Attention Is All You Need(NIPS2017)
论文:https://arxiv.org/pdf/1706.03762v5.pdf
李沐:https://www.bilibili.com/video/BV1pu411o7BE?spm_id_from=333.999.0.0
Transformer的开山之作,其最早被用于NLP如机器翻译等领域。
此前相关领域用的都是RNN及其变种,且接收输入与计算输出都是串行的,效率非常低。另外RNN、LSTM类结构由于是串行计算的,其长距离的信息获取能力相对较弱。而Transformer将长距离信息获取的操作数降低为了1。
Transformer构建了一种更为直接的纯注意力机制,抛弃了序列化计算,取得非常优异的结果。
Transformer概览
Transformer整体网络的基本结构如下图所示,输入的自然语言经过词嵌入(与后面会提到的位置编码)后得到一个序列化的向量,经过6个Encoder Block与6个Decoder Block后得到输出。下图为机器翻译任务的一个简单示例图。
词嵌入历史悠久源远流长,不清楚的可以单独查一下也是很容易看懂的= =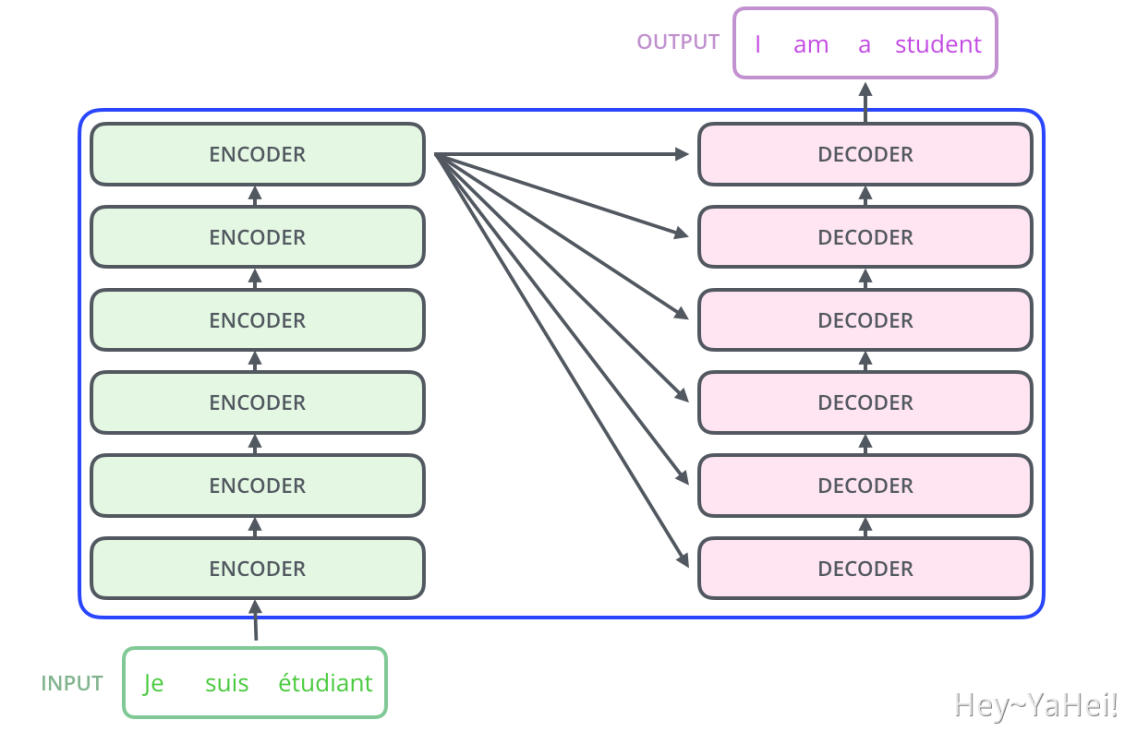
图中的Multi-Head Attention就是Self-Attention,Feed Forward就是两个全连接层(MLP)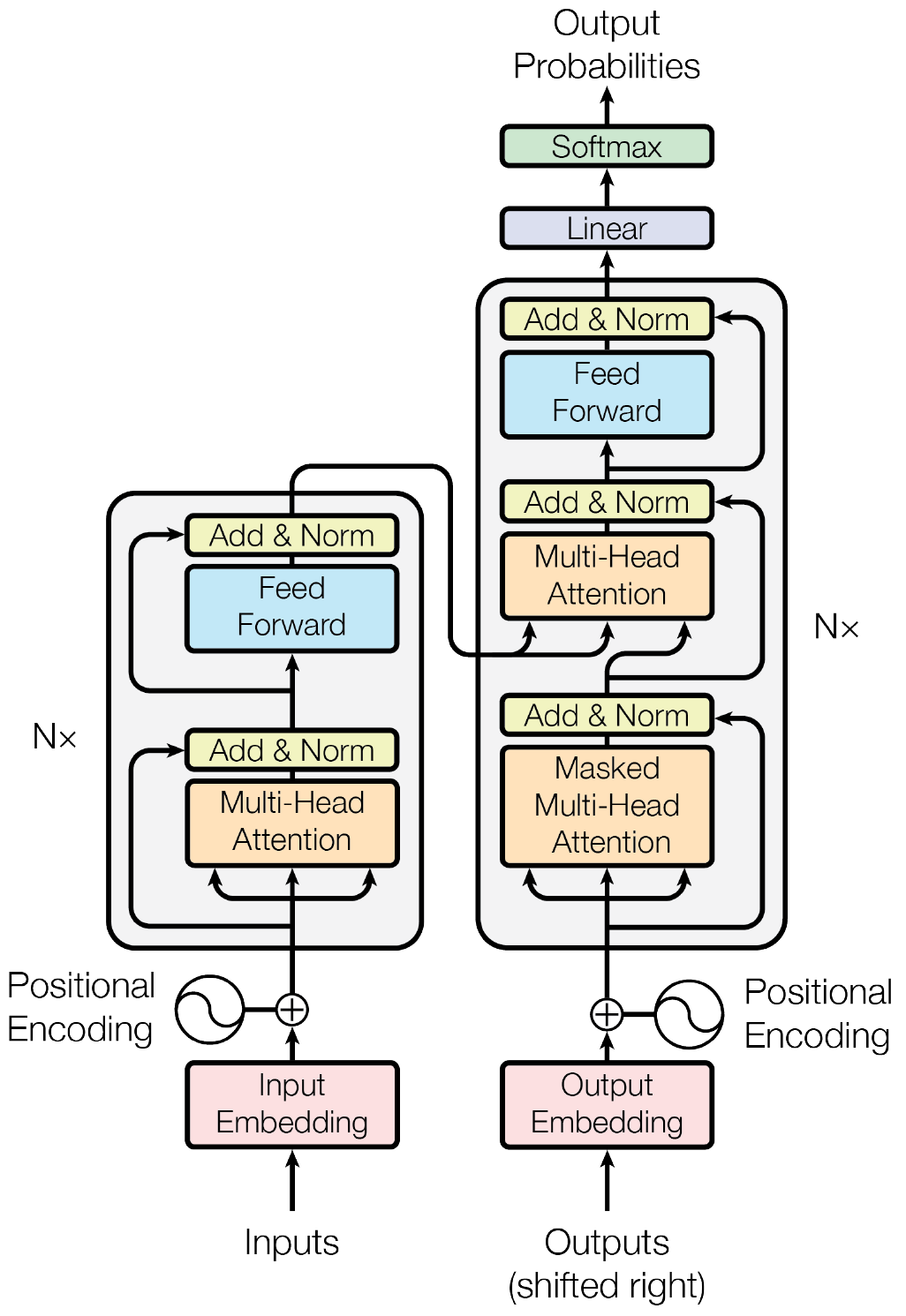
Self-Attention
Self-Attention即上图中的Multi-Head Attention,至于为什么被叫做Multi-Head我们之后再讲。
自注意力模块的输入 为
为 的向量,其中B为batch-size,L为序列长度(文中L=200),D为每个token的维度即每个向量的长度(文中D=512)。
的向量,其中B为batch-size,L为序列长度(文中L=200),D为每个token的维度即每个向量的长度(文中D=512)。 经过三个不同的权重矩阵
经过三个不同的权重矩阵 (均为512512)得到
(均为512512)得到 (query)、
(query)、 (key)、
(key)、 (value)三个同样为
(value)三个同样为 的向量。其中
的向量。其中 (key)表示每个token的索引;
(key)表示每个token的索引; (query)表示每个token在进一步特征提取时需要什么样的东西,与当前query越接近的key即越重要;
(query)表示每个token在进一步特征提取时需要什么样的东西,与当前query越接近的key即越重要; (value)表示每个token的特征。
(value)表示每个token的特征。
形象一点来描述就是 ,现在我们用
,现在我们用 去索引
去索引 ,看看哪些
,看看哪些 比较相似然后取出里面的
比较相似然后取出里面的 。反映成公式就是:
。反映成公式就是:
 是在计算所有
是在计算所有 与
与 的相似度,并除以
的相似度,并除以 、通过
、通过 归一化后,加权地取出
归一化后,加权地取出 的值。通过计算
的值。通过计算 与
与 的相似度,发现更为重要的
的相似度,发现更为重要的 ,即是Transformer基本的*注意力机制。
,即是Transformer基本的*注意力机制。
下图用一个简单的例子展示了这一过程。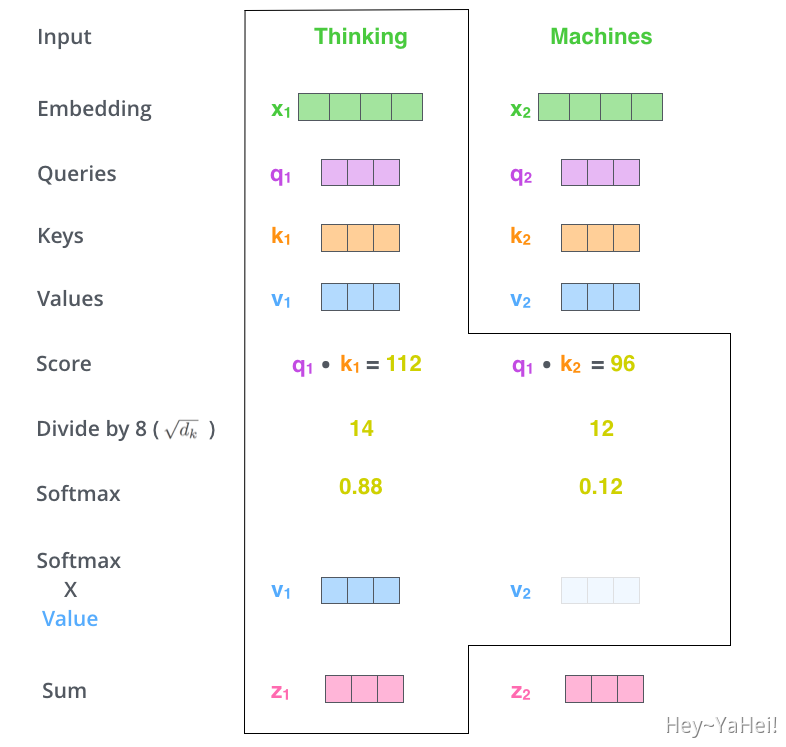
Transformer基础Block
def encoder(src_seq, src_mask):out = src_word_emb(src_seq) # B*L*D, where D=512out = position_enc(out) # Position Encodingout = LayerNorm(dropout(out, p=0.1), eps=1e-6)for enc_layer in layer_stack: # 6 encoder layersout = enc_layer(out, src_mask) # Main encoder blocksreturn outdef decoder(trg_seq, trg_mask, enc_output, src_mask)out = trg_word_emd(trg_seq) # B*L*D, where D=512out = position_enc(out) # Position Encodingout = LayerNorm(dropout(out, p=0.1), eps=1e-6)for dec_layer in layer_stack: # 6 decoder layersout = dec_layer(out, trg_mask, enc_output, enc_mask) # Main decoder blocksreturn outdef transformer(src_seq, trg_seq)src_mask = get_pad_mask(src_seq) # src_seq中补零的padding tokentrg_mask = get_pad_mask(trg_seq) & # trg_seq中补零的padding tokenget_subsequent_mask(trg_seq) # 不能看到之后位置的tokenenc_output = encoder(src_seq, src_mask)dec_output = decoder(trg_seq, trg_mask, enc_output, src_mask)seq_logit = trg_word_prj(dec_output) # 给token进行分类得到预测结果return seq_logit
Positional Encoding
RNN、LSTM等结果通过串行的顺序计算,显式地获取位置信息。Transformer把输入看为一个序列,在Self-Attention中序列中每个token的顺序并不影响Self-Attention的结果,这河里吗?不!这不河里!
Transformer在词嵌入(word embedding)后加了一个位置编码,用于表明序列中每个token的顺序与位置:
位置编码中融合了从高频 (i=0)至低频
(i=0)至低频 (i=D/2)的位置信息,被证实了能有效表示顺序与位置信息。
(i=D/2)的位置信息,被证实了能有效表示顺序与位置信息。
使用LayerNorm
在时序序列输入中,样本的长度可能发生变化(虽然是补齐到固定长度的),如果继续使用BatchNorm,样本长度的变化可能会造成巨大的影响:比如一个Batch中有长为1补零到1000的序列也有长为1000的序列,它们却被强制同一套BatchNorm参数。改用LayerNorm时不同长度的序列可以各自做Norm,受序列长度影响更小,更稳定。
Transformer Block
def attention(q, k, v, mask)attn = matmul(q, k.transpose(2, 3)) / sqrt(dk) # B*N*L*Lattn.fill(mask==0, -1e9) # masked the attn before softmaxattn = dropout(softmax(attn), p=0.1)y = matmul(attn, v) # B*N*L*dkreturn ydef multi_head_attention(src_q, src_k, src_v, mask)q = Wq(src_q).view(B, L, N, dk) # N为head数, N=8, dk=64k = Wk(src_k).view(B, L, N, dk)v = Wv(src_v).view(B, L, N, dk)q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)# `B L N dk` -> `B N L dk`out = multi_head_attention(x, mask)out = out.transpose(1, 2).view(B, L, -1) # `B N L dk`->`B L N dk`->`B L (N dk)`out = dropout(fc(out), p=0.1) # `B L (N dk)` -> `B L D`# 防止N*dk != D的情况out = LayerNorm(out + x) # shortcutreturn outdef feed_forward(x)out = relu(fc1(x)) # `B L D` -> `B L 4*D`out = dropout(out, p=0.1)out = fc2(out) # `B L 4*D` -> `B L D`out = LayerNorm(out)return outdef encoder_layer(x, mask)out = multi_head_attention(x, x, x, mask) # encoder中q k v均来源于xout = feed_forward(out)return outdef decoder_layer(x, trg_mask, enc_output, enc_mask)out = multi_head_attention(x, x, x, trg_mask) # masked MHA, 需要mask掉不该看的输出out = multi_head_attention(out, enc_output, enc_output)# q来源于decoder, k v来源于encoder, 相当于从encoder中获取需要的信息out = feed_forward(out)return out
Multi-Head Attention就是将 的的输入拆分为多组,分别计算
的的输入拆分为多组,分别计算 ,做多次Self-Attention,以求模型可以学到不同的注意力模式,有点类似于ResNeXt的分组卷积。文中是拆成8组,即head数为8,把
,做多次Self-Attention,以求模型可以学到不同的注意力模式,有点类似于ResNeXt的分组卷积。文中是拆成8组,即head数为8,把 拆为
拆为 。Decoder中的Decoder-Encoder的Multi-Head Attention中
。Decoder中的Decoder-Encoder的Multi-Head Attention中 来自于Encoder而
来自于Encoder而 来自于Decoder,即根据解码器寻找编码器输出中感兴趣的部分。
来自于Decoder,即根据解码器寻找编码器输出中感兴趣的部分。
Feed-Forward Network(FFN)就是两个单纯的全连接,先把通道数升为4倍再复原。
另外decoder中的Masked Multi-Head Attention与Multi-Head Attention的区别就是在于多了个输入的mask。在预测 处的输出时,decoder会将
处的输出时,decoder会将 处的输出作为输入,而transformer的self-attention是全局的,为了不让decoder看到
处的输出作为输入,而transformer的self-attention是全局的,为了不让decoder看到 中不该看到的来自将来的输出结果(训练过程中是通过label给出的),我们要将
中不该看到的来自将来的输出结果(训练过程中是通过label给出的),我们要将 中的输出结果mask掉(需要注意的是mask只作用于attention)。
中的输出结果mask掉(需要注意的是mask只作用于attention)。
复杂度分析
| Input | Output | Para | FLOPs | |
|---|---|---|---|---|
| QKV Project | L*D | N3L*dk | 3DD | 3LD*D |
| Attention | NLdk (Q), NLdk (K) | L*L | — | LLD |
| Assigned Value | LL (Attn), NLdk *(V) | NLdk | — | LLD |
| Output Project | LNdk | L*D | D*D | LDD |
| FFN_1 | L*D | L*4D | 4DD | 4LD*D |
| FFN_2 | L*4D | L*D | 4DD | 4LD*D |
| Total | 12DD | 2LLD+11LDD |
可以看到,Self-Attention部分的计算开销与序列长度呈二次关系,因此长序列输入的Self-Attention计算开销会很大。另外当 固定时,head的数量
固定时,head的数量 对参数量与计算量并无关联,这与ResNeXt的group-conv有所不同。
对参数量与计算量并无关联,这与ResNeXt的group-conv有所不同。
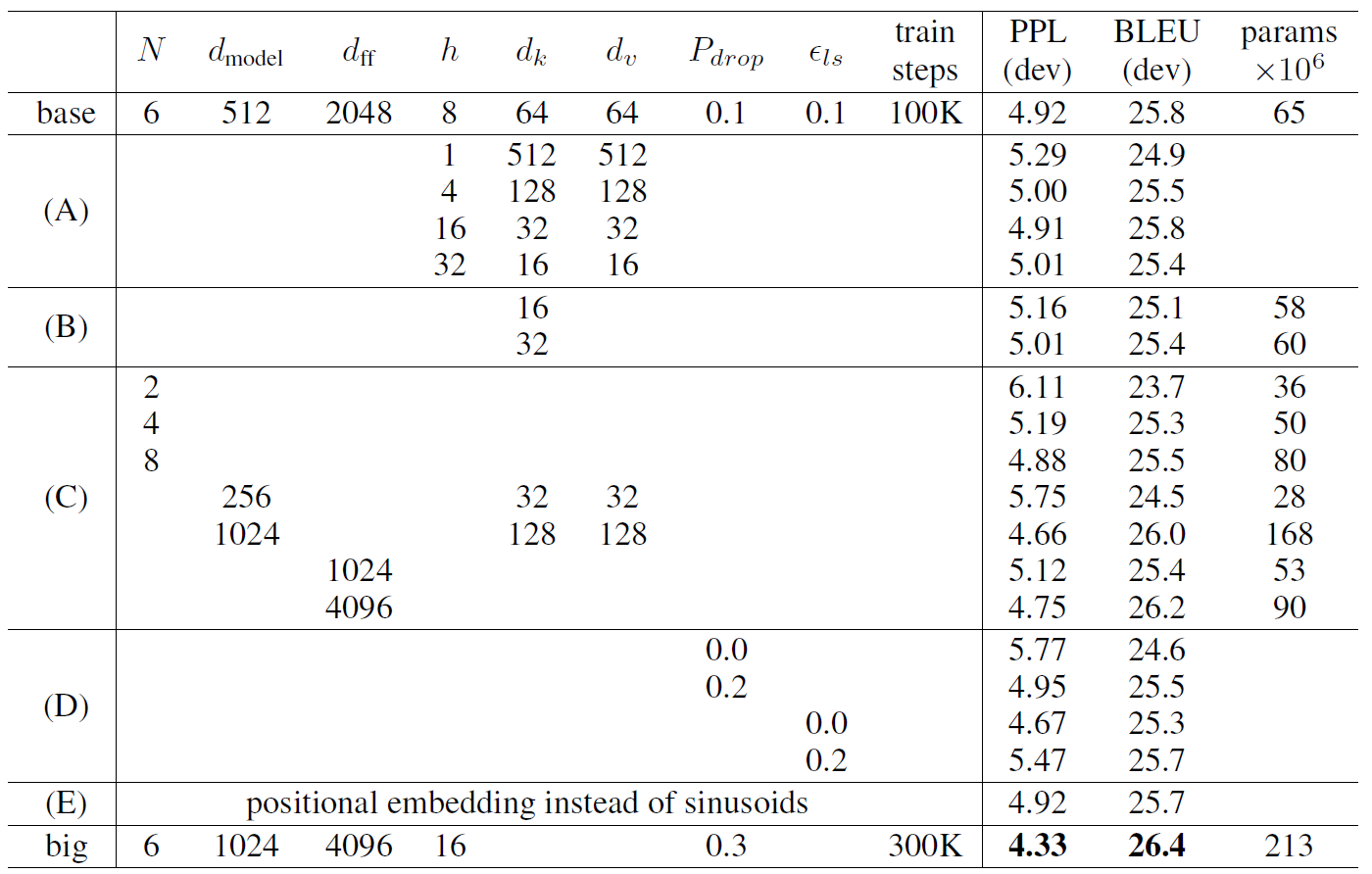
Ablation Study
ViT(ICLR2021)
《[An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》
论文:https://arxiv.org/pdf/2010.11929.pdf?ref=https://githubhelp.com
李沐:https://www.bilibili.com/video/BV15P4y137jb/?spm_id_from=333.788
将transformer用到CV里的开山鼻祖,将图片分割为没有重叠的patch序列化以后做Self-Attention,并通过纯注意力机制的Vision Transformer模型取得了媲美CNN的效果,挑战了2012年AlexNet以来CNN在CV领域的绝对统治地位。
ViT的弊端也非常明显,需要在足够多的数据上做预训练。当直接从ImageNet上训练时,ViT会弱于ResNet;但当经过大数据预训练后,ViT会反超ResNet。作者认为这个缺陷也是可预期的,因为CNN拥有很多先验,或者叫归纳偏置(inductive biases),即局部性与平移不变性。Transformer缺乏这样的先验,必须从足够多的数据中去学出来。
ViT结构
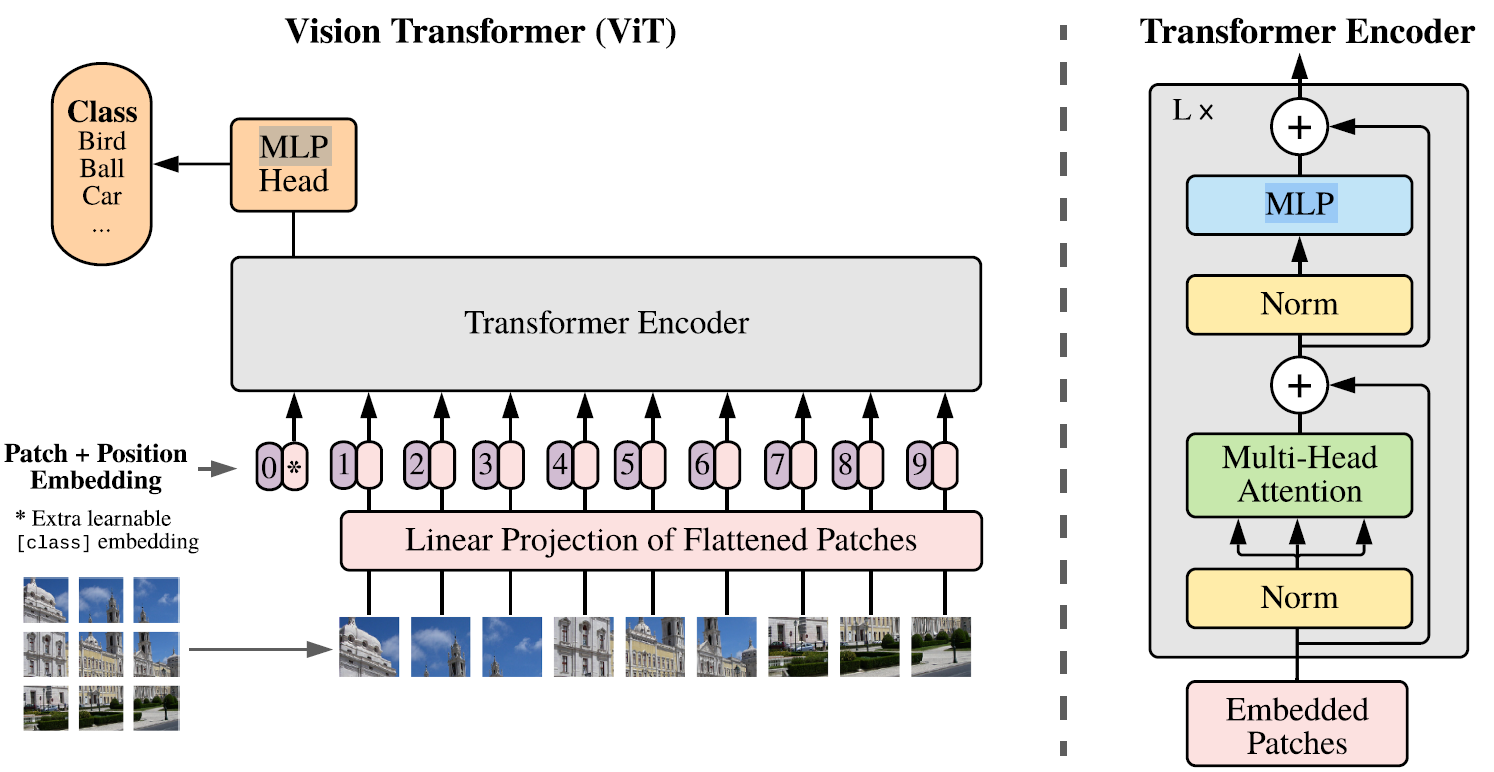
由于上一篇论文中我们讨论过,Self-Attention的复杂度和序列长度呈平方关系,如果将224224的图像直接按像素序列化,得到的序列长度是爆炸大的。也有一些工作在浅层进行卷积,然后把中间的feature-map拉出来扔进transformer。ViT是一个纯注意力机制的backbone,它直接在stem部分将输入图像分为patch,取patch的分辨率为1616,共得到14*14=196个patch,即ViT中序列长度为196。
3224224————>196316*16———>196*768————————->196*D————->197*D———->197*D
(割patch) (flatten) (linear projection) (cls token) (pos enc)
Transformer Block的输入接受了197个输入token,其中第一个token为可学习的class embedding,而其它196个token来自于patch的linear projection。linear projection可以理解为k16s16的卷积。
最后一个Block在class embedding处的输出被用于分类(最后一个Block的其它196个输出会被直接丢弃),因为NLP中的transformer也是这么干的。作者表示不加这个class embedding直接在最后一个block后做global average pooling后拉全连接也是可以的,效果类似。
Transformer Encoder的结构和之前的完全一样,只不过ViT不包含Decoder。Transformer从头到尾不会改变序列长度(L=197)与维度(D=768),与CNN中若干stage的金字塔结构有所不同。
Positional Encoding
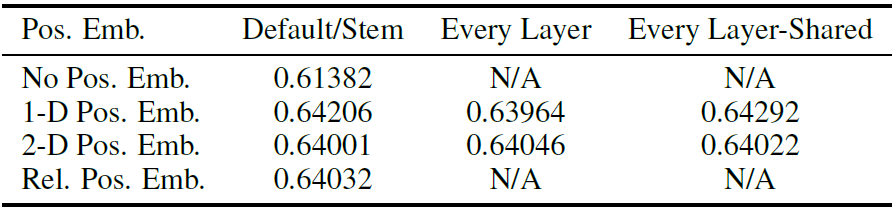
原始的Transformer中位置编码是写死的三角函数,但是ViT中的位置编码是可学习的。作者考虑了三种不同的位置编码方式:
- 没有位置编码
- 1D编码,196768;*(文中使用的)
- 2D编码,14384+14384;(可是这个难道不是开销更小?)
- 相对编码,这个好复杂因为结果做出来用哪种编码效果都差不多所以暂时偷个懒先不看hhhh
- 为啥不试试和原来transformer里一样写死的三角函数的位置编码?
下图展示了1D编码下,学出来的不同位置的编码与所有其它位置编码的相似度,可以看到即使是1D编码也是真的可以学出二维空间关联性的。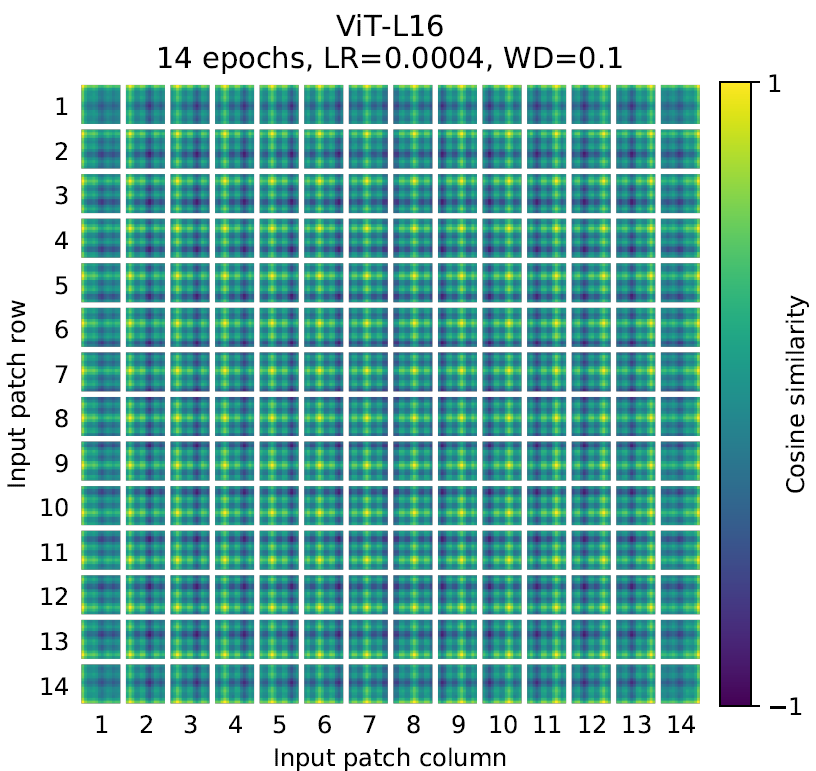
适配不同分辨率输入
对于Self-Attention部分,不同分辨率的输入对应不同的序列长度,这不会影响Self-Attention的计算,就和CNN可以处理不同分辨率的输入一样。
问题主要处在position encoding中,比如原来是196的序列长度,现在突然改成了256的序列长度,原来训出来的position encoding就没用了。ViT的作者表示直接对位置编码进行简单的2D插值即可(torch.interpolate),但是如果插值前后的序列长度差异过大,最终结果是会掉点的,这算是ViT在高分辨率fintune与接收不同分辨率输入时的一个局限性。
ViT模型

由于patch的大小会影响ViT的序列长度,从而也能影响模型的规模,作者将patch大小也计入了模型表示中。譬如ViT-B/16代表patch为1616的ViT-B(L=196),ViT-L/14代表patch为1414的ViT-L(L=256)。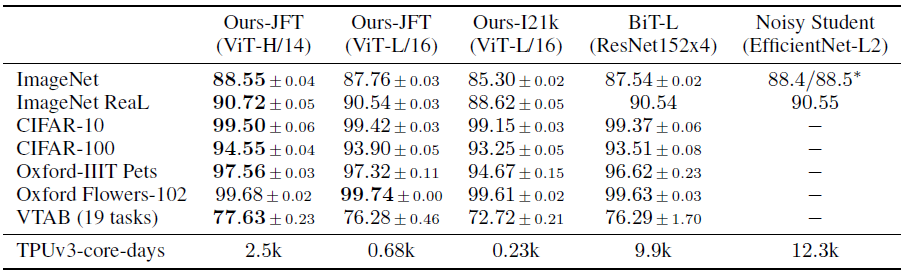
(↑↑↑上表中左边三列表示在什么数据集上预训练的)
作者还说ViT训练便宜,只要2.5k TPU-days,我一开始还少看了个k,我是真是信你个鬼!
ViT到底需要多少训练数据
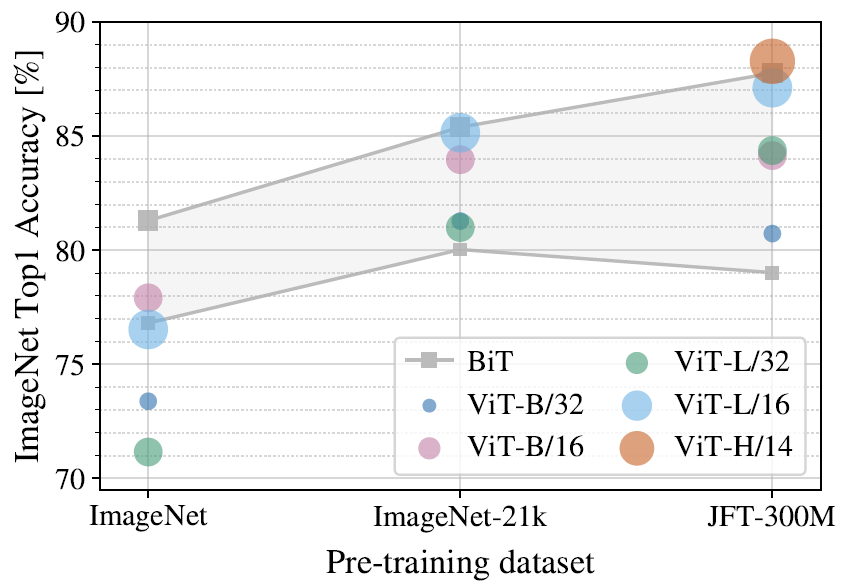
当只在ImageNet上训练时,ViT是全面不如的ResNet的。但当数据集规模上升后,ViT达到了接近ResNet甚至更好的结果。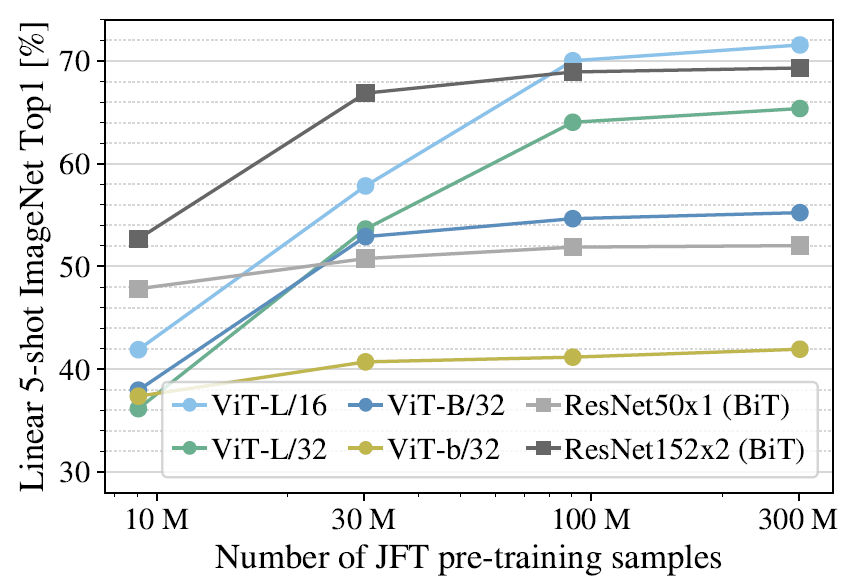
在不同训练图片数的JFT上预训练后,冻结模型只重新训练分类头的5-shot(每个类5张图)分类结果,算是完全考研backbone的特征提取能力了。
作者表示如何用ViT在小样本上做学习是一个很有前途的方向。(Swin Transformer加了先验感觉就好很多了,这个方向也可以再关注一下)
注意力机制的感受范围
Transformer相对于CNN最主要的优势就是全局感受野,特别是在浅层也能拥有覆盖整个输入图像的感受野。那么Transformer中各层的attention距离到底有多远呢?下图以ViT-L/16为例,计算了256张图像在各个层中16个Head的平均attention距离。(通过计算某一像素与其它所有像素基于Q-K attention加权的距离得出)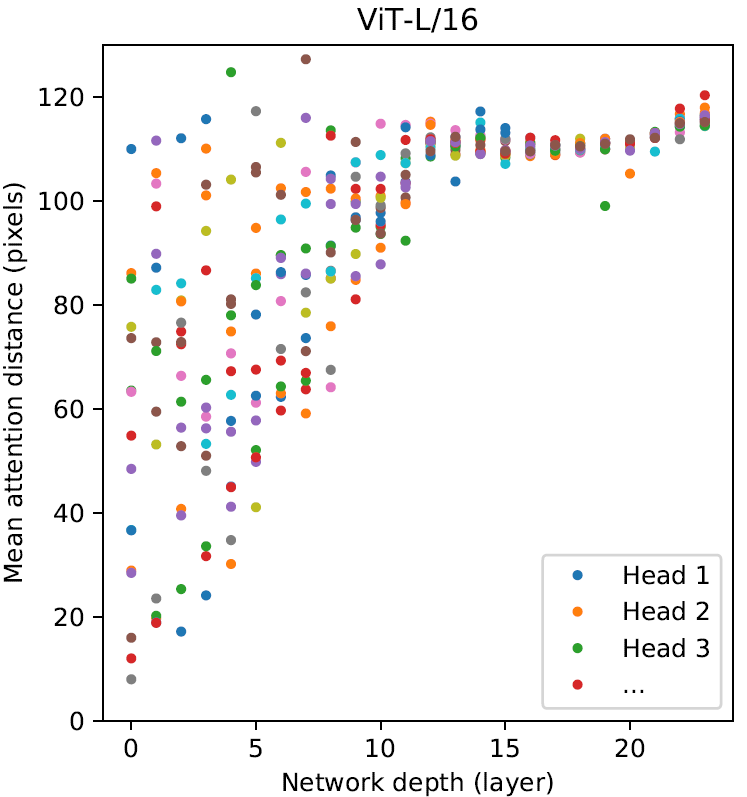
可以看到浅层不同Head有的注意到了局部特征,但也有Head注意到了非常远的全局特征。随着网络变深,所有Head都趋向于注意全局特征。
DeiT(ICML2021)
《Training data-efficient image transformers & distillation through attention》
论文:http://proceedings.mlr.press/v139/touvron21a/touvron21a.pdf
DeiT的名字来源于Data-efficient image Transformer,本文的主要贡献点:
- 作者展示了纯transformer也能在不用额外数据,在4GPU上训练三天就获得ImageNet SOTA的效果。
- 作者提出了一种transformer的蒸馏方法,在ViT增加cls token外额外又加了个distill token,且蒸馏是完全通过注意力机制实现的。
- 作者发现用CNN做教师网络比transformer效果更好。
作者提到,知识蒸馏可以通过软标签隐式地提供一种先验(inductive bias),从而指导缺乏先验的ViT的训练。
蒸馏方式
将教师网络的输出记为 ,学生网络的输出记为
,学生网络的输出记为 ,
, 代表ground-truth的one-hot label,
代表ground-truth的one-hot label, 代表教师网络输出的one-hot label(概率最大的那个类)。
代表教师网络输出的one-hot label(概率最大的那个类)。
Soft Distillation
Hard Distillation
非常神奇的,作者表示Hard Distillation的效果比传统基于KL散度的Soft Distillation效果更好,并且是parameter-free的,不需要调 这些超参,同时也可以利用smooth label实现软标签的效果。
这些超参,同时也可以利用smooth label实现软标签的效果。
Distillation token
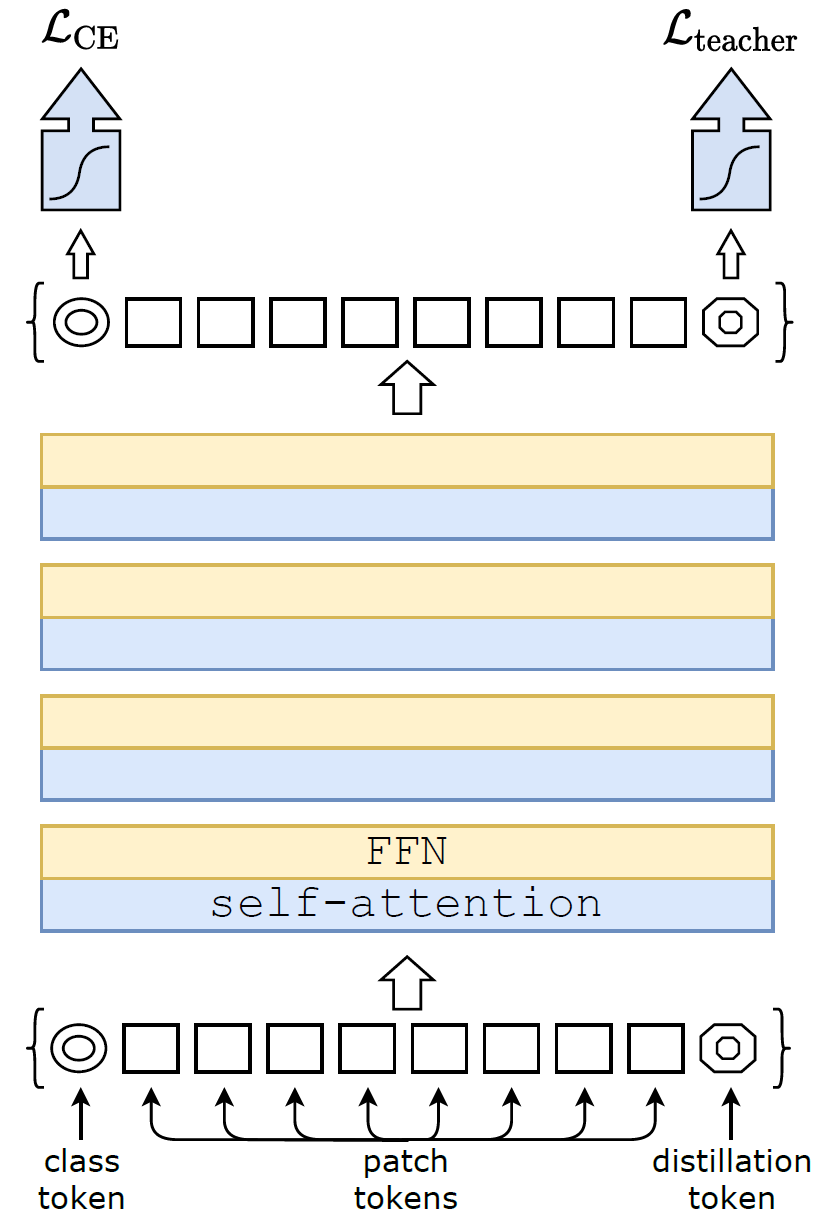
如上图整体架构所示,DeiT在patch embedding的时候除了加了class token外,还加了distillation token,因此序列的长度也从ViT的197增加到了198。在网络输出的时候,分别从class token处与distillation token处计算GT-CE loss与Distill loss。
作者发现学出来的class token与distillation token的相似度只有0.06(几乎正交),但是随着网络逐渐加深相似度逐渐变高,最终在输出层其相似度达到0.93(依然低于1),说明它们确实学到了不一样的东西。
高分辨率finetune
《Fixing the train-test resolution discrepancy》里提出,Test比Train分辨率更大效果会好很多,比如用160训练然后用224的分辨率finetune,推理也用224。
作者用“DeiT↑384”表示用384分辨率finetune的模型(实际推理也要用384所以开销是大很多的),并用非常魔幻的“DeiT⚗”表示使用了基于distill token的蒸馏方法。(我都不知道这个符号怎么打出来的orz)另外作者在高分辨率finetune阶段也用了上一节提出的蒸馏方法。
模型分析

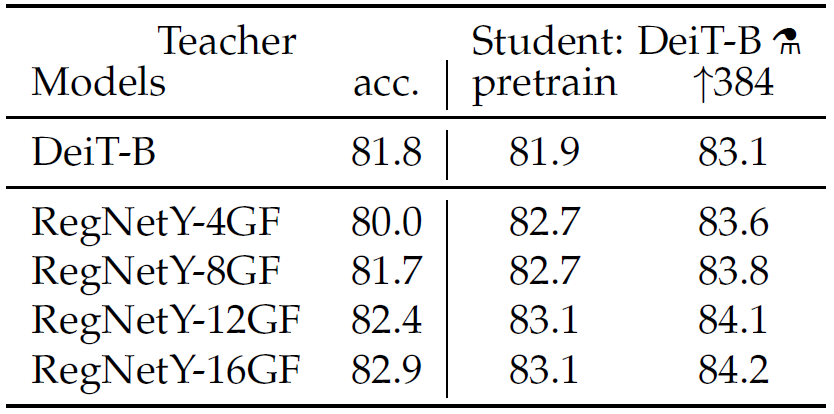
上表展示了不同教师网络的baseline性能,以及蒸馏得到的DeiT-B的准确度(标准训练以及用384分辨率finetune)。可以看出,使用CNN作为教师得到的学生网络效果更好,作者认为这是因为用CNN蒸馏使得作为学生的transformer继承得到了一部分先验(inductive bias)。因此在所有实验中作者使用了RegNetY-16GF作为教师网络。
实验结果
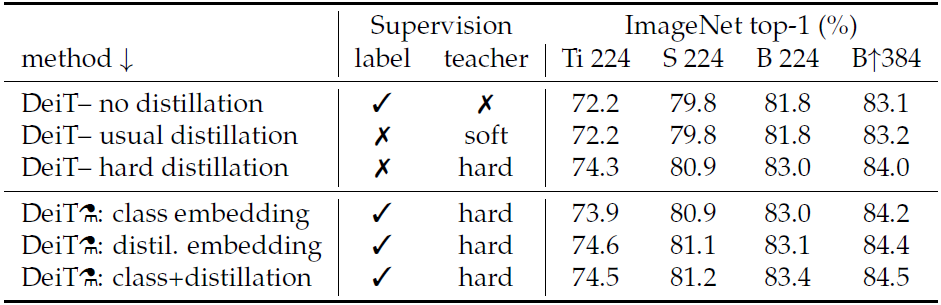
表中上面三行是没有distill token的,下三行表示论文提出的有distill token的蒸馏,并在最后一层输出时使用不同token进行预测的结果。
超参
*对于Soft-Distillation使用了 。
。
对比ViT的训练config: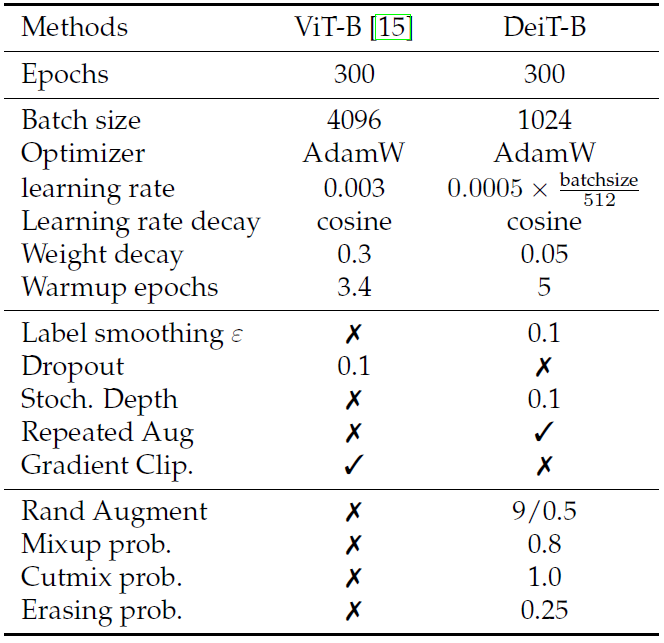
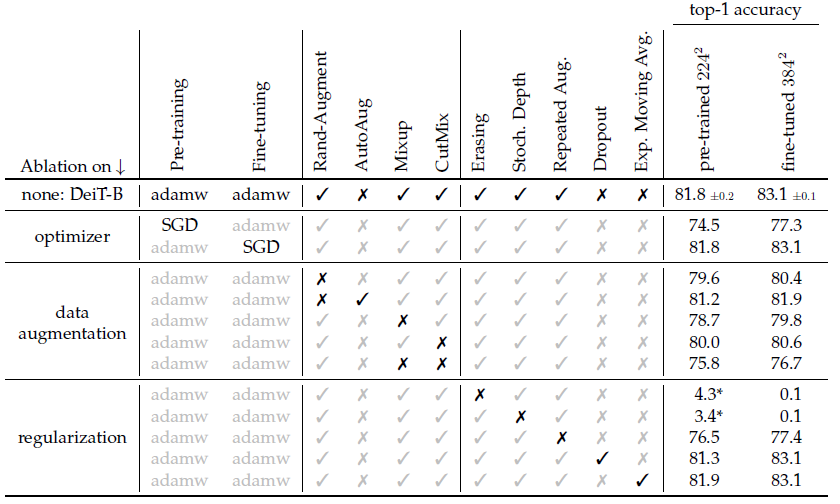
总而言之这篇文章不错,但是用了蒸馏和baseline的CNN和ViT比是不是多少有亿点不厚道……
Swin Transformer(ICCV2021)
论文:https://openaccess.thecvf.com/content/ICCV2021/papers/Liu_Swin_Transformer_Hierarchical_Vision_Transformer_Using_Shifted_Windows_ICCV_2021_paper.pdf
李沐:https://www.bilibili.com/video/BV13L4y1475U/?spm_id_from=333.788
传统的ViT无法获得多尺度的信息,全程的分辨率都一样,而Swin Transformer引入了类似CNN中多stage的金字塔结构。Swin Transformer将patch分为若干窗口分别做通过Self-Attention,并通过Shifted-windows实现窗口间的交互。
ViT只在ImageNet上做了分类实验,由于不包含高分辨率的特征,无法较好地去做检测、分割等下游任务。而Swin Transformer拥有多尺度特征,对下游任务适配地非常好,和CNN作为backbone的结构几乎完全一致。
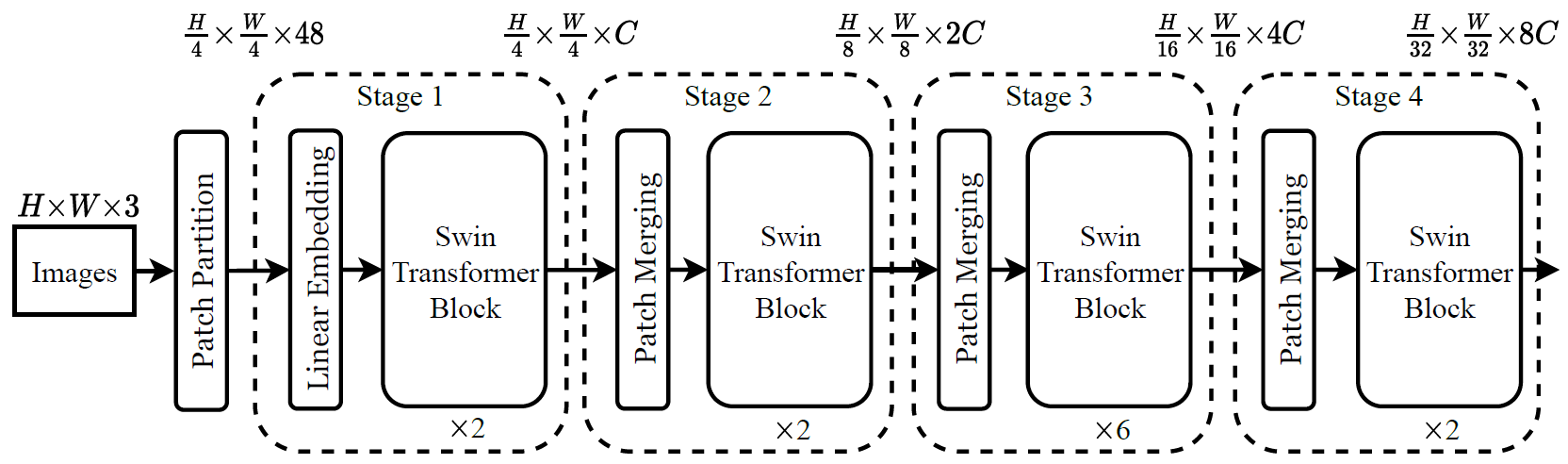
Swin Transformer结构
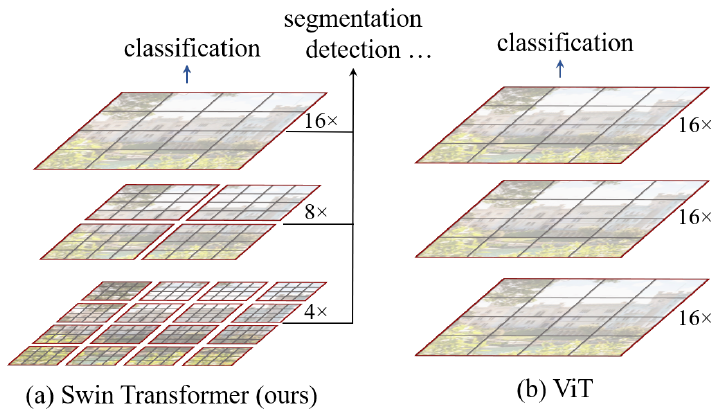
当应用于下游检测或分割等任务时,输入分辨率较大(譬如800*800),即使使用16倍下采样进行序列化,其序列长度依然大的难以接受(BERT的1024已经非常大了)。
不同于ViT全程patch大小都是16*16并包含196个patch,Swin Transformer共分为4个stage。其中:
- stage-1的patch大小为44,包含5656个patch;每个Self-Attention窗口包含7*7个patch,共64窗口;
- stage-2的patch大小为88,包含2828个patch;每个Self-Attention窗口包含7*7个patch,共16窗口;
- stage-3的patch大小为1616,包含1414个patch;每个Self-Attention窗口包含7*7个patch,共4窗口;
- stage-4的patch大小为3232,包含77个patch;每个Self-Attention窗口包含7*7个patch,共1窗口。
当输入分辨率从 增加到
增加到 时,不同于ViT中序列长度增大
时,不同于ViT中序列长度增大 倍从而导致Self-Attention的计算开销呈
倍从而导致Self-Attention的计算开销呈 倍增长;Swin Transformer中仅仅窗口的数量增加了
倍增长;Swin Transformer中仅仅窗口的数量增加了 倍,计算开销也仅增加
倍,计算开销也仅增加 倍。这种操作也利用了CNN中广为使用的locality的先验(inductive bias)。
倍。这种操作也利用了CNN中广为使用的locality的先验(inductive bias)。
在做分类时,不同于ViT从class token处取特征向量而丢弃其它token的输出,Swin Transformer用了和CNN类似的Global Average Pooling来生成最终的特征向量。
Shifted Windows
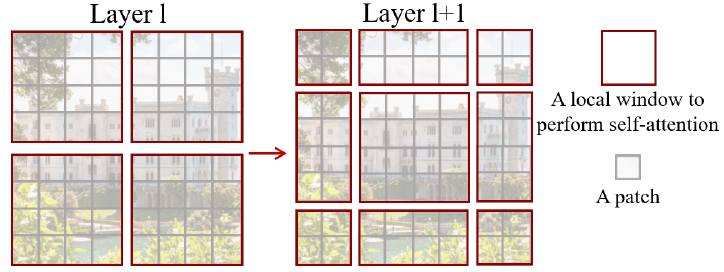
上面这张示意图展示了Shifted Windows的基本工作原理。每个灰色的小框是一个patch,而红色的框即是计算Self-Attention的单元,在论文中被固定为7*7个patch(即序列长度L=49)。
在CNN中,卷积是overlapped的操作,而Transformer中的Self-Attention是non-overlapped的,因此如果不加干预则不同窗口之间无法进行信息交互 (如果把窗口划分作为overlapped的会咋样?)。为了使得窗口可以相互交互,论文提出了一重Shifted Windows的方法,即把每个窗口往右下移动了2个patch,如上图所示。因此Swin Transformer的基本单元包含两个block,每个stage的block数必须为偶数。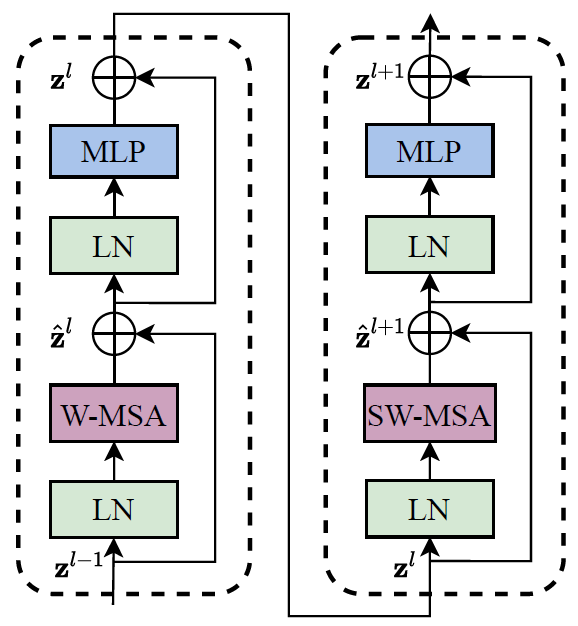
新的风暴又出现了,Shifted Windows虽然可以实现窗口间的交互,但是增加了窗口的数量,且不同窗口包含的patch数不同,不利于并行(除非把角落的窗口补零成和中间一样大)。作者在论文中提出了一种非常巧妙的掩码方式,具体参照李沐视频39分钟或源代码,这里就先不展开讲了。(简直是七巧板啊家人们!)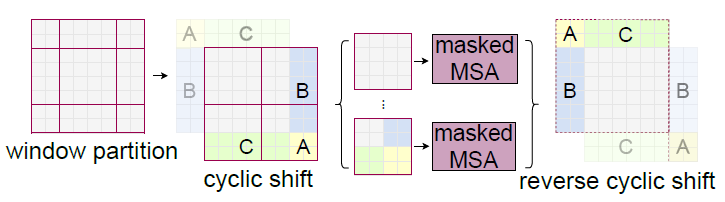
Patch Merging
参考李沐视频24分钟,源代码:
class PatchMerging(nn.Module):
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x
(可是我感觉这就是个k2s2的卷积啊!咋搞这么复杂)
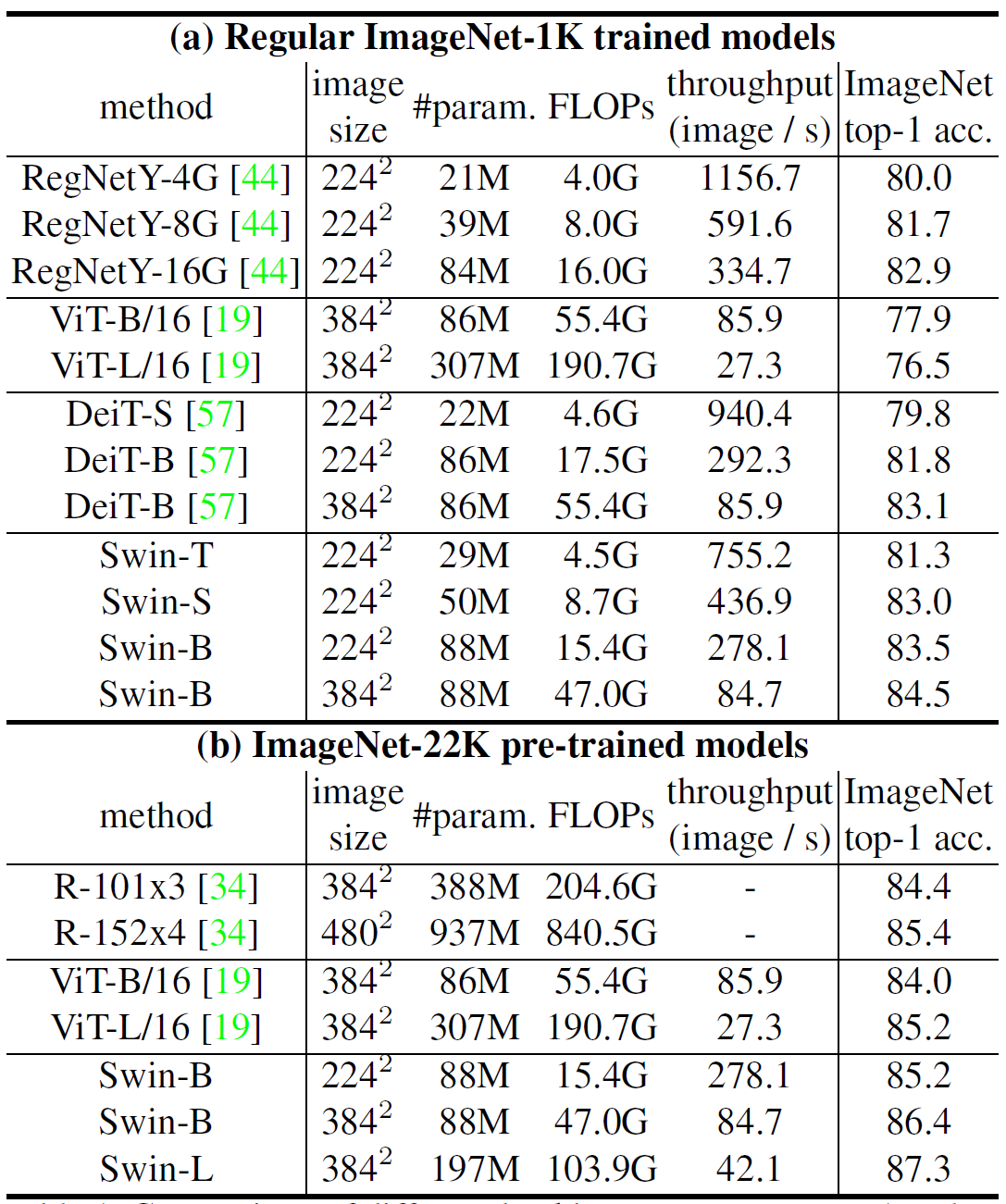
实验结果

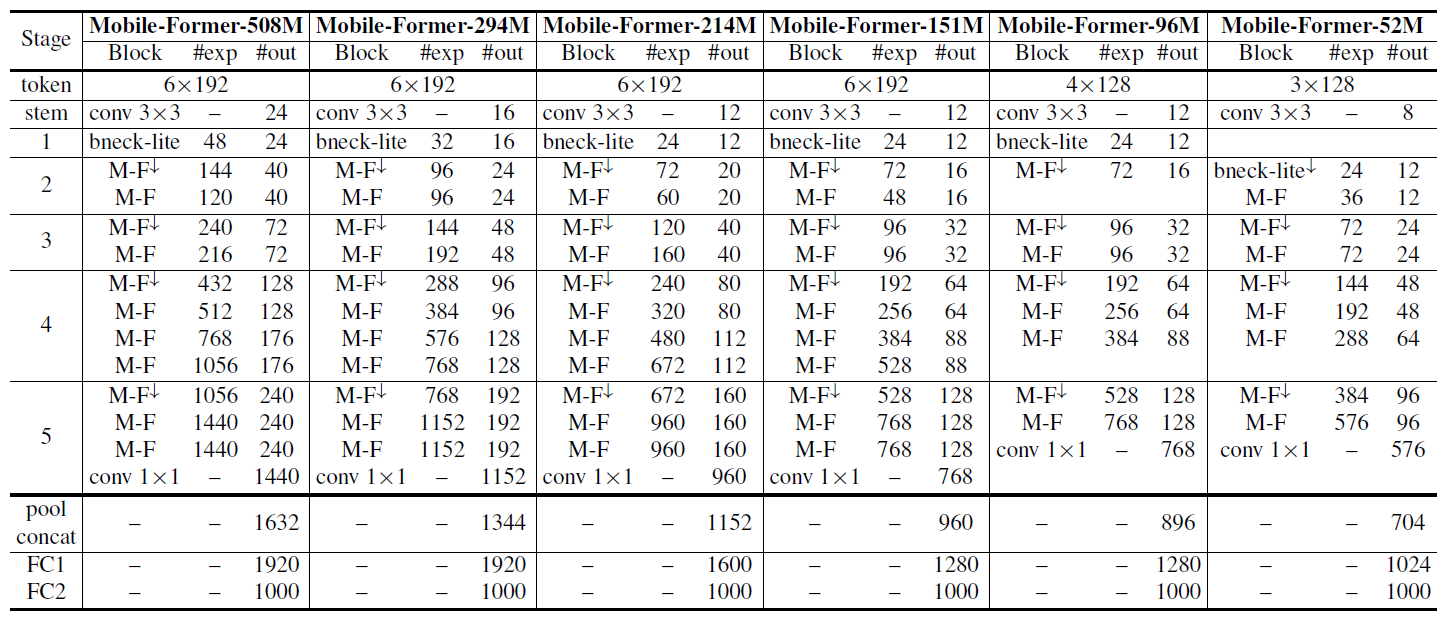
Mobile-Former(CVPR2022)
论文:https://arxiv.org/pdf/2108.05895.pdf?ref=https://githubhelp.com
git:https://github.com/slwang9353/MobileFormer/tree/d2f1a0d37a207f102337a61b908122f6e20ddf16
Mobile-Former提出了一种结合MobileNet与Transformer的backbone,使得网络可以同时获得CNN局部纹理特征提取能力与Transformer的全局注意力。论文的核心思想:How to design efficient networks to effectively encode both local processing and global interaction?
网络结构
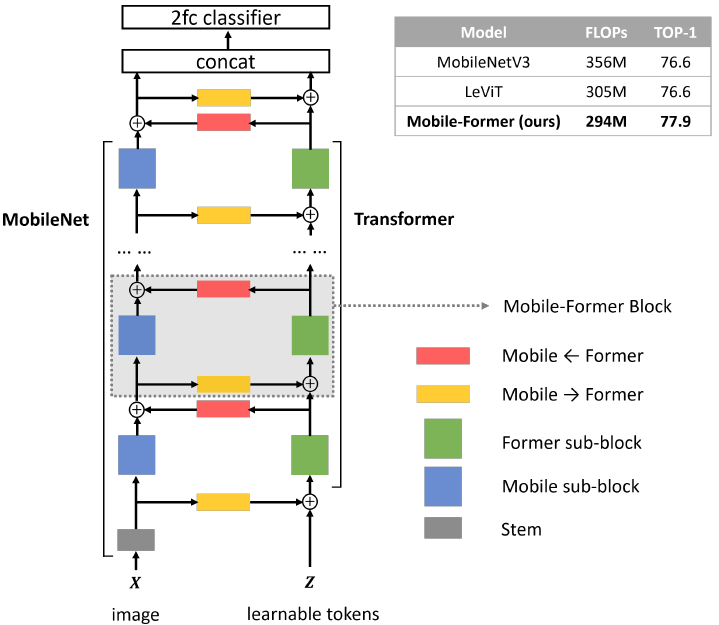
网络结构总览图中,左边分支是MobileNet的网络,右边分支是Transformer,两个分支通过Mobile←Former与Mobile→Former进行双向交互。
在ViT中,序列的长度高达196。而在Mobile-Former中,Transformer分支只是对CNN缺乏的全局信息的补充,在文中作者只取了 的token序列长度,因为非常轻量化。
的token序列长度,因为非常轻量化。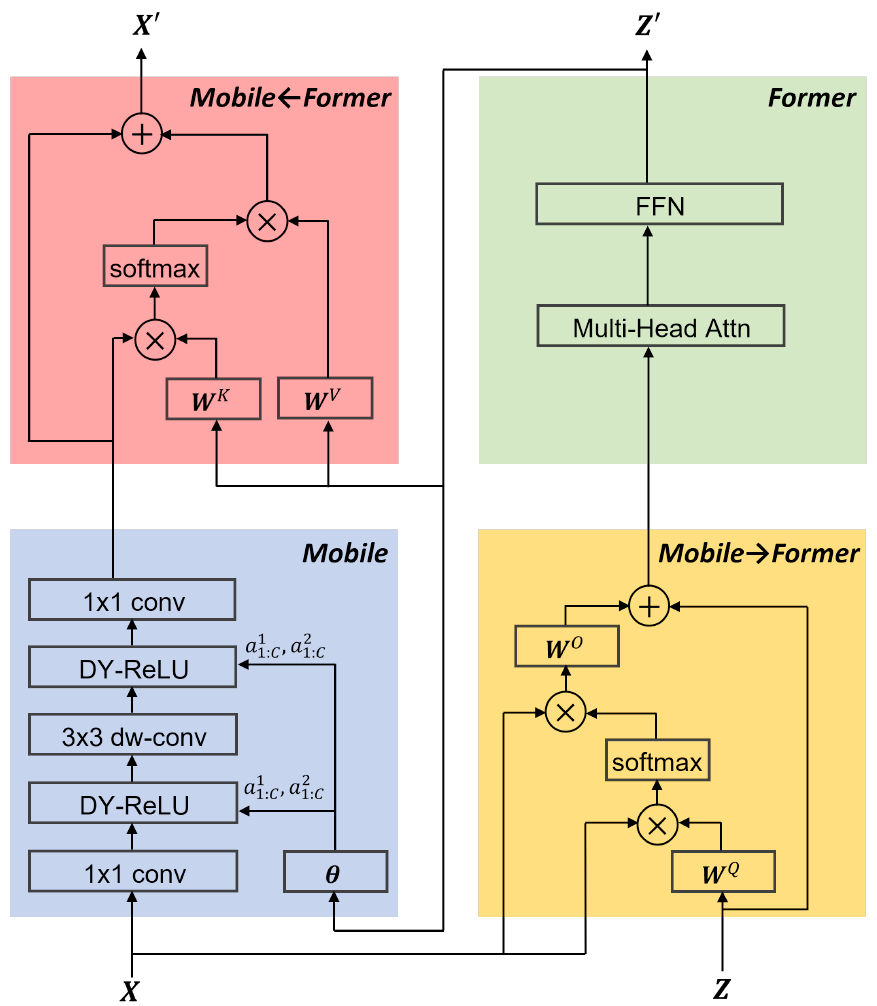
Mobile
Mobile->Former
Mobile2Former其实也是一个Transformer的QKV Self-Attention,其中 是来自于CNN的输入
是来自于CNN的输入 的,且为了节省开销
的,且为了节省开销 被省略,
被省略, 经过重排以后(’B C H W’ -> ‘B H*W C’)被直接当做了
经过重排以后(’B C H W’ -> ‘B H*W C’)被直接当做了 。Mobile2Former的输出为(M d),分别表示序列长度和序列维度。
。Mobile2Former的输出为(M d),分别表示序列长度和序列维度。
Mobile2Former中的 对的数量非常多,但是作为Former数据通路的
对的数量非常多,但是作为Former数据通路的 的数量却很少(
的数量却很少( )因此Self Attention算起来复杂度从
)因此Self Attention算起来复杂度从 降低为了
降低为了 。
。
Former->Mobile
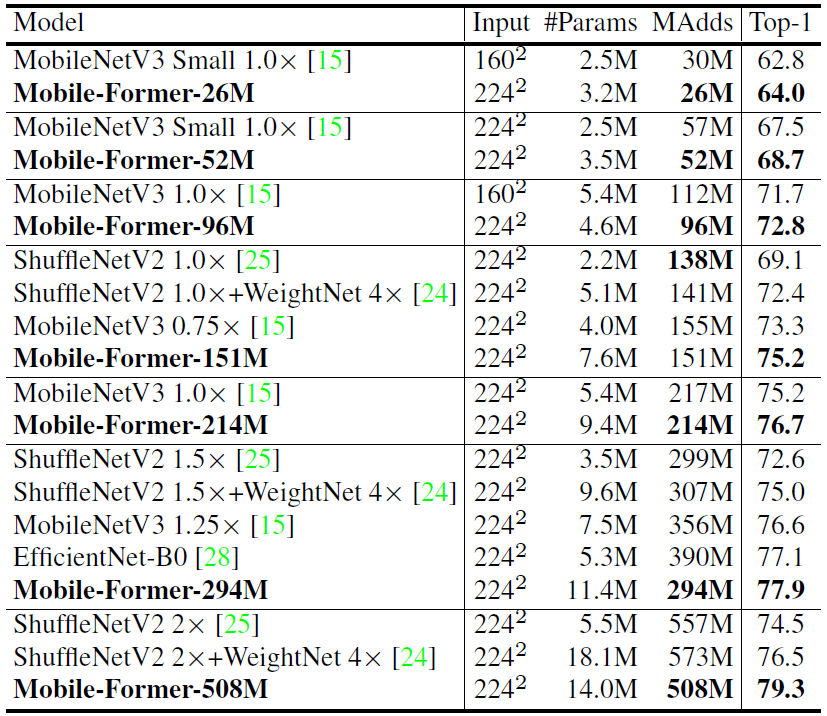
实验结果
Augmenting Convolutional networks with attention-based aggregation

若有收获,就点个赞吧
0 人点赞
