参考网课:李宏毅深度学习2020
简介
强化学习的主体包括Agent(AI)和Environment(环境,譬如游戏、CNN),Agent从Environment通过Observation得到State(游戏局面、网络的特征图等状态),并作出Action(决策),得到Reward。
强化学习的目标是得到一个Agent,其Action能得到的最大的Reward。
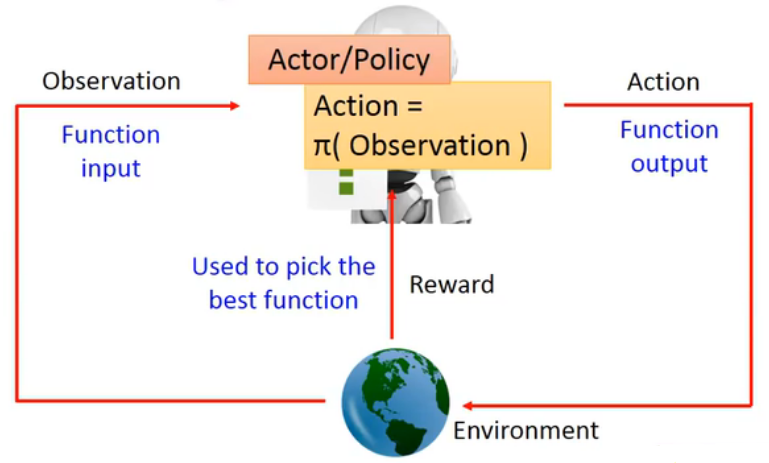
如果Agent由神经网络构成,则这样的强化学习可称为深度强化学习(Deep-Reinforcement Learning)。网络可以是一个接受游戏图像的CNN,通过分类任务输出各个操作的概率。
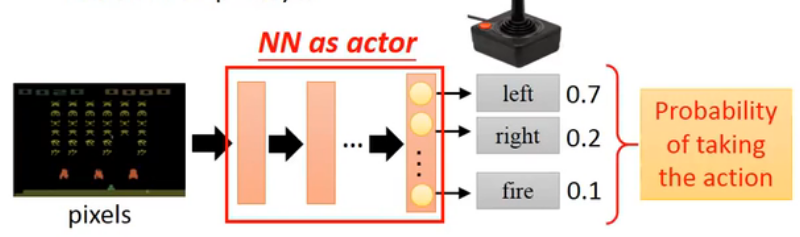
Agent的组成
(以下引用郑老师https://www.yuque.com/yahei/hey-yahei/rl-introduction)
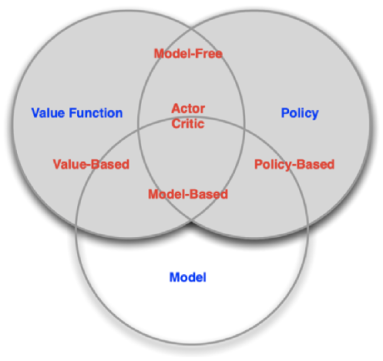
Policy-based(基于决策):训练一个Actor,对Agent的行为进行建模,根据当前state输出一系列行为的概率分布;
Value-based(基于价值):训练一个Critic,根据当前state来预测Actor能取得的价值。(是预测Actor能取得的结果而非上帝视角的结果);
Model-based(基于模型):预测未来会发生什么事,譬如围棋中使用的蒙特卡洛搜索树,根据当前state和即将采取的action来预测下一阶段的state和reward。在棋类中用的比较多,state相对可预测,而游戏则不太有用Model-based方法的。
强化学习的难点
- reward是稀疏的情况,譬如围棋,在绝大多数情况下reward=0,直到对弈结束分胜负方能获得reward。如何在reward为稀疏的情况下进行训练是一大难点。
- reward延迟,考虑简单的小霸王游戏只有往左、往右、射击三个动作,虽然往左、往右是必须的但只有射击才能获得reward。
- Agent应该要有探索不同行为的能力,否则Agent发现只有射击能获得reward于是从来不进行移动。
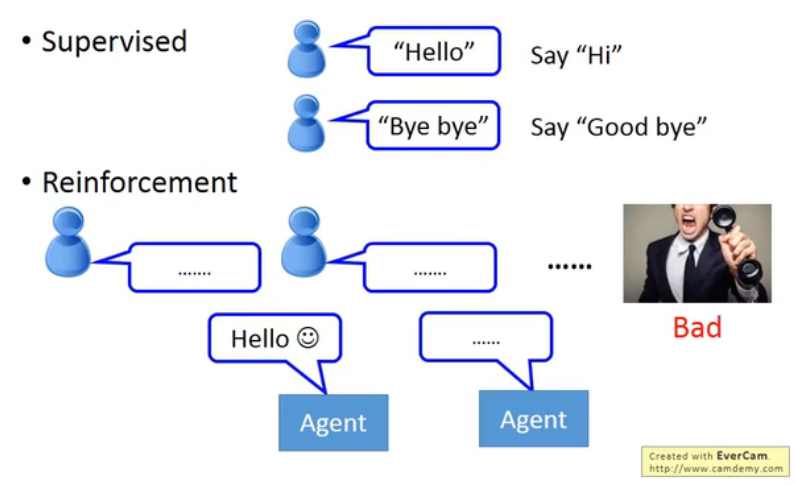
监督学习 vs 强化学习
对比监督学习与强化学习,监督学习是通过label训练出一个模型,让模型学会模仿在什么局面下什么棋。而强化学习通过一系列的对弈模拟,自己学出规律(往往需要非常多的对局模拟)
对于chat-bot任务(对话机器人),监督学习的做法可以通过训练一个RNN让模型学会在接受什么输入的时候要输出什么东西,而强化学习只能瞎J2对话,得到reward后根据reward更新。比如一个傻屌对话机器人把人气得砸键盘了,那就得到了bad reward,告诉Agent它说的话不对。
Actor
Policy Gradient
这一节讨论的问题是,如何对Actor的参数进行训练,如何使用梯度下降。
给定Actor: ,指的是参数为
,指的是参数为 ,观察到state为
,观察到state为 时,Actor会采取的action。
时,Actor会采取的action。
定义 ,为一次完整的过程,其中
,为一次完整的过程,其中 分别为每一步Agent观察到的state、采取的action、获得的reward。
分别为每一步Agent观察到的state、采取的action、获得的reward。
*区分上下标, 代表第
代表第 次模拟中,第
次模拟中,第 步中,Agent观察到的state。
步中,Agent观察到的state。
 训练时,从
训练时,从 中进行采样来对近似。
中进行采样来对近似。

为什么要做这步转换?因为我们在训练中,是通过 进行近似,如果同一局面在N次采样中出现了多次,譬如
进行近似,如果同一局面在N次采样中出现了多次,譬如 相同,都取得了
相同,都取得了 ,在计算梯度时等效为
,在计算梯度时等效为 但是取得了
但是取得了 ;而
;而 取得了
取得了 。如果不这么做近似,那么将会主导更新的梯度。将
。如果不这么做近似,那么将会主导更新的梯度。将 转化为
转化为 实际上是对做了归一化排除这种情况。
实际上是对做了归一化排除这种情况。
两点改进
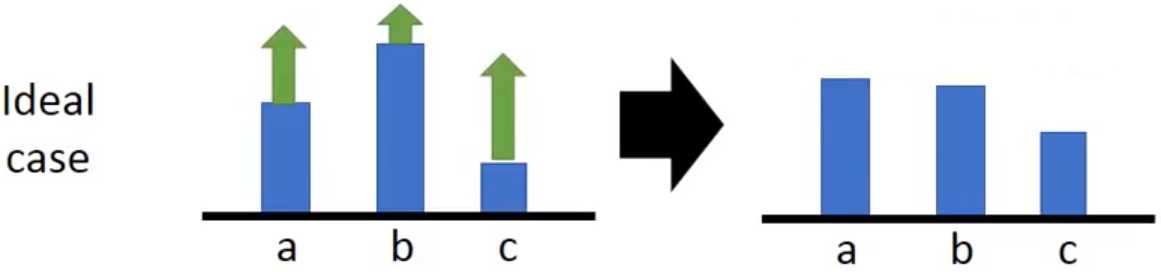
· 添加baseline
对于一些任务,可能 恒为正,譬如贪吃蛇的计分等。但即使所有action的梯度为正,梯度正的比较小的或者为零的action依然会在更新后获得更小的概率,因为分类的时候被softmax归一化了。有的时候有些action比较倒霉,前期没被采样到,被拉低了概率,后期越发没可能采样到了,最终这个action全程没有被Agent探索过。
恒为正,譬如贪吃蛇的计分等。但即使所有action的梯度为正,梯度正的比较小的或者为零的action依然会在更新后获得更小的概率,因为分类的时候被softmax归一化了。有的时候有些action比较倒霉,前期没被采样到,被拉低了概率,后期越发没可能采样到了,最终这个action全程没有被Agent探索过。
因此建议对于这种恒为正或恒为负的任务,手工设计一个偏置,将 作为权重。
作为权重。
<br /> 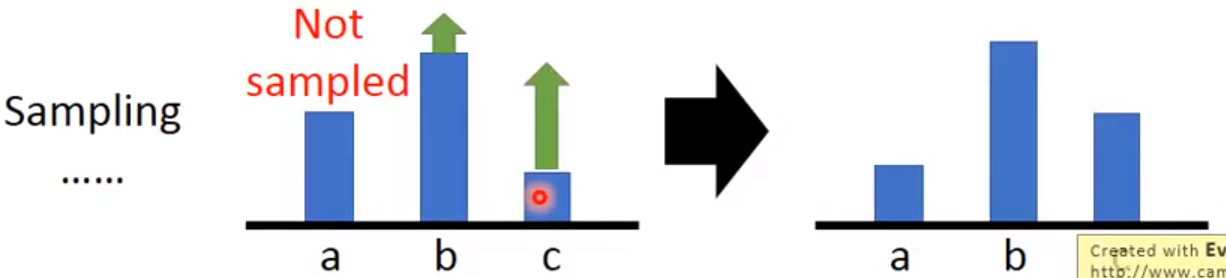
· 时间权重 / Advantage Function
(以下引用郑老师https://www.yuque.com/yahei/hey-yahei/rl-introduction)
另外,对于 ,可以计算得到
,可以计算得到 ,但此时我们基于梯度进行更新时,
,但此时我们基于梯度进行更新时, 、
、 、
、 的权重都为3,但显然主要贡献来自于
的权重都为3,但显然主要贡献来自于 ,这不太合理。一种比较合理的做法是,将
,这不太合理。一种比较合理的做法是,将 作为
作为 的权重。
的权重。
再有的,为了尽快拿到更高的reward,或者说削弱非常遥远的reward对Actor的影响,引入超参 ,使得权重变为
,使得权重变为 。
。
如果我们令Advantage Function: ,则梯度计算转化为下式所示:
,则梯度计算转化为下式所示: 
On Policy / Off Policy
若执行模拟并用于采样的模型,与训练的模型是同一个,则称为On Policy。(比如自己在下棋中学习);
若两者不是同一个模型,则称为Off Policy。(比如看别人下棋自己在旁边思考学习)。
虽然On Policy比较直观,之所以要考虑用Off Policy是为了避免训练的每个step后都要重新对 进行采样(重新进行模拟),这样效率非常低。若能通过某种手段采用Off Policy训练,则可以节省大量的采样与模拟开销。
进行采样(重新进行模拟),这样效率非常低。若能通过某种手段采用Off Policy训练,则可以节省大量的采样与模拟开销。
说白了要用Off Policy就是为了避免频繁的采样与模拟。
分布修正
在Off Policy中,我们保留一份参数的副本 ,通过的采样结果对进行训练,K个step后再将赋值给,这样就不需要每个step都进行模拟,每K个step模拟一次就可以了。
,通过的采样结果对进行训练,K个step后再将赋值给,这样就不需要每个step都进行模拟,每K个step模拟一次就可以了。
但是由于经过K次迭代,与已经有一定的差距,我们基于对进行更新时需要做分布修正。
FBI Warning:接下来的数学推导有点令人头秃
预备知识 Importance Sample
记有函数 ,且输入的
,且输入的 符合分布
符合分布 ,那么我们可以直接通过对
,那么我们可以直接通过对 采样来计算
采样来计算

但如果我们不知道的真实分布,而是从 对进行采样,此时为了计算就需要进
对进行采样,此时为了计算就需要进
行分布修正:

*
训练Actor时,其原始梯度为:
现在我们的是从采样得到而非,根据 Importance Sample,可以得到修正后的梯度为:
展开上式,并且用Advantage Function  替换:
替换:
在On Policy时我们的目标函数是 ;而当Off Policy时,我们可以根据上述推导
;而当Off Policy时,我们可以根据上述推导
得到新的目标函数(我们想最大化的函数):
根据: ,
,
又有 ,记
,记 ,
,
可以得出Off Policy时的目标函数:

避免分布差异过大
然而就算我们做了分布修正,这也只是使得Off Policy时,梯度的期望与On Policy时一致,但方差却依然是不同的。由Importance Sample,我们可以得到:
但是:
显然分布 与
与 的差异越大,
的差异越大, 与
与 的差异就越大。
的差异就越大。
在实际的Off Policy训练过程中,我们是取从中采样的梯度均值作为梯度的期望的估计。若与的分布差异过大,则的采样数量必须非常非常大,以避免巨大方差对期望的估计带来的影响。
举个例子,如果与的分布差异巨大而我们依然从中采样,并取采样均值作为的估计。实际上是负的,但如果我们从中采样的样本全部位于 处,则会得到正的估计,这显然是错误的。除非我们从中采样的样本足够多,遍历到了
处,则会得到正的估计,这显然是错误的。除非我们从中采样的样本足够多,遍历到了 的区间,才能得到正确的估计。
的区间,才能得到正确的估计。
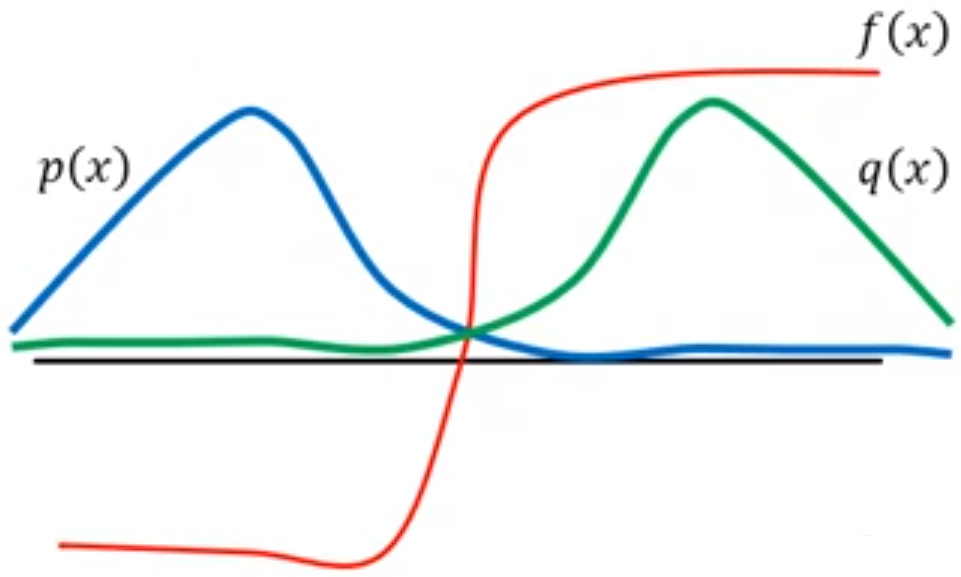
因此在Off Policy训练时,我们需要采取一些手段避免与的分布差异过大。
TRPO与PPO
原始Off Policy的目标函数为:
现在我们需要对目标函数引入用于限制与的分布差异过大的正则化。
*需要注意**,以下提出的 并非直接计算参数的向量间距离,而是计算Actor的输出分布的距离,也就是
并非直接计算参数的向量间距离,而是计算Actor的输出分布的距离,也就是 ,李宏毅的PPT里写成了这样并给了解释。
,李宏毅的PPT里写成了这样并给了解释。
· TRPO(Trust Region Policy Optimization)
在使得目标函数最大化的同时,直接添加 的硬门限。
的硬门限。
· PPO(Proximal Policy Optimization)
PPO是一种高效训练Actor的方法,也是OpenAI默认的强化学习训练方法。不同于TRPO添加硬门限,并且在硬门限的约束条件下难以求解,PPO则是将作为类似于L2惩罚的正则化惩罚项引入目标函数,即:

论文原文中有提出动态地调整 ,当
,当 时调大,当
时调大,当 时调小。
时调小。
· PPO2
PPO2是对PPO的改进,它更为简洁,毕竟算很麻烦。

看起来很复杂,实际上只是限制了 的范围不超出
的范围不超出 ,当
,当 时,排除进一步扩大对目标函数
时,排除进一步扩大对目标函数 带来提升;而当
带来提升;而当 时,排除进一步缩小使得目标函数的值更小。
时,排除进一步缩小使得目标函数的值更小。
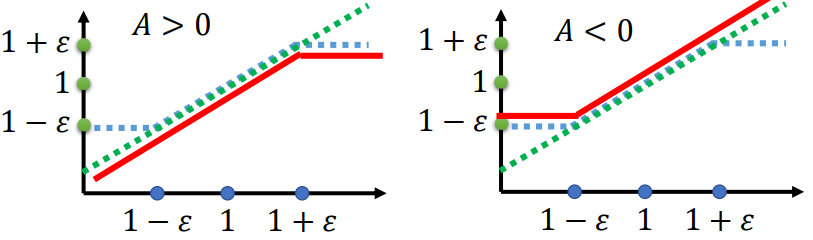
通过这样的限制措施,使用PPO2训练时不需要计算,非常方便。
Critic
Critic是一个评估函数 ,其本身不产生决策,只是用于衡量特定的决策器
,其本身不产生决策,只是用于衡量特定的决策器 (Actor),在某一局面下的估值,类似于Alphg-Go用来预测胜率的评估模型。Critic对于不同的Actor可以在同一state下给出截然不同的结果,因此Critic是与Actor绑定的。
(Actor),在某一局面下的估值,类似于Alphg-Go用来预测胜率的评估模型。Critic对于不同的Actor可以在同一state下给出截然不同的结果,因此Critic是与Actor绑定的。
如果把Actor和Critic结合在一起则成为Actor-Critic技术。这时候Actor不是直接根据环境给的reward进行学习,而是根据Critic的评价进行学习。其实这与GAN的思路有点像,把Actor理解成GAN里的生成器,Critic理解成判别器。
只考虑状态的训练
- 蒙特卡洛(MC)
最简单的就是使用蒙特卡洛方法,随机生成state让Critic看Actor操作,等一个episode结束时记录reward用于训练Critic,持续若干次模拟。
- 时间差分(TD)
MC的缺点是每个step的训练都需要Actor完成整个episode的模拟,效率低。Temporal-difference方法观察一个短暂的中间片段 ,计算
,计算 与
与 ,以
,以
这一规则进行差分训练。
(李宏毅的课里说TD用的比较多)
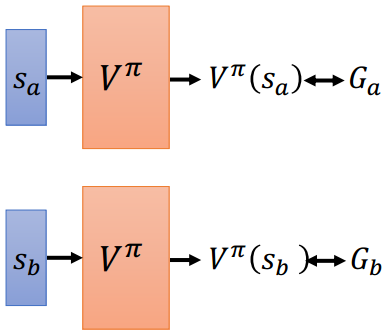 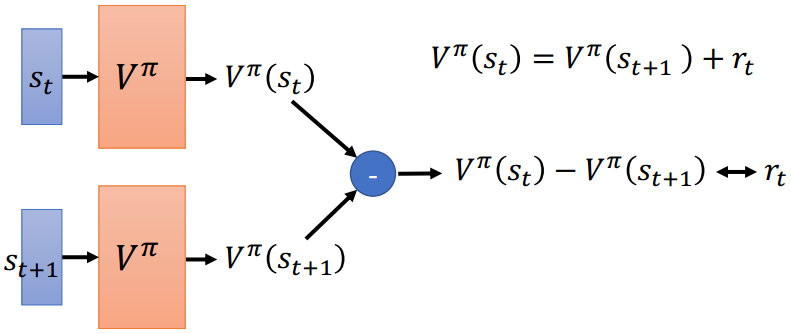<br />MC法 TD法
相比之下,MC方法较为精准,但方差大,若episode中step数较多则难以收敛;TD方法比较稳定,但差分训
练相对来说没有那么合理和准确。
除此之外,MC会关注不同状态的相关性而TD不会(都合理但都不完美)。拿李宏毅课中的例子来说:

 出现了8次,其中2次reward为0,而6次reward为1,且为episode的终点,可直接得出
出现了8次,其中2次reward为0,而6次reward为1,且为episode的终点,可直接得出 。但MC认为出现
。但MC认为出现 态后能获得的累计reward为零,后导致
态后能获得的累计reward为零,后导致 是
是 的出现导致的,因此
的出现导致的,因此 ,而TD遵循差分原则,它认为
,而TD遵循差分原则,它认为 ,而在第一个episode中(仅第一个episode出现了
,而在第一个episode中(仅第一个episode出现了 )差分的
)差分的 ,而则是偶然,因此
,而则是偶然,因此 。
。
Q-Learning
Q-Learning在使用Critic的时候不仅仅考虑了state,还结合了action的影响(就这么点区别)。Q-Learning有两种表现形式:

右边这种表现形式仅针对离散action的任务(如俄罗斯方块、棋类),就相当于把action枚举后扔进左边这种形式的Critic。对于Q-Learning来说,并不一定需要独立的Actor,因为对于离散action的任务,右边这种形式的Critic已经充当了一个分类器了,选择价值最高的action即可。
Q-Learning的训练过程如下图所示,通过TD或者MC得到 以后,通过
以后,通过 来迭代Actor 来获得新的Actor,并往复迭代,而我们的最终目标则是最大化。
来迭代Actor 来获得新的Actor,并往复迭代,而我们的最终目标则是最大化。
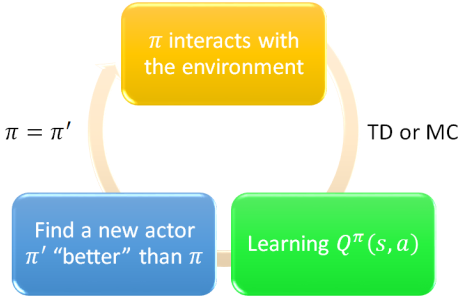<br />将Q-Learning和深度学习结合起来,即用神经网络充当Critic,则称为Deep Q-Learning Network(**DQN**)。
三点改进
- Target Network
在用TD训练时,我们根据 进行训练,但是不能单纯让
进行训练,但是不能单纯让 拟合
拟合 ,或者让拟合,因为只有一份,更新了一边会影响另一边,这使得模型拟合的label一直在发生变化,会造成训练的不稳定。
,或者让拟合,因为只有一份,更新了一边会影响另一边,这使得模型拟合的label一直在发生变化,会造成训练的不稳定。
Target Network提出,将复制一个副本得到 ,让去拟合
,让去拟合 ,更新而保持不变,训练N个steps后再重新将复制给。这么做可以使得至少在N个steps内,拟合的label是稳定的。
,更新而保持不变,训练N个steps后再重新将复制给。这么做可以使得至少在N个steps内,拟合的label是稳定的。
这么做有点类似于之前讨论Actor的训练时Off Policy的做法,但因为Critic出来的结果不像Actor一样是分布,也就不用做Off Policy里的那种分布修正了。
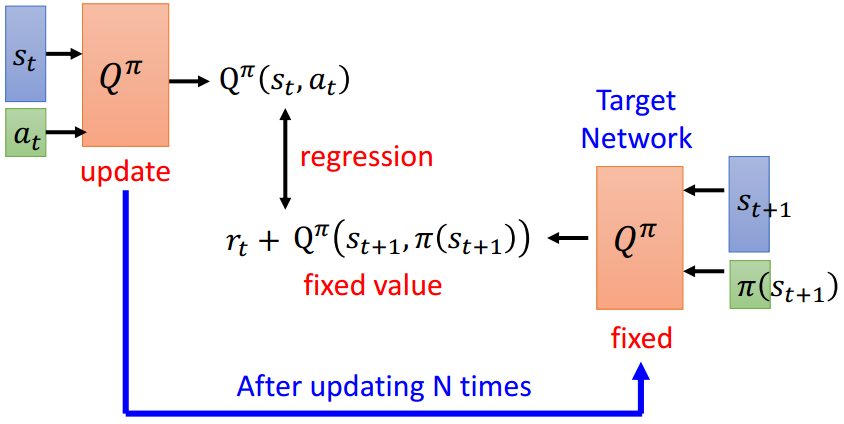
- Exploration
在我们对game进行模拟以收集 时,Actor会在每一步得出所有可能的action的概率分布,并依概率采样;而Q-Learning中我们就算能得到每个action的
时,Actor会在每一步得出所有可能的action的概率分布,并依概率采样;而Q-Learning中我们就算能得到每个action的 也无法获得采取每个action的概率分布,Critic永远只会采取最高的action,如果刚好这个action获得了正的reward,那之后在
也无法获得采取每个action的概率分布,Critic永远只会采取最高的action,如果刚好这个action获得了正的reward,那之后在 时Critic就会永远选择这个action。
时Critic就会永远选择这个action。
下面给出了两种鼓励Critic探索不同action的方法:
· Epsilon Greedy
以概率 随机挑选除了令最大的action外其它action,只有
随机挑选除了令最大的action外其它action,只有 的概率会挑选会令最大的action。
的概率会挑选会令最大的action。
当 时即为完全随机,通常在训练初期较大,而后越来越小。
时即为完全随机,通常在训练初期较大,而后越来越小。
· Boltzmann Exploration
通过类似于softmax的方法,为所有可能的action提供概率分布后依概率选择。
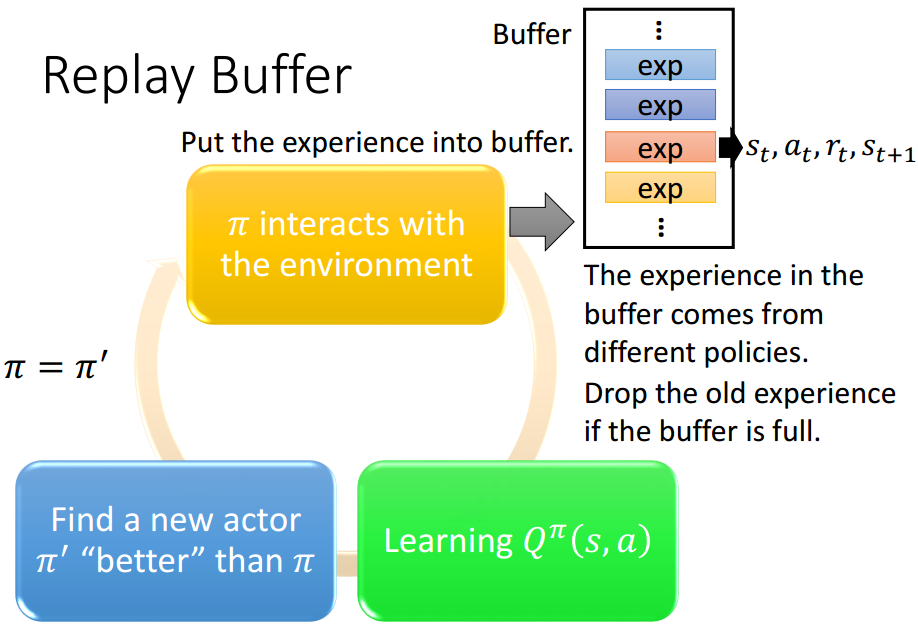
- Replay Buffer
我们之前在训练Actor时讲过,On Policy训练会带来过大的采样与模拟开销,因此我们引入了Off Policy。在Q-Learning中,常规的步骤是:用与环境互动收集一系列 ,用它们训练
,用它们训练 ,接着用类似GAN的思路,训练得到一个能让最大的Actor
,接着用类似GAN的思路,训练得到一个能让最大的Actor  ,再接着用与环境互动……。
,再接着用与环境互动……。
同样,每次Actor模拟得到的数据都只能用于一轮迭代,采样与模拟的开销较大。使用Replay Buffer我们可以存储若干个历史版本的数据,利用它们共同进行训练。当buffer填满时,根据FIFO策略覆盖。
虽然这些模拟数据可能来自于不同的Policy,甚至是差别很大,差了好几个版本的Policy。但是客观存在的,跟Policy本身无关,并且这么做也能有助于上一点中提出的鼓励探索,因此是合理的。
典型的Q-Learning流程
(只有Critic没有Actor的离散action任务)
初始化Q-Function Q, Target Network的Q-Function Q^=Q
for each iteration:
for t in range(T):
a_t = Q.get_action(s_t)
r_t, s_(t+1) = do_action(s_t, a_t)
if replay_buffer.is_full():
replay_buffer.pop()
replay_buffer.append((s_t, a_t, r_t, s_(t+1)))
for step in range(Q_steps):
sample = replay_buffer.get_batch()
output = Q(s_i, a_i)
target = sample.r_i + Q^(sample.s_(i+1), Q^.get_action(sample.s_(i+1)))
loss = fun_loss(output, target)
train(Q, loss)
if step % C == 0:
Q^ = Q
Actor-Critic
郑老师的博文已经总结的很到位了:https://www.yuque.com/yahei/hey-yahei/rl-actor_critic
Imitation Learning
在许多情境中reward function是未知的(譬如自动驾驶),这时候我们请来人类专家,让机器观察专家的若干操作 。
。
一开始我们拥有一个弱的reward function,譬如随机的,我们让Actor根据当前reward function最大化reward得到弱Actor,此时再更新reward function让其相比Actor的action,永远对人类专家的action给出更高的reward。若干轮后,我们就能得到一个强Actor和强reward function。该思路也是和GAN有点像,把Actor理解成生成器,reward function理解成判别器。
总结各类任务的训练方法
- 俄罗斯方块、贪吃蛇等积分制游戏
训练一个Actor,其Advantage Function:

指游戏结束之前Agent得到的reward总和,我们希望得到最大的 的期望值
的期望值 。引入时间衰减因子促使
。引入时间衰减因子促使
Actor偏向于尽快拿到reward。这也是李宏毅课里面的例子。
- 国际象棋、五子棋等博弈游戏
使用Actor-Critic技术联合训练。
我想了很久还是没想出不用Critic而只用Actor的训练方法,因为无法构建Actor的reward。不用Critic时显然只能由静态评估函数 提供
提供 ,尽管可以是一个CNN。如果取
,尽管可以是一个CNN。如果取 ,那么这个Actor将会和只会搜
,那么这个Actor将会和只会搜 的弱智搜索树一样;如果取
的弱智搜索树一样;如果取 (其中
(其中 为搜索深度,之所以这么写是因为要考虑到可能没搜到层游戏就结束了,需要对权重归一化),首先不是越大越好,一开始给很大的肯定会完全训不动;其次缺乏了静态搜索(Q-Search)这样做的地平线效应会非常严重。
为搜索深度,之所以这么写是因为要考虑到可能没搜到层游戏就结束了,需要对权重归一化),首先不是越大越好,一开始给很大的肯定会完全训不动;其次缺乏了静态搜索(Q-Search)这样做的地平线效应会非常严重。
- 自动驾驶、对话机器人等无法给reward的任务
用Imitation Learning。
- SkipNet等CNN的条件计算
在这种使用情境下,一个episode只有一个state,因为action仅仅为各个Block的开闭,一旦决定,reward可以通过准确率与开销的联合函数直接给出。
在这里显然就不需要用TD进行训练,直接用MC就行了,因为一个episode只有一个state。

若有收获,就点个赞吧
0 人点赞
