原始目标检测——滑动窗口检测器
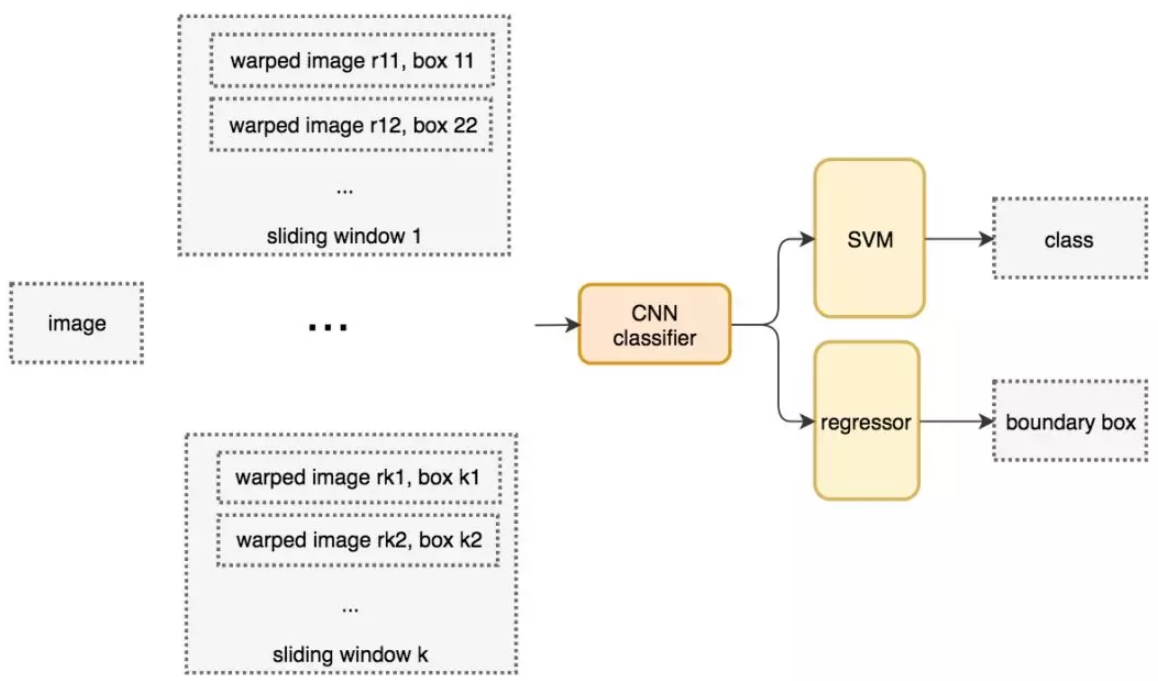
自从 AlexNet 获得 ILSVRC 2012 挑战赛冠军后,用 CNN 进行分类成为主流。一种用于目标检测的暴力方法是从左到右、从上到下滑动窗口,利用分类识别目标。为了在不同观察距离处检测不同的目标类型,我们使用不同大小和宽高比的窗口。

我们根据滑动窗口从图像中剪切图像块。由于很多分类器只取固定大小的图像,因此这些图像块是经过变形转换的。但是,这不影响分类准确率,因为分类器可以处理变形后的图像。

传统的目标检测方法采用暴力枚举候选框,并对每个候选框进行特征提取以实现目标检测。一副图像经暴力枚举候选框生成的候选框数量可达数十万个,因此原始目标检测方法计算量巨大,不具有可行性。
选择性搜索(Selective-Search)
https://blog.csdn.net/charwing/article/details/27180421
(论文)http://www.huppelen.nl/publications/selectiveSearchDraft.pdf
我们不使用暴力方法,而是用候选区域方法创建目标检测的感兴趣区域(ROI)。
选择性搜索综合了暴力搜索和分割的方法,意在找出可能的目标位置来进行物体的识别。与传统的单一策略相比,选择性搜索提供了多种策略,并且与蛮力搜索相比,大幅度降低搜索空间,让我们可以用到更好的识别算法。相比暴力搜索枚举出数十万个边界框,SS方法可以将候选框数量降到2000左右。
SS中用到的分割方法
传统图像分割被应用于Selective-Search的一开始用于生成初始区域R。
https://blog.csdn.net/surgewong/article/details/39008861
(论文)https://link.springer.com/article/10.1023/B:VISI.0000022288.19776.77
分割算法将整幅图像看作一副无向连同图,初始状态下每个像素点为图的一个节点,采用4邻接、8邻接等准则构造无向图的边,初始边的权值即这条边所连接的两个像素点的像素值之差。
算法流程:
0. 对于图G的所有边,按照权值进行排序(升序)
1. S[0]是一个原始分割,相当于每个顶点当做是一个分割区域
2. q = 1,2,…,m 重复3的操作(m为边的条数,也就是每次处理一条边)
3. 根据上次S[q-1]的构建。选择一条边oq,如果vi和vj在分割的互不相交的区域中,比较这条边的权值 与这两个分割区域之间的最小分割内部差MInt,如果oq < MInt,那么合并这两个区域,其他区域不 变;如果否,什么都不做。
4. 最后得到的就是所求的分割S = S[m]
R-CNN
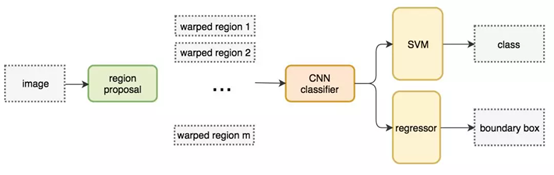
候选区域ROI
首先通过候选区域方法(ROI)创建目标检测的感兴趣区域。参考上文中的SS方法。
边界框回归器
候选区域方法有非常高的计算复杂度。为了加速这个过程,我们通常会使用计算量较少的候选区域选择方法构建 ROI,并在后面使用线性回归器(全连接层)进一步提炼边界框。我也不知道为什么CNN出来的特征向量直接拉全连接就能学出边界框的偏置!
训练过程
相较Fast R-CNN和Faster R-CNN,R-CNN是一阶段训练的。训练过程中CNN根据SVM和regressor反传的loss加起来,进行梯度下降训练。这时候CNN不再采用交叉熵等loss训练,CNN只是作为一个组件服务于整个模型。
Fast R-CNN
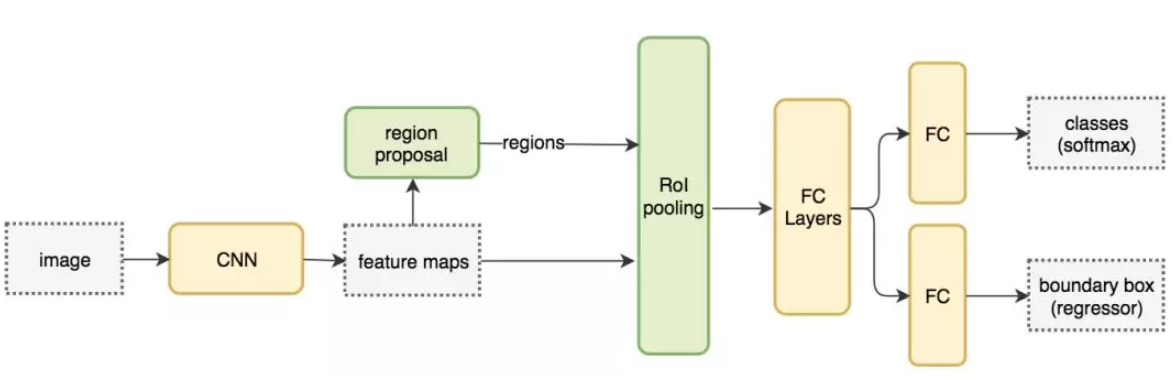
R-CNN 需要非常多的候选区域以提升准确度,但其实有很多区域是彼此重叠的,因此 R-CNN 的训练和推断速度非常慢。如果我们有 2000 个候选区域,且每一个都需要独立地馈送到 CNN 中,那么对于不同的 ROI,我们需要重复提取 2000 次特征。
Fast R-CNN使用CNN先提取整幅图像的特征,然后将ROI方法应用于深层的FeatureMap上。例如,标准的Fast R-CNN通过VGG16中的conv5层输出来生成ROI,这些关注区域随后会结合对应的特征图以裁剪为特征图块,并用于目标检测任务中。我们使用 ROI 池化将特征图块转换为固定的大小,并馈送到全连接层进行分类和定位。因为 Fast-RCNN 不会重复提取特征,因此它能显著地减少处理时间。
相比R-CNN,Fast R-CNN的训练速度提升了10倍,推理速度提升了150倍。
ROI池化
因为 Fast R-CNN 使用全连接层,所以我们应用 ROI 池化将不同大小的 ROI 转换为固定大小。
以下举例将 8×8 特征图转换为预定义的 2×2 大小: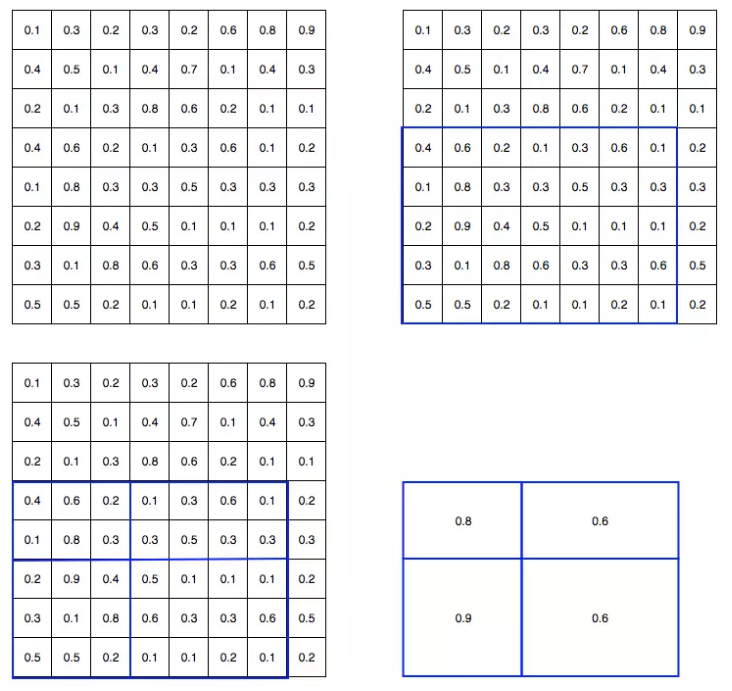
图(1)为FeatureMap;
图(2)中的蓝框为ROI区域;
图(3)将ROI区域拆分为目标维度(大小相似或相等的部分)
图(4)通过ROI max-pooling,得到变换后的特征图送入全连接层
遗留问题
在7*7的FeatureMap上框精确度低,完全靠边界框回归来弥补么?
应该是的
特征提取网络怎么训?
我咋知道
↑↑↑↑↑猴哥说没人会问Fast R-CNN的,不用管
Faster R-CNN
论文:https://arxiv.org/pdf/1506.01497.pdf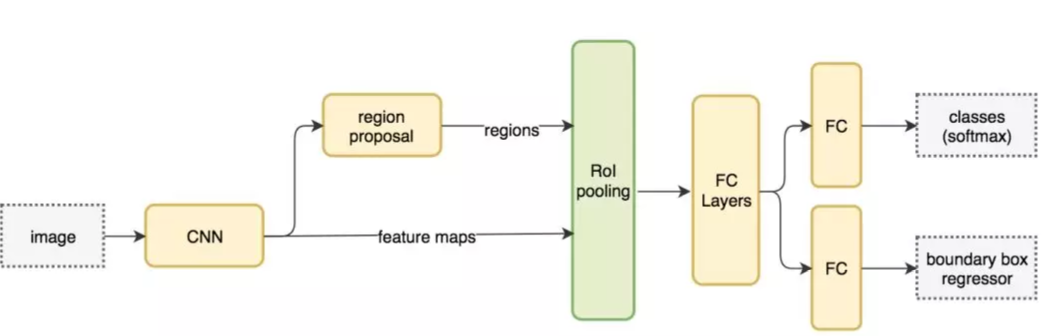
Fast R-CNN 依赖于外部候选区域方法,如选择性搜索。但这些算法在 CPU 上运行且速度很慢。在测试中,Fast R-CNN 需要 2.3 秒来进行预测,其中 2 秒用于生成 2000 个 ROI。
Faster R-CNN 采用与 Fast R-CNN 相同的设计,只是它用候选区域网络代替了候选区域方法。新的候选区域网络(RPN)在生成 ROI 时效率更高,并且以每幅图像 10 毫秒的速度运行。
候选区域网络RPN
候选区域网络(RPN)将第一个卷积网络的输出特征图作为输入。它在特征图上滑动一个 3×3 的卷积核,以使用卷积网络(如下所示的 ZF 网络)构建与类别无关的候选区域。其他深度网络(如 VGG 或 ResNet)可用于更全面的特征提取,但这需要以速度为代价。ZF网络最后输出 一个256维的向量,并馈送到两个独立的全连接层,以预测边界框和两个objectness 分数,表示度量边界框包含目标/不包含目标的概率(用一个也完全可以)。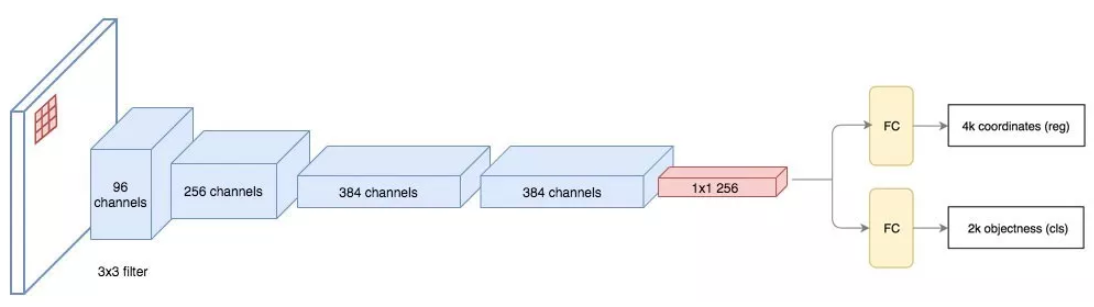
锚框anchor
对于特征图中的每一个位置,RPN 会做 k 次预测(用k个框去框)。因此,RPN 将输出 4×k 个坐标和每个位置上 2×k 个得分。Faster R-CNN原文部署了9个锚点框(即k=9):3个不同的宽高比(1:2,1:1,2:1)、3个不同大小(x1,x2,x4)。
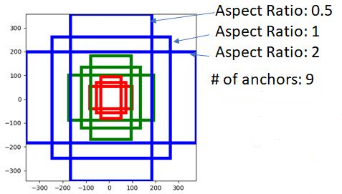
假设特征提取网络的输入为800600(论文里说的,目标检测任务的输入都比较大)对于5125038的特征图,每个位置输出36个坐标、18个回归分数(9个也行),整张图共生成503836个坐标、503818个回归分数。
需要注意的是,这里所谓的*“框”都是虚拟的,不需要裁出来,RPN网络始终是在对整张FeatureMap进行分析,只不过输出结果的时候输出了每一个虚拟框处的分数。
预测框修正
由于锚框的尺寸和位置是固定的,我们需要根据输入来给锚框预测一个修正值从而得到真正的预测框。
考虑到我们通常用左上坐标 与右下坐标
与右下坐标 来标定一个矩形框,最直接的预测框修正方法就是生成坐标偏移量
来标定一个矩形框,最直接的预测框修正方法就是生成坐标偏移量 。但是这么做,对同一偏移量
。但是这么做,对同一偏移量 ,对小矩形来说可能是一次巨变,但对大矩形来说可能不痛不痒,并不合理。
,对小矩形来说可能是一次巨变,但对大矩形来说可能不痛不痒,并不合理。
这里采用了一种新方法用于表示预测框修正:记预测框中心坐标为 ,锚框中心坐标为
,锚框中心坐标为 ;预测框宽高为
;预测框宽高为 ,锚框宽高为
,锚框宽高为 。对如下所示
。对如下所示 进行回归以替代:
进行回归以替代:

* 碎碎念**:可能因为算loss的时候是根据交并比算的,因此在生成偏移量的时候需要考虑一致性。使用偏移 量的话对小矩形loss影响很大而对大矩形影响小;使用这种新方法时,偏移指标改变一定的值时对大 小矩形loss的影响程度相同。
预测框筛选
交并比IoU
交并比(Intersection over Union)也称jaccard重叠率,通过计算两个集合的交集和并集的比值,用来指示两个集合的重合程度。
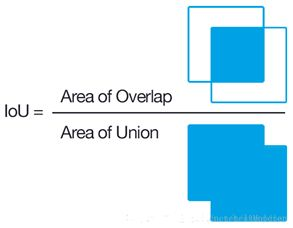
对于矩形框目标检测任务,计算IoU有些小技巧。
非极大值抑制NMS
网络生成的预测框有约20000个,NMS的目的在于筛选去除重叠率较高的预测框,并提高候选框的质量。
首先根据边界框的置信度对边界框进行排序,接着选取前景概率最高的框,并去除所有与当前框交并比大于阈值(譬如0.7)的边界框。重复以上操作直到遍历所有边界框。
一般会在NMS结果中选取前景概率最高的1000个框送入FC。
vector<BBox> NMS(vector<BBox> bbox){sort(bbox.begin(), bbox.end());for(cur = bbox.begin(); cur != bbox.end(); ++cur){for(it = cur; it < bbox.end(); ++it){float IoU = calcIoU(cur, it);if (IoU > 0.7)bbox.erase(it);}}if (bbox.size() < 1000)return bbox;elsereturn vector<BBox>(bbox.begin(), bbox.begin()+1000);}
在训练阶段NMS只在RPN结束后使用,预测阶段需要同时在RPN与FC后使用(FC的预测框回归会影响预测框间的交并比)。FC后的预测框是带类别属性的,因此FC后的NMS与RPN中的NMS稍有不同,需要逐类进行。
#define TypeCount 21vector<vector<BBox>> NMS(vector<vector<BBox>> bbox){for(tp = 0; tp < TypeCount; ++tp){sort(bbox[tp].begin(), bbox[tp].end());for(cur = bbox[tp].begin(); cur != bbox[tp].end(); ++cur){for(it = cur; it < bbox[tp].end(); ++it){float IoU = calcIoU(cur, it);if (IoU > 0.5)bbox[tp].erase(it);}}}return bbox;}
样本匹配
以下笔记根据mmdetection样本匹配部分的源代码进行记录与说明。mmdetection源码
源码中index=-1代表丢弃的框,index=0为负样本,其余为正样本。
需要注意的是,RPN和FC是单独训练的,而样本匹配只需要在train中进行。因此在某一训练阶段中,RPN和FC中一定只有一个部分需要做样本匹配。RPN训练时,FC直接被挂起;FC训练时,RPN直接根据NMS结果,筛选后将候选框送入FC进行样本匹配。因此以下只是介绍了训练RPN时与训练FC时样本匹配机制的差异。
RPN中的样本匹配
- 对于与所有GTBox的IoU都小于0.3的bbox,直接标记为负样本
- 记录每个bbox和所有GTBox的IoU中的最大值与最大值对应的GTBox,若该最大IoU大于0.7,则直接将bbox与该最大IoU对应的GTBox进行匹配
- 低质量匹配:记录每个GTBox和所有bbox的IoU中的最大值和最大值对应的bbox,若该最大IoU大于0.3,则直接将该最大IoU对应的bbox与当前GTBox匹配(可覆盖第2步的结果)
* 对于与GTBox最大IoU在0.3~0.7间的bbox,除非在低质量匹配中被选中,否则会别直接丢弃(反正框多,这 么做可以保留置信度高的框进行RPN的训练,而不是那些既像前景又像背景的框)。
FC中的样本匹配
- 对于与所有GTBox的IoU都小于0.5的bbox,直接标记为负样本
- 记录每个bbox和所有GTBox的IoU中的最大值与最大值对应的GTBox,若该最大IoU大于0.5,则直接将bbox与该最大IoU对应的GTBox进行匹配
* FC中正样本参与SmoothL1 loss的计算,并根据匹配的GTBox确定前景类lable;负样本不参与SmoothL1 loss 的计算,分类任务的lable为背景类。
低质量匹配
低质量匹配的目的是提高目标检测的召回率,使得在RPN阶段每个GTBox对应的目标尽可能都被匹配到,避免漏检。但是低质量匹配也有缺点,第2步中我们为每个bbox选择了最佳的匹配对象,而第3步中低质量匹配可能会覆盖第2步的结果。
例如,bbox A与GTBox1、GTBox2的IoU分别为0.9、0.8,按第2步中最佳匹配的结果,bbox A本应和GTBox1匹配,但可能由于与GTBox2的IoU最大的bbox为bbox A,bbox A的匹配对象被覆写为了GTBox2。
正是由于这种原因,低质量匹配在FC中没有被使用。RPN是用于生成候选框的一个流程,因此我们需要尽可能保证每个GTBox都能被匹配到,而FC的候选框来自于RPN,没必要为了召回率而拉低匹配准确度。
正负样本抽样
由于负样本数将远大于正样本数,为了防止训练数据不平衡,通常只选取一定比例的负样本进行训练,譬如正负样本取1:3的比例进行采样。(论文中128正样本、384负样本)
- 随机抽样
- 难例挖掘 (HEM):boostrap自举法,在训练过程中逐步扩充错题集 没仔细看
参考:https://www.zhihu.com/question/46292829
- 随机抽样进行初步训练
- 用训练后的网络进行预测,把其中的FP样本(误把负样本预测为正样本)纳入训练的负样本集
- 用新的样本集进行训练,重复这个过程
- 在线难例挖掘(OHEM)没仔细看
论文:https://arxiv.org/pdf/1604.03540.pdf
参考:https://zhuanlan.zhihu.com/p/58162337
每次迭代时,先把所有ROI输入RPN预测,并计算每个ROI的loss,挑选loss最高的一部分hard ROI并将其
它ROI的loss置零进行反传。
以上方案由于大多数ROI的loss被置零却依然需要反传,训练效率低。因此可以在前传后记录挑选出的
ROI,并将它们单独再做一次前传并反传。虽然多做了一次前传却减少了大量不必要的反传。
训练过程
四阶段训练
A代表特征提取CNN网络,B代表候选区域网络RPN,C代表全连接分类器/回归器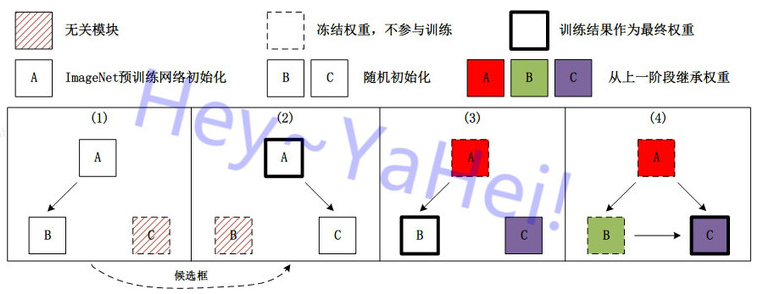
(盗郑老师的图)
| A(CNN) | B(RPN) | C(FC) | |
|---|---|---|---|
| 阶段1 | 预训练初始化 | 随机初始化 | 不管 |
| 训练 | 训练 | 无关 | |
| 阶段2 | 预训练初始化 | 保留上一阶段结果 | 随机初始化 |
| 训练 | 无关 | 训练 | |
| 阶段3a | 保留上一阶段结果 | 保留上一阶段结果 | 保留上一阶段结果 |
| 冻结 | 训练 | 冻结 | |
| 阶段3b | 保留上一阶段结果 | 保留上一阶段结果 | 保留上一阶段结果 |
| 冻结 | 冻结 | 训练 |
用预训练分类网络初始化CNN,随机初始化RPN。根据RPN输出的候选框与label框的交并比(IoU)构建loss,同时训练CNN与RPN直到收敛。
*训练结束后运行一次test,保存数据集中所有样本对应的候选框(在有数据增广时,可以存储所有增广的 图片与候选框,或者存储当前的CNN与RPN权重。前者消耗硬盘空间,后者消耗第二阶段显存与CPU)**
丢弃阶段1中CNN的训练结果,重新用预训练分类网络初始化CNN,随机初始化FC。此阶段的训练与RPN无关,直接将第一阶段结束后test生成的候选框(或第一阶段的CNN、RPN训练结果实时生成)输入FC进行训练。根据FC回归结果的分类交叉熵+边界框SmoothL1构建loss,同时训练CNN和FC直到收敛。
- 保留此前的训练结果,冻结CNN,轮流训练RPN和FC,这一步起到微调网络的作用。我们可以将RPN和FC视为两个独立的模块,RPN可以直接用于目标检测,而FC用于精细化检测结果。
损失函数
RPN与FC的训练都使用以下损失函数:

其中 为分类的交叉熵(对RPN而言是前景背景的0-1二分类,对FC而言是前景多分类+背景分类)
为分类的交叉熵(对RPN而言是前景背景的0-1二分类,对FC而言是前景多分类+背景分类)
其中 为预测框空间位置的SmoothL1(回归参数参见链接)
为预测框空间位置的SmoothL1(回归参数参见链接)
- RPN训练过程中的loss计算:
在计算loss时,首先根据GTBox区分正负样例进行0-1二分类的标注。基于所有样本计算0-1二分类的softmax交叉熵,只基于正样本计算预测框空间位置回归的SmoothL1。
- FC训练过程中的loss计算:
不同于RPN,FC在开始训练前就已经完成正负样本的标注了(参见下一章)。基于所有样本计算前景多分类与背景分类(比如前景20类,加上背景类就是21分类)的softmax交叉熵,只基于正样本计算预测框空间位置回归的SmoothL1。
FC训练时候选框的一生
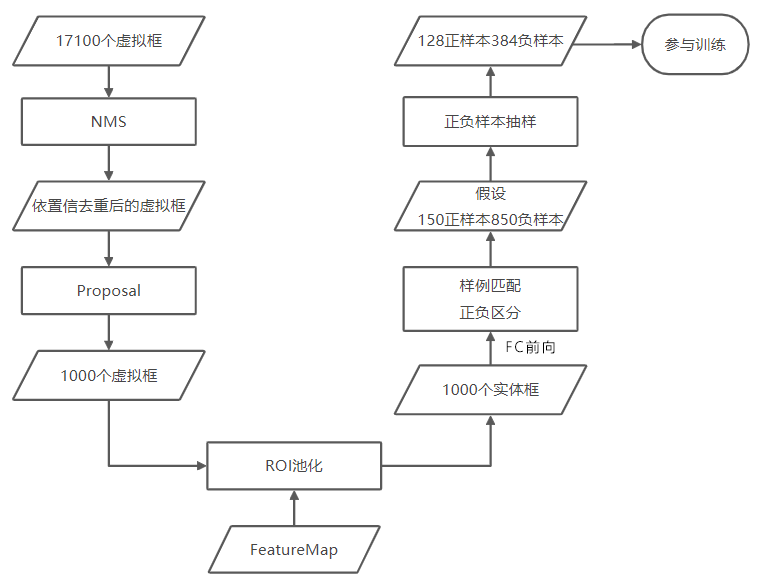
预测过程
需要注意的是,预测过程相比训练过程多了一步按类别NMS,但RPN阶段nms_thr=0.7而FC中nms_thr=0.5。过了NMS会有一个缺点:两个重合度很高的人可能会被识别成一个人,因为NMS不知道这是两个目标而误认为是一个目标的冗余预测框。
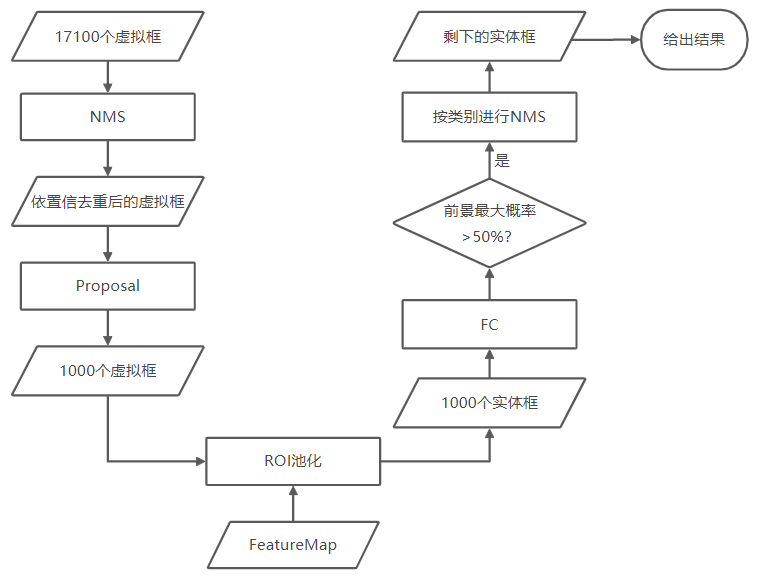
mmdetection config
参考:https://blog.csdn.net/hajlyx/article/details/85991400
NMS是用CUDA写的,github上看不到python源代码。
NMS中的nms_thr指的是去除与当前候选框IoU在多少以上的其它候选框。
遗留问题
config中的nms_pre、nms_post、max_num都是啥?score_thr是啥?

若有收获,就点个赞吧
0 人点赞
