Proxy Task
Proxy Task指的是NAS的RNN控制器优化过程中产生的子任务。
暴力搜索
在用NAS搜索一个ImageNet分类网络时,最暴力的方式就是每个sampled-network都训到收敛,将收敛后的网络准确度(reward)反馈给RNN控制器,这时Proxt Task就是“在ImageNet上训至收敛”。但是本身NAS的搜索空间就非常大,每个Proxy Task的开销又这么大的话,会导致NAS的搜索代价实在太大。
将小任务上的结果迁移到大任务
NASNet的做法是在CIFAR10数据集上执行搜索,并将搜索得到的网络姐u共up-scale迁移到ImageNet数据集上,这时Proxt Task就是“在CIFAR10上训至收敛”。但是MnasNet的论文中指出,需要up-scale的网络无法将推理延迟、FLOPS等开销指标融入reward反馈给RNN控制器。
在大任务上进行不完全训练
MnasNet的做法是直接在ImageNet数据集上执行搜索,但是只训5-epochs,根据此时的准确度直接反馈,“在ImageNet上训练5-epochs”。后来也有很多NAS相关的论文是这么做的,譬如NAS-FPN取了Proxy Task为“在COCO上训练10-epochs”,甚至把backbone缩成了ResNet-10,输入分辨率缩成了512×512。
NASNet
论文:Learning Transferable Architectures for Scalable Image Recognition
这篇论文的创新点即结合了NAS技术,搜索出一个多分支Conv Cell用于堆叠(很像GoogleNet那一套)。所有stage上的各个block的结构都相同,都采用搜出来的block,只是不同stage上卷积的宽度不同。
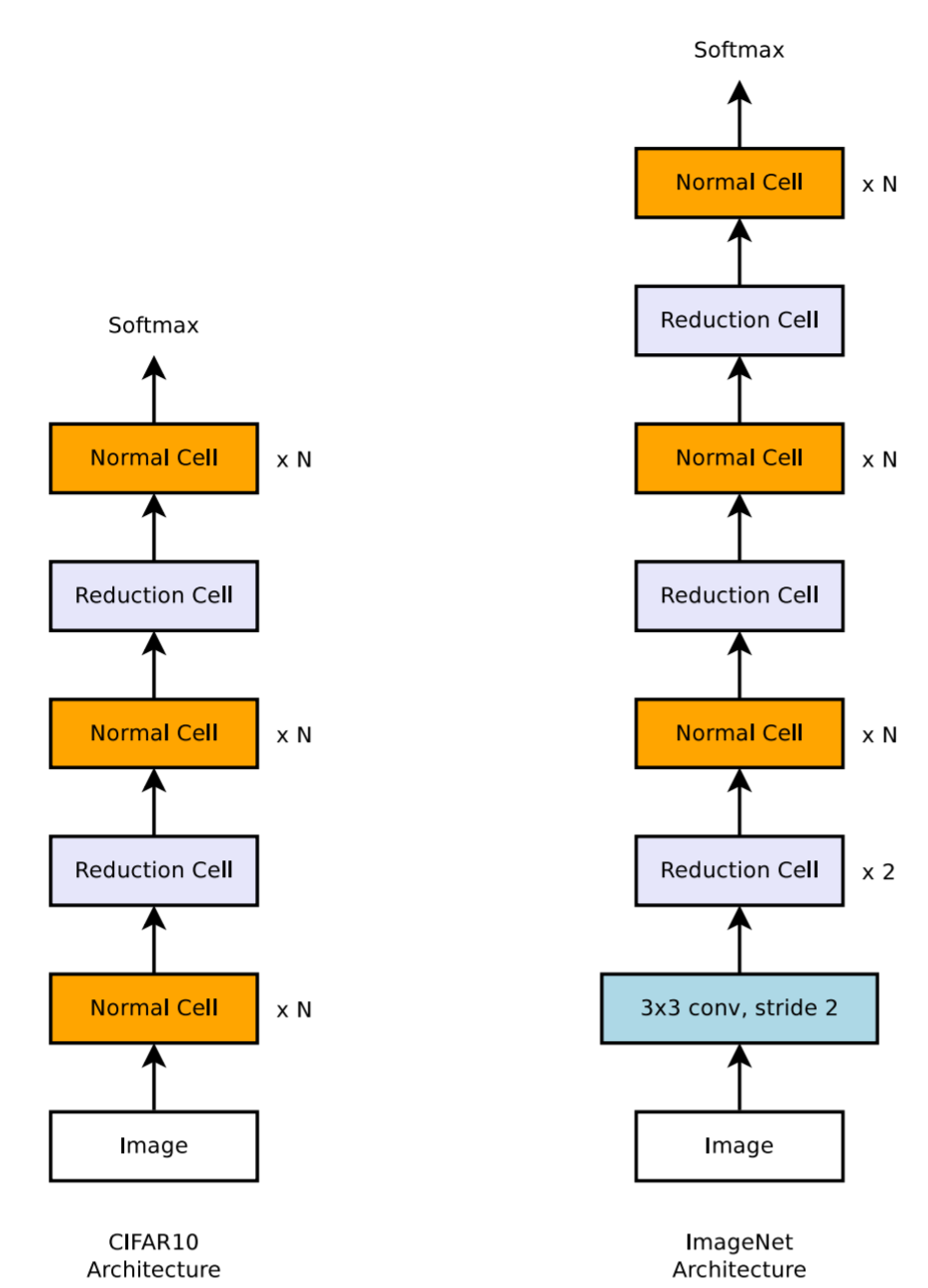
NASNet只搜索了两个block的结构,其中一个用于需要进行下采样时用,另一个平时用。其用于CIFAR和ImageNet的模型结构如下图所示:
搜索空间
NASNet搜索了两个单独的block,每个block固定有5个分支(作者认为这样效果好,没做实验论证)每个分支的结构如下图所示。
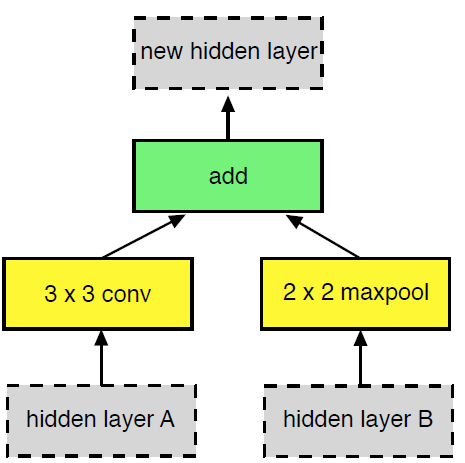
每个分支的搜索分为三步:
- 假设当前层的输入为
 ,当前分支为block内的第
,当前分支为block内的第 分支,则从
分支,则从 中选取两项作为该分支的输入
中选取两项作为该分支的输入 (允许选取当前block内,当前分支之前的分支的输出作为当前分支的输入);
(允许选取当前block内,当前分支之前的分支的输出作为当前分支的输入); - 从以下op中选择两个,分别作用于;
identity 1x3conv+3x1conv 1x7conv+7x1conv 3x3 dilated-conv
3x3avgpool 3x3maxpool 5x5maxpool 7x7maxpool
1x1conv 3x3conv 3x3,5x5,7x7dw-conv
- 从元素级加和、concat两种中选择一种方法用于融合

论文中使用的搜索方法,对block每个分支上的5个决策(第一步和第二步各2个决策,第三步一个决策),每个决策用了一个分类器,共2(总共要搜两种block)5(每个block有5个分支)5(每分支5个决策)=50个分类器。
不过就算整个过程只是搜了2个block的结构,并且作者为了节省算力缩小搜索开销,NASNet的搜索是在CIFAR10上完成的(ImageNet的网络是在搜出来的NASNet基础上scale up得到的),NAS过程依然在500张P100上跑了整整4天。。。。
网络结构
NASNet搜出来的网络就尼玛离谱,这什么东西,和GoogleNet一样恶心得令人作呕(个人直观感受)。下图左边是普通的block,右边为需要下采样时的block。(sep就是深度可分离卷积)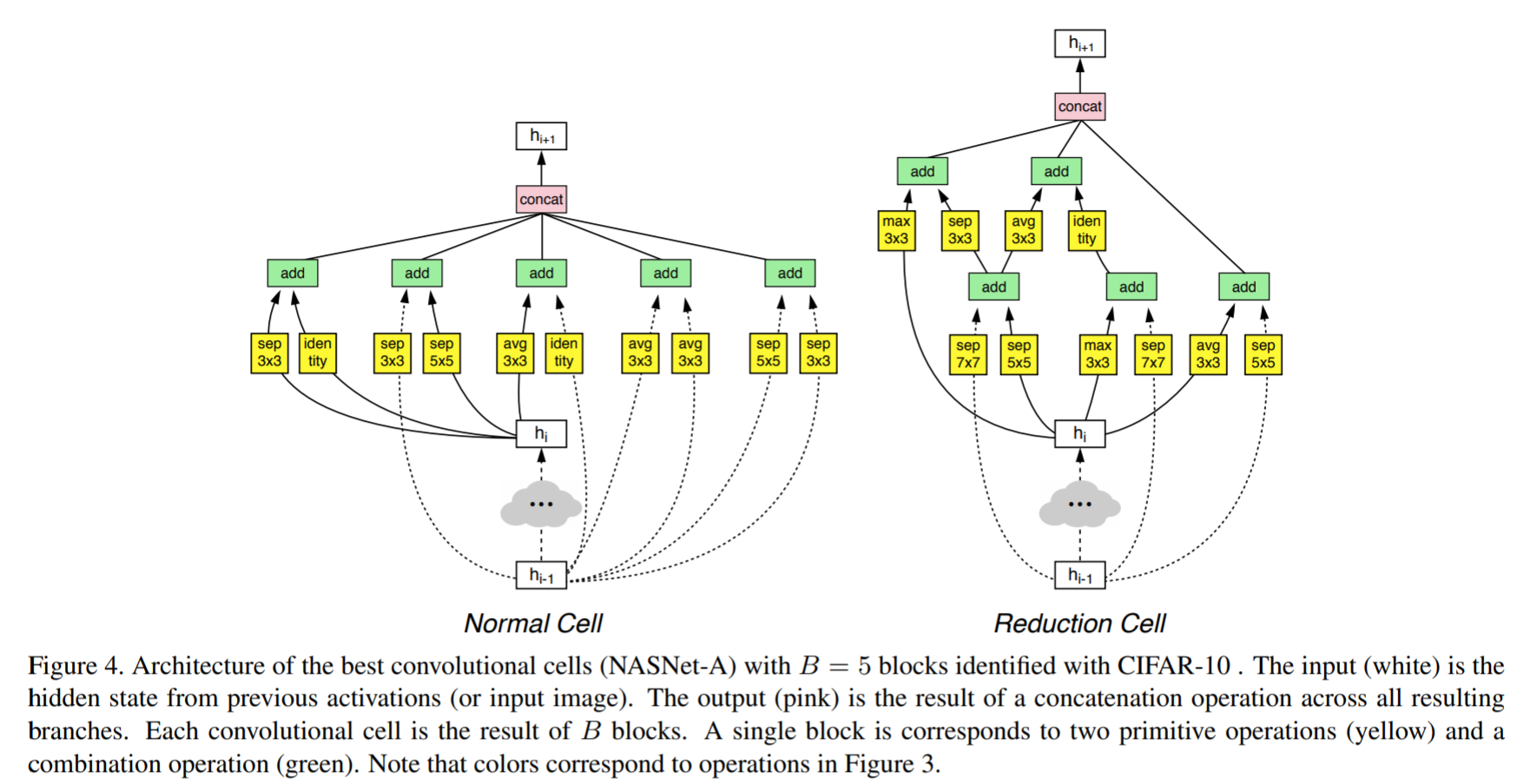
网络的超参数就只剩下 代表每间隔几个
代表每间隔几个 后跟一个
后跟一个 用于下采样;
用于下采样; 代表网络宽度。论文中用
代表网络宽度。论文中用 表示,其中表示最后一个Cell的通道数。
表示,其中表示最后一个Cell的通道数。
实验结果
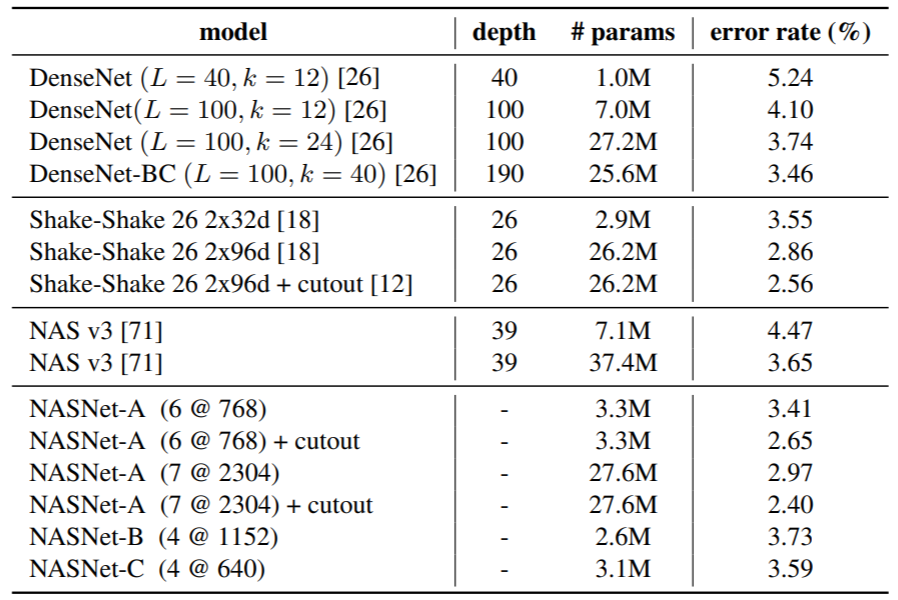
CIFAR10
ImageNet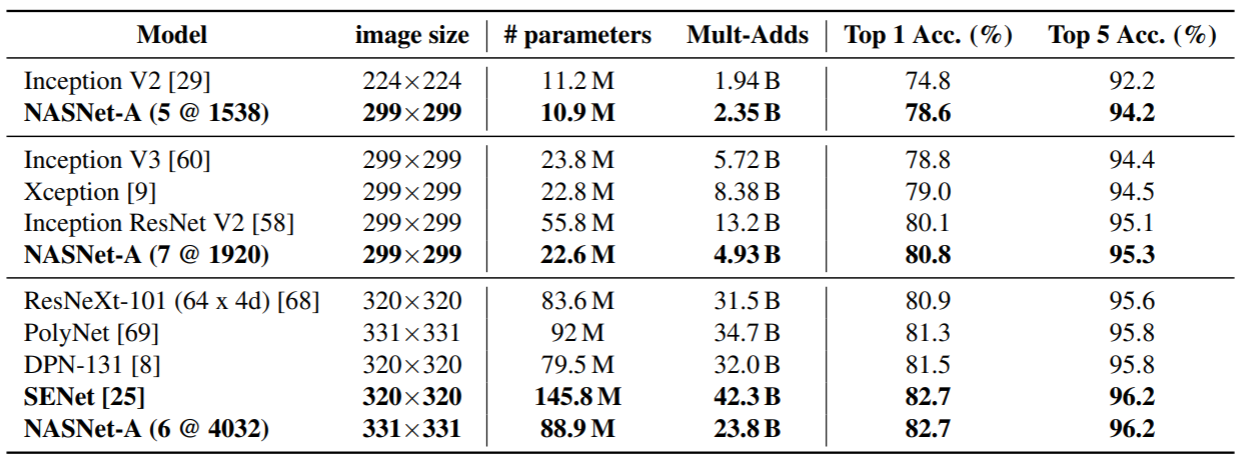
MnasNet
论文:https://arxiv.org/pdf/1807.11626v1.pdf
相比NASNet,MnasNet除了精度外,还将模型的推理耗时显式地纳入了NAS的考虑范围内,以求搜索出能在精度和时延间良好权衡地模型。MnasNet没有将FLOPS用于度量开销,而是直接拿了个手机用来记录延时。
本文的创新点有两个:
- 提出了强化学习的multi-objective奖励,除了精度外还融合了时延。
- 不同于NASNet搜出一个非常复杂的block并将其应用于整个网络,MnasNet为每个block搜索不同的简单op。
优化目标
<br />其中为目标时延,为权重因子,定义为:<br />
作者提出,根据经验值,通常提高一倍开销可以获得5%的相对精度提升,据此可以将 设置为-0.07,此时NAS将搜索时延位于
设置为-0.07,此时NAS将搜索时延位于 附近的网络结构,也有可能搜索时延小于或大于的网络。如果我们面临一个实时系统,对时延有严格的要求,可以将
附近的网络结构,也有可能搜索时延小于或大于的网络。如果我们面临一个实时系统,对时延有严格的要求,可以将 设为0,
设为0, 设非常小的值,即在满足时延的情况下继续减小时延不会带来收益,但时延超过的模型都会被加上非常严厉的惩罚。
设非常小的值,即在满足时延的情况下继续减小时延不会带来收益,但时延超过的模型都会被加上非常严厉的惩罚。
下图展示了 时,
时, 、
、 两种权重因子设置方法下,优化目标
两种权重因子设置方法下,优化目标 随时延变化的曲线。
随时延变化的曲线。
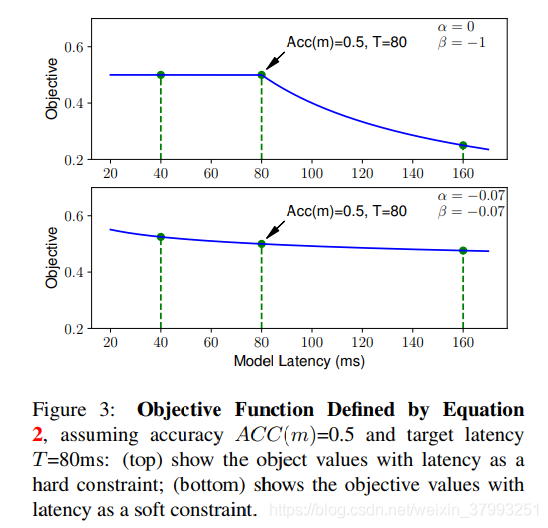
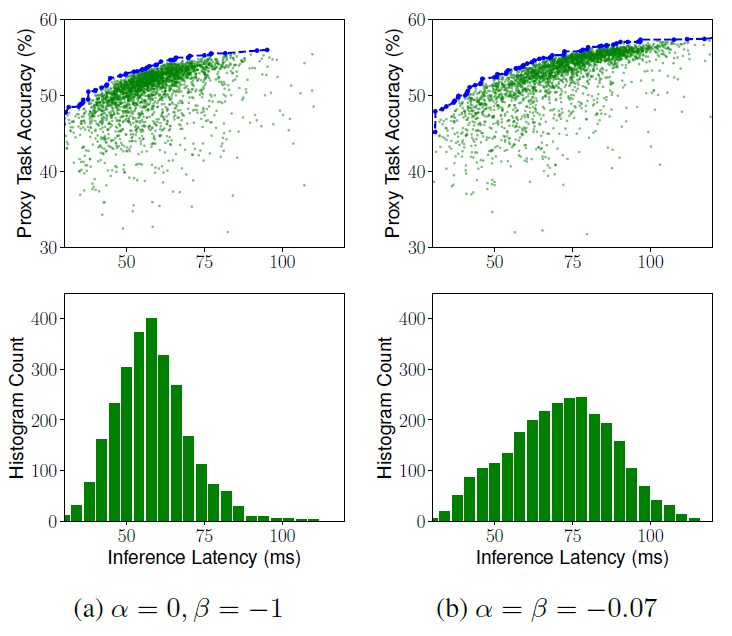
下图展示了以上两种权重因子设置方法下,NAS采样的网络的时延分布(=75ms):
搜索空间
作者根据先验,在MobileNet v2的基础上进行进一步搜索。MobileNet v2将整个网络划分为7个Block加一个接受输入的卷积,并在第2、3、4、6 Block进行下采样,如下图所示。为了减小搜索空间,MnasNet的搜索中,每个Block中的所有Layer共享同一结构。
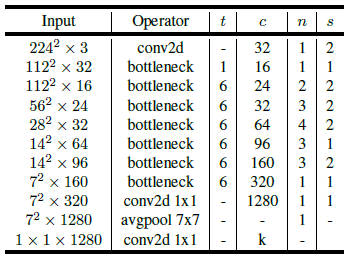
MobileNet v2 (t代表expansion,c代表block的输出通道数,n代表堆叠block数,s代表stride)
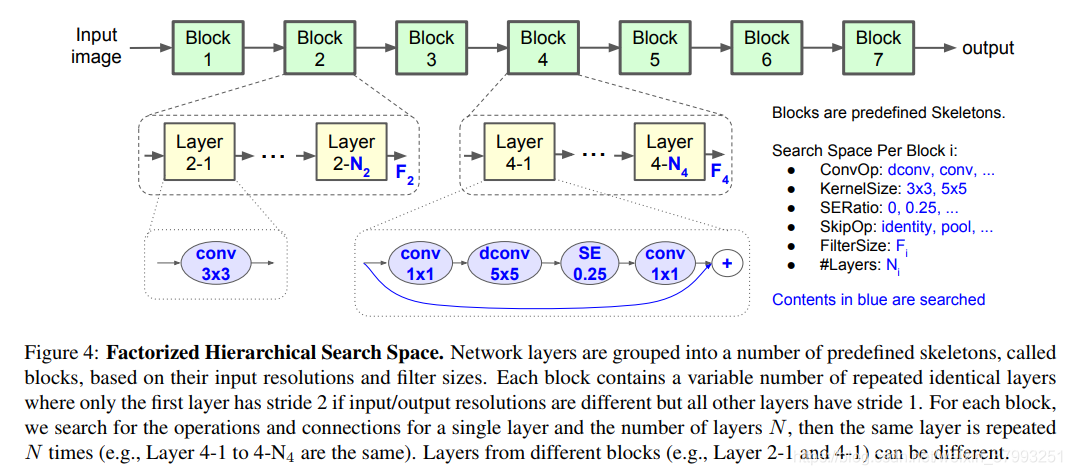
作者将搜索空间定义为:
- 每个Block堆叠的Layer数
每个Block的Layer数在MobileNet v2的基础上,在{ 0, +1, -1 }三个取值中搜索
- 每个Block中的Layer所采用的op
ConvOp:常规卷积、深度可分离卷积、MobileNet v2采用的Inverted Bottleneck(expand=3或6)
KernelSize:3x3、5x5
SE:不采用、SE Ratio=0.25
SkipOp:池化、Identity、不采用
Width:输出通道数在{ x0.75, x1.0, x1.25 }三个取值中搜索
不同于NASNet在CIFAR10上做NAS,MnasNet直接在ImageNet上做NAS,在64个TPUv2上跑了4.5天(1个TPUv2的算力大约顶5-6个P100)
网络结构
与MobileNet v2的对比如下: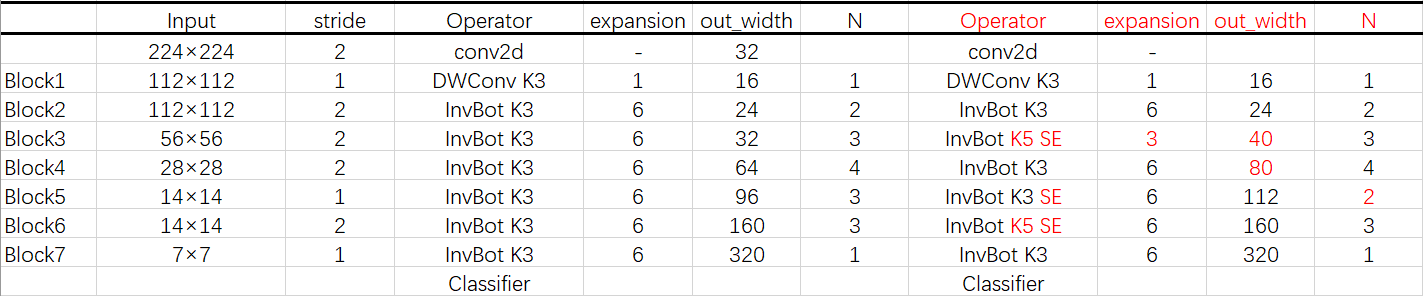
实验结果
ImageNet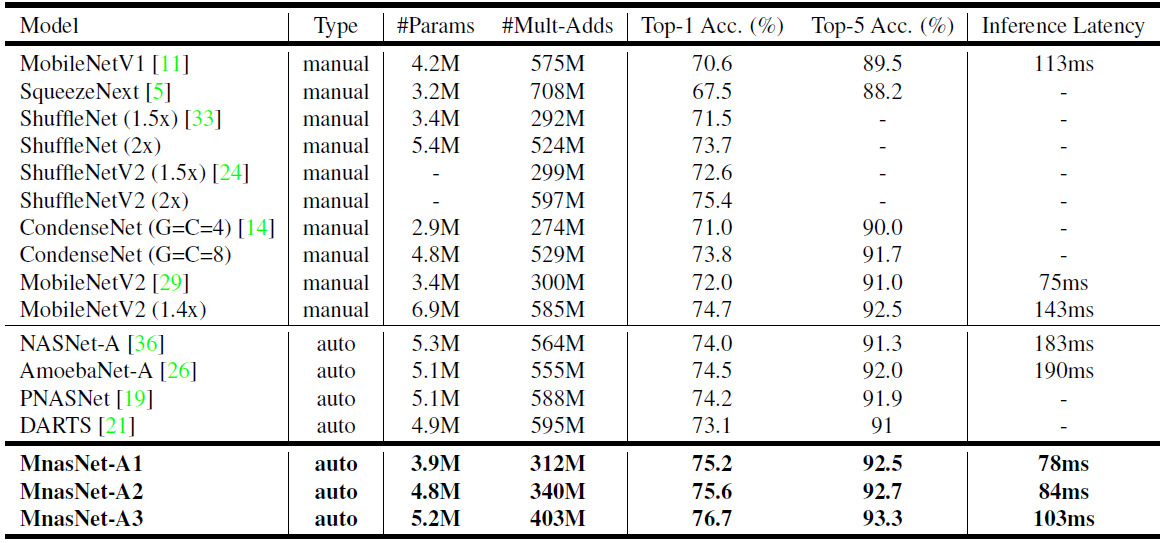
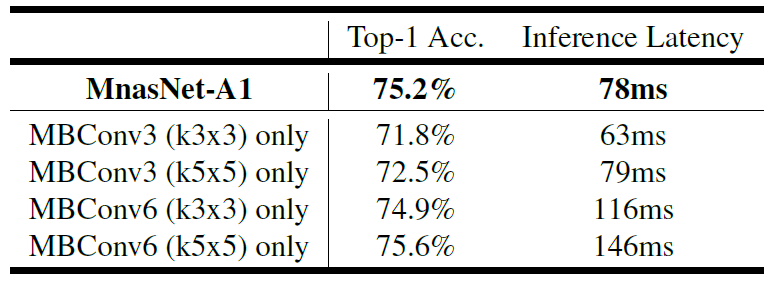
SE模块的使用
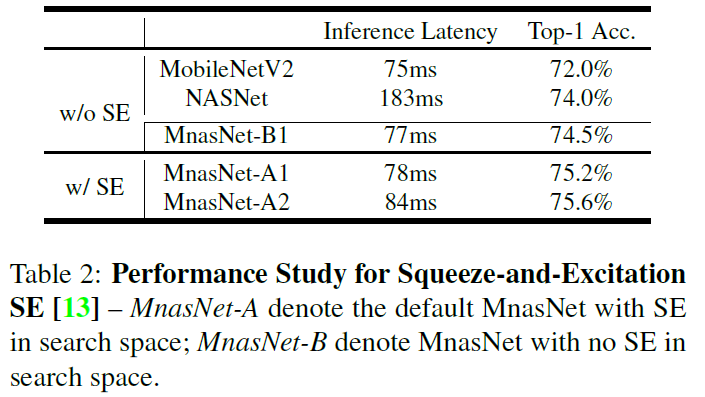
在目标开销上重搜比scale up/down更好
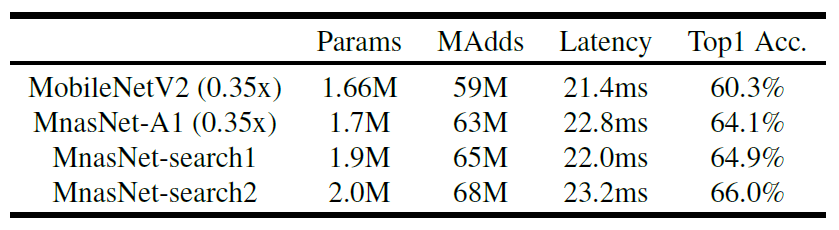
与固定op网络的对比
MobileNet v3
详细参考博文:MobileNet v3
MobileNet v3是在MnasNet的基础上做改进的:
- 所有InversedBottleneck添加了SE模块;
- 添加了Swish(实际使用的是Hard-Swish)作为激活函数;
- 使用了NetAdapt(应该也是类似NAS的方法)用于调整InversedBottleneck中DW卷积层的宽度(MnsaNet对于网络宽度的搜索是固定expansion=6搜索输出宽度的)
- 手工优化了网络,去除或压缩了一些开销大的层
EfficientNet
论文:https://arxiv.org/pdf/1905.11946.pdf#page=10&zoom=100,0,0
EfficientNet的创新点其实和NAS没什么关系,其主要创新点是提出了在网络深度、网络宽度、输入分辨率三个维度上共同对网络进行缩放,而之前的网络基本都在一个维度上进行缩放,譬如单纯缩放网络深度的ResNet、单纯缩放网络宽度的MobileNet v2等等。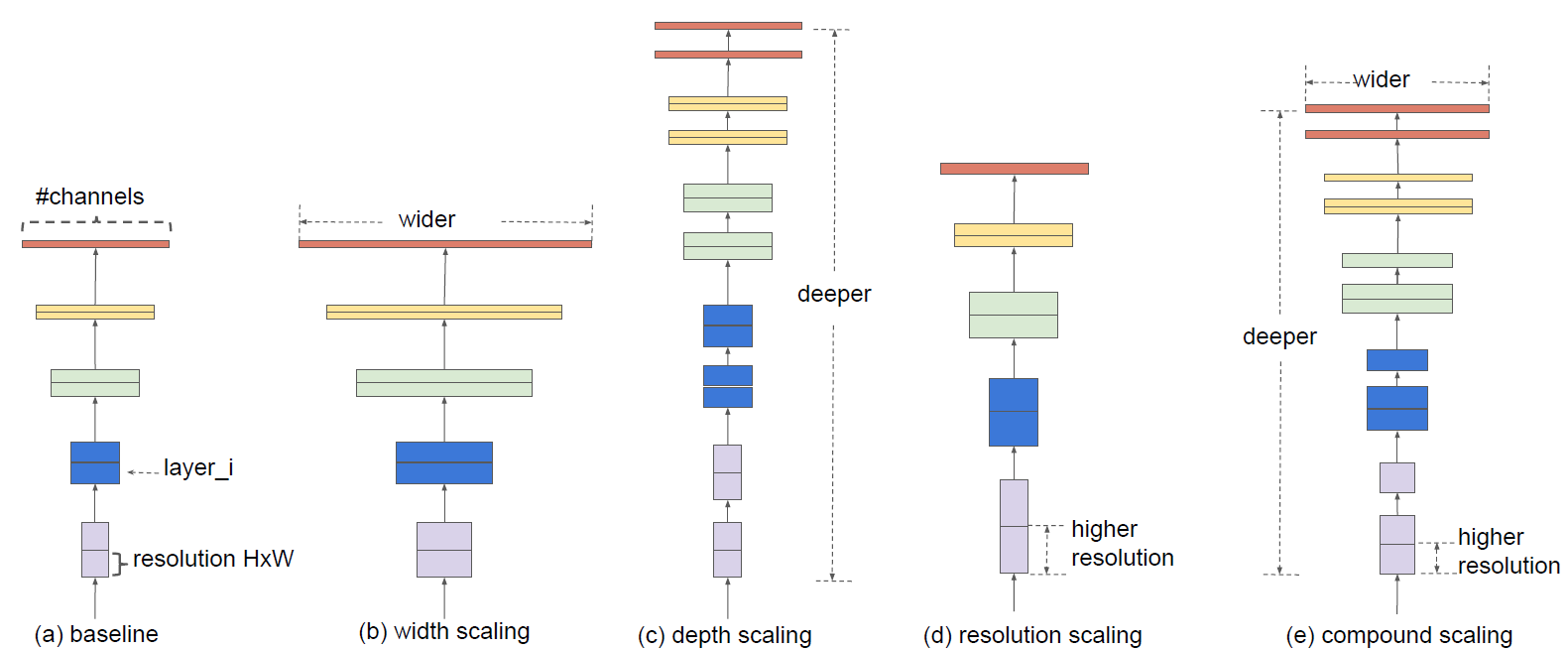
作者用与MnasNet相同的方法先搜出一个非常小的baseline(不过没用延迟作为指标,还是用的FLOPS),然后在该baseline的基础上进行scale-up。
假设我们现在有两倍的算力,需要在depth、width、resolution三个维度上进行一定的缩放,使网络的FLOPS达到baseline的两倍并且拥有最佳的精度,如下所示:
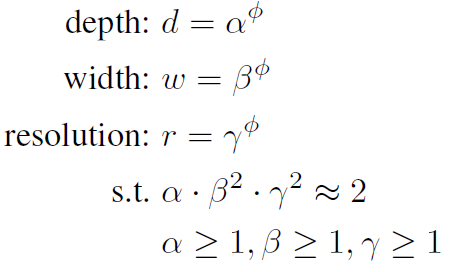
这一步也用到了NAS,而我们的搜索空间即是找出最佳的 。作者搜出来
。作者搜出来 。
。
网络结构
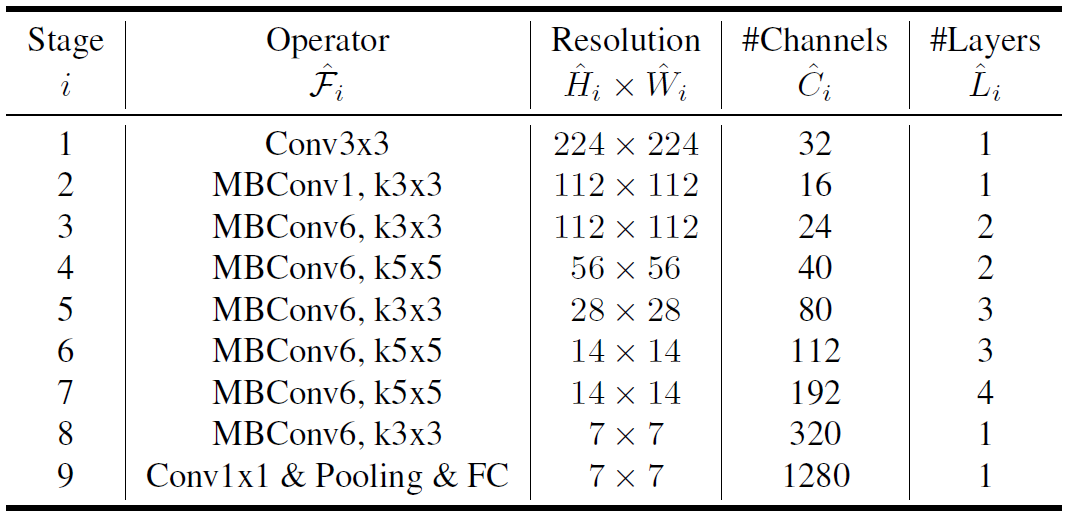
EfficientNet分为B0~B7共8个网络(后面还出了更大的B8和L2),B0的结构如下:
B0~B7的具体scale因子如下:
| 宽度缩放 | 深度缩放 | 输入分辨率 | fc-dropout | #Params | #FLOPs | |
|---|---|---|---|---|---|---|
| B0 | 1.0 | 1.0 | 224 | 0.2 | 5.3M | 0.39B |
| B1 | 1.0 | 1.1 | 240 | 0.2 | 7.8M | 0.70B |
| B2 | 1.1 | 1.2 | 260 | 0.3 | 9.2M | 1.0B |
| B3 | 1.2 | 1.4 | 300 | 0.3 | 12M | 1.8B |
| B4 | 1.4 | 1.8 | 380 | 0.4 | 19M | 4.2B |
| B5 | 1.6 | 2.2 | 456 | 0.4 | 30M | 9.9B |
| B6 | 1.8 | 2.6 | 528 | 0.5 | 43M | 19B |
| B7 | 2.0 | 3.1 | 600 | 0.5 | 66M | 37B |
| B8 | 2.2 | 3.6 | 800 | 0.5 | ~95M | ~75B |
网络定义时,分辨率缩放和宽度缩放比较好实现(宽度缩放一般会将宽度缩放后再round到8的整数倍),但深度的缩放比较烦,官方实现直接简单粗暴地将每个stage的深度分别scale-up后向上取整(1.1和1.2的深度缩放因子生成的B1和B2在深度上是完全一样的)
实验结果
ImageNet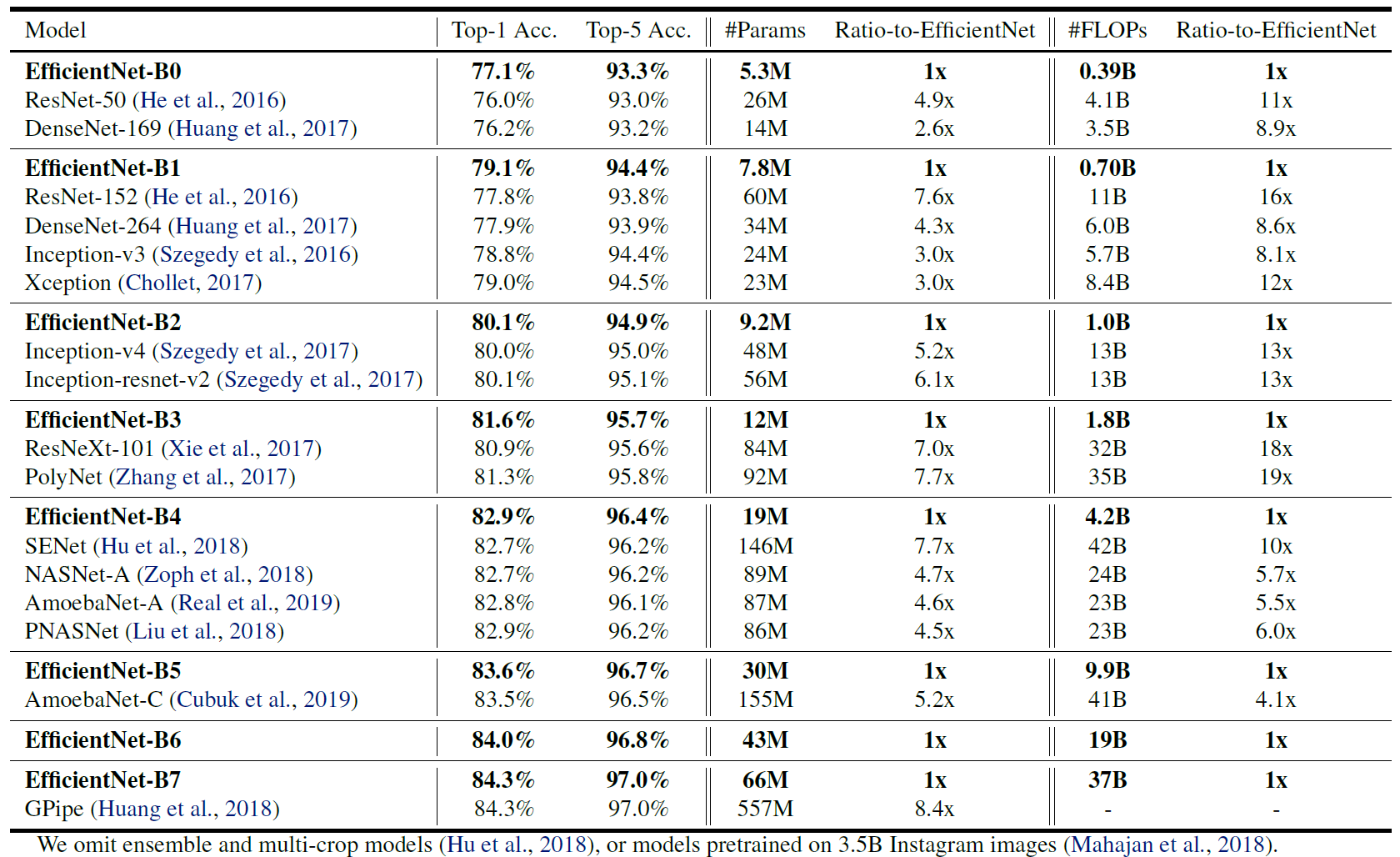
迁移至其它数据集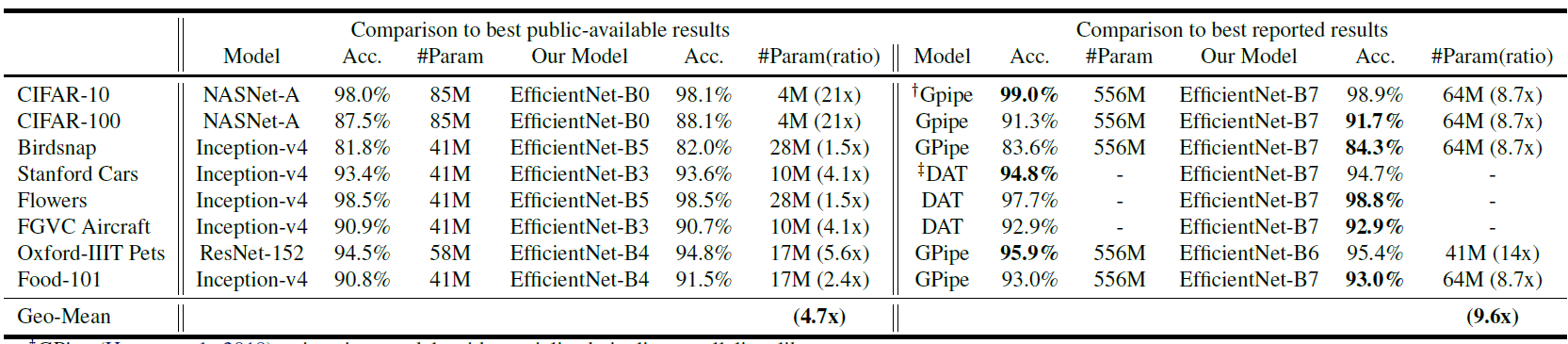
这里作者说EfficientNet B0都能在CIFAR100上跑88.1,但是我却80也跑不到,嗯。。。我也不想做它了
NAS-FPN
不同于分类网络,NAS-FPN将NAS用到了目标检测中。
如果对这方面不熟的话可以复习一下目标检测概览中的FPN、RetinaNet。
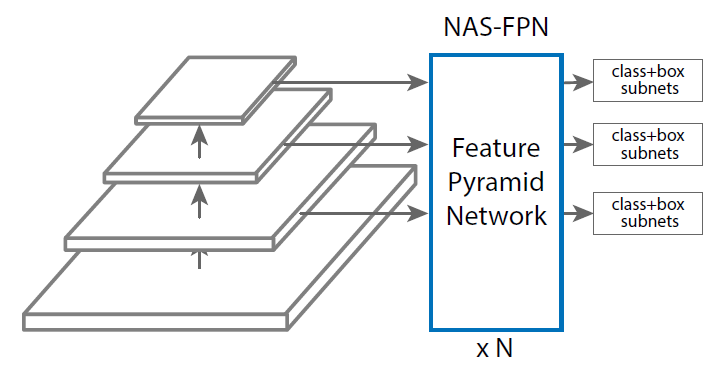
NAS-FPN主要是为了搜出一个良好的neck网络(下图中NAS-FPN部分)。NAS-FPN的baseline选取了RetinaNet,以提升搜索速度并排除Two-Stage检测中proposal采样等的影响。(特征金字塔总共有5层 ,别看图里只画了3层,它瞎j2画的)
,别看图里只画了3层,它瞎j2画的)
另外NAS-FPN还可以进行堆叠以进一步提高性能(也许?),还可以在堆叠的每一个NAS-FPN后分别拉head分类器做early stop(和自蒸馏分类网络的early stop类似)。
搜索空间
搜索的过程是为了寻找一系列Merging cell,其结构如下图所示:
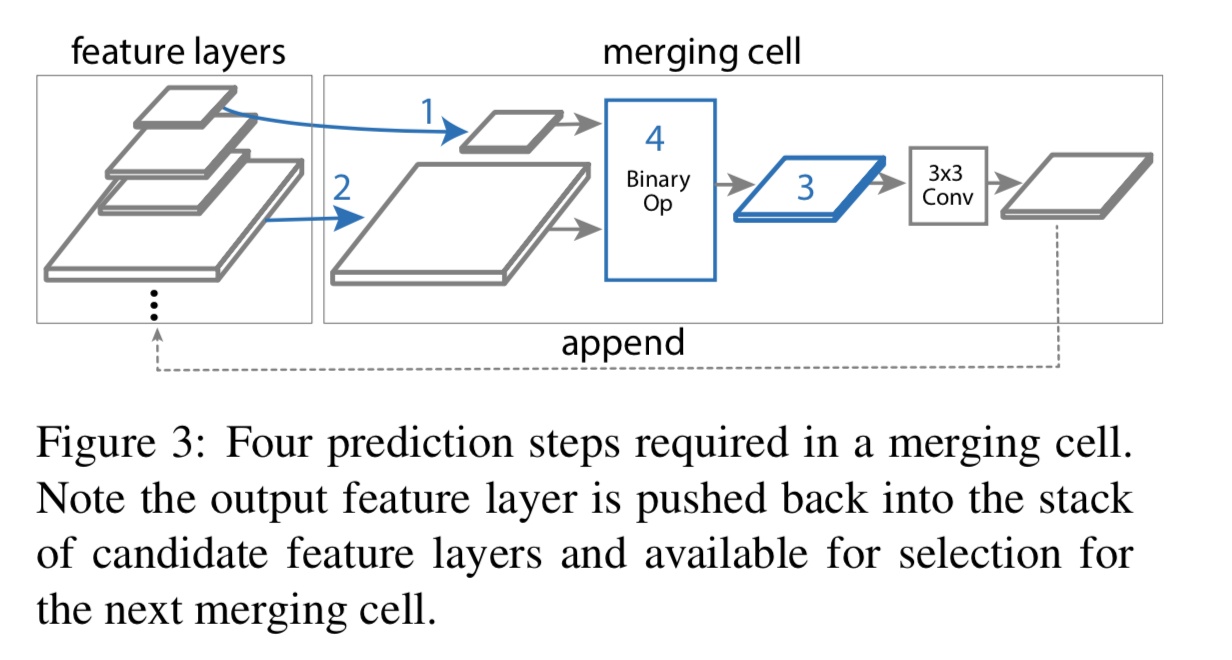
neck网络的Mearning cell数量作为超参,在搜索过程中是固定的,论文中取 ,也就是说有2个中间节点与5个不同分辨率的输出节点。
,也就是说有2个中间节点与5个不同分辨率的输出节点。
给定特征图节点集合 ,输出分辨率集合
,输出分辨率集合
- 从
 中选择两个节点
中选择两个节点 ,作为用于融合的两个特征输入(可以是不同分辨率的);
,作为用于融合的两个特征输入(可以是不同分辨率的); - 从
 中选择一个分辨率
中选择一个分辨率 ,作为输出分辨率(不允许
,作为输出分辨率(不允许 分辨率作为中间节点以节省开销);
分辨率作为中间节点以节省开销); - 从以下两个
 中选择一个,用于融合两个输入特征,并将融合后的节点
中选择一个,用于融合两个输入特征,并将融合后的节点 ,在3x3Conv-BN-ReLU后,重新加入输入节点集合。
,在3x3Conv-BN-ReLU后,重新加入输入节点集合。 5个分辨率的输出特征图的输出顺序也是NAS的RNN预测出来的,因此7个cell中的后5个cell的搜索只需要进行1,3步,输出分辨率已经由RNN controller指定好了。
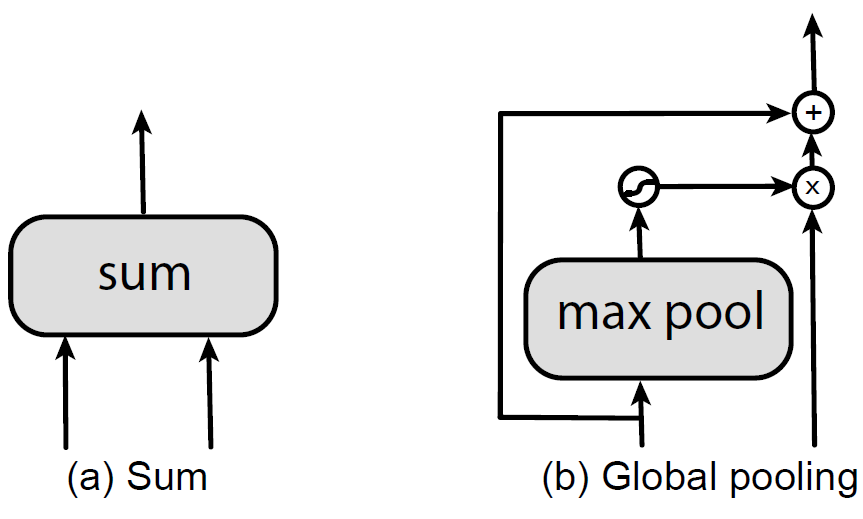<br />↑↑↑(特征融合op)
特征融合的 借鉴了Pyramid Attention Networks,即高层特征不适合和底层特征直接相加,而需要引入注意力机制有效融合。出于简单高效考虑,的构建删除了原有block的卷积层,并且没有引入任何可训练参数。另外,若的分辨率与不同,则通过最近邻上采样或max pool下采样调整至。
借鉴了Pyramid Attention Networks,即高层特征不适合和底层特征直接相加,而需要引入注意力机制有效融合。出于简单高效考虑,的构建删除了原有block的卷积层,并且没有引入任何可训练参数。另外,若的分辨率与不同,则通过最近邻上采样或max pool下采样调整至。
搜索过程
Proxy Task
NAS-FPN取了Proxy Task为,在COCO数据集上训练10-epochs(8-epochs时砍10倍学习率),而完整训练需要50-epochs(30/40-epochs砍10倍学习率)、带DropBlock的完整训练150-epochs(120/140-epochs砍10倍学习率)。。。DropBlock真的好难训,在CIFAR上自己做实验时200-epochs需要涨到500epochs。
为了减小搜索开销,NAS-FPN在搜索过程中还把backbone缩成了ResNet10,输入分辨率也缩成了512×512。反正搜的是neck网络,backbone部分怎么改应该问题也不大。
但是很神奇的是NAS-FPN在搜索阶段就把neck网络直接堆叠了3次!
搜索过程
下图展示了NAS搜索过程中的reward(左)和采样的结构数量/采样的非重复结构数量曲线(右)。从右图可以看到8000-steps后采样到的非常复结构就几乎没有了,搜索就基本已经收敛了。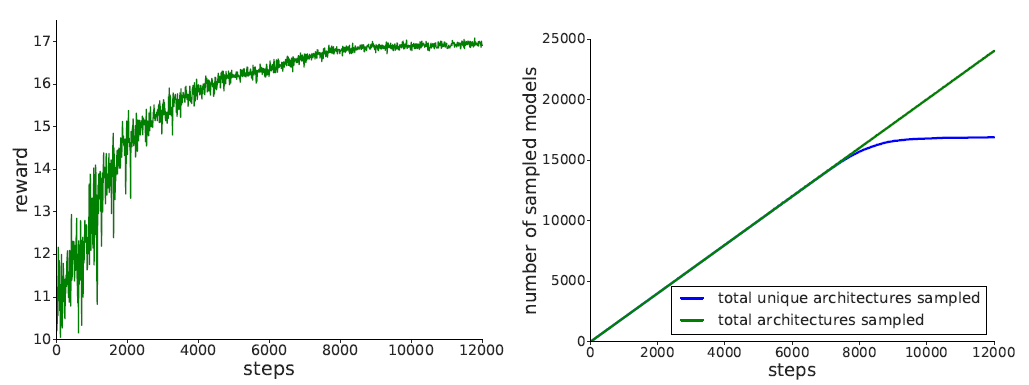
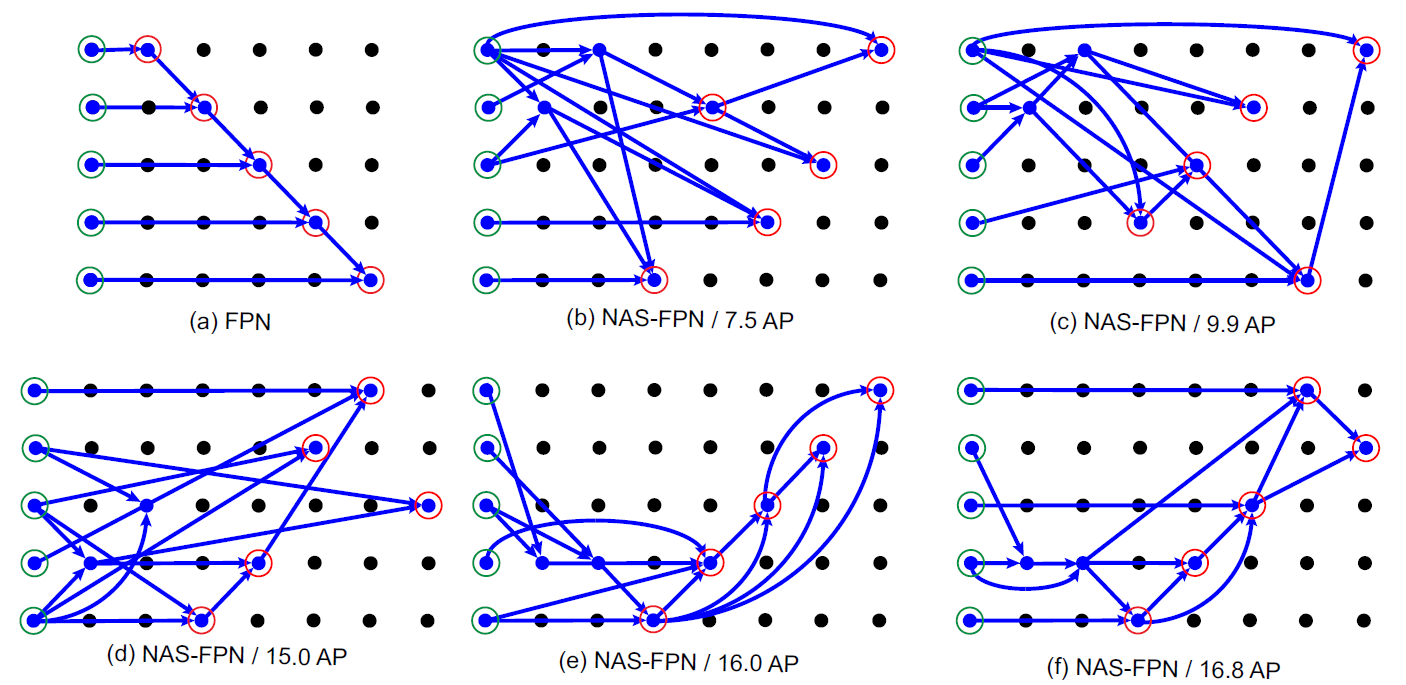
下图展示了NAS搜索过程中得到的一些中间结果(b~e)与NAS-FPN的最终结构(f)。可以看出在搜索初期(b),网络就已经发现了Top-down Path,在训练中期(d)又发现了Bottem-up Path。
虽说每个节点只接收两个输入,但是如果有特征图 没有连接至任何中间节点,则会被连接至
没有连接至任何中间节点,则会被连接至 ,因此有些节点会有三个输入,融合方式为先对其它两个节点通过
,因此有些节点会有三个输入,融合方式为先对其它两个节点通过 融合,融合后的节点再和通过
融合,融合后的节点再和通过 融合得到。(如NAS-FPN的
融合得到。(如NAS-FPN的 )
)
非常戏剧性的一点就是,PANet是2018年的论文,NAS-FPN是2019年的论文,但NAS-FPN在一开头提到了PANet但是没有和PANet比而是持续鞭尸FPN。
SpineNet
论文:SpineNet
尺度变换网络
不同于NAS-FPN搜了个neck,SpineNet直接在COCO上搜了个backbone。该论文认为单纯把分类网络迁移至目标检测任务作为backbone并不太好,因为传统分类网络只充当了编码器的角色(特征图分辨率逐渐降低),但目标检测、图像分割等高阶任务对空间信息要求较高,传统分类网络在编码过程中损失了过多的空间信息。对此作者提出了SpineNet,同时充当了编码器与解码器的角色——其层级间排列是被打乱的而非简单的Bottem-up。
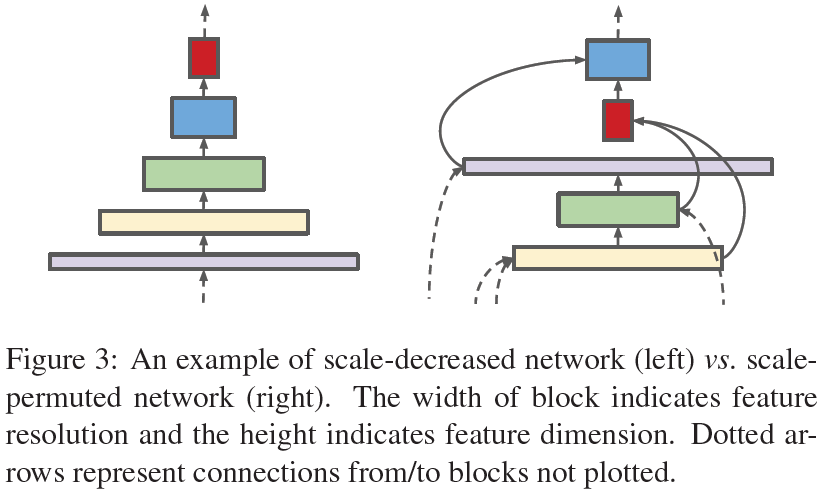
Scale-permuted network的每个block(除了前两个block)都接受两个任意层级的特征图作为输入,经过融合后再送入特征提取block。特征融合过程如下图所示: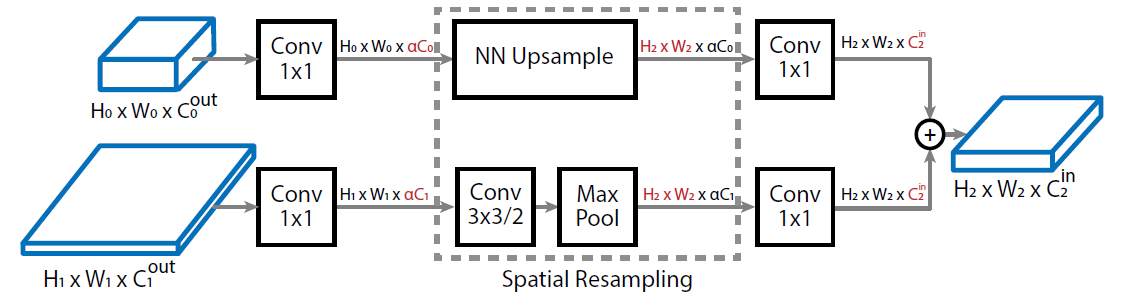
两个输入特征图首先经过1x1卷积降低通道数至 倍(论文中取
倍(论文中取 ),经过必要的上采样(插值)或下采样(stride-2 3x3卷积+maxpool如果必要)后再通过1x1卷积将通道数转换为目标block的宽度后,进行元素级加和,送入目标block进行特征提取。
),经过必要的上采样(插值)或下采样(stride-2 3x3卷积+maxpool如果必要)后再通过1x1卷积将通道数转换为目标block的宽度后,进行元素级加和,送入目标block进行特征提取。
搜索空间
前面说了,SpineNet的尺度变化网络中各层的层级顺序是打乱的。具体怎么确定呢?答对了,这可是谷歌发的论文,谷歌是干嘛的呢?NAS给老子搜出来。。。
层级顺序:每层的层级。这里搜的不是不同stage的排序,同一尺度的block是可以乱序出现的而不需要连着,因此SpaineNet里已经完全没有“stage”的概念了,网络有几个block就需要搜几次。论文中作者把中间block和五个输出block分开搜了,因此搜索空间为 。
。
层级连接:每个block接收哪两个输入,理论上每个block都可以接受任意两个比它更浅的block的输出作为输入,作者为了减小搜索空间,中间block只允许从离其最接近的前5个block中选择输入,但输出block依然允许从任意浅层选择输入。
Block调整:每个中间block都可以调整自己的层级(也就是分辨率-宽度),层级越高分辨率低/宽度大;层级越低分辨率高/宽度小。每个中间block都可以从 中选择一种层级改变方式。
中选择一种层级改变方式。
↑↑↑这么大的搜索空间是真的非常令人摸不着头脑,虽然作者在搜索过程中把整个网络的宽度都缩为了 ,输入缩成
,输入缩成 ,并且只训5 epchs,但这搜索空间依然是大的令人绝望啊。。。
,并且只训5 epchs,但这搜索空间依然是大的令人绝望啊。。。
实验结果
搜出来的SpineNet49如下图所示: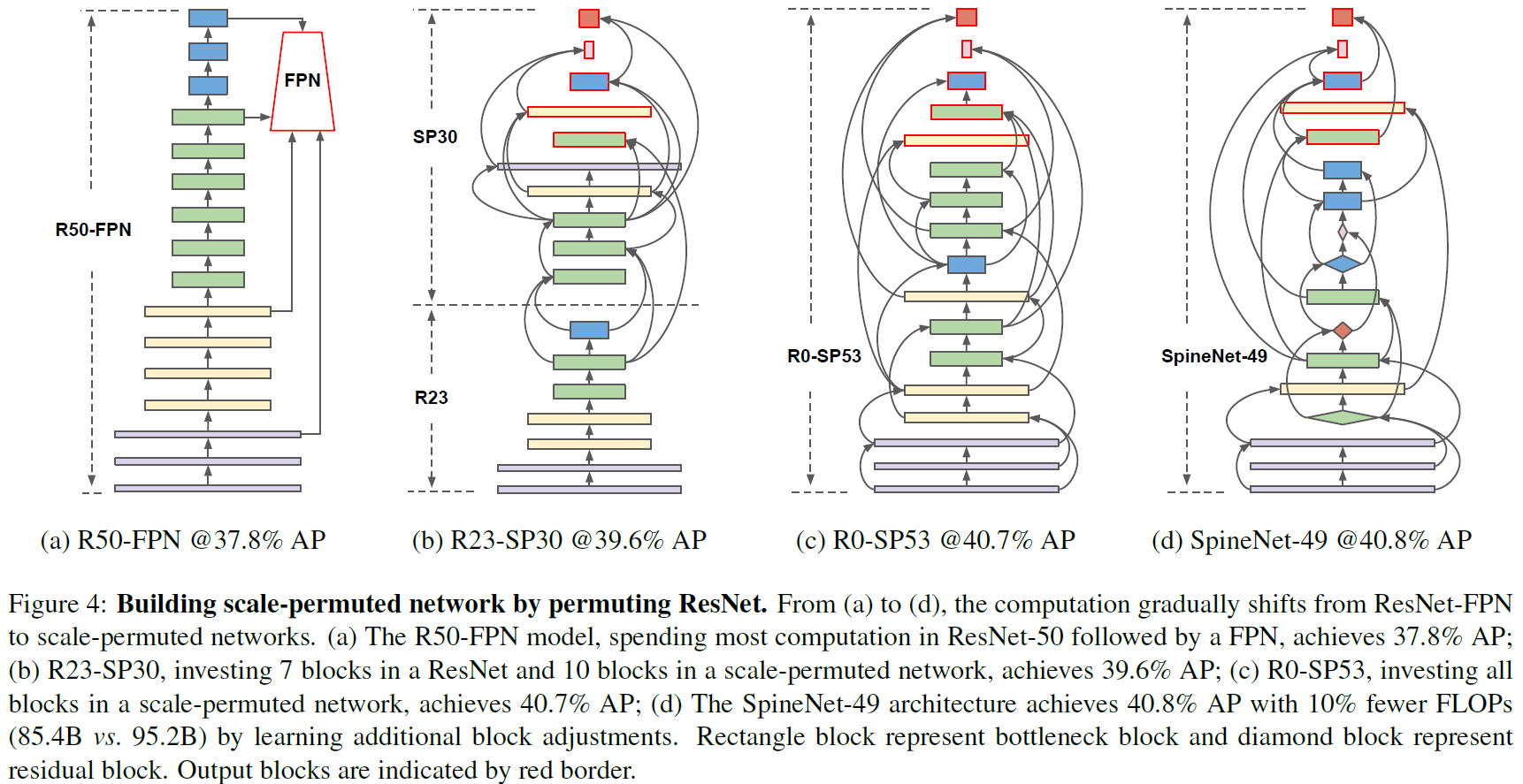
SpineNet还有其它几个尺寸:SpineNet49S单纯把网络宽度乘了0.65,SpineNet96把每个block堆了两次(接收融合完的两个输入后连续过两个相同的block再输出),SpineNet143把每个block堆了三次,SpineNet190把每个block都堆了四次外加把网络宽度乘了1.3。
GENet
论文:https://arxiv.org/pdf/2006.14090v1.pdf
参考:https://zhuanlan.zhihu.com/p/151042330
论文主要提出了,在不同的阶段采用不同的Block类型(BasicBlock、Bottleneck、Inverted Bottleneck)
三种Block的对比
文中将BasicBlock称为XX,Bottleneck称为BL,Inverted Bottleneck称为DW。
作者提出了衡量模型开销不能仅仅依据“广为所用的”FLOPS,FLOPS相同的模型可能推理耗时会大不相同。为此,作者构建了3个简单的网络用于评测XX、BL、DW三种Block对于推理耗时的影响。为了保证感受野相同,Net1包含5个XX Block,Net2包含10个BL Block,Net3包含10个DW Block。可以看出,当 时,BL、DW结构的效率非常低。
时,BL、DW结构的效率非常低。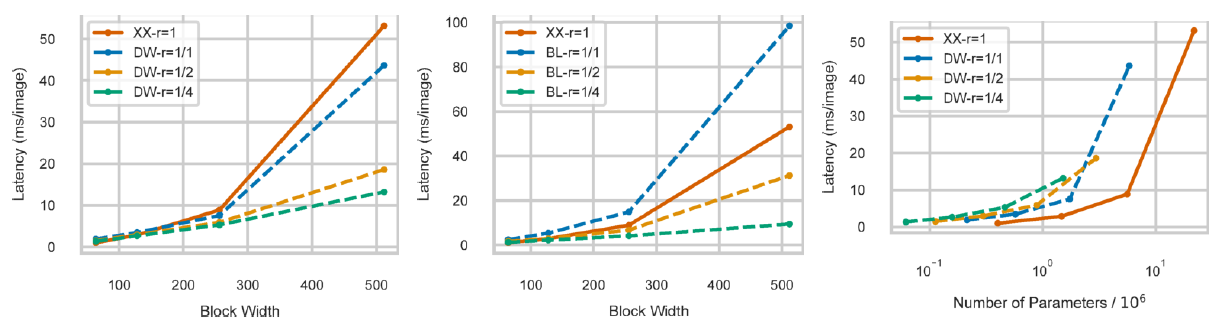
作者认为BL、DW理论上是对XX的一种低秩近似:
- BL用宽度较小的3x3卷积,结合1x1卷积对特征进行解码,以拟合较宽的3x3卷积的效果;
- DW则通过“DW卷积+PW卷积”,拟合常规3x3卷积的效果。
要良好地进行低秩近似地前提是,被近似的目标3x3卷积不是满秩而是低秩的,否则就必须设置BL、DW Block中的以尽可能地保留信息,而前面我们已经讨论了当时,BL、DW结构是非常低效的。
对此,作者研究了全部由XX Block构成的网络,其卷积核在不同stage上的奇异值分布情况,如下图所示(纵坐标为归一化后的奇异值,横坐标为归一化后的通道index)。可见更深的stage中,归一化后的奇异值下降趋势明显更强,因而进行低秩近似时的损失更小(参考矩阵的SVD的压缩方法)。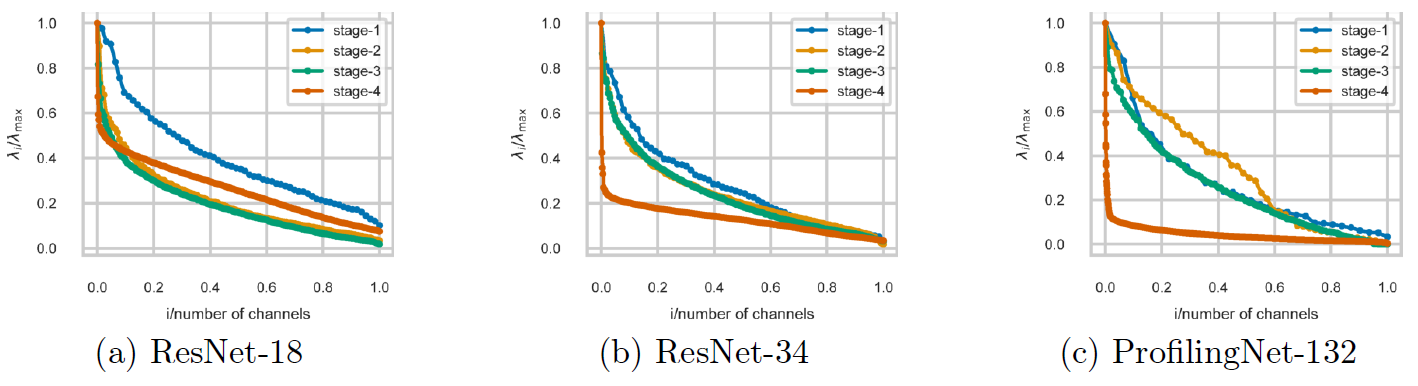
为此,作者提出了在浅层使用XX Block而在深层使用BL、DW Block。
实验结果
GENet是基于手工给定的前两个stage用XX Block、后两个stage用BL、DW的先验,用NAS搜出来的。但是感觉论文写的很烂,对此不想赘述,只是觉得作者对于不同stage采用不同Block Type的思想比较可取,对于卷积核的秩的分析比较在理。
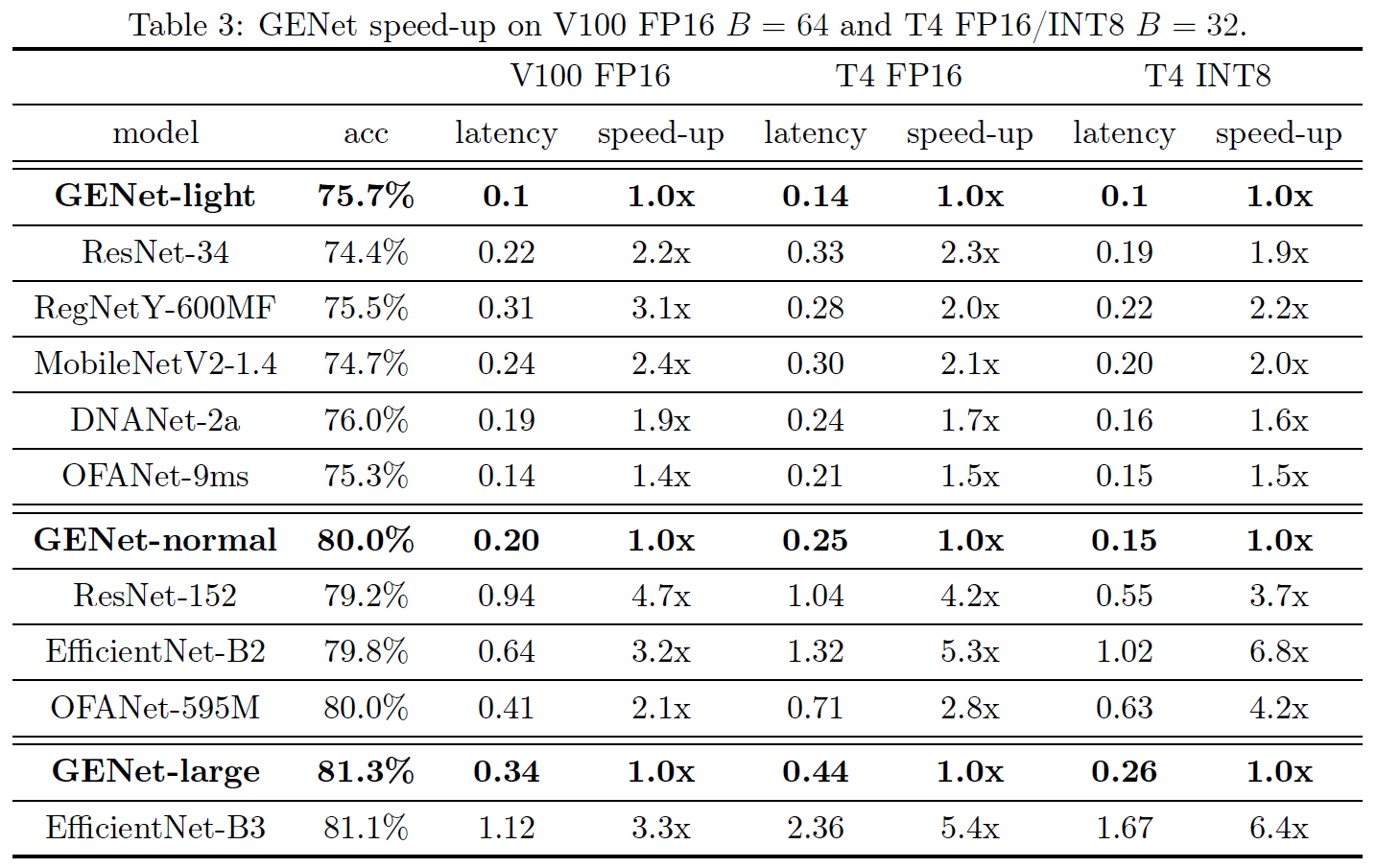
就简单列一下GENet的结构和实验结果吧。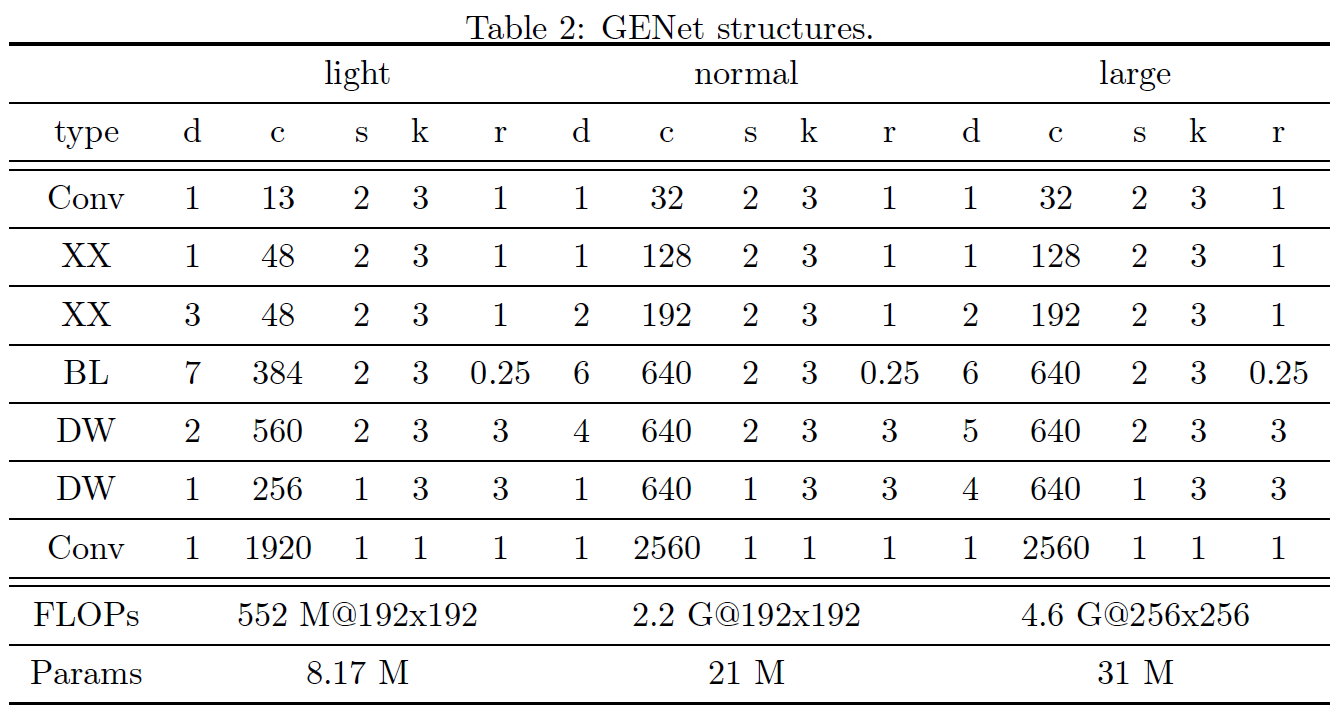

若有收获,就点个赞吧
0 人点赞
