2020.01
刚刚看完ResNet v1的论文,一来是想试一下ResNet这个网络,二来是对ResNet的结构部分存有一部分疑问和想法,然后想着找个标准数据集做吧,毕竟上次做人脸用的那个数据集基本是自娱自乐。CIFAR感觉实在是太小了,3232的input自己都分不出是啥,224224的标准数据集好像也只有ImageNet,这个又太大了根本跑不来,听郑老师说有个tiny-ImageNet,就下下来作为了这次的数据集。后来由于跑tiny-ImageNet的时候踩了个弱智坑,又用了CIFAR(毕竟用的人多有参考指标)。
tiny-ImageNet
数据集网站:http://tiny-imagenet.herokuapp.com/
tiny-ImageNet抽取了ImageNet里1000分类中的200个分类,每个分类包含500张64*64的图片。数据集中每分类有500张用于训练,另外50张用于测试,共11w张图片。
tiny-ImageNet训起来还是挺慢的,基本上用2080ti训一遍要大半天。后来换CIFAR以后就快多了,不大的网络一两个小时就能跑完。
数据集结构与Dataloader
这次用的数据集的标注方法很神奇,根目录下有200个文件夹,每个文件夹里有500张图,通过文件夹进行分类标注。

Python中 与
与 两个函数可用于处理路径寻找目录下的文件。
两个函数可用于处理路径寻找目录下的文件。 函数作为一个搜索树进行遍历,而
函数作为一个搜索树进行遍历,而 函数只列出当前目录下的文件。
函数只列出当前目录下的文件。
在我们的这个例子中,以下代码可用于完成图片读取与标注:
def create_index(): #创建了从文件夹乱七八糟的名字到顺序的索引img_list = []d = {}index = 0fp = open('./data/wnids.txt', 'r')for line in fp.readlines():img_list.append(line.split()[0])img_list.sort()for name in img_list:d[name] = indexindex = index + 1return dindex_dict = create_index()for folder_name in os.listdir(root_dir):index = index_dict[folder_name]cur_dir = os.path.join(root_dir, folder_name, 'images')for img in os.listdir(cur_dir):self.imgs.append(os.path.join(cur_dir, img))self.labels.append(index)
适配原始ResNet网络结构
原始的ResNet网络结构接收的是224224的输入,我们的输入只有6464,因此需要更改一下网络结构。当然不改也行,直接把64*64暴力resize(224)扔进去也不是不可以。但参考CIFAR数据集的话,大家往往都会更改网络结构,譬如把开头stride=2的7x7卷积改成stride=3的3x3卷积、去掉maxpool、去掉一个stage等等。
下图左边分支为直接resize(224)套用原始ResNet的方法,右边分支为更改网络结构的方法。

图小的时候不要随便resize和旋转
上一节展示了两种将ResNet适配tiny-ImageNet的方法,结果实验做出来直接resize的方法没问题,随手训一下没收敛就有60%的准确率了(下图棕线)。然而自己改的适配网络结果差到亲妈爆炸,Train loss可以训到0.2以下但Test loss一直在3以上下不来,训收敛的时候准确率也只有40%(训练参数:bs=256,Adam lr=0.0016)。
第一次自己改网络结构的我自信心受到了极大的打击,难道我的网络搭错了?咋回事啊?咋办啊?我是谁啊?我在哪啊?
后来又怀疑了会不会是学习率过大/过小,换用SGD又训了一遍,又把自定义网络中Conv1的33 stride1卷积换成了77 stride1,反正都没用,结果都一样。
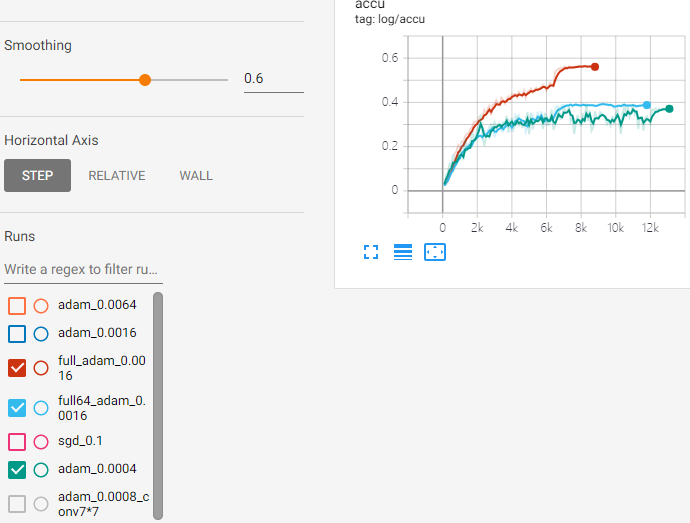
郑老师看了下我的数据预处理部分,是这个样子的(其实我只是手贱把知道的全扔进去用,一波操作猛如虎一看准确度0.5):
transform_train = transforms.Compose([transforms.Resize(72),transforms.RandomRotation(6),transforms.RandomCrop(64),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.15, contrast=0.15, saturation=0.15, hue=0),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ])
郑老师说小的输入(64*64这种)一般不太用Resize+RandomCrop(大的输入图一般才这么用),直接在RandomCrop的时候给图像补padding用的比较多。一开始我也没在意,后来试了这种预处理,也就是下面这样,立马就训的好了:(参见runs/adam0_0.0008)
transform_train = transforms.Compose([transforms.RandomCrop(64, padding=8),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.15, contrast=0.15, saturation=0.15, hue=0),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ])
我觉得奇怪啊,就在Jupytor里随便拉了张图出来,看看两种预处理有什么区别导致结果差这么多。结果一看吓一跳:左图是原来用的预处理(上面这个),右图是郑老师建议的(下面这个)。由于从6464 resize到7272插值导致了图像清晰度的巨大幅度下降!当然旋转也是插值插出来的,小图的时候都别用。


图小的时候不要随便resize和旋转!!!
图小的时候不要随便resize和旋转!!!
图小的时候不要随便resize和旋转!!!
CIFAR数据集
写这篇笔记的时候我当然已经知道tiny-ImageNet为啥亲妈爆炸了,但当时并不知道啊!由于tiny-ImageNet的实验、论文、网络这种真的很少,那也没办法了,郑老师建议我还是换成CIFAR跑跑看。CIFAR有CIFAR-10和CIFAR-100两个数据就,都是50000训练10000测试,每个类别包含的图片数量相同(因此不存在不平衡问题),图片尺寸为32323。
CIFAR在pytorch里用起来倒是特别方便,和MNIST一样已经集成了,调用的时候会自动给你下载。
对比暴力resize(224)和自改结构
由于这时候数据集分辨率变成了32*32,我们直接砍了ResNet的stage4整个大层。对于原始ResNet,resize成112输入,其余不变;对于自改ResNet,用stride=1的3x3卷积作为第一层,删除maxpool,其余不变。<br />结果在CIFAR-10上两者表现几乎相同,但在CIFAR-100上自改架构能到74.9%的准确率,而原始架构只有72.6%。代表对于小的输入,自己改结构相比于直接暴力resize(224)**拥有更高的性能和效率**。<br />之后的实验也都是基于的CIFAR进行的了。
学习率的研究
训练参数:bs=100,Wide ResNet17(width=64)
图太多了,可以去tensorboard里看。说结论的话,SGD(momentum=0.9)在0.2的学习率下都能训的不错,但是一直把学习率降到0.005也没怎么发现收敛变慢;Adam的话,0.002的学习率已经是极限了,再高就不太理想了,最低没往太小试,但合适的学习率确实是和SGD差两个数量级的样子。SGD_0.1训出来(75.24%)比Adam_0.0008略好(75.08%)但差不多。
然后,根据周期性学习率的论文,把学习率扫了一遍以后,可以上周期性学习率了(余弦学习率)。余弦学习率的细节参见余弦学习率。Pytorch自带的schedule不支持warm_up,所以我还是用了非常不优雅的adjust_lr然后每个step调用一次。总共异想天开的尝试了以下三种:
*由于bs=100,dataset=50000,一个epoch有500step
- SGD(momentum=0.9),0.003~0.2,Tmax=2000
- SGD(momentum=0.9),0.001~0.2,Tmax=2000。完整训练4轮共32个epoch后,每一轮的最大学习率都减半。因为感觉训到后期还用这么大的max_lr会把模型震出最优区间。

- SGD(momentum=0.9),0.004~0.2,Tmax=2000。对学习率的对数取周期而不是直接对学习率取周期。因为感觉传统方法基本上都会一直取决于max_lr。
反正结果就是我在瞎折腾:
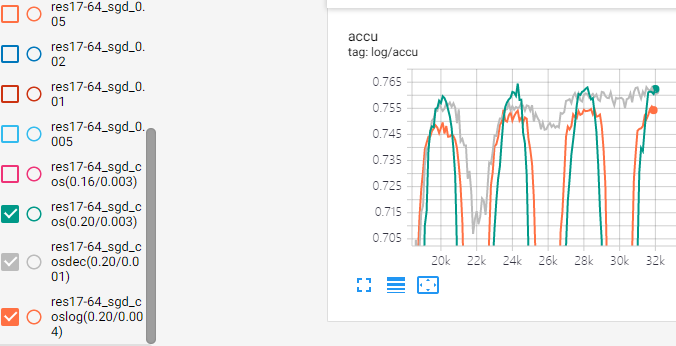
ResNet v2实验讨论
训练参数:bs=50,lr=cos(0.01,0.1,Tmax=6000),epoch=96+4
**
Zero_init_residual
《Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour》论文里提出了对ResNet v1的每个Block的最后一个BN层用0初始化 使得初始状态下残差单元也是identity mapping,pytorch也支持了这个优化项。
使得初始状态下残差单元也是identity mapping,pytorch也支持了这个优化项。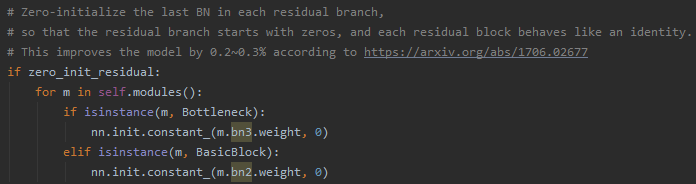
但是这是因为ResNet v1里每个Block的最后一层是BN,而ResNet v2改了结构将BN与ReLU前置,这时候给BN中的进行0初始化会导致卷积层得到的数据全为0, ,权重的梯度都全为0了,那当然啥都训不了了啊!
,权重的梯度都全为0了,那当然啥都训不了了啊!
然后我就白跑了两天然后训不出个毛线出来。


↑↑↑↑↑这个故事和《图小的时候不要随便resize和旋转》告诉我们,弄不清楚半吊子的时候不要瞎J2想骚操作优化。
但是看到这个让我突然想到一个神奇的模型压缩方法,通过对γ施加强L1正则化,达到直接裁掉整个残差单元的目的?
Bottleneck和BasicBlock
Bottleneck结构和BasicBlock结构的FLOPS差不多但前者深度更深,以ResNet34/50为例,前者3.6GFLOPS,后者3.8GFLOPS,但是Bottleneck比BasicBlock用GPU训练时慢好多,用CPU预测时差不多。郑老师说应该是因为GPU并行度太高,层变多了以后需要取数据什么什么的,而CPU并行度没那么高所有Bottleneck层多也不会太影响性能。
显存占用与cudnn
Pytorch默认开cudnn,会自动选择最快的卷积方式。因此我在进行实验的时候同一个模型同一份代码在不同硬件上可能占用显存大小、运行速度等有所不同。比如Bottleneck的48-48-48结构,宽度为32的Resnet,bs=50,在GTX1080上占用了7577MB显存,而在RTX2080ti上占用了8493MB显存。
cudnn会在前几个step的时候尝试不同的卷积组合方式,选择最优的那个。但是在2080ti上适用的方法在1080上就爆显存了,cudnn不会在尝试搜索爆显存的时候直接traceback而选择可以跑的下的那种卷积方法,即使它更慢。除非所有的卷积方法都爆显存才会报CUDA out of memory。
实验结果
因为太慢了所以实验只测了一次不太准,按理来说应该测个五次去最佳值记录,凑合着看趋势吧只能。可以发现一味地叠深度并不是最好的选择,性价比最高的几个超参数基本上是在每个Block里4~6个残差单元的样子。
《各个网络结构分析.xlsx》中分析了BasicBlock和Bottleneck两种单元,可以发现计算量的FLOPS和估计的内存占用都是差不多的。但是在实际实验中,Bottleneck相对于BasicBlock的显存占用与训练耗时基本都是翻倍的关系;测试阶段的耗时相差大约20%。这个可能涉及到底层实现了,因此也没有深究下去,只是记了个结果。
论文中的CIFAR实验细节
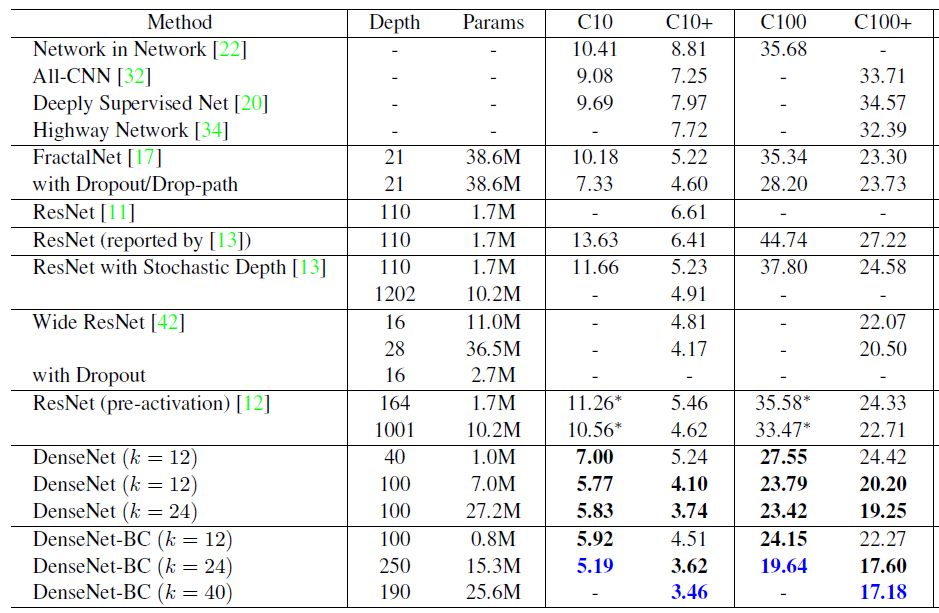
* pre-act-ResNet为ResNet v2,C10与C100为不经过预处理的实验
ResNet v1和ResNet v2中:
bs=128,SGD(momentum=0.9, weight_decay=0.0001)
lr=0.01 warm up 400step后回归lr=0.1(32k step与48k step砍10倍),训练64k step
Wide ResNet中:
全部使用BasicBlock结构
bs=128,SGD(momentum=0.9, nesterov=true, weight_decay=0.0005)
lr=0.1(60epc、120epc、160epc砍5倍),训练200epc
DenseNet中:
bs=64,SGD(momentum=0.9, nesterov=true, weight_decay=0.0001)
lr=0.1(150epc、225epc砍10倍),训练300epc
ResNeXt中:
bs=128,SGD(momentum=0.9, weight_decay=0.0005)
lr=0.1(150epc、225epc砍10倍),训练300epc

若有收获,就点个赞吧
0 人点赞
