GAN基本结构
GAN全称对抗生成网络,顾名思义是生成模型的一种,而他的训练则是处于一种对抗博弈状态中的。GAN的主要结构包括一个生成器G(Generator)和一个判别器D(Discriminator)。以下通过一个简单的例子展示了GAN的结构。
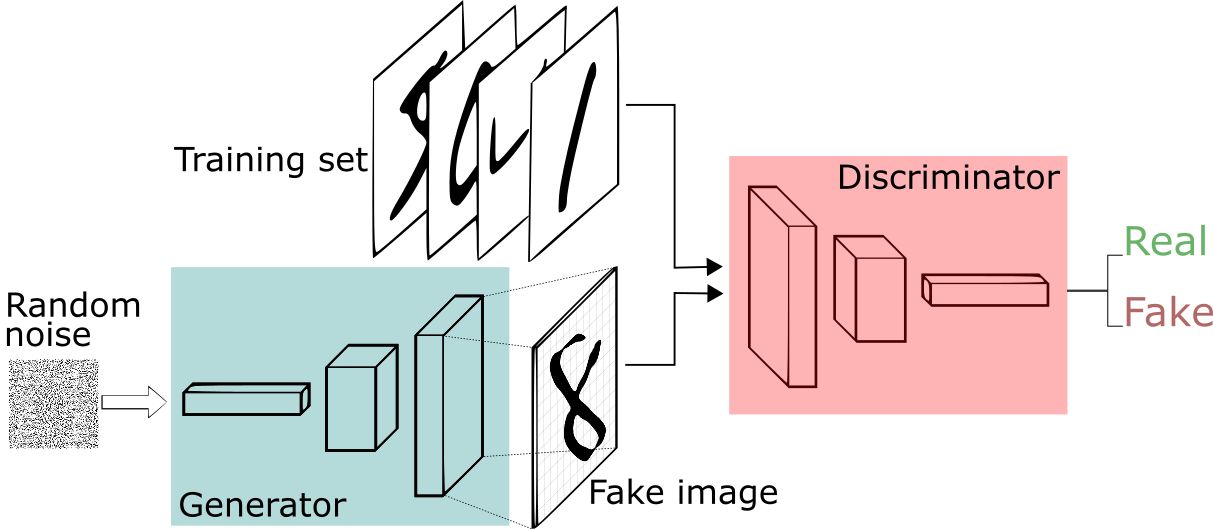
假设我们现在拥有大量的手写数字的数据集,我们希望通过GAN生成一些能够以假乱真的手写字图片。主要由如下两个部分组成:
- 定义一个模型来作为生成器(图三中蓝色部分),能够输入一个向量,输出手写数字大小的像素图像。
- 定义一个分类器来作为判别器(图三中红色部分)用来判别图片是真的还是假的(或者说是来自数据集中的还是生成器中生成的),输入为手写图片,输出为判别图片的标签。
这里生成器输入的向量我们将其视为携带输出的某些信息,在不加限制的情况下它们没有任何语义含义,可以为随机噪声。
GAN的训练过程如下:
- 初始化判别器
 和生成器
和生成器 的参数;
的参数; - 从真实数据集中采样m个真实样本
 ,从给定噪声分布中采样m个噪声样本
,从给定噪声分布中采样m个噪声样本 ,将它们输入生成器以获取m个生成样本
,将它们输入生成器以获取m个生成样本 。固定生成器,训练判别器以区分真实样本与生成的假样本。(当然一开始假样本都是随机噪声)
。固定生成器,训练判别器以区分真实样本与生成的假样本。(当然一开始假样本都是随机噪声) - 循环k次迭代更新后,使用较小的学习率来更新一次,训练生成器使其尽可能减小生成样本与真是样本之间的差距。(由于的训练依赖于,的准确度非常重要,因此一般的训练密度比高,即k>1)
- 多次迭代更新后,理想状况是:生成的假样本能够以假乱真,无法分辨出样本的真假。

若有收获,就点个赞吧
0 人点赞
