Tensor
Tensor的类型
ByteTensor(uint8)
CharTensor(int8)
ShortTensor(int16)
IntTensor(int32)
LongTensor(int64)
HalfTensor(float16)
FloatTensor(float32)
DoubleTensor(float64)
Tensor(float32)
可使用data=data.byte()等转换类型
Tensor的定义
torch.Tensor(2,3,4) # 生成一个2*3*4大小的Tensortorch.Tensor([[1,2,3],[4,5,6]]) # 从list生成Tensortorch.zeros(2,3,4) # 生成一个2*3*4大小的全零Tensortorch.ones(2,3,4) # 生成一个2*3*4大小的全一Tensortorch.full([2,3],0.5) # 生成一个2*3大小的,全部用0.5填充的Tensortorch.eye(3) # 生成一个3*3大小的,单位对角Tensortorch.arange(0,10,2) # 类似于range()生成list,生成包含0,2,4,6,8的LongTensortorch.linspace(0,10,4) # 生成最小数为0、最大数为10的、长度为4的,等分Tensor# >>> [0.0, 3.3, 6.7, 10.0]torch.rand(2,3) # 生成一个2*3大小的,在[0,1]区间上均匀分布的随机Tensortorch.randn(2,3) # 生成一个2*3大小的,0均值、1方差的标准正态分布随机Tensortorch.randint(-10,10,[2,3,4]) # 生成一个2*3*4大小的,[-10,10]上均匀分布的LongTensortorch.randperm(10) # 将0~9这10个数字乱序输出为一个Tensor, 常用于下标索引x = torch.cuda.FloatTensor(shape) # 用GPU生成随机数torch.rand(shape, out=x)x = torch.Tensor(8,256,14,14)torch.masked_select(x, x>0.5) # 找出img中所有大于0.5的值,合并到一个一维Tensor中
Tensor的复制
| # Operation | New/Shared memory | Still in computation graph |
|---|---|---|
| tensor.clone() | New | Yes |
| tensor.detach() | Shared | No |
| tensor.clone().detach() | New | No |
Tensor与Numpy的转化
x = torch.Tensor(2,3)y = x.numpy() # Tensor转numpyx = torch.from_numpy(y) # numpy转Tensor
Tensor的操作
x = torch.Tensor(1,32,32)y = x.unsqueeze(1).unsqueeze(-1) # 1*1*32*32*1y = y.squeeze() # 32*32y = x.expand(4,32,32,4) # 复制16份, 4*32*32*4y = x.expand(4,33,32,4) # traceback, 不为1的维度不能更改y = x.expand(4,-1,-1,-1) # 复制4份, 4*32*32*1, `-1`代表维度不变y = x.repeat(4,32,1,1) # 复制4*32=128份, 4*1024*32*1y = x.repeat(4,1,1,1) # 复制4分, 4*32*32*1, 维度不能用`-1`x = torch.Tensor(3,4)x.t() # 转置x = torch.Tensor(64,3,224,224)x.transpose(0,1) # 交换0、1两个维度 3*64*224*224x.permute(0,2,3,1) # 指定新Tensor每个维度对应的维度 64*224*224*3x.flatten(startdim=2) # 拉平从startdim开始的所有维度,输出64*3*50176a | b, a & b, a ^ b, ~a # BoolTensor的运算a = torch.Tensor(64,16,56,56)b = torch.Tensor(64,16,56,56)torch.cat([a,b], dim=1) # 拼接得到64*32*56*56的Tensortorch.stack([a,b], dim=1) # 拼接得到64*2*16*56*56的Tensor stack对象须形状一样a.split(5, dim=1) # 拆分得长度4的tuple。64*5*56*56三个+64*1*56*56一个# split指定了每个子Tensor在特定维度上的大小a.chunk(5, dim=1) # 同上!每个子Tensor在dim的大小为ceil(16/5)=4# chunk指定了要分成多少个子Tensor # 所以实际上虽然要求分5个但只分了4个a.floor() # 向下取整a.ceil() # 向上取整a.round() # 四舍五入a.trunc() # 整数部分,取出来依然为FloatTensora.frac() # 小数部分a.clamp(6) # 钳位,小于6的全变6a.clamp(6,8) # 钳位,小于6的全变6,大于8的全变8
Tensor的维度操作(einpos)
from einops import rearrange# x.shape [c,t]y = x.transpose(0,1)y = rearrange(x, 'c t -> t c')# x.shape [b,c,t]b, c, t = x.size()y = x.view(b * c, t)y = rearrange(x, 'b c t -> (b c) t')y = x.view(b, c, t, 1)y = rearrange(x, 'b c (t a) -> b c t a', a=1)# x.shape [1,c,t]y = x.squeeze(0)y = rearrange(x, 'b c t -> (b c) t')
Tensor的统计属性
x = torch.Tensor(128,1000)x.sum, x.prod() # 求和、求所有元素点积x.mean(), x.var() # 均值、方差x.norm(p) # 返回p阶范数x.min(), x.max() # 最大最小值x.argmax(), x.argmin() # 最大最小值对应的索引(将Tensor拉平以后计算索引,只有一维)x.max(dim=1) # 返回长为128的Tensor,在第一维上取到的最大值x.argmax(dim=1) # 返回长为128的Tensor,在第一维上取到最大值的下标x.argmax(dim=1, keedim=True) # 返回Tensor为128*1,而非128torch.eq(a, b) # a与b两个Tensor中每个位置的元素是否相同,输出BoolTensortorch.equal(a, b) # 返回True或False,两个Tensor是否完全相同torch.all(a) # a中元素是否全部不为0,输出长为1的ByteTensor,a为Byte或Bool
Tensor的骚操作
x = torch.Tensor(...)x.multinomial(num_samples=100, replacement=False) # 将x归一化为和为1,依概率抽样100次,返回抽样的# 下标的Tensor。replacement控制抽完是否放回
乘法
包括乘标量、通过mul进行数值乘法(乘行向量、列向量等)、通过mm进行矩阵乘法等。
size函数
data = torch.Tensor(32,3,224,224)data.size(0)>>>32data.size(4)>>>Traceback (most recent calls last):data.size(-1)>>>224
view/reshape/clone
x = torch.Tensor(4, 64)a = x.view(2,2,8,8) #2*2*8*8a = x.view(7, 36) #Traceback boom boom shakalaka!!!#可以用-1代表缺省,程序会自动计算该位置上的维度,但只有一个维度上的值可以为-1a = x.view(-1,4,16) #4*4*16a = x.view(7,-1) #Traceback boom boom shakalaka!!!a = x.view(-1,-1,16) #Traceback boom boom shakalaka!!!#常用方法:x.size()>>>32*512*7*7x = x.view(32, -1)x = fc(x)
reshape函数与view类似,但view保证两个对象占用同一内存空间,reshape则不保证。
若要保证两个对象占用不同内存空间,则应调用clone函数。
交叉熵
位于torch.nn.functional中
nll_loss与log_softmax一起使用
cross_entropy = nll_loss + log_softmax
函数原型:
def nll_loss(input, target, weight=None, size_average=None, ignore_index=-100, reduce=None, reduction=’mean’):
reduce:是否对结果降维,若reduce=False则结果为一个长度为batchsize的Tensor(list)
reduction:’mean’、’sum’、’none’
Dataloader
包括Dataset和Dataloader,其实Dataset需要按照一定的格式读取数据集,Dataloader根据指定的batch_size在训练与测试的过程中提供每个batch的数据,也用于将训练集数据随机打散。Dataset一般需要根据数据集自定义,Dataloader直接使用pytorch自带的就行。以tiny-ImageNet为例:
train_dataset = Dataloader.MyTrainDataset(root_dir='./data/train', index_dict=name2index)train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True,num_workers=20)test_dataset = Dataloader.MyTestDataset(root_dir='./data/val', index_dict=name2index)test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False,num_workers=20)
其中num_workers表示用于进行数据预取和预处理的线程个数,num_workers=0代表直接通过主线程进行数据预取和预处理。CIFAR中一般用0就行,ImageNet类型的224*224输入依网络类型,小网络一般需要更大的num_workers,譬如8;大网络比如vgg16甚至num_workers开2就足够。
网络定义
卷积层
def init(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=’zeros’):
输入通道数in_channel与输出通道数out_channel<br /> 核大小kernel_size<br /> 步长stride=1、stride=(1,2)<br /> 边缘补像素数padding=0、padding=(0,1)<br /> 核膨胀系数dilation=1、dilation=(1,2),代表卷积核每两个作用点之间的距离<br /> 分组数group=1,将卷积分组进行后叠加(**ResNeXt**、**Depth-wise conv**)<br /> 偏置bias=True,参数中是否包含偏置b<br /> 边缘补全模式padding_mode='zeros'
优化器
Torch.optim.SGD/Adam
优化的参数params
学习速率lr
动量momentum //Pr = Pr + momentum vt-1 – (1 - dampening) η * ▽Pr
阻尼dampening //好像没啥用直接把1-dampening合到η中不好么
L2正则化系数weight_decay
nesterov(是否使用nesterov动量)
获取网络中的所有层
网络中的所有层都以nn.Module为父类,定义好网络以后,model.modules()会返回一个包含了所有网络层的迭代器。
譬如找出网络中所有的BN层可以写为:
model = Net()layer_bn = []for m in model.modules():if isinstance(m, nn.BatchNorm2d):layer_bn.append(m)
ModuleList
pytorch中,通过self.modules()获取parameter时,会通过dfs的方式遍历所有以nn.Module为基类的成员,但如果我们用list构建了一系列卷积层(譬如Res2Net Bottleneck),虽然list中的每一个元素都是nn.Conv2D,它们都以nn.Module为基类,但是由于其对外表现的type为list,因此self.modules()不会获取到list中的卷积层。
nn.ModuleList则是用于将一个list中所有的module都注册,以使得self.modules()可以获取到所有list中的层。
self.convs = nn.ModuleList([nn.Conv2d(width_per_group, width_per_group, kernel_size=kernel_size,stride=stride, padding=padding) for _ in range(self.nums)])
预处理
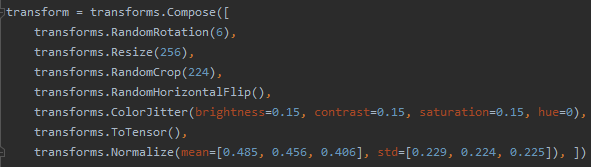
Normalize
根据给定的通道均值、方差,将输入转化为0均值1方差的标准分布。
ToTensor/ToPILImage
ToTensor用于image转tensor,它干了以下几件事:
- img.tobytes() 将图片转化成内存中的存储格式
- torch.BytesStorage.frombuffer(img.tobytes())将字节以流形式输入,转化成一维张量
- 对张量进行reshape和transpose(从2242243变成3224224)
- 将当前张量的每个元素除以255
ToPILImage用于tensor转image,它干了以下几件事:
- 将张量的每个元素乘上255
- 将张量的数据类型有FloatTensor转化成Uint8
- 将张量转化成numpy的ndarray类型
- 对ndarray对象做transpose (1, 2, 0)的操作(从3224224变成2242243)
- 利用Image下的fromarray函数,将ndarray对象转化成PILImage形式
由于ToTensor与ToPILImage都是类而不是函数,只能实例化以后使用:
trans = transforms.ToPILImage()
img = trans(img) # is ok.
img1 = transforms.ToPILImage(img1) # boom boom shakalaka!
空间操作
RandomRotation(n):随机旋转(-n~n)度
Resize(n):更改大小为n*n,注意图像长宽比防止拉伸
RandomCrop(n)/CentorCrop(n):顾名思义,随机裁剪和中心裁剪
RandomHorizontalFlip:随机水平翻转,还有个垂直翻转
色彩抖动
ColorJitter:brightness亮度(0~1),contrast对比度(0~1),saturation饱和度(0~1),hue色调(0~0.5),数字全部表示变换幅度,会在1-x,1+x间变化(色调不一样)
模型的存储与加载
[https://www.cnblogs.com/leebxo/p/10920134.html](https://www.cnblogs.com/leebxo/p/10920134.html)<br />↑↑↑博文里讲的挺清楚的。
model.static_dict是一个字典:{‘name’: parameters / buffers }
# pytorch官方建议的方法
torch.save(model.state_dict(), PATH)
model = Net()
model.load_state_dict(torch.load(PATH))
def load_model(trained_dict, new):
model_dict = new.state_dict()
trained_dict = {k: v for k, v in trained_dict.items() if k in model_dict}
model_dict.update(trained_dict)
new.load_state_dict(model_dict)
# 根据需要过滤需要的参数
load_model(torch.load(PATH).state_dict(), model1)
# 不推荐的方法,踩了坑
torch.save(model, PATH)
model = torch.load(PATH) #加载整个模型结构和模型参数
上面提到的直接save和load模型而非state_dict的方法,本以为能够存储整个模型的结构,但是发现模型的加载依然依赖网络定义的py文件net.py,且net.py必须和main.py位于同一顶层目录,否则会报找不到net Module。
以resnet为例,我们在MyResNet.py中重写了适合自己的resnet网络,torch.save(model, PATH)存储的结果虽然包含了模型结构,但是只记录了最顶层的block。它知道卷积、池化、BN等是什么,但不知道BasicBlock内部是啥,依赖于MyResNet.py文件。如果main.py位于root目录下,而MyResNet.py位于/models/MyResNet.py,那就会报错No Module named MyResNet,除非把MyResNet.py移到和main.py一个目录下——这非常愚蠢。
综上所述,还是用state_dict方法比较好。
FLOPS计算
from torchstat import stat
stat(model, (3, 32, 32))
分布式训练
参考:https://zhuanlan.zhihu.com/p/98535650
DataParallel
这是最方便的方法,定义完model以后加一句:
model=torch.nn.DaraParallel(model, device_ids=YOUR_GPUS, output_device=YOUR_GPUS[0])
然后用了几张卡就把batch_size扩大几倍,就OK了,什么事都没有了。但是相比接下来要讲的DDP方法,这
里使用的DataParallel方法相对效率较低,实测在多卡效率在65%~80%左右。
但是即使是用DataParallel方法,也存在跨GPU交互问题,因为每个GPU中都会存放一份model。所有对于model属性的更改,只有master GPU的更改会生效,其它slaver GPU上对于model属性的更改都会在同步点(通常是optimizer.step())被销毁并从master GPU重新copy整个model。
DDP
torch.nn.parallel.DistributedDataParallel是pytorch集成的一种分布式方法,该方法甚至支持多机多卡的分布式训练,不过由于家境贫寒没有多机这里只介绍单机多卡的配置,相对多机多卡也会简单不少。比较神奇的是Windows下的pytorch不知道为啥找不到torch.distributed这个包,可能是Windows不配做分布式吧。
DistributedDataParallel的做法是,在所有GPU中维护独立的模型参数,每次待所有GPU backward完成后对梯度取平均后分发到各个GPU,再由各个GPU对各自保存的模型参数分别进行更新,避免了广播模型参数的开销。
以下是DDP的示例main.py程序,运行的指令相比原始的单卡训练稍有不同:
单卡训练指令:
python main.py
DDP单机多卡训练指令:
python -m torch.distributed.launch —nproc_per_node=NUM_GPUS_YOU_HAVE main.py
该指令相当于通过torch.distributed.launch.py去运行我们的main.py。launch.py会为每一个GPU开一个进程,
每个进程都会执行相同的main.py的代码,它们之间相互独立,不共享内存与变量。每个main.py进程都会得到launch.py传入的参数local_rank,代表当前进程调用的是哪一个GPU。
DistributedSampler是用于DDP分布式训练的数据集采样器,用于在分布式环境下对数据集进行采样。DDP方法下main.py设置的batch_size应为每张卡的batch_size,不同于DataParallel方法需要将batch_size乘上GPU数量。如果我们不使用DistributedSampler,那么每张卡都会把整个数据集算一遍。假设bs=100,dataset=10000,GPU数量为4,如果不采用DistributedSampler那么每张卡在每个epoch都会计算100step,而使用DistributedSampler则每张卡在每个epoch都只需要集算25step。
需要注意的是,test只需要在一张卡上做就可以了,如果testset也用DistributedSampler采样,那么三张卡对应的三个进程将无法交互loss与acc。另外参数sampler与shuffle互斥,DistributedSampler会自动为我们随机采样,我们不再需要开启train_loader的shuffle选项。
import torch
import torch.nn
from torch.utils.data.distributed import DistributedSampler
torch.distributed.init_process_group(backend="nccl")
local_rank = torch.distributed.get_rank()
torch.cuda.set_device(local_rank)
device = torch.device("cuda", local_rank)
train_dataset = xxx
test_dataset = xxx
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset, batch_size=batch_size, shuffle=False, num_workers=4,
sampler=train_sampler)
test_loader = torch.utils.data.DataLoader(
dataset=test_dataset, batch_size=batch_size, shuffle=False, num_workers=4)
model = xxx
model = torch.nn.parallel.DistributedDataParallel(
model, device_ids=[local_rank], output_device=local_rank)
optimizer = xxx
for epc in range(EPOCH_CNT):
train(epc)
if local_rank == 0:
test()
DDP会对所有进程进行batch同步,当所有进程执行完成上一batch的optimizer.step()时,才开始执行下一个batch的forward。torch.distributed.reduce()提供了跨GPU的信息交互功能,能够帮助我们融合各个进程得到的train_loss等等。
from torch import distributed as dist
world_size = dist.get_world_size()
def reduce_loss(tensor, world_size):
with torch.no_grad():
dist.all_reduce(tensor)
tensor /= world_size
def train(epc):
for data, target in train_loader:
optimizer.zero_grad()
output = model(data.cuda(device)) # 这一行之前等待所有进程optimizer.step结束
_, pred = torch.max(output.data, 1)
train_correct += pred.eq(target.data.cuda(device).view_as(pred)).sum()
loss = F.cross_entropy(output, target.cuda(device))
total_loss += loss.item()
loss.backward()
optimizer.step()
reduce_loss(loss, world_size) # 这一步是跨进程交互,获取所有进程的平均loss
global_step += 1
if global_step % 100 == 0:
pass
all_reduce函数源码:第二个参数op为处理所有进程间tensor的方式,默认为SUM求和,其他方法还有PRODUCT、MIN、MAX、BAND、BOR、BXOR。
def all_reduce(tensor,
op=ReduceOp.SUM,
group=group.WORLD,
async_op=False):
"""
Reduces the tensor data across all machines in such a way that all get
the final result.
After the call ``tensor`` is going to be bitwise identical in all processes.
Arguments:
tensor (Tensor): Input and output of the collective. The function
operates in-place.
op (optional): One of the values from
``torch.distributed.ReduceOp``
enum. Specifies an operation used for element-wise reductions.
group (ProcessGroup, optional): The process group to work on
async_op (bool, optional): Whether this op should be an async op
Returns:
Async work handle, if async_op is set to True.
None, if not async_op or if not part of the group
"""
_check_single_tensor(tensor, "tensor")
if _rank_not_in_group(group):
return
opts = AllreduceOptions()
opts.reduceOp = op
if group == GroupMember.WORLD:
_check_default_pg()
work = _default_pg.allreduce([tensor], opts)
else:
work = group.allreduce([tensor], opts)
if async_op:
return work
else:
work.wait()
Pycharm下的分布式运行
pycharm专业版可以进行ssh远程开发,由于高贵的ZJU邮箱被Jetbrain ban了,只能用破解了。pycharm怎么配置ssh远程开发这里就不赘述了。问题是我们的指令有这么长一串,而且需要通过launch.py调用自己的script,因此需要在pycharm中配置一番。
打开Run->Edit Configurations,其中Parameters为我们自己的script(如main.py)的参数。Environment variables为环境变量,相当于命令行中加在python之前的变量。Interpreter options为跟在python后的变量。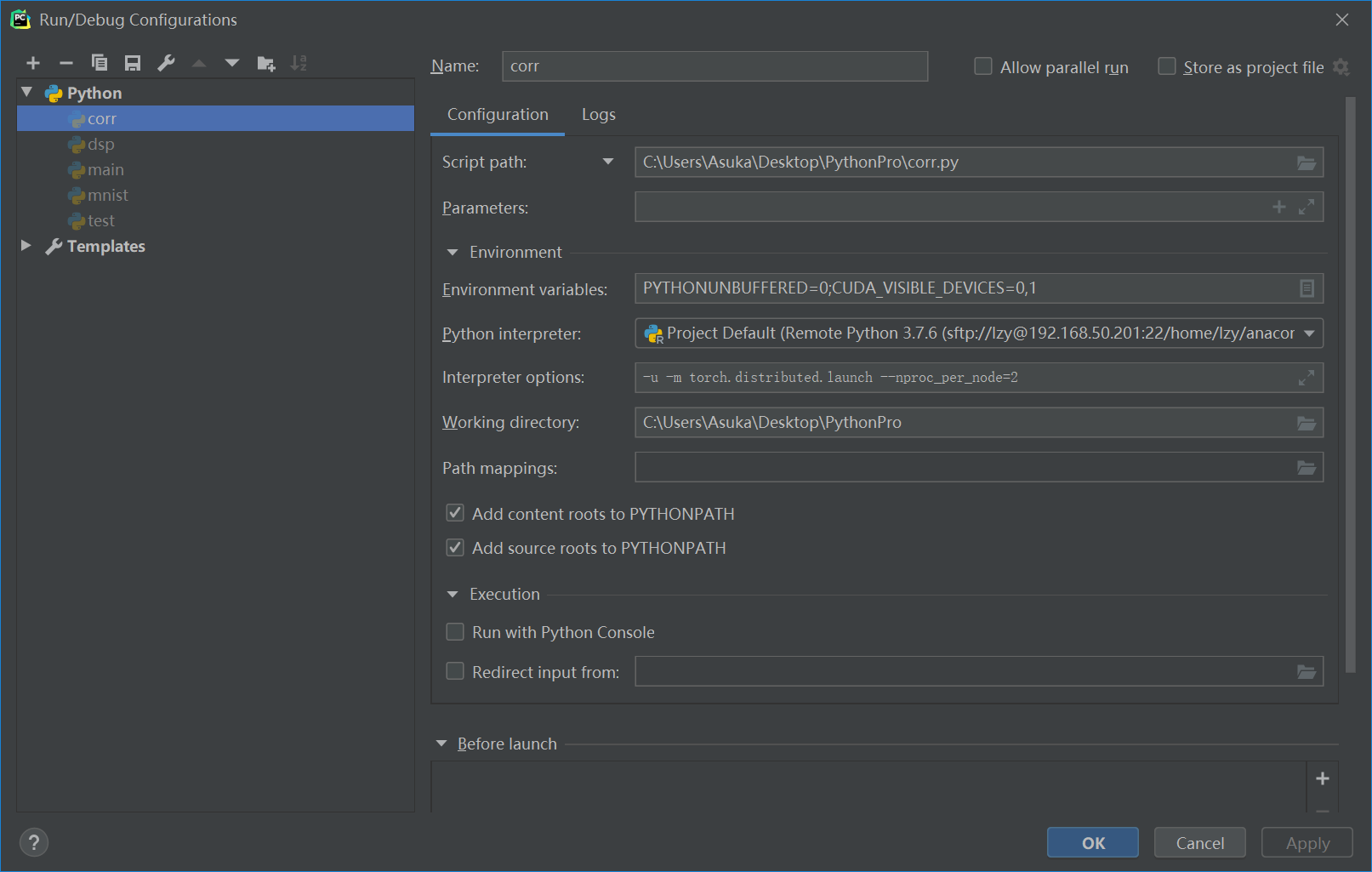
直接在Interpreter options中输入-m torch.distributed.launch —nproc_per_node=2后运行,报错:
launch.py: error: unrecognized arguments: -u
仔细观察pycharm中的命令,发现pycharm自动带上了-u,运行的指令为:
ssh://lzy@192.168.50.201:22/home/lzy/anaconda3/bin/python -m torch.distributed.launch —nproc_per_node=2 -u /home/lzy/PythonPro/corr.py
可以看到奇奇怪怪地被带上了一个-u,百度以后发现这是用于:强制其标准输出也同标准错误一样不通过缓存直接打印到屏幕。
问题的关键是,这是一个应该被传递给python解释器的参数,但是由于跟在了-m torch.distributed.launch后,这个参数被传递给了launch.py,导致了launch.py报错。我们如果显示地把-u加到了Interpreter options中并把它放到开头,pycharm就不会再自动为我们添加这个参数。所以最后的Interpreter options为:
-u -m torch.distributed.launch —nproc_per_node=2
安装Anaconda、Pytorch
conda config —add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config —add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config —set show_channel_urls yes
conda config —add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda install pytorch torchvision cudatoolkit=x.x
(不推荐)但有的时候上面的命令会一直solving environment,也可以直接到清华源下包后离线安装:
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
下载完成以后是bz2格式的包,运行:
conda install —offline xxx.bz2
但很多时候因为依赖项原因这么装上的包会用不了!
Anaconda配置
添加环境变量:vim ~/.bashrc
拉到最后添加(目录根据实际情况修改):
. /home/lzy/anaconda3/etc/profile.d/conda.sh
conda activate
加完以后:source ~/.bashrc
但是这么干了以后每次登录终端都要source ~/.bashrc,一劳永逸的办法:
vim ~/.bash_profile,加以下语句:
if [ -f ~/.bashrc ]; then
source ~/.bashrc
fi
然后source ~/.bash_profile
Anaconda虚拟环境
Anaconda的虚拟环境默认为(base)
conda create -n env_name python=version # 创建名为env_name的虚拟环境
conda activate env_name # 激活名为env_name的虚拟环境
conda deactivate # 退出当前虚拟环境
conda remove -n env_name —all # 删除名为env_name的虚拟环境
conda info -e # 列出所有虚拟环境

若有收获,就点个赞吧
0 人点赞
