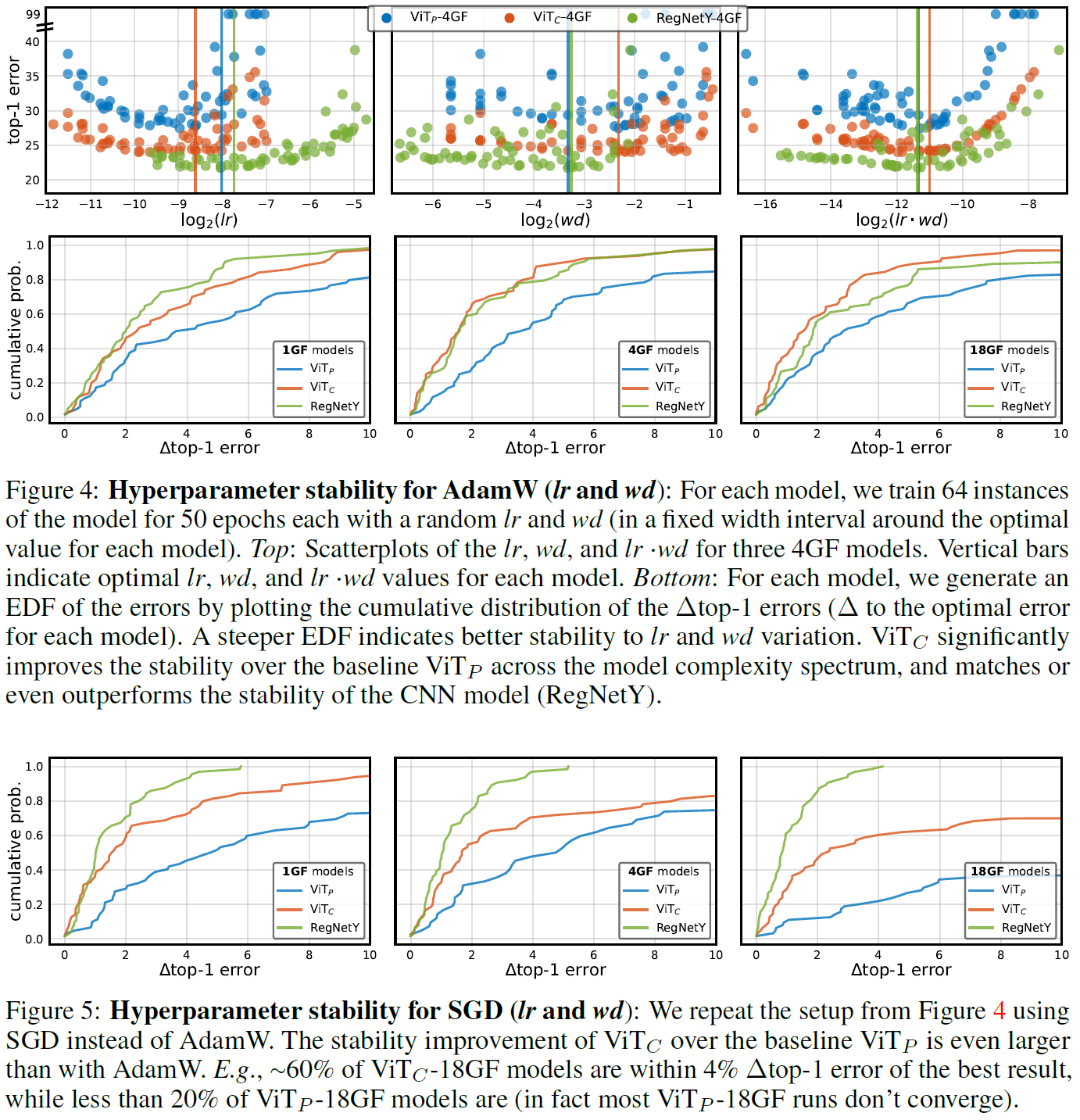
不同stem设计(3x3卷积+ViT的patch化)
实验结果
400epoch,AdamW,lr=1e-3,wd=0.24,mixup+cutmix+label-smoothing+AutoAugment
不同epoch数使用的config相同
ViT-36GF使用了lr=6e-4,wd=0.28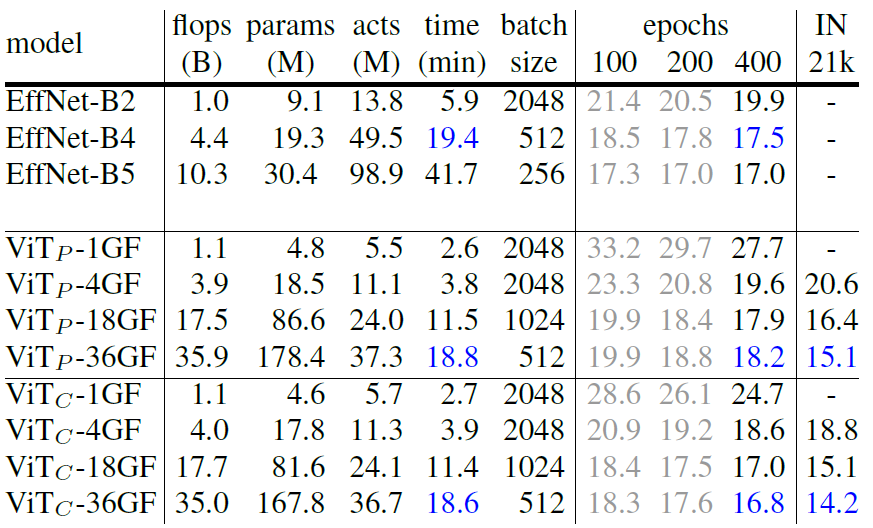
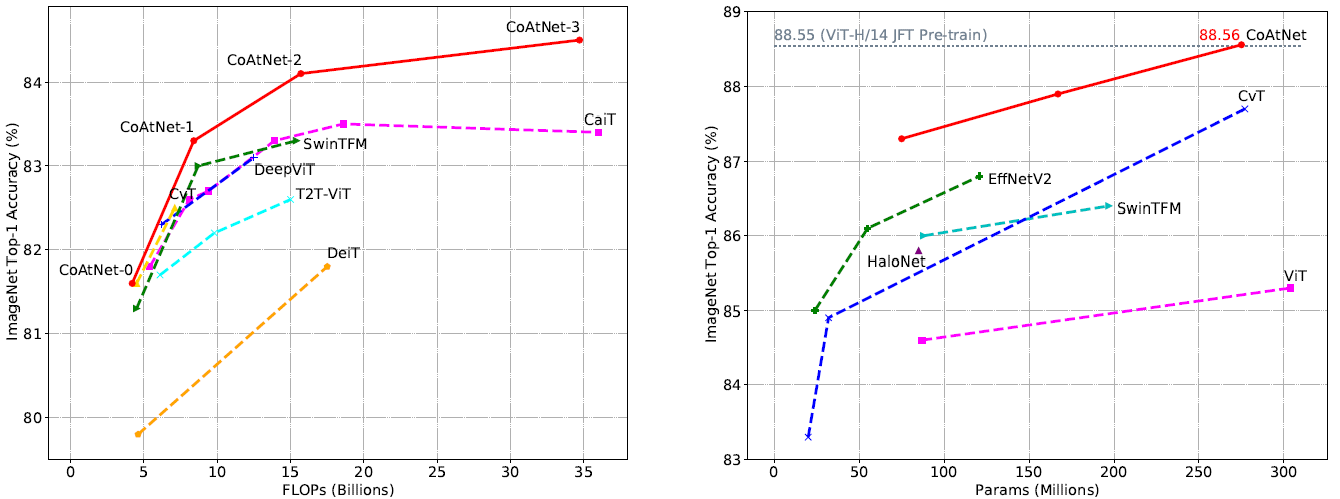
CoAtNet(NIPS2021)
论文:https://arxiv.org/pdf/2106.04803.pdf
github:https://github.com/chinhsuanwu/coatnet-pytorch
CoAtNet是把卷积核直接加到了QK AttentionMap上再算softmax,但感觉和Swin Transformer里的相对位置编码完全一样哇!(确实是一样的作者在related work里说了,只不过Swin是在window里做的)
模型结构
DW卷积与Attention
- DW卷积的权重是静态的,而Attention的权重是根据输入动态推理得到的。因此Attention可以捕获到更加高级的语义特征,但是由于缺失了先验,更加容易过拟合。
- DW卷积只关注卷积核窗口内像素的相对位置,而不是ViT(使用绝对位置编码)中绝对位置,因此拥有平移不变性。诸多工作表明平移不变性可以在数据有限时提高模型的泛化能力。
- Attention拥有全局感受野。

为了融合所有的3个优点,作者决定强行把DW卷积和Attention揉到一起。
DW Conv:( 为卷积核窗口范围)
为卷积核窗口范围)
Attention:( 为整个特征图)
为整个特征图)
作者提出的两种融合方法:

前者为把静态权重加到AttentionMap上,后者则是将静态权重加到QK-Attention中以生成AttentionMap,作者使用了后者。(这到底和Swin Transformer的相对位置编码有什么区别???没有区别!)
Stage设计
CoAtNet也是有层级结构的,但是徐彬的外婆都知道对浅层stage中112112、5656这么大的FeatureMap做Attention序列长度会爆炸长(Swin Transformer是采用了窗口化Attention的方法进行分治)。作者提出了三种解决方案:
- 当下采样至FeatureMap足够小时再做Attention;
- 强制Attention的范围缩小至一个局部范围(类似卷积);
- 将传统的O(L^2)复杂度的Attention替换为O(L)的快速算法。
作者尝试了(3)但是没有得到好的效果,使用(2)又会在大量reshape等操作上耗费时间,因此还是决定用(1)。作者尝试了5种结构:
- ViT_rel:iT的原始结构,直接在stem部分做16倍下采样
- C-C-C-C:层级结构,4个stage分别为(Conv,Conv,Conv,Conv)
- C-C-C-T:层级结构,4个stage分别为(Conv,Conv,Conv,Transformer)
- C-C-T-T:层级结构,4个stage分别为(Conv,Conv,Transformer,Transformer)
- C-T-T-T:层级结构,4个stage分别为(Conv,Transformer,Transformer,Transformer)
对于generalization,即泛化能力、鲁棒性(train和valid的准确度差异),有:
C-C-C-C C-C-C-T
C-C-C-T  C-C-T-T
C-C-T-T C-T-T-T
C-T-T-T ViT_rel
ViT_rel
对于capacity,即模型拟合超大型数据集的能力(JFT300M),有:
C-C-T-T C-T-T-T
C-T-T-T ViT_rel
ViT_rel C-C-C-T
C-C-C-T C-C-C-C
C-C-C-C
因此作者最终还是选择了C-C-T-T结构,即只有1414和77上用Transformer
模型Family

MBConv全部用了SE,expansion=4;所有head宽度都为32只有head数不同。
另外为了统一性,作者在整个网络中都用了ResNet v2中的Pre-Activate结构,并把激活函数改成了GELU。另外作者表示在CoAtNet中,MBConv Block中使用LayerNorm和BatchNorm性能一样。
Transformer中下采样通过maxpool实现(Shortcut里要再加个变通道的1x1),而MBConv的下采样从3x3DW移到了第一个1x1。作者表示这样虽然会让小模型掉点但是更快,能更好trade-off。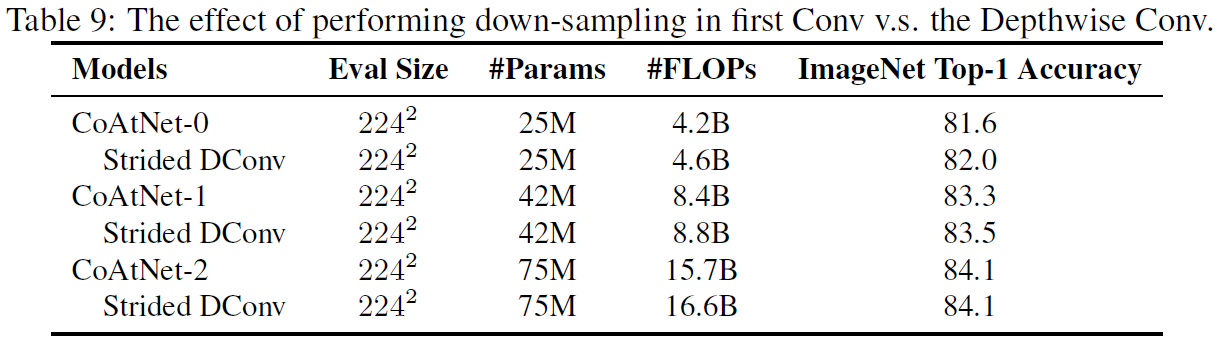
实验结果
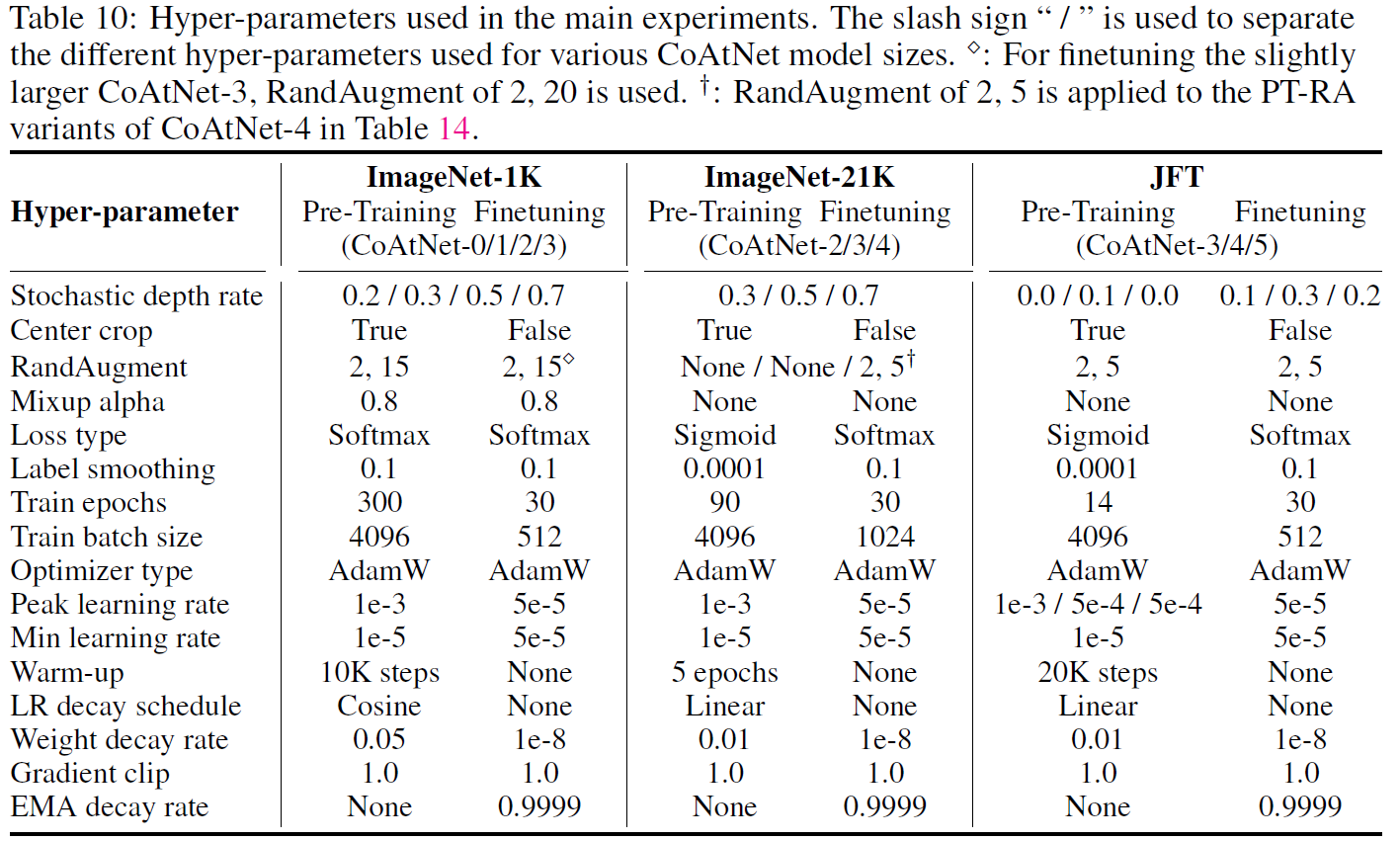
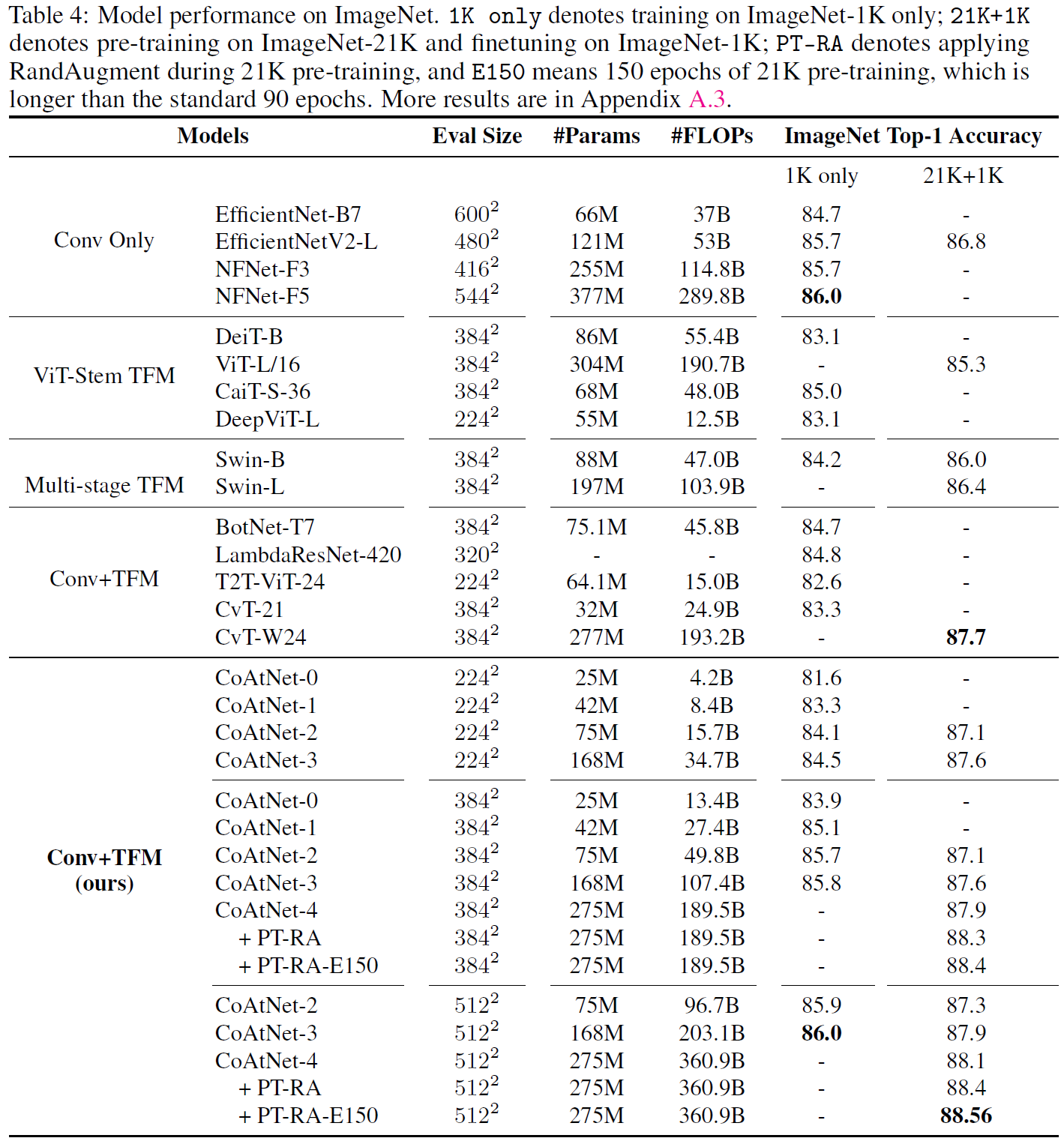
这里的Relative Attention就是Attention里的静态w,也就是swin里的相对位置编码: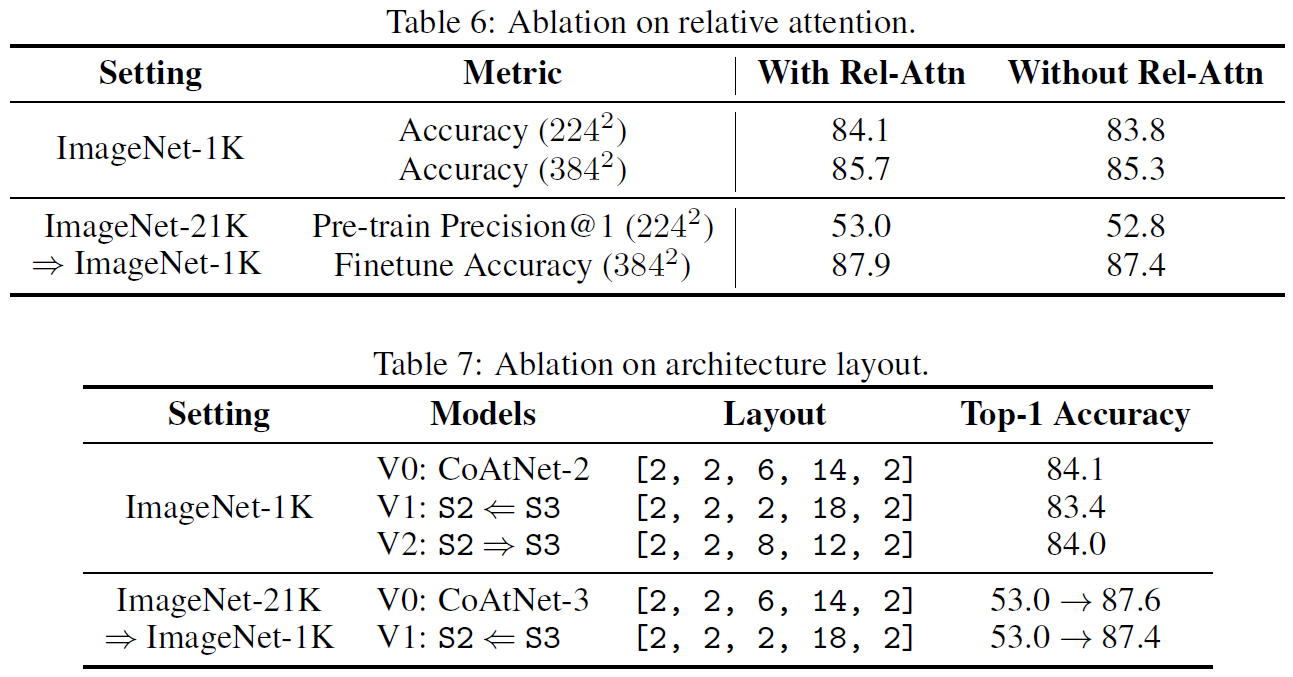

若有收获,就点个赞吧
0 人点赞
