ResNet
论文:Deep Residual Learning for Image Recognition
网络退化
传统深层网络的训练会面临“退化”问题,虽然深层网络的表征能力更强,但是随着网络变得更深准确度反而可能会下降。这种“退化”并不是由过拟合引起的,因为不仅test loss,连train loss也会升高。
若网络能够拟合出恒等映射,即 ,那么更深层的网络至少不会比浅层网络表现的差(多出来的层全做恒等映射)。深层网络比浅层网络表现差,那就代表传统的卷积层很难对恒等映射进行拟合。因此作者提出了残差网络,不同于传统网络对
,那么更深层的网络至少不会比浅层网络表现的差(多出来的层全做恒等映射)。深层网络比浅层网络表现差,那就代表传统的卷积层很难对恒等映射进行拟合。因此作者提出了残差网络,不同于传统网络对 中的
中的 进行学习,残差网络学习的函数是
进行学习,残差网络学习的函数是 ,网络通过
,网络通过 进行前向传播。如果最终训练得到的权重函数相较zero mapping更接近identity mapping,那么采用残差结构的网络就会更容易训练。
进行前向传播。如果最终训练得到的权重函数相较zero mapping更接近identity mapping,那么采用残差结构的网络就会更容易训练。
网络结构概览
残差单元
作者提出了BasicBlock和Bottleneck两种残差单元,前者用于ResNet18、34,后者用于ResNet50、101、152。
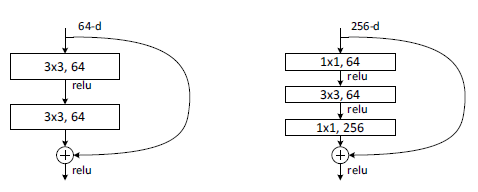
BasicBlock Bottleneck
BasicBlock在每个残差单元堆叠了两个卷积层,并将残差单元的输入短连接至残差单元输出进行元素级相加。Bottleneck的引入是为了在网络搭的深(权重层的层数多,1x1卷积也算)的同时减小计算量,另外一前一后通道数不同的1x1卷积扮演者编码器、解码器的角色,更有利于3x3卷积的有效学习。
虽然我觉得Bottleneck很神奇,明明能有效提取特征的3x3卷积的层数变少了,取而代之的是两层只能做特征融合和编解码的1x1解码,反而效果却更好……
在Wide ResNet的论文中(之后会讨论)作者做了实验,每个BasicBlock单元包含1/2/3/4个33卷积时效果如何,结果是每个单元2层卷积最好。另虽然Bottleneck和BasicBlock的FLOPS差不多,但由于并行度低或者硬件不友好,GPU训练起来Bottleneck慢很多(CPU测试差的不多)。
Bottleneck结构的feature map下采样在33卷积做(第一个1*1只变通道)!
短连接下采样
在面临下采样和通道变化时(645656->1282828),ResNet的shortcut有三种形式:
- 128通道中前64通道复制,后64通道补零;
- 进行stride=2的1x1卷积进行通道变换;
- 除了在下采样时,在其它所有残差单元的shortcut都引入stride=1的1x1卷积。
主要是(b)方案用的比较多,(c)方案引入了更多的参数。另外ResNet v2的提出也依赖该方案。
###短连接分支的1x1卷积后是有BN的!
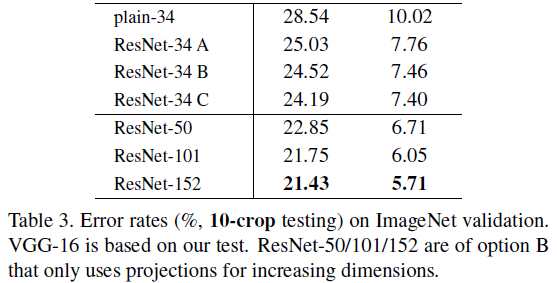
网络结构
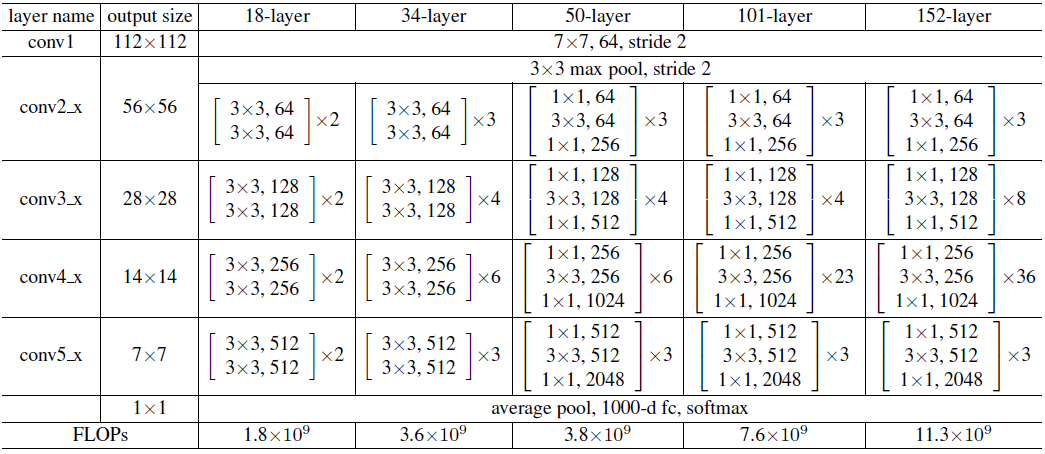
需要注意的是,ResNet18、34、50、101、152的层数计数包含了所有卷积层(包括1x1卷积)以及最后的全连接层。
在CIFAR中使用时,由于CIFAR的输入只有3232,第一个stride=2的7x7卷积被改为了stride=1的33卷积,且maxpool被删除。剩下的4个stage被改为了3个stage,且每个stage堆叠了相同数量的残差单元,残差单元全部使用BasicBlock。(这是论文中的方法)

ResNet v2
论文:Identity Mappings in Deep Residual Networks
在ResNet v1中,受残差单元最后的ReLU的影响,前后向传播都不能完整地传递最干净的原始信息。作者提出了一种pre-activation残差单元,使得每一层的前后传都能将最干净原始的信息送到下一层。 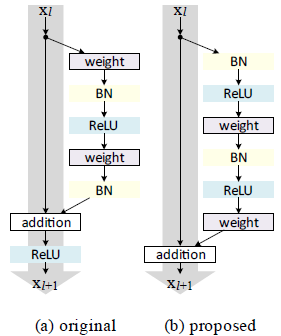
这种结构还能带来良好的前后传性质,前传过程中输入信号能被完完整整地传递到任意深度的层,而反传时最后一层的梯度也能被完完整整地传递到任意浅的层。

作者在文中展示了以下5种残差单元结构在CIFAR-10上的结果。
- ResNet v1的原始结构;
- 该结构在shortcut通路中又增添了其它部件导致了精度下降;
- 该结构中残差部分的输出被ReLU限制为非负数,因而每层的输出必然递增,导致模型拟合能力下降;
- 该结构中ReLU没有与BN一起使用,导致其没能享受到BN带来的优势。
- full pre-activation结构为ResNet v2中使用的残差单元结构。
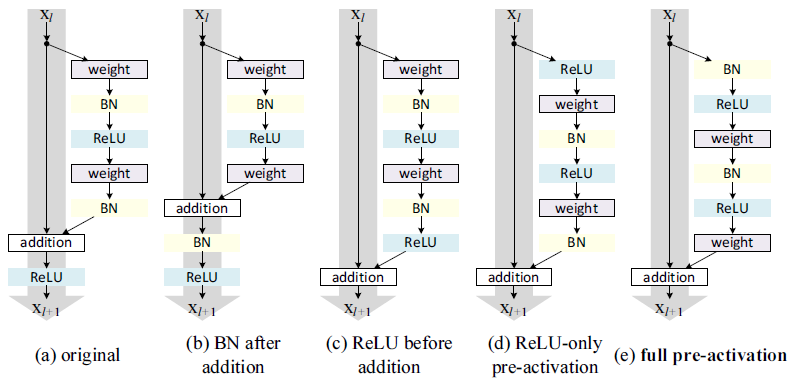

作者在实验中观察到,采用残差结构(a)的网络在训练一段时间后,addition以后的结构趋向于大于0而受ReLU的影响变小。但是在1001层网络中,网络很难适应,因而一开始时loss曲线下降缓慢。另外残差单元(e)还有一定的防止过拟合的作用,因为(a)中的BN仅仅对残差部分起作用,而(e)中BN在下一层的残差分支中进行,保证输入权重层的数据是经过了BN的。
ResNet v2的forawrd函数(torchvision.models中只有ResNet v1,v2需要自己写):
def forward(self, x):x = self.conv1(x)# x = self.bn(self.relu(x)) #延后到第一个残差单元处进行x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.bn(self.relu(x)) #补上最后一个残差单元后的BN和ReLUx = self.avgpool(x)x = torch.flatten(x, 1)x = self.fc(x)
Wide ResNet
深层的网络会面对梯度爆炸、梯度消失、退化等问题,虽然现在已经有很多人提出了很多方法去避免它们。在ResNet架构下,提升相同的准确率往往需要网络的深度翻为两倍才能达成,这造成了深层的ResNet计算量巨大但提升微乎其微。
ResNet的残差结构使得我们能更好地训练深层网络,但是这种结构从另一方面来说也是一个缺点:梯度能够流畅地经短连接通过所有的层而不会强迫其通过残差部分,使得很多残差单元实际上都没能学到有效信息,对最终结果的贡献微乎其微。对于ResNet,有人提出随机禁用残差单元的方法,这实际上是一种dropout的特例。
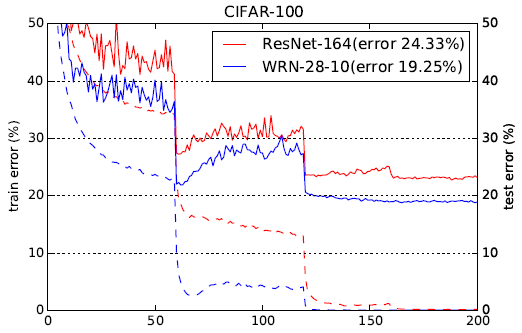
论文里说砍第一刀学习率之后训练集和测试集的loss/error会上涨直到下一次砍学习率,作者认为这是由于weight_decay导致的,但是减小weight_decay会导致最终结果显著下降。自己跑了实验以后以后发现确实是这样的(CIFAR100,ResNet26,k=6,lr=0.4 [100,150]x0.1,warmup 2epc,totally 200epc,SGD_Nesterov),其中黄线weight_decay=0.0001,蓝线weight_decay=0.0005。L2比较小的时候第一刀学习率砍了以后train_loss就基本到0了没得训了,模型有一定的过拟合。
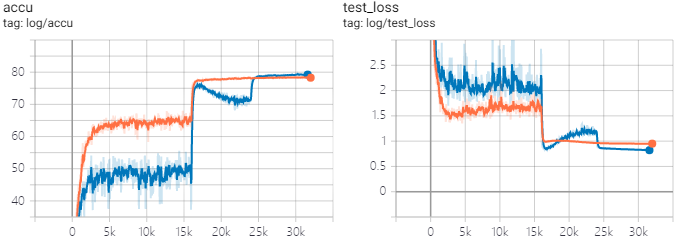
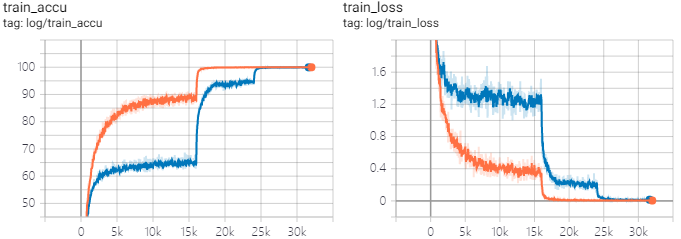
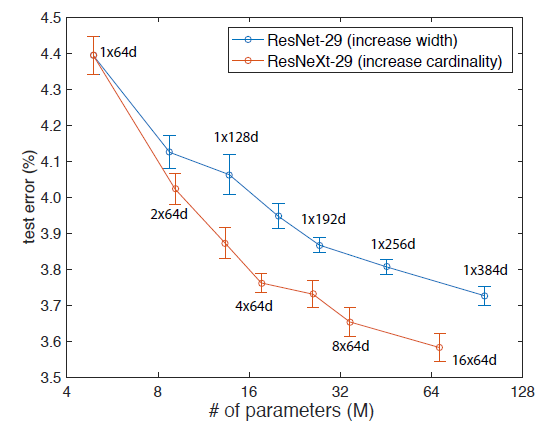
剩下的就是说一味加深有的时候没有把网络加宽来的有效。
DenseNet
论文:Densely Connected Convolutional Networks
DenseNet因为内存开销大而臭名远扬,但思想值得借鉴学习
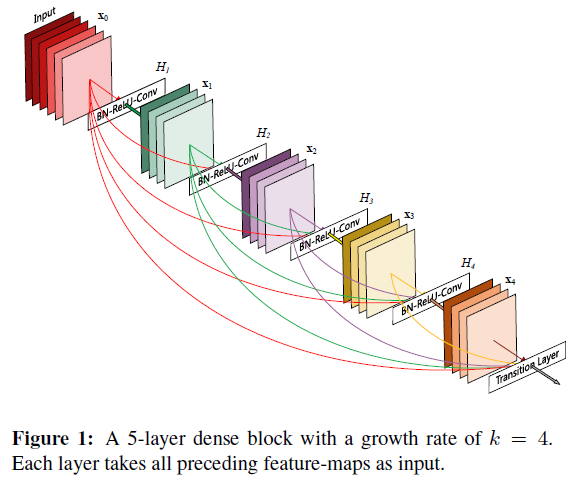
DenseNet提出的思想就是浅层的特征与所有深层均通过特征图拼接的方法连接。对比一下ResNet与DenseNet的结构,我们可以发现:

DenseNet的作者认为,ResNet中采用的通过将权重层输出与恒等映射相加的方法可能会阻碍信息流在网络中的传递,因此DenseNet采用了特征图拼接的方法将浅层信息传递至深层(就是直接把浅层若干通道的特征concat到深层输入的通道上)。为了进一步提高层之间的信息流传递效率,DenseNet采用了稠密连接,浅层会与所有更深的层连接。
一个DenseBlock内第 层的输入通道数为
层的输入通道数为 ,输出通道为
,输出通道为 。
。
论文中作者给出的官方growth_rate均为32。
网络结构概览
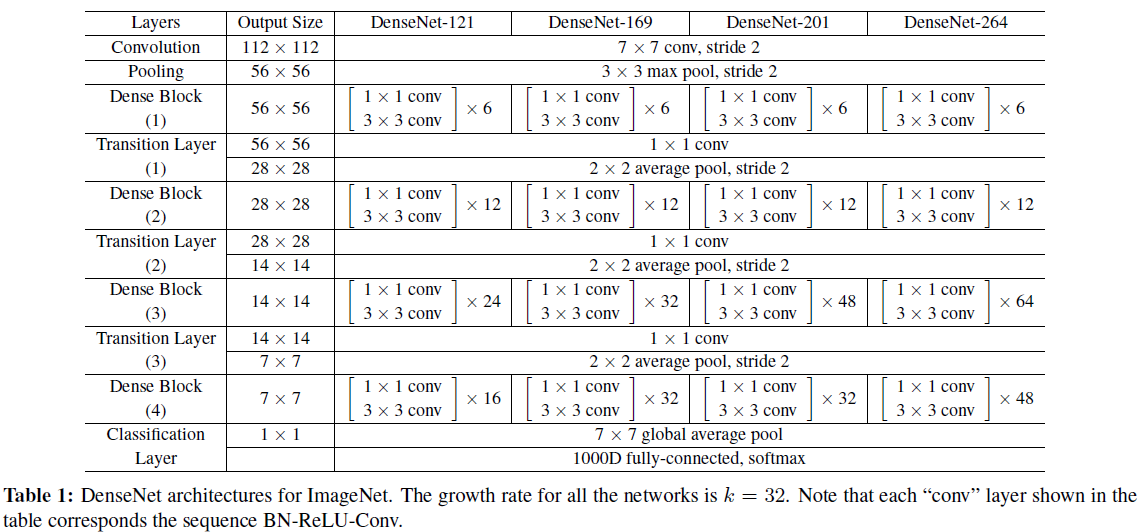
以层数最少的DenseNet121为例,DenseBlock(4)中的输入通道数已经非常非常多了,Block中每层的输出都再增添32个通道,最后一层的输入通道就达到了1856以上,做一个 的3x3卷积是非常昂贵的。因此作者在每个33卷积之前增加了一个11卷积用于对压缩通道,将每个33卷积的输入通道始终保持在4growth_rate,也就是说现在每层我们都只做一个
的3x3卷积是非常昂贵的。因此作者在每个33卷积之前增加了一个11卷积用于对压缩通道,将每个33卷积的输入通道始终保持在4growth_rate,也就是说现在每层我们都只做一个 的3x3卷积(代码中bn_size给的4,也就是输入通道为growth_rate*bn_size=128)。
的3x3卷积(代码中bn_size给的4,也就是输入通道为growth_rate*bn_size=128)。
Transetion Layer
上述代码中第28行:每个DenseBlock(不是DenseLayer)结束时(每个stage的末尾),都有一个transition layer用于对传入下一个DenseBlock的FeatureMap进行通道压缩,作者提出的方法是直接把通道数减半。论文中比对了是否做通道压缩的模型,不进行通道压缩的记为 ,进行通道压缩的记为
,进行通道压缩的记为 。结果是同等计算量下,进行通道压缩的模型性能远好于不进行通道压缩的。
。结果是同等计算量下,进行通道压缩的模型性能远好于不进行通道压缩的。
Transition layer的另一个作用时用来对feature map通过AvgPool做下采样。不知道为什么作者要先做1*1卷积后做AvgPool,先做AvgPool明明可以把卷积计算量降4倍啊???
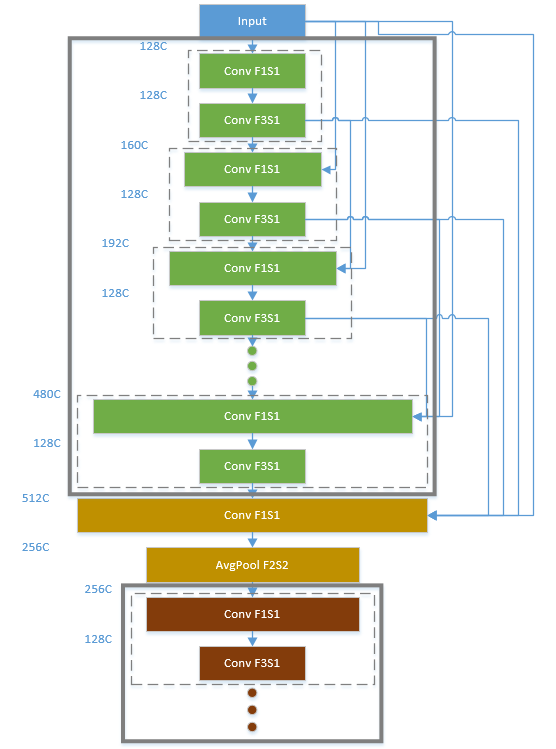
DenseBlock缩略图
我们来梳理一下这个极度复杂的网络:(虚线DenseLayer,粗线DenseBlock)
Block内浅层与所有深层连接,深层获取Block的输入特征图,以及所有Block内浅层提供的每层32通道的特征图。Transition Layer在每个Block后(最后一个Block后没有),包含一个11卷积和一个22的AvgPool,前者用于压缩通道数,后者用于对FeatureMap下采样。
↓↓↓↓↓DenseNet的pytorch代码
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16),num_init_features=64, bn_size=4, drop_rate=0, num_classes=1000, memory_efficient=False):super(DenseNet, self).__init__()# First convolutionself.features = nn.Sequential(OrderedDict([('conv0', nn.Conv2d(3, num_init_features, kernel_size=7, stride=2,padding=3, bias=False)),('norm0', nn.BatchNorm2d(num_init_features)),('relu0', nn.ReLU(inplace=True)),('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),]))# Each denseblocknum_features = num_init_featuresfor i, num_layers in enumerate(block_config):block = _DenseBlock(num_layers=num_layers,num_input_features=num_features,bn_size=bn_size,growth_rate=growth_rate,drop_rate=drop_rate,memory_efficient=memory_efficient)self.features.add_module('denseblock%d' % (i + 1), block)num_features = num_features + num_layers * growth_rateif i != len(block_config) - 1:trans = _Transition(num_input_features=num_features,num_output_features=num_features // 2)self.features.add_module('transition%d' % (i + 1), trans)num_features = num_features // 2self.features.add_module('norm5', nn.BatchNorm2d(num_features))self.classifier = nn.Linear(num_features, num_classes)
特征复用性
作者提出,DenseNet可以在模型参数数量远小于ResNet的情况下获得更高的精度,由于参数数量少同时具有防止过拟合的能力。DenseNet的一个最主要的特征就是特征的重复使用(features reuse)。
作者在CIFAR-10上训练了一个40层(每个block有12个DenseLayer),growth_rate=12的DenseNet,并画出了层间特征传递对应的卷积权重平均绝对值大小热力图。
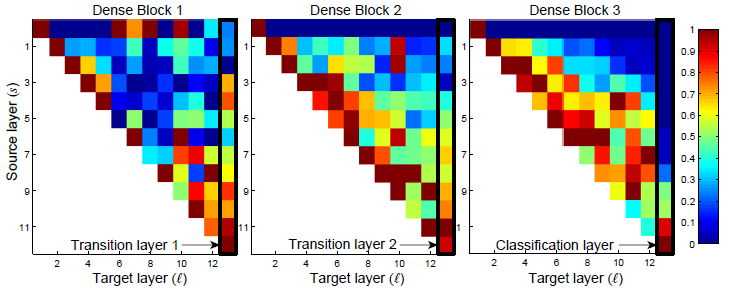
从热力图中我们可以看到:
- 不少浅层提取得到的特征都被更深的网络层直接利用了
- 过渡层指示了信息间接地从第一层流向最后一层
- 第2、3个block热力图的最上面一行指示了上一block中的信息几乎没有被深层用到,代表它们输出了很多冗余特性,因此过渡层压缩通道的做法是非常有效的
- 尽管充当分类器的全连接层使用了多个浅层的结果,但它依然趋向于使用更深层的特征。
遗留问题
DenseNet一开始的conv1层的BN和ReLU感觉没用啊,反正进了DenseBlock一上来就是BN和ReLU。
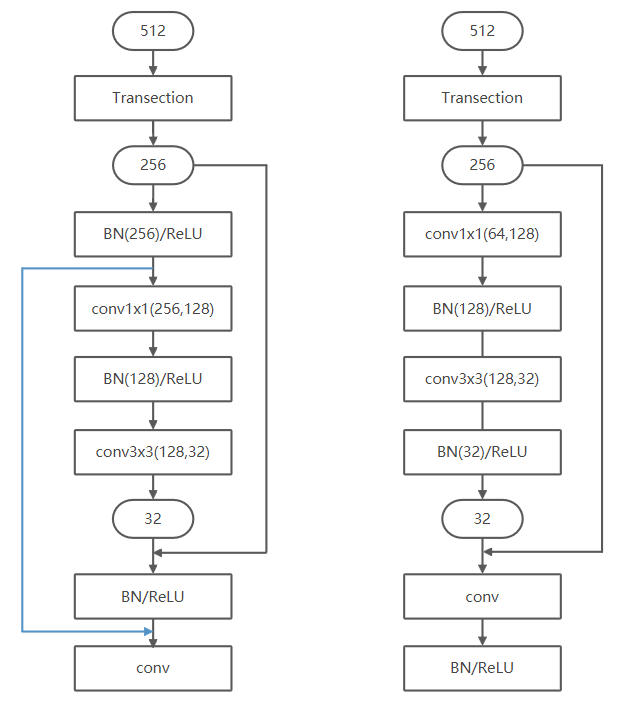
另外以下图为例,过了Transection Layer后的256通道特征被反复BN、ReLU了很多遍,如果更换conv和BN、ReLU的顺序就可以让BN和ReLU接收通道更少的FeatureMap(左边蓝线,网络结构变为右边)。ResNet v2将BN和ReLU提到conv前是为了维护短连通路的干净,DenseNet应该不要紧?
ResNeXt
论文:Aggregated Residual Transformations for Deep Neural Networks
尽管Inception的“拆分-卷积-合并”结构获得了可观的精度,但是每个Block内的结构都需要根据数据集精心配制,其泛化性能较为欠缺。作者以原始ResNet的结构为基础,提出了一种新的,非常简单的,能够泛化的,多分支卷积神经网络,如图右所示。
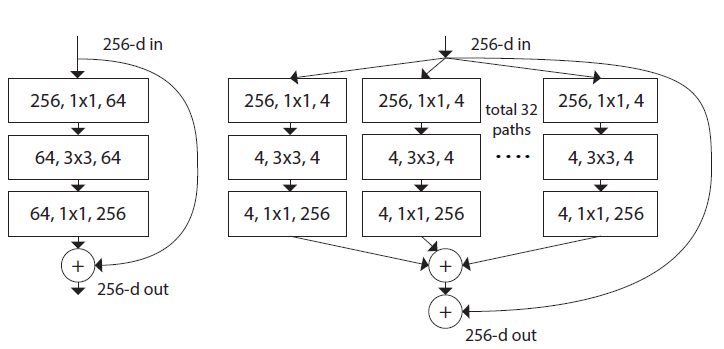
ResNet ResNeXt
ResNeXt简单的将原来ResNet残差单元中的3x3卷积使用分组卷积(group convolution)进行。“分解”是一种常用的,减少网络冗余部分并降低复杂度和模型大小的方法。
ResNeXt中通过 表示残差单元,其中
表示残差单元,其中 代表3x3卷积层的分组数,
代表3x3卷积层的分组数, 代表分组卷积中每一组的通道数。譬如上图右侧展示的ResNeXt单元就可以通过
代表分组卷积中每一组的通道数。譬如上图右侧展示的ResNeXt单元就可以通过 来表示。
来表示。
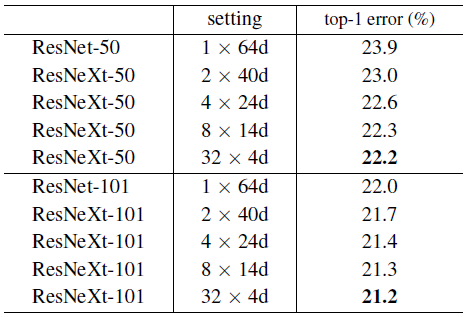
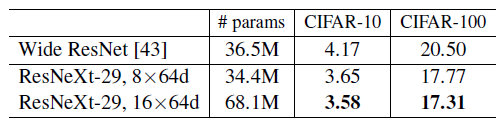
作者展示了保证计算量相同时,不同组数与组内宽度的组合对结果的影响,其中1*64d对应了原始的ResNet Bottleneck。可以看出在ImageNet数据集下, 的结果最好。
的结果最好。
但是到了CIFAR数据集中,情况却变得不那么一样,组内宽度 较小的网络基本直接去世,作者也没解释为啥会这样直接在做CIFAR实验的时候用了
较小的网络基本直接去世,作者也没解释为啥会这样直接在做CIFAR实验的时候用了 。
。
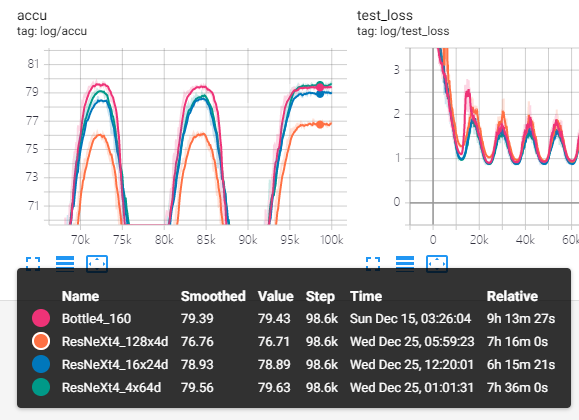
我自己也做了实验,测试了 四种单元在CIFAR100下的性能。论文里用的
四种单元在CIFAR100下的性能。论文里用的 计算量大的恐怖懒得跑。结果确实是相同计算量下组内宽度更大的情况下更好,但和作者得出的ResNeXt比Wide ResNet好不符。
计算量大的恐怖懒得跑。结果确实是相同计算量下组内宽度更大的情况下更好,但和作者得出的ResNeXt比Wide ResNet好不符。
CIFAR模型性能
| 网络 | 深度/宽度 | 参数数量 | C10+ | C100+ |
|---|---|---|---|---|
| ResNet | 110/16 | 1.7M | 6.41 | 27.22 |
| 164/16 | 1.7M | - | 25.16 | |
| ResNet v2 | 164/16 | 1.7M | 5.46 | 24.33 |
| 1001/16 | 10.2M | 4.62 | 22.71 | |
| Wide ResNet | 16/128 | 11.0M | 4.81 | 22.07 |
| 28/160 | 36.5M | 4.17 | 20.50 | |
| DenseNet-BC | 100/k=12 | 0.8M | 4.51 | 22.27 |
| 250/k=24 | 15.3M | 3.62 | 17.60 | |
| 190/k=40 | 25.6M | 3.46 | 17.18 | |
| ResNeXt | 29/8x64d | 34.4M | 3.65 | 17.77 |
| 29/16x64d | 68.1M | 3.58 | 17.31 |

若有收获,就点个赞吧
0 人点赞
