MobileNet
MobileNet v1(2017.04)
论文:https://arxiv.org/pdf/1704.04861.pdf
主要贡献
- 用深度可分离卷积(dw卷积+pw卷积组合特征)替代传统卷积,大幅提高卷积效率
- 利用dw卷积设计出了高效的直筒网络MobileNet
基本思想
MobileNet使用了深度可分离卷积(dw卷积),将传统的3x3卷积拆分为了一个通道内的3x3 depthwise卷积和1x1 pointwise卷积,实现了非常好的模型压缩与加速效果。
下图(a)为传统的3x3卷积,(b)为dw卷积(相当于group数与通道数相同的卷积),(c)为1x1pw卷积。
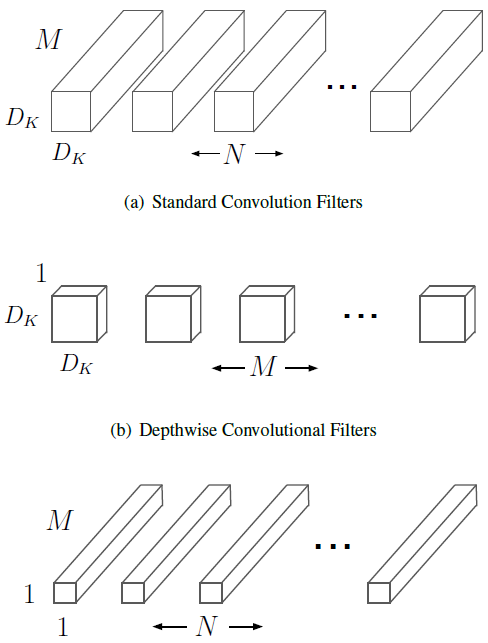
当用深度可分离卷积替代3x3卷积时,计算量减小了8~9倍,当卷积核大的时候(譬如5x5、7x7,虽然在轻量化网络中它们应该不可能存在)提速的倍率更高。如果用GEMM(矩阵乘法算子)做卷积的话要做im2col,1x1卷积该开销非常小,也不需要额外显存(im2col会使得显存开销变为Filter*Filter倍)。
论文里说1x1卷积不需要做im2col,说的不太准确。采用通常的N·C·H·W排布时,在用GEMM计算卷积时依然需要做一次内存重排,如果将Tensor采用N·H·W·C排布那就不需要任何im2col操作,但是卷积算完会呈N·C·H·W排布,需要变回来。←←←这就是出来混迟早要还的=。=
网络结构
MobileNet是一种直筒网络,没有残差结构。另外接受输入的3x3卷积(输入通道为3)是一个例外,执行完整的传统卷积;其它卷积层全部用深度可分离卷积替换。
下图是MobileNet的标准结构,可以看出网络有5个stage,卷积层数为[1, 2, 2, 6, 2](dw+pw算一层),总共28层权重层。
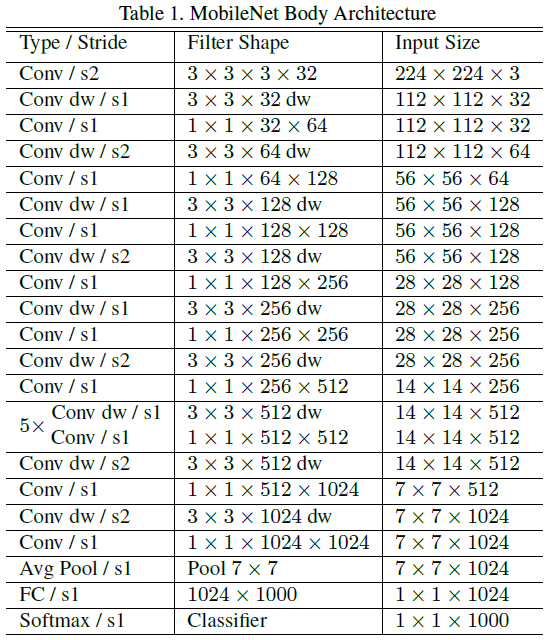
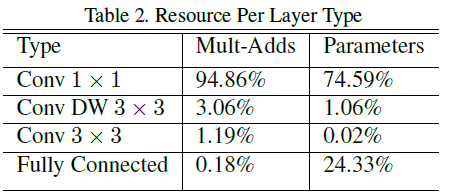
另外,网络超过九成的计算量都集中在1x1卷积。(虽然不能直接通过FLOPS判断开销分布,毕竟dw卷积会有访存问题)。另外由于dw卷积参数数量非常少,应该对其施加非常小的L2 decay或者不加(1x1 pw卷积可加)。
实验结果
在MobileNet网络结构的基础上,采用dw卷积相比不采用dw卷积,在ImageNet上精度只下降了1%,但计算量减小了9倍、参数数量减小了7倍。(可以做做看FLOPS相同时是否采用dw卷积的精度?)

在进一步压缩网络复杂度时,削减深度(去除stage4的5层1414512时的卷积)与削减宽度的对比。可以看出由于MobileNet实际上只有13层卷积,再削减深度带来的精度下降更剧烈。因此MobileNet砍宽度和输入大小都不能再砍深度!
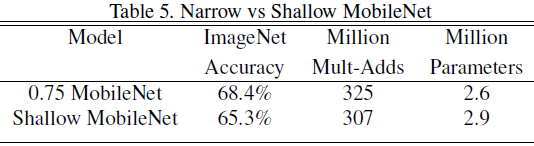
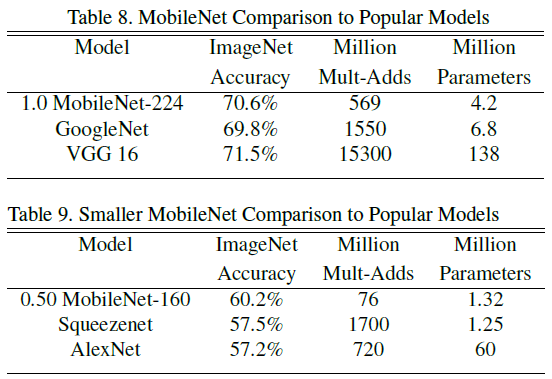
在标准的<1.0 MobileNet-224>的基础上进一步压缩网络宽度、输入大小:
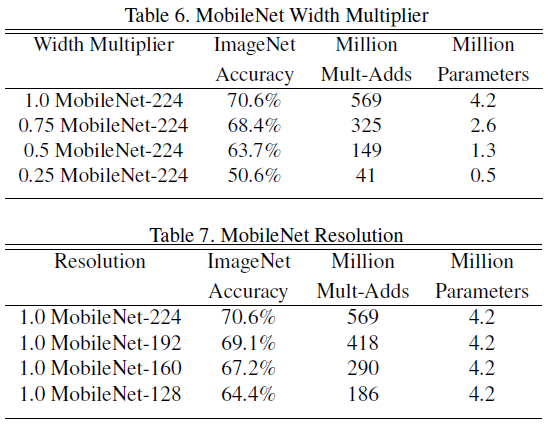
将<准确度-log(FLOPS)>作图,可以看出当FLOPS再100M以上时,准确度与log(FLOPS)基本呈线性关系;100M FLOPS是一个拐点,FLOPS小于100M的模型过于简陋导致精度的急剧下降。
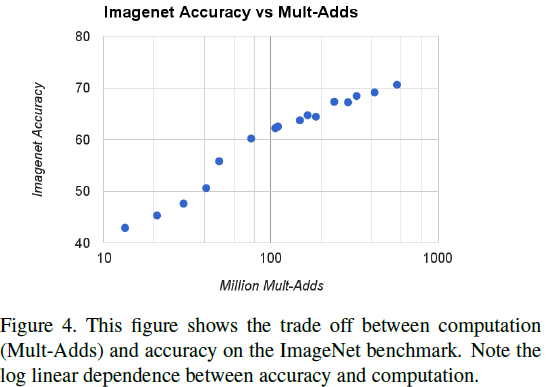
对比其它知名网络结构(严重怀疑这个Squeezenet的1700M FLOPS是怎么算出来的):
MobileNet v2(2018.01)
论文:https://arxiv.org/pdf/1801.04381v3.pdf
主要贡献
- 提出通道收缩时采用非线性激活会带来信息丢失,取消了Bottleneck中用于通道收缩的1x1卷积后的非线性
- 将ReLU改为ReLU6限制激活的输出范围(除了方便量化没说有什么用)
- 引入了反残差结构,由于dw卷积计算量小,在block内构建<通道扩增-dw卷积-通道收缩>的结构,扩增dw卷积的输入输出通道,这么做有利于特征提取。
Linear Bottleneck
论文中把激活输出特征称为兴趣流形(mainfold of interest),用词之难懂真的无力吐槽……
长期以来我们一直认为,神经网络提取到的各式各样的特征能够被嵌入到一个低维空间。卷积层中每个通道的输出中都存在着多种编码信息,兴趣流形也隐含于其中,我们可以通过降维将其嵌入至低维子空间中。
MobileNet v1正是利用了宽度因子进行宽度压缩(降维),在计算量与精度中取折中。用上面的理论来说,宽度因子控制着激活输出特征空间的维度,直到兴趣流形占满整个输出空间(类似矩阵满秩无法降维的感觉)。
但由于非线性激活函数的存在,譬如ReLU,会让激活空间坍塌(因为负数全变0了),不可避免地造成信息丢失。当我们对一个通道(维度)作用ReLU时,造成了该通道地坍塌;但如果我们拥有足够多地通道数,且神经网络提取到地各个通道的特征是相互冗余的,丢失的信息就依然能够被其它通道保留下来。
文中作者距离将螺旋线团经随机矩阵 变换嵌入N维空间后,过ReLU,再通过
变换嵌入N维空间后,过ReLU,再通过 投影回2D平面:
投影回2D平面:
可以看出当通道数比较少时,螺旋中心发生了坍塌,造成了大量的信息丢失;而通道数较多时,ReLU带来的信息丢失就少了很多。作者提出,当输入的兴趣流形能够嵌入比输入维度低很多维度的空间时,引入ReLU能够在引入非线性、增加模型复杂度的同时很好地保留信息。
因此,在普通卷积与通道扩增之后可以引入ReLU,但在通道压缩时不宜引入ReLU。进而作者提出了Linear Bottleneck,在压缩通道的权重层后不加非线性,作为一个线性层以防止信息丢失。另外作者还发现,对于带短连接的网络结构,非线性带来的信息丢失会少一些。
反残差结构
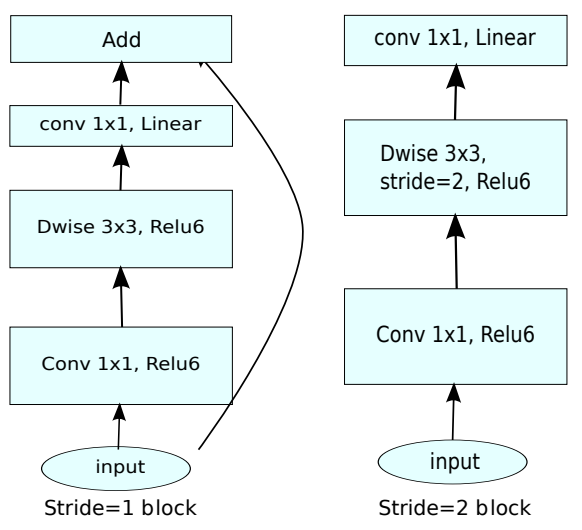
MobileNet v2引入了类似ResNet的短连接结构,但是不同于ResNet Bottleneck为了减小计算量将网络堆得更深而压缩3x3卷积的宽度所采用的<通道收缩-3x3卷积-通道扩增>结构,MobileNet v2的3x3卷积采用dw卷积,计算量较小,采用了相反的<通道扩增-3x3 dw卷积-通道收缩>的结构,并且在最后一个用于收缩通道的1x1卷积不用ReLU。
下图左为ResNet Bottleneck,右为MobileNet v2。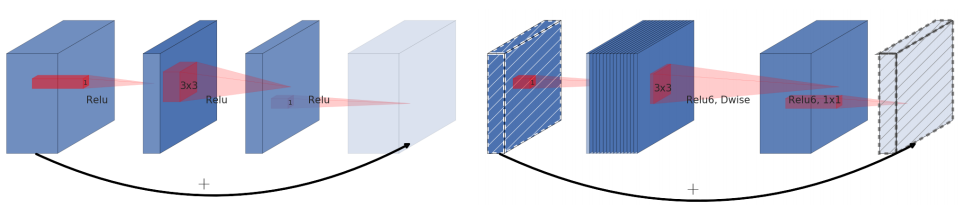
另外,短连接只在stride=1时使用,设计下采样的block采用直筒设计。且不同于ResNet,MobileNet v2的短连接在元素级相加后没有ReLU!!!
作者说做实验做出来这么好,我也不知道,他说是就是8。
内存开销分析
这种卷积模式非常适用于移动端设备,由于其不需要对中间过程的大Tensor进行实例化,可大大减小推理阶段的内存开销。MobileNet v2每个block中最宽的阶段位于通道扩增以后,用于存储该中间Tensor是内存开销最大的时候。作者提出了一种分治-dp算法,使得该中间Tensor不需要全部放于内存中,大大减小了内存开销。
用于扩增通道的1x1卷积可以一部分一部分做,譬如input_c=24、output_c=24、expansion=6(hid_c=144)的block,用于扩增通道的1x1卷积我们可以分9次做,每次只输出16个通道,总共做9次。由于dw卷积只需要在通道内做,不依赖整个input Tensor,我们直接对这16个通道做dw卷积后,利用dp的思想将输出堆叠到output buffer中,而不需要存储dw卷积的输入Tensor与输出Tensor两个宽度大的Tensor。
最极端的做法是block开头用于扩增通道的1x1卷积每次只输出1个通道,总共做144次,这样需要存储的中间Tensor更小。但根据木桶原理,此时输入输出Tensor比中间Tensor大,系统内存占用取决于输入输出Tensor。
def InvertedBottleneck(x, t, input_c=24, output_c=24): # t为分治的划分数量expansion = 6hid_c = input_c * expansionc_perround = hid_c / tcur_c = 0output = Tensor([x.shape(0), output_c, x.shape(2), x.shape(3)]) # x.shape(0)为batchsizewhile cur_c < hid_c:next_c = min(cur_c + c_perround, hid_c)dw_input = relu(bn(Conv(w_1x1amp[cur_c : next_c], x))) # 16*56*56dw_output = relu(bn(Conv(w_dw, x))) # 16*56*56for co in range(output_c):output[co] += dw_output * w_1x1shrink[co, cur_c : next_c]return bn(output) + x
目前库函数中CPU端都是正常的一层一层计算,除非自己改算子。因此调库的话都是v2的内存开销会大于v1(郑老师测出来v2占60M内存,v1占50M内存)。郑老师说用FPGA推理这种算法很有用,因为FPGA对内存极度敏感。
作者自己也说了,由于更多的cache-miss,使用该分治-dp算法会造成运行速度下降。论文中n表示隐藏层的宽度,通常n为 ;t表示分治的划分数量,即总共进行多少轮划分。作者表示,当划分轮数t位于2~5时算法的效果最好,对速度的影响不会太大同时又能显著减小内存开销。
;t表示分治的划分数量,即总共进行多少轮划分。作者表示,当划分轮数t位于2~5时算法的效果最好,对速度的影响不会太大同时又能显著减小内存开销。
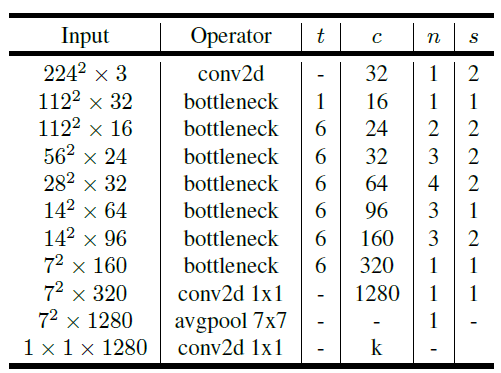
网络结构
其中t为Bottleneck第一个1x1卷积的扩展率,如果扩展率为1则去除该block用于扩增通道的1x1卷积,直接做3x3dw卷积。c为输出通道数,n为堆叠数量,s为stride。
与ResNet Bottleneck结构不同,由于MobileNet v2的Bottleneck是先扩增通道再收缩通道的,每个block的输出通道都非常小,因此最后送入全连接前会接一个用于扩增通道的1x1卷积。并且作者提出,当网络的宽度因子width_mult小于1时,其不对最后一个用于扩增通道的1x1卷积起作用,确保全连接层的输入宽度足够大。该层卷积可以表示为:Conv(320 width_mult, 1280 max(1.0, width_mult))。作者认为这么做能提高小网络的精度。
作者提出t为5~10时的效果都几乎相同,但对于小网络较小的t更为合适,对于大网络稍大的t更为合适。
另外最后的1x1卷积与avgpool交换次序后结果是不同的,因为1x1卷积后跟了ReLU。但具体交换以后对效果有没有影响,这部分计算量减小会不会有副作用,没做过实验。虽然这个1x1看着似乎开销大因为通道多,但是再整个网络看来也没特别大,毕竟Block中的1x1卷积的开销是要算上expansion的。
实验结果
ImageNet训练config:
RMSProp(momentum=0.9, weight_decay=4e-5),bs=96,lr=0.045,指数衰减每个epc x0.98
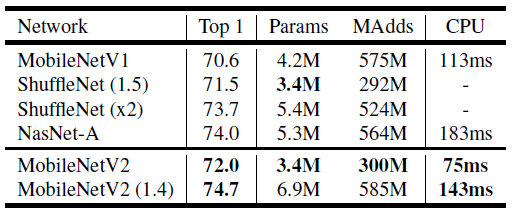
gluoncv训出来的model zoo里MobileNet v1是比MobileNet v2好的,就很神奇。
MobileNet v3(2019.05)
论文:https://arxiv.org/pdf/1905.02244.pdf
网络搜索
用到了NAS用于搜索网络结构、NetAdapt用于搜索网络宽度(有卡人才做的起的实验我甚至不想记实验细节)
不过里面提高的用于估计网络最终准确度的方法值得借鉴,只训10000step根据此时的准确度差距判断训收敛以后的准确度差距。(如果可行的话可以大大减小以后以后做实验的开销)
搜完了以后作者还自己调了模型,去除或压缩了一些开销大的层。譬如作者将最后的Classify部分从v2的结构更改为如下。由于9603201*1是整个网络最大的一个Filter,并且作者说去除它也不会影响精度。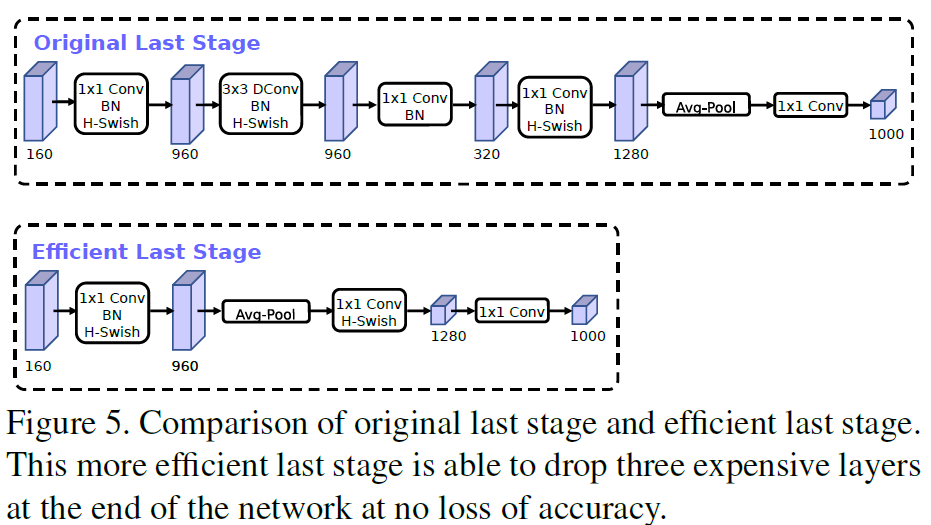
感觉如果真的要压缩的绝的话,直接在160通道的时候用AvgPool拉平过一个全连接到1280是不是也行。
非线性激活函数
作者在MobileNet v3中引入了 激活函数,其中
激活函数,其中 。这种激活函数能够提升精度,但是sigmoid激活函数的计算在嵌入式系统中开销较大,作者提出通过
。这种激活函数能够提升精度,但是sigmoid激活函数的计算在嵌入式系统中开销较大,作者提出通过 进行近似:
进行近似:

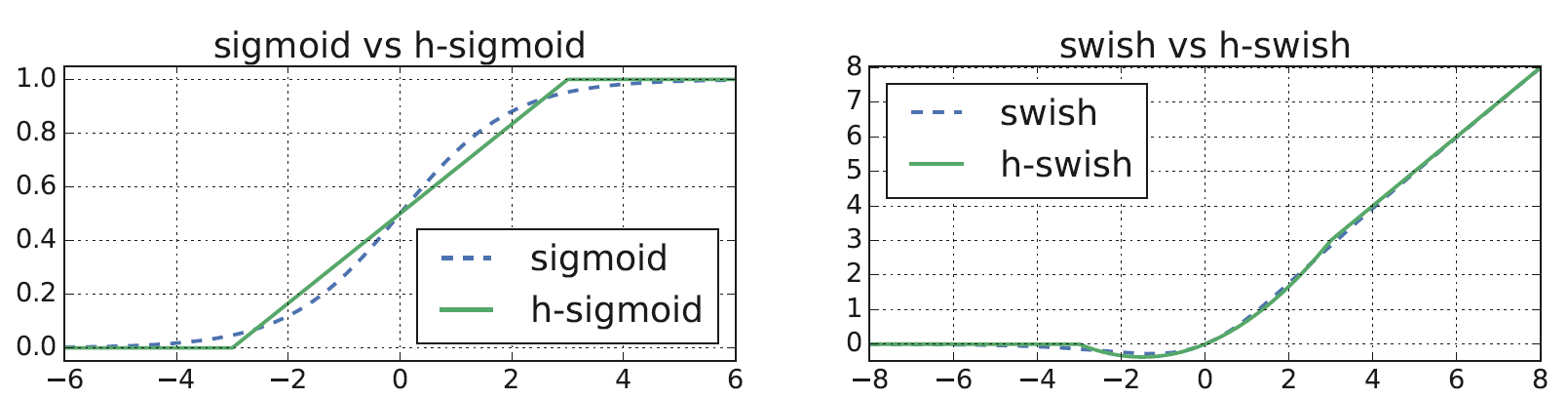
即使如此,h-swish激活函数相比ReLU还是有额外开销的。由于随着stage的加深,若通道数与分辨率等比例变化,非线性的计算量是越来越小的(譬如51277和1282828相比)。作者提出只在更深层使用h-swish,而在浅层继续使用ReLU。
题外话:还有一种更牛逼的激活函数叫mish:
实际上mish的形状和性质和swish是很像的,下图为swish和mish的一阶、二阶导数: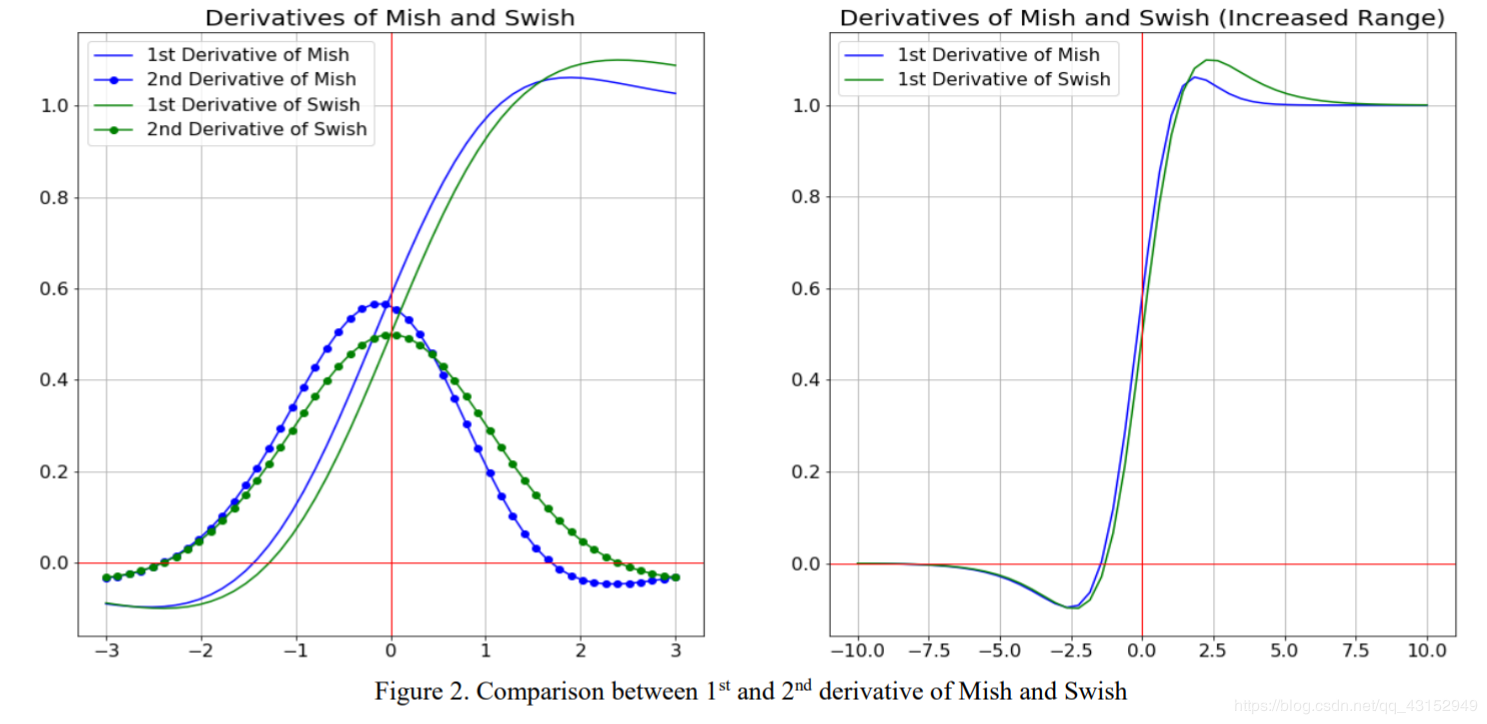
SE模块的引入
MobileNet v3引入了SE模块(SE注意力机制),其中SE模块原文构建了一个<通道数 - 通道数/16 - 通道数>的Bottleneck结构,MobileNet v3中使用的是<通道数 - expansion通道数/4 - 通道数>的结构。v3中expansion通道数并非输入通道的6倍,是搜出来的。
网络结构
MobileNet v3分为Large和Small两个网络。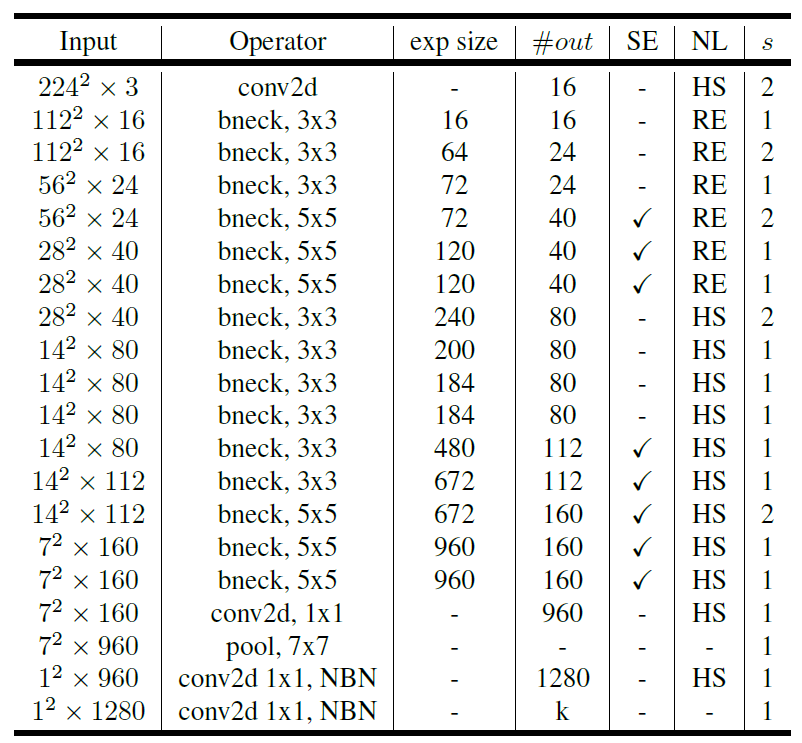
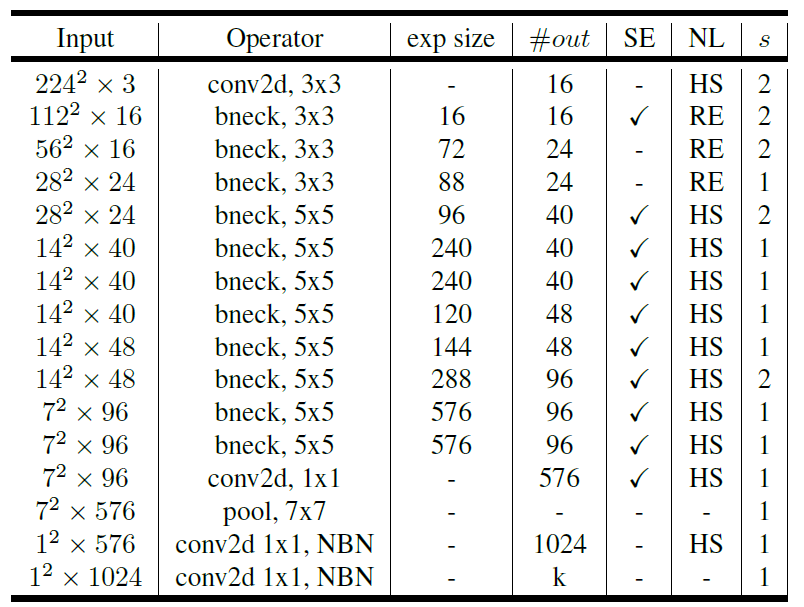
实验结果
ImageNet训练config:
RMSProp(momentum=0.9, weight_decay=1e-5),bs=4096,lr=0.1,指数衰减每3个epc x0.99
ImageNet下的Top-1精度及其在P-1、P-2、P-3三台手机上的推理耗时(ms):

对比MobileNet v3L、v3S、v2
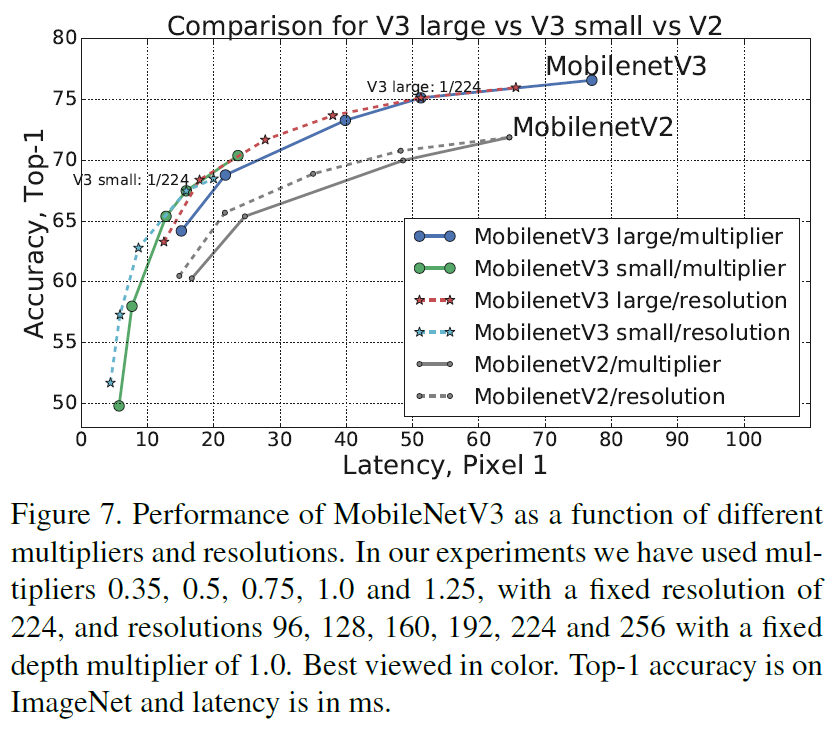
作者对“在网络的什么阶段开始用HS替换ReLU”做了实验,如下图,h-swish@N表示当输出通道为多少时开始用HS替换ReLU。实验结果表明对于v3 Large,在输出通道为80的时候开始使用HS是一个较好的trade-off。
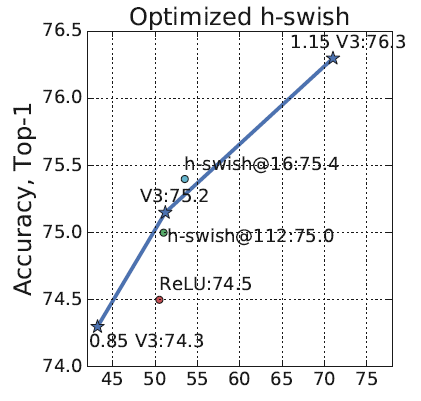
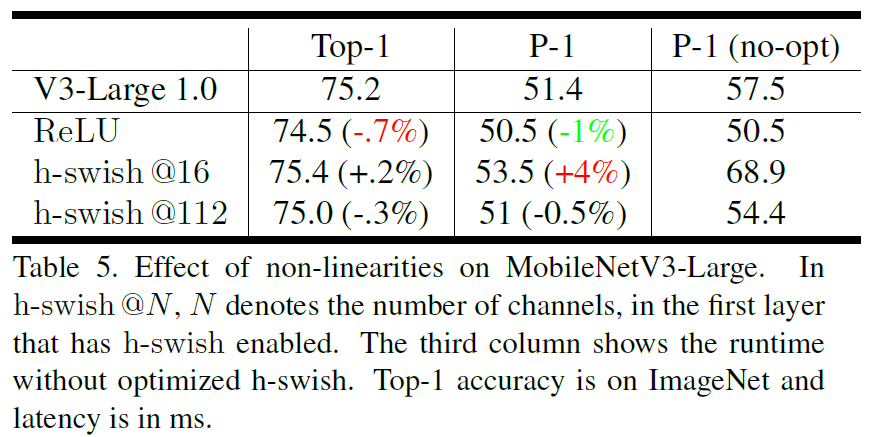
优化完好的h-swish激活函数只增添了1ms的推理时间,但没有优化过的h-swish会慢很多。
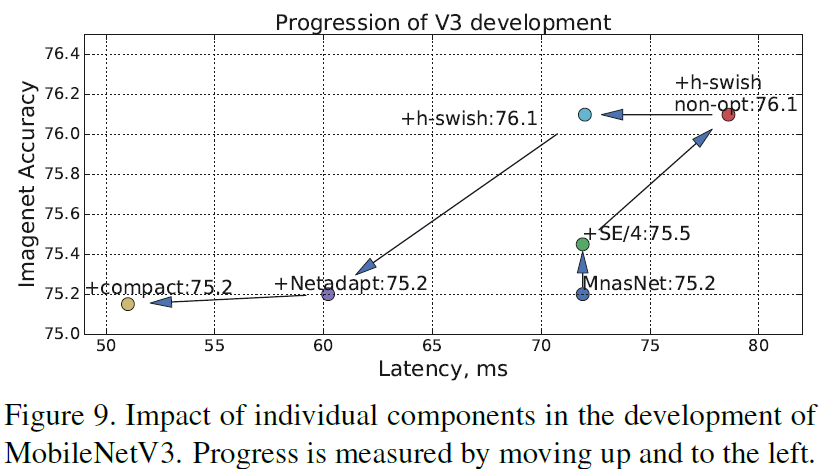
总结一下,下图展示了作者是怎么从MnasNet(NASNet就是用NAS搜出来的网络)改进得出MobileNet v3的
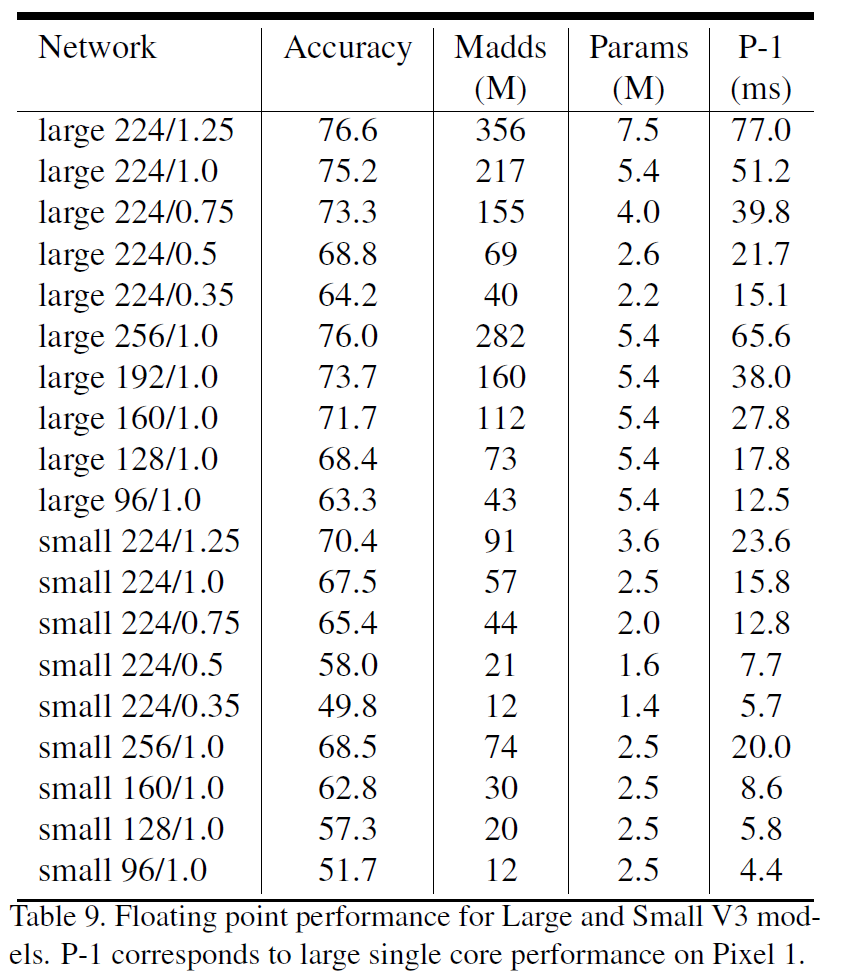
不同结构的MobileNet v3的ImageNet精度、FLOPS、参数数量与Pixel手机推理耗时:
ShuffleNet
ShuffleNet v1
论文:https://arxiv.org/pdf/1707.01083.pdf
主要贡献
- 基于MobileNet v2,提出其中1x1的pw卷积占据了绝大部分FLOPS,模仿ResNeXt进行group卷积减小1x1卷积开销
- 利用channel shuffle操作组合不同group的信息
ShuffleNet Unit
下图比较了MobileNet v2与ShuffleNet Block的区别,以及ShuffleNet Block在stride为2时的Block。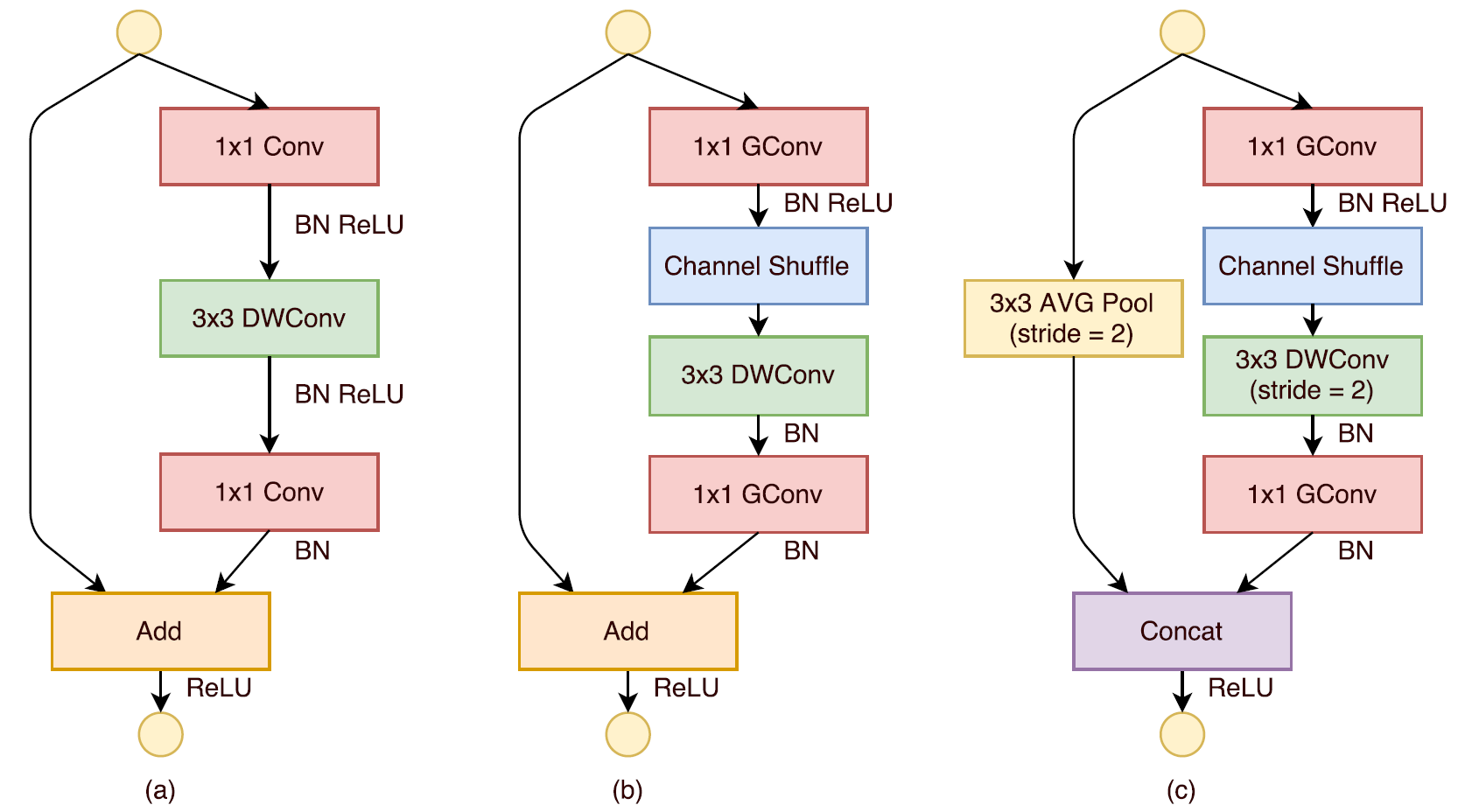
需要注意比较骚的一点是,stride为2的时候作者为了省去shortcut上的1x1卷积以及ele-wise相加的开销,直接把两个分支concat起来实现通道翻倍。
另外注意一下ReLU的使用位置
Channel Shuffle
如果没有channel shuffle操作,那么堆叠的group卷积与dw卷积中信息流只会在group内传递而不能流通。作者引入了channel shuffle操作使得信息可以在各个group间流通。
另外ShuffleNet只在Block的第一个1x1GConv后接了channel shuffle,Block最后的第二个1x1GConv后则没有,作者说第二个1x1GConv后加channel shuffle不会有性能提升。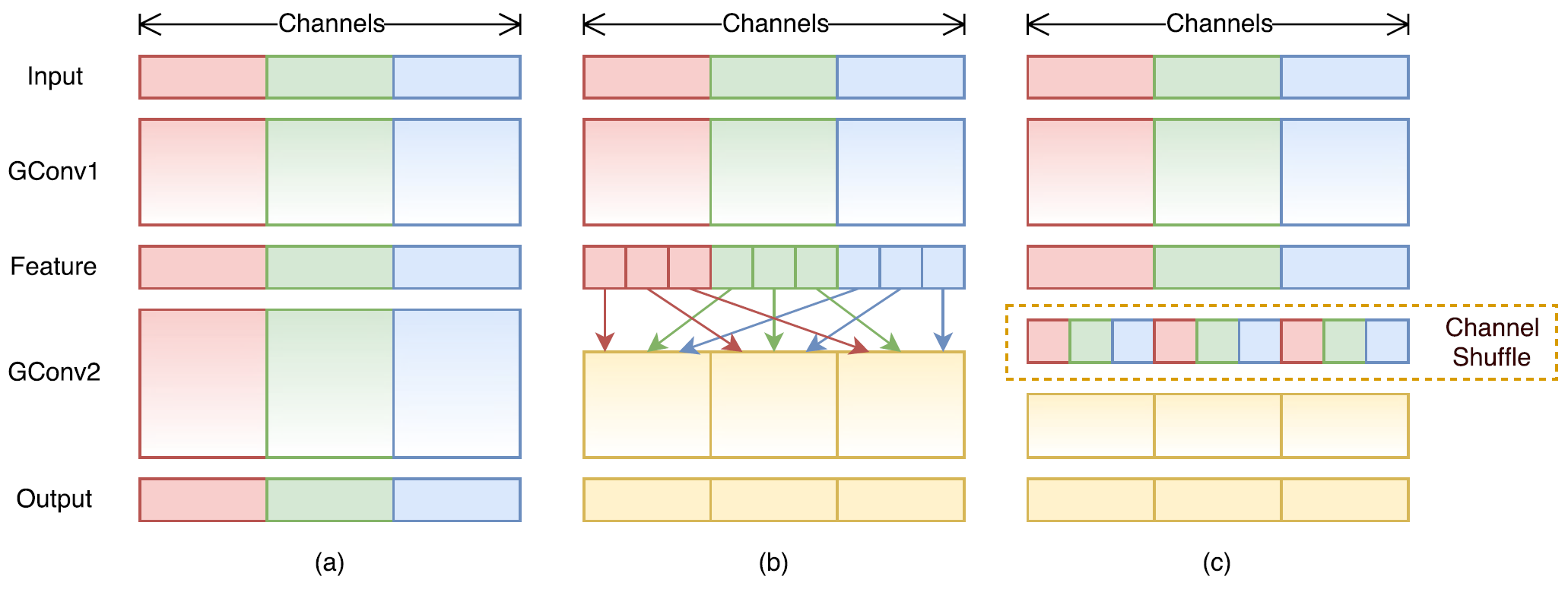
网络结构
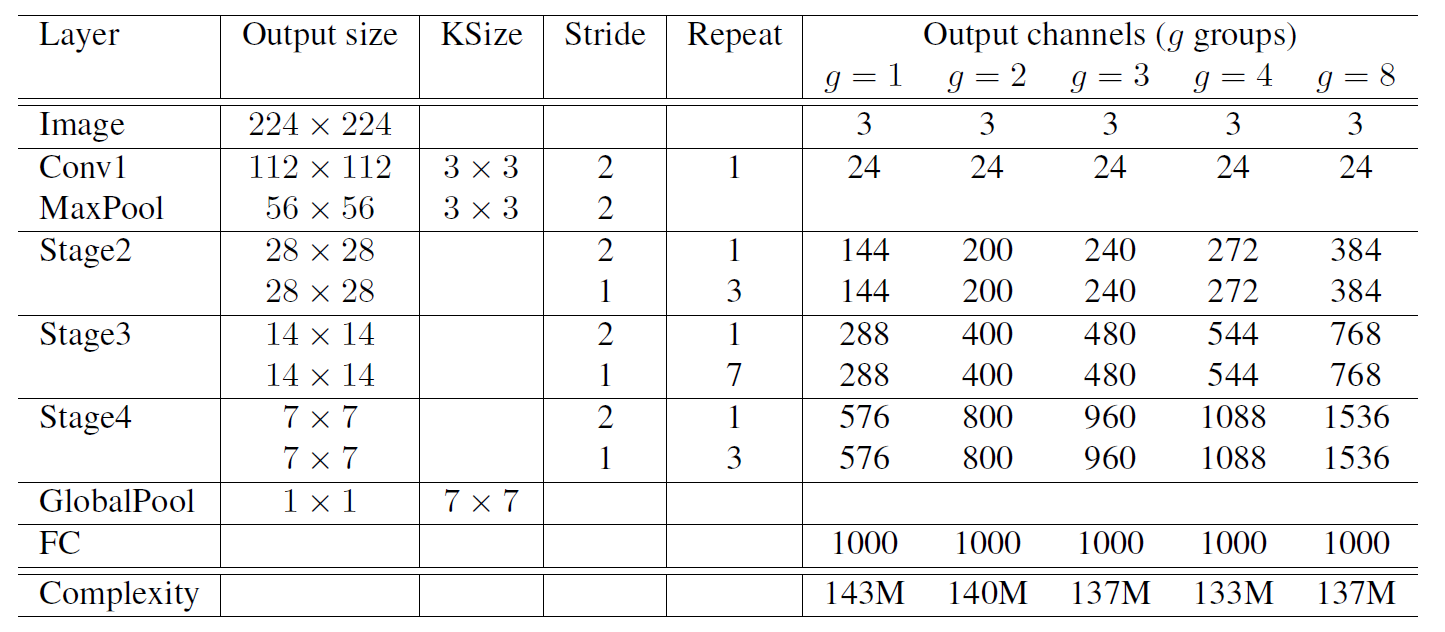
作者做实验做出来基本group=8是最好的
Absolation Study
不同group数的结果: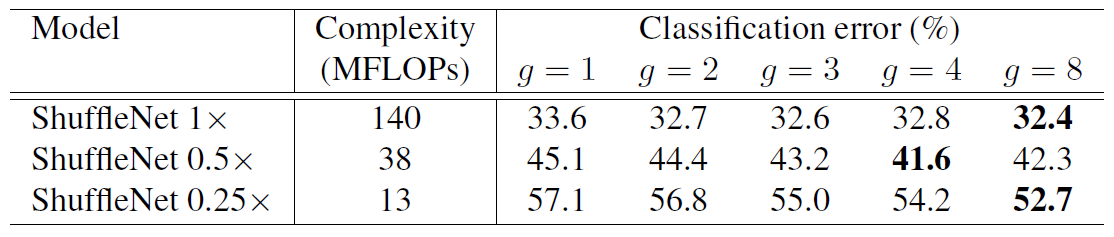
是否使用channel shuffle的结果: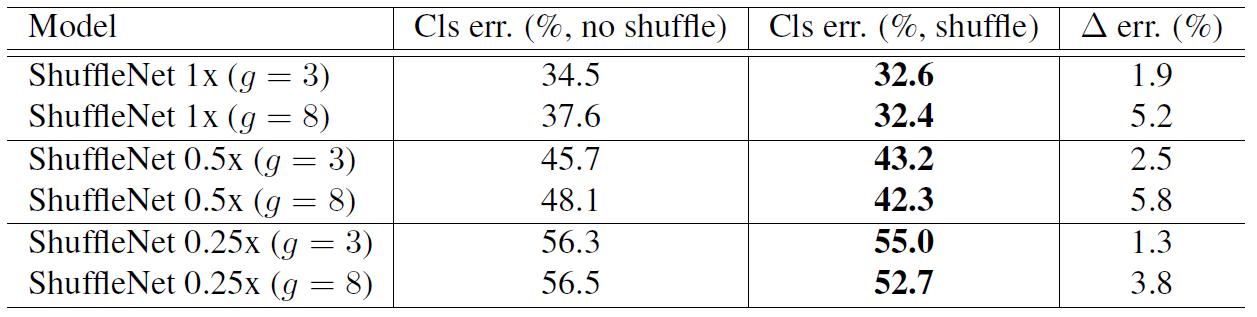
ShuffleNet v2
论文:https://arxiv.org/pdf/1807.11164.pdf
主要贡献
- 分析了影响实际推理延迟的因素,并提出FLOPS和推理延迟不可等价
- 提出了针对影响实际推理延迟的因素优化的高效网络ShuffleNet v2
影响实际推理延迟的因素
- FLOPS相同时,输入通道与输出通道的比值对延迟的影响
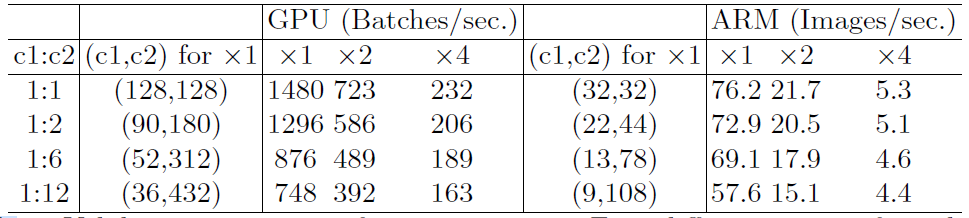
- FLOPS相同时,不同group数的卷积对延迟的影响
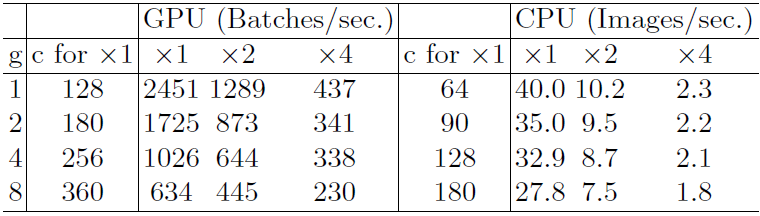
- FLOPS相同时,网络分支数量对延迟的影响
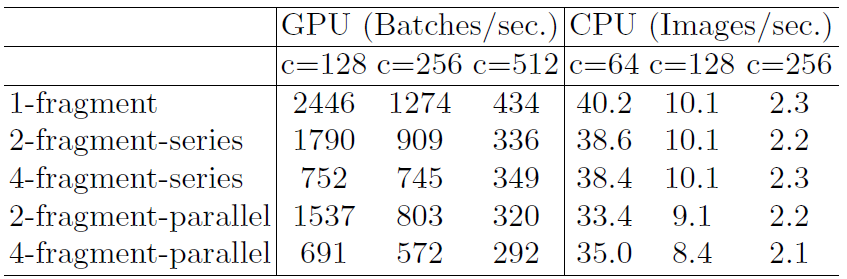
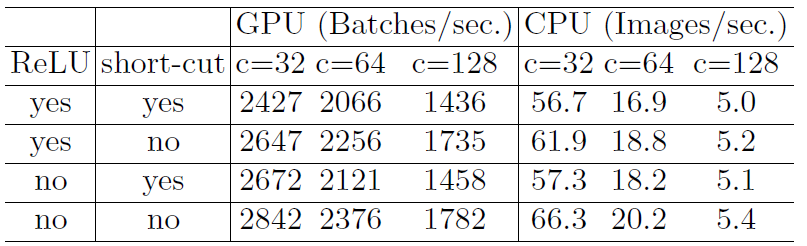
- FLOPS相同时,是否使用ReLU与shortcut对延迟的影响
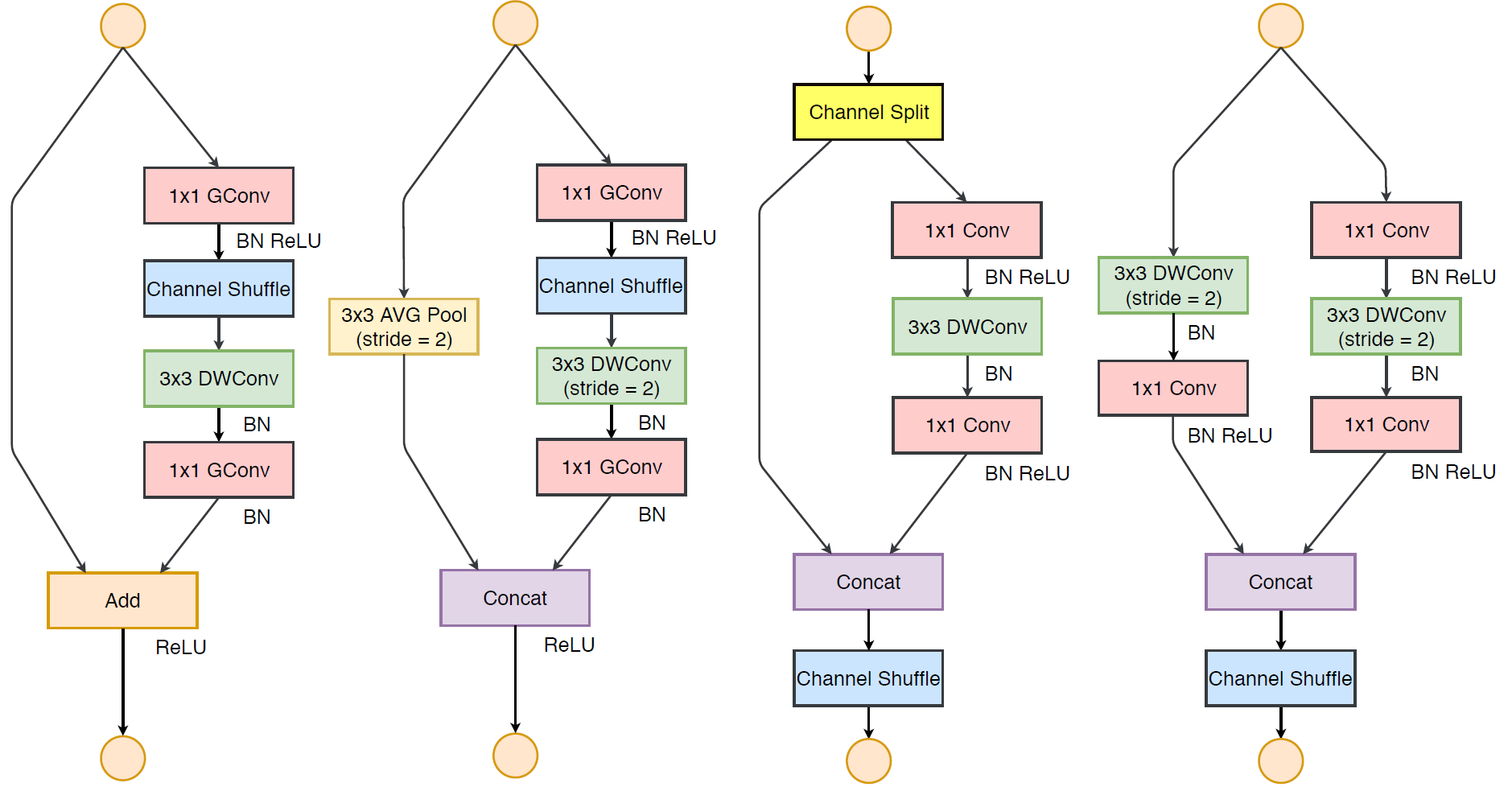
ShuffleNet v2 Unit
下图比较了ShuffleNet v1与ShuffleNet v2的Block的区别。可以看到ShuffleNet:
- 为了迎合上述因素1(简称G1),干掉了MoblieNet的Inverted Bottleneck;
- 为了迎合G2,干掉了ShuffleNet v1的group-pw卷积改用channel split减小1x1卷积宽度;
- 为了迎合G4,干掉了shortcut与ele-wise add而改用了concat做短连接融合。
其实ShuffleNet v2的设计结构有点像DenseNet,只不过ShuffleNet v2利用了Block间隔越远相关性更可能较低的原理,间隔 个Block间短连接的通道数量为
个Block间短连接的通道数量为 ,因为channel split操作将两个支路通道数等分,每个Block都会保留上个Block中一半的短连接通道数。
,因为channel split操作将两个支路通道数等分,每个Block都会保留上个Block中一半的短连接通道数。
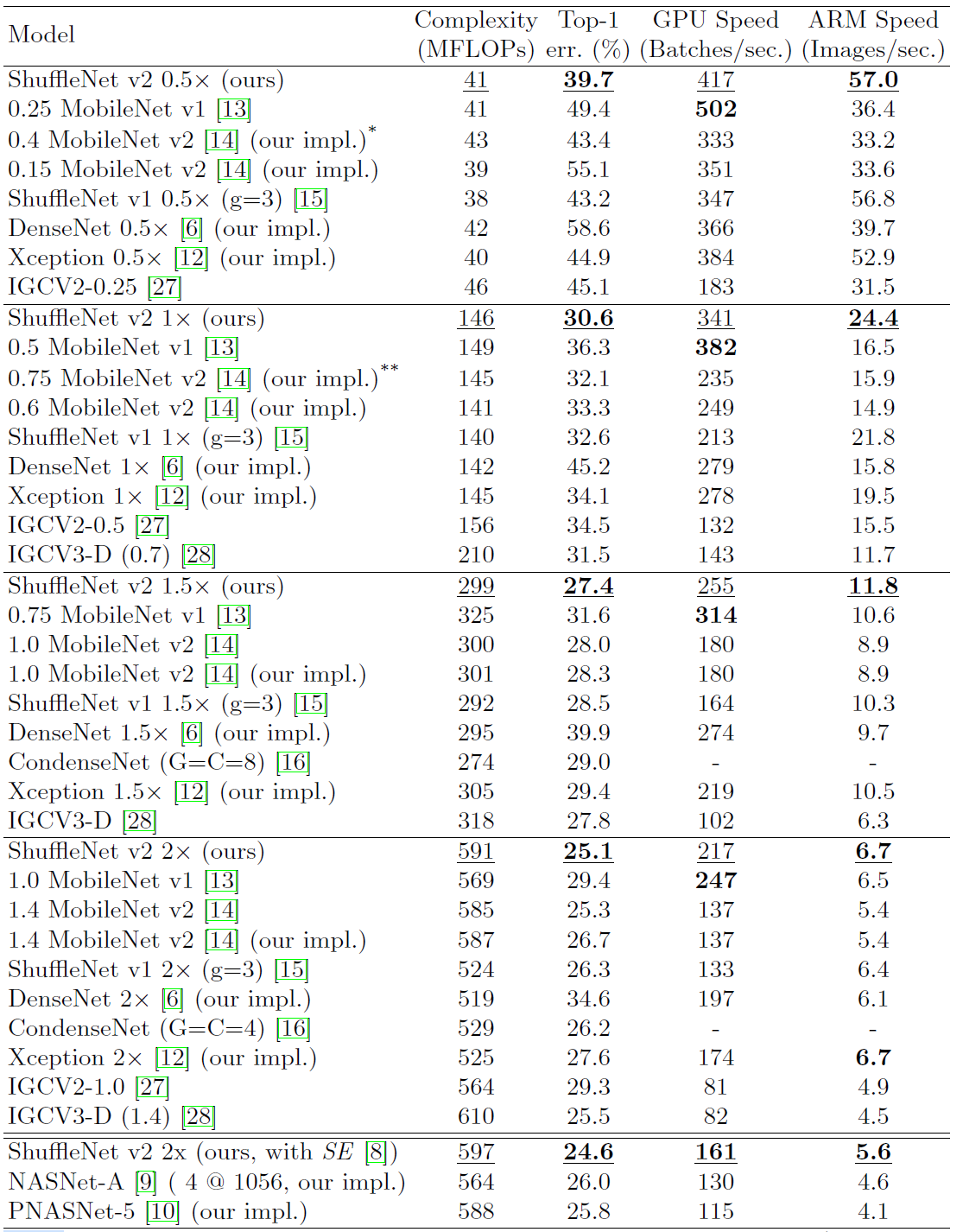
实验结果
遗留
FlattenedNet
SqueezeNet
ShiftNet
合集
https://zhuanlan.zhihu.com/p/134146703?from_voters_page=true

若有收获,就点个赞吧
0 人点赞
