RePr(CVPR2019)
论文:https://arxiv.org/pdf/1811.07275.pdf
乍一看还以为是裁剪,细看才发现是一种训练的trick。论文提出,在训练中期裁掉那些和同一层中其它filter相关性高的filter后(通道级裁剪)继续训练,之后再把裁掉的filter补回来重新初始化后做finetune以强迫模型学到新的特征,当然最后也可以直接把裁掉的filter去掉以实现裁剪的目的。
伪代码:
for N iterations dofor S1 iterations doTrain the full network: M_FendCompute the metric : R(f) ∀ f ∈ FLet Fb be bottom p% of F using R(f)for S2 iterations doTrain the sub-network : M_(F−Fb)endReinitialize the filters (Fb) s.t. F ⊥ F bend
正交性矩阵
正交性矩阵决定了哪些层的哪些通道会被裁掉,也就是用于决定上面伪代码中的 是什么。
是什么。
假设层 中输入通道为
中输入通道为 ,输出通道为
,输出通道为 ,包含了
,包含了 个shape为
个shape为 的filter。我们将每个filter都拉成一个一维的长向量,得到
的filter。我们将每个filter都拉成一个一维的长向量,得到 个长为
个长为 的向量,计算两两间的余弦距离(向量的cos夹角),得到一个
的向量,计算两两间的余弦距离(向量的cos夹角),得到一个 的相关性矩阵
的相关性矩阵 ,其中
,其中 表示第
表示第 个filter与第
个filter与第 个filter的相关性。
个filter的相关性。
记 ,
, 表示了层
表示了层 中第
中第 个filter与该层中其它filter的正交性,
个filter与该层中其它filter的正交性, 代表该filter与该层其它filter的相关性越高,可以裁掉。
代表该filter与该层其它filter的相关性越高,可以裁掉。
遍历卷积神经网络的每个层,得到所有层中所有滤波器的正交性 ,取出其中的
,取出其中的 裁掉。(正交性的计算是在层内计算的,但裁是按整个网络裁的而非一层层裁,可能有一层被裁了一大半而有些层一个通道都没被裁)
裁掉。(正交性的计算是在层内计算的,但裁是按整个网络裁的而非一层层裁,可能有一层被裁了一大半而有些层一个通道都没被裁)
延伸
论文:Soft Filter Pruning for Accelerating Deep Convolutional Neural Networks
这篇文章是IJCAI 2018的论文,提出的思路非常类似,只不过依赖的不是通道间的相关性,而是每个滤波器的L2范数。也是训一会裁,裁掉重新初始化。
实验结果
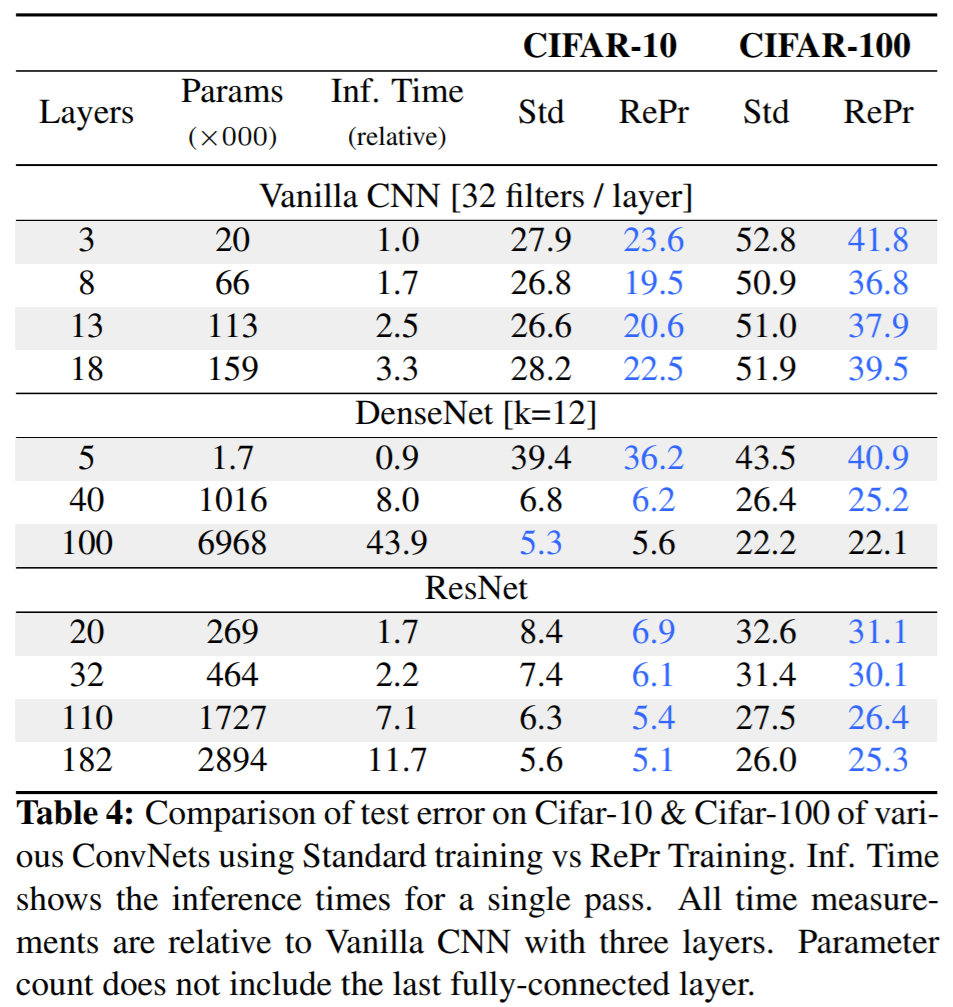
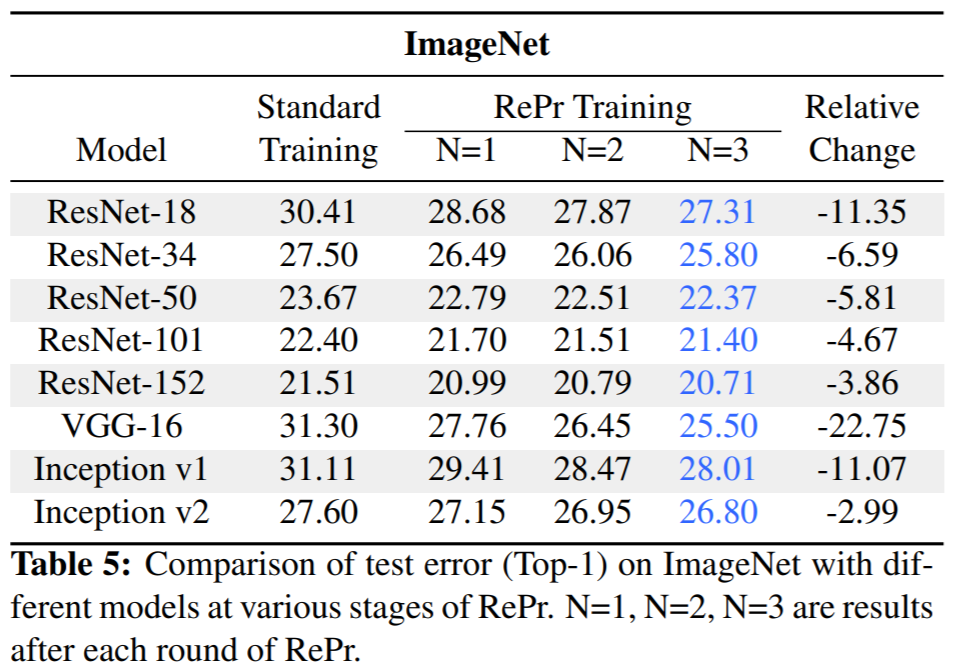
你他娘的学术造假
参考博客:https://blog.csdn.net/mooneve/article/details/88535805
撕逼现场:https://www.reddit.com/r/MachineLearning/comments/ayh2hf/r_repr_improved_training_of_convolutional_filters/(翻墙)
第三方实现:https://github.com/siahuat0727/RePr
这篇论文的思路确实有点儿意思,可是实际做出来结果如何?作者并没有开源代码,结果存疑。
复现采用了和文中一致的Vanilla网络,包含3个宽度为32,没有stride、没有BN的卷积层,并拉了一个超级大的323232的全连接。
第三方的实现结果表示,通道间的余弦相似度会随着通道的入度变大而变小,因此浅层,特别是入度仅为3x3x3的第一个卷积层,其余弦相似度非常高,采用论文方法进行prune会裁掉所有的第一层卷积通道并且模型直接爆炸。解决方法有两个:
1. 在计算相似度时乘上一个和入度大小有关的因子,譬如sqrt(入度)、入度^0.25等;
2. 论文中筛选需要裁剪的通道时是整个网络一起筛的,改为逐层筛。
实测这两种方法都没用,与baseline的对比:
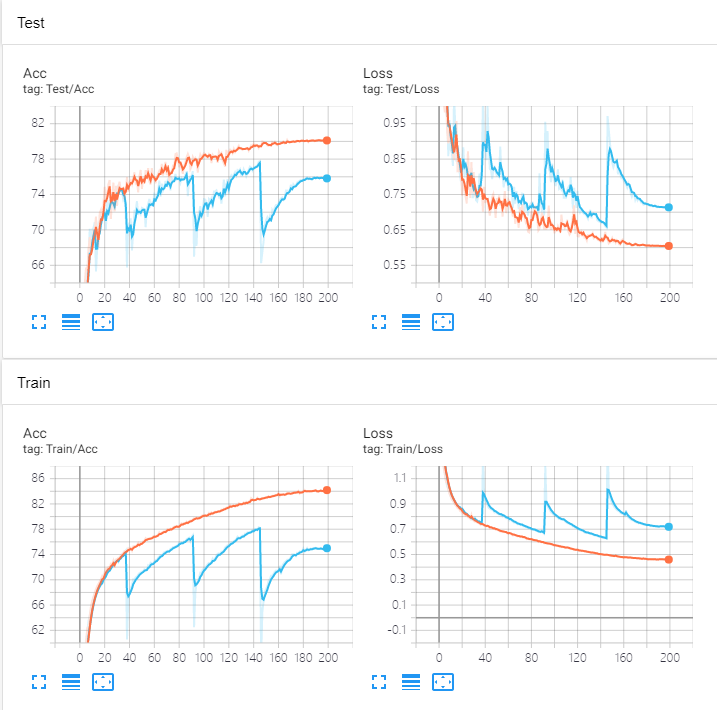
于此同时,观察到被裁掉并重新恢复的通道,其反传的梯度明显低于其它没被裁的通道,第三方复现者们也都提出了同样的问题,但论文作者表示在他这里重新初始化的通道反而梯度明显更大。三层中每一层都如此,梯度只有没被裁通道的1/5~1/3。于是强行手动把之前被裁了又重新初始化的通道的梯度每次放大10倍,以求对重新初始化通道更快的训练,结果从76涨到了78+,但依然比baseline差。
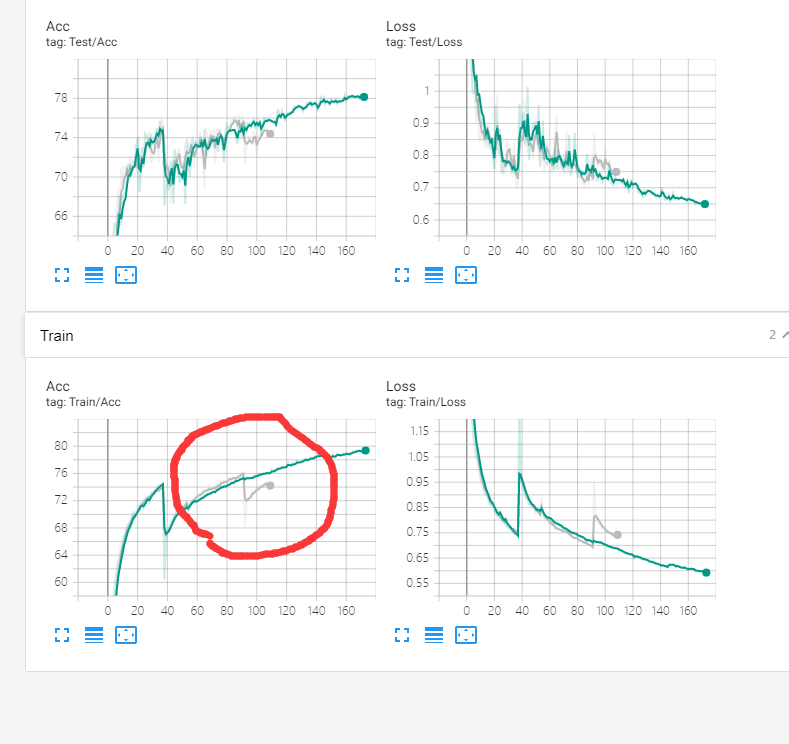
为了验证这些通道确实是有效的,我在第一次裁剪、恢复训练子网络、重新初始化倍裁通道联合训练后,在第二次裁剪时,不根据正交性裁,而是直接继续裁第一次被裁的那些通道。结果发现——裁了以后完全不掉点,不会有按正交性裁的时候那样断崖式的精度下降之后再慢慢恢复回来。也就是说,这些被恢复回来的通道完全没学到任何有用的信息。
ENC(CVPR2019)
论文:https://arxiv.org/pdf/1811.12781.pdf
少有的对低秩压缩的研究,不过感觉也没啥新意,算是比较水的一篇顶会了吧,看都看了简单记一下吧。用到的低秩方法仍然是SVD,没有介绍具体的实现不过作者开源了。(用SVD似乎只能用im2col不能用winograd)论文里在讨论的也是如何为各层寻找合适的r。论文里说了也有人用强化学习做过了(应该是类似NAS的方法),作者的说法是这种方法搜索开销大,他的方法搜索开销小。ENC即Efficient Network Compression的简称,好土- -
度量方法
作者为每层的SVD秩 都采取了一定手段进行度量,评价它们的效果是否良好,这一评价是逐层进行的。这里作者提出了两种度量手段。虽说不同层的秩
都采取了一定手段进行度量,评价它们的效果是否良好,这一评价是逐层进行的。这里作者提出了两种度量手段。虽说不同层的秩 对整个模型的影响并非独立,作者近似地将它们分开看待。
对整个模型的影响并非独立,作者近似地将它们分开看待。
- 基于PCA能量
这个最简单粗暴,直接计算奇异值之和的占比: ,其中
,其中 。
。
- 基于验证集精度
检查第 层地秩
层地秩 的影响时,固定其它所有层的秩,单独研究
的影响时,固定其它所有层的秩,单独研究 变化时,验证集精度的变化。相比基于PCA能量的度量方法
变化时,验证集精度的变化。相比基于PCA能量的度量方法 ,这种方法需要在验证集上跑推理。
,这种方法需要在验证集上跑推理。 的计算方法与
的计算方法与 类似,只不过
类似,只不过 的含义变为了验证集的精度。
的含义变为了验证集的精度。
为了能够一次性评价一组秩的config: ,作者简单粗暴地把每层的
,作者简单粗暴地把每层的 或
或 乘起来:
乘起来:
 ,
, 。
。
作者发现在实验中,在压缩率较高的情况下 表现不太好,因为基于PCA能量的度量指标并没有直接和模型精度挂钩。而压缩率较低,模型较为冗余的情况下,基于验证集精度的度量方法
表现不太好,因为基于PCA能量的度量指标并没有直接和模型精度挂钩。而压缩率较低,模型较为冗余的情况下,基于验证集精度的度量方法 不能很好地指导压缩(毕竟冗余网络压了很多可能精度都不掉),作者又提出了另一种结合了以上两种方法的度量指标:
不能很好地指导压缩(毕竟冗余网络压了很多可能精度都不掉),作者又提出了另一种结合了以上两种方法的度量指标: 
其中 为模型复杂度。
为模型复杂度。
压缩方法
- Uniform
每层拥有一样的压缩率,最naive的方法。
- ENC-Map
每层拥有相用的度量值 ,可以自行选择使用哪种度量方法。在这个限制条件下,每一层的与模型复杂度
,可以自行选择使用哪种度量方法。在这个限制条件下,每一层的与模型复杂度 的关系是单调的,因此只要我们给定模型复杂度
的关系是单调的,因此只要我们给定模型复杂度 就能推理得到整个网络的秩的config:
就能推理得到整个网络的秩的config: ,这是一种基于
,这是一种基于 映射的决策方法,文中称为ENC-Map。
映射的决策方法,文中称为ENC-Map。
- ENC-Model、ENC-Inf
在给定复杂度 与阈值
与阈值 下,通过
下,通过 映射计算
映射计算 ,此时我们为每一层的秩
,此时我们为每一层的秩 都限定了范围,接下来就可以在这个区间内用栅格法搜索出合适的
都限定了范围,接下来就可以在这个区间内用栅格法搜索出合适的 。由于该搜索过程的复杂度为
。由于该搜索过程的复杂度为 ,作者采用了分治法。
,作者采用了分治法。
ENC-Model与ENC-Inf的区别是,ENC-Model直接搜出 最高的模型,而ENC-Inf搜出
最高的模型,而ENC-Inf搜出 最高的N个模型后,把这N个模型在验证集上都跑一遍取表现最好的那一个。
最高的N个模型后,把这N个模型在验证集上都跑一遍取表现最好的那一个。
压缩算法的伪代码:

实验结果
SVD的粒度为层,只有网络的第一层粒度:VGG16为层,其它为按通道做SVD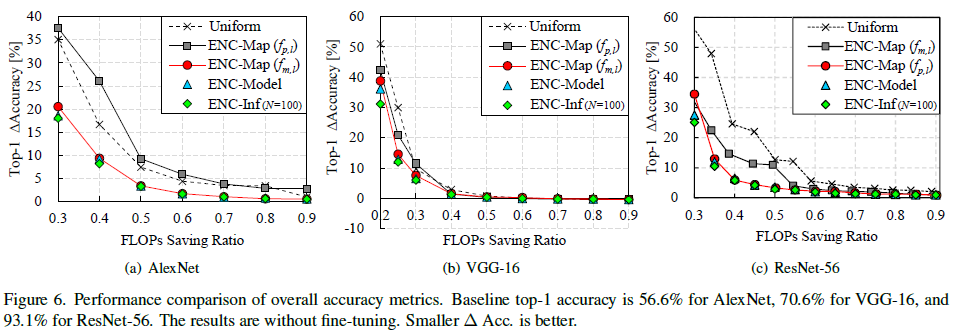
下表中FT代表是否进行Finetune重训练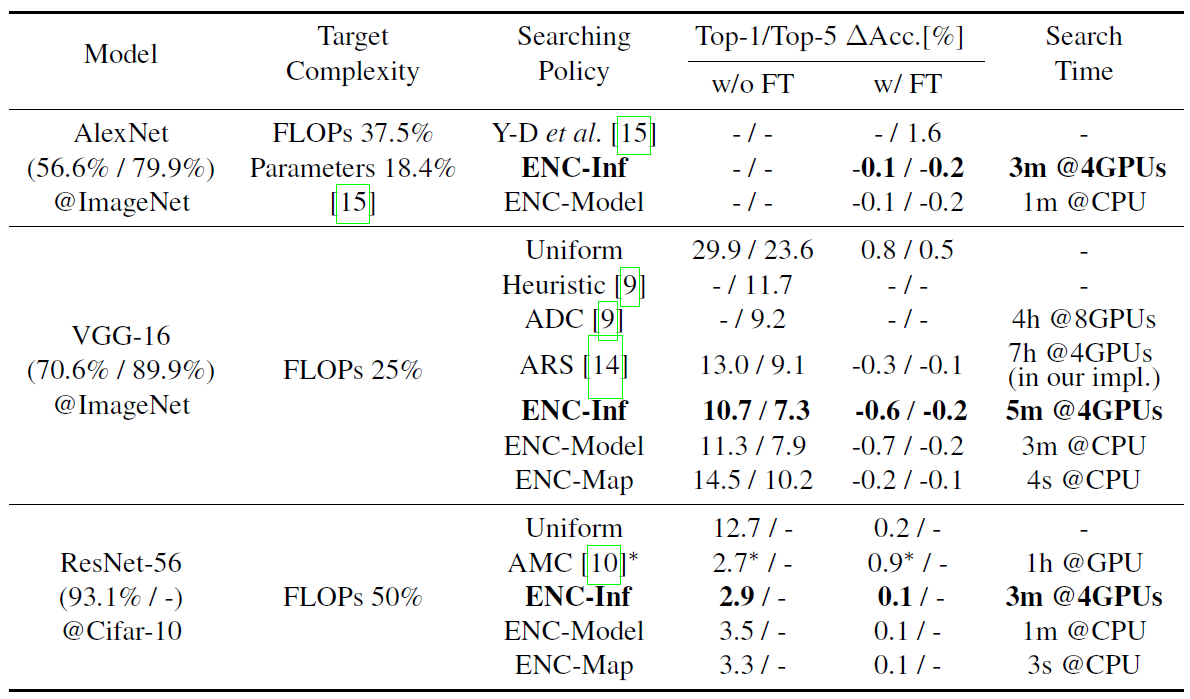
QuantNoise
论文:https://arxiv.org/pdf/2004.07320.pdf
论文的核心思想,每次量化的时候保留一部分不进行量化,随机抽取一部分数据量化,保证所有数据都有机会通过全精度通道获取梯度而不需要经过STE。
QAT:
noise = Quantizate(v) - vv = v + noise.detach()
QuantNoise:
rate = 0.5 # QuantNoise应用的概率,当rate=1.0时即为QATnoise = Quantizate(v) - vmask = (torch.rand_like(v) <= rate).float()v = v + noise.detach() * mask
Product Quantization
这里的Product指的是“笛卡尔积”。Product Quantization(以下简称PQ)是由Vector Quantization(以下简称VQ)进化而来的。
VQ的做法是,比如我有10000个128维的向量,对它们做K-means聚类后,每个向量可以直接用index表示。PQ在VQ的基础上做了一次分治,譬如将每个128维的向量拆成8个16维向量,此时每个向量可用8个16维的子向量表示。对每组16维的子向量做K-means聚类后,我们得到8个码表,每个向量可以用8个index表示。
到了CNN里,譬如我有一个输入输出通道都为64的3x3卷积,64x64x3x3,我们对每个3x3的向量进行256-cluster的K-means聚类,存储空间就只需要6464字节用于存储每个3x3向量的index,以及25633sizeof(dtype)字节用于存储码表。如果后续需要进行熵编码,还需要记录每个index的向量数。
需要注意的是,PQ只能起到压缩模型大小的作用,不能进行任何加速。
↑↑↑所以其实我还是不太明白VQ和PQ有啥区别
实验结果
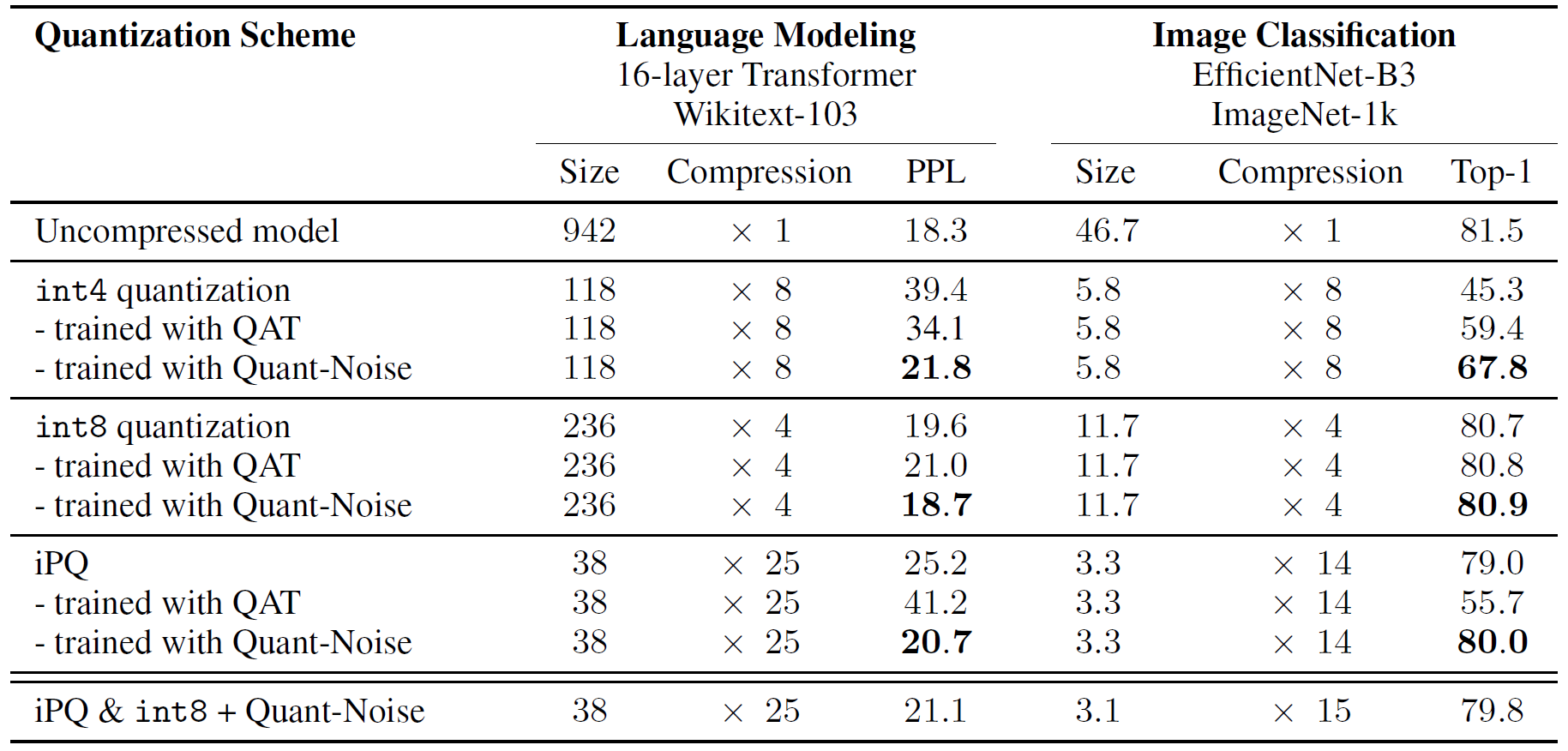
不过郑老师说做出来没效果,论文里QAT用的是指数平滑平均,QuantNoise用的是直方图法。
Stochastic Depth
论文:https://arxiv.org/pdf/1603.09382.pdf
这篇论文其实就是我曾经突发奇想过的ResNet Block Dropout。作者提出这么做可以缩短训练过程的数据流长度,使得梯度能够更通畅地传递,同时加速训练。
训练过程中,mask的粒度论文中是用的是一个batch一个mask。对于一个batch共用一个mask还是每个sample独享自己的mask做了实验发现差不多,说不清。
Survival Rate
作者说浅层扔的概率小深层扔的概率大效果更好,即每一层的survival rate符合: 。这和我SkipNet做出来的实验挺矛盾的,SkipNet的HRL丢的最多的就是stage1的Block。
。这和我SkipNet做出来的实验挺矛盾的,SkipNet的HRL丢的最多的就是stage1的Block。
作者展示了不同survival rate下,每层drop rate相同的uniform方式和浅层扔的概率小深层扔的概率大的linear方式效果的差别:(这里的speedup指训练过程加速比不太有用可以忽略)
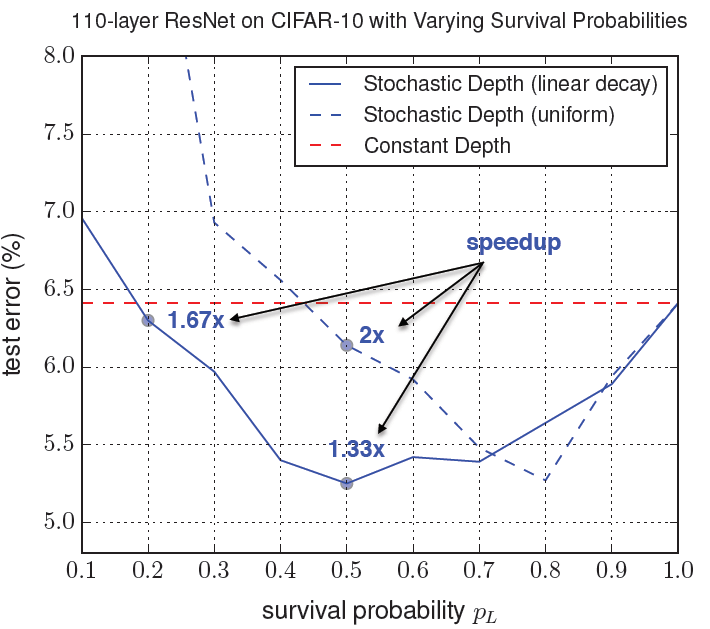
接下来这点很重要!!!
由于在训练阶段我们只开启了一部分Block,但在推理阶段开启了所有Block,而我们训练得到的权重是适配于drop rate控制下的统计信息的,因此在推理时我们需要将每层的残差都乘上这一层的survival rate: 。
。
即:

CLIP
视频:https://www.bilibili.com/video/BV1SL4y1s7LQ/?spm_id_from=333.788
论文:http://proceedings.mlr.press/v139/radford21a/radford21a.pdf
这篇论文感觉是人工智障到通用人工智能路程中里程碑式的一个工作= =笔记暂时搁置,简单介绍一下CLIP的使用方法。(训练别想了,要卡的,592张V100训了18天)
安装
github:https://github.com/openai/CLIP
git config --global url."https://".insteadOf git:// # 这个好像是git被墙的缘故pip install ftfy regex tqdmpip install git+https://github.com/openai/CLIP.git
使用
clip总共包含了[‘RN50’, ‘RN101’, ‘RN50x4’, ‘RN50x16’, ‘RN50x64’, ‘ViT-B/32’, ‘ViT-B/16’, ‘ViT-L/14’]。(这些指的都是image encoder,text encoder为一个)
clip.load的时候会自动下载模型。
另外CLIP的github中还有zero-shot推理、linear-projection finetune的示例。
import torchimport clipfrom PIL import Imagedevice = "cuda" if torch.cuda.is_available() else "cpu"model, preprocess = clip.load("ViT-B/32", device=device)image = preprocess(Image.open("1.jpg")).unsqueeze(0).to(device)sentences = ["A teacher is discussing academic issues with his student","Two people are quarrelling","A student is educating his teacher","Middle school students are walking on their way home from school","Two people are playing games","Two people are in love"]text = clip.tokenize(sentences).to(device)with torch.no_grad():image_features = model.encode_image(image)text_features = model.encode_text(text)logits_per_image, logits_per_text = model(image, text)probs = logits_per_image.softmax(dim=-1).cpu().numpy()print("Label probs:")for i in range(len(sentences)):print(sentences[i], ": ", probs[0, i])

若有收获,就点个赞吧
0 人点赞
