Python基础
字符串
python的字符串可以用‘’或者“”括起来。
赋值符与浅拷贝
python中的赋值符只是指针赋值,而不是深拷贝。a=1, b=a, a=2, print(b)的结果是1。
除法
python中/除法的计算结果是浮点数,不论除数与被除数是什么类型。//除法为地板除,结果向下取整。
10/3=3.33333(float)
10//3=3(int)
10//3.0=3.0(float)
取整
a = numpy.array([…])
numpy.round(a) # 四舍五入
numpy.floor(a) # 向下取整
numpy.ceil(a) # 向上取整
循环
for v in (list/tuple)
for i in range(100) //for i = 0; i <100; ++i
while i <= 100
break与continue与C相同。
range函数
range(5) //0, 1, 2, 3, 4, 5
range(10, 15) //10, 11, 12, 13, 14
range(20, 10, -2) //20, 18, 16, 14, 12
类型检查
判断一个对象是否为特定类型:isinstance(object, type),返回布尔变量
isinstance(1, int) -> True
isinstance(2.34, list) -> False
main函数与全局变量
Python中写在if name == ‘main’里面的都是全局变量!
在自定义函数中使用全局变量需要用global声明!
Python中注释符号也需要缩进
Python基础IO
转义字符串
转义字符同C,可以用r’xxxxx’表示内部的字符串默认不转义

连续print多行内容
换行符\n的可读性差,可通过’’’xxx’’’表示多行内容

print的格式化输出
与C类似,包括%d、%f、%s、%x等(%05d、%-5d)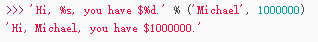
format()方法
用传入的参数依次替换字符串内的占位符{0}、{1}……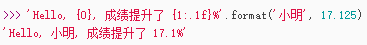
print的颜色
print("\033[1;30m 字体颜色:白色\033[0m")print("\033[1;31m 字体颜色:红色\033[0m")print("\033[1;32m 字体颜色:深黄色\033[0m")print("\033[1;33m 字体颜色:浅黄色\033[0m")print("\033[1;34m 字体颜色:蓝色\033[0m")print("\033[1;35m 字体颜色:淡紫色\033[0m")print("\033[1;36m 字体颜色:青色\033[0m")print("\033[1;37m 字体颜色:灰色\033[0m")print("\033[1;38m 字体颜色:浅灰色\033[0m")print("背景颜色:白色 \033[1;40m \033[0m")print("背景颜色:红色 \033[1;41m \033[0m")print("背景颜色:深黄色 \033[1;42m \033[0m")print("背景颜色:浅黄色 \033[1;43m \033[0m")print("背景颜色:蓝色 \033[1;44m \033[0m")print("背景颜色:淡紫色 \033[1;45m \033[0m")print("背景颜色:青色 \033[1;46m \033[0m")print("背景颜色:灰色 \033[1;47m \033[0m")

读取键盘输入
通过input()函数读取用户输入,但是默认读取字符串类型
Python基础数据结构
list
c = ['abc', 123, 4.567] #用方括号!可以放不同元素,是异质的len(c) #返回list中元素的个数c[-1] = 'jkl' #-1代表倒数第一个元素c.append('xyz') #在末尾添加元素c.insert(1, 'xyz') #在指定位置插入元素,其余元素后移c.pop() #删除末尾元素c.pop(1) #删除指定位置元素,其余元素前移
tuple
t = ('abc', 123, 4.567) #用圆括号!和list一样可以放不同元素,是异质的t1 = (1), t2 = (1,) #t1是整数,构造单元素的tuple t2时,增加逗号消除歧义t[1] = 0 错误!!! #tuple与list的不同在于tuple是const的,不可变
tuple中存复杂元素时,存储的是目标的指针,该指针不可变但可以通过该指针改变复杂元素

dict
python中的dict类似于C++中的map,但是是异质的。
d = { 'Ming': 95, 'Gang': 75, 'Hong': 85 } #用花括号d['Hua'] = 67 #增加元素或者更改元素d[1] = 'ABC' #可以使用各种类型作为key或者valueif 'Hahaha' in d: #检测元素是否在dict中v = d.get('Hahaha') #返回特定键的值,不存在时返回Nonev = d.pop('Gang') #删除某个key
set
python中的set类似于C++中的set,但是是异质的。
s = set([1, 2, 3, 4]) #可用list、tuple进行构造s.add(5),s.remove(1) #增添、删除元素s = s1 & s2 #取交集s = s1 | s2 #取并集
tuple(1,2,3)可作为dict与set的key,但tuple(1,[2,3])不可,因为存在可以改变的元素(即不可哈希项)
Python中的赋值
讨论如下代码块,在第二行中插入不同的赋值函数:
import copyold = [1, [1, 2, 3], 3](---assign function---)old[0] = 3old[1][0] = 3print(new)
非拷贝方法(直接赋值)
new = old
输出结果:[3, [3, 2, 3], 3]
浅拷贝方法
copy()函数
new = copy.copy(old)
列表生成式
new = [i for i in old]
for循环
new = []for i in range(len(old)):new.append(old[i])
切片
new = old[:]
输出结果:[1, [3, 2, 3], 3]
深拷贝方法
new = copy.deepcopy(old)
输出结果:[1, [1, 2, 3], 3]
Python的高级特性
切片
[begin=0 : end=len : stride=1] #======等同于C语言中的:for(int i=begin; i<len; i+=stride)L = [i for i in range(100)]L[:5] #0, 1, 2, 3, 4L[-3:] #97, 98, 99L[3:5] #3, 4L[:10:2] #0, 2, 4, 6, 8L[::20] #0, 20, 40, 60, 80
迭代
L = [1,2,3]for v in L:do somethingT = (1,2,3)for v in T:do somethingD = {'A':1, 'B':2, 'C':3}for key in d:do somethingfor val in d.values():do somethingfor k, v in d.items():do somethingfor i, val in enumerate(L): #使得循环过程中增加一个indexprint(i, val)>>>0 A>>>1 B>>>2 C#判断对象是否可迭代isinstance('abc', Iterable)>>>Trueisinstance([1,2,3], Iterable)>>>Trueisinstance(123, Iterable)>>>False
列表生成式
L = [x*x for x in range(10,20) if x%2 == 0] #100,144,256,324D = {'x':A, 'y':B, 'z':C}LL = [k + '=' + v for k,v in d.items()] #['x=A','y=B','z=C']
生成器
与列表生成式类似,但是会实时计算被访问的元素而不会事先完成所有计算,可用于节省内存和开销。生成器中的元素必须被顺序访问,不支持下标访问。
G = (x * x for x in range(10, 20) if x % 2 == 0) #使用小括号!print(G[2]) 错误!!! #Traceback!print(next(G)) #访问下一个G中的元素for v in G #通过迭代器遍历G
可以通过函数构造复杂的迭代器,在函数中使用关键词yield表示这不是一个普通函数而是一个用户构造迭代器的函数,函数执行到yield处进行一次元素返回。
以斐波那契数列迭代器为例:
def fib(max):n, a, b = 0, 0, 1while n < max:yield ba, b = b, a+bn = n+1return 'done'#fib(6)可用于构造一个包含6个元素的生成器
迭代器
生成器是迭代器,而list、dict等虽然是Iterable的,却不是Iterator。Iterator不支持下标访问,只可用for迭代访问或通过next()访问下一个元素直到没有数据时抛出StopIteration错误。迭代器对象表示的是一个数据流,不可调用len函数获取长度,Iterator是惰性的,只有需要返回下一个数据时才会计算。
可以用iter()函数将Iterable的对象转换Iterator。
高阶函数
map()
map用于完成映射,接受两个参数,分别为映射函数和数据序列, 将映射函数作用于数据序列中的每一个元素。map返回的是一个Iterator!
def f(x):return x*xr = map(f, [1,2,3,4,5]) #r = [1,4,9,16,25]rr = list(map(str, [1,2,3,4,5])) #rr = ['1','2','3','4','5']
reduce()
reduce用于将上一次的运算结果送入下一次迭代。reduce返回的是一个Iterator!
# reduce(f, [x1,x2,x3,x4])=========f(f(f(x1,x2),x3),x4)def fn(x,y):return x*10 + yres = reduce(fn, [1,3,5,7,9]) #res = 13579
filter()
filter用于从序列中过滤出符合条件的元素。filter返回的是一个Iterator!
def is_odd(n):return n % 2 == 1list(filter(is_odd), [1,2,3,4,5]) #[1,3,5]
装饰器
假设我们已经有一个函数 ,但是我们要增添
,但是我们要增添 的功能,又不想直接更改函数
的功能,又不想直接更改函数 ,譬如我们希望在每次卷积层前统计参数的分布等等。
,譬如我们希望在每次卷积层前统计参数的分布等等。
下面是廖雪峰教程中的例子,在一个打印时间的函数执行前print一行当前调用的函数。
def log(func):def wrapper(*args, **kw):print('call %s():' % func.__name__) # 先于now函数执行return func(*args, **kw) # now函数的执行return wrapper@logdef now():print('2015-3-25')now() # 等效于now = log(now)>>> call now():>>> 2015-3-25
如果装饰器本身也有参数,则需要多一层嵌套装饰器:
def log(text):def decorator(func):def wrapper(*args, **kw):print('%s %s():' % (text, func.__name__))return func(*args, **kw)return wrapperreturn decorator@log('execute')def now():print('2015-3-25')now() # 等效于now = log('execute')(now)>>> execute now():>>> 2015-3-25
面向对象编程
定义一个自定义类:
class Student(object)
括号中为继承的父类,若没有则使用object类
当没有构造函数__init__时,可以使用默认构造函数,通过Student()创建一个对象,否则必须根据构造函数要求的参数进行构造。构造函数不能重载只能有一个!<br /> 类的成员函数的第一个参数一定是self代表自己。
Python允许对实例动态绑定,同一个类的两个实例可能拥有完全不同的变量名:
bart = Student('Bart Simpson', 59)lisa = Student('Lisa Simpson', 87)bart.age = 8print(bart.age)>>>8print(lisa.age)>>>Traceback (most recent call last):
类中的私有成员以__开头,外部无法访问
def __init__(self, name, score):self.__name = nameself.__score = scorebart = Student('Bart Simpson', 59)print(bart.__name)>>>Traceback (most recent call last):bart.__name = 'New Name'print(bart.__name)>>>'New Name'#此时类内属性__name依然为'Bart Simpson'#实际上类内属性__name的真实名称为_Student__name#我们在外部相当于对bart这个实例动态绑定了一个新的变量__name
class Student(object):name = 'Student'score = 0Student a, ba.age = 8#hasattr函数返回布尔类型,检测一个对象是否拥有特定属性hasattr(a, 'age')>>>Truehasattr(b, 'age')>>>False#setattr函数能为对象添加一个特定属性并赋值,若对象已存在该属性则直接赋值setattr(b, 'age', 12)#getattr函数用于返回对象中特定属性的值,可以指定属性不存在时的默认返回参数getattr(a, 'salery')>>>Traceback (most recent call last):setattr(a, 'salery', 5000)getattr(a, 'salery')>>>>5000getattr(b, 'salery', 404)>>>404#以上的属性不局限于成员变量,同样可以是成员函数

从上面的例子可以看出,在编写程序的时候,千万不要对实例属性和类属性使用相同的名字,因为相同名称的实例属性将屏蔽掉类属性,但是当你删除实例属性后,再使用相同的名称,访问到的将是类属性。
面向对象高级编程
动态绑定添加方法
from types import MethodTypeclass Student():def __init__(self, name):self.name = namedef set_age(self, age)self.age = ages = Student('Asuka')s.set_age = MethodType(set_age) # 为s这个实例添加set_age方法Student.set_age = set_age # 为Student类添加set_age方法,所有实例都可使用
slots
slots用于限制实例可在外部添加的属性:
class Student():__slots__ = ('age', 'sex') # 作为一个tuple,限制在外部只能添加'age'和'sex'属性s = Student()s.age = 18 # is OKs.sex = 'Female' # is OKs.score = 98 # traceback, 'Student' object has no attribute 'score'
@property
@property可以将类的一个方法转化为属性进行访问。
廖雪峰教程中举得例子是,Student的score属性必须限定在0~100分中,如果直接将score属性暴露给外部则可能无法满足约束条件,除非增加get_score和set_score两个方法:
class Student(object):def get_score(self):return self._scoredef set_score(self, value):if not isinstance(value, int):raise ValueError('score must be an integer!')if value < 0 or value > 100:raise ValueError('score must between 0 ~ 100!')self._score = value
这样显得非常麻烦,利用@property:
class Student(object):@propertydef score(self):return self._score@score.setterdef score(self, value):if not isinstance(value, int):raise ValueError('score must be an integer!')if value < 0 or value > 100:raise ValueError('score must between 0 ~ 100!')self._score = value
为类添加只读属性:
class Screen(object):def __init__(self):self.width = 0self.height = 0@propertydef resolution(self):return self.width * self.height
定制类
class Fibnacci(object):def __init__(self, count=10):self.a = 0self.b = 1self.count = 10self.cur = 0def __len__(self):return self.countdef __str__(self):return 'Fibnacci object, {}/{} visited'.format(self.cur, self.count)__repr__ = __str__def __iter__(self): # 用于for ... in Fibnacci的迭代return selfdef __next__(self):if self.cur >= self.count:raise StopIteration()self.a, self.b = self.b, self.a + self.bself.cur += 1return self.a # 返回下一个值def __getitem__(self, n): # 用于构建list,下标索引a, b = 1, 1for x in range(n):a, b = b, a+breturn adef __getattr__(self, attr): # 当实例中找不到外部访问的属性时,python会试图调用getattr获取if attr=='father': # 如果读不到实例中有father属性,则返回'lzy'return 'lzy'elif attr=='son': # 如果读不到实例中有son属性,则返回'lhm'return 'lhm'raise AttributeError('\'Fibnacci\' object has no attribute \'%s\' % attr)# __getattr__默认返回None,我们需要补上异常def __call__(self, **kwargs): # f=Fibnacci, f(...)的调用pass
静态方法和类方法
classmethod类似于C++中的静态成员函数,只能访问类属性而不能访问实例属性。staticmethod作为一个工具函数,不能访问类的属性也不能访问实例的属性。
class cal():cal_name = '计算器'def __init__(self,x,y):self.x = xself.y = y@classmethod #@classmethon代表函数是类方法,只能访问类的数据属性,不能获取实例的数据属性def cal_info(cls): #python自动传入位置参数cls就是类本身print('这是一个%s'%cls.cal_name) #cls.cal_name调用类自己的数据属性@staticmethod #静态方法 类或实例均可调用def cal_test(a,b,c): #静态方法函数里不传入self或clsprint(a,b,c)
绘制点图
import matplotlib.pyplot as pltfig = plt.figure()ax = fig.add_subplot(1, 1, 1)ax.scatter(x, y) # x和y是listplt.show()
绘制分布图
import seaborn as snsx = list(...)sns.distplot(x)
init.py的使用
init.py的原始使命是声明一个模块,所以它可以是一个空文件。在init.py中声明的所有类型和变量,就是其代表的模块的类型和变量。我们在利用init.py时,应该遵循如下几个原则:
1、不要污染现有的命名空间。模块一个目的,是为了避免命名冲突,如果你在种用init.py时违背这个原则,是反其道而为之,就没有必要使用模块了。
2、利用init.py对外提供类型、变量和接口,对用户隐藏各个子模块的实现。一个模块的实现可能非常复杂,你需要用很多个文件,甚至很多子模块来实现,但用户可能只需要知道一个类型和接口。
假设我们的文件结构是这样的:
└── main.py└── mypackage├── test.py├── sub1│ ├── test11.py│ └── test12.py├── sub2│ ├── test21.py│ └── test22.py└── sub3├── test31.py└── test32.py
test.py:
from .sub1 import test11.py # boom, unresolved `sub1`
必须要给子文件夹加上init.py,python才会将子文件夹认为是一个包(package),才能import。文件夹中的init.py会在该包被import时调用(只会执行一次,不会因为多次被import就执行多次)。
加上init.py后的文件结构应该是这样的:
└── main.py└── mypackage├── test.py├── __init__.py├── sub1│ ├── __init__.py│ ├── test11.py│ └── test12.py├── sub2│ ├── __init__.py│ ├── test21.py│ └── test22.py└── sub3├── __init__.py├── test31.py└── test32.py
mypackage.sub1.init.py:
from . import test11from . import test12f1 = test11.f1f2 = test21.f2 # 这两行写了以后可以在main.py中mypackage.sub1.f1()这样# 不需要mypackage.sub1.test11.f1()# f1、f2成为了sub1这个package的module
mypackage.init.py:
from . import sub1from . import sub2from . import sub3__all__ = ['sub1', 'sub2'] # 在main.py中from mypackage import * 时只有sub1、sub2会导入# 郑老师说__all__多写在功能py中不会写在__init__里

若有收获,就点个赞吧
0 人点赞
